
A Method of Probability Distribution Modeling of Multi-Dimensional Conditions for Wind Power Forecast Error Based on MNSGA-II-Kmeans


Abstract
:1. Introduction
- Most of the existing conditional modeling methods consider only the influence of FWO on the probability distribution of WPFE. Actually, the probability distribution of WPFE is not only related to simple electrical variables, such as FWO, but also closely coupled with many non-electrical variables. The conditions for the probability distribution of WPFE should be complex and multi-dimensional.
- Although many studies have used conditional modeling to describe the uncertainty of WPFE, none of them has explained the advantages of conditional probability distribution over non-conditional probability distribution, which is modeled based solely on historical data of WPFE, from a principled point of view. As a result, the application value of the conditional modeling way cannot be guaranteed in the modeling process.
- New technique: A conditional probability distribution of WPFE based on MDIF is proposed, which is realized by clustering the historical data of MDIF and modeling the PDF of different MDIF modes’ WPFE. Compared with the existing modeling methods of wind power uncertainty, we consider both the effects of weather and FWO in the modeling process of the WPFE conditional probability distribution.
- New method: A multi-objective clustering algorithm named MNSGA-II-Kmeans is proposed. This algorithm takes MDIF as the clustering object. In the clustering process, one of the goals is to maximize the difference in the PDFs of WPFE between different modes, so as to ensure the application value of the conditional probability distribution to SED problems. Besides, it also uses the proposed adaptive crossover operator and mutation operator to improve the search ability.
- Increase in wind power consumption: Based on the identification of MDIF modes, the specific application process of multi-dimensional conditional probability distribution of WPFE in SED problem is proposed. Compared with the non-conditional modeling method that does not consider MDIF, the method proposed can achieve better decision-making results, that is, to improve the wind power consumption of the power system from a statistical point of view.
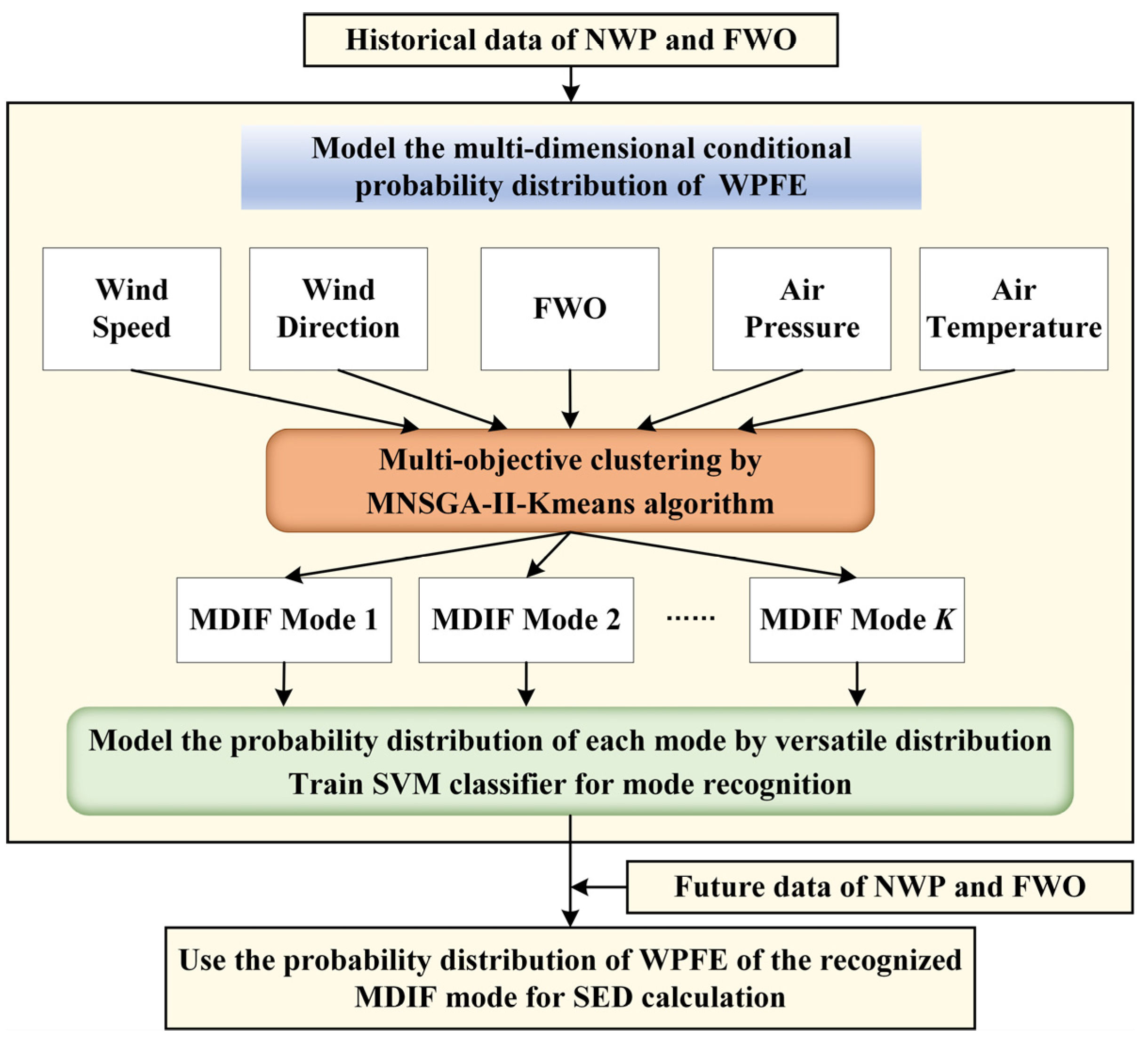
2. Proposed Multi-Dimensional Conditional Probability Distribution Modeling for WPFE
- Take the historical data of NWP (wind speed, air temperature, air pressure, etc.) and FWO at the same sampling time to be the historical dataset of MDIF. Then, divide them into several categories by multi-objective clustering algorithm. Each category is called a mode of MDIF. The PDF of historical WPFE data corresponding to each mode is fitted, which is called the conditional probability model of WPFE corresponding to this MDIF mode.
- The forecast data of MDIF given by NWP and FWO at a certain time in the future are attributed to one of the above-mentioned modes through mode recognition. The PDF of WPFE corresponding to the recognized mode is used as the probability model at the time. Based on the FWO at this time, the probability distribution of wind power is obtained.
