

Feature Transfer and Rapid Adaptation for Few-Shot Solar Power Forecasting


Abstract
:1. Introduction
- In the proposed FTRA, the adopted deep-learning-based SPF model will be reasonably divided into Transferable Learner and Adaptive Learner, which are responsible for Feature Transfer and Rapid Adaptation, respectively.
- TL and Reptile were integrated to develop different pre-training and fine-tuning strategies for parameters in different parts of the model, so as to extract valuable knowledge from the SSP to the TSP and adapt the pre-trained model to TSP rapidly.
2. Solar Power Forecasting Models
- (1)
- Transformer-based: The encoderlayer in [32] is used as the ME in the Transformer-based SPF model, which contains a multi-head self-attention mechanism, residual connection, layer normalization, and position-wise FCNN;
- (2)
- LSTM-based: Single-layer LSTM in [33] is used as the ME in the LSTM-based SPF model, which comprises of forget gate, input gate, update gate, and output gate;
- (3)
- GRU-based: Single-layer GRU in [34] is used as the ME in the LSTM-based SPF model, which is made up of a reset gate and an update gate.
3. Methodology: FTRA
3.1. Division of SPF Model
3.2. Transfer-Pre-Training
| Algorithm 1 Transfer-Pre-Training Algorithm | |
| Require: , , , | |
| 1. | Randomly initialize |
| 2. | while not done do |
| 3. | Randomly select SSPs as |
| 4. | for all do |
| 5. | |
| 6. | Sample one datapoints from |
| 7. | Update |
| 8. | end for |
| 9. | Update |
| 10. | end while |
3.3. Meta-Pre-Training
| Algorithm 2 Meta-Pre-Training Algorithm | |
| Require: , , , , , | |
| 1. | Randomly initialize |
| 2. | while not done do |
| 3. | Randomly select SPPs as |
| 4. | for all do |
| 5. | |
| 6. | Sample datapoints from |
| //Inner Loop | |
| 7. | for all [ do |
| 8. | Update |
| 9. | end for |
| 10. | end for |
| //Outer Loop | |
| 11. | Update |
| 12. | end while |
3.4. Fine-Tuning
| Algorithm 3 Fine-Tunning Algorithm | |
| Require: , , | |
| 1. | while not done do |
| 2. | Sample one datapoints from |
| 3. | Update |
| 4. | end while |
4. Case Study
4.1. Data Description
4.2. Settings of SPP and TPP
4.3. Evaluation Metric
4.4. Evaluation Method
4.5. Comparison Methods
4.6. Hyperparameters
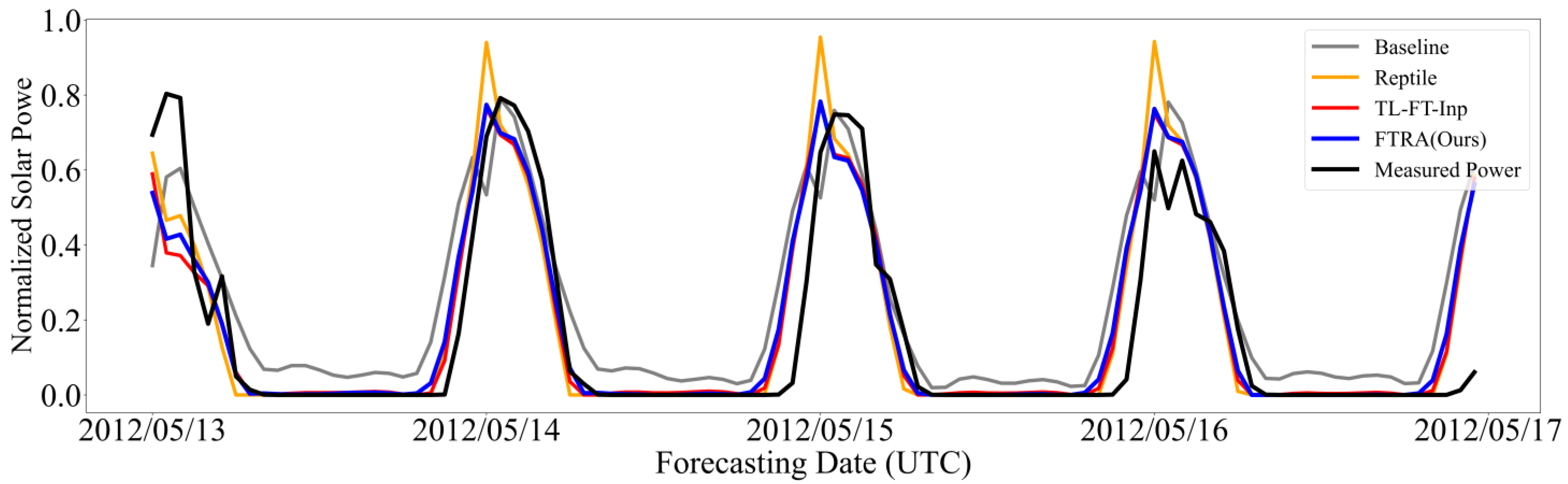
4.7. FSSPF Results
4.8. Computational Costs
5. Conclusions
- (1)
- FTRA will divide the adopted deep-learning-based SPF model into the Transferable Learner and the Adaptive Learner, which will take charge of Feature Transfer and Rapid Adaptation, respectively.
