
A Novel Method of Deep Learning for Shear Velocity Prediction in a Tight Sandstone Reservoir


Abstract
:1. Introduction
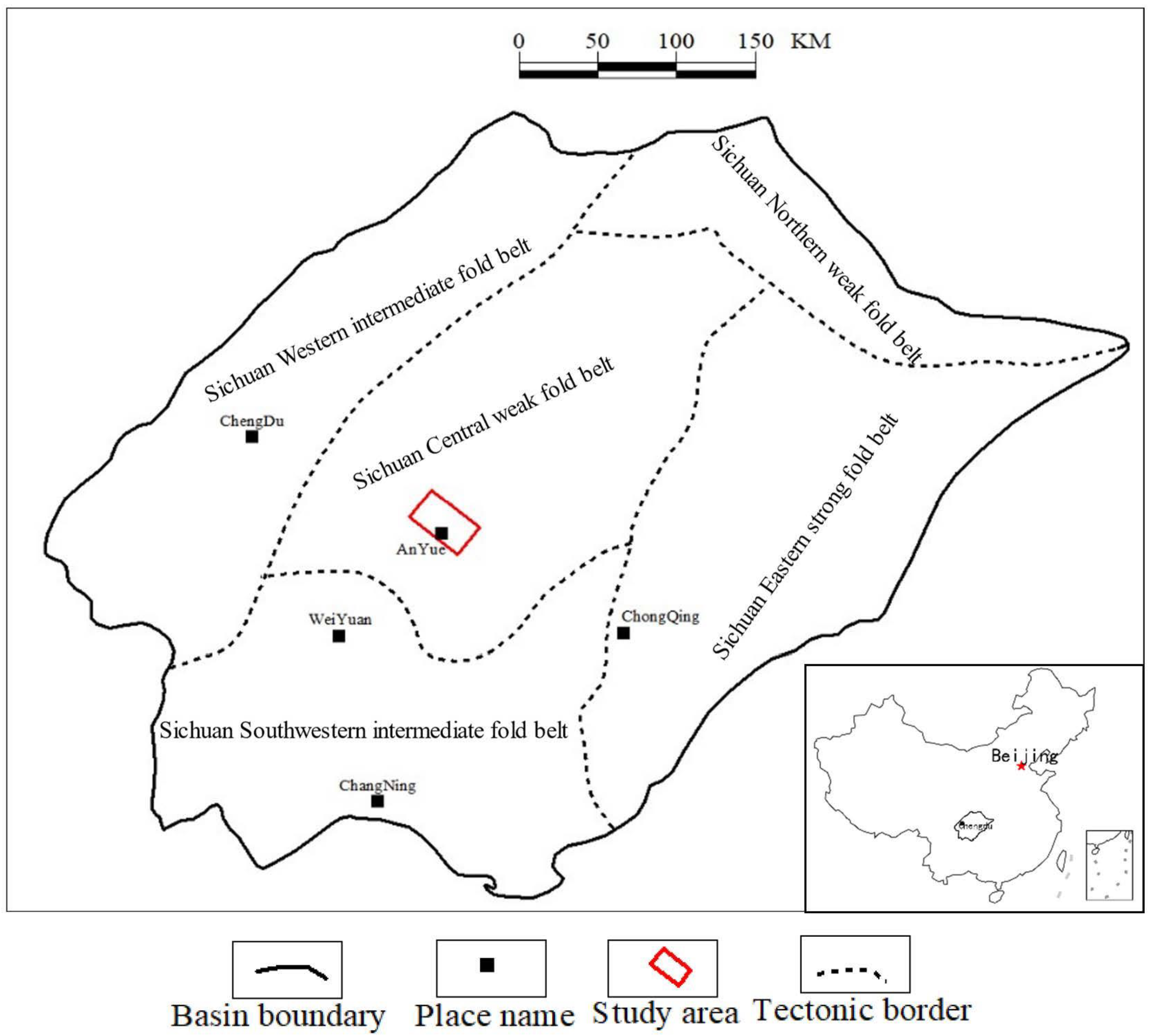
2. Geologic Settings
2.1. Structural Geology
2.2. Sedimentary Geology
3. Well Data
4. Methodology and Workflow
- 1.
- Data preparation and cleaning: The purpose of this step is to remove the abnormal values and eliminate the influence of the borehole environment on the input and target curve.