3. Multi-Objective Clustering Based on MNSGA-II-Kmeans
3.1. Modeling of Multi-Objective Clustering Problem
3.1.1. The Objective Function
3.1.2. Constraints
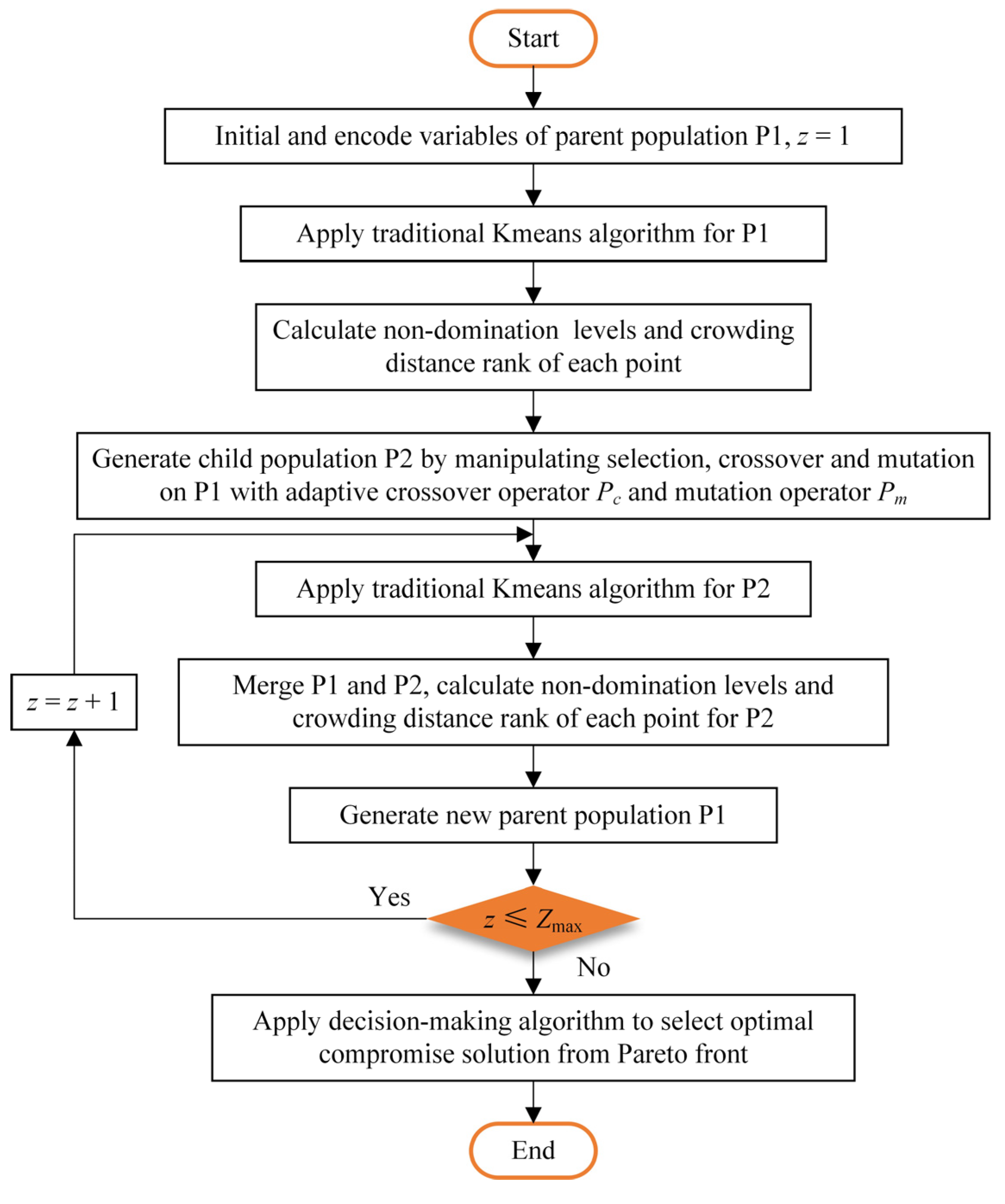
3.2. MNSGA-II-Kmeans Algorithm
3.2.1. Adaptive Crossover Operator and Mutation Operator
3.2.2. Clustering Based on Kmeans Algorithm
3.2.3. Decision-Making Algorithm
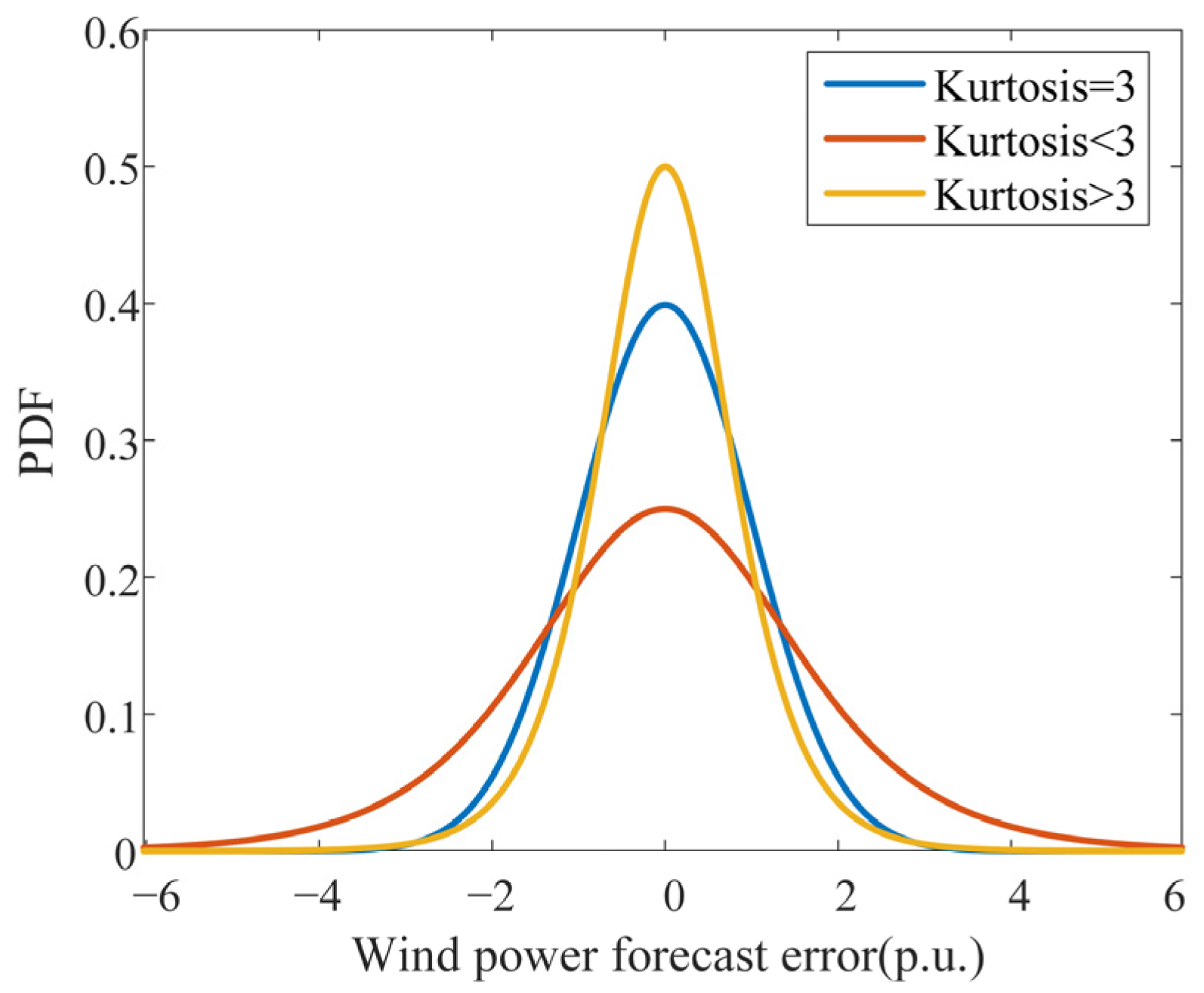
4. Versatile Distribution for Probability Distribution Modeling
5. SVM Algorithm for Mode Recognition
- Select the RBF kernel function that performs better in most cases.
- Equation (16) shows how to calculate the accuracy of SVM classification.
