
Predicting the Compressibility Factor of Natural Gas by Using Statistical Modeling and Neural Network



Abstract
:
1. Introduction
2. Literature Review
3. Methodology
3.1. Data Gathering
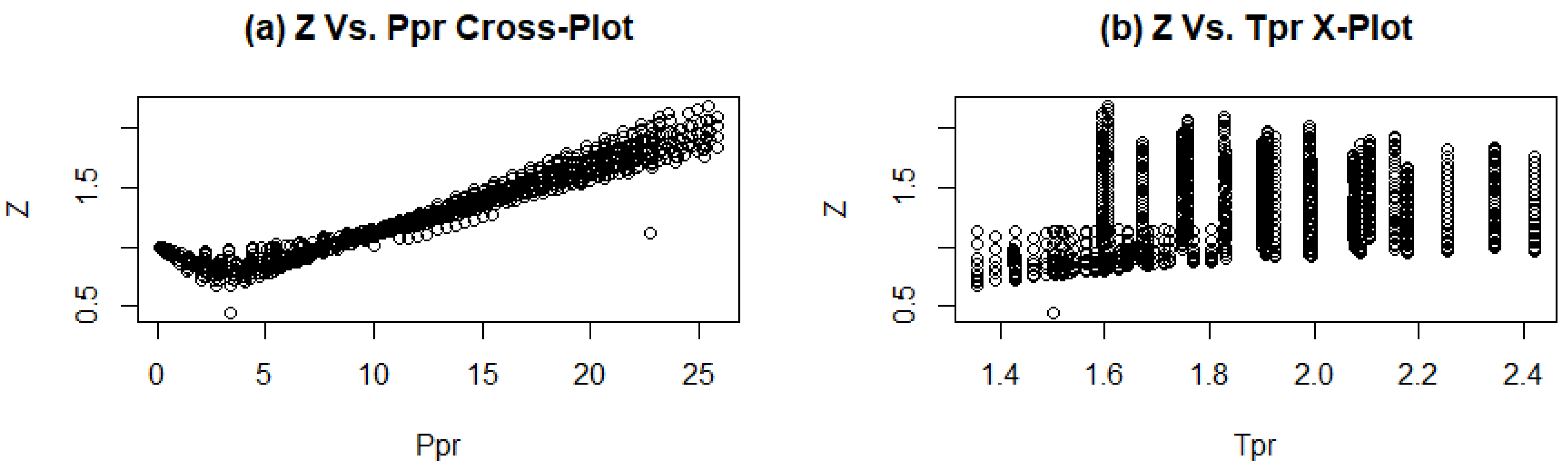
3.2. Data Exploration
3.3. Model Selection
3.4. Model Postulation
Statistical Regression Modeling
3.5. MLFN Model
4. Results
4.1. Data Gathering
4.2. Data Exploration
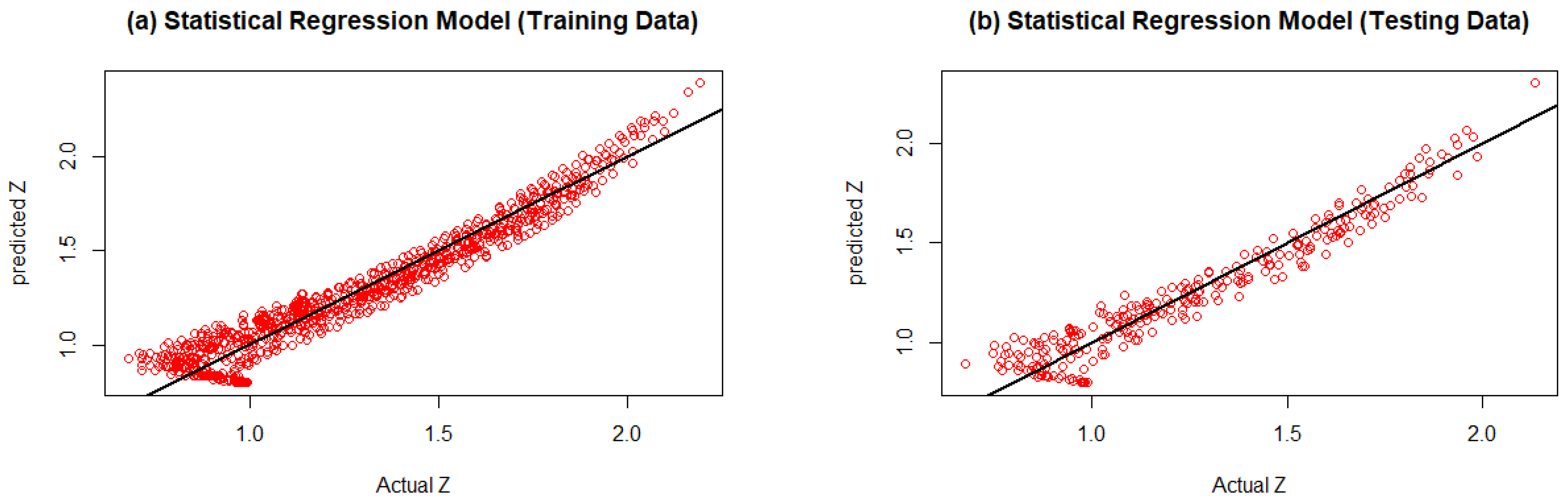
4.3. Results of the Statistical Regression Model
4.4. Results of the MLFN Model
5. Discussion
6. Conclusions
- The Ppr and Tpr were calculated using the compositional analysis and the reservoir pressure and temperature for each sample, according to Kay’s rule.
- The statistical regression model and the MLFN neural network were postulated and trained for a wide range of Ppr (0.12 to 25.8) and Tpr (1.3 to 2.4).
- The designed MLFN neural network consists of one input layer with two anodes, three hidden layers, and one output layer.
- Both the correlation coefficient and the residual analysis showed that the MLFN model is more stable and accurate than the statistical model. However, statistical modeling is an important step before running neural networks because it helps recognize the hidden patterns in data and test various sets of model variables in order to obtain the best group of predictors that could be later used as inputs to neural networks.
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Nomenclature
| GOR | Gas oil ratio |
| FVF | Formation volume factor |
| PVT | Pressure, volume and temperature |
| MLFN | Multi-layer-feedforward neural network |
| MCMC | Markov chain Monte Carlo |
| EOS | Equation of state |
| Pr | Reduced pressure |
| Tr | Reduced temperature |
| Pc | Critical pressure |
| Tc | Critical temperature |
| Ppr | Pseudo-reduced pressure |
| Tpr | Pseudo-reduced temperature |
| LANN | Linked adaptive neural network |
| GA | Genetic Algorithm |
| LSSVM | Least square support vector machine |
References
- Gaganis, V.; Homouz, D.; Maalouf, M.; Khoury, N.; Polychronopoulou, K. An Efficient Method to Predict Compressibility Factor of Natural Gas Streams. Energies 2019, 12, 2577. [Google Scholar] [CrossRef] [Green Version]
- Cengel, Y.A.; Boles, M.A. Energy, energy transfer, and general energy analysis. In An Engineering Approach; McGraw-Hill: New York, NY, USA, 2007. [Google Scholar]
- Danesh, A. PVT and Phase Behaviour of Petroleum Reservoir Fluids; Elsevier: Amsterdam, The Netherlands, 1998. [Google Scholar]
- Sanjari, E.; Lay, E.N. Estimation of natural gas compressibility factors using artificial neural network approach. J. Nat. Gas Sci. Eng. 2012, 9, 220–226. [Google Scholar] [CrossRef]
