
A Novel Feature Identification Method of Pipeline In-Line Inspected Bending Strain Based on Optimized Deep Belief Network Model


Abstract
:1. Introduction
- (1)
- The identification efficiency by using the algorithm assisted with manual discrimination was low. Generally, after excluding the bend and dent data that were recorded by the geometric inspection and magnetic flux leakage detection, still, more than 1000 pipe sections whose bending strain value exceeds 0.125% can be detected, as was verified by the algorithm in the IMU inspection data for one trip of more than 200 km. It is interesting to notice that the pipe sections with large strain generally include those with bending strain, geometrically deformed dent, suspected bend, and girth weld anomaly, which have to be identified manually, so the identification efficiency is low.
- (2)
- Manual identification still possesses the problems of low accuracy and fuzzy boundaries. Among the pipe sections where large strain is identified by the algorithm, pipe sections with bends and dents are also suspected. The strain load of these pipe sections exceeds the value of 0.125%, but the features are similar to those of sections with bends or dents.
- (3)
- Data noise interferes with the features of the pipe section. Additionally, in the raw IMU strain data, jagged noises that fluctuate up and down owing to spiral welds and other reasons can be observed. During the process of the manual identification, some pipeline sections exhibit strain values greater than 0.125% only at a few points, but they are classified as bending strain sections. These points with large strain values may be caused by noise fluctuations, whereas it is not necessary to identify these sections when the noise is eliminated.
2. Pipeline Bending Strain In-Line Inspection System and Bending Strain Calculation
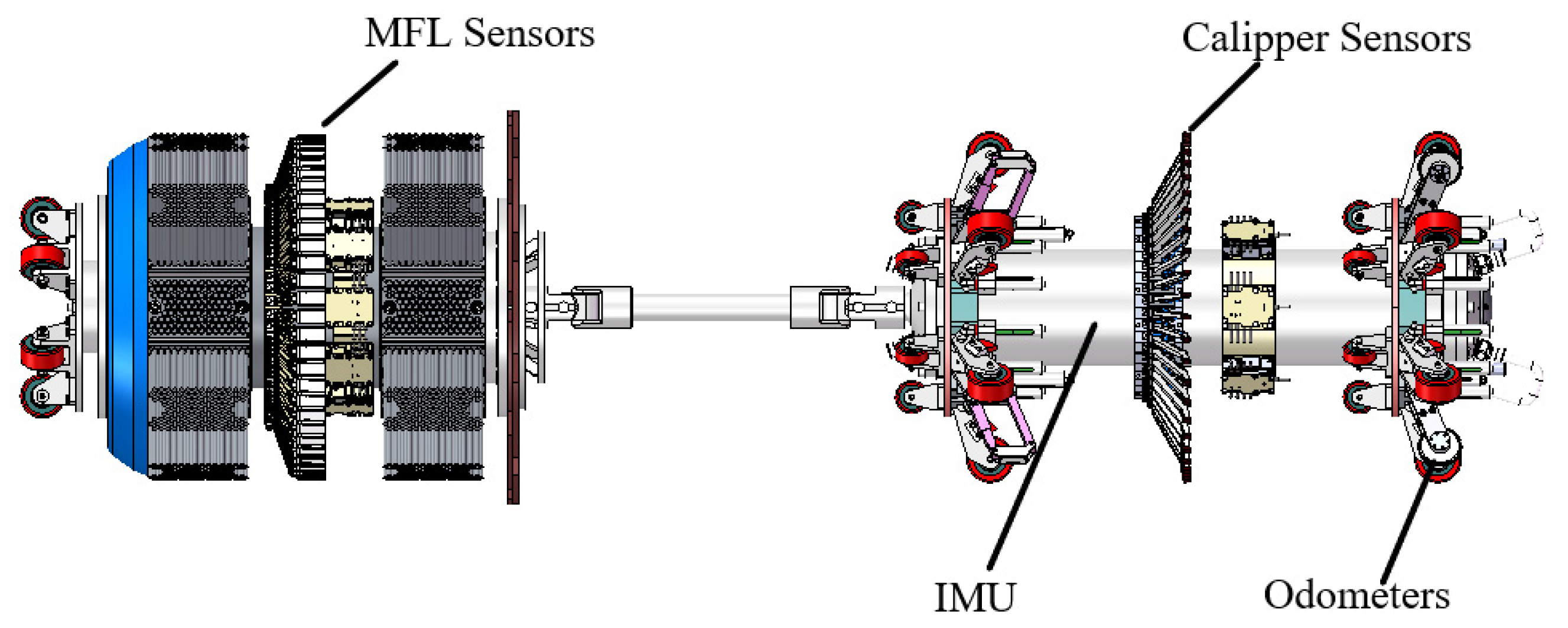
2.1. Composition of the Pipeline Bending Strain In-Line Inspection System
2.2. Calculation Method of the Pipeline Bending Strain
2.3. Denoising of the Bending Strain Data
2.4. Pipeline Features Based on Bending Strain
- (1)
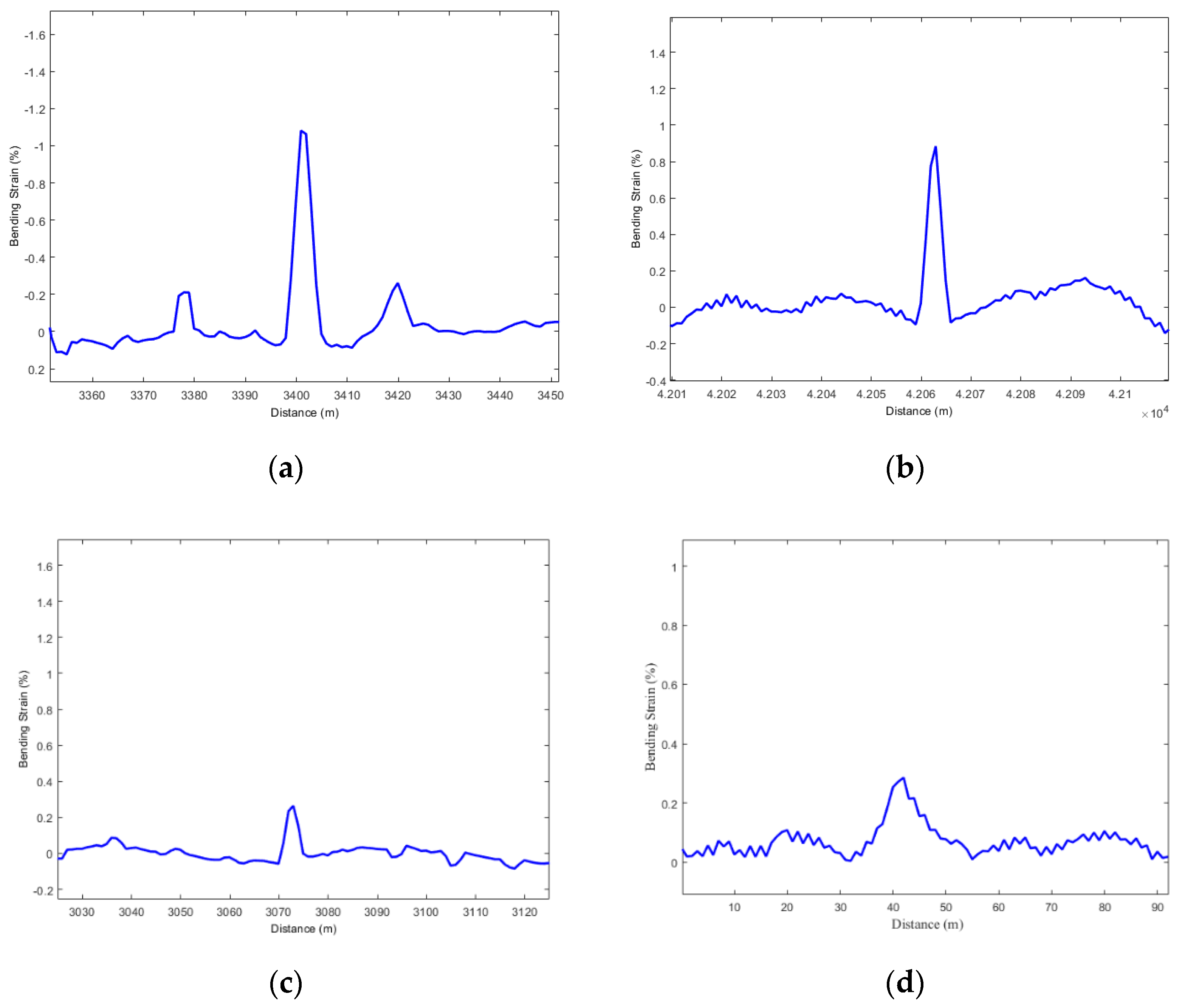
- Dent: Figure 3a illustrates the strain signal of the pipeline dent. As a common defect form of pipelines, it seriously threatens the safe operation of the pipelines and even leads to pipe failure. We have to underline that the pipe dent effect refers to the local elastic-plastic deformation where an obvious change in the pipe surface curvature is caused by an external impact or extrusion. On top of that, during the construction and operation of the pipeline, owing to the extrusion of hard and big objects such as rocks and the collision of excavating equipment and falling rocks, both the bottom and top of the pipeline may be dented.
