
Shape Carving Methods of Geologic Body Interpretation from Seismic Data Based on Deep Learning

Abstract
:1. Introduction
2. Materials and Methods
2.1. Datasets
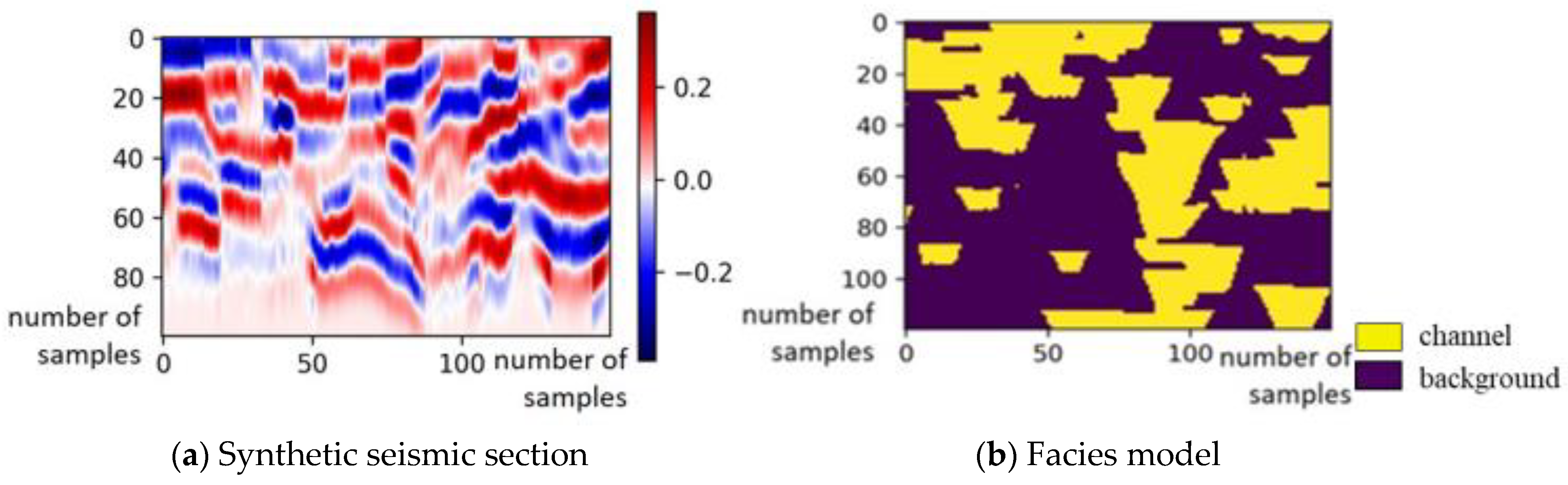
2.1.1. The Synthetic Dataset
2.1.2. The F3 Dataset
2.1.3. The RIPED Dataset
2.2. Architectures
2.2.1. Fully Convolutional 2D Network with Dilated Convolutional Layers
2.2.2. The 3D Convolutional Network
2.2.3. The U-Net Architecture
2.3. Investigating the Validation–Test Accuracy Gap
3. Results and Discussion
3.1. Experiments with the Fully Convolutional 2D Network with Dilated Convolutional Layers
3.2. Experiments with the 3D Convolutional Network
3.3. Experiments with the U-Net Architecture
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Thadani, S.G. Reservoir Characterization with Seismic Data Using Pattern Recognition and Spatial Statistics. In Geostatistics Tróia’92; Soares, A., Ed.; Springer: Dordrecht, The Netherlands, 1993; pp. 519–542. [Google Scholar]
- Wong, P.M.; Jian, F.X.; Taggart, I.J.A. critical comparison of neural networks and discriminant analysis in lithofacies, porosity and permeability predictions. J. Pet. Geol. 1995, 18, 191–206. [Google Scholar] [CrossRef]
- Caers, J.; Ma, X. Modeling Conditional Distributions of Facies from Seismic Using Neural Nets. Math. Geol. 2002, 34, 143–167. [Google Scholar] [CrossRef]
- de Matos, M.C.; Osorio, P.L.; Johann, P.R. Unsupervised seismic facies analysis using wavelet transform and self-organizing maps. Geophysics 2007, 72, P9–P21. [Google Scholar] [CrossRef]
- Chopra, S.; Marfurt, K.J. Seismic facies classification using some unsupervised machine-learning methods. In Proceedings of the SEG International Exposition and Annual Meeting, Anaheim, CA, USA, 14–19 October 2018. [Google Scholar]
- Lubo-Robles, D.; Marfurt, K. Independent component analysis for reservoir geomorphology and unsupervised seismic facies classification in the Taranaki Basin, New Zealand. Interpretation 2019, 7, SE19–SE42. [Google Scholar] [CrossRef]
- Bagheri, M.; Riahi, M.A. Support Vector Machine-based Facies Classification Using Seismic Attributes in an Oil Field of Iran. Iran. J. Oil Gas Sci. Technol. 2013, 2, 1–10. [Google Scholar]
- Li, Y.; Anderson-Sprecher, R. Facies identification from well logs: A comparison of discriminant analysis and naïve Bayes classifier. J. Pet. Sci. Eng. 2006, 53, 149–157. [Google Scholar] [CrossRef]
- Wrona, T.; Pan, I.; Gawthorpe, R.L.; Fossen, H. Seismic facies analysis using machine learning. Geophysics 2018, 83, O83–O95. [Google Scholar] [CrossRef]