- Azizi, N.; Behbahani, R.M. Predicting the compressibility factor of natural gas. Pet. Sci. Technol. 2017, 35, 696–702. [Google Scholar] [CrossRef]
- Mohamadi-Baghmolaei, M.; Azin, R.; Osfouri, S.; Mohamadi-Baghmolaei, R.; Zarei, Z. Prediction of gas compressibility factor using intelligent models. Nat. Gas Ind. B 2015, 2, 283–294. [Google Scholar] [CrossRef] [Green Version]
- Almehaideb, R.A.; Al-Khanbashi, A.S.; Abdulkarim, M.; Ali, M.A. EOS tuning to model full field crude oil properties using multiple well fluid PVT analysis. J. Pet. Sci. Eng. 2000, 26, 291–300. [Google Scholar] [CrossRef]
- Varzandeh, F.; Stenby, E.H.; Yan, W. Comparison of GERG-2008 and simpler EoS models in calculation of phase equilibrium and physical properties of natural gas related systems. Fluid Phase Equilibria 2017, 434, 21–43. [Google Scholar] [CrossRef] [Green Version]
- Hendriks, E.; Kontogeorgis, G.; Dohrn, R.; De Hemptinne, J.-C.; Economou, I.; Žilnik, L.F.; Vesovic, V. Industrial Requirements for Thermodynamics and Transport Properties. Ind. Eng. Chem. Res. 2010, 49, 11131–11141. [Google Scholar] [CrossRef]
- Orbey, H.; Sandler, S.I. Modeling Vapor-Liquid Equilibria: Cubic Equations of State and Their Mixing Rules; Cambridge University Press: Cambridge, UK, 1998. [Google Scholar]
- Dindoruk, B.; Ratnakar, R.R.; He, J. Review of recent advances in petroleum fluid properties and their representation. J. Nat. Gas Sci. Eng. 2020, 83, 103541. [Google Scholar] [CrossRef]
- Seitmaganbetov, N.; Rezaei, N.; Shafiei, A. Characterization of crude oils and asphaltenes using the PC-SAFT EoS: A systematic review. Fuel 2021, 291, 120180. [Google Scholar] [CrossRef]
- Fayazi, A.; Arabloo, M.; Mohammadi, A.H. Efficient estimation of natural gas compressibility factor using a rigorous method. J. Nat. Gas Sci. Eng. 2014, 16, 8–17. [Google Scholar] [CrossRef]
- Al-Fatlawi, O.; Hossain, M.; Osborne, J. Determination of best possible correlation for gas compressibility factor to accurately predict the initial gas reserves in gas-hydrocarbon reservoirs. Int. J. Hydrogen Energy 2017, 42, 25492–25508. [Google Scholar] [CrossRef]
- Brill, J.; Beggs, H. Two-Phase Flow in Pipes; INTERCOMP Course, The Hague. University of Tulsa: Tulsa, OK, USA, 1974. Available online: https://www.scribd.com/doc/311112901/Brill-J-P-Beggs-H-D-Two-Phase-Flow-in-Pipes (accessed on 26 December 2021).
- Kamyab, M.; Sampaio, J.H.; Qanbari, F.; Eustes, A.W. Using artificial neural networks to estimate the z-factor for natural hydrocarbon gases. J. Pet. Sci. Eng. 2010, 73, 248–257. [Google Scholar] [CrossRef]
