


Proximal Policy Optimization for Energy Management of Electric Vehicles and PV Storage Units



Abstract
:1. Introduction
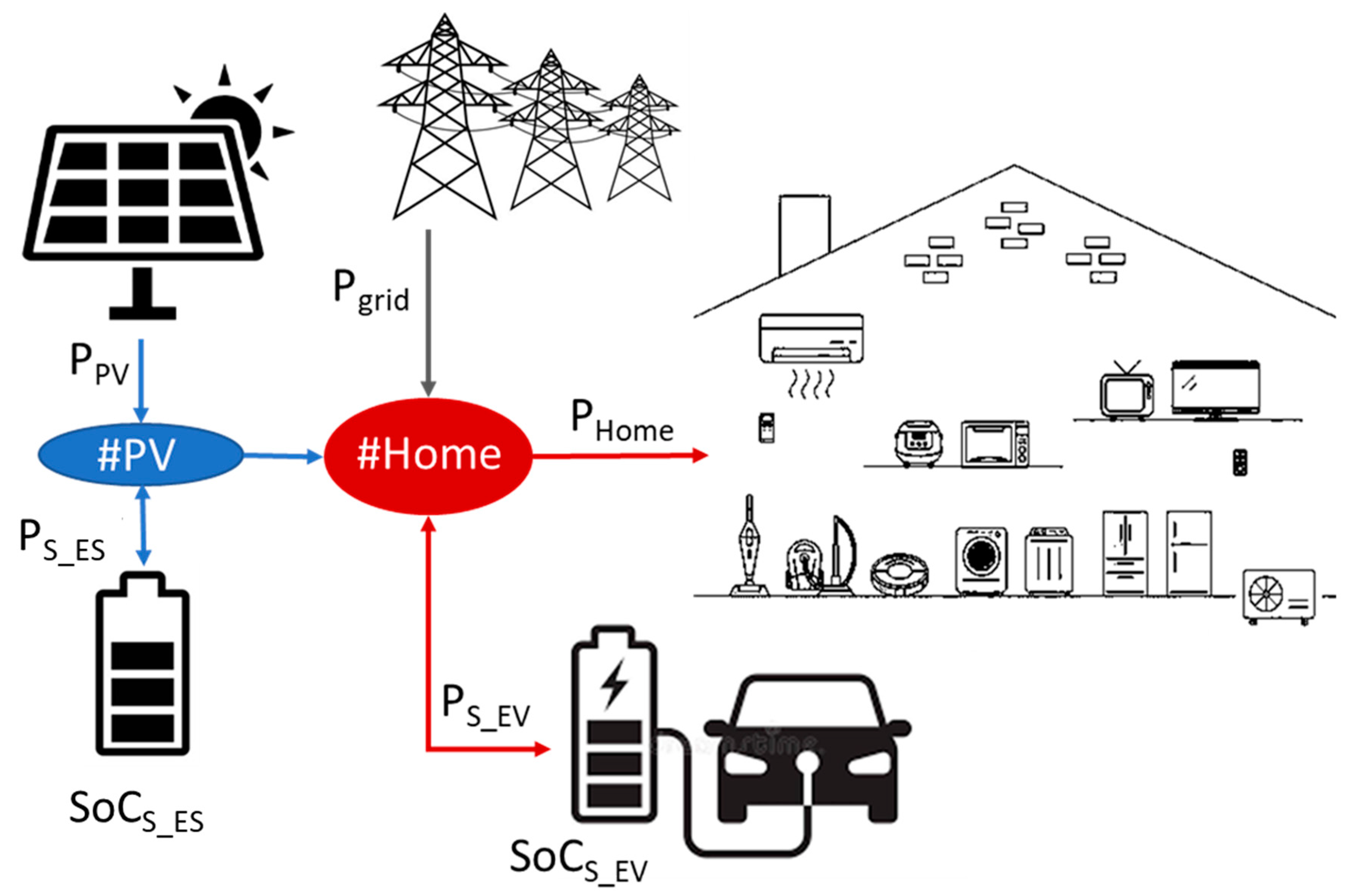
- This paper presents a formulation for the energy management of a detached residential house with CAEVs (G2V and V2G), PV generation and BESS units. Uncertainties regarding PV generation and CAEV mobility are incorporated into the optimization problem. The objective of the HEMS proposed is to manage the controllable energy resources: CAEV battery and BESS energy management to reduce the residential power grid demand from the grid and, consequently, the installation electricity bill.
