
Customer Perceived Risk Measurement with NLP Method in Electric Vehicles Consumption Market: Empirical Study from China



Abstract
:1. Introduction
- Introduce the related research of perceived risk theory and the NLP methods of this study.
- Design consumer perceived risk measure architecture based on social media comments, build the NLP tasks implementation process and analyze experimental results.
- Conduct empirical results and analysis to prove the method’s feasibility and obtain advanced suggestions and means for government management and enterprise operation.
2. Literature Review
2.1. Perceived Risk Research in Consumer Behavior Theory
2.2. Perceived Risk Dimension Research
2.3. NLP Methods for Measuring Psychological Perception
3. Methodology
- Construct a data set of consumers’ social media comments toward EVs. At present, there is no adequate public data set on the customer perceived risk of EVs based on social media comments or corresponding methods for measuring customer perceived risk of EVs in China. Therefore, this paper preprocesses the collected related data to improve NLP accuracy through Chinese word segmentation, manual tagging corpus, and data cleaning.
- Establish a measurement system of customer perceived risk, including three NLP tasks. The first NLP task is to determine the classification of labels. The abstract extraction function of the BERT model was used to obtain quantitative analysis results from text data. Combined with previous research findings, labels containing perceived risk dimensions and granularity were obtained through manual screening and matching. Then, a word vector trained by the BERT model was used as initialization parameters of subsequent model. The second NLP task is the semantic identification of the consumer social media comments about the perceived risk of EVs. Based on the experiment results of the first NLP task, construct a multi-label classification method with the Text CNN model to complete the consumer comments semantic identification task. The third NLP task is the emotional intensity analysis of each perceived risk dimension. Based on the experimental results of the second NLP task, an emotion classification method is established to realize the multi-dimensional emotion analysis task by fusing the Bi-LSTM model and the attention mechanism.
- To find the key aspects and their correlation in finer granularity by analyzing the recognition results of different semantic expressions in consumer comments, the emotional intensity of different perceived risk dimensions, with the feature word lists.
