1. Introduction
In the last decades, the greenhouse effect has gradually become a global issue [
1], and higher thermal efficiency and lower emission output have become the primary goals for the development of modern internal combustion engines. Correspondingly, emission regulations are becoming increasingly stringent to reduce emissions in the transportation section of each country [
2,
3]. Automotive manufacturers need to meet these regulations under complex transient test conditions, and to minimize vehicle emissions. In fact, there is a significant difference between the steady-state test and transient test of engine emission performance [
4]. Steady-state data usually means the average output value of the engine over a period. Due to the low time resolution of conventional emission analyzers, the results of steady-state experiments normally cannot compare with real-time engine performance. Fast response emissions analyzers can collect transient data to measure emissions variations under transient operating conditions such as engine start/stop and acceleration/deceleration. Transient operating conditions normally represent the real engine working conditions, sometimes with an extremely high-resolution ratio. Therefore, as an assessment tool, an accurate engine emission prediction model, which can be applied to evaluate the engine transient emission performance, is critical for engine control and calibration.
In view of the deficiency of online NOx monitoring equipment in practical application, CFD (Computational Fluid Dynamics) simulations [
5,
6,
7] are commonly used to predict NOx emissions and have been applied to optimize the engine control strategies in the past. However, for real-time forecasting demand, CFD is not applicable due to its high computational cost, high calibration requirements, complex structure [
8,
9,
10,
11] and poor adaptability to different engines. Considering the high dimensional engine control MAPs and lookup tables which are embedded in the engine ECU system, the number of experiments required is exponential, which leads to excessive cost. Recently, Acritical Intelligent (AI) methodologies have been widely considered as promising tools for engine performance calibration, especially for engine emission performance prediction and optimization. Liu et al. [
12] combined a data preprocessing and long and short-term memory (LSTM) model [
13] to estimate numerical emission predictions under unsteady conditions with acceptable accuracy. Kiyas et al. [
14] modeled combustion efficiency and exhaust emission indexes for a turbocharged engine with an LSTM model. Halil et al. [
15] compared a Deep Neural Network (DNN) to a traditional artificial neural network (ANN) [
16,
17,
18] method regarding the emission prediction ability. The results showed that the performance of the DNN model was much better than the traditional ANN model with a lower relative error. However, the above models are only applicable to single time-step emission prediction, and their multi- time-step forecasting performances are limited.
To achieve a high-precision engine control and calibration method, predicting long time step emission sequences is required [
19]. Emission prediction can be viewed as a time series forecasting problem and a long sequence time-series forecasting problems. In the last decade, performance degradation has proved to be the major limitation of the LSTM model due to gradient disappearance [
20]. On the other hand, the Transformer model [
21] has made breakthroughs in sequence events prediction [
22,
23]. However, both models ignore the interconnection between multivariate time series and cannot capture the information of high frequency variation characteristics. In addition, the quadratic computation process for solving the self-attention mechanism leads to a further limitation of the transformer model when predicting a long sequence [
24]. The potential solution for handling the above issue is a graph neural network (GNN) model [
25], since it enhances the spatial modeling and spatiotemporal feature extraction ability. GNN is based on the graph convolution structure, which has the possibility to avoid the gradient disappearance problem.