- (2)
- Through integrating TL and Reptile, the parameters of the Transferable Learner and the Adaptive Learner will be assigned different pre-training and fine-tuning strategies.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| FSSPF | Few-Shot Solar Power Forecasting |
| FTRA | Feature Transfer and Rapid Adaptation |
| SP | Solar Power |
| SSP | Source Solar Plants |
| TSP | Target Solar Plants |
| SPF | Solar Power Forecasting |
| LSTM | Long Short-Term Memory Neural Network |
| GRU | Gate Recurrent Unit |
| TL | Transfer learning |
| FSL | Few-Shot Learning |
| NWP | Numerical Weather Prediction |
| NWPEL | NWP Embedding Layer |
| ME | Meteorological Encoder |
| POL | Power Output Layer |
| FCNN | Fully-Connected Neural Networks |
| GEFCom2014 | 2014 Global Energy Competition |
| RMSE | Root Mean Square Error |
| MAE | Mean Average Error |
| KFCV | K-Fold Cross-Validation method |
References
- Zhang, J.; Hao, Y.; Fan, R.; Wang, Z. An Ultra-Short-Term PV Power Forecasting Method for Changeable Weather Based on Clustering and Signal Decomposition. Energies 2023, 16, 3092. [Google Scholar] [CrossRef]
- Wu, K.; Peng, X.; Li, Z.; Cui, W.; Yuan, H.; Lai, C.S.; Lai, L.L. A Short-Term Photovoltaic Power Forecasting Method Combining a Deep Learning Model with Trend Feature Extraction and Feature Selection. Energies 2022, 15, 5410. [Google Scholar] [CrossRef]
- Marweni, M.; Hajji, M.; Mansouri, M.; Mimouni, M.F. Photovoltaic Power Forecasting Using Multiscale-Model-Based Machine Learning Techniques. Energies 2023, 16, 4696. [Google Scholar] [CrossRef]
- Cantillo-Luna, S.; Moreno-Chuquen, R.; Celeita, D.; Anders, G. Deep and Machine Learning Models to Forecast Photovoltaic Power Generation. Energies 2023, 16, 4097. [Google Scholar] [CrossRef]
- Wang, M.; Wang, P.; Zhang, T. Evidential Extreme Learning Machine Algorithm-Based Day-Ahead Photovoltaic Power Forecasting. Energies 2022, 15, 3882. [Google Scholar] [CrossRef]
- Huang, H.; Zhu, Q.; Zhu, X.; Zhang, J. An Adaptive, Data-Driven Stacking Ensemble Learning Framework for the Short-Term Forecasting of Renewable Energy Generation. Energies 2023, 16, 1963. [Google Scholar] [CrossRef]
- Alkhayat, G.; Mehmood, R. A Review and Taxonomy of Wind and Solar Energy Forecasting Methods Based on Deep Learning. Energy AI 2021, 4, 100060. [Google Scholar] [CrossRef]
- Zhao, S.; Wu, Q.; Zhang, Y.; Wu, J.; Li, X.-A. An Asymmetric Bisquare Regression for Mixed Cyberattack-Resilient Load Forecasting. Expert Syst. Appl. 2022, 210, 118467. [Google Scholar] [CrossRef]
- Yang, Y.; Zhou, H.; Wu, J.; Liu, C.-J.; Wang, Y.-G. A Novel Decompose-Cluster-Feedback Algorithm for Load Forecasting with Hierarchical Structure. Int. J. Electr. Power Energy Syst. 2022, 142, 108249. [Google Scholar] [CrossRef]