- 2.
- Optimization of feature curves: XGBoost algorithm was used to automatically select the most important curve associated with the shear velocity as the final input curve for training.
- 3.
- Construction of feedforward neural network: We constructed a deep feedforward neural network with multiple layers.
- 4.
- Network fitting and evaluation: Because the weight and bias coefficients of the hidden layer cannot be obtained directly, the parameters of the network can be adjusted by comparing the errors between the results of the output layer and the expected output during the training process.
- (a)
- Based on the optimization of the activation and loss functions, the constructed network’s weight coefficient and bias were initialized randomly.
- (b)
- Forward propagation of the network: We imported the optimized feature curves into the input layer of the neural network, calculated the output value of the output layer (see Equations (1) and (2)), compared them with the expected output (shear velocity measured) and calculated the loss function value.
- (c)
- Network backpropagation: If the loss function value cannot meet the terminating condition, the output will be backpropagated layer-by-layer through the hidden layer to the input layer in a certain form, and the selected optimization algorithm will be used to allocate the error to all neurons in the front layers to obtain the error signal of each unit and as the basis for updating the weight coefficient and bias.
- (d)
- Suppose the loss function value meets the accuracy requirements or other terminating conditions, in that case, the training process and parameters updating should be ended, and the final network parameters can be saved for subsequent shear velocity prediction. Otherwise, steps (b) and (c) should be repeated.
- the activation function of neurons in l- layer
- the weight matrix of neurons from l-1 to l- layer
- the bias coefficient of neurons from the l-1 to l- layerthe net input of neurons in l- layer
- the output of neurons in l- layer
5. Data Cleaning and Preparation
5.1. Removal of Outliers Values and Correction of Logging Curves
5.2. Optimization of Feature Curves
5.3. Multi-Well Standardization
5.4. Data Splitting
5.5. Construction of the Network
6. Training
6.1. Normalization of Input Curves
6.2. Random Initialization of Model Parameters
6.3. Selection of Loss Function
6.4. Optimization of Activation Function
6.5. Optimization of Algorithm
7. Validation
8. Conclusions and Further Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gholami, A.; Amirpour, M.; Ansari, H.R.; Seyedali, S.M.; Semnani, A.; Golsanami, N.; Heidaryan, E.; Ostadhassan, M. Porosity prediction from pre-stack seismic data via committee machine with optimized parameters. J. Pet. Sci. Eng. 2022, 210, 110067. [Google Scholar] [CrossRef]
- Liu, L.; Geng, J.-H.; Guo, T.-L. The bound weighted average method (BWAM) for predicting S-wave velocity. Appl. Geophys. 2012, 9, 421–428. [Google Scholar] [CrossRef]
- Qiu, T.; Xu, D.; Liu, J. Shear Wave Velocity Prediction of Glutenite Reservoir Based on Pore Structure Classification and Multiple Regression. In Proceedings of the 83rd EAGE Annual Conference & Exhibition, Madrid, Spain, 6–9 June 2022; pp. 1–5. [Google Scholar]
- Zhang, Y.; Zhang, C.; Ma, Q.; Zhang, X.; Zhou, H. Automatic prediction of shear wave velocity using convolutional neural networks for different reservoirs in Ordos Basin. J. Pet. Sci. Eng. 2022, 208, 109252. [Google Scholar] [CrossRef]
- Ghanbarnejad Moghanloo, H.; Riahi, M.A. Application of prestack Poisson dampening factor and Poisson impedance inversion in sand quality and lithofacies discrimination. Arab. J. Geosci. 2022, 15, 116. [Google Scholar] [CrossRef]
