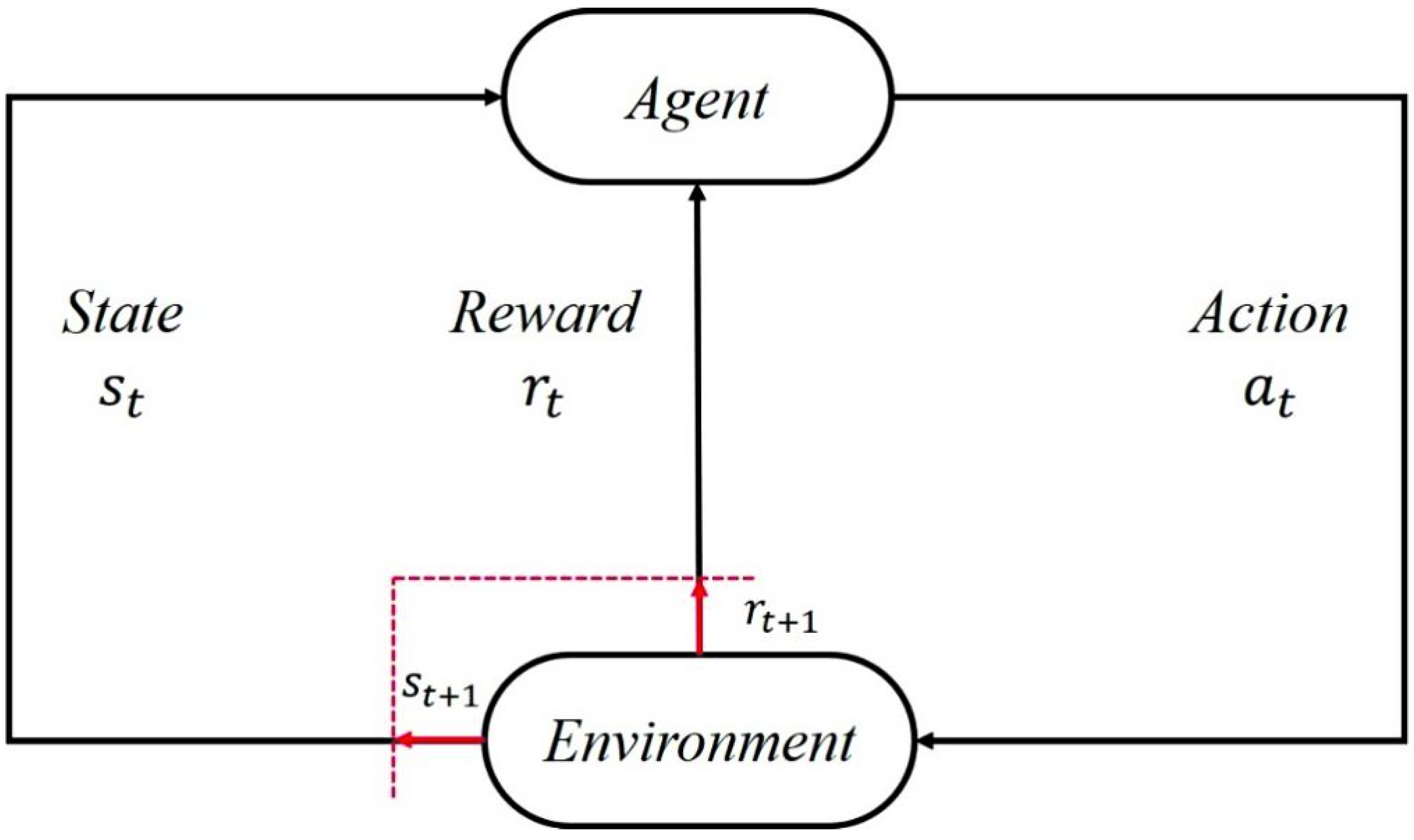
3.1. Model Training
According to the model settings mentioned in
Section 2.5.1, the three proposed reward functions were used to train the model. In addition, the training target related to the end of training, i.e., the average reward of the last 10 episodes, were set as primary, intermediate and advanced targets, corresponding to 1/3, 1/2 and 2/3 of the total reward, respectively. The result is shown in
Figure 11.