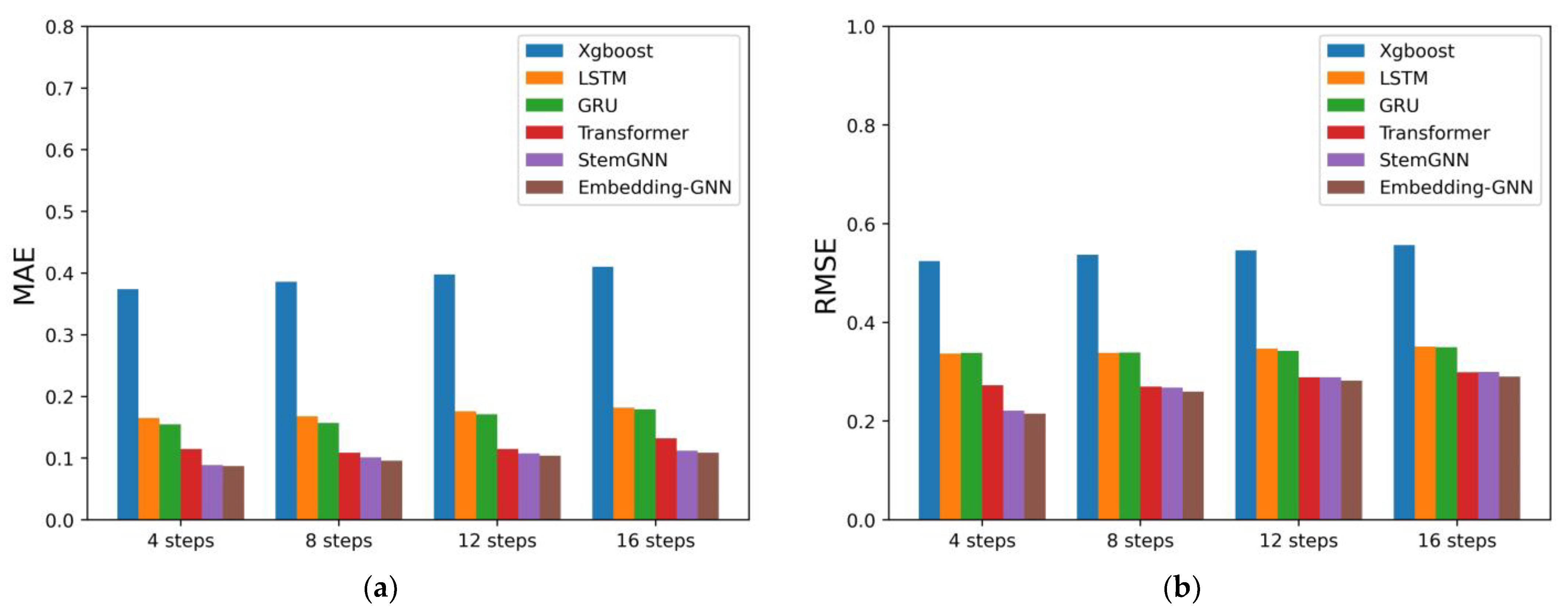
Based on the above analysis, the main purpose of this study was to create a general method for engine NOx emission prediction with high prediction accuracy. We propose a novel graph neural network model based on dimensional embedding algorithm (EGNN), and the performance of this model is and conventional GNN model. The results show that the present EGNN model yields higher accuracy and better performance. A fast emissions analyzer is utilized in this study for data acquisition. Compared with the steady-state emission meter, fast emissions analyzers can obtain more data in a given time period and save the experimental cost.
To achieve such a goal, the main tasks of this work can be described as follows:
- (1)
First, attaching a multi-dimensional variable encoding layer to the attention map learning layer. Since there are signal characteristic differences between different sensors such as data accuracy, digital resolution and signal drifting level, an encoder layer is applied to deal with these differences and embed them into the network as a new data feature. In addition, the application of the encoding layer guarantees the EGNN model a better anti-noise performance comparing to other models.
- (2)
Second, a sparse attention method is coupled with the self-attention graph generation mechanism to convert the high-dimensional graph relationships into low-dimensional ones, thereby the reduction of model inputs and memory overhead becomes possible [
26]. In addition, the proposed attention mechanism provides the ability to accurately predict the long-time step sequence. Compared with the traditional GNN, the self-attention mechanism generates a graph structure automatically, which saves the process of manually finding the relationship between variables.
- (3)
To improve the data accuracy, transient emitters are applied in the EGNN model rather than those steady emitters. Hence, the time cost can be significantly reduced when large dataset being processed.