3.1. Classification Label Mining Based on BERT Model
3.2. Semantic Identification Based on Bert-TextCNN Model
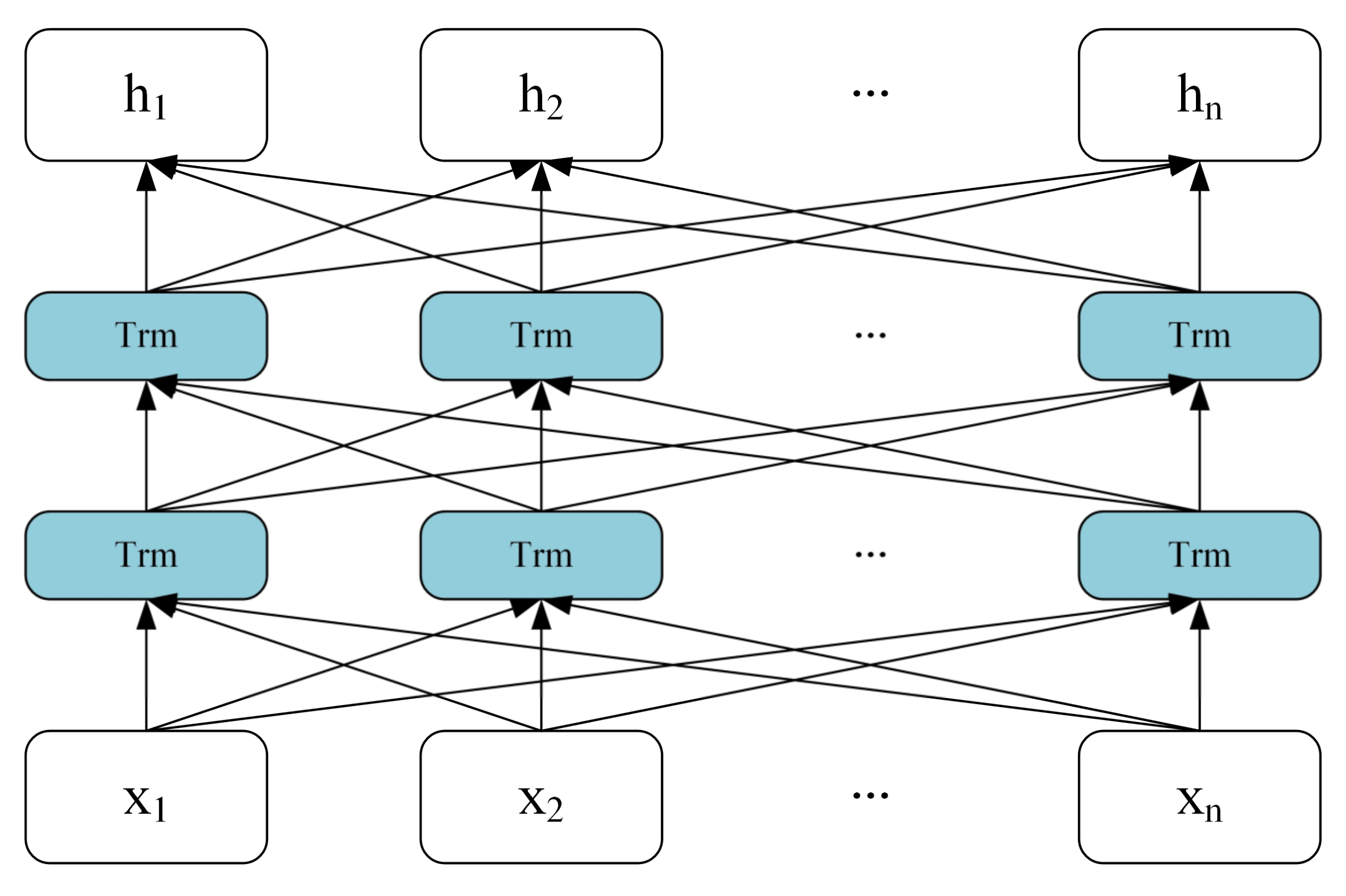
3.3. Emotion Analysis Based on Att-BiLSTM Model
- Word Vector Layer
- Bi-LSTM Layer
- Attention Layer
- Output Layer
4. Data Sources and Experimental Settings
4.1. Data Sources
4.2. Model Parameters Setup
4.3. Model Performance Evaluation Index
5. Result Analysis and Discussion
5.1. The Result of First NLP Task
5.2. The Result of Second NLP Task
5.3. The Result of Third NLP Task
5.4. The Analysis of NLP Tasks Results
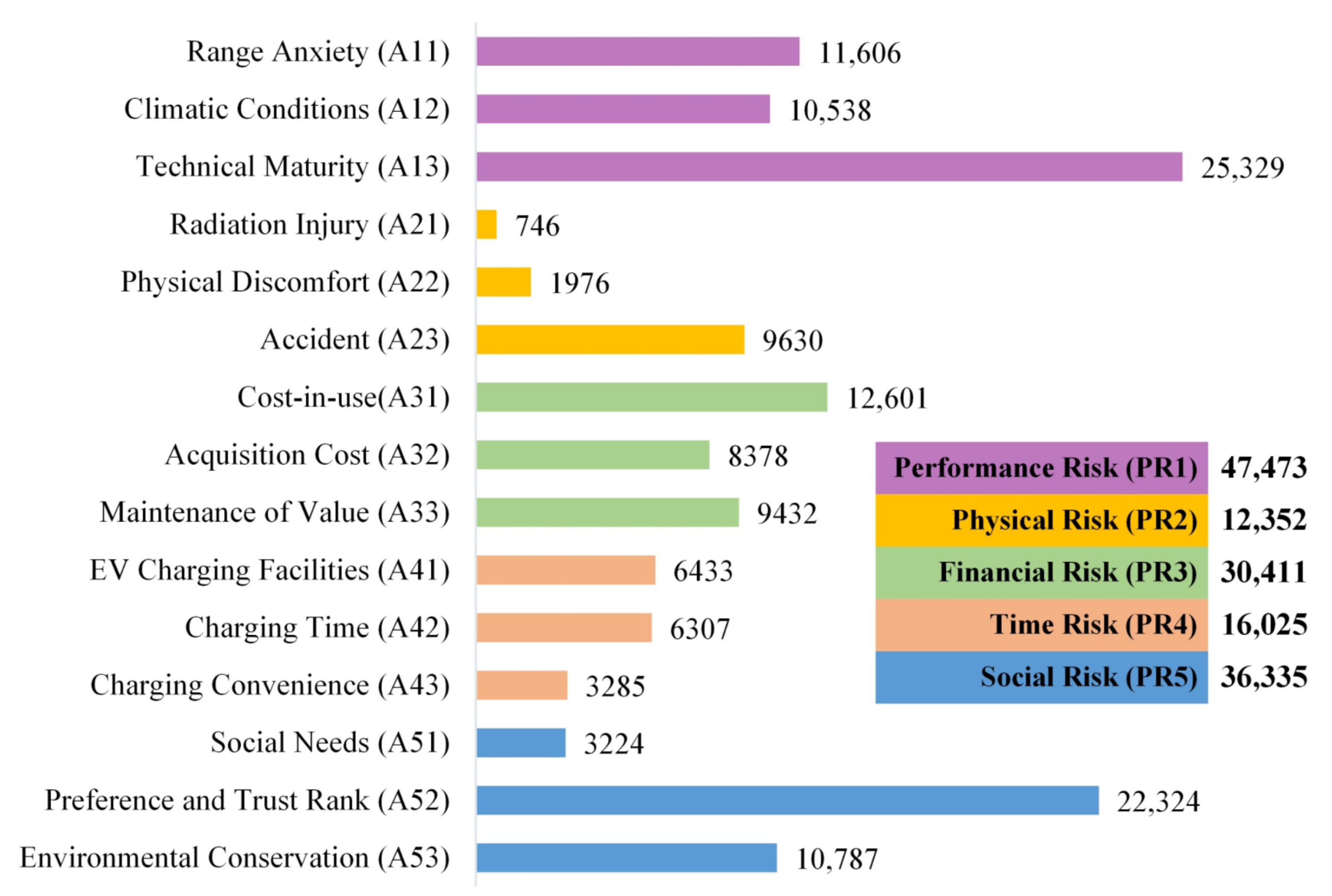
- Of particular note is that the comment amounts related to the “Technology Maturity” (A13) and “Preference and Trust Rank” (A52) abstracts are more additional than other abstracts. Combined with the feature words list of “Technology Maturity” (A13), such as “Workmanship”, “Maturity”, “Limitations”, “Degree of Attenuation”, “Hydrogen Fuel”, etc., it follows that Chinese consumers take the technical maturity issue of EVs the problem that needs the most attention. The same situation also occurs in “Preference and Trust Rank” A52, with the feature words list as “Preference”, “Believe”, “Dislike”, “Domestic”, “Foreign”, etc. The negative emotional comments (A13, 38%; A52, 39%) of these 2 abstracts also significant more than positive ones (A13, 32%; A52, 28%). The experiments show that the discussion mainly focuses on the disadvantages and limitations of technology, and the still fragile confidence of new technology or new EVs brands. Meanwhile, as shown in Table 5 the “Technology Maturity” (A13) is also the most occurred abstract in top 10 combined labels, accounting for seven times. It can be concluded that the abstract in performance risk dimension “Technology Maturity” (A13) in “Performance Risk” (PR1) dimension is the key factor to effect consumers perceived risks.
- Accounting for 54% of negative-in-emotion results, the comments about the “Time Risk” (PR4) occupy first place in the five dimensions of risks. Though the total related comments are relatively more minor, the consumers discussed much more about “EV Charging Facilities” (A41, 40.1%) or “Charging Time” (A42, 39.3%) than “Charging Convenience” (A43, 20.6%). Combined with the sentimental results of negative emotions, “Charging Time” (A42, 58%) is the first of all 15 abstracts. “EV Charging Facilities” (A41, 53%) is also very high negatively emotional. Consumers are obviously unsatisfied with the charging facility and its quantity put into use and efficiency.