- Ashraf, U.; Zhang, H.; Anees, A.; Ali, M.; Zhang, X.; Shakeel Abbasi, S.; Nasir Mangi, H. Controls on reservoir heterogeneity of a shallow-marine reservoir in Sawan Gas Field, SE Pakistan: Implications for reservoir quality prediction using acoustic impedance inversion. Water 2020, 12, 2972. [Google Scholar] [CrossRef]
- Anees, A.; Zhang, H.; Ashraf, U.; Wang, R.; Liu, K.; Abbas, A.; Ullah, Z.; Zhang, X.; Duan, L.; Liu, F. Sedimentary facies controls for reservoir quality prediction of lower shihezi member-1 of the Hangjinqi area, Ordos Basin. Minerals 2022, 12, 126. [Google Scholar] [CrossRef]
- Farfour, M.; Gaci, S.; El-Ghali, M.; Mostafa, M. A review about recent seismic techniques in shale-gas exploration. In Methods and Applications in Petroleum and Mineral Exploration and Engineering Geology; Elsevier: Amsterdam, The Netherlands, 2021; pp. 65–80. [Google Scholar]
- Sohail, G.M.; Hawkes, C.D. An evaluation of empirical and rock physics models to estimate shear wave velocity in a potential shale gas reservoir using wireline logs. J. Pet. Sci. Eng. 2020, 185, 106666. [Google Scholar] [CrossRef]
- Du, Q.; Yasin, Q.; Ismail, A.; Sohail, G.M. Combining classification and regression for improving shear wave velocity estimation from well logs data. J. Pet. Sci. Eng. 2019, 182, 106260. [Google Scholar] [CrossRef]
- Castagna, J.P.; Batzle, M.L.; Eastwood, R.L. Relationships between compressional-wave and shear-wave velocities in clastic silicate rocks. Geophysics 1985, 50, 571–581. [Google Scholar] [CrossRef]
- Domenico, S.N. Rock lithology and porosity determination from shear and compressional wave velocity. Geophysics 1984, 49, 1188–1195. [Google Scholar] [CrossRef]
- Greenberg, M.; Castagna, J. Shear-wave velocity estimation in porous rocks: Theoretical formulation, preliminary verification and applications1. Geophys. Prospect. 1992, 40, 195–209. [Google Scholar] [CrossRef]
- Han, D.-h.; Nur, A.; Morgan, D. Effects of porosity and clay content on wave velocities in sandstones. Geophysics 1986, 51, 2093–2107. [Google Scholar] [CrossRef]
- Pickett, G.R. Acoustic character logs and their applications in formation evaluation. J. Pet. Technol. 1963, 15, 659–667. [Google Scholar] [CrossRef]
- Tosaya, C.; Nur, A. Effects of diagenesis and clays on compressional velocities in rocks. Geophys. Res. Lett. 1982, 9, 5–8. [Google Scholar] [CrossRef]
- Wang, P.; Peng, S. On a new method of estimating shear wave velocity from conventional well logs. J. Pet. Sci. Eng. 2019, 180, 105–123. [Google Scholar] [CrossRef]
- Wyllie, M.; Gregory, A.; Gardner, G. An experimental investigation of factors affecting elastic wave velocities in porous media. Geophysics 1958, 23, 459–493. [Google Scholar] [CrossRef]
- Ali, M.; Jiang, R.; Ma, H.; Pan, H.; Abbas, K.; Ashraf, U.; Ullah, J. Machine learning-A novel approach of well logs similarity based on synchronization measures to predict shear sonic logs. J. Pet. Sci. Eng. 2021, 203, 108602. [Google Scholar] [CrossRef]
- Rajabi, M.; Hazbeh, O.; Davoodi, S.; Wood, D.A.; Tehrani, P.S.; Ghorbani, H.; Mehrad, M.; Mohamadian, N.; Rukavishnikov, V.S.; Radwan, A.E. Predicting shear wave velocity from conventional well logs with deep and hybrid machine learning algorithms. J. Pet. Explor. Prod. Technol. 2022, 1–24. [Google Scholar] [CrossRef]
- Ali, M.; Ma, H.; Pan, H.; Ashraf, U.; Jiang, R. Building a rock physics model for the formation evaluation of the Lower Goru sand reservoir of the Southern Indus Basin in Pakistan. J. Pet. Sci. Eng. 2020, 194, 107461. [Google Scholar] [CrossRef]
- Hou, B.; Chen, X.; Zhang, X. Critical porosity Pride model and its application. Shiyou Diqiu Wuli Kantan (Oil Geophys. Prospect.) 2012, 47, 277–281. [Google Scholar]
- Lee, M.W. A simple method of predicting S-wave velocity. Geophysics 2006, 71, F161–F164. [Google Scholar] [CrossRef]
- Xu, S.; Payne, M.A. Modeling elastic properties in carbonate rocks. Lead. Edge 2009, 28, 66–74. [Google Scholar] [CrossRef]