- Sareen, K.; Panigrahi, B.K.; Shikhola, T.; Sharma, R. An Imputation and Decomposition Algorithms Based Integrated Approach with Bidirectional LSTM Neural Network for Wind Speed Prediction. Energy 2023, 278, 127799. [Google Scholar] [CrossRef]
- Ji, L.; Fu, C.; Ju, Z.; Shi, Y.; Wu, S.; Tao, L. Short-Term Canyon Wind Speed Prediction Based on CNN—GRU Transfer Learning. Atmosphere 2022, 13, 813. [Google Scholar] [CrossRef]
- Al-Ali, E.M.; Hajji, Y.; Said, Y.; Hleili, M.; Alanzi, A.M.; Laatar, A.H.; Atri, M. Solar Energy Production Forecasting Based on a Hybrid CNN-LSTM-Transformer Model. Mathematics 2023, 11, 676. [Google Scholar] [CrossRef]
- Hu, J.; Li, H. A Transfer Learning-Based Scenario Generation Method for Stochastic Optimal Scheduling of Microgrid with Newly-Built Wind Farm. Renew. Energy 2022, 185, 1139–1151. [Google Scholar] [CrossRef]
- Yang, Y.; Wang, Z.; Zhao, S.; Wu, J. An Integrated Federated Learning Algorithm for Short-Term Load Forecasting. Electr. Power Syst. Res. 2023, 214, 108830. [Google Scholar] [CrossRef]
- Luo, X.; Zhang, D.; Zhu, X. Combining Transfer Learning and Constrained Long Short-Term Memory for Power Generation Forecasting of Newly-Constructed Photovoltaic Plants. Renew. Energy 2022, 185, 1062–1077. [Google Scholar] [CrossRef]
- Wen, Q.; Sun, L.; Yang, F.; Song, X.; Gao, J.; Wang, X.; Xu, H. Time Series Data Augmentation for Deep Learning: A Survey. arXiv 2020, arXiv:2002.12478. [Google Scholar]
- Liu, L.-M.; Ren, X.-Y.; Zhang, F.; Gao, L.; Hao, B. Dual-Dimension Time-GGAN Data Augmentation Method for Improving the Performance of Deep Learning Models for PV Power Forecasting. Energy Rep. 2023, 9, 6419–6433. [Google Scholar] [CrossRef]
- Kaya, M.; Bilge, H. Deep Metric Learning: A Survey. Symmetry 2019, 11, 1066. [Google Scholar] [CrossRef]
- Mao, Y.; Fan, F. Ultra-short-term prediction of PV power based on similar days of Mahalanobis distance. Renew. Energy Resour. 2021, 2, 175–181. [Google Scholar]
- Sun, Q.; Liu, Y.; Chen, Z.; Chua, T.-S.; Schiele, B. Meta-Transfer Learning Through Hard Tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 1443–1456. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Yang, H.; Wang, W. Prediction of photovoltaic power generation based on LSTM and transfer learning digital twin. J. Phys. Conf. Ser. 2023, 2467, 012015. [Google Scholar] [CrossRef]
- Miraftabzadeh, S.M.; Colombo, C.G.; Longo, M.; Foiadelli, F. A Day-Ahead Photovoltaic Power Prediction via Transfer Learning and Deep Neural Networks. Forecasting 2023, 5, 213–228. [Google Scholar] [CrossRef]