- CAEV drivers’ range anxiety is incorporated as a reward term into the HEMS RL problem. This term penalizes the possibility of not having fully charged CAEV batteries at departure time. To the best of the authors’ knowledge, CAEV customers’ range anxiety is rarely incorporated into the HEMS RL problem.
- To optimize the CAEV charging/discharging improving the battery life, a punishment term regarding battery aging due to cycling operation is included in the RL formulation. This term penalizes repetitive charging/discharging operations during G2V and V2G processes, and it is considered a key aspect of HEMS.
- The RL rewards among energy consumption from the grid, range anxiety and battery aging are considered in the HEMS formulation based on a PPO algorithm that considers a tradeoff among the three individuals reward/punishment terms. To the best of the authors’ knowledge, range anxiety, combined with battery aging and G2V–V2G flexibility services, has scarcely been studied in HEMS research.
- A comparison with non-optimized and deterministic solutions was conducted to highlight the superiority of the proposed PPO-based HEMS system in terms of energy cost reduction. The results show the superiority of the PPO over the non-optimized and deterministic methods on the relative daily energy cost.
2. Residential EV Management with PV Energy Sources and EV
2.1. Problem Definition
2.2. Home Energy Management
2.2.1. Energy Cost
2.2.2. Battery Fear Cost
2.2.3. Battery Degradation Cost
3. Markov Decision Process Formulation
3.1. State Space
- -
- the SoCs of the EVs batteries and PV units storage units (SoCS_EV,k, SoCS_ES,k);
- -
- the EV departure time and plugged availability (ts,dep, PluggedEV,k);
- -
- the energy demand of the detached house (Phome);
- -
- PV production and information regarding the time slot (PPV, ts);
- -
- the electricity price (λeg).
3.2. Action Space
- The action regarding the charging/discharging orders of the PV-associated storage unit (BESS) (),
- The action regarding the charging/discharging orders of the CAEV battery ().
- The charge/discharge action determines, for each time slot, the amount of bidirectional energy flow between the PV generation and its associated storage unit (BESS). For the case of CAEV, the charging/discharge action for EV batteries is limited by the maximum charging/discharging power that could flow through the EV battery socket. When the action’s value is zero, there is no power flow between the charging socket and the battery. Both actions () are continuous and are measured in kW.
3.3. Transition Function
- The transition function associated with the energy management of CAEVs: the charging/discharging of EV batteries.
- The transition function associated with the energy management of PV storage units: the charging/discharging of BESS batteries.
3.3.1. The Transition Function of CAEV Energy Management
- CAEV charging:
- CAEV discharging:
3.3.2. PV Storage Energy Management Transition function
3.4. Reward
- The revenues/expenses due to the consumption or injection of electrical energy at the connection point of the residential house (21) which depend on the energy purchased from the grid () and the price of the energy () at instant time .
- The expenses incurred due to batteries’ degradation (CAEV, PV storage), which are shown in (22), depend on the amount of charged or discharged power on these units (, ) multiplied by the weight factors of EV battery degradation ( and BESS storage degradation and ().
- The range anxiety expense is associated with the uncompleted SoC of the EV at the departure instant. At this instant, (), the range anxiety reward calculates the difference between the maximum SoC of the electric vehicle battery and the current SoC at departure time, as shown in (23).