- The number of comments related to “Physical Risk” (PR2) ranked at the end shows that the majority of consumers do not think safety is an exclusive problem to EVs. Even this, in a finer granular, 78% of comments related to “Physical Risk” (PR2) expressed concerns about “Accident” (A23). Not only that, 46% of the comments about the “Accident” (A23) abstract tested to be negative emotions. Analysis of the feature words list connected to “Accident” (A23) shows that consumers worried about the battery burning or and exploding, the brake system, etc.
- In the dimension of financial risk, the number of public comments about each abstract are relatively close. Combined with emotion analysis, consumers have more negative emotions about the value maintenance of EVs, which indicates that consumers have low evaluation on the second-hand value of EVs;
- Finally, there is a significant change when consumers discuss the social risk of EVs. In previous studies, questionnaires and interviews paid great attention to measuring the risk that consumers’ purchase or use of EVs may cause adverse effects such as family and friends’ incomprehension. However, through the measurement method proposed in this paper, the measurement results of consumers’ perceived social risk dimension show only 3224 comments related to “Social Needs” (A51). This is a sharp contrast to the comments of “Preference and Trust Rank” (A52), 22,324, in the same dimension. It implies that consumers have come to accept EVs as a regular, considerable commodity rather than a new, poorly practicable and experimental novelty.
5.5. The Discussion of Key Risks in Co-occurrence Network
- (1)
- Based on the co-occurrence mathematical matrix Table 5, this paper selects the top 10 co-occurrence risk abstracts to form a co-occurrence network, as shown in Figure 8. The abstract “Technology Maturity” (A13) in the “Performance Risk” (PR1) dimension is obliviously the central node of the network. As it has the largest number (25,329) of comments and forms a co-occurrence relationship with 7 other abstracts, it is the key factor that affects consumers’ perceived risks.
- In the same dimension, the relationship between “Technology Maturity” (A13), “Range Anxiety” (A11), and “Climatic Conditions” (A12) shows that consumers’ doubts about the technological maturity of EVs, especially the uncertainty of battery performance, leads to consumers’ range anxiety and anxieties about performance in cold weather.
- “Technology Maturity” (A13) and “Accident” (A23) also have co-occurrence, suggesting that it may be due to the lack of reliable and intelligent driving and control systems that consumers worry about accidents of EVs.
