1. Introduction
Renewable energy refers to the generation of electricity from natural, sustainable resources such as the sun, wind, and water. Solar energy is one of the most popular renewable energy sources. It supplies electric energy to homes or businesses by capturing sunlight. Countries have recently been paying attention to solar energy development because of their advantages: inexhaustible, non-polluting emissions, competitive sources, reducing fossil fuel and natural gas, R
2 and many others [
1]. Even during the COVID-19 pandemic, the solar energy market development did not have a significant impact, excluding some delays due to lockdowns [
2]. Like many other countries, South Korea’s government is interested in increasing solar energy usage. More specifically, the government declared the goal of a low-carbon and eco-friendly nation by increasing the renewable energy market to 40% by 2030 from the current 30% [
3]. Despite the benefits of solar energy, the provision of electrical energy from solar panels also has some drawbacks. More specifically, there is a high initial investment, ample space required for installing solar panels, and inefficient solar panels [
1]. Moreover, solar energy is considered to be intermittent because solar panels produce energy from sunlight. Thus, there are energy storage systems that do not interrupt the power supply. However, persistent bad weather, such as cloudy, rainy, or snowy weather, can result in power outages. Consumers need to monitor weather, electricity production, and consumption to prevent this potential power outage. Energy production forecasting can aid the government’s renewable energy policy as well as help consumers and businesses plan their consumption and develop new products.
Solar panel power generation forecasting is considered a time-series data analysis, which predicts a future outcome based on historical time-stamped data such as the weather. Deep learning methods, particularly long short-term memory (LSTM), have been successfully applied to forecasting time-series data across many domains, including solar panels [
4,
5,
6,
7,
8,
9,
10,
11,
12]. In particular, some studies [
4,
5,
6] have shown the superiority of LSTM models by comparing simple LSTM with other state-of-the-art models, such as back propagation neural networks (BPNN), wavelet neural networks (WNN), support vector machines (SVM), simple recurrent neural networks (RNN), XGBoost, and artificial neural network (ANN). Moreover, incorporating simple LSTM and other deep learning methods such as RNN [
7,
8], convolutional neural network (CNN) [
9,
10,
11], and autoencoders [
12] achieve high performance in forecasting power generation. Even though single LSTM models have achieved significant success in forecasting power generation, single methods may still be weak in overcoming time-series data challenges [
13]. More specifically, effectively capturing data characteristics, such as trends, seasonality, and noise robustness, is essential in time-series data analysis.
Ensemble learning-based deep learning methods have shown significant improvements in forecasting the solar panel power generation to overcome these challenges [
14,
15,
16,
17,
18]. Ensemble learning combines the results from two or more predictive models (i.e., member or base model) to achieve better accuracy than any base model. A common ideology of ensemble learning is that, even if a member is weak in a specific case, the other can be strong. The steps involved in ensemble learning are as follows: (1) base independent models predict an outcome based on various modeling or training data, and (2) ensemble models combine the results of all models to produce a final output. Khan et al. [
14] forecasted the solar panel power generation by proposing a stacked ensemble algorithm that combines LSTM and ANN models. The authors reported that the proposed ensemble method demonstrated an improvement in the R
2 score of 10–12% for a single LSTM and ANN. Pirbazari et al. [
15] also predicted solar panel energy generation and household consumption based on an ensemble method combined with several sequence-to-sequence LSTM networks. Experiments on the proposed method showed the potential of the ensemble LSTM to provide more stable and accurate forecasts. Although numerous studies have employed ensemble methods with various data partitioning methods, most have emphasized enhancing the predictive methods by associating many different models or integrating different hyperparameters and interactions. In practice, the performances of ensemble machine learning models are highly dependent on the data partitioning strategy, the number of partitions, and subset sizes. Choosing only a dedicated data partition strategy and subset size may weaken the prediction model for neglected fluctuations. Liang et al. [
19] and Wang et al. [
20] mentioned the problems of ensemble methods: (1) the number of members significantly affects the accuracy and diversity of ensemble methods, and (2) if the similarity between members is high, the ensemble method may lead to poor performance. Therefore, a feasibility study of data partitioning strategies is essential to effectively reveal the characteristics and features of time-series data and improve the accuracy of power generation forecasting.