4. Proximal Policy Optimization
| Algorithm 1. PPO, Actor-Critic pseudocode | |
| Require: Initialize actor-critic network with parameter θ, μ, clipping threshold ∊, and a storage buffer D for trajectory memory | |
| 1 | for each step of an episode do |
| 2 | for k = 1…T do |
| 3 | get initial state s |
| 4 | select the action from actor network, |
| 5 | run the action through the environment obtain the reward from the critic network, and next state s’ |
| 6 | Update the actor-critic network parameters |
| 7 | store the tuple {S, a, T, R} in the replay buffer D |
| 8 | |
| 9 | end for |
| 10 | end for |
5. Practical Implementation
5.1. Dataset Description
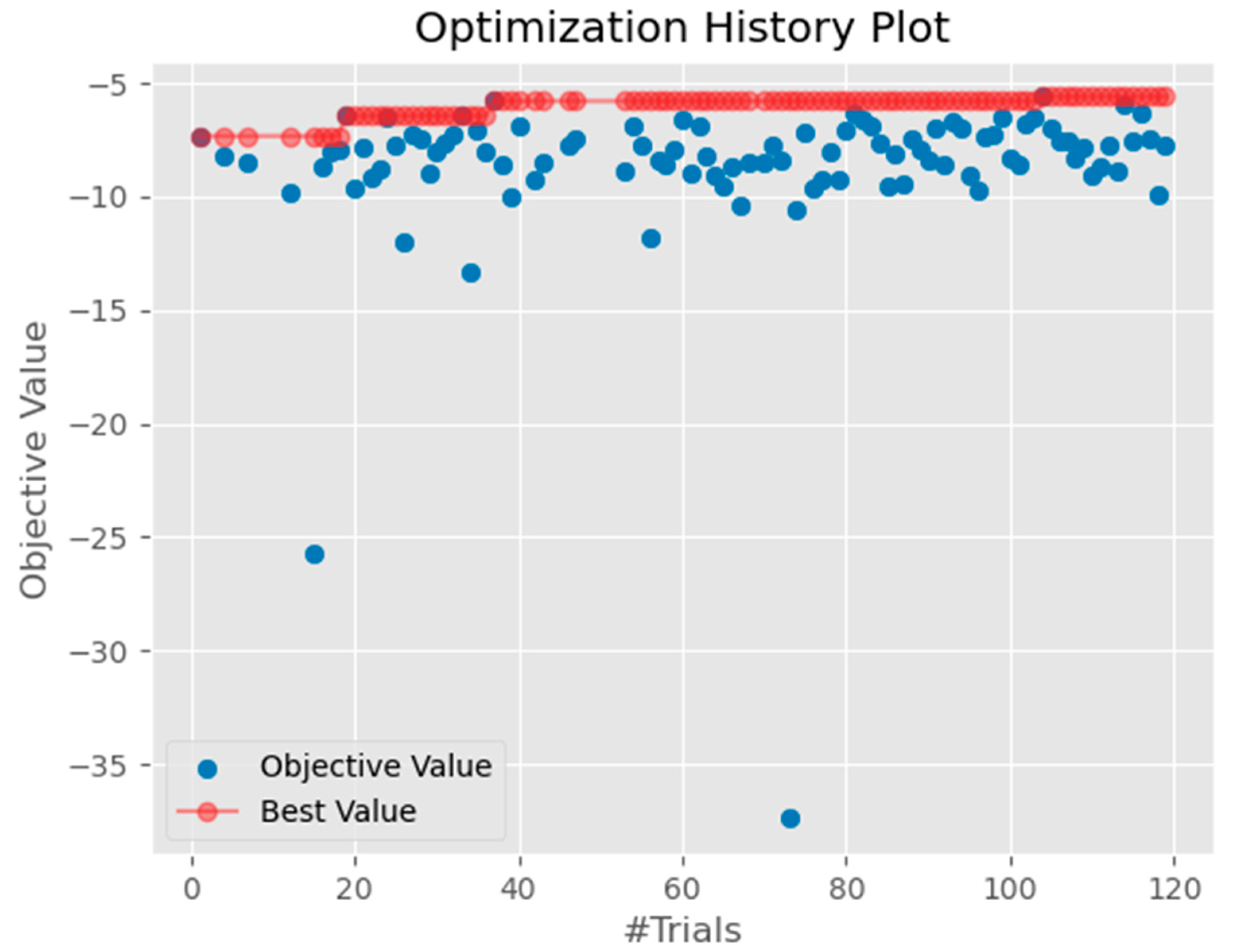
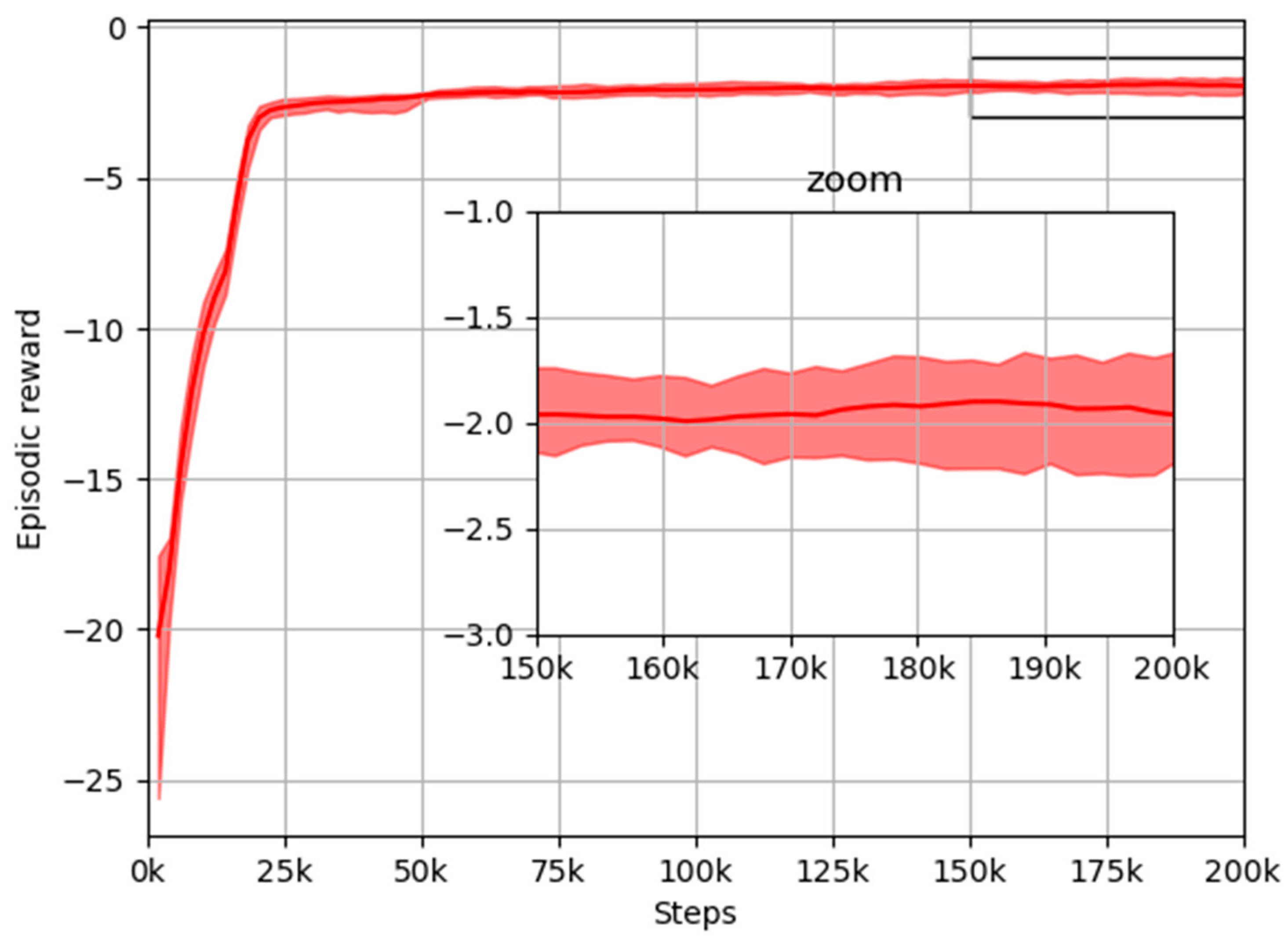
5.2. PPO Training
- -
- Learning rate: 0.000436
- -
- Gamma: 0.999155
- -
- N_step = 2048
- -
- Gae (γ): 0.95
- -
- Batch size = 64
- -
- Clip_range = 0.2
- -
- Number epoch: 37
- -
- Entropy coef = 0.0005
- -
- Number eval_episodes = 5
- -
- Total time steps = 200,000
5.3. Energy Management with the PPO