- The “Technology Maturity” (A13) and “Environmental Conservation” (A53) co-occurrence, occurring 5837 times, suggests that the EVs potential pollution risks of battery scrapping, damage, and existing pollution and emission in the power generation industry make consumers doubt the authenticity of EVs’ environmental friendliness. Consumers also expressed other environmentally friendly energy products that are potential alternatives to fuel or electric vehicles, such as hydrogen vehicles. Then the joint action of “Technology Maturity” (A13) and “Environmental Conservation” (A53) pulls down the evaluation of “Maintenance of Value” (A33).
- (2)
- More importantly, four risk nodes, which are “Technology Maturity” (A13), “Preference and Trust Rank” (A52), “Cost-in-use” (A31), and “Maintenance of Value” (A33), form a local network.
- “Technology Maturity” (A13) has direct relationships with all other risks in the local network. The connection of “Technology Maturity” (A13) and “Cost-in-use” (A31) shows that the immaturity of EVs technology also leads to some consumers worrying about the high cost of battery repair, replacement, and the correspondingly high cost of insurance. Moreover, they will question whether EVs can meet the manufacturer’s promise of low cost-in-use.
- Finally, the joint action of “Technology Maturity” (A13) and “Environmental Conservation” (A53) pulls down the evaluation of “Maintenance of Value” (A33). Most importantly, the co-occurrence of “Preference and Trust Rank” (A52) and “Technology Maturity” (A13) is the most frequent of all, occurring 9869 times. Moreover, the connections between “Preference and Trust Rank” (A52) and “Cost-in-use” (A31) are 4621, and between “Preference and Trust Rank” (A52) and “Maintenance of Value” (A33) are 4225. This represents that consumers’ perceived risk of EVs’ technology maturity is closely related to EV brands’ preference and trust ranking, directly or indirectly. That is to say, consumers’ concerns about technology maturity will affect their choice of fuel vehicles and EVs and focus on comparing the technology maturity of different EVs brands.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ma, L.; Zhong, W.; Mei, S. Research on “Fall off” Problem of Subsidy Policies for New-Energy Vehicles. Soft Sci. 2018, 32, 26–30. [Google Scholar]
- Li, L.; Wang, Z.; Chen, L.; Wang, Z. Consumer preferences for battery electric vehicles: A choice experimental survey in China. Transp. Res. Part D Transp. Environ. 2020, 78, 102185. [Google Scholar] [CrossRef]
- Wang, S.; Li, J.; Zhao, D. The impact of policy measures on consumer intention to adopt electric vehicles: Evidence from China. Transp. Res. Part A Policy Pract. 2017, 105, 14–26. [Google Scholar] [CrossRef]
- Kongklaew, C.; Phoungthong, K.; Prabpayak, C.; Chowdhury, M.S.; Khan, I.; Yuangyai, N.; Yuangyai, C.; Techato, K. Barriers to Electric Vehicle Adoption in Thailand. Sustainability 2021, 13, 12839. [Google Scholar] [CrossRef]
- Zhong, K.; Wang, P.; Pei, J.; Xu, J.; Han, Z.; Xu, J. Multiobjective Optimization regarding Vehicles and Power Grids. Wirel. Commun. Mob. Comput. 2021, 2021, 5552626. [Google Scholar] [CrossRef]
- Du, H.; Liu, D.; Sovacool, B.K.; Wang, Y.; Ma, S.; Li, R.Y.M. Who buys New Energy Vehicles in China? Assessing social-psychological predictors of purchasing awareness, intention, and policy. Transp. Res. Part F Traffic Psychol. Behav. 2018, 58, 56–69. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Wang, J.; Li, J.; Wang, J.; Liang, L. Policy implications for promoting the adoption of electric vehicles: Do consumer’s knowledge, perceived risk and financial incentive policy matter? Transp. Res. Part A Policy Pract. 2018, 117, 58–69. [Google Scholar] [CrossRef]
- Brown, D.E.; Abbasi, A.; Lau, R.Y.K. Predictive analytics: Predictive modeling at the micro level. IEEE Intell. Syst. 2015, 30, 6–8. [Google Scholar] [CrossRef] [Green Version]
- Zhong, K.; Wang, Y.; Pei, J.; Tang, S.; Han, Z. Super Efficiency SBM-DEA and Neural Network for Performance Evaluation. Inf. Process. Manag. 2021, 58, 102728. [Google Scholar] [CrossRef]
- Abbasi, A.; Lau, R.Y.K.; Brown, D.E. Predicting behavior. IEEE Intell. Syst. 2015, 30, 35–43. [Google Scholar] [CrossRef]
- Rust, J.; Golombok, S. Modern Psychometrics: The Science of Psychological Assessment, 3rd ed.; Routledge: London, UK, 2014. [Google Scholar]