The article is organized as follows. The related work is presented in
Section 2. The structure of the proposed method is introduced in
Section 3. In
Section 4, the basic parameters of the engine, the bench test process and the method of data preprocessing, are described. We compare the proposed method with five other models in
Section 5, and the paper is concluded in
Section 6.
2. Related Works
In this section, studies related to engine emission prediction based on machine learning methods in the past 3 years are summarized for better understanding the background of the present study.
Mohammad et al. [
27] utilized three machine learning methods to predict engine emissions, namely LSTM, ANN and random forest, and better results were achieved compared to traditional emission predicting methods. Aran et al. [
28] used principal component analysis (PCA) in an emission forecasting model to reduce the number of input variables. The results showed that the predicting performance of the model can be improved in a condition in which the computational budget is limited. On the other hand, Armin et al. [
29] studied the effect of different input variables on an SVM model under four different engine steady operating conditions. It was found that a model with multiple input variables yielded higher accuracy. Ma et al. [
30] combined ANN and a particle swarm optimization algorithm, and the engine fuel consumption and emission performance were well predicted. The above research mainly focused on steady-state conditions, and the methods used were mainly traditional ANN and machine learning models. Our paper considers both the engine steady-state and transient-state conditions.
Fang et al. [
31] applied a fast response emission analyzer in their study. The results showed that a transient model could be developed and the prediction of transient NOx emission became possible. To reduce the dimension of input variables in the emission predicating model, Nick et al. [
32] tested two filtering approaches, a
p-value test method, and a Pearson correlation coefficient method. Yu et al. [
33] combined LSTM and filtering methods to predict NOx emissions under engine transient conditions. Compared with the studies listed in the literature [
31,
32,
33], the major novelty of our paper is that for the first time, the possibility of modeling long-term emission sequence with fewer variables is demonstrated and verified, and the accuracy of the model developed in this work is significantly improved.