- (a)
- Power consumption from the grid
- (b)
- BESS energy management
- (c)
- CAEV energy management
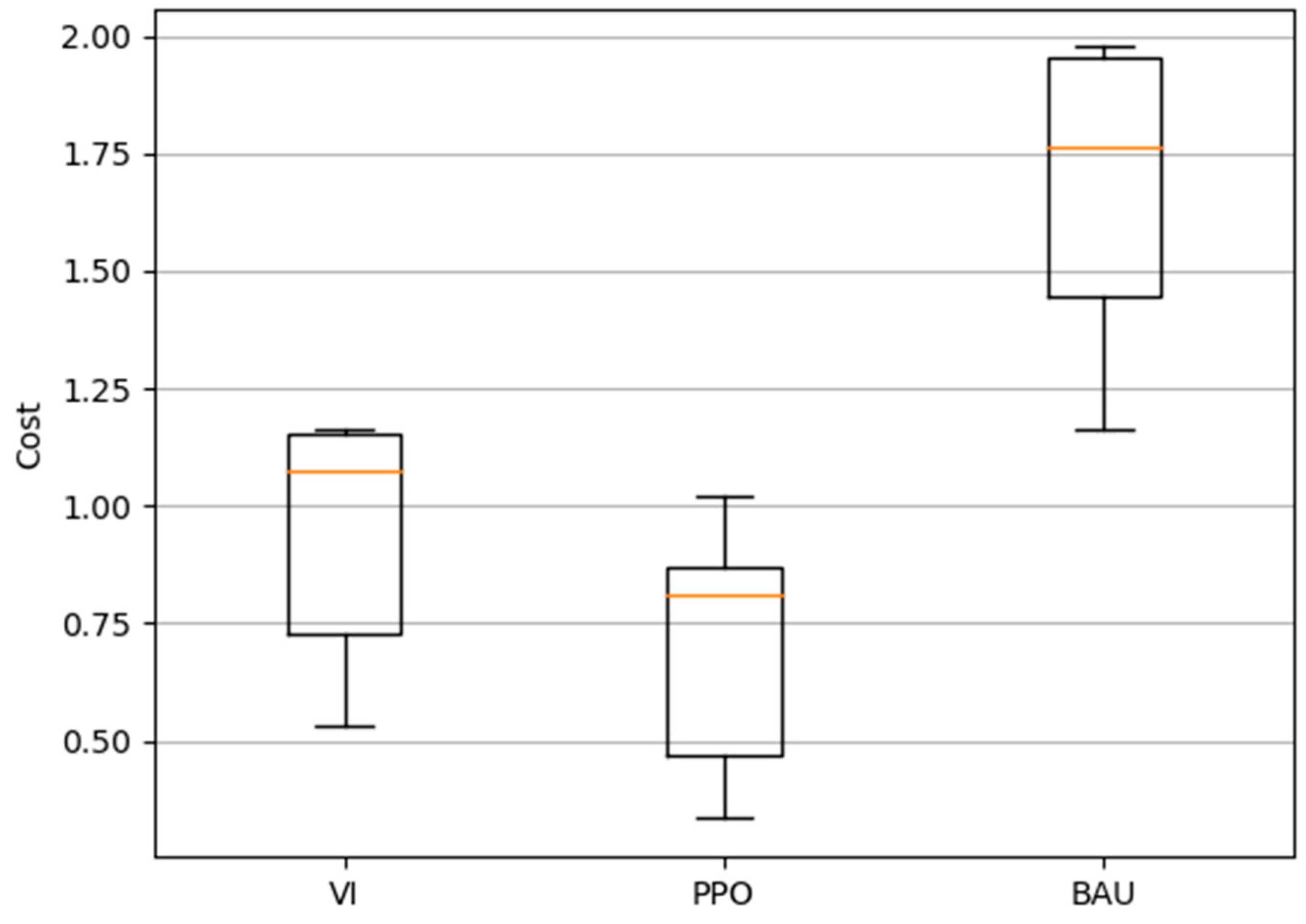
5.4. Total Cost Comparison
- -
- In the BAU scheme, any optimization is performed over the controllable loads. In this scheme, the CAEVs were connected to the grid and the charging process started without delay as soon as they arrived at the house. This scheme did not use information regarding energy prices, and only the G2V mode was allowed for the CAEVs.