- (2)
- Bend: Figure 3b divulges the strain signal of the pipe bend. Since pipelines are the main equipment for transporting fluid medium in the petroleum industry, bends must be used to adjust the transmission direction of the pipeline or connect two pipes whose central axis is not aligned due to the limitation of space or design route. The commonly used bends are 45°, 90°, and 180°, and bends of 60°, and other unconventional angles are also used according to the engineering needs.
- (3)
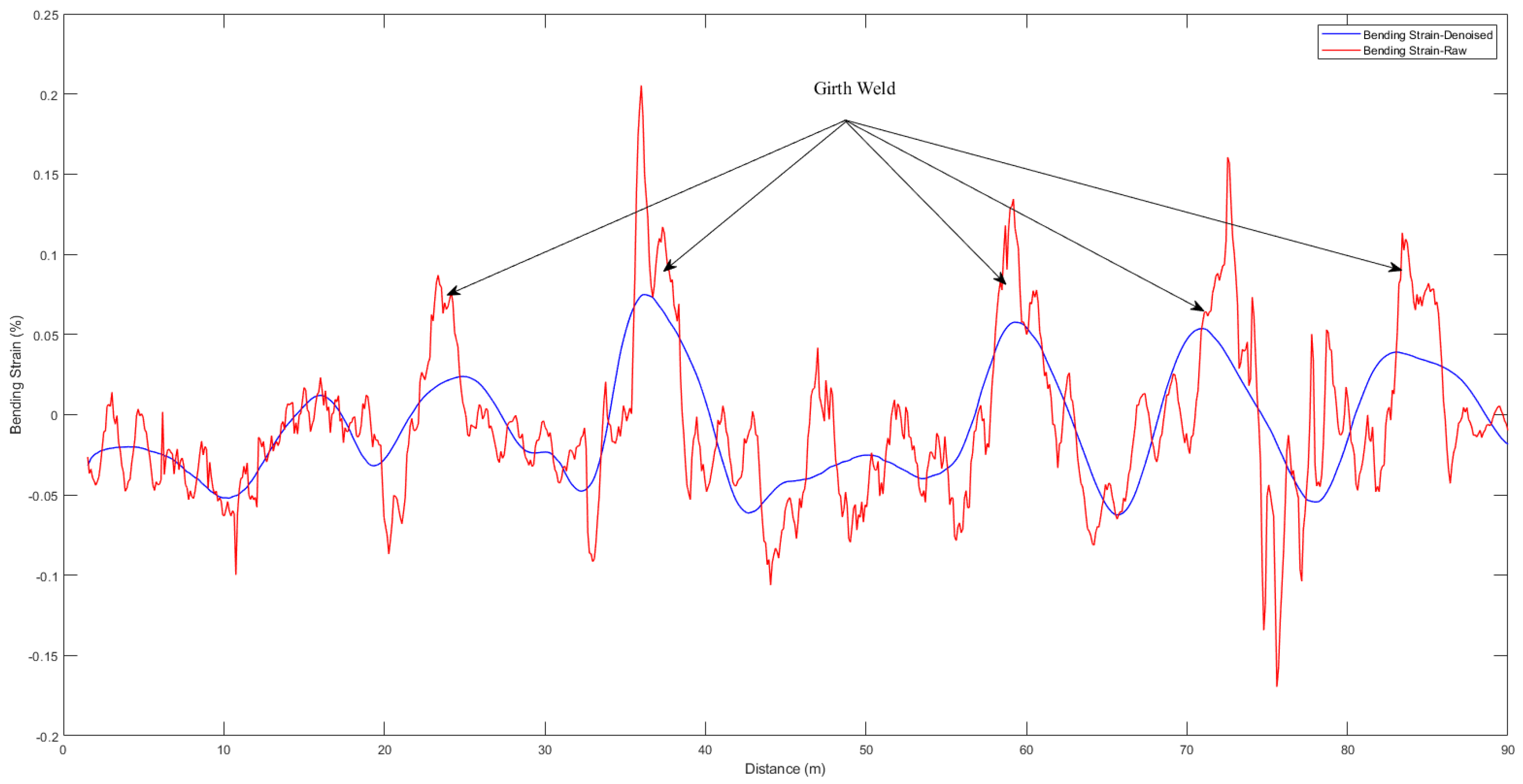
- The girth weld anomaly of the pipeline: Figure 3c reveals the strain signal of the girth weld anomaly of the pipeline. Moreover, long-distance oil and gas pipelines are generally made of a large number of factory-manufactured straight pipes that are connected with accessories (bends, tees, valves, etc.). Since the welded joints are not only firm and durable, but also have high joint mechanical strength and tightness, they are the most commonly used for the fabrication of important pipeline connection modes in pipeline construction projects. It is interesting to notice that when the in-line tool runs in the pipeline, due to the abnormality of some girth welds (miter joint, excessive reinforcement, staggered edge, etc.), the in-line tool is subjected to a large impact and vibration loads at the girth weld anomalies, so the information of these girth welds also needs to be distinguished.