- Hospedales, T.M.; Antoniou, A.; Micaelli, P.; Storkey, A.J. Meta-Learning in Neural Networks: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 1. [Google Scholar] [CrossRef] [PubMed]
- Finn, C.; Abbeel, P.; Levine, S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks 2017. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Feng, Y.; Chen, J.; Xie, J.; Zhang, T.; Lv, H.; Pan, T. Meta-Learning as a Promising Approach for Few-Shot cross-Domain Fault Diagnosis: Algorithms, Applications, and Prospects. Knowl.-Based Syst. 2022, 235, 107646. [Google Scholar] [CrossRef]
- Liu, T.; Ma, X.; Li, S.; Li, X.; Zhang, C. A Stock Price Prediction Method Based on Meta-Learning and Variational Mode Decomposition. Knowl.-Based Syst. 2022, 252, 109324. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, S.; Hu, R.; Lu, N. A Meta-Learning Based Distribution System Load Forecasting Model Selection Framework. Appl. Energy 2021, 294, 116991. [Google Scholar] [CrossRef]
- Nichol, A.; Achiam, J.; Schulman, J. On First-Order Meta-Learning Algorithms 2018. arXiv 2018, arXiv:1803.02999. [Google Scholar]
- Yan, M.; Pan, Y. Meta-Learning for Compressed Language Model: A Multiple Choice Question Answering Study. Neurocomputing 2022, 487, 181–189. [Google Scholar] [CrossRef]
- Hong, T.; Pinson, P.; Fan, S.; Zareipour, H.; Troccoli, A.; Hyndman, R.J. Probabilistic Energy Forecasting: Global Energy Forecasting Competition 2014 and beyond. Int. J. Forecast. 2016, 32, 896–913. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. In Proceedings of the NIPS 2014 Workshop on Deep Learning, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Wu, H.; Xu, J.; Wang, J.; Long, M. Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting. In Proceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS 2021), Online, 6–14 December 2021; pp. 1–12. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Names | TSP | SSP |
|---|---|---|
| S-1 | SPP1 | SPP2, SPP3 |
| S-2 | SPP2 | SPP1, SPP3 |
| S-3 | SPP3 | SPP1, SPP2 |
| Models | Approaches | 10-Day | 20-Day | 30-Day | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S-1 | S-2 | S-3 | AVE + | S-1 | S-2 | S-3 | AVE | S-1 | S-2 | S-3 | AVE | ||
| Transformer-based | Baseline [23] | 12.69 | 12.99 | 16.86 | 14.18 | 11.36 | 10.97 | 11.26 | 11.20 | 10.58 | 10.28 | 11.09 | 10.65 |
| TL-FT-Out [23] | 9.78 | 9.16 | 9.82 | 9.59 | 9.26 | 8.62 | 9.35 | 9.08 | 9.09 | 8.54 | 9.27 | 8.97 | |
| TL-FT-All [22] | 8.79 | 8.93 | 9.03 | 8.92 | 8.16 | 8.17 | 8.56 | 8.30 | 7.94 | 8.14 | 8.34 | 8.14 | |
| TL-FT-Inp | 8.22 | 9.06 | 9.54 | 8.94 | 7.61 | 8.35 | 9.12 | 8.36 | 7.40 | 8.24 | 8.95 | 8.20 | |