- -
- The value iteration solution scheme (VI) is a deterministic method, with a low percentage of uncertainties in the information, and perfect knowledge of the model. This method lies in the beginning of RL algorithms. VI relies on the acquisition of the optimal policy for an MDP by calculating the value function (), defined as (30), where represents the discount factor considering the uncertainty associated with future costs and ensures that the return () is a finite value.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Nomenclature
| Acronyms | ||
| BESS | Battery energy storage system | |
| CAEV | Connected autonomous electric vehicles | |
| EV | Electric vehicles | |
| G2V | Grid to vehicle | |
| HEMS | Home energy management system | |
| MDP | Markov decision process | |
| PPO | Proximal policy optimization | |
| RL | Reinforcement learning | |
| V2G | Vehicle to grid | |
| V2X | Vehicle to X | |
| SoC | State of charge | |
| MDP tuple | ||
| Action space | ||
| Reward space | ||
| State space | ||
| Transition function space | ||
| RL Parameters | ||
| Action at instant | ||
| Reward (EUR) | ||
| Degradation cost regard (EUR) | ||
| Electricity reward (EUR) | ||
| Range anxiety reward (EUR) | ||
| Reward at instant (EUR) | ||
| Degradation cost reward at instant (EUR) | ||
| Electricity cost reward at instant (EUR) | ||
| Range anxiety cost reward at instant (EUR) | ||
| State space at instant | ||
| Advantage estimation function | ||
| Storage unit aging or degradation cost (EUR) | ||
| Range anxiety cost (EUR) | ||
| BESS degradation cost (EUR /kWh) | ||
| EV battery degradation cost (EUR /kWh) | ||
| Clipped target function | ||
| BESS capacity (kWh) | ||
| EV battery capacity (kWh) | ||
| Value function parametrized by | ||
| Policy for state and action parametrized by | ||
| Optimal policy | ||
| Parameters | ||
| Time slot (h) | ||
| Electricity price (EUR /kWh) | ||
| hyperparameter | ||
| Discount factor | ||
| Maximum power supplied by the EV installation (kWh) | ||
| Minimum power supplied by the EV installation (kWh) | ||
| Maximum state of charge of BESS (kWh) | ||
| Minimum state of charge of BESS (kWh) | ||
| Maximum state of charge of EV battery (kWh) | ||
| Minimum state of charge of EV battery (kWh) | ||
| Variables | ||
| Charge/discharge action over BESS unit (kWh) | ||
| Charge/discharge action over EV battery (kWh) | ||
| Power demanded by the EV (kW) | ||
| Power supplied by the EV installation (kW) | ||
| Power supplied by the grid (kW) | ||
| Power demand by house (kW) | ||
| Power generated by PV installation (kW) | ||
| Power flow from the PV installation to the house (kW) | ||
| Power flow to BESS (kW) | ||
| Power flow to EV battery (kW) | ||
| State of charge of BESS (%) | ||
| State of charge of EV battery (%) |
References
- IEA. Transport, IEA, Paris. 2022. Available online: https://www.iea.org/reports/transport (accessed on 30 April 2023).
- Esmaili, M.; Shafiee, H.; Aghaei, J. Range anxiety of electric vehicles in energy management of microgrids with controllable loads. J. Energy Storage 2018, 20, 57–66. [Google Scholar] [CrossRef]
- Communication from the Commission to the European Parliament, the European Council, the Council, the European Economic and Social Committee and the Committee of the Regions. The European Green Deal. COM/2019/640 Final. Available online: http://eur-lex.europa.eu/LexUriServ/LexUriServ.do?uri=CELEX:52012DC0673:EN:NOT (accessed on 1 June 2023).
- Kempton, W.; Tomic, J. Vehicle-to-grid power fundamentals: Calculating capacity and net revenue. J. Power Sources 2005, 144, 268–279. [Google Scholar] [CrossRef]
- Alonso, M.; Amaris, H.; Martin, D.; De La Escalera, A. Energy management of autonomous electric vehicles by reinforcement learning techniques. In Proceedings of the Second International Conference on Sustainable Mobility Applications, Renewables and Technology (SMART), Cassino, Italy, 12 December 2022. [Google Scholar]
- V2G Hub Insights. Available online: https://www.v2g-hub.com/insights (accessed on 4 November 2022).