- Li, J.; Larsen, K.R.; Abbasi, A. TheoryOn: A Design Framework and System for Unlocking Behavioral Knowledge through Ontology Learning. MIS Q. 2020, 44, 1733–1772. [Google Scholar] [CrossRef]
- Li, C.; Ye, L.; Wang, L. The Influence of New Energy Vehicle Consumption Promotion Policy on the Purchase Intention of Potential Consumers. Chin. J. Manag. Sci. 2021, 29, 151–164. [Google Scholar]
- Ye, F.; Kang, W.; Li, L.; Wang, Z. Why do consumers choose to buy electric vehicles? A paired data analysis of purchase intention configurations. Transp. Res. Part A Policy Pract. 2021, 147, 14–27. [Google Scholar] [CrossRef]
- Gefen, D.; Larsen, K.R. Controlling for Lexical Closeness in Survey Research: A Demonstration on the Technology Acceptance Model. J. Assoc. Inf. Syst. 2017, 18, 727–757. [Google Scholar] [CrossRef] [Green Version]
- Choudhury, P.; Wang, D.; Carlson, N.A. Machine learning approaches to facial and text analysis: Discovering CEO oral communication styles. Strateg. Manag. 2019, 40, 1705–1732. [Google Scholar] [CrossRef]
- Choi, J.; Menon, A.; Tabakovic, H. Using machine learning to revisit the diversification-performance relationship. Strateg. Manag. 2021, 42, 1632–1661. [Google Scholar] [CrossRef]
- Wang, Y.-Y.; Chi, Y.-Y.; Xu, J.-H.; Li, J.-L. Consumer Preferences for Electric Vehicle Charging Infrastructure Based on the Text Mining Method. Energies 2021, 14, 4598. [Google Scholar] [CrossRef]
- Qian, M.; Xu, Z. A Study of Dynamic Recognition of Consumer Brand Decision-making Preference Based on Machine Learning Method. Nankai Bus. Rev. 2019, 22, 66–76. [Google Scholar]
- Wang, W.; Ying, S.; Lyu, J.; Qi, X. Perceived image study with online data from social media: The case of boutique hotels in China. Ind. Manag. Data Syst. 2019, 119, 950–967. [Google Scholar] [CrossRef]
- Dou, Z.; Cheng, Z.; Huang, D. Research on Migrant Works’ Concern Recognition and Emotion Analysis Based on Web Text Data. Front. Psychol. 2021, 12, 741928. [Google Scholar] [CrossRef]
- Bauer, R.A. Consumer behavior as risk taking. In Proceedings of the 43rd National Conference of the American Marketing Association, Chicago, IL, USA, 15–17 June 1960; pp. 389–398. [Google Scholar]
- Cunningham, M.S. The major dimensions of perceived risk. In Risk-Taking and Information-Handling in Consumer Behavior; Cox, D.F., Ed.; Harvard University Press: Boston, MA, USA, 1967; pp. 82–108. [Google Scholar]
- Cox, D.F. Risk handling in consumer behavior—An intensive study of two cases. In Risk-Taking and Information-Handling in Consumer Behavior; Cox, D.F., Ed.; Harvard University Press: Boston, MA, USA, 1967; pp. 34–81. [Google Scholar]
- Dowling, G.R.; Staelin, R. A Model of Perceived Risk and Intended Risk-handling Activity. J. Consum. Res. 1994, 21, 119–134. [Google Scholar] [CrossRef]
- Kotler, P. Marketing Management: Analysis, Planning, Implementation and Control; Prentice-Hall PTR: Hoboken, NJ, USA, 1998. [Google Scholar]
- Mitchell, V.W. Consumer Perceived Risk: Conceptualization and Models. Eur. J. Mark. 1999, 100, 171–183. [Google Scholar] [CrossRef]
- Chen, R.; He, F. Examination of brand knowledge, perceived risk and consumers’ intention to adopt an online retailer. Total Qual. Manag. Bus. Excell. 2003, 14, 677–693. [Google Scholar] [CrossRef]
- Featherman, M.S.; Pavlou, P.A. Predicting e-services adoption: A perceived risk facets perspective. Int. J. Hum. Comput. Stud. 2003, 59, 451–474. [Google Scholar] [CrossRef] [Green Version]
- Burgess, M.; King, N.; Harris, M.; Lewis, E. Electric vehicle drivers’ reported interactions with the public: Driving stereotype change? Transp. Res. Part F Traffic Psychol. Behav. 2013, 17, 33–44. [Google Scholar] [CrossRef]
- Qian, L.; Yin, J. Linking Chinese cultural values and the adoption of electric vehicles: The mediating role of ethical evaluation. Transp. Res. Part D Transp. Environ. 2017, 56, 175–188. [Google Scholar] [CrossRef]
- White, L.V.; Sintov, N.D. You are what you drive: Environmentalist and social innovator symbolism drives electric vehicle adoption intentions. Transp. Res. Part A Policy Pract. 2017, 99, 94–113. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Long, R.; Chen, H.; Geng, J. Household factors and adopting intention of battery electric vehicles: A multi-group structural equation model analysis among consumers in Jiangsu Province, China. Nat. Hazards 2017, 87, 945–960. [Google Scholar] [CrossRef]