- (4)
- The bending deformation section: Figure 3d reveals the strain signal of the bending deformation of the pipeline. Due to the nature of the employed long-distance oil and gas pipelines, they often pass through areas with unstable geological conditions or natural disasters, such as earthquake areas and frozen soil areas. As a result, in these areas, large lateral displacement and deformation on the pipeline is easier to be imposed, and in severe cases, a large bending strain will be generated locally. Therefore, these bending deformation features need to be effectively identified by using an in-line IMU inspection method.
3. Feature Identification Method for the In-Line Inspected Pipeline Bending Strain Based on Optimized DBN Model
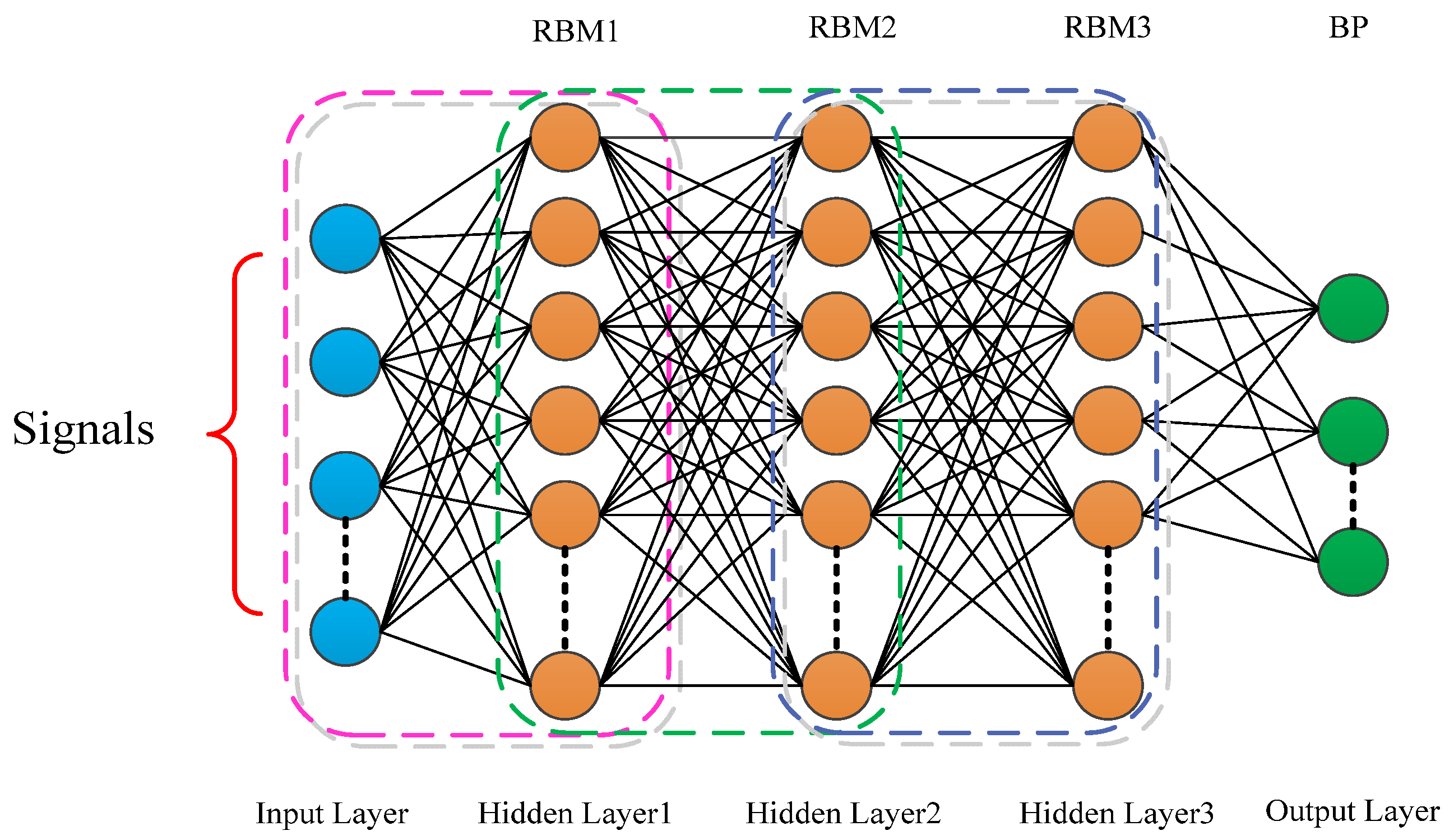
3.1. DBN Theory
- (1)
- Pre-training
- (2)
- Fine-tuning
3.2. Peak Hold Down Sampling (PHDS) Algorithm
3.3. Particle Swarm Optimization Algorithm (PSO)
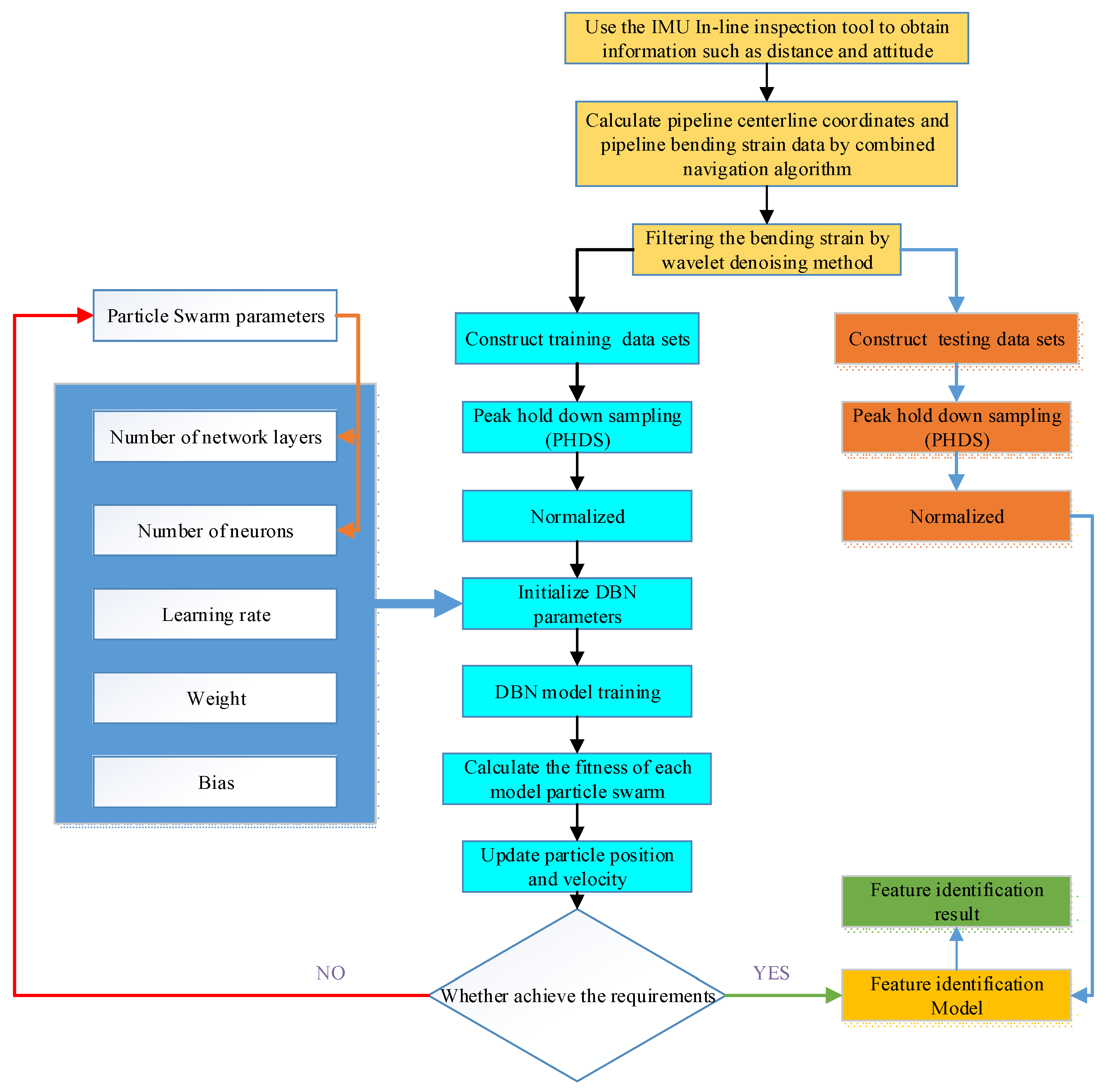
3.4. Pipeline Bending Strain Feature Identification Method Based on Improved DBN with Particle Swarm Optimization
- (1)
- The data sample set was constructed with the de-noised signals obtained through the calculation of the pipeline bending strain, including both the training data sample set and the test sample set. The PHDS method was also used to compress the data samples. To ensure that the state information of the compressed sample data is not seriously affected, the downsampling rate is generally 2–4.