- Xu, S.; White, R. A new velocity model for clay-sand mixtures: Geophysical Prospecting. Int. J. Rock Mech. Min. Sci. Geomech. Abstr. 1995, 7, 333A. [Google Scholar]
- Mehrgini, B.; Izadi, H.; Memarian, H. Shear wave velocity prediction using Elman artificial neural network. Carbonates Evaporites 2019, 34, 1281–1291. [Google Scholar] [CrossRef]
- Tabari, K.; Tabari, O.; Tabari, M. A fast method for estimating shear wave velocity by using neural network. Aust. J. Basic Appl. Sci. 2011, 5, 1429–1434. [Google Scholar]
- Zahmatkesh, I.; Soleimani, B.; Kadkhodaie, A.; Golalzadeh, A.; Abdollahi, A.-M. Estimation of DSI log parameters from conventional well log data using a hybrid particle swarm optimization–adaptive neuro-fuzzy inference system. J. Pet. Sci. Eng. 2017, 157, 842–859. [Google Scholar] [CrossRef]
- Akkurt, R.; Conroy, T.T.; Psaila, D.; Paxton, A.; Low, J.; Spaans, P. Accelerating and enhancing petrophysical analysis with machine learning: A case study of an automated system for well log outlier detection and reconstruction. In Proceedings of the SPWLA 59th Annual Logging Symposium, London, UK, 2–6 June 2018. [Google Scholar]
- Silva, A.A.; Neto, I.A.L.; Misságia, R.M.; Ceia, M.A.; Carrasquilla, A.G.; Archilha, N.L. Artificial neural networks to support petrographic classification of carbonate-siliciclastic rocks using well logs and textural information. J. Appl. Geophys. 2015, 117, 118–125. [Google Scholar] [CrossRef]
- Ashraf, U.; Zhang, H.; Anees, A.; Mangi, H.N.; Ali, M.; Zhang, X.; Imraz, M.; Abbasi, S.S.; Abbas, A.; Ullah, Z. A core logging, machine learning and geostatistical modeling interactive approach for subsurface imaging of lenticular geobodies in a clastic depositional system, SE Pakistan. Nat. Resour. Res. 2021, 30, 2807–2830. [Google Scholar] [CrossRef]
- Hussain, M.; Liu, S.; Ashraf, U.; Ali, M.; Hussain, W.; Ali, N.; Anees, A. Application of Machine Learning for Lithofacies Prediction and Cluster Analysis Approach to Identify Rock Type. Energies 2022, 15, 4501. [Google Scholar] [CrossRef]
- Sahoo, S.; Jha, M.K. Pattern recognition in lithology classification: Modeling using neural networks, self-organizing maps and genetic algorithms. Hydrogeol. J. 2017, 25, 311–330. [Google Scholar] [CrossRef]
- Li, Y.; Anderson-Sprecher, R. Facies identification from well logs: A comparison of discriminant analysis and naïve Bayes classifier. J. Pet. Sci. Eng. 2006, 53, 149–157. [Google Scholar] [CrossRef]
- Sebtosheikh, M.A.; Motafakkerfard, R.; Riahi, M.-A.; Moradi, S.; Sabety, N. Support vector machine method, a new technique for lithology prediction in an Iranian heterogeneous carbonate reservoir using petrophysical well logs. Carbonates Evaporites 2015, 30, 59–68. [Google Scholar] [CrossRef]
- Shi, N.; Li, H.-Q.; Luo, W.-P. Data mining and well logging interpretation: Application to a conglomerate reservoir. Appl. Geophys. 2015, 12, 263–272. [Google Scholar] [CrossRef]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386. [Google Scholar] [CrossRef]
- Widrow, B.; Hoff, M.E. Adaptive switching circuits. in 1960 ire wescon convention record, 1960. reprinted in. Neurocomputing 1988, 49, 123. [Google Scholar]
- Rumelhart, D.E. Learning internal representations by error propagation. In Parallel Distributed Processing: Explorations in the Microstructure of Cognition; MIT Press: Cambridge, MA, USA, 1986; pp. 318–362. [Google Scholar]
- LeCun, Y.; Touresky, D.; Hinton, G.; Sejnowski, T. A theoretical framework for back-propagation. In Proceedings of the 1988 Connectionist Models Summer School; Morgan Kaufmann: San Mateo, CA, USA, 1988; pp. 21–28. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Hinton, G. Graduate Summer School: Deep learning, Feature Learning. 2012. Available online: https://www.ipam.ucla.edu/schedule.aspx?pc=gss2012 (accessed on 24 August 2022).