- Lee, M.C. Factors influencing the adoption of internet banking: An integration of TAM and TPB with perceived risk and perceived benefit. Electron. Commer. Res. Appl. 2009, 8, 130–141. [Google Scholar] [CrossRef]
- Park, E.; Ohm, J.Y. Factors influencing the public intention to use renewable energy technologies in South Korea: Effects of the Fukushima nuclear accident. Energy Policy 2014, 65, 198–211. [Google Scholar] [CrossRef]
- Peter, J.P.; Tarpey, S.; Lawrence, X. A comparative analysis of three-consumer decision strategic. J. Consum. Res. 1975, 2, 29–37. [Google Scholar] [CrossRef]
- Zhang, X.; Bai, X.; Shang, J. Is subsidized electric vehicles adoption sustainable: Consumers’ perceptions and motivation toward incentive policies, environmental benefits, and risks. J. Clean. Prod. 2018, 192, 71–79. [Google Scholar] [CrossRef]
- Stone, R.N.; Gronhaug, K. Perceived Risk: Further Considerations for the Marketing Discipline. Eur. J. Mark. 1993, 27, 173–180. [Google Scholar] [CrossRef]
- Chaudhuri, A. Product class effects on perceived risk: The role of emotion. Int. J. Res. Mark. 1998, 15, 157–168. [Google Scholar] [CrossRef]
- Mitchell, V.W.; McGoldrick, P.J. Consumer’s risk-reduction strategies: A review and synthesis. Int. Rev. Retail. Distrib. Consum. Res. 1996, 6, 1–33. [Google Scholar] [CrossRef]
- Jensen, A.F.; Cherchi, E.; Mabit, S.L. On the stability of preferences and attitudes before and after experiencing an electric vehicle. Transp. Res. Part D Transp. Environ. 2013, 25, 24–32. [Google Scholar] [CrossRef] [Green Version]
- Flamm, B.J.; Agrawal, A.W. Constraints to green vehicle ownership: A focus group study. Transp. Res. Part D Transp. Environ. 2012, 17, 108–115. [Google Scholar] [CrossRef]
- Egbue, O.; Long, S. Barriers to widespread adoption of electric vehicles: An analysis of consumer attitudes and perceptions. Energy Policy 2012, 48, 717–729. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, K.; Hao, Y.; Fan, J.; Wei, Y. The impact of government policy on preference for NEVs: The evidence from China. Energy Policy 2013, 61, 382–393. [Google Scholar] [CrossRef]
- Degirmenci, K.; Breitner, M.H. Consumer purchase intentions for electric vehicles: Is green more important than price and range? Transp. Res. Part D Transp. Environ. 2017, 51, 250–260. [Google Scholar] [CrossRef] [Green Version]
- Dumortier, J.; Siddiki, S.; Carley, S.; Cisney, J.; Krause, R.M.; Lane, B.W.; Rupp, J.A.; Graham, J.D. Effects of providing total cost of ownership information on consumers’ intent to purchase a hybrid or plug-in electric vehicle. Transp. Res. Part A Policy Pract. 2015, 72, 71–86. [Google Scholar] [CrossRef] [Green Version]
- Ko, W.; Hahn, T. Analysis of Consumer Preferences for Electric Vehicles. IEEE Trans. Smart Grid 2013, 4, 437–442. [Google Scholar] [CrossRef]
- Schuitema, G.; Anable, J.; Skippon, S.; Kinnear, N. The role of instrumental, hedonic and symbolic attributes in the intention to adopt electric vehicles. Transp. Res. Part A Policy Pract. 2013, 48, 39–49. [Google Scholar] [CrossRef]
- Barth, M.; Jugert, P.; Fritsche, I. Still underdetected—Social norms and collective efficacy predict the acceptance of electric vehicles in Germany. Transp. Res. Part F Traffic Psychol. Behav. 2016, 37, 64–77. [Google Scholar] [CrossRef]
- Wang, Y.; Hazen, B.T. Consumer product knowledge and intention to purchase remanufactured products. Int. J. Prod. Econ. 2016, 181, 460–469. [Google Scholar] [CrossRef]
- Ciampa, P.J.; Osborn, C.Y.; Peterson, N.B.; Rothman, R.L. Patient Numeracy, Perceptions of Provider Communication, and Colorectal Cancer Screening Utilization. J. Health Commun. 2010, 15, 157–168. [Google Scholar] [CrossRef] [Green Version]
- Osborne, R.H.; Batterham, R.W.; Elsworth, G.R.; Hawkins, M.; Buchbinder, R. The grounded psychometric development and initial validation of the Health Literacy Questionnaire (HLQ). BMC Public Health 2013, 13, 658. [Google Scholar] [CrossRef] [Green Version]
- Ahmad, F.; Abbasi, A.; Li, J.; Dobolyi, D.G.; Netemeyer, R.G.; Clifford, G.D.; Chen, H. A Deep Learning Architecture for Psychometric Natural Language Processing. ACM Trans. Inf. Syst. 2020, 38, 1–29. [Google Scholar] [CrossRef] [Green Version]