- Dranchuk, P.; Abou-Kassem, H. Calculation of Z Factors for Natural Gases Using Equations of State. J. Can. Pet. Technol. 1975, 14, PETSOC-75-03-03. [Google Scholar] [CrossRef]
- Fatoorehchi, H.; Abolghasemi, H.; Rach, R.; Assar, M. An improved algorithm for calculation of the natural gas compressibility factor via the Hall-Yarborough equation of state. Can. J. Chem. Eng. 2014, 92, 2211–2217. [Google Scholar] [CrossRef]
- Kumar, N.A. Compressibility Factors for Natural and Sour Reservoir Gases by Correlations and Cubic Equations of State. Ph.D. Thesis, Texas Tech University, Lubbock, TX, USA, 2004. [Google Scholar]
- Azizi, N.; Behbahani, R.; Isazadeh, M. An efficient correlation for calculating compressibility factor of natural gases. J. Nat. Gas Chem. 2010, 19, 642–645. [Google Scholar] [CrossRef]
- Omobolanle, O.C.; Akinsete, O.O. A Comprehensive Review of Recent Advances in the Estimation of Natural Gas Compressibility Factor. In Proceedings of the SPE Nigeria Annual International Conference and Exhibition, Lagos, Nigeria, 2–4 August 2021. [Google Scholar]
- Tariq, Z.; Aljawad, M.S.; Hasan, A.; Murtaza, M.; Mohammed, E.; El-Husseiny, A.; Alarifi, S.A.; Mahmoud, M.; Abdulraheem, A. A systematic review of data science and machine learning applications to the oil and gas industry. J. Pet. Explor. Prod. Technol. 2021, 11, 4339–4374. [Google Scholar] [CrossRef]
- Normandin, A.; Grandjean, B.P.A.; Thibault, J. PVT data analysis using neural network models. Ind. Eng. Chem. Res. 1993, 32, 970–975. [Google Scholar] [CrossRef]
- Chamkalani, A.; Mae’Soumi, A.; Sameni, A. An intelligent approach for optimal prediction of gas deviation factor using particle swarm optimization and genetic algorithm. J. Nat. Gas Sci. Eng. 2013, 14, 132–143. [Google Scholar] [CrossRef]
- Azizi, N.; Rezakazemi, M.; Zarei, M.M. An intelligent approach to predict gas compressibility factor using neural network model. Neural Comput. Appl. 2017, 31, 55–64. [Google Scholar] [CrossRef]
- Saemi, M.; Ahmadi, M.; Varjani, A.Y. Design of neural networks using genetic algorithm for the permeability estimation of the reservoir. J. Pet. Sci. Eng. 2007, 59, 97–105. [Google Scholar] [CrossRef]
- Moghadassi, A.R.; Parvizian, F.; Hosseini, S.M.; Fazlali, A.R. A new approach for estimation of PVT properties of pure gases based on artificial neural network model. Braz. J. Chem. Eng. 2009, 26, 199–206. [Google Scholar] [CrossRef] [Green Version]
- Saghafi, H.; Arabloo, M. Development of genetic programming (GP) models for gas condensate compressibility factor determination below dew point pressure. J. Pet. Sci. Eng. 2018, 171, 890–904. [Google Scholar] [CrossRef]