- Zhao, T.; Jayaram, V.; Roy, A.; Marfurt, K.J. A comparison of classification techniques for seismic facies recognition. Interpretation 2015, 3, SAE29–SAE58. [Google Scholar] [CrossRef]
- Grana, D.; Azevedo, L.; Liu, M. A comparison of deep machine learning and Monte Carlo methods for facies classification from seismic data. Geophysics 2020, 85, WA41–WA52. [Google Scholar] [CrossRef]
- Waldeland, A.U.; Solberg, A.H.S.S. Salt Classification Using Deep Learning. In Proceedings of the 79th EAGE Conference and Exhibition, Paris, France, 12–15 June 2017; pp. 1–5. [Google Scholar]
- Dramsch, J.S.; Lüthje, M. Deep-learning seismic facies on state-of-the-art CNN architectures. In Proceedings of the SEG International Exposition and 88th Annual Meeting, Anaheim, CA, USA, 14–19 October 2018. [Google Scholar]
- Puzyrev, V.; Elders, C. Unsupervised seismic facies classification using deep convolutional autoencoder. In Proceedings of the EAGE/AAPG Digital Subsurface for Asia Pacific Conference, Kuala Lumpur, Malaysia, 7–10 September 2020; pp. 1–3. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 39, 640–651. [Google Scholar]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. In Proceedings of the International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the MICCAI, Berlin, Heidelberg, 5 October 2015; pp. 234–241. [Google Scholar]
- Castro, S.A.; Caers, J.; Mukerji, T. The Stanford VI Reservoir; 18th Annual Report; Stanford Center for Reservoir Forecasting, Stanford University: Stanford, CA, USA, 2005. [Google Scholar]
- Project F3 Demo. Available online: https://terranubis.com/datainfo/F3-Demo-2020 (accessed on 14 June 2021).
- Kruskal, J.B.; Wish, M. Multidimensional Scaling; Sage University Paper Series on Quantitative Application in the Social Sciences; Sage Publications: Newbury Park, CA, USA, 1978; pp. 7–11. [Google Scholar]
- Pradhan, A.; Mukerji, T. Seismic Inversion for Reservoir Facies under Geologically Realistic Prior Uncertainty with 3D Convolutional Neural Networks; SEG Technical Program Expanded Abstracts; Society of Exploration Geophysicists: Houston, TX, USA, 2020; pp. 1516–1520. [Google Scholar]
- Chu, W.; Yang, I. CNN-Based Seismic Facies Classification from 3D Seismic Data. Available online: https://cs230.stanford.edu/projects_spring_2018/reports/8291004.pdf (accessed on 14 June 2021).
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2016, arXiv:1511.07122. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the ICML, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- MalenoV (MAchine LEarNing of Voxels). Available online: https://github.com/bolgebrygg/MalenoV (accessed on 14 June 2021).