3. Research Methods
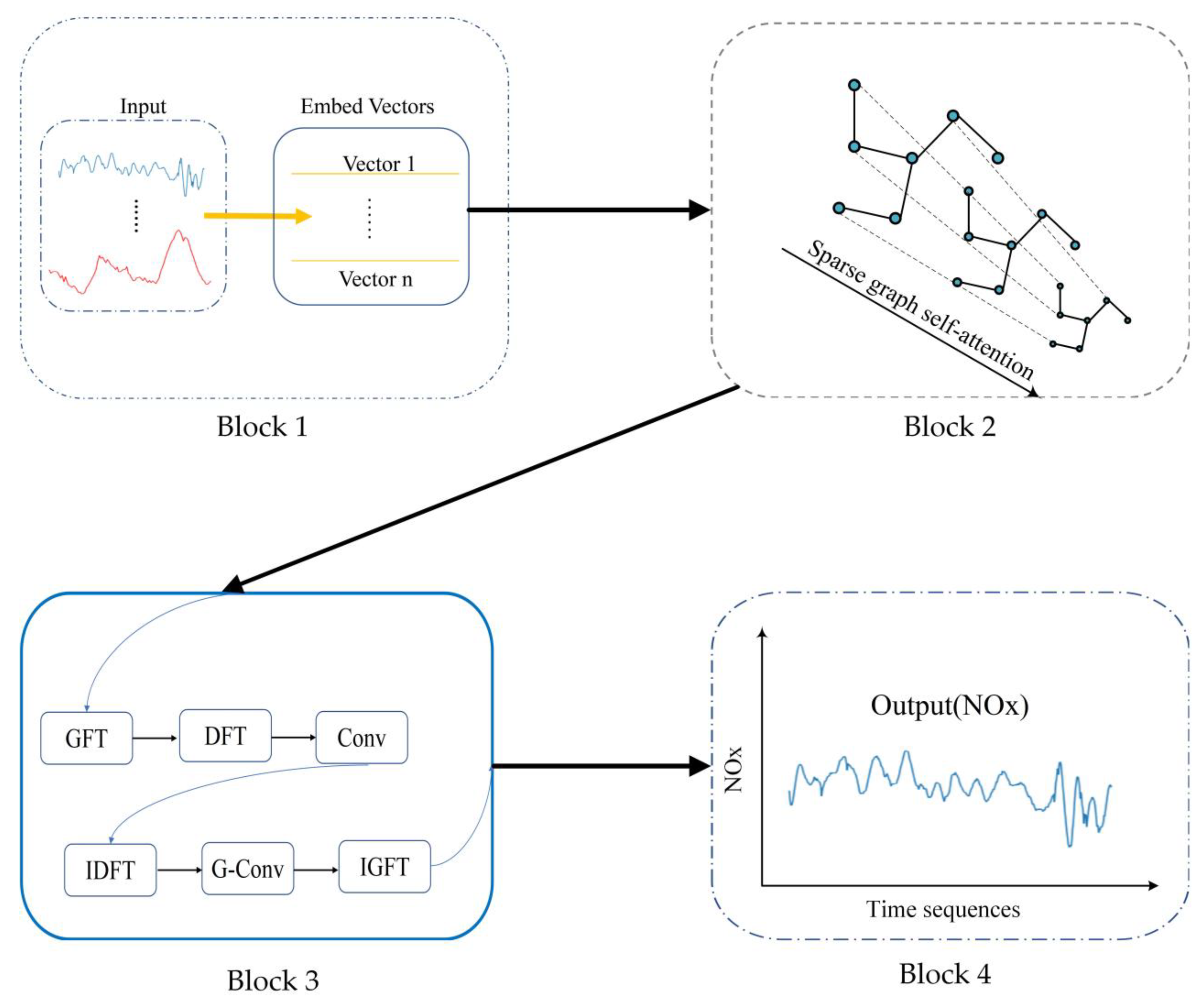
Figure 1 is a schematic diagram of our proposed structure, and involves four main blocks introduced in the following sections.
Multidimensional Variable Embedding (
Section 3.2): process the variables by the embedding method to learn the unique characteristics of sensors.
Sparse graph self-attention mechanism (
Section 3.3): develop a graph structure adaptively based on the improved self-graph-attention mechanism for the neural network.
Graph neural network based on Fourier transform (
Section 3.4): adopt spectrogram GNN to capture the relationship in the graph structure and complete the establishment of the emission prediction model.
Output block (
Section 3.4): output the prediction result of NOx.
3.1. Problem Definition
The NOx emission prediction is based on the time series of historical emission information to estimate the emission values in the future, which means the emission values of time
can be predicted at time t, where
denotes time interval between two points. To capture the relationship between multivariate variables and NOx, the data structure, multivariate graph shown in
Figure 2 is adopted.
We define the multivariate variables model as a graph
, where
X = {
x1, x2, ..., xN} is a finite set of
N nodes that represents multivariate variables and
xi where
T is the timestamp and m is the embedding dimension, which will beis explained in the
Section 3.3.
represents the adjacency matrix of graph
G.
With the input values of previous L time steps Xt−l, Xt−l+1, ..., Xt, our target is to predict the K time step values of the NOx emission. The prediction can be denoted by Xt+1, Xt+2, ..., Xt+h, and inferred by the deep learning model Y (G, Xt−l, Xt−l+1, ..., Xt).
3.2. Multidimensional Variable Embedding
Multidimensional variables represent multiple characteristic inputs to the model. Various sensors have their own unique characteristics in different stages and environments. At the same time, their initial noise values are different. To reduce the influence of hardware on the model’s prediction performance, we utilized an encoding method to generate feature vectors for multidimensional variables. Compared with the positional encoding in Transformer [
21], the embedding vectors provided to the input variables are learnable.
Figure 3 is a schematic diagram of encoding. The representation method for embedding vector is as follows:
where
N is the number of the variables and
N* is positive integer set.