The results show that when R1 was used, the highest average reward in the past 10 episodes is only −28.3, while the total reward of a single episode is 168, and the highest reward in a single episode is 53. After training, the primary target of 1/3 of the total reward was still not reached, so the model training failed. When R2 and R3 were used, both the primary and intermediate targets can be achieved. To reach the primary target, the target reward of R2 is 5600. After 800 episodes of training, the model achieved the primary target, and the average reward of 10 episodes was 5671. The primary target of R3 was 2800. After 845 episodes, the model achieved the primary target, and the average reward of 10 episodes was 2832. On the other hand, to reach the intermediate target, the target reward of R2 is 8400. After 586 episodes of training, the model achieved the intermediate target, and the average reward of 10 episodes was 8650. The intermediate target of R3 is 4200. After 612 episodes, the average reward of 10 episodes was 4264 which achieved the intermediate target. Aiming to achieve the advanced target, the model cannot be successfully trained directly using any of the three reward functions proposed in this study. However, if the pretrained model of R2 which achieved the intermediate target was used for retraining, the average reward of 10 episodes was 11,850 after 367 episodes which achieved the advanced target. In summary, results show that R2 is the most suitable for the experimental situation proposed in this study.
The experimental results show that the design of the reward function significantly influences the performance of the model after training. For the same architecture of the agent, the model failed in training when R1 was used, while the model can achieve the advanced target when R2 was used through retraining. The reward distribution of R1 is very sparse due to the fact that there is only one positive reward interval in R1. As a result, the probability that the model can achieve a positive reward during training is low, and the model may not be able to find the correct optimization direction after many attempts, which seriously affects model training efficiency. In addition, the positive and negative rewards set in R1 are not uniform in magnitude, the positive reward is only 1, while the negative reward is −10 and −100. Consequently, the model is more likely to tend to avoid high negative rewards, rather than obtaining high positive rewards during training. The training direction is inconsistent with our training objective. This phenomenon is also verified in the training results, the rewards of most late episodes are small negative values rather than positive values, which indicates a design failure of R1.
Compared with R1, since the reward of target interval in R2 and R3 has the same order of magnitude as the disqualified intervals, the training performance is significantly improved. In addition, the reward of suitable intervals in R2 and R3 is set to 1, which aims to guide the optimization direction of model training. The experimental results also verify the effectiveness of this method. From the perspective of indoor thermal comfort, residents are more reluctant to accept indoor temperatures below 18 °C compared to above 24 °C, because high indoor temperature can be decreased by opening the windows. Therefore, R3 halves the reward for target interval and high temperature intervals, aiming to guide the model to avoid low indoor temperature during training. However, the experimental results show that using R3 does not have better performance, it fails to reach the advanced target even retraining method is used.
With the upgrade of model training target, the difficulty of model training will also increase significantly. Due to all the default parameters of neural network model are randomly initialized at the beginning, the model proposed in this study is not always successful during training. It is found that the training will always fail when R1 is used. However, when the other reward functions are used, the success probabilities of the primary target and the intermediate target are about 40% and 15%, respectively. When R2 is used by the retraining method, the success probability to achieve the advanced target is about 20%. In addition, due to random initialization, even the same agent architecture and reward function are used, the parameters of the final model obtained from each training attempt are different. Therefore, it is not meaningful to compare the number of episodes used for each training attempt. For example, during two different training attempts with R2, it took 800 episodes to reach the primary target, but only took 586 episodes to reach the intermediate target.
3.2. The Performance of Indoor Temperature Control
Figure 12 shows the variation of indoor temperature when the environment was controlled by different prediction models.
When R2 was used, the model which achieved primary target could control the average indoor temperature within 168 h of a complete single episode to 21.6 °C, the RMSE is 1.3 °C and the CV-RMSE is 6.26%. The indoor temperature was controlled within the target interval for 60 h, accounting for 35.7%, within the acceptable interval for 156 h, accounting for 92.9%, and within the qualified interval for 12 h, accounting for 7.1%. The model achieved intermediate target can control the average indoor temperature of a complete single episode to 20.8 °C, the RMSE is 0.5 °C and the CV-RMSE is 2.67%. The indoor temperature was controlled within the target interval for 101 h, accounting for 60.1%, within the acceptable interval for 162 h, accounting for 96.4%, and within the qualified interval for 6 h, accounting for 3.6%. The model which achieved the advanced target could control the average indoor temperature of a complete single episode to 21.2 °C, the RMSE is 0.3 °C and the CV-RMSE is 1.23%. The indoor temperature was controlled within the target interval for 118 h, accounting for 70.2%, within the acceptable interval for 168 h, accounting for 100%.