- Tensorflow U-Net. Available online: https://github.com/jakeret/unet (accessed on 14 June 2021).
- Zeiler, M.D.; Krishnan, D.; Taylor, G.W.; Fergus, R. Deconvolutional networks. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2528–2535. [Google Scholar]
- Metropolis, N. The Beginning of the Monte Carlo Method. Los Alamos Sci. Spec. Issue 1987, 15, 125–130. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Mahalanobis, P.C. On the Generalised Distance in Statistics. Proc. Natl. Inst. Sci. India 1936, 2, 49–55. [Google Scholar]
- Park, J.; Yang, G.; Satija, A.; Scheidt, C.; Caers, J. DGSA: A Matlab toolbox for distance-based generalized sensitivity analysis of geoscientific computer experiments. Comput. Geosci. 2016, 97, 15–29. [Google Scholar] [CrossRef]
- Uhrig, J.; Schneide, N.; Schneider, L.; Franke, U.; Brox, T.; Geiger, A. Sparsity Invariant CNNs. In Proceedings of the IEEE International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017. [Google Scholar]



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Values |
|---|---|
| number of convolutional layers | 2, 3, 4, 5 |
| number of dilated convolutional layers | 2, 3, 4, 5 |
| kernel size | 3, 5, 7 |
| number of filters | 16, 32 |
| learning rate | 0.0005, 0.001 |
| training example size | 16, 32, 64 |
| training example overlap | 30, 50, 70, 80 |
| batch size | 4, 8, 15 |
| max pooling | True, False |
| telescopic architecture | True, False |
| Parameter | Values |
|---|---|
| learning rate | 1 × 10−4, 1 × 10−5, 5 × 10−6 |
| network depth (the number of convolutional blocks in both top-down and bottom-up pathways) | 3, 5, 6 |
| number of filters in the first convolutional block | 16, 32, 64 |
| training example size | 64, 128, 256 |
| training example size overlap (in percent, horizontal and vertical) | 30, 50, 70 |
| number of epochs | 150, 250 |
| Baseline | 0.1 mix | 0.2 mix | 0.3 mix | |
|---|---|---|---|---|
| accuracy (best case) | 0.847 | 0.886 | 0.909 | 0.938 |
| mean | 0.823 | 0.837 | 0.886 | 0.931 |
| std | 0.021 | 0.026 | 0.012 | 0.006 |
| Baseline | 0.1 mix | 0.2 mix | 0.3 mix | |
|---|---|---|---|---|
| accuracy (best case) | 0.858 | 0.845 | 0.918 | 0.946 |
| mean | 0.801 | 0.806 | 0.876 | 0.934 |
| std | 0.033 | 0.037 | 0.036 | 0.010 |
| Dilated FCN | 3D Conv | U-Net | |
|---|---|---|---|
| synthetic | 0.92 | 0.74 | 0.91 |
| F3 | 0.83 | 0.81 | 0.82 |
| RIPED (slices) | 0.8 | 0.8 | 0.85 |
| Dilated FCN | 3D Conv | U-Net | |
|---|---|---|---|
| training time | 729 s (40 ep) | 115 s (2 ep) | 883.6 s (250 ep) |
| prediction time (one section) | 0.74 s | 13 s | 0.15 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Petrov, S.; Mukerji, T.; Zhang, X.; Yan, X. Shape Carving Methods of Geologic Body Interpretation from Seismic Data Based on Deep Learning. Energies 2022, 15, 1064. https://doi.org/10.3390/en15031064
Petrov S, Mukerji T, Zhang X, Yan X. Shape Carving Methods of Geologic Body Interpretation from Seismic Data Based on Deep Learning. Energies. 2022; 15(3):1064. https://doi.org/10.3390/en15031064
Chicago/Turabian StylePetrov, Sergei, Tapan Mukerji, Xin Zhang, and Xinfei Yan. 2022. "Shape Carving Methods of Geologic Body Interpretation from Seismic Data Based on Deep Learning" Energies 15, no. 3: 1064. https://doi.org/10.3390/en15031064