- Xu, K.; Huang, J.; Qi, G. A new sentiment and topic model for short texts on social media. Proceedings of Joint International Semantic Technology Conference, Gold Coast, Australia, 10–12 November 2017; pp. 183–198. [Google Scholar]
- Huang, M.; Qian, Q.; Zhu, X. Encoding Syntactic Knowledge in Neural Networks for Sentiment Classification. ACM Trans. Inf. Syst. 2017, 35, 1–27. [Google Scholar] [CrossRef]
- Vieira, J.P.A.; Moura, R.S. An analysis of convolutional neural networks for sentence classification. In Proceedings of the 2017 XLIII Latin American Computer Conference, Cordoba, Argentina, 4–8 September 2017; pp. 1–5. [Google Scholar]
- Chen, H.; Han, F.X.; Niu, D.; Liu, D.; Lai, K.; Wu, C. MIX: Multi-channel information crossing for text matching. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 110–119. [Google Scholar]
- Zimbra, D.; Abbasi, A.; Zeng, D.; Chen, H. The State-of-the-Art in Twitter Sentiment Analysis: A Review and Benchmark Evaluation. ACM Trans. Manag. Inf. Syst. 2018, 9, 1–29. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Duan, R.; Chao, W.; Zhang, Y. Application of pre-trained language model BERT in downstream tasks. J. Beijing Inf. Sci. Technol. Univ. 2020, 35, 77–83. [Google Scholar]
- Yang, W.; Xie, Y.; Lin, A.; Li, X.; Tan, L.; Xiong, K.; Li, M.; Lin, J. End-to-end open-domain question answering with BERTserini. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (Demonstrations), Minneapolis, MN, USA, 2–7 June 2019; pp. 72–77. [Google Scholar]
- Yang, L.; Huang, X.; Wang, J.; Ding, L.; Li, Z.; Li, J. Clinical Trial Disease Subtype Identification based on BERT-TextCNN. Data Anal. Knowl. Discov. 2021, 1–17. [Google Scholar]
- Sun, C.; Qiu, X.; Xu, Y.; Huang, X. How to fine-tune BERT for text classification? In Proceedings of the 18th China National Conference on Chinese Computational Linguistics, Kunming, China, 18–20 October 2019; pp. 194–206. [Google Scholar]
- Li, K.; Chen, Y.; Niu, S. Social E-commerce Text Classification Algorithm Based on BERT. Comput. Sci. 2021, 48, 87–92. [Google Scholar]
- Xu, H.; Liu, B.; Shu, L.; Yu, P.S. BERT Post-Training for Review Reading Comprehension and Aspect-based Sentiment Analysis. arXiv 2019, arXiv:1904.02232. [Google Scholar]
- Yang, J.; Yang, W. Text comment sentiment analysis based on BERT model. J. Tianjin Univ. Technol. 2021, 27, 12–16. [Google Scholar]
- Chen, Z.; Trabelsi, M.; Heflin, J.; Xu, Y.; Davison, B.D. Table search using a deep contextualized language model. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Online, China, 25–30 July 2020; pp. 589–598. [Google Scholar]
- Du, L.; Cao, D.; Lin, S.; Qu, Y.; Ye, H. Extraction and Automatic Classification of TCM Medical Records Based on Attention Mechanism of BERT and Bi-LSTM. Comput. Sci. 2020, 47, 416–420. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, F. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural Language Processing (Almost) from Scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level Convolutional Networks for Text Classification. Adv. Neural Inf. Process. Syst. 2015, 28, 649–657. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Elman, J.L. Finding Structure in Time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Cho, K.; Merrienboer, B.V.; Bahdanau, D.; Bengio, Y. On the Properties of Neural Machine Translation: Encoder-Decoder Approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- Jiang, W.; Jin, Z. Text Classification Based on Phrase Attention Mechanism. J. Chin. Inf. Process. 2018, 32, 103–119. [Google Scholar]
- Lyu, X.; Peng, C.; Zhang, L.; Dong, Z.; You, X. Text mutli-label classification method incorporating BERT and label semantic attention. J. Comput. Appl. 2022, 42, 57–63. [Google Scholar]
- Wu, X.; Chen, L.; Wei, T.; Fan, T. Sentiment Analysis of Chinese Short Text Based on Self-Attention and Bi-LSTM. J. Chin. Inf. Process. 2019, 33, 100–107. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Yao, X. Attention-based BiLSTM neural networks for sentiment classification of short texts. Proceedings of Information Science and Cloud Computing (ISCC 2017), Guangzhou, China, 16–17 December 2017; pp. 110–117. [Google Scholar]
- Zhao, Q.; Cai, X.; Li, B.; Lyu, L. Text feature extraction method based on LSTM-Attention neural network. Mod. Electron. Tech. 2018, 41, 167–170. [Google Scholar]