- Buxton, T.S.; Campbell, J.M. Compressibility Factors for Lean Natural Gas-Carbon Dioxide Mixtures at High Pressure. Soc. Pet. Eng. J. 1967, 7, 80–86. [Google Scholar] [CrossRef]
- Satter, A.; Campbell, J.M. Non-Ideal Behavior of Gases and Their Mixtures. Soc. Pet. Eng. J. 1963, 3, 333–347. [Google Scholar] [CrossRef] [Green Version]
- McLeod, W.R. Applications of Molecular Refraction to the Principle of Corresponding States; The University of Oklahoma: Norman, OK, USA, 1968. [Google Scholar]
- Liu, H.; Sun, C.-Y.; Yan, K.-L.; Ma, Q.-L.; Wang, J.; Chen, G.-J.; Xiao, X.-J.; Wang, H.-Y.; Zheng, X.-T.; Li, S. Phase behavior and compressibility factor of two China gas condensate samples at pressures up to 95MPa. Fluid Phase Equilibria 2013, 337, 363–369. [Google Scholar] [CrossRef]
- Li, Q.; Guo, T.-M. A study on the super-compressibility and compressibility factors of natural gas mixtures. J. Pet. Sci. Eng. 1991, 6, 235–247. [Google Scholar] [CrossRef]
- Sun, C.-Y.; Liu, H.; Yan, K.-L.; Ma, Q.-L.; Liu, B.; Chen, G.-J.; Xiao, X.-J.; Wang, H.-Y.; Zheng, X.-T.; Li, S. Experiments and Modeling of Volumetric Properties and Phase Behavior for Condensate Gas under Ultra-High-Pressure Conditions. Ind. Eng. Chem. Res. 2012, 51, 6916–6925. [Google Scholar] [CrossRef]
- Becker, R.A.; Chambers, J.M.; Wilks, A.R. The New S Language; Wadsworth & Brooks/Cole: Pacific Grove, CA, USA, 1988. [Google Scholar]
- Geladi, P.; Kowalski, B. Partial Least Squares Regression: A Tutorial. Anal. Chim. Acta 1986, 185, 1–17. [Google Scholar] [CrossRef]
- Jolliffe, I.T. Principla Component Analysis, 2nd ed.; Springer: New York, NY, USA, 2002. [Google Scholar]
- Mulaik, S.A. Foundations of Factor Analysis, 2nd ed.; Chapman Hall/CRC: London, UK, 2009. [Google Scholar]
- Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Open: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Hami-Eddine, K.; Klein, P.; Richard, L. Well facies based supervised classification of prestack seismic: Application to a turbidite field. In Proceedings of the 2009 SEG Annual Meeting, Houston, TX, USA, 25–30 October 2009. [Google Scholar]
- Nikravesh, M.; Zadeh, L.A.; Aminzadeh, F. Soft Computing and Intelligent Data Analysis in Oil Exploration; Elsevier: Amsterdam, The Netherlands, 2003. [Google Scholar]
- Svozil, D.; Kvasnicka, V.; Pospichal, J. Introduction to multi-layer feed-forward neural networks. Chemom. Intell. Lab. Syst. 1997, 39, 43–62. [Google Scholar] [CrossRef]
- Stuart, A. Kendall’s Advanced Theory of Statistics; Distribution Theory; Wiley: Hoboken, NJ, USA, 1994; Volume 1. [Google Scholar]
- Banerjee, S.; Carlin, B.P.; Gelfand, A.E. Hierarchical Modeling and Analysis for Spatial Data; Chapman: London, UK, 2003; Hall/CRC: Boca Raton, FL, USA, 2003. [Google Scholar]