- (2)
- The compressed data samples were normalized through the range method , to obtain the ratio of the result of a segment of signal data minus the minimum value to the result of the maximal value minus the minimum value.
- (3)
- Consequently, the weight of the DBN is set, and the bias parameter is initialized immediately. Additionally, the loss function is the mean square error, the activation function is the sigmoid function, the learning rate is set to 0.1, the number of iterations is set to 50, the number of the network layers is an integer between 1 and 4, and the number of neurons in each layer of the network is initialized immediately.
- (4)
- The training sample set is loaded, then the PSO algorithm is used, and the test accuracy of the test data model is taken as the objective function to search the number of the network layers while the number of neurons in each layer of the model with the highest test accuracy of the test data.
- (5)
- According to the number of the network layers and the number of neurons in each layer, the optimal DBN model is constructed for the studied object, and the feature classification process based on bending strain is realized by using the DBN model.
4. Field Experimental Investigation
4.1. Data Preparation for Field Experiment
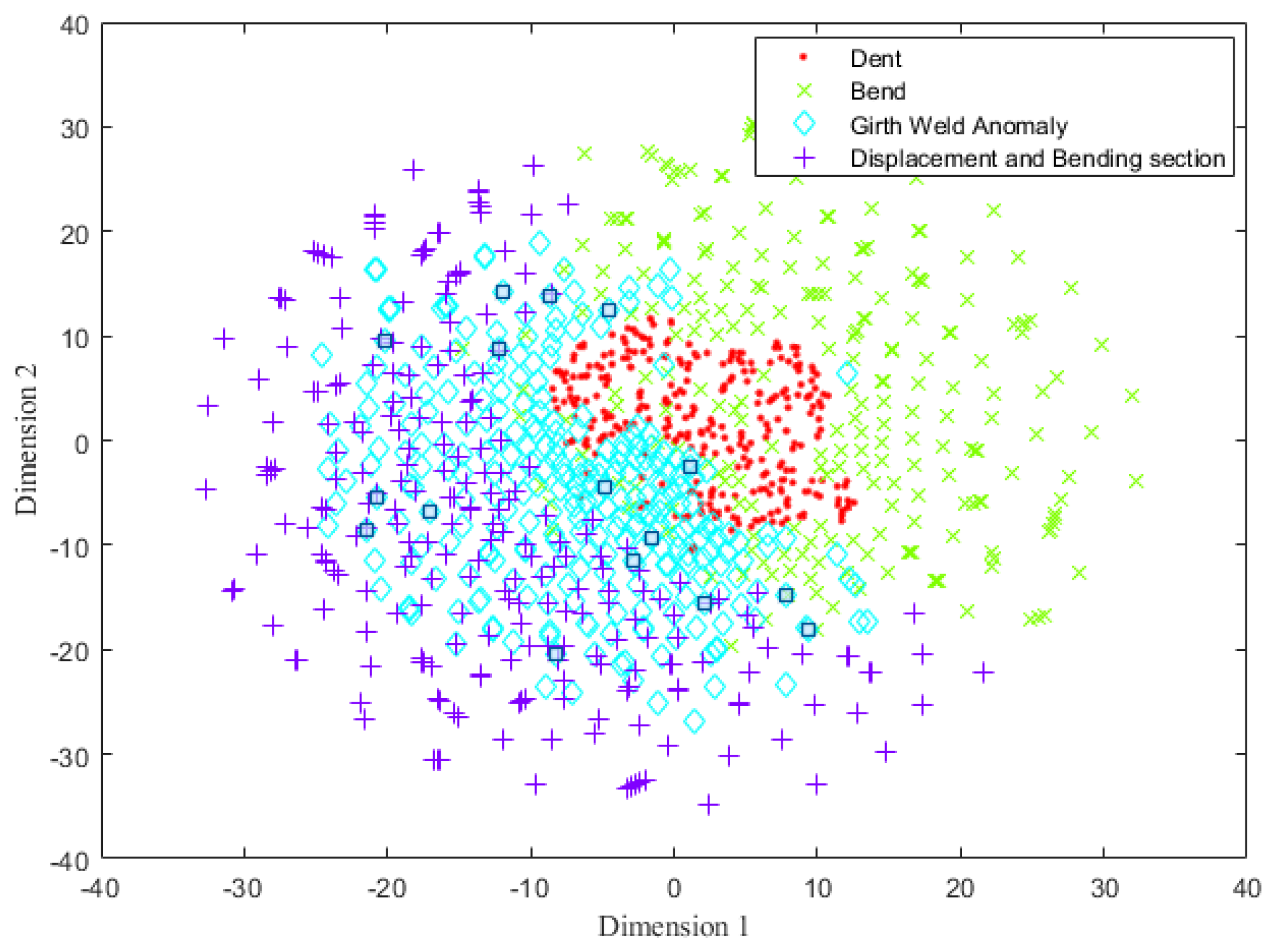
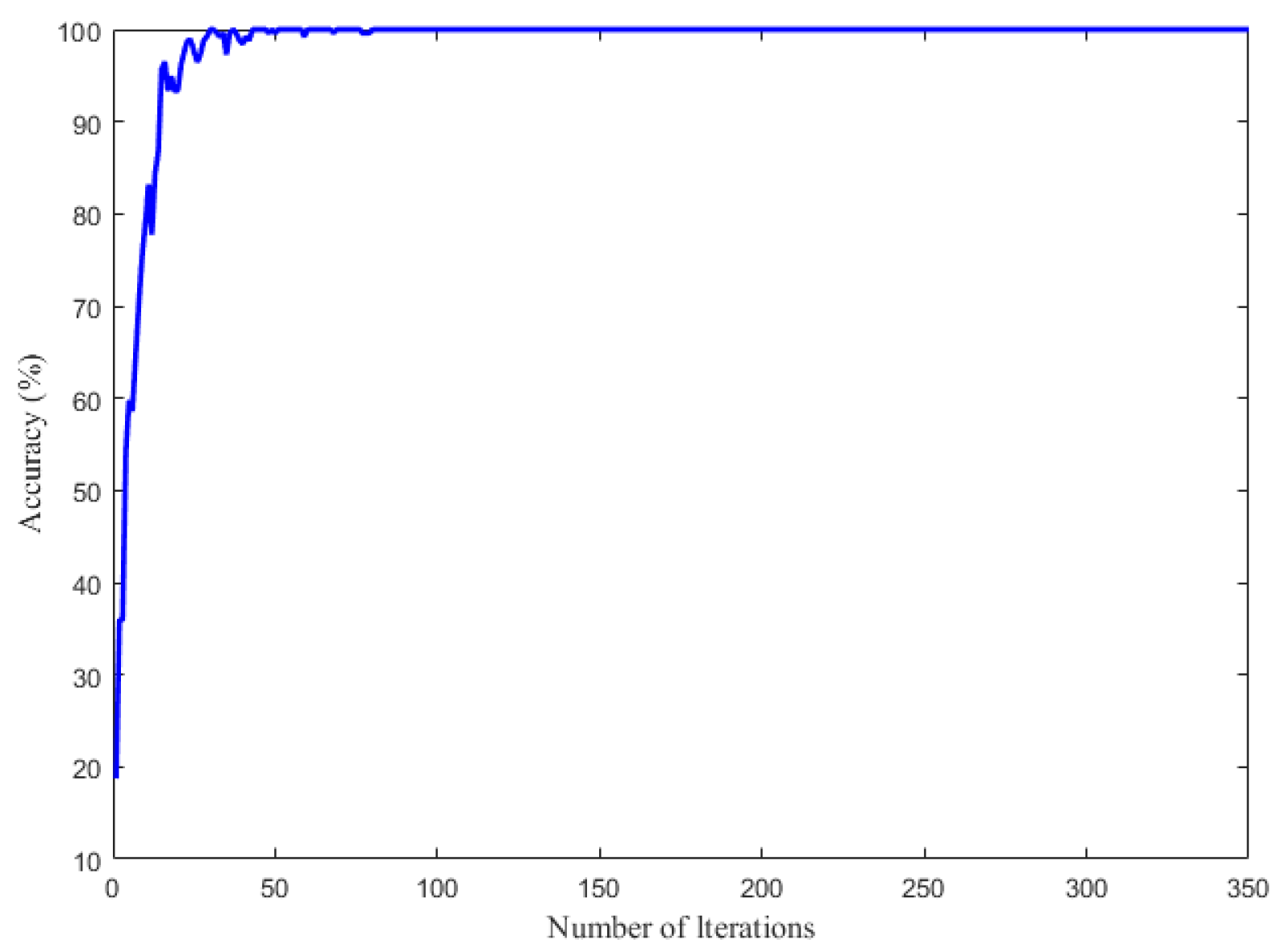
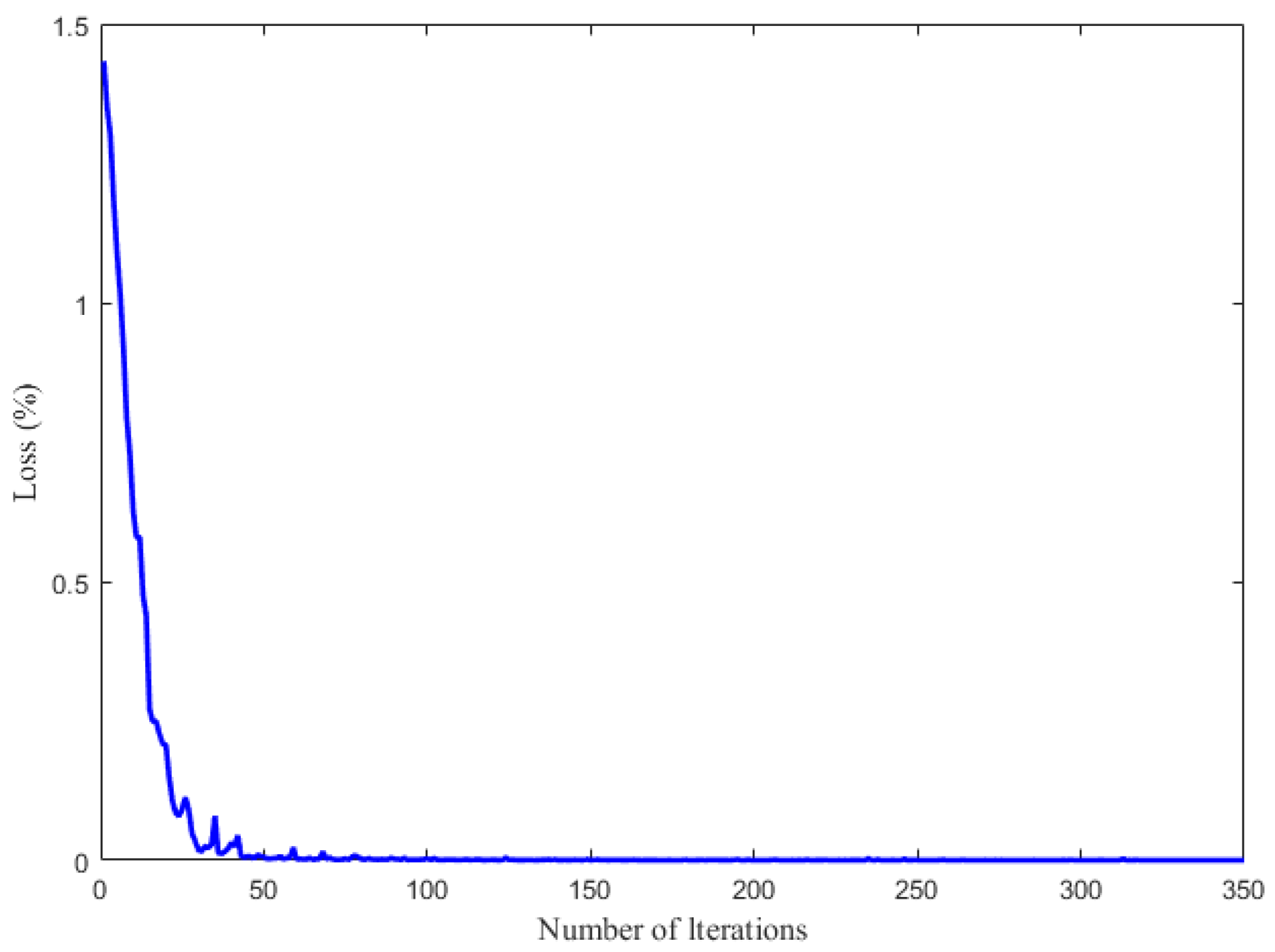
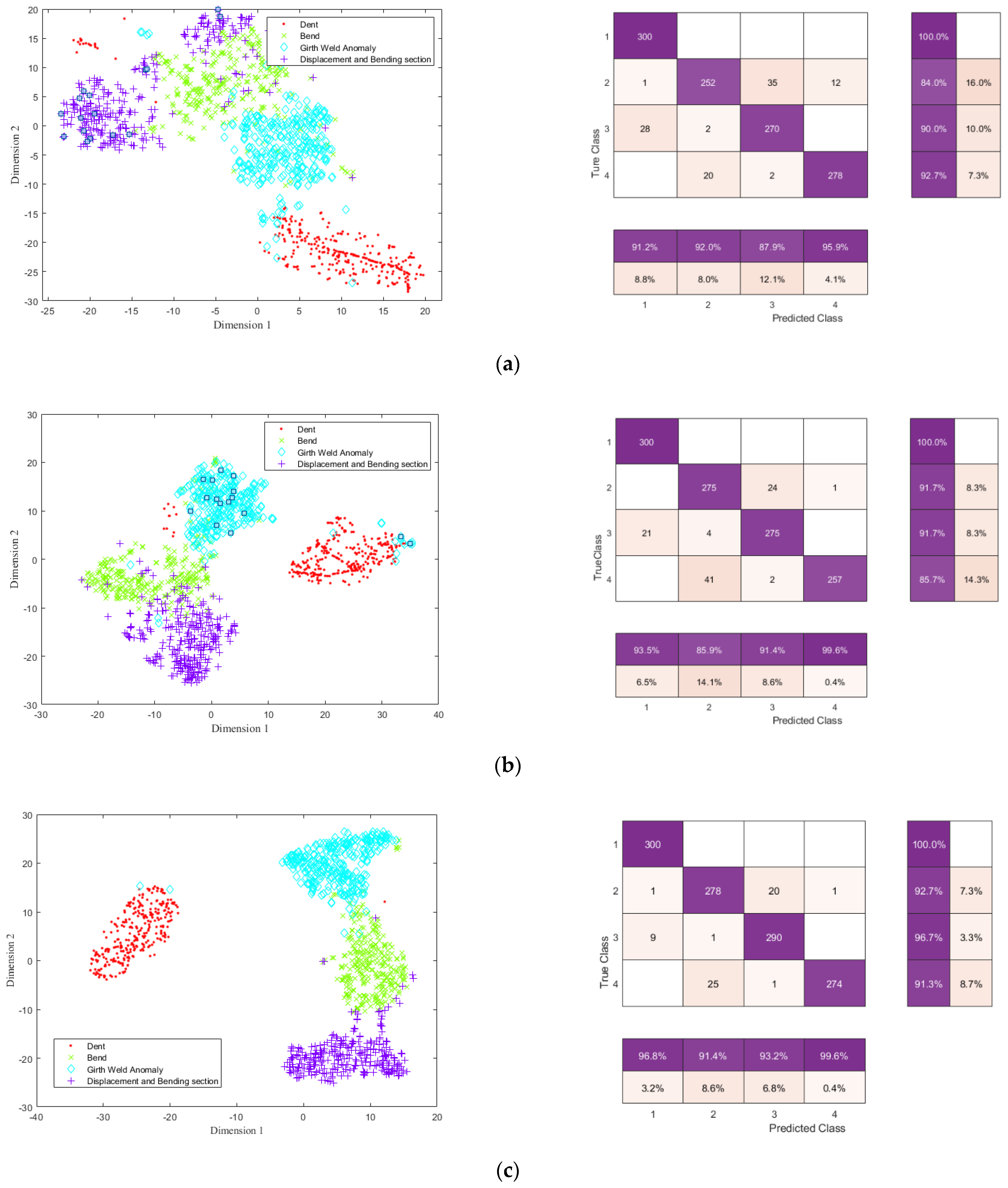
4.2. Pipeline Feature Classification Based on the Improved DBN