- Zhang, Y.; Zheng, J.; Huang, G.; Jiang, Y. Microblog sentiment analysis method based on a double attention model. J. Tsinghua Univ. 2018, 58, 122–130. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. arXiv 2019, arXiv:1906.08237. [Google Scholar]
- Graves, A. Long Short-Term Memory. Supervised Seq. Label. Recurr. Neural Netw. Stud. Comput. Intell. 2012, 385, 37–45. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Products Type | Dimensions | Description | Author(s) |
|---|---|---|---|
| Generic Products |
| The purchased product does not perform as expected. | [38,39,40] |
| The personal injury caused by purchasing the product. | [38,39,40] | |
| The purchase products will result in a loss of money or other resources. | [38,39,40] | |
| The time loss caused by purchasing or retaining products. | [38,39,40] | |
| The product leads to an inconsistent self-image. | [38,39,40] | |
| The products are not accepted by relatives and friends. | [38,39,40] | |
| EVs |
| Consumers worry about the performance differences between EVs and traditional gasoline vehicles. | [5,37] |
| Consumers tend to have general perceptions that EVs offer several lower levels of performance, such as reduced range, low maximum speed, less powerful acceleration. | [30,32] | ||
| EVs might not perform well because of long recharging time, short driving distance, and limited charging stations. | [7,33] | ||
| There can be safety and reliability issues in EVs, such as spontaneous combustion which can cause physical damages. | [7,41] | |
| EVs can cause contingency, such as batteries to burst into flames, and result in physical damages. | [33,42] | ||
| The batteries in EVs cannot be insured in China. When the battery fails, it is difficult for consumers to ask for compensation. | [43,44] | |
| The total purchase cost of EVs is higher than that of conventional gasoline cars. | [45,46] | ||
| Consumers may loss time in the using process of EVs, such as spending long time to recharge the battery. | [33,47] | |
| The lack of charging infrastructure leads to consumers spending a lot of time looking for charging stations and charging piles. | [18,48] | ||
| Consumers’ social status maybe improved or decreased lies on how EVs are viewed. | [7,49] | |
| Consumers’ purchases of EVs may be misunderstood by other people, damaging their social status and self-image in social groups. | [31,50] |
| Parameter | Value | |
|---|---|---|
| TextCNN | Att-BiLSTM | |
| Batch size | 64 | 128 |
| Epochs | 50 | 120 |
| Internal layer | 3 | 3 |
| No of hidden layers | 3 | 3 |
| Activation function | RELU | RELU |
| Learning optimizer | Adam(stochastic) | Adam(stochastic) |
| Regularization | L2-regularization = 0.0001 | L2-regularization = 0.003 |
| Model | MaP(+) | MaR(+) | MaF1(+) | HL(−) |
|---|---|---|---|---|
| BERT-TextCNN | 0.93 | 0.91 | 0.92 | 0.0011 |
| Model | P | R | F1 |
|---|---|---|---|
| BERT-Att-BiLSTM | 0.91 | 0.92 | 0.90 |
| Combined Labels | Number of Comments | ||
|---|---|---|---|
| Technology Maturity (A13) | + | Preference and Trust Rank (A52) | 9869 |
| Technology Maturity (A13) | + | Cost-in-use (A31) | 5993 |
| Technology Maturity (A13) | + | Environmental Conservation (A53) | 5837 |
| Technology Maturity (A13) | + | Range Anxiety (A11) | 5744 |
| Technology Maturity (A13) | + | Climatic Conditions (A12) | 5358 |
| Cost-in-use (A31) | + | Preference and Trust Rank (A52) | 4621 |
| Technology Maturity (A13) | + | Maintenance of Value (A33) | 4403 |
| Technology Maturity (A13) | + | Accident (A23) | 4226 |
| Maintenance of Value (A33) | + | Preference and Trust Rank (A52) | 4225 |
| Maintenance of Value (A33) | + | Environmental Conservation (A53) | 4186 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shu, T.; Wang, Z.; Lin, L.; Jia, H.; Zhou, J. Customer Perceived Risk Measurement with NLP Method in Electric Vehicles Consumption Market: Empirical Study from China. Energies 2022, 15, 1637. https://doi.org/10.3390/en15051637
Shu T, Wang Z, Lin L, Jia H, Zhou J. Customer Perceived Risk Measurement with NLP Method in Electric Vehicles Consumption Market: Empirical Study from China. Energies. 2022; 15(5):1637. https://doi.org/10.3390/en15051637
Chicago/Turabian StyleShu, Tao, Zhiyi Wang, Ling Lin, Huading Jia, and Jixian Zhou. 2022. "Customer Perceived Risk Measurement with NLP Method in Electric Vehicles Consumption Market: Empirical Study from China" Energies 15, no. 5: 1637. https://doi.org/10.3390/en15051637