- Jian, L.; Zheng, Y.; Xiao, X.; Chan, C.C. Optimal scheduling for vehicle to-grid operation with stochastic connection of plug-in electric vehicles to smart grid. Appl. Energy 2015, 146, 150–161. [Google Scholar] [CrossRef]
- Lund, H.; Kempton, W. Integration of renewable energy into the transport and electricity sectors through V2G. Energy Policy 2008, 36, 3578–3587. [Google Scholar] [CrossRef]
- Al-Awami, A.T.; Sortomme, E. Coordinating vehicle-to-grid services with energy trading. IEEE Trans. Smart Grid 2012, 3, 453–462. [Google Scholar] [CrossRef]
- Shariff, S.M.; Iqbal, D.; Alam, M.S.; Ahmad, F. A state of the art review of electric vehicle to grid (V2G) technology. IOP Conf. Ser. Mater. Sci. Eng. 2019, 561, 012103. [Google Scholar] [CrossRef]
- Barbato, A.; Capone, A. Optimization Models and Methods for Demand-Side Management of Residential Users: A Survey. Energies 2014, 7, 5787–5824. [Google Scholar] [CrossRef] [Green Version]
- Carli, R.; Dotoli, M. Energy scheduling of a smart home under nonlinear pricing. In Proceedings of the 53rd IEEE Conference on Decision and Control, Los Angeles, CA, USA, 15–17 December 2014; pp. 5648–5653. [Google Scholar]
- Falvo, M.C.; Graditi, G.; Siano, P. Electric Vehicles integration in demand response programs. In Proceedings of the International Symposium on Power Electronics, Electrical Drives, Automation and Motion, Ischia, Italy, 18–20 June 2014; pp. 548–553. [Google Scholar]
- Scott, C.; Ahsan, M.; Albarbar, A. Machine learning based vehicle to grid strategy for improving the energy performance of public buildings. Sustainability 2021, 13, 4003. [Google Scholar] [CrossRef]
- Kern, T.; Dossow, P.; von Roon, S. Integrating bidirectionally chargeable electric vehicles into the electricity markets. Energies 2020, 13, 5812. [Google Scholar] [CrossRef]
- Sovacool, B.K.; Noel, L.; Axsen, J.; Kempton, W. The neglected social dimensions to a vehicle-to-grid (V2G) transition: A critical and systematic review. Environ. Res. Lett. 2018, 13, 013001. [Google Scholar] [CrossRef]
- Yao, L.; Lim, W.H.; Tsai, T.S. A real-time charging scheme for demand response in electric vehicle parking station. IEEE Trans. Smart Grid 2017, 8, 52–62. [Google Scholar] [CrossRef]
- Chen, H.; Hu, Z.; Zhang, H.; Luo, H. Coordinated charging and discharging strategies for plug-in electric bus fast charging station with energy storage system. IET Gener. Transm. Distrib. 2018, 12, 2019–2028. [Google Scholar] [CrossRef] [Green Version]
- Vagropoulos, S.I.; Bakirtzis, A.G. Optimal bidding strategy for electric vehicle aggregators in electricity markets. IEEE Trans. Power Syst. 2013, 28, 4031–4041. [Google Scholar] [CrossRef]
- Amin, A.; Tareen, W.U.K.; Usman, M.; Ali, H.; Bari, I.; Horan, B.; Mekhilef, S.; Asif, M.; Ahmed, S.; Mahmood, A. A review of optimal charging strategy for electric vehicles under dynamic pricing schemes in the distribution charging network. Sustainability 2020, 12, 10160. [Google Scholar] [CrossRef]
- Xu, Y.; Pan, F.; Tong, L. Dynamic scheduling for charging electric vehicles: A priority rule. IEEE Trans. Autom. Control 2016, 61, 4094–4099. [Google Scholar] [CrossRef]
- Chen, Q.; Folly, K.A. Application of Artificial Intelligence for EV Charging and Discharging Scheduling and Dynamic Pricing: A Review. Energies 2023, 16, 146. [Google Scholar] [CrossRef]
- Al-Ogaili, A.S.; Hashim, T.J.T.; Rahmat, N.A.; Ramasamy, A.K.; Marsadek, M.B.; Faisal, M.; Hannan, M.A. Review on scheduling, clustering, and forecasting strategies for controlling electric vehicle charging: Challenges and recommendations. IEEE Access 2019, 7, 128353–128371. [Google Scholar] [CrossRef]
- Lee, S.; Choi, D.H. Dynamic pricing and energy management for profit maximization in multiple smart electric vehicles charging stations: A privacy-preserving deep reinforcement learning approach. Appl. Energy 2021, 304, 117754. [Google Scholar] [CrossRef]
- Cedillo, M.H.; Sun, H.; Jiang, J.; Cao, Y. Dynamic pricing and control for EV charging stations with solar generation. Appl. Energy 2022, 326, 119920. [Google Scholar] [CrossRef]