3.3. Sparse Graph Self-Attention Mechanism
3.3.1. Sparse Self-Attention Mechanism
In the Transformer [
26], the self-attention calculates the dot product of the i-th query as follows:
where
d is the model’s input dimension,
qi is the
i-th row of
Q, and
Q,
K,
V.
L is the input sequence length.
In the self-attention mechanism, according to the Formula (2), the probability distribution of
Q and
K is as follows:
is the asymmetric exponential kernel , representing column i of Q matrix and column j of K matrix, respectively.
We define a uniform distribution as
. When the matrix probability distribution of
Q and
K approximates a uniform distribution, then, for the overall self-attention mechanism, the weight is approximated to a random input, which means the neural network loses its function. Therefore, we adopted the MMD method (Maximum Mean Discrepancy) shown in Formula (5) to measure the similarity between parameter weight distribution and uniform distribution.
For the convenience of calculation, Formula (4) is transformed into the following form, and the linear kernel function is used for mapping:
Multiply both sides of the above equation by
L2 and drop the constant to get the Formula (6):
Following the inference in the informer [
28], which is
, the Formula (6) can be rewritten as the following form:
By Formula (7), dot product pairs with higher attention weights are screened out to make the size of learned graph smaller, with the depth of the model reduced concerning parameters memory consumption as shown in
Figure 4. Therefore, the matrix
Q is transformed into the sparse special matrix in Formula (8). The hyperparameter s is set that indicates the Top-s product pairs are selected as the input of the next layer.
where
sam(.) is the function that samples the
q in top-s product pairs to generate the
Q*.
3.3.2. Graph Construction
Simple GNN-based methods require a graph structure when modeling engine multidimensional parameters. The graph structure can be constructed by physical knowledge or experience, which can be difficult to build because of the nonlinear relationship among the parameters of the engine. To adapt to different engines, we utilize the sparse self-attention mechanism to automatically learn the potential correlations between multiple engine parameters as shown in Formula (9):
where
Q* is the sparse spatial matrix generated in Formula (8),
relu function is chosen as the activation function, and
Softmax is adopted to normalize the generated graph.
In this way, the model builds a graph structure of its own parameters in a data-driven manner.
3.4. Graph Neural Network Based on Fourier Transform
Most time series research has focused on the time-domain correlation between multi-dimensional variables, while ignoring the intrinsic relationship between the parameters in the frequency domain. Considering the high-frequency variation of parameters caused by high engine speed, we attempted to use an improved spectrogram neural network to establish an engine emission prediction model by combining the graph generated in the Block 2 of
Figure 1. The improved spectrogram neural network Block is displayed in the block 3 of
Figure 1.
To combine the sensor embedding vectors
vi with the neural network, we improved the overall calculation flow. First, our graph generator incorporates
vi and to do this, we compute the graph attention as follows:
where Formula (10) combines the input features and embedding vectors, and
Gelu is used as the nonlinear activation to calculate the attention coefficient in Formula (11).
Softmax function normalizes the attention coefficients in Formula (12).
The generated emission graph is transformed into a spectral matrix by Graph Fourier Transform (GFT), which maps the input graph to an orthonormal space based on the normalized graph Laplacian. The normalized graph Laplacian Lap is shown in Formula (13):
where
I is the identity matrix,
D is a degree matrix and
G is the graph generated in Formula (9).
In Formula (14), the Lap can be spectrally decomposed, the matrix composed of its eigenvectors is
U, and
A is the eigenvalue matrix.
Therefore, GFT and Inverse Graph Fourier Transform (IGFT) can be calculated as shown in Formulas (15) and (16).
After the operation, the multi-dimensional sensor variables become independent of each other. Then, by the Discrete Fourier transform (DFT) operation, variables for the engine are transformed into the frequency domain, which can capture feature information under the Gated Linear Units (GLU) layers’ transform and the convolution layer. Inverse Discrete Fourier Transform (IDFT) brings the variables back to the time domain. Finally, we use the graph convolution in Formula (17) and IGFT to generate the final output.
where
is the weight of the k-hop neighbor.

 ,
, 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}