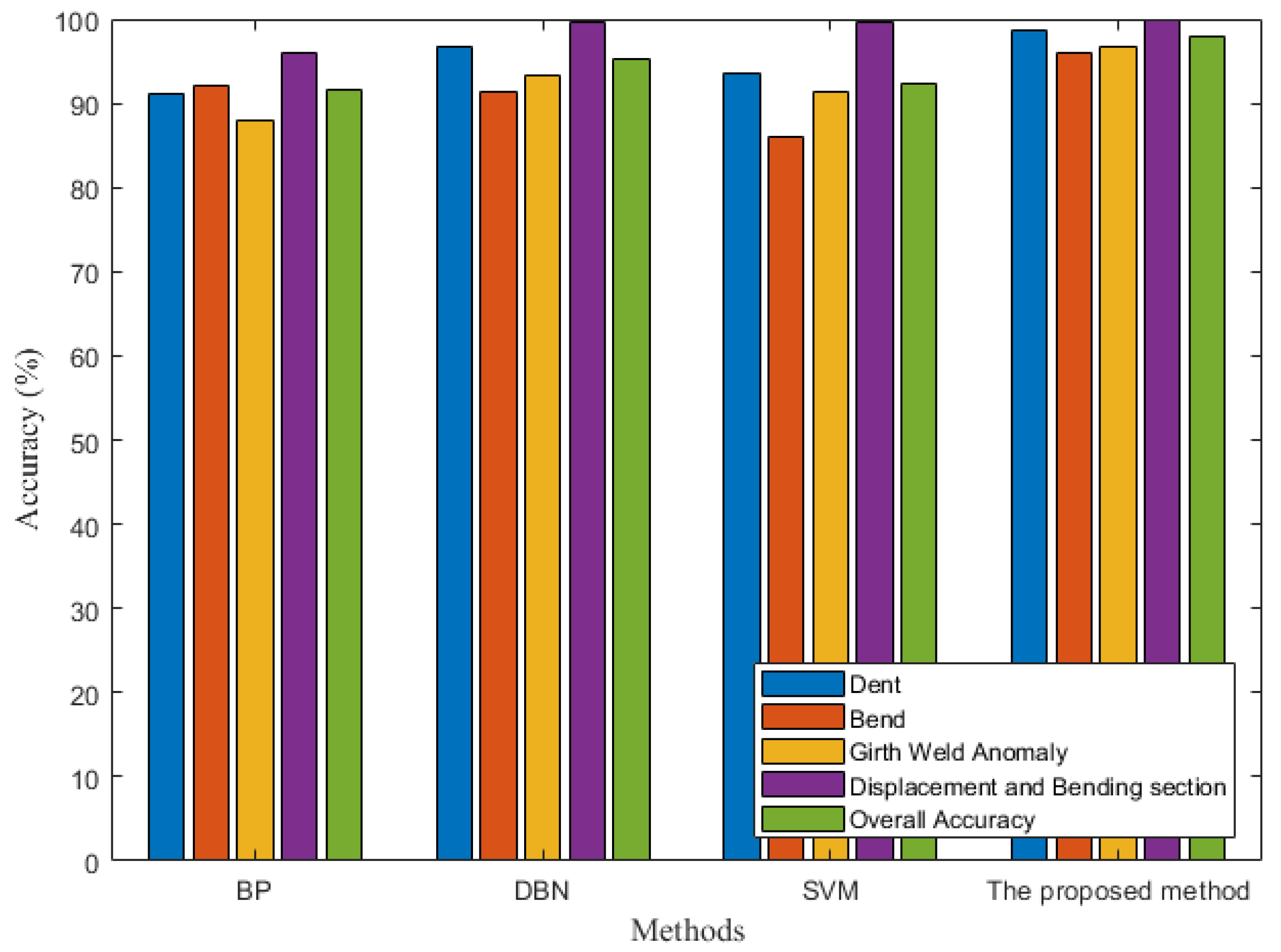
4.3. Comparisons with Other Methods
- (1)
- BP neural network: the BP neural network is practically a multi-layer feedforward neural network, which is characterized by the signal forward transmission and error back propagation. During the forward propagation process, the input signal is processed from the input layer to the output layer through the hidden layer. The neuron state of each layer affects only the neuron state of the next layer. Consequently, if the output layer cannot obtain the expected output, it will turn back propagation and adjust the network’s weight and threshold according to the prediction error to continuously approach the expected output of the BP neural network.