6. Experimental Results
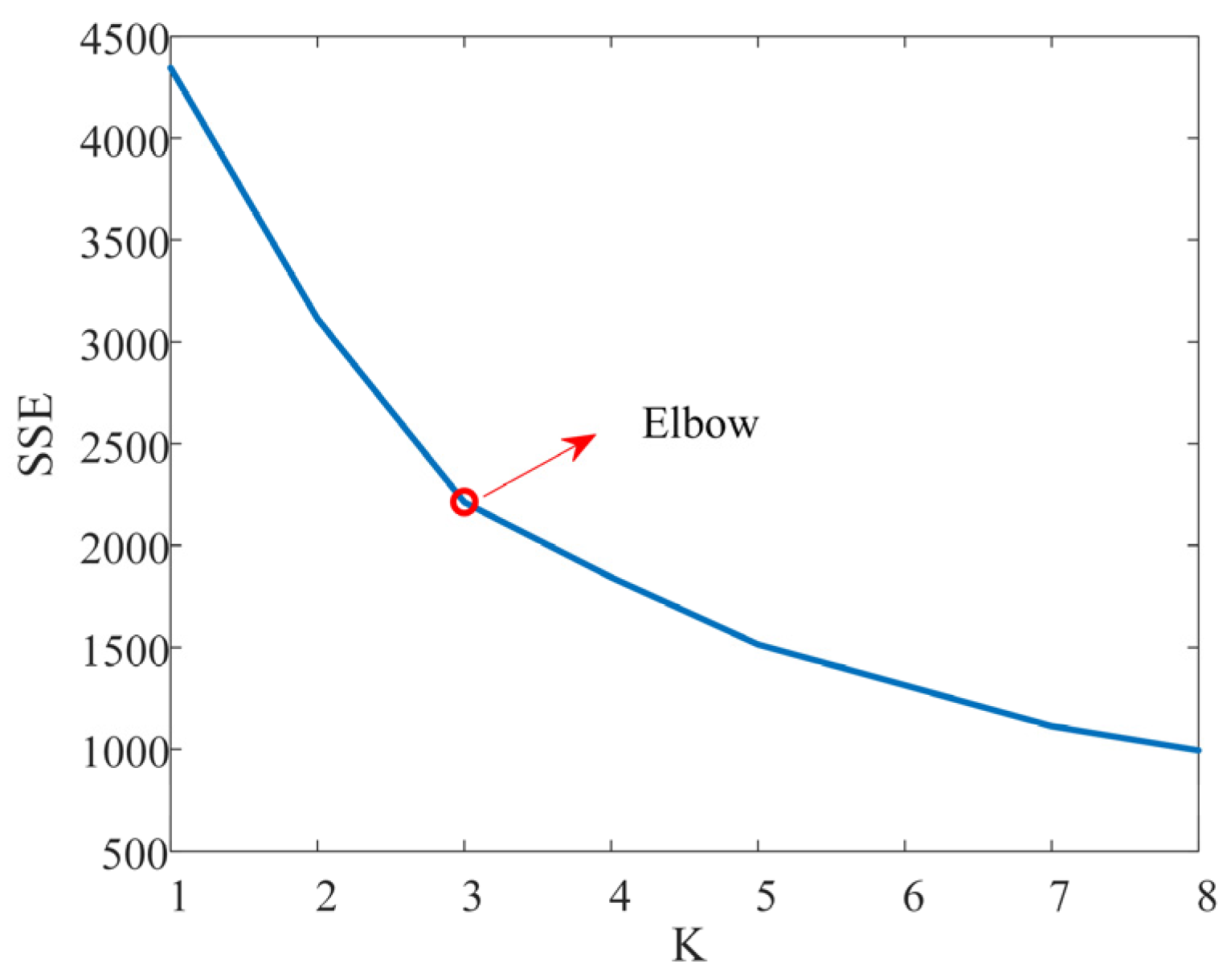
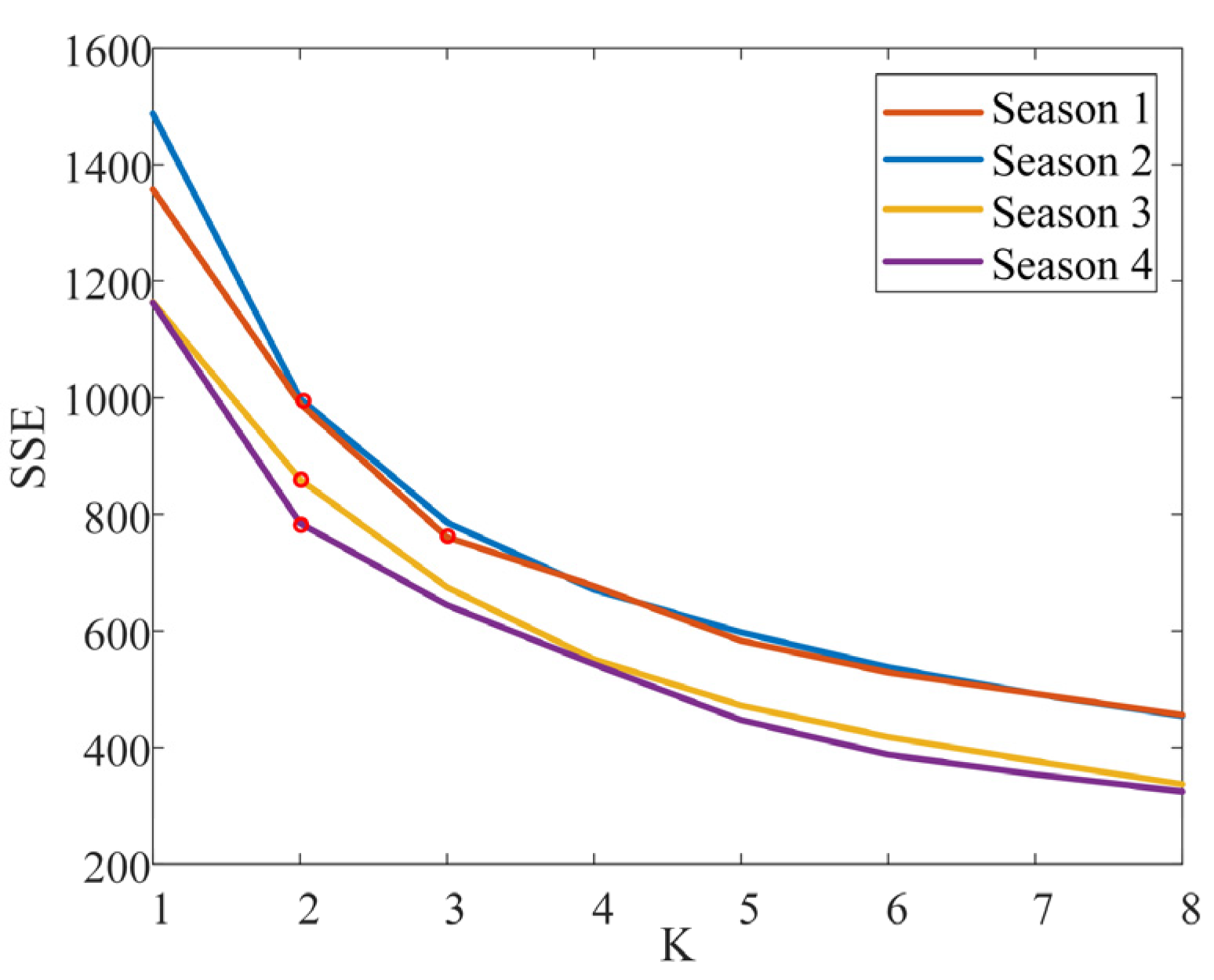
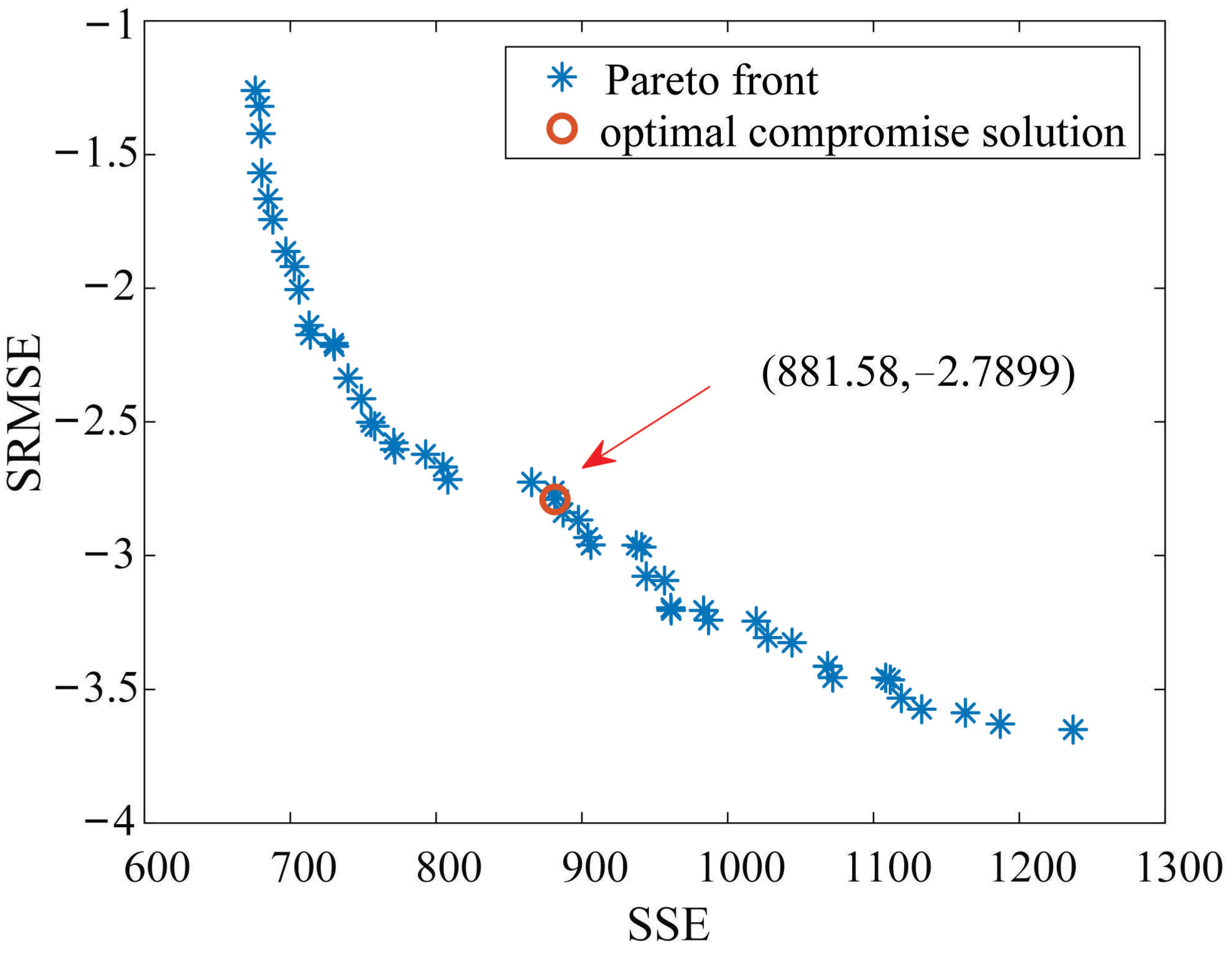
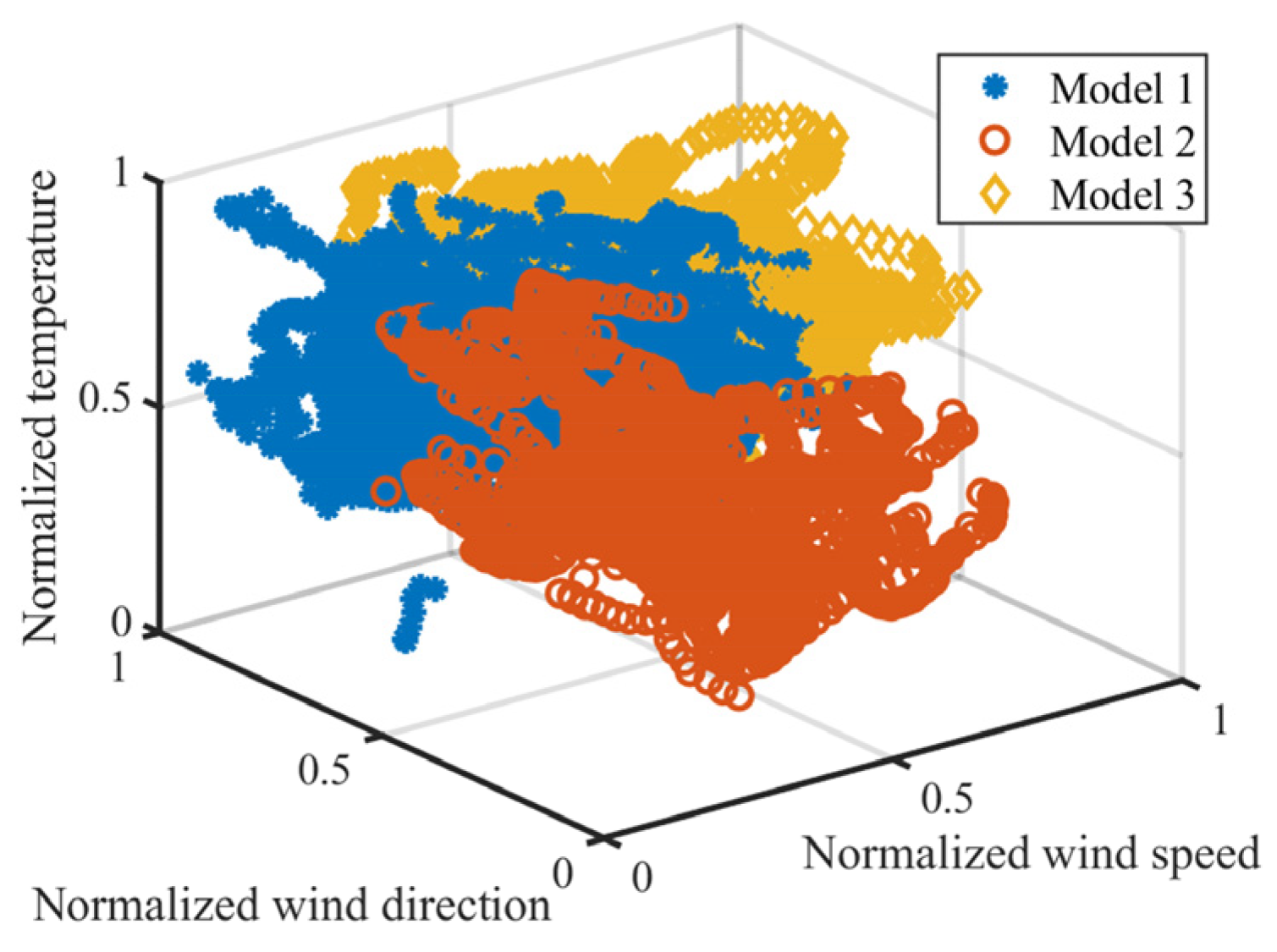
6.1. Multi-Objective Clustering Results
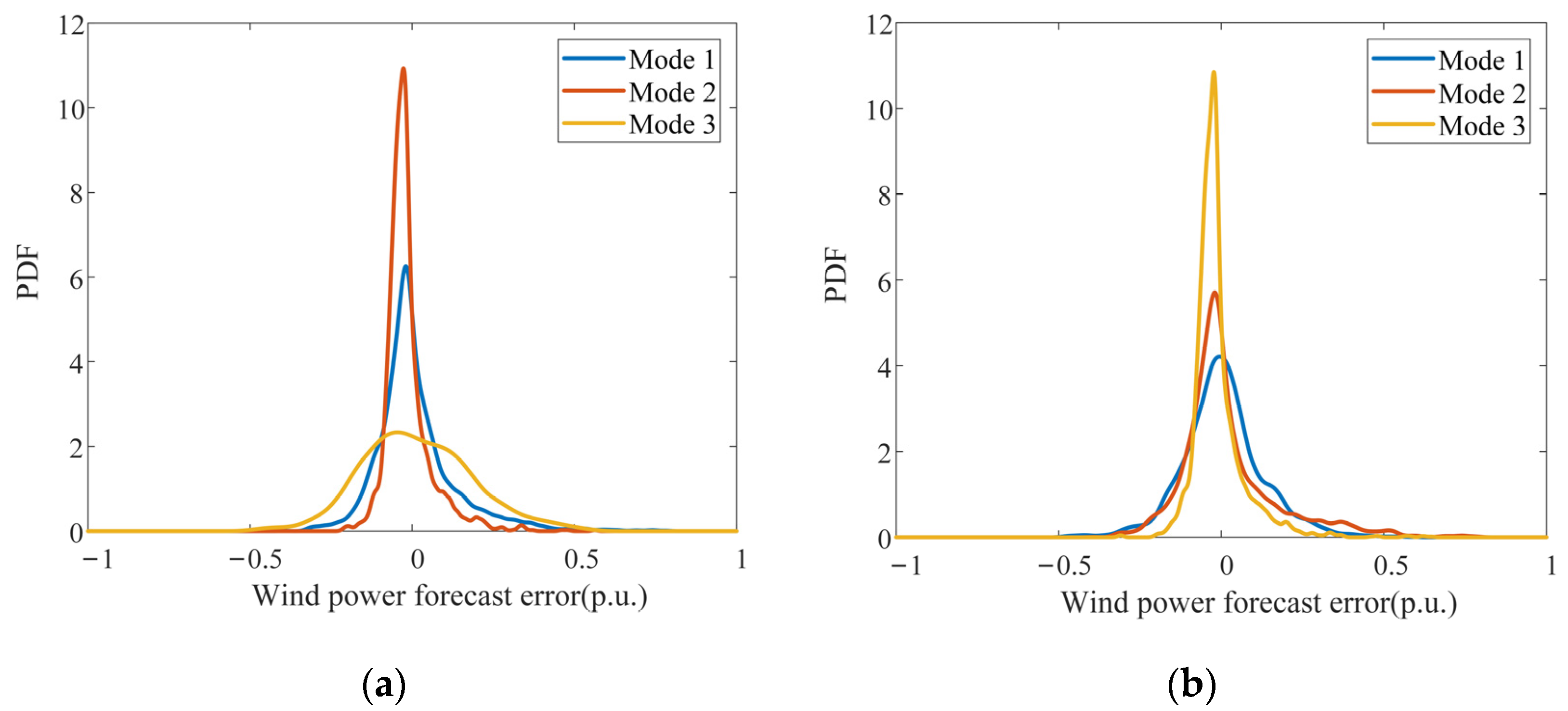
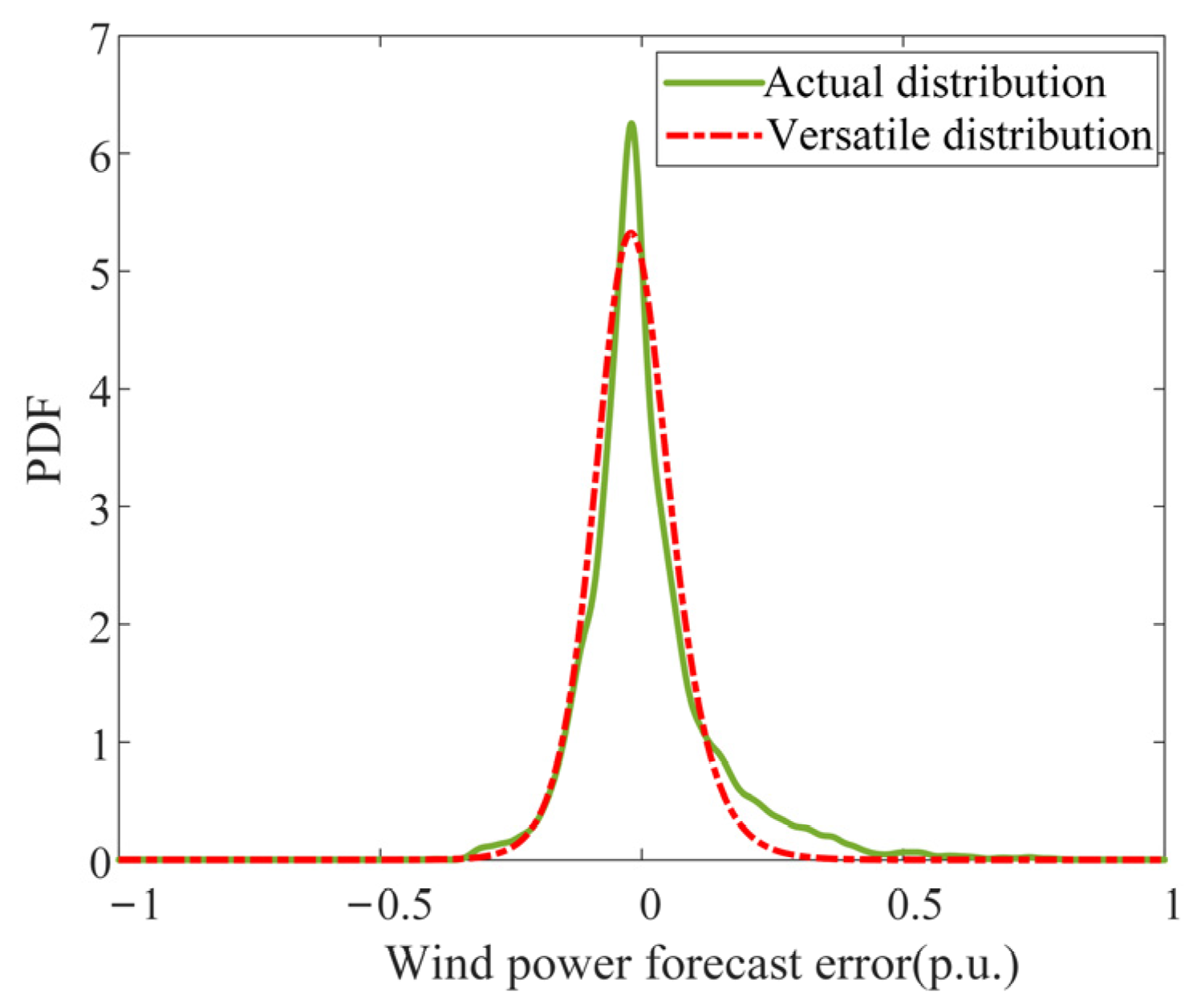
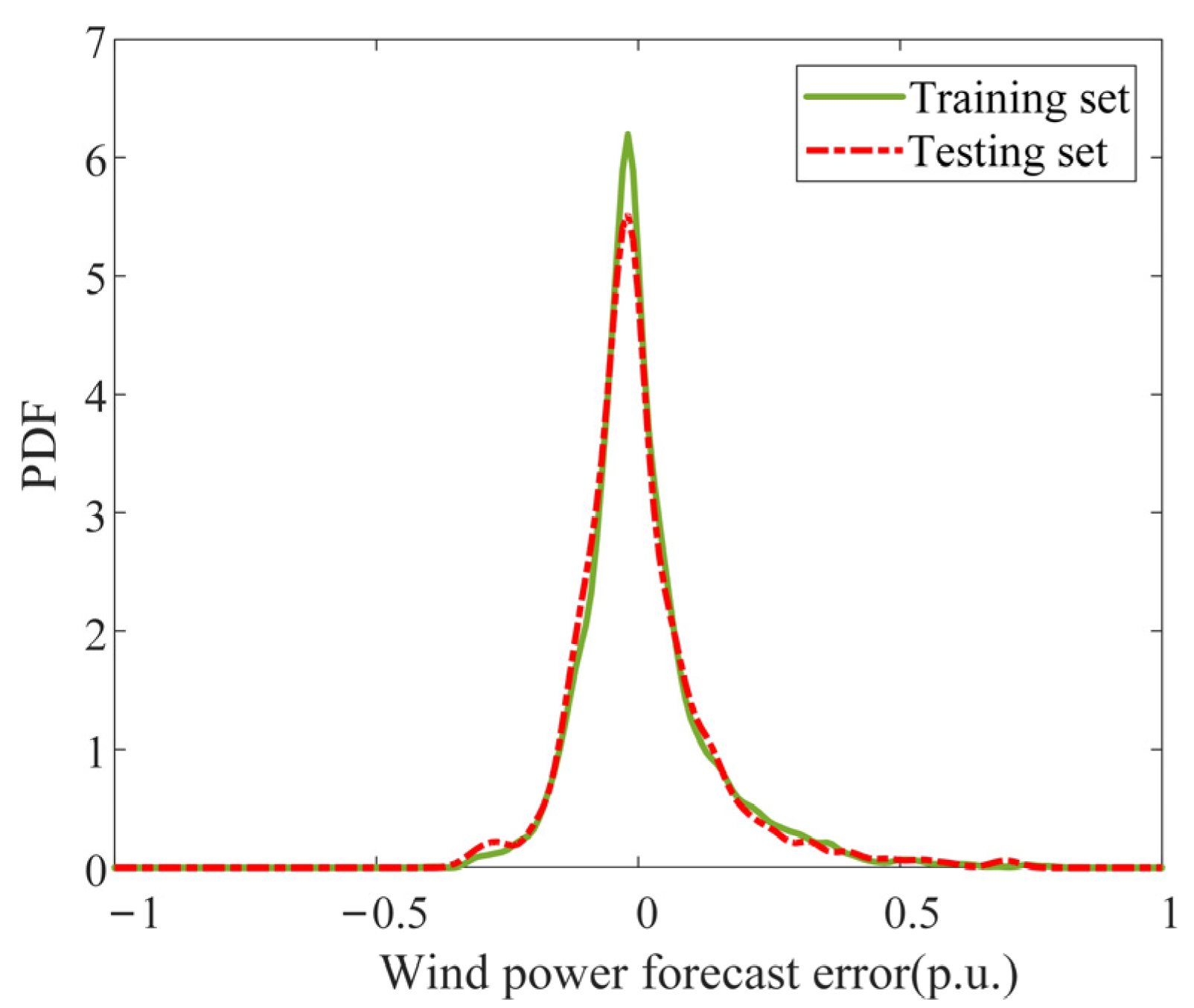
6.2. Results of Probability Distribution Modeling
6.3. Verification of MDIF Mode Recognition
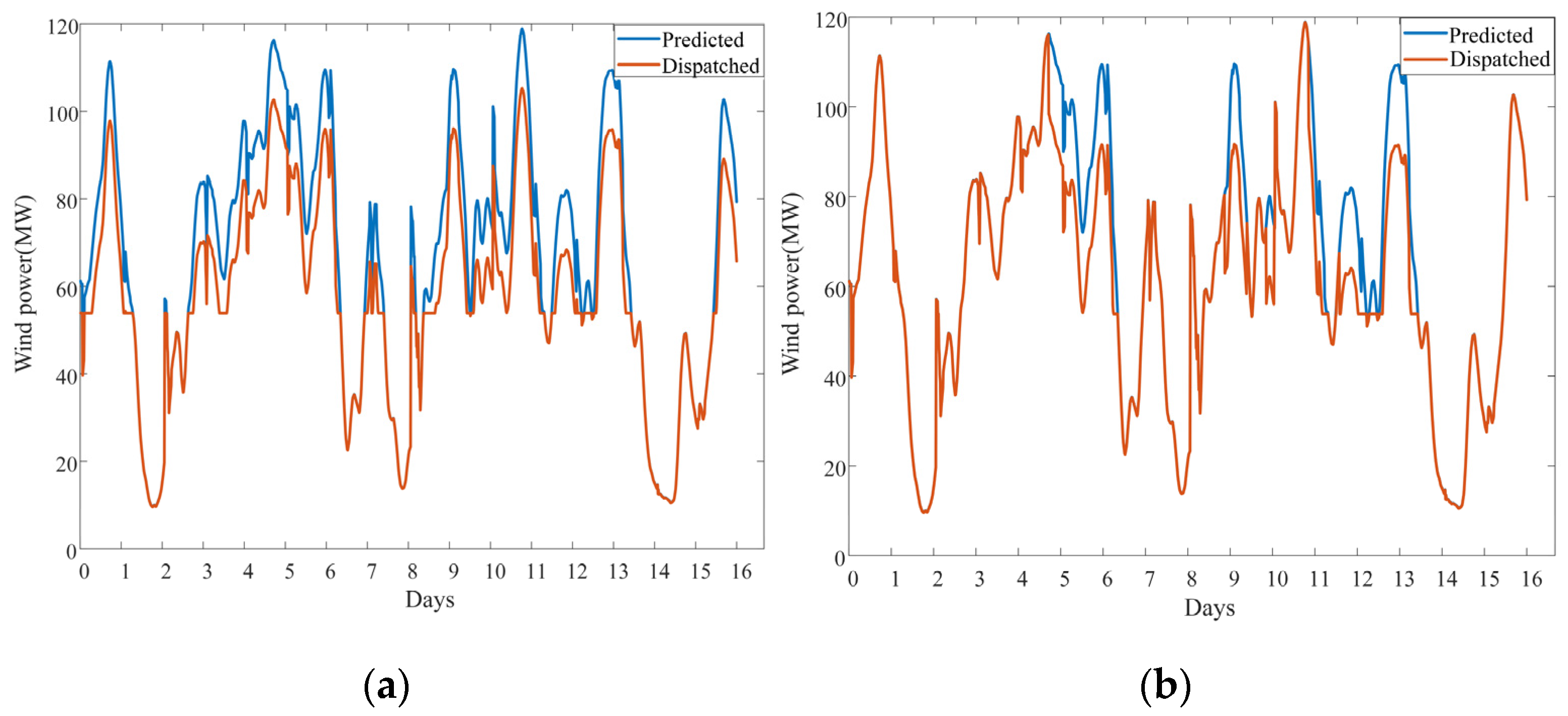
6.4. Application in SED Problems
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| VMD | Variational mode decomposition |
| LSTM | Long short-term memory network |
| EMD | Empirical mode decomposition |
| SWD | Stationary wavelet decomposition |
| ANFIS | Artificial neuro-fuzzy inference system |
| ANN | Artificial neural network |
| SVR | Support vector regression |
| WPFE | Wind power forecast error |
| MDIF | Multi-dimensional influencing factors |
| SVM | Support vector machine |
| NWP | Numerical weather prediction |
| Probability density function | |
| FWO | Forecast wind power output |
| SED | Stochastic economic dispatch |
| PAES | Pareto-archived evolution strategy |
| SPEA | Strength Pareto evolutionary algorithm |
| SSE | Square sum of error |
| SRMSE | Sum of root mean square error |
| RMSE | Root mean square error |
| KDE | Kernel density estimation |
| VC | Vapnik–Chervonenkis |
| SRM | Structure risk minimization principle |
| CDF | Cumulative distribution function |
| LLCR | Lower limit coverage rate |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Unit | Capacity | a ($/MW2) | b ($/MW) | c ($) | Minimum Output | Maximum Output |
|---|---|---|---|---|---|---|
| #1 1, #2, #3 | 100 MW | 0.053 | 42 | 781 | 100 MW | 35 MW |
| #4, #5, #6 | 80 MW | 0.014 | 43 | 212 | 80 MW | 28 MW |
References
- Jiang, R.; Wang, J.; Guan, Y. Robust Unit Commitment With Wind Power and Pumped Storage Hydro. IEEE Trans. Power Syst. 2012, 27, 800–810. [Google Scholar] [CrossRef]
- Bertsimas, D.; Litvinov, E.; Sun, X.A.; Zhao, J.; Zheng, T. Adaptive Robust Optimization for the Security Constrained Unit Commitment Problem. IEEE Trans. Power Syst. 2013, 28, 52–63. [Google Scholar] [CrossRef]
- Dvorkin, Y.; Lubin, M.; Backhaus, S.; Chertkov, M. Uncertainty Sets for Wind Power Generation. IEEE Trans. Power Syst. 2016, 31, 3326–3327. [Google Scholar] [CrossRef] [Green Version]
- Yu, H.; Chung, C.Y.; Wong, K.P.; Zhang, J.H. A Chance Constrained Transmission Network Expansion Planning Method With Consideration of Load and Wind Farm Uncertainties. IEEE Trans. Power Syst. 2009, 24, 1568–1576. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, N.; Kang, C.; Miao, M.; Shi, R.; Xia, Q. An Efficient Approach to Power System Uncertainty Analysis With High-Dimensional Dependencies. IEEE Trans. Power Syst. 2018, 33, 2984–2994. [Google Scholar] [CrossRef]
- Le, X.; Yingzhong, G.; Xinxin, Z.; Genton, M. Short-term spatio-temporal wind power forecast in robust look-ahead power system dispatch. In Proceedings of the 2016 IEEE Power and Energy Society General Meeting (PESGM), Boston, MA, USA, 17–21 July 2016. [Google Scholar] [CrossRef]