- Bengio, Y.; LeCun, Y. Scaling learning algorithms towards AI. Large-Scale Kernel Mach. 2007, 34, 1–41. [Google Scholar]
- Ranzato, M.A.; Boureau, Y.-L.; Cun, Y. Sparse feature learning for deep belief networks. In Proceedings of the Twenty-First Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007. [Google Scholar]
- Delalleau, O.; Bengio, Y. Shallow vs. deep sum-product networks. In Proceedings of the 25th Annual Conference on Neural Information Processing Systems 2011, Granada, Spain, 12–14 December 2011. [Google Scholar]
- Montufar, G.F.; Pascanu, R.; Cho, K.; Bengio, Y. On the number of linear regions of deep neural networks. In Proceedings of the Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Pascanu, R.; Gulcehre, C.; Cho, K.; Bengio, Y. How to construct deep recurrent neural networks. arXiv 2013, arXiv:1312.6026. [Google Scholar]
- Ashraf, U.; Zhang, H.; Anees, A.; Nasir Mangi, H.; Ali, M.; Ullah, Z.; Zhang, X. Application of unconventional seismic attributes and unsupervised machine learning for the identification of fault and fracture network. Appl. Sci. 2020, 10, 3864. [Google Scholar] [CrossRef]
- Meshalkin, Y.; Koroteev, D.; Popov, E.; Chekhonin, E.; Popov, Y. Robotized petrophysics: Machine learning and thermal profiling for automated mapping of lithotypes in unconventionals. J. Pet. Sci. Eng. 2018, 167, 944–948. [Google Scholar] [CrossRef]
- Li, S.; Liu, B.; Ren, Y.; Chen, Y.; Yang, S.; Wang, Y.; Jiang, P. Deep-learning inversion of seismic data. arXiv 2019, arXiv:1901.07733. [Google Scholar] [CrossRef]
- Liu, M.; Grana, D. Accelerating geostatistical seismic inversion using TensorFlow: A heterogeneous distributed deep learning framework. Comput. Geosci. 2019, 124, 37–45. [Google Scholar] [CrossRef]
- Richardson, A. Seismic full-waveform inversion using deep learning tools and techniques. arXiv 2018, arXiv:1801.07232. [Google Scholar]
- Sacramento, I.; Trindade, E.; Roisenberg, M.; Bordignon, F.; Rodrigues, B.B. Acoustic impedance deblurring with a deep convolution neural network. IEEE Geosci. Remote Sens. Lett. 2018, 16, 315–319. [Google Scholar] [CrossRef]
- Feng, R. Estimation of reservoir porosity based on seismic inversion results using deep learning methods. J. Nat. Gas Sci. Eng. 2020, 77, 103270. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, G.; Bai, M.; Zu, S.; Guan, Z.; Zhang, M. Automatic waveform classification and arrival picking based on convolutional neural network. Earth Space Sci. 2019, 6, 1244–1261. [Google Scholar] [CrossRef] [Green Version]
- Yuan, S.; Liu, J.; Wang, S.; Wang, T.; Shi, P. Seismic waveform classification and first-break picking using convolution neural networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 272–276. [Google Scholar] [CrossRef]
- Smith, R.; Mukerji, T.; Lupo, T. Correlating geologic and seismic data with unconventional resource production curves using machine learning. Geophysics 2019, 84, O39–O47. [Google Scholar] [CrossRef]
- Jiang, R.; Zhao, L.; Xu, A.; Ashraf, U.; Yin, J.; Song, H.; Su, N.; Du, B.; Anees, A. Sweet spots prediction through fracture genesis using multi-scale geological and geophysical data in the karst reservoirs of Cambrian Longwangmiao Carbonate Formation, Moxi-Gaoshiti area in Sichuan Basin, South China. J. Pet. Explor. Prod. Technol. 2022, 12, 1313–1328. [Google Scholar] [CrossRef]
- Kangling, D. Formation and evolution of Sichuan Basin and domains for oil and gas exploration. Nat. Gas Ind. 1992, 12, 7–12. [Google Scholar]
- Huang, X.; Zhang, L.; Zheng, W.; Xiang, X.; Wang, G. Controlling Factors of Gas Well Deliverability in the Tight Sand Gas Reservoirs of the Upper Submember of the Second Memher of the Upper Triassic Xujiahe Formation in the Anyue Area, Sichuan Basin. Nat. Gas Ind. 2012, 32, 65. [Google Scholar]