- Moghaddam, V.; Yazdani, A.; Wang, H.; Parlevliet, D.; Shahnia, F. An online reinforcement learning approach for dynamic pricing of electric vehicle charging stations. IEEE Access 2020, 8, 130305–130313. [Google Scholar] [CrossRef]
- Sun, D.; Ou, Q.; Yao, X.; Gao, S.; Wang, Z.; Ma, W.; Li, W. Integrated human-machine intelligence for EV charging prediction in 5G smart grid. EURASIP J. Wirel. Commun. Netw. 2020, 2020, 139. [Google Scholar] [CrossRef]
- Boulakhbar, M.; Farag, M.; Benabdelaziz, K.; Kousksou, T.; Zazi, M. A deep learning approach for prediction of electrical vehicle charging stations power demand in regulated electricity markets: The case of Morocco. Clean. Energy Syst. 2022, 3, 100039. [Google Scholar] [CrossRef]
- Kaewdornhan, N.; Srithapon, C.; Liemthong, R.; Chatthaworn, R. Real-Time Multi-Home Energy Management with EV Charging Scheduling Using Multi-Agent Deep Reinforcement Learning Optimization. Energies 2023, 16, 2357. [Google Scholar] [CrossRef]
- Jin, J.; Xu, Y. Optimal Policy Characterization Enhanced Actor-Critic Approach for Electric Vehicle Charging Scheduling in a Power Distribution Network. IEEE Trans. Smart Grid 2021, 12, 1416–1428. [Google Scholar] [CrossRef]
- Zhang, C.; Li, T.; Cui, W.; Cui, N. Proximal Policy Optimization Based Intelligent Energy Management for Plug-In Hybrid Electric Bus Considering Battery Thermal Characteristic. World Electr. Veh. J. 2023, 14, 47. [Google Scholar] [CrossRef]
- Schulman, J.W.; Dhariwal, F.; Radford, P.; Oleg, A.; Oleg, K. Proximal Policy Optimization Algorithm. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Red Eléctrica Española. Sistema de Información del Operador del Sistema Eléctrico en España. Available online: https://esios.ree.es/en (accessed on 20 October 2022).
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A next generation hyperparameter optimization framework. In Proceedings of the 25th ACM SIGKDD International Conference of the Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2623–2631. [Google Scholar]
- Raffin, A.; Hill, A.; Gleave, A.; Kanervisto, A.; Ernestus, M.; Dormann, N. Stable-Baselines3: Reliable Reinforcement Learning Implementations. J. Mach. Learn. Res. 2021, 22, 1–8. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | [2] | [17] | [18] | [20] | [24] | [27] | [28] | [29] | [30] | Our Study |
|---|---|---|---|---|---|---|---|---|---|---|
| Energy management | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ | ✓ | ✓ |
| Distributed energy resources | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ | ✓ | ✓ |
| V2G–G2V operation | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ |
| Uncertainties | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ | ✓ | ✓ |
| Range anxiety | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ | ✗ | ✗ | ✓ | ✓ |
| RL method | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| States | Description | Range |
|---|---|---|
| ts | Daily time | [t0: t0 + Ns Δt] |
| SoCS_ES,k | BESS storage SoC | [SoCS_ES,min: SoCS_ES,max] |
| SoCS_EV,k | CAEV Battery SoC | [SoCS_EV,min: SoCS_EV,max] |
| PluggedEV,k | Flag EV plugged into the grid | [0 (disconnected): 1 (connected)] |
| ts,dep | Time slot departure | [t0: t0 + Ns Δt] |
| λeg | Energy price | EUR/kWh |
| Phome | Residential demand | kWh |
| PPV | PV generation | kWh |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alonso, M.; Amaris, H.; Martin, D.; de la Escalera, A. Proximal Policy Optimization for Energy Management of Electric Vehicles and PV Storage Units. Energies 2023, 16, 5689. https://doi.org/10.3390/en16155689
Alonso M, Amaris H, Martin D, de la Escalera A. Proximal Policy Optimization for Energy Management of Electric Vehicles and PV Storage Units. Energies. 2023; 16(15):5689. https://doi.org/10.3390/en16155689
Chicago/Turabian StyleAlonso, Monica, Hortensia Amaris, David Martin, and Arturo de la Escalera. 2023. "Proximal Policy Optimization for Energy Management of Electric Vehicles and PV Storage Units" Energies 16, no. 15: 5689. https://doi.org/10.3390/en16155689