- (2)
- Support vector machine (SVM): a support vector machine (SVM) method is proposed based on statistical learning theory. It is widely used in both pattern recognition and classification approaches due to its faster training convergence rate, stronger generalization ability than neural networks, and the ability to solve small sample learning problems.
- (3)
- DBN: the DBN is adopted for comparison with the proposed method.
5. Conclusions
- (1)
- The wavelet denoising method can effectively remove the interference and noise of the bending strain data in pipeline detection, which lays a foundation for pipeline feature identification.
- (2)
- The PHDS method was used to compress the sample data, which can improve the identification speed to ensure elevated identification accuracy.
- (3)
- The PSO algorithm was adopted to optimize the parameters of the DBN model, which improves the training efficiency of the network model, realizes the global optimization of model parameters, and obtains a high test accuracy. The acquired application results show that the accuracy of pipeline feature identification based on the bending strain can reach the value of 97.83%, and the identification efficiency can reach 0.02 min/km.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- DONG, S.H. Review of China’s oil and gas pipeline integrity management in the past 20 years and development suggestions. Oil Gas Storage Transp. 2020, 39, 241–261. [Google Scholar]
- Wang, J.; He, R.; Liu, Z.; Hao, G. Development status of oil & gas pipeline integrity management standards in China and the USA and their differences. Oil Gas Storage Transp. 2017, 36, 1–10. [Google Scholar]
- Taylor, P.; Wielki, J.; Shea, T. Incorporating Environmental Considerations into Pipeline Integrity Management Programs. In International Pipeline Conference; American Society of Mechanical Engineers: Calgary, AB, Canada, 2012; pp. 307–316. [Google Scholar]
- Tejedor, J.; Martins, H.F.; Piote, D.; Macias-Guarasa, J.; Pastor-Graells, J.; Martin-Lopez, S.; Guillen, P.C.; De Smet, F.; Postvoll, W.; Gonzalez-Herraez, M. Toward Prevention of Pipeline Integrity Threats Using a Smart Fiber-Optic Surveillance System. J. Lightwave Technol. 2016, 34, 4445–4453. [Google Scholar] [CrossRef] [Green Version]
- Feng, Q.; Li, R.; Nie, B.; Liu, S.; Zhao, L.; Zhang, H. Literature Review: Theory and Application of In-Line Inspection Technologies for Oil and Gas Pipeline Girth Weld Defection. Sensors 2017, 17, 50. [Google Scholar] [CrossRef]
- Hussein, S.; Naser, E.S. A Novel Method to Enhance Pipeline Trajectory Determination Using Pipeline Junctions. Sensors 2016, 16, 567. [Google Scholar]
- Liu, S.; Zheng, D.; Li, R. Compensation Method for Pipeline Centerline Measurement of in-Line Inspection during Odometer Slips Based on Multi-Sensor Fusion and LSTM Network. Sensors 2019, 19, 3740. [Google Scholar] [CrossRef] [Green Version]
- Li, R.; Cai, M.; Shi, Y.; Feng, Q.; Chen, P. Technologies and application of pipeline centerline and bending strain of In-line inspection based on inertial navigation. Trans. Inst. Meas. Control 2018, 40, 1554–1567. [Google Scholar] [CrossRef]
- Li, R.; Wang, Z.; Chen, P. Development the method of pipeline bending strain measurement based on microelectro mechanical systems inertial measurement unit. Sci. Prog. 2020, 103, 0036850420925231. [Google Scholar] [CrossRef]
- James, D.; Hart, J.; Czyz, A.; Zulfiqar, N. REVIEW OF PIPELINE INERTIAL SURVEYING FOR GROUND MOVEMENT-INDUCED DEFORMATIONS. In Proceedings of the Conference on Asset Integrity Management-Pipeline Integrity Management Under Geohazard Conditions, AIM-PIMG 2019, Houston, TX, USA, 25–28 March 2019. [Google Scholar]
- Murray, I. Pipeline Bending Strain Assessment using ILI Tools: Case Studies. In Proceedings of the Pipeline Technology Conference, Berlin, Germany, 8–10 June 2015. [Google Scholar]
- Zhao, X.; Li, R.; Chen, P.C.; Feng, W.; Fu, K.; Zheng, J. Identification and evaluation on bending deformation of China-Russia Eastern Gas Pipeline. Oil Gas Storage Transp. 2020, 39, 763–768. [Google Scholar]
- Zhang, P.; Hancock, C.M.; Lau, L.; Roberts, G.W.; de Ligt, H. Low-cost IMU and odometer tightly coupled integration with Robust Kalman filter for underground 3-D pipeline mapping. Measurement 2019, 137, 454–463. [Google Scholar] [CrossRef]
- Liu, S.; Zheng, D.; Dai, M.; Chen, P. A Compensation Method for Spiral Error of Pipeline Bending Strain In-Line Inspection. J. Test. Eval. 2018, 47, 20180110. [Google Scholar] [CrossRef]
- Feng, Y.X.; Deng, H.G.; Cheng, Y. Weld surface defect detection method based on convolution neural network. Comput. Meas. Control 2021, 29, 56–60, 66. [Google Scholar]
- Zhao, H.X.; Zhang, M.; Guo, B.Y.; Wang, D.G.; He, R.Y. Recognition method of pipeline metal loss defects based on machine learning. China Pet. Mach. 2020, 48, 138–145. [Google Scholar] [CrossRef]
- Wang, X.Y.; Song, X.S.; Yang, T.W. Application of Depth Learning Neural Network in Pipeline Fault Diagnosis. Saf. Environ. Eng. 2018, 1, 137–142. [Google Scholar]
- Sun, Z.G.; Zhao, Y.; Liu, C.S.; Yu, Z.N.; Zhang, S.X.; Lan, M.Y.; Liu, J.J.; Wang, Y.Y. Research on Inner Wall Defect Detection Method of Metal Welded Pipe Based on Deep Learning. Welded Pipe Tube 2020, 43, 1–7. [Google Scholar] [CrossRef]
- Chen, Q.; Niu, X.; Kuang, J.; Liu, J. IMU Mounting Angle Calibration for Pipeline Surveying Apparatus. IEEE Trans. Instrum. Meas. 2019, 69, 1765–1774. [Google Scholar] [CrossRef]
- Chowdhury, M.S.; Abdel-Hafez, M.F. Pipeline Inspection Gauge Position Estimation Using Inertial Measurement Unit, Odometer, and a Set of Reference Stations. ASCE-ASME J. Risk Uncertain. Eng. Syst. Part B Mech. Eng. 2016, 2, 21001. [Google Scholar] [CrossRef]