- Ullah, J.; Luo, M.; Ashraf, U.; Pan, H.; Anees, A.; Li, D.; Ali, M.; Ali, J. Evaluation of the geothermal parameters to decipher the thermal structure of the upper crust of the Longmenshan fault zone derived from borehole data. Geothermics 2022, 98, 102268. [Google Scholar] [CrossRef]
- Li, M.; Lai, Q.; Huang, K. Logging identification of fluid properties in low porosity and low permeability clastic reservoir: A case study of Xujiahe Fm gas reservoirs in the Anyue gas field, Sichuan basin. Nat. Gas Ind. 2013, 33, 34–38. (In Chinese) [Google Scholar]
- Zeng, Q.; Gong, C.; Li, J.; Che, G.; Lin, J. Exploration achievements and potential analysis of gas reservoirs in the Xujiahe formation, central Sichuan Basin. Nat. Gas Ind. 2009, 29, 13–18. [Google Scholar]
- Xu, C.; Misra, S.; Srinivasan, P.; Ma, S. When petrophysics meets big data: What can machine do? In Proceedings of the SPE Middle East Oil and Gas Show and Conference, Manama, Bahrain, 18–21 March 2019. [Google Scholar]
- Rumbert, D. Learning internal representations by error propagation. Parallel Distrib. Process. 1986, 1, 318–363. [Google Scholar]
- de Macedo, I.A.; de Figueiredo, J.J.S.; De Sousa, M.C. Density log correction for borehole effects and its impact on well-to-seismic tie: Application on a North Sea data set. Interpretation 2020, 8, T43–T53. [Google Scholar] [CrossRef]
- Ugborugbo, O.; Rao, T. Impact of borehole washout on acoustic logs and well-to-seismic ties. In Proceedings of the Nigeria Annual International Conference and Exhibition, Abuja, Nigeria, 3 August 2009. [Google Scholar]
- Anifowose, F.A.; Labadin, J.; Abdulraheem, A. Non-linear feature selection-based hybrid computational intelligence models for improved natural gas reservoir characterization. J. Nat. Gas Sci. Eng. 2014, 21, 397–410. [Google Scholar] [CrossRef]
- Tao, Z.; Huiling, L.; Wenwen, W.; Xia, Y. GA-SVM based feature selection and parameter optimization in hospitalization expense modeling. Appl. Soft Comput. 2019, 75, 323–332. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Lideng, G.; Xiaofeng, D.; Zhang, X.; Linggao, L.; Wenhui, D.; Xiaohong, L.; Yinbo, G.; Minghui, L.; Shufang, M.; HUANG, Z. Key technologies for seismic reservoir characterization of high water-cut oilfields. Pet. Explor. Dev. 2012, 39, 391–404. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Al-Farisi, O.; Dajani, N.; Boyd, D.; Al-Felasi, A. Data management and quality control in the petrophysical environment. In Proceedings of the Abu Dhabi International Petroleum Exhibition and Conference, Abu Dhabi, United Arab Emirates, 11–14 October 2002. [Google Scholar]
- Kumar, M.; Dasgupta, R.; Singha, D.K.; Singh, N. Petrophysical evaluation of well log data and rock physics modeling for characterization of Eocene reservoir in Chandmari oil field of Assam-Arakan basin, India. J. Pet. Explor. Prod. Technol. 2018, 8, 323–340. [Google Scholar] [CrossRef]
- Theys, P.; Roque, T.; Constable, M.V.; Williams, J.; Storey, M. Current status of well logging data deliverables and a vision forward. In Proceedings of the SPWLA 55th Annual Logging Symposium, Abu Dhabi, United Arab Emirates, 18–22 May 2014. [Google Scholar]
- Jarrett, K.; Kavukcuoglu, K.; Ranzato, M.A.; LeCun, Y. What is the best multi-stage architecture for object recognition? In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2146–2153. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the ICML, Atlanta, GA, USA, 16–21 June 2013; p. 3. [Google Scholar]