- Gao, R.; Sheng, Y. Law of large numbers for uncertain random variables with different chance distributions. J. Intell. Fuzzy Syst. 2016, 31, 1227–1234. [Google Scholar] [CrossRef] [Green Version]
- Abid, S.H.; Al-Hassany, S. On the inverted gamma distribution. Int. J. Syst. Sci. Appl. Math. 2016, 1, 16–22. [Google Scholar]
- Lunn, D.; Spiegelhalter, D.; Thomas, A.; Best, N. The BUGS project: Evolution, critique and future directions. Stat. Med. 2009, 28, 3049–3067. [Google Scholar] [CrossRef] [PubMed]
- Plummer, M.; Best, N.; Cowles, K.; Vines, K. CODA: Convergence Diagnosis and Output Analysis for MCMC. R News 2006, 6, 7–11. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Werbos, P.J. The Roots of Backpropagation: From Ordered Derivatives to Neural Networks and Political Forecasting; John Wiley & Sons: Hoboken, NJ, USA, 1994; Volume 1. [Google Scholar]
- Intrator, O.; Intrator, N. Using Neural Nets for Interpretation of Nonlinear Models. In Proceedings of the Statistical Computing Section; American Statistical Society: San Francisco, CA, USA, 1993; pp. 244–249. [Google Scholar]
- Gooch, J.W. Pearson’s Product-Moment Correlation Coefficient. In Encyclopedic Dictionary of Polymers; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2011; p. 991. [Google Scholar]
- Chambers, J.; Hastie, T. Chapter 4 of Statistical Models in S. In Linear Models; Wadsworth & Brooks/Cole: Pacific Grove, CA, USA, 1992. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistical Property | Ppr | Tpr | Z |
|---|---|---|---|
| Count | 1079 | 1079 | 1079 |
| Mean | 12.360625 | 1.838588 | 1.285249 |
| Std | 6.900794 | 0.253642 | 0.351064 |
| Min | 0.162203 | 1.357125 | 0.445000 |
| Max | 25.821442 | 2.420676 | 2.192700 |
| Model Name | Training Data | Testing Data |
|---|---|---|
| Statistical Model | 0.969 | 0.967 |
| MLFN Model | 0.982 | 0.979 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ghanem, A.; Gouda, M.F.; Alharthy, R.D.; Desouky, S.M. Predicting the Compressibility Factor of Natural Gas by Using Statistical Modeling and Neural Network. Energies 2022, 15, 1807. https://doi.org/10.3390/en15051807
Ghanem A, Gouda MF, Alharthy RD, Desouky SM. Predicting the Compressibility Factor of Natural Gas by Using Statistical Modeling and Neural Network. Energies. 2022; 15(5):1807. https://doi.org/10.3390/en15051807
Chicago/Turabian StyleGhanem, Alaa, Mohammed F. Gouda, Rima D. Alharthy, and Saad M. Desouky. 2022. "Predicting the Compressibility Factor of Natural Gas by Using Statistical Modeling and Neural Network" Energies 15, no. 5: 1807. https://doi.org/10.3390/en15051807