- Niu, X.; Kuang, J.; Chen, Q. Study on the Posibility of the PIG Positioning Using MEMS-based IMU. Chin. J. Sens. Actuators 2016, 29, 40–44. [Google Scholar]
- Slaughter, M.; Huss, M.; Zakharov, Y.; Vassiljev, A. A Pipeline Inspection Case Study: Design Improvements on a New Generation UT In-line Inspection Crack Tool. Pipeline Gas J. 2012, 239, 118. [Google Scholar]
- Ying, D.U.; Tian-Jian, L.I.; Wang, H.X. Research of pipeline trajectory detection algorithm based on strapdown inertial navigation technology. J. Beijing Inf. Sci. Technol. Univ. 2014, 29, 6. [Google Scholar]
- Czyz, J.A.; Adams, J.R. Computations of pipeline-bending strains based on geopig measurements. In Proceedings of the Pipeline Pigging and Integrity Monitoring Conference, Houston, TX, USA, 14–17 February 1994. [Google Scholar]
- Wendel, S.; Kirkvik, R.H.; Clouston, S.; Czyz, J. Pipeline out of straightness and depth of burial measurement using an Inertial geometry intelligent Pig. In Proceedings of the 23rd Annual Offshore Pipeline Technology Conference (OPT 2000), Oslo, Norway, 18 February 2000; pp. 124–129. [Google Scholar]
- Taler, J.; Dzierwa, P.; Taler, D.; Jaremkiewicz, M.; Trojan, M. Monitoring of Thermal Stresses and Heating Optimization Including Industrial Applications; Nova Science Publishers: New York, NY, USA, 2016. [Google Scholar]
- Taler, J.; Taler, D. Surface-heat transfer measurements using transient techniques. In Encyclopedia of Thermal Stresses; Hetnarski, R., Ed.; Springer: Dordrecht, The Netherlands, 2014; pp. 4774–4784. [Google Scholar]
- Wodecki, J.; Michalak, A.; Stefaniak, P. Review of smoothing methods for enhancement of noisy data from heavy-duty LHD mining machines. E3S Web Conf. 2018, 29, 11. [Google Scholar] [CrossRef] [Green Version]
- Horgan, G.H. Using wavelets for data smoothing: A simulation study. J. Appl. Stat. 1999, 26, 923–932. [Google Scholar] [CrossRef]
- Li, R.; Cai, M.; Shi, Y.; Feng, Q.; Liu, S.; Zhao, X. Pipeline bending Strain Measurement and Compensation Technology Based on Wavelet Neural Network. J. Sens. 2016, 33, 1–7. [Google Scholar] [CrossRef] [Green Version]
- Zhao, B.; Wu, C.J. Sound quality evaluation of electronic expansion valve using Gaussian restricted Boltzmann machines based DBN. Appl. Acoust. 2020, 170, 107493. [Google Scholar] [CrossRef]
- Liu, M.; Ma, J.; Duo, Y.; Sun, T. Reliability Analysis of Gasifier Lock Bucket Valve System Based on DBN Method. Math. Probl. Eng. 2021, 2021, 1–10. [Google Scholar] [CrossRef]
- Gao, W.; Yang, G.; Guo, M.; Yang, C. Internal overvoltage type identification for distribution network based on DTCWT-DBN algorithm. Power Syst. Prot. Control 2020, 188–197. [Google Scholar] [CrossRef]
- Lin, T.R.; Kim, E.; Tan, A. A practical signal processing approach for condition monitoring of low speed machinery using Peak-Hold-Down-Sample algorithm. Mech. Syst. Signal Process. 2013, 36, 256–270. [Google Scholar] [CrossRef] [Green Version]
- Thanh, P.N.; Cho, M.Y.; Da, T.N. Insulator leakage current prediction using surface spark discharge data and particle swarm optimization based neural network. Electr. Power Syst. Res. 2021, 191, 106888. [Google Scholar] [CrossRef]
- Meng, Y.; Sun, Y.; Chang, W.S. Optimal trajectory planning of complicated robotic timber joints based on particle swarm optimization and an adaptive genetic algorithm. Constr. Robot. 2021, 5, 131–146. [Google Scholar] [CrossRef]
- Li, W.; Cerise, J.E.; Yang, Y.; Han, H. Application of t-SNE to human genetic data. J. Bioinform. Comput. Biol. 2017, 15, 1750017. [Google Scholar] [CrossRef]
- Abdelmoula, W.M.; Balluff, B.; Englert, S.; Dijkstra, J.; Reinders, M.J.; Walch, A.; McDonnell, L.A.; Lelieveldt, B.P. Data-driven identification of prognostic tumor subpopulations using spatially mapped t-SNE of mass spectrometry imaging data. Proc. Natl. Acad. Sci. USA 2016, 113, 12244–12249. [Google Scholar] [CrossRef] [PubMed] [Green Version]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Down Sampling Rate | Sample Length | Model Training Time | Test Accuracy |
|---|---|---|---|---|
| 1 | 1 | 2048 | 176 s | 97.95% |
| 2 | 2 | 1024 | 142 s | 97.83% |
| 3 | 4 | 512 | 130 s | 90.1% |
| 4 | 8 | 256 | 81 s | 82.8% |
| 5 | 16 | 128 | 47 s | 55.4% |
| 6 | 32 | 64 | 28 s | 43.6% |
| Category | Model | Training Time (s) | Test Accuracy (%) |
|---|---|---|---|
| 1 | BP | 96 | 91.6 (1100/1200) |
| 2 | SVM | 118 | 92.25 (1107/1200) |
| 3 | DBN | 128 | 95.17 (1142/1200) |
| 4 | Proposed method | 142 | 97.83 (1174/1200) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; Wang, H.; Li, R.; Ji, B. A Novel Feature Identification Method of Pipeline In-Line Inspected Bending Strain Based on Optimized Deep Belief Network Model. Energies 2022, 15, 1586. https://doi.org/10.3390/en15041586
Liu S, Wang H, Li R, Ji B. A Novel Feature Identification Method of Pipeline In-Line Inspected Bending Strain Based on Optimized Deep Belief Network Model. Energies. 2022; 15(4):1586. https://doi.org/10.3390/en15041586
Chicago/Turabian StyleLiu, Shucong, Hongjun Wang, Rui Li, and Beilei Ji. 2022. "A Novel Feature Identification Method of Pipeline In-Line Inspected Bending Strain Based on Optimized Deep Belief Network Model" Energies 15, no. 4: 1586. https://doi.org/10.3390/en15041586
APA StyleLiu, S., Wang, H., Li, R., & Ji, B. (2022). A Novel Feature Identification Method of Pipeline In-Line Inspected Bending Strain Based on Optimized Deep Belief Network Model. Energies, 15(4), 1586. https://doi.org/10.3390/en15041586