When R3 was used, the model which achieved the primary target could control the average indoor temperature within a complete single episode to 21.5 °C, the RMSE is 1.3 °C and the CV-RMSE is 6.19%. The indoor temperature was controlled within the target interval for 62 h, accounting for 36.9%, within the acceptable interval for 157 h, accounting for 93.5%, and within the qualified interval for 11 h, accounting for 6.5%. The model which achieved the intermediate target could control the average indoor temperature of a complete single episode to 21.2 °C, the RMSE is 0.5 °C and the CV-RMSE is 2.61%. The indoor temperature was controlled within the target interval for 93 h, accounting for 55.4%, within the acceptable interval for 165 h, accounting for 98.2%, and within the qualified interval for 3 h, accounting for 1.8%.
The experimental results show that under the same training target, models trained with different reward functions have similar performance on indoor temperature control. When the primary target is achieved, the time for the indoor temperature in the target interval is more than 35%; when the intermediate target is achieved, this time increases to more than 55%; and it can further increase to more than 70% when the advanced target is achieved. The performance of indoor temperature control can be significantly improved with the upgrade of the training target, but it should be noticed that the upgrade of the training target will also lead to a significant increase in the difficulty of the model training. It can be seen in
Figure 12 that even with the primary target, the model can maintain the indoor temperature in the acceptable interval for more than 90% of the time. All of the poor indoor temperature control occurs within the first 10 hours of the simulation. The reason is that the initial temperature of the internal node of each building envelope layer was set to 18 °C. Therefore, the heating scenario of the early stage is different from common operation, which requires additional preheating of the building envelopes. It is difficult to learn the preheating scenario in the training process, as a result, it is found in the experiment that the model cannot achieve advanced targets through conventional training methods. However, when the model achieves the intermediate target, the indoor temperature can be appropriately controlled except for the preheating scenario in the early stage. Therefore, on this basis, the retraining method can be used to fine-tune the original model and help the model learn the characteristics of the preheating scenario. The experimental results also verify the effectiveness of retraining method.
3.3. The Performance of On-Demand Heating Operation
Figure 13 shows the variation of heat supply when the environment was controlled by different prediction models.
In the experiment, the total heat demand in a complete episode of 168 h is 43,665.4 kWh. When R2 was used, the total heat supply of the model that achieved the primary target, the intermediate target and the advanced target were 48,060.8 kWh, 42,804.4 kWh and 45,656.6 kWh, respectively. The supply–demand error is 10.07%, −1.97% and 4.56%, respectively. On the other hand, when R3 was used, the total heat supply of the model that achieved the primary target and the intermediate target is 47,148.8 kWh and 45,460.7 kWh, respectively. The supply–demand error is 7.98% and 4.11%, respectively.
Due to the difference in the average indoor temperature controlled by different models, the total heat supply in a single episode is slightly different. In general, the trained model can control the supply–demand error within 10%. For the model with the best indoor temperature control performance, the supply–demand error is only 4.56%. In addition, it can be found from
Figure 13 that the indoor heat demand changes periodically. With the upgrade of the training target, the fitting of the heat supply and the heat demand curve is significantly improved. Based on the primary target, although the heat supply is consistent with the heat demand in the changing trend, the peaks and valleys cannot be well fitted. Under this condition, the indoor temperature can be maintained in the acceptable interval based on the thermal storage of building envelopes. However, the indoor temperature will still be very high during the low heat demand at noon every day. When the intermediate target is achieved in training, the previous problem can be significantly alleviated as the prediction accuracy is sharply improved. When training with the advanced target, with the introduction of the retraining method, the fitting of heat demand and heat supply is further improved, and the problem of additional heat demand caused by the preheating of building envelopes in the early stage can be solved.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}