- Klambauer, G.; Unterthiner, T.; Mayr, A.; Hochreiter, S. Self-normalizing neural networks. In Proceedings of the Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Clevert, D.-A.; Unterthiner, T.; Hochreiter, S. Fast and accurate deep network learning by exponential linear units (elus). arXiv 2015, arXiv:1511.07289. [Google Scholar]
- Hochreiter, S.; Younger, A.S.; Conwell, P.R. Learning to learn using gradient descent. In Proceedings of the International Conference on Artificial Neural Networks, Vienna, Austria, 21–25 August 2001; pp. 87–94. [Google Scholar]
- Darken, C.; Chang, J.; Moody, J. Learning rate schedules for faster stochastic gradient search. In Proceedings of the Neural Networks for Signal Processing, Helsingoer, Denmark, 31 August–2 September 1992. [Google Scholar]
- Khirirat, S.; Feyzmahdavian, H.R.; Johansson, M. Mini-batch gradient descent: Faster convergence under data sparsity. In Proceedings of the 2017 IEEE 56th Annual Conference on Decision and Control (CDC), Melbourne, Australia, 12–15 December 2017; pp. 2880–2887. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Nesterov, Y. Gradient methods for minimizing composite functions. Math. Program. 2013, 140, 125–161. [Google Scholar] [CrossRef]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Liu, K.; Sun, J.; Zhang, H.; Liu, H.; Chen, X. A new method for calculation of water saturation in shale gas reservoirs using VP-to-VS ratio and porosity. J. Geophys. Eng. 2018, 15, 224–233. [Google Scholar] [CrossRef] [Green Version]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CAL | CNL | RHOB | DTC | GR | lg_RT | lg_RXO | DTS | |
|---|---|---|---|---|---|---|---|---|
| Count | 11,391 | 11,391 | 11,391 | 11,391 | 11,391 | 11,391 | 11,391 | 11,391 |
| Mean | 6.73 | 0.12 | 2.57 | 63.75 | 94.27 | 1.60 | 1.60 | 106.20 |
| Std | 0.48 | 0.06 | 0.10 | 5.91 | 33.84 | 0.40 | 0.41 | 13.66 |
| Min | 4.02 | 0.01 | 1.68 | 49.99 | 33.97 | 0.49 | 0.38 | 83.54 |
| Max | 9.15 | 0.65 | 2.84 | 88.26 | 313.11 | 4.57 | 4.79 | 180.04 |
| Name of Activation Function | Formula | Effect |
|---|---|---|
| sigmoid | Its effect is to scale the output of each input neuron to 0–1. | |
| ReLU | If the input x is less than 0, then make the output equal to 0; otherwise, then make the output equal to the input. | |
| Leaky-Relu | If input x is greater than 0, the output is x. If input x is less than or equal to 0, the output is α times the input. | |
| Selu | If the input value x is greater than 0, the output value is x times λ. If the input value x is less than 0, a singular function is obtained, which increases with the increase of x and approaches to the value when x is 0. | |
| Gelu | When x is greater than 0, the output is x, except for the interval from x = 0 to x = 1. At this time, the curve is more inclined to y-axis. | |
| Elu | The result is the same as that of ReLU; that is, the y value is equal to the x value, but if the input x is less than 0, we will obtain a value slightly less than 0. The parameter α can be adjusted as needed. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, R.; Ji, Z.; Mo, W.; Wang, S.; Zhang, M.; Yin, W.; Wang, Z.; Lin, Y.; Wang, X.; Ashraf, U. A Novel Method of Deep Learning for Shear Velocity Prediction in a Tight Sandstone Reservoir. Energies 2022, 15, 7016. https://doi.org/10.3390/en15197016
Jiang R, Ji Z, Mo W, Wang S, Zhang M, Yin W, Wang Z, Lin Y, Wang X, Ashraf U. A Novel Method of Deep Learning for Shear Velocity Prediction in a Tight Sandstone Reservoir. Energies. 2022; 15(19):7016. https://doi.org/10.3390/en15197016
Chicago/Turabian StyleJiang, Ren, Zhifeng Ji, Wuling Mo, Suhua Wang, Mingjun Zhang, Wei Yin, Zhen Wang, Yaping Lin, Xueke Wang, and Umar Ashraf. 2022. "A Novel Method of Deep Learning for Shear Velocity Prediction in a Tight Sandstone Reservoir" Energies 15, no. 19: 7016. https://doi.org/10.3390/en15197016