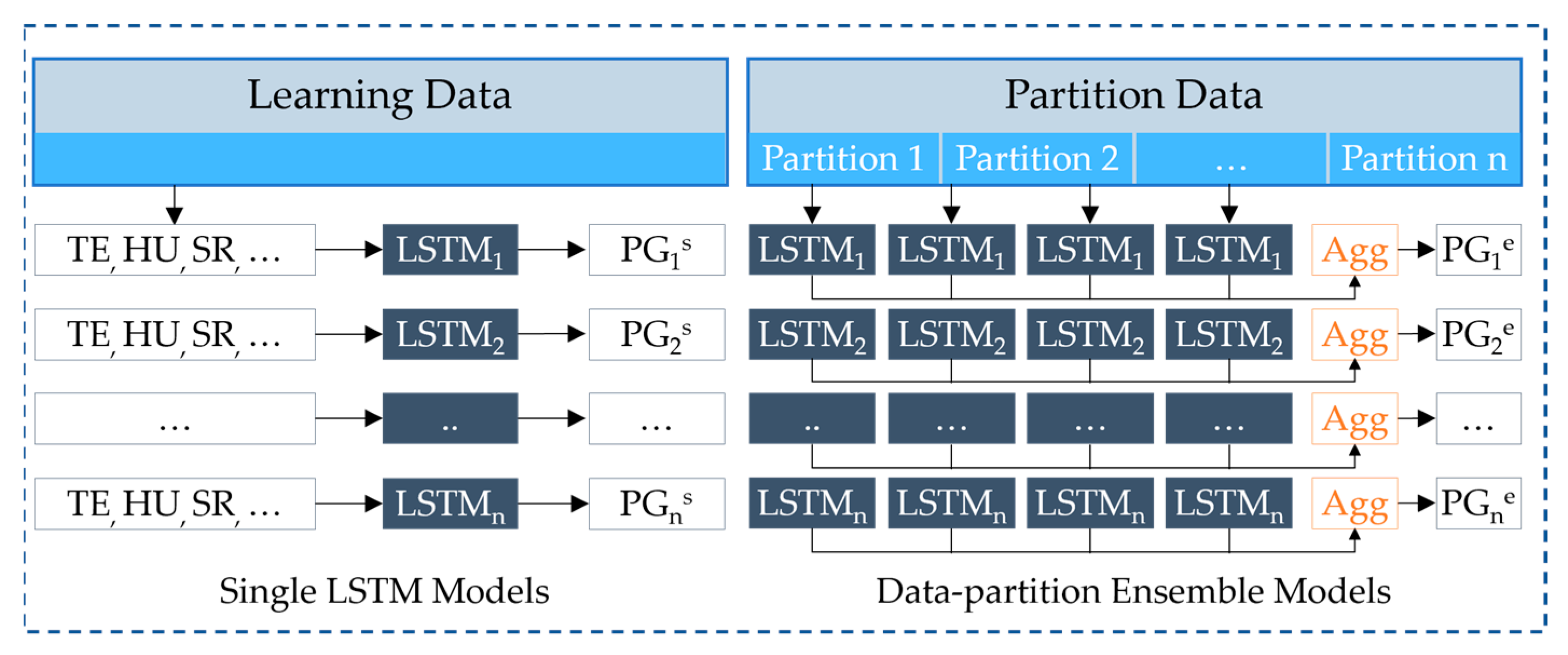
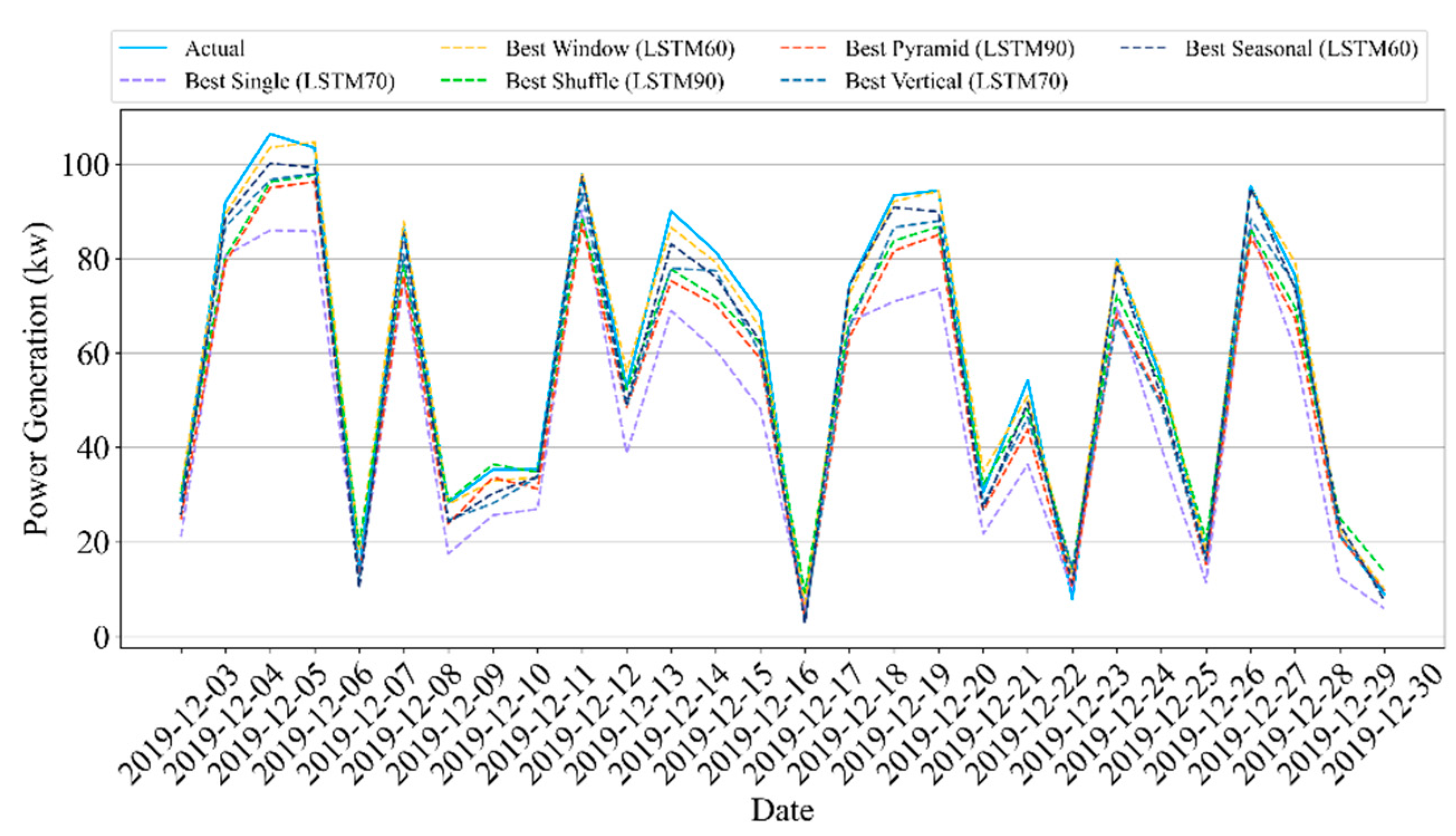
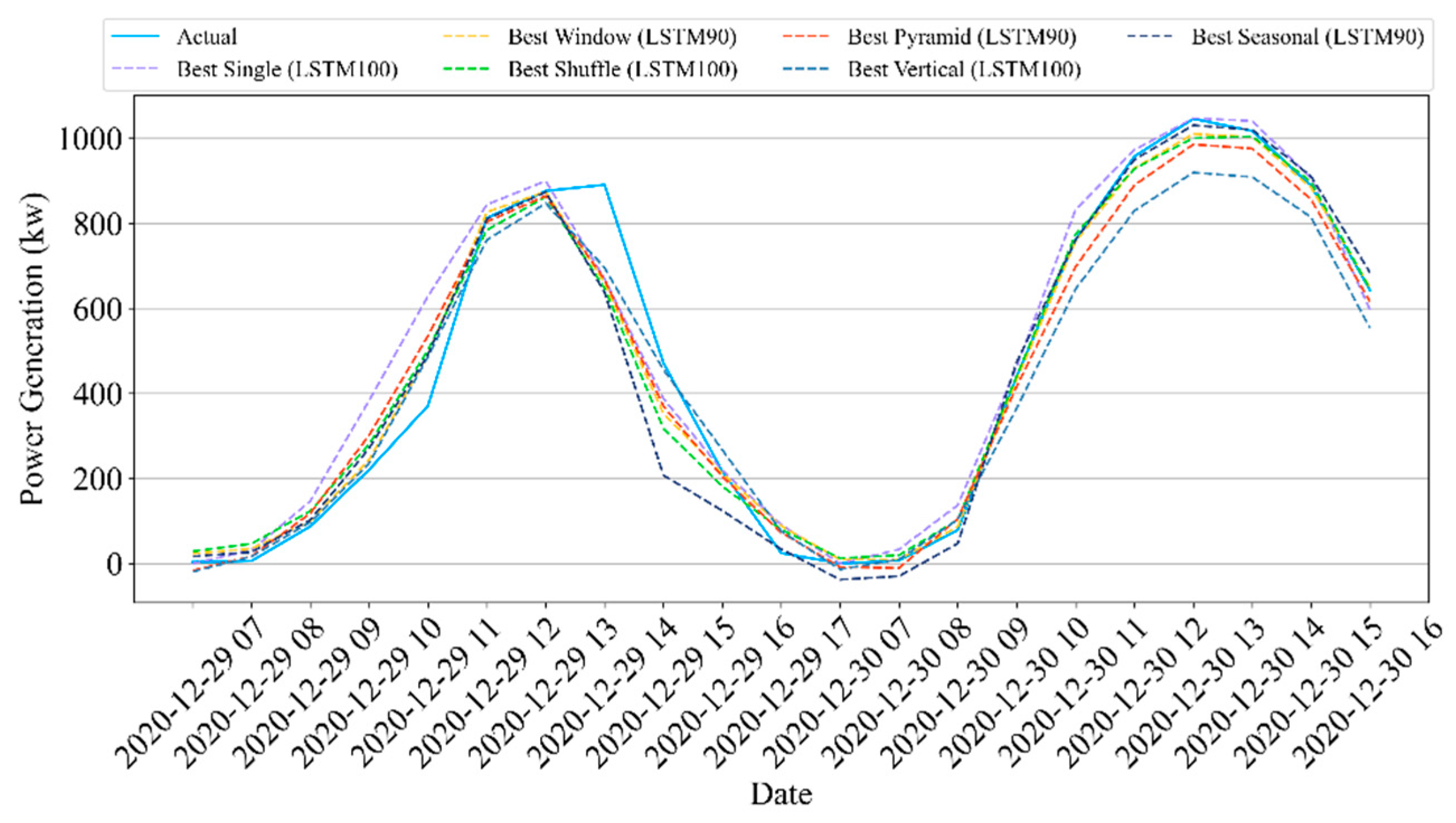
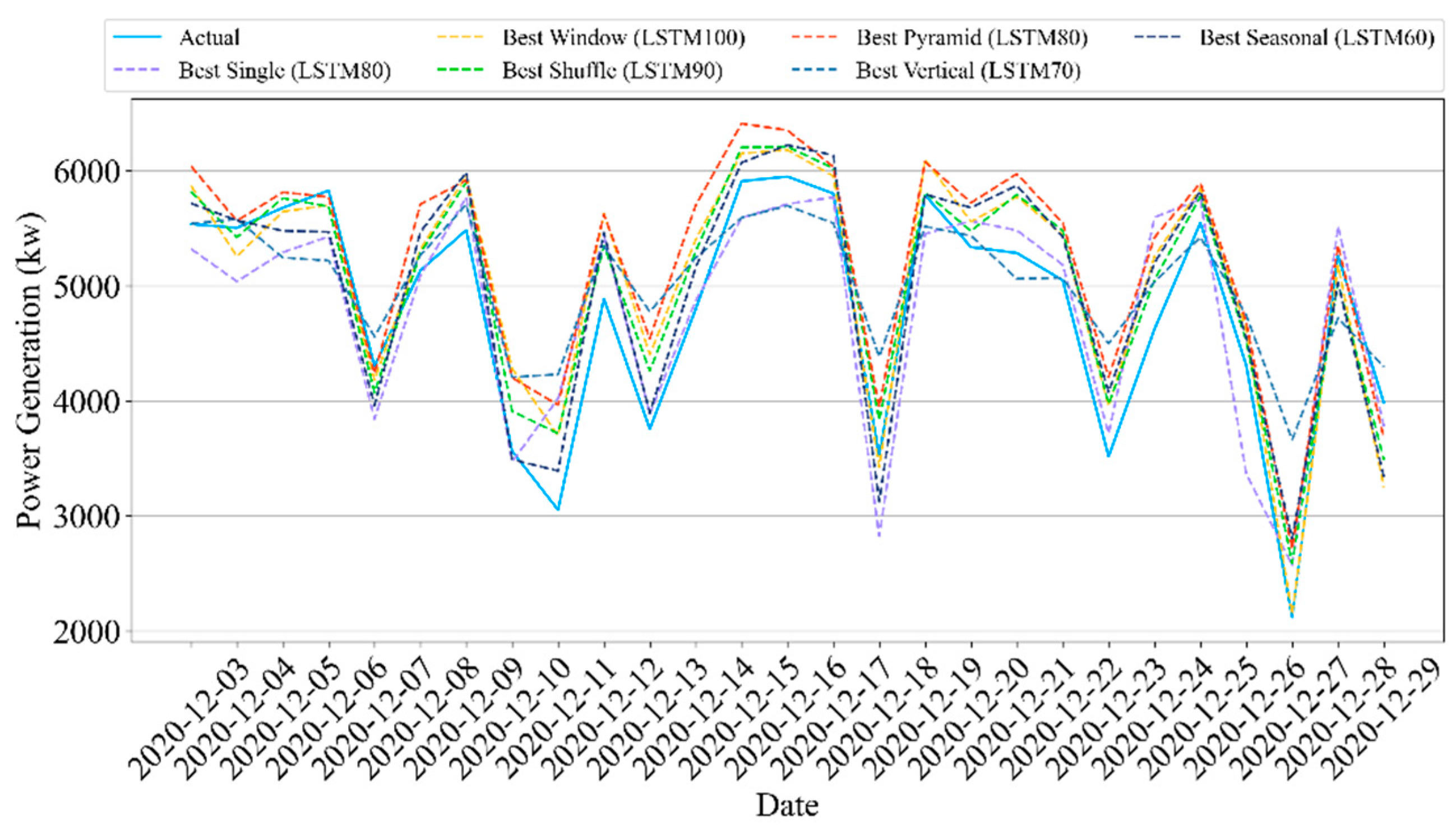
We propose a method for an ensemble deep learning method and data partition strategies to accurately forecast the daily and hourly solar panel power generation. We conducted empirical experiments, in contrast to existing ensemble learning methods, to evaluate the influence of time-series data partition strategies, the number of partitions, and subset sizes. Here, we used an ensemble LSTM model with five time-series data partition strategies: window, shuffle, pyramid, vertical, and seasonal. These data partition strategies enable us to recognize different characteristics and features in time-series data. The main contributions of this study are as follows:
First, we propose an accurate methodology for forecasting daily and hourly solar panel power generation using an ensemble deep learning model and data partitioning. The method consists of three steps: partitioning time-series data, training models using partitioned subsets, and aggregating the results of each model to obtain the final forecasted power generation.