| Reptile [29] | 8.61 | 9.23 | 8.97 | 8.94 | 8.28 | 8.53 | 8.48 | 8.43 | 8.22 | 8.32 | 8.31 | 8.28 | |
| FTRA(Ours) | 8.01 | 8.81 | 8.43 | 8.42 | 7.74 | 8.07 | 8.21 | 8.01 | 7.49 | 8.08 | 8.16 | 7.91 | |
| Upper-Bound * | 6.57 | 7.01 | 7.38 | 6.99 | 6.57 | 7.01 | 7.38 | 6.99 | 6.57 | 7.01 | 7.38 | 6.99 | |
| LSTM-based | Baseline [23] | 16.50 | 16.53 | 17.04 | 16.69 | 13.50 | 12.98 | 13.97 | 13.48 | 12.42 | 12.14 | 12.89 | 12.48 |
| TL-FT-Out [23] | 9.56 | 9.46 | 8.90 | 9.31 | 8.91 | 8.80 | 10.06 | 9.26 | 8.67 | 8.64 | 9.79 | 9.03 | |
| TL-FT-All [22] | 8.98 | 8.85 | 9.28 | 9.04 | 8.40 | 8.18 | 8.71 | 8.43 | 8.23 | 8.11 | 8.44 | 8.26 | |
| TL-FT-Inp | 8.61 | 8.90 | 9.49 | 9.00 | 7.98 | 8.23 | 8.80 | 8.34 | 7.76 | 8.22 | 8.60 | 8.19 | |
| Reptile [29] | 8.27 | 9.23 | 8.80 | 8.77 | 7.89 | 8.83 | 8.65 | 8.46 | 7.70 | 8.66 | 8.30 | 8.22 | |
| FTRA(Ours) | 8.28 | 8.70 | 8.38 | 8.45 | 8.02 | 8.09 | 8.13 | 8.08 | 7.92 | 7.98 | 7.95 | 7.95 | |
| Upper-Bound | 6.52 | 6.95 | 7.38 | 6.95 | 6.52 | 6.95 | 7.38 | 6.95 | 6.52 | 6.95 | 7.38 | 6.95 | |
| GRU-based | Baseline [23] | 15.97 | 16.44 | 16.86 | 16.42 | 12.79 | 12.55 | 13.68 | 13.01 | 11.73 | 11.41 | 12.58 | 11.91 |
| TL-FT-Out [23] | 9.89 | 9.41 | 11.34 | 10.21 | 9.31 | 8.71 | 10.26 | 9.43 | 9.09 | 8.55 | 9.72 | 9.12 | |
| TL-FT-All [22] | 9.04 | 8.92 | 9.41 | 9.12 | 8.57 | 8.31 | 8.78 | 8.55 | 8.41 | 8.20 | 8.51 | 8.37 | |
| TL-FT-Inp | 8.40 | 8.77 | 9.68 | 8.95 | 7.63 | 8.29 | 9.15 | 8.36 | 7.51 | 8.19 | 8.91 | 8.20 | |
| Reptile [29] | 8.27 | 8.72 | 8.73 | 8.57 | 7.80 | 8.23 | 8.43 | 8.15 | 7.67 | 8.12 | 8.25 | 8.01 | |
| FTRA(Ours) | 8.05 | 8.58 | 8.44 | 8.36 | 7.61 | 7.99 | 8.23 | 7.94 | 7.52 | 7.99 | 8.18 | 7.90 | |
| Upper-Bound | 6.51 | 6.96 | 7.28 | 6.92 | 6.51 | 6.96 | 7.28 | 6.92 | 6.51 | 6.96 | 7.28 | 6.92 | |
| Models | Approaches | 10-Day | 20-Day | 30-Day | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S-1 | S-2 | S-3 | AVE + | S-1 | S-2 | S-3 | AVE | S-1 | S-2 | S-3 | AVE | ||
| Transformer -based | Baseline [23] | 8.19 | 8.78 | 9.10 | 8.69 | 7.10 | 7.20 | 7.27 | 7.19 | 6.39 | 6.55 | 6.82 | 6.59 |
| TL-FT-Out [23] | 5.97 | 5.75 | 6.11 | 5.94 | 5.47 | 5.39 | 5.82 | 5.56 | 5.31 | 5.13 | 5.75 | 5.40 | |
| TL-FT-All [22] | 5.29 | 5.34 | 5.29 | 5.31 | 4.81 | 4.76 | 4.95 | 4.84 | 4.54 | 4.68 | 4.81 | 4.68 | |
| TL-FT-Inp | 4.55 | 5.50 | 5.71 | 5.25 | 4.14 | 4.94 | 5.31 | 4.80 | 3.98 | 4.82 | 5.20 | 4.67 | |
| Reptile [29] | 4.89 | 5.51 | 5.19 | 5.20 | 4.68 | 5.04 | 4.84 | 4.85 | 4.67 | 4.82 | 4.78 | 4.76 | |
| FTRA(Ours) | 4.36 | 5.37 | 4.98 | 4.90 | 4.23 | 4.79 | 4.84 | 4.62 | 4.04 | 4.75 | 4.80 | 4.53 | |
| Upper-Bound * | 3.41 | 3.83 | 4.07 | 3.77 | 3.41 | 3.83 | 4.07 | 3.77 | 3.41 | 3.83 | 4.07 | 3.77 | |