- Li, Y.; Wang, Y.; Wu, B. Short-Term Direct Probability Prediction Model of Wind Power Based on Improved Natural Gradient Boosting. Energies 2020, 13, 4629. [Google Scholar] [CrossRef]
- Buhan, S.; Özkazanç, Y.; Çadırcı, I. Wind Pattern Recognition and Reference Wind Mast Data Correlations With NWP for Improved Wind-Electric Power Forecasts. IEEE Trans. Ind. Inform. 2016, 12, 991–1004. [Google Scholar] [CrossRef]
- Tascikaraoglu, A.; Uzunoglu, M. A review of combined approaches for prediction of short-term wind speed and power. Renew. Sustain. Energy Rev. 2014, 34, 243–254. [Google Scholar] [CrossRef]
- Jung, J.; Broadwater, R.P. Current status and future advances for wind speed and power forecasting. Renew. Sustain. Energy Rev. 2014, 31, 762–777. [Google Scholar] [CrossRef]
- Wang, J.; Hu, J.; Ma, K.; Zhang, Y. A self-adaptive hybrid approach for wind speed forecasting. Renew. Energy 2015, 78, 374–385. [Google Scholar] [CrossRef]
- Li, D.; Yan, W.; Li, W.; Ren, Z. A Two-Tier Wind Power Time Series Model Considering Day-to-Day Weather Transition and Intraday Wind Power Fluctuations. IEEE Trans. Power Syst. 2016, 31, 4330–4339. [Google Scholar] [CrossRef]
- Shi, Z.; Liang, H.; Dinavahi, V. Direct Interval Forecast of Uncertain Wind Power Based on Recurrent Neural Networks. IEEE Trans. Sustain. Energy 2018, 9, 1177–1187. [Google Scholar] [CrossRef]
- Han, L.; Zhang, R.; Wang, X.; Bao, A.; Jing, H. Multi-step wind power forecast based on VMD-LSTM. IET Renew. Power Gener. 2019, 13, 1690–1700. [Google Scholar] [CrossRef]
- Cevik, H.H.; Cunka, M.; Polat, K. A new multistage short-term wind power forecast model using decomposition and artificial intelligence methods. Phys. A Stat. Mech. Appl. 2019, 534, 122177. [Google Scholar] [CrossRef]
- Bibi, N.; Shah, I.; Alsubie, A.; Ali, S.; Lone, S.A. Electricity Spot Prices Forecasting Based on Ensemble Learning. IEEE Access 2021, 9, 150984–150992. [Google Scholar] [CrossRef]
- Lisi, F.; Shah, I. Forecasting next-day electricity demand and prices based on functional models. Energy Syst. 2020, 11, 947–979. [Google Scholar] [CrossRef]
- Shah, I.; Lisi, F. Day-Ahead Electricity Demand Forecasting with Nonparametric Functional Models. In Proceedings of the 12th International Conference on the European Energy Market, EEM 2015, Lisbon, Portugal, 19–22 May 2015; IEEE Computer Society: Lisbon, Portugal, 2015; pp. 1–5. [Google Scholar] [CrossRef]
- Shah, I.; Lisi, F. Forecasting of electricity price through a functional prediction of sale and purchase curves. J. Forecast. 2020, 39, 242–259. [Google Scholar] [CrossRef]
- Liu, R.; Peng, M.; Xiao, X. Ultra-Short-Term Wind Power Prediction Based on Multivariate Phase Space Reconstruction and Multivariate Linear Regression. Energies 2018, 11, 2763. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Wang, J.; Wang, X. Review on probabilistic forecasting of wind power generation. Renew. Sustain. Energy Rev. 2014, 32, 255–270. [Google Scholar] [CrossRef]
- Shouman, N.; Hegazy, Y.G.; Omran, W.A. Hybrid Mean Variance Mapping Optimization Algorithm for Solving Stochastic Based Dynamic Economic Dispatch Incorporating Wind Power Uncertainty. Electr. Power Compon. Syst. 2021, 48, 1786–1797. [Google Scholar] [CrossRef]