Furthermore, we use five simple data partition strategies, namely window, shuffle, pyramid, vertical, and seasonal, to investigate the influence of each strategy on the accuracy of forecasting the solar panel power generation. Data partition strategies are selected to divide the datasets into effective subsets with different characteristics and features in the time-series data. The ensemble model can comprehend multiple characteristics of data by learning from various characteristics. The experiments evaluated the subset sizes and the number of partitions.
Finally, we evaluated the proposed data partition strategies through extensive experiments using LSTM to forecast the power generation of the solar panels. The experiments examined each data partition using LSTM models with different hyperparameters and checked the influence of different numbers of partitions and subset sizes. We evaluate the experiments on two independent datasets to demonstrate the applicability of the proposed method.
The remainder of this paper is organized as follows: prior studies on the forecasting of solar panel power generation are explained and discussed in
Section 2; the materials and methods used in this study are explained in
Section 3; the evaluation methods and evaluation results are presented in
Section 4; and finally,
Section 5 summarizes and concludes this study and discusses future works.
5. Discussion and Conclusions
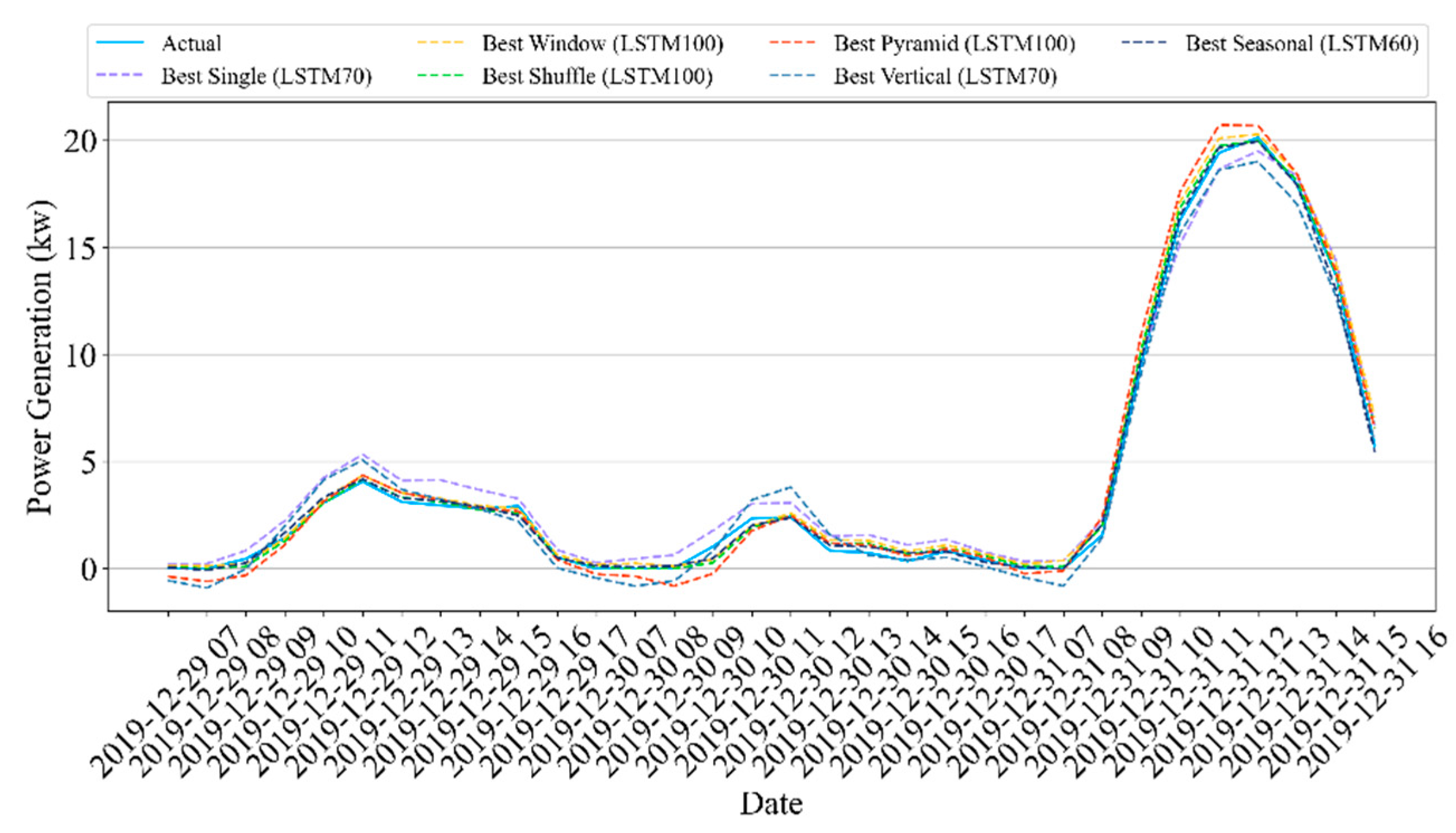
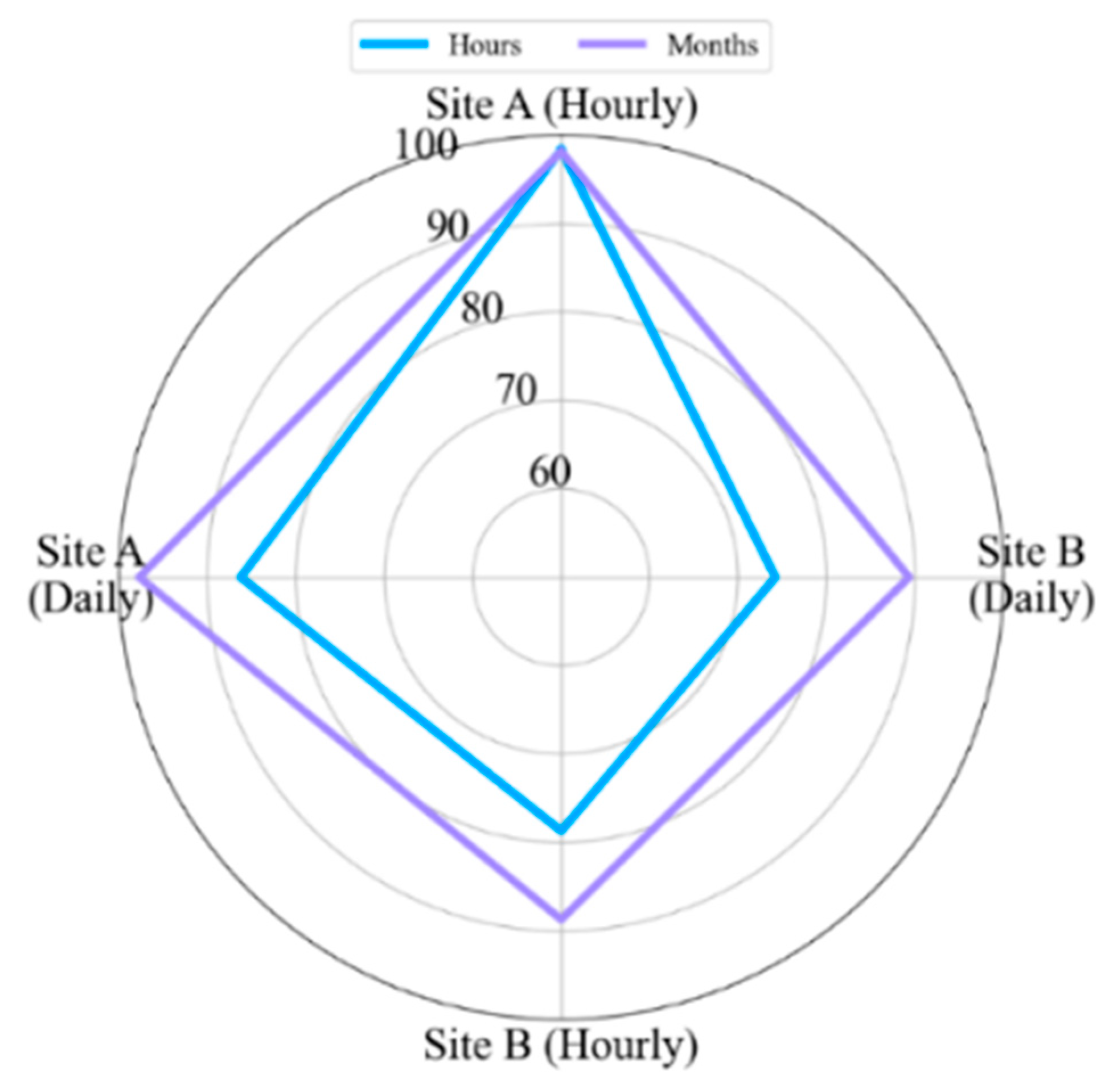
This study presented a methodology that forecasts the hourly and daily solar panel power generation using ensemble LSTM models and five data partition strategies: window, shuffle, pyramid, vertical, and seasonal. We intended to explore the influences of different time-series data partition strategies, the number of partitions, and subset sizes on the performance of the ensemble LSTM model. The extensive experimental results compared the concepts of LSTM methods using testbed (i.e., Site A) and real-world (i.e., Site B) solar panel data.