| LSTM-based | Baseline [23] | 11.77 | 12.13 | 12.64 | 12.18 | 9.52 | 9.09 | 10.17 | 9.59 | 8.12 | 8.31 | 9.07 | 8.50 |
| TL-FT-Out [23] | 5.57 | 5.82 | 5.76 | 5.72 | 5.33 | 5.52 | 6.41 | 5.75 | 5.08 | 5.28 | 6.22 | 5.53 | |
| TL-FT-All [22] | 5.06 | 5.24 | 5.55 | 5.28 | 4.68 | 4.75 | 5.11 | 4.85 | 4.59 | 4.67 | 4.95 | 4.74 | |
| TL-FT-Inp | 4.83 | 5.30 | 5.69 | 5.27 | 4.42 | 4.96 | 5.25 | 4.88 | 4.30 | 4.80 | 5.12 | 4.74 | |
| Reptile [29] | 4.65 | 5.63 | 5.20 | 5.16 | 4.41 | 5.28 | 5.10 | 4.93 | 4.29 | 5.13 | 4.89 | 4.77 | |
| FTRA(Ours) | 4.69 | 5.28 | 4.78 | 4.92 | 4.50 | 4.98 | 4.66 | 4.71 | 4.43 | 4.75 | 4.58 | 4.59 | |
| Upper-Bound | 3.45 | 3.82 | 4.05 | 3.77 | 3.45 | 3.82 | 4.05 | 3.77 | 3.45 | 3.82 | 4.05 | 3.77 | |
| GRU-based | Baseline [23] | 10.80 | 12.17 | 12.44 | 11.80 | 8.28 | 9.04 | 10.01 | 9.11 | 7.34 | 7.79 | 8.68 | 7.94 |
| TL-FT-Out [23] | 6.16 | 5.87 | 7.12 | 6.38 | 5.45 | 5.31 | 6.29 | 5.68 | 5.31 | 5.16 | 5.87 | 5.45 | |
| TL-FT-All [22] | 5.24 | 5.35 | 5.61 | 5.40 | 4.93 | 4.86 | 5.15 | 4.98 | 4.82 | 4.73 | 5.12 | 4.89 | |
| TL-FT-Inp | 4.68 | 5.23 | 5.87 | 5.26 | 4.19 | 4.85 | 5.45 | 4.83 | 4.11 | 4.72 | 5.33 | 4.72 | |
| Reptile [29] | 4.71 | 5.22 | 5.32 | 5.08 | 4.40 | 4.87 | 5.10 | 4.79 | 4.32 | 4.75 | 4.93 | 4.67 | |
| FTRA(Ours) | 4.55 | 5.27 | 4.87 | 4.90 | 4.23 | 4.84 | 4.78 | 4.62 | 4.18 | 4.80 | 4.76 | 4.58 | |
| Upper-Bound | 3.42 | 3.83 | 3.99 | 3.75 | 3.42 | 3.83 | 3.99 | 3.75 | 3.42 | 3.83 | 3.99 | 3.75 | |
| Settings | Models | Algorithm 1 | Algorithm 2 | Algoritm 3 * | ||
|---|---|---|---|---|---|---|
| 10-Day | 20-Day | 30-Day | ||||
| S-1 | Transformer -based | 54 | 16 | 6 | 10 | 15 |
| LSTM-based | 75 | 9 | 12 | 14 | 18 | |
| GRU-based | 14 | 7 | 8 | 14 | 15 | |
| S-2 | Transformer -based | 75 | 17 | 15 | 20 | 23 |
| LSTM-based | 100 | 41 | 22 | 28 | 31 | |
| GRU-based | 86 | 3 | 18 | 21 | 32 | |
| S-3 | Transformer -based | 18 | 22 | 4 | 9 | 13 |
| LSTM-based | 12 | 9 | 6 | 15 | 21 | |
| GRU-based | 118 | 13 | 10 | 13 | 17 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, X.; Wang, Y.; Cao, Z.; Chen, F.; Li, Y.; Yan, J. Feature Transfer and Rapid Adaptation for Few-Shot Solar Power Forecasting. Energies 2023, 16, 6211. https://doi.org/10.3390/en16176211
Ren X, Wang Y, Cao Z, Chen F, Li Y, Yan J. Feature Transfer and Rapid Adaptation for Few-Shot Solar Power Forecasting. Energies. 2023; 16(17):6211. https://doi.org/10.3390/en16176211
Chicago/Turabian StyleRen, Xin, Yimei Wang, Zhi Cao, Fuhao Chen, Yujia Li, and Jie Yan. 2023. "Feature Transfer and Rapid Adaptation for Few-Shot Solar Power Forecasting" Energies 16, no. 17: 6211. https://doi.org/10.3390/en16176211
APA StyleRen, X., Wang, Y