- Hu, Z.; Xu, Y.; Korkali, M.; Chen, X.; Mili, L.; Valinejad, J. A Bayesian Approach for Estimating Uncertainty in Stochastic Economic Dispatch Considering Wind Power Penetration. IEEE Trans. Sustain. Energy 2021, 12, 671–681. [Google Scholar] [CrossRef]
- Wang, X.; Liu, R.-P.; Wang, X.; Hou, Y.; Bouffard, F. A Data-Driven Uncertainty Quantification Method for Stochastic Economic Dispatch. IEEE Trans. Power Syst. 2022, 37, 812–815. [Google Scholar] [CrossRef]
- Zeng, L.; Xu, J.; Liu, Y.; Li, C.; Wu, M.; Wen, M.; Xiao, H. Stochastic economic dispatch strategy based on quantile regression. Int. J. Electr. Power Energy Syst. 2022, 134, 107363. [Google Scholar] [CrossRef]
- Tang, C.; Xu, J.; Sun, Y.; Liu, J.; Ma, X.; Jiang, H. Stochastic dynamic economic dispatch with multiple wind farms based on wind power conditional distribution models. In Proceedings of the 2017 IEEE Power and Energy Society General Meeting, PESGM 2017, Chicago, IL, USA, 16–20 July 2017; IEEE Computer Society: Chicago, IL, USA, 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Bludszuweit, H.; Dominguez-Navarro, J.A.; Llombart, A. Statistical analysis of wind power forecast error. IEEE Trans. Power Syst. 2008, 23, 983–991. [Google Scholar] [CrossRef]
- Ge, F.; Ju, Y.; Qi, Z.; Lin, Y. Parameter estimation of a Gaussian mixture model for wind power forecast error by riemann L-BFGS optimization. IEEE Access 2018, 6, 38892–38899. [Google Scholar] [CrossRef]
- Yu, Y.; Yang, M.; Han, X.; Zhang, Y.; Ye, P. A Regional Wind Power Probabilistic Forecast Method Based on Deep Quantile Regression. IEEE Trans. Ind. Appl. 2021, 57, 4420–4427. [Google Scholar] [CrossRef]
- Zhou, Y.; Sun, Y.; Wang, S.; Mahfoud, R.J.; Alhelou, H.H.; Hatziargyriou, N.; Siano, P. Performance Improvement of Very Short-term Prediction Intervals for Regional Wind Power Based on Composite Conditional Nonlinear Quantile Regression. J. Mod. Power Syst. Clean Energy 2022, 10, 60–70. [Google Scholar] [CrossRef]
- Dong, W.; Sun, H.; Tan, J.; Li, Z.; Zhang, J.; Yang, H. Regional wind power probabilistic forecasting based on an improved kernel density estimation, regular vine copulas, and ensemble learning. Energy 2022, 238, 122045. [Google Scholar] [CrossRef]
- Yang, X.; Ma, X.; Kang, N.; Maihemuti, M. Probability Interval Prediction of Wind Power Based on KDE Method with Rough Sets and Weighted Markov Chain. IEEE Access 2018, 6, 51556–51565. [Google Scholar] [CrossRef]
- Wang, J.; Niu, T.; Lu, H.; Yang, W.; Du, P. A Novel Framework of Reservoir Computing for Deterministic and Probabilistic Wind Power Forecasting. IEEE Trans. Sustain. Energy 2020, 11, 337–349. [Google Scholar] [CrossRef]
- Lin, Y.; Yang, M.; Wan, C.; Wang, J.; Song, Y. A Multi-Model Combination Approach for Probabilistic Wind Power Forecasting. IEEE Trans. Sustain. Energy 2019, 10, 226–237. [Google Scholar] [CrossRef]
- Bruninx, K.; Delarue, E. A Statistical Description of the Error on Wind Power Forecasts for Probabilistic Reserve Sizing. IEEE Trans. Sustain. Energy 2014, 5, 995–1002. [Google Scholar] [CrossRef]
- Zhang, Z.; Sun, Y.; Gao, D.W.; Lin, J.; Cheng, L. A Versatile Probability Distribution Model for Wind Power Forecast Errors and Its Application in Economic Dispatch. IEEE Trans. Power Syst. 2013, 28, 3114–3125. [Google Scholar] [CrossRef]