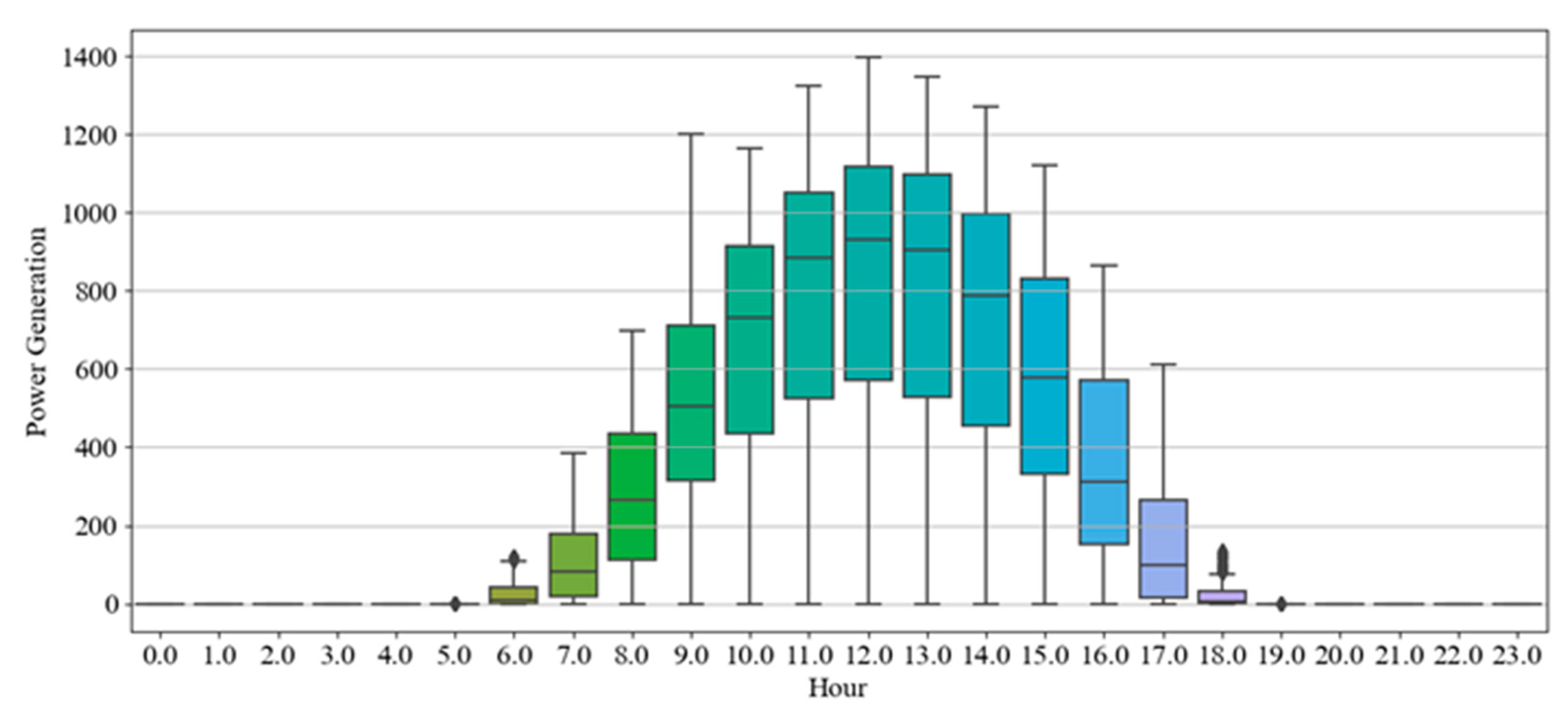
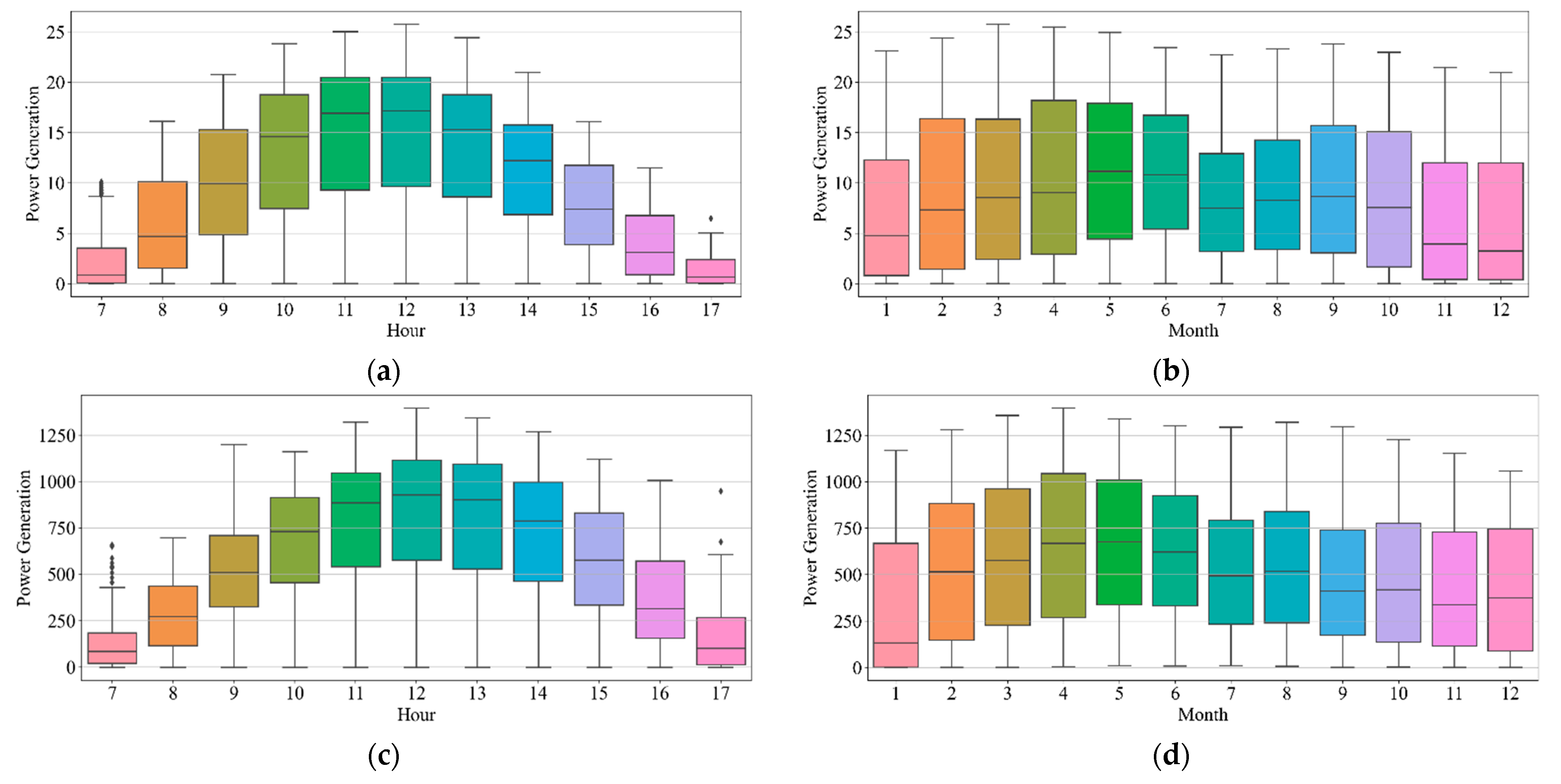
We first implemented five single LSTM models with different units using identical training and test data. The single models had an R2 scores of 93.6–94.9% and 84.4–85.2% for Sites A and B, respectively, in hourly forecasting. For daily forecasting, Sites A and B had R2 scores of 86.8–94% and 83.7–85.8%, respectively. Second, the data partition ensemble LSTM model outperformed all single LSTM models in the experimental cases. More specifically, the results were as follows: Sites A and B had R2 scores of 95.3–98.3% and 85.6–89%, respectively, in hourly forecasting and 90.5–98% and 82.2–89.3%, respectively, in daily forecasting. Particularly, the two-level seasonal data partition strategy showed good performance improvements. Solar panel power generation depends highly on seasons. If we compare winter and summer, winter days are shorter than summer days. Because of shorter days, the sun angle on solar panels changes rapidly in winter. On the contrary, the sun goes higher and stays longer in summer. Additionally, the winter months have more stormy and cloudy weather. Based on these reasons, the collected solar panel power generation data have different features for each season. Training prediction model for each season helps us to reduce high variance and bias. Additionally, we investigated the relationship between performance and the number of partitions as well as the size of subsets. The results indicated that adding more training data did not improve performance.
The experiments proved that the proposed data partition ensemble LSTM methods forecast the hourly and daily solar panel power generation more accurately and reliably. Integrating solar energy monitoring with forecasting models increases the performance of solar panel systems and provides advantages to all participants in the sector, such as government, businesses, and consumers. Using this system, solar energy consumers can reconcile their electricity usage and avoid unexpected power outages and unnecessary costs. Additionally, businesses can give customers additional options and products. Furthermore, the data generated from the models can be used to improve and develop plans. Governments have been promoting renewable energy and have set time-bound goals. Efficient electricity consumption by consumers will help to make government goals more realistic.
This study demonstrated that data partitioning has positive influences on forecasting the solar panel power generation, even though we used simple strategies. However, unlike methods such as clustering, these strategies cannot account for the relationship between the data. Therefore, we plan to study more logical strategies for data partitioning in future study. Consequently, each part of the data contains appropriate data points and helps improve the forecasting performance.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}