- Jia, M.; Shen, C.; Wang, Z. A Distributed Probabilistic Modeling Algorithm for the Aggregated Power Forecast Error of Multiple Newly Built Wind Farms. IEEE Trans. Sustain. Energy 2019, 10, 1857–1866. [Google Scholar] [CrossRef]
- Tang, C.; Xu, J.; Sun, Y.; Liu, J.; Li, X.; Ke, D.; Yang, J.; Peng, X. Look-Ahead Economic Dispatch With Adjustable Confidence Interval Based on a Truncated Versatile Distribution Model for Wind Power. IEEE Trans. Power Syst. 2018, 33, 1755–1767. [Google Scholar] [CrossRef]
- Gómez-Lázaro, E.; Bueso, M.C.; Kessler, M.; Martín-Martínez, S.; Zhang, J.; Hodge, B.-M.; Molina-García, A. Probability Density Function Characterization for Aggregated Large-Scale Wind Power Based on Weibull Mixtures. Energies 2016, 9, 91. [Google Scholar] [CrossRef] [Green Version]
- Pinson, P.; Kariniotakis, G. Conditional Prediction Intervals of Wind Power Generation. IEEE Trans. Power Syst. 2010, 25, 1845–1856. [Google Scholar] [CrossRef] [Green Version]
- Zhang, N.; Kang, C.; Xia, Q.; Liang, J. Modeling Conditional Forecast Error for Wind Power in Generation Scheduling. IEEE Trans. Power Syst. 2014, 29, 1316–1324. [Google Scholar] [CrossRef]
- Wang, Z.; Shen, C.; Liu, F. A conditional model of wind power forecast errors and its application in scenario generation. Appl. Energy 2018, 212, 771–785. [Google Scholar] [CrossRef] [Green Version]
- Ela, E.; O’Malley, M. Studying the Variability and Uncertainty Impacts of Variable Generation at Multiple Timescales. IEEE Trans. Power Syst. 2012, 27, 1324–1333. [Google Scholar] [CrossRef] [Green Version]
- Khorramdel, B.; Chung, C.Y.; Safari, N.; Price, G.C.D. A Fuzzy Adaptive Probabilistic Wind Power Prediction Framework Using Diffusion Kernel Density Estimators. IEEE Trans. Power Syst. 2018, 33, 7109–7121. [Google Scholar] [CrossRef]
- Sorensen, P.; Cutululis, N.A.; Vigueras-Rodriguez, A.; Madsen, H.; Pinson, P.; Jensen, L.E.; Hjerrild, J.; Donovan, M. Modelling of power fluctuations from large offshore wind farms. Wind Energy 2008, 11, 29–43. [Google Scholar] [CrossRef]
- Xie, W.; Zhang, P.; Chen, R.; Zhou, Z. A Nonparametric Bayesian Framework for Short-Term Wind Power Probabilistic Forecast. IEEE Trans. Power Syst. 2019, 34, 371–379. [Google Scholar] [CrossRef]
- Su, X.; Masoum, M.A.S.; Wolfs, P.J. Optimal PV Inverter Reactive Power Control and Real Power Curtailment to Improve Performance of Unbalanced Four-Wire LV Distribution Networks. IEEE Trans. Sustain. Energy 2014, 5, 967–977. [Google Scholar] [CrossRef]
- Wu, X.; Shi, W.; Du, J. Multi-Objective Optimal Charging Method for Lithium-Ion Batteries. Energies 2017, 10, 1271. [Google Scholar] [CrossRef]
- Mostafa, H.A.; El-Shatshat, R.; Salama, M.M.A. Multi-Objective Optimization for the Operation of an Electric Distribution System With a Large Number of Single Phase Solar Generators. IEEE Trans. Smart Grid 2013, 4, 1038–1047. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Lotfan, S.; Ghiasi, R.A.; Fallah, M.; Sadeghi, M.H. ANN-based modeling and reducing dual-fuel engine’s challenging emissions by multi-objective evolutionary algorithm NSGA-II. Appl. Energy 2016, 175, 91–99. [Google Scholar] [CrossRef]
- Chen, N.; Qian, Z.; Nabney, I.T.; Meng, X. Wind Power Forecasts Using Gaussian Processes and Numerical Weather Prediction. IEEE Trans. Power Syst. 2014, 29, 656–665. [Google Scholar] [CrossRef] [Green Version]
- Zhou, B.; Ma, X.; Luo, Y.; Yang, D. Wind Power Prediction Based on LSTM Networks and Nonparametric Kernel Density Estimation. IEEE Access 2019, 7, 165279–165292. [Google Scholar] [CrossRef]
- Nepal, B.; Yamaha, M.; Sahashi, H.; Yokoe, A. Analysis of Building Electricity Use Pattern Using K-Means Clustering Algorithm by Determination of Better Initial Centroids and Number of Clusters. Energies 2019, 12, 2451. [Google Scholar] [CrossRef] [Green Version]
- Hernández, L.; Baladrón, C.; Aguiar, J.M.; Carro, B.; Sánchez-Esguevillas, A. Classification and Clustering of Electricity Demand Patterns in Industrial Parks. Energies 2012, 5, 5215–5228. [Google Scholar] [CrossRef] [Green Version]
- Hanyang, Z.; Xin, S.; Zhenguo, Y. Vessel Sailing Patterns Analysis from S-AIS Data Dased on K-means Clustering Algorithm. In Proceedings of the 2019 IEEE 4th International Conference on Big Data Analytics (ICBDA), Suzhou, China, 15–18 March 2019; IEEE: Piscataway, NY, USA, 2019; pp. 10–13. [Google Scholar] [CrossRef]
- Aksan, F.; Jasiński, M.; Sikorski, T.; Kaczorowska, D.; Rezmer, J.; Suresh, V.; Leonowicz, Z.; Kostyła, P.; Szymańda, J.; Janik, P. Clustering Methods for Power Quality Measurements in Virtual Power Plant. Energies 2021, 14, 5902. [Google Scholar] [CrossRef]
- Tewari, S.; Geyer, C.J.; Mohan, N. A Statistical Model for Wind Power Forecast Error and its Application to the Estimation of Penalties in Liberalized Markets. IEEE Trans. Power Syst. 2011, 26, 2031–2039. [Google Scholar] [CrossRef]
- Huang, S.; Sun, Y.; Wu, Q. Stochastic Economic Dispatch With Wind Using Versatile Probability Distribution and L-BFGS-B Based Dual Decomposition. IEEE Trans. Power Syst. 2018, 33, 6254–6263. [Google Scholar] [CrossRef]
- Zhang, Q.; Lai, K.K.; Niu, D.; Wang, Q.; Zhang, X. A Fuzzy Group Forecasting Model Based on Least Squares Support Vector Machine (LS-SVM) for Short-Term Wind Power. Energies 2012, 5, 3329–3346. [Google Scholar] [CrossRef]
- Ibrahim, A.; Anayi, F.; Packianather, M.; Alomari, O.A. New Hybrid Invasive Weed Optimization and Machine Learning Approach for Fault Detection. Energies 2022, 15, 1488. [Google Scholar] [CrossRef]
- De Giorgi, M.G.; Campilongo, S.; Ficarella, A.; Congedo, P.M. Comparison Between Wind Power Prediction Models Based on Wavelet Decomposition with Least-Squares Support Vector Machine (LS-SVM) and Artificial Neural Network (ANN). Energies 2014, 7, 5251–5272. [Google Scholar] [CrossRef]
- Chih-Wei, H.; Chih-Jen, L. A comparison of methods for multiclass support vector machines. IEEE Trans. Neural Netw. 2002, 13, 415–425. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Wang, R.; Zeng, Y.S. An Improvement of One-Against-One Method for Multi-Class Support Vector Machine. In Proceedings of the 2007 International Conference on Machine Learning and Cybernetics, Hong Kong, China, 19–22 August 2007; IEEE: Piscataway, NY, USA, 2007; pp. 2915–2920. [Google Scholar] [CrossRef]
- Taijia, X.; Dong, R.; Shuanghui, L.; Junqiao, Z.; Xiaobo, L. Based on grid-search and PSO parameter optimization for Support Vector Machine. In Proceedings of the 11th World Congress on Intelligent Control and Automation, Shenyang, China, 29 June–4 July 2014; IEEE: Piscataway, NY, USA, 2014; pp. 1529–1533. [Google Scholar] [CrossRef]
- Lin, J.; Zhang, J. A Fast Parameters Selection Method of Support Vector Machine Based on Coarse Grid Search and Pattern Search. In Proceedings of the 2013 Fourth Global Congress on Intelligent Systems, Hong Kong, China, 3–4 December 2013; IEEE: Piscataway, NY, USA, 2013; pp. 77–81. [Google Scholar] [CrossRef]











| Season | MNSGA-II-Kmeans | Kmeans | |
|---|---|---|---|
| 1 | NK | 78.02% | 57.78% |
| SRMSE | 2.7899 | 2.0424 | |
| SSE | 881.58 | 805.83 | |
| 2 | NK | 61.90% | 24.32% |
| SRMSE | 0.6715 | 0.4967 | |
| SSE | 1215.08 | 999.08 | |
| 3 | NK | 76.22% | 43.62% |
| SRMSE | 0.5396 | 0.5269 | |
| SSE | 1037.80 | 890.99 | |
| 4 | NK | 65.35% | 47.74% |
| SRMSE | 0.4617 | 0.4133 | |
| SSE | 852.44 | 785.04 | |
| MDIF Mode | RMSE | |||||
|---|---|---|---|---|---|---|
| Season 1 | Mode 1 | 19.92 | 1.267 | −0.0326 | 0.9596 | 0.2341 |
| Mode 2 | 38.24 | 1.503 | −0.0449 | 0.9755 | 0.2680 | |
| Mode 3 | 7.674 | 2.651 | −0.149 | 0.9945 | 0.0564 | |
| Season 2 | Mode 1 | 15.85 | 1.559 | −0.0603 | 0.9637 | 0.2035 |
| Mode 2 | 10.42 | 0.6278 | 0.1062 | 0.9854 | 0.0870 | |
| Season 3 | Mode 1 | 15.06 | 1.859 | −0.0477 | 0.9645 | 0.2834 |
| Mode 2 | 11.68 | 0.5874 | 0.0964 | 0.9846 | 0.0906 | |
| Season 4 | Mode 1 | 10.52 | 1.562 | −0.0492 | 0.9289 | 0.2185 |
| Mode 2 | 8.48 | 0.5528 | 0.0974 | 0.9697 | 0.1036 | |
| Season | Accuracy (Optimized) | Accuracy (Verified) | ||
|---|---|---|---|---|
| 1 | 90.5097 | 0.1768 | 99.55% | 99.83% |
| 2 | 128 | 0.5000 | 99.72% | 99.89% |
| 3 | 90.5097 | 0.3536 | 99.70% | 99.48% |
| 4 | 16 | 0.1250 | 99.81% | 99.59% |
| Probability Model of WPFE Used | System Wind Power Consumption (MWh) | LLCR |
|---|---|---|
| Non-conditional | 22,370.23 | 98.50% |
| Proposed multi-dimensional conditional | 23,765.15 | 96.09% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.; Liu, Y.; Jiang, S.; Luo, Y.; Liu, N.; Ke, D. A Method of Probability Distribution Modeling of Multi-Dimensional Conditions for Wind Power Forecast Error Based on MNSGA-II-Kmeans. Energies 2022, 15, 2462. https://doi.org/10.3390/en15072462
Yang J, Liu Y, Jiang S, Luo Y, Liu N, Ke D. A Method of Probability Distribution Modeling of Multi-Dimensional Conditions for Wind Power Forecast Error Based on MNSGA-II-Kmeans. Energies. 2022; 15(7):2462. https://doi.org/10.3390/en15072462
Chicago/Turabian StyleYang, Jian, Yu Liu, Shangguang Jiang, Yazhou Luo, Nianzhang Liu, and Deping Ke. 2022. "A Method of Probability Distribution Modeling of Multi-Dimensional Conditions for Wind Power Forecast Error Based on MNSGA-II-Kmeans" Energies 15, no. 7: 2462. https://doi.org/10.3390/en15072462
APA StyleYang, J., Liu, Y., Jiang, S., Luo, Y., Liu, N., & Ke, D. (2022). A Method of Probability Distribution Modeling of Multi-Dimensional Conditions for Wind Power Forecast Error Based on MNSGA-II-Kmeans. Energies, 15(7), 2462. https://doi.org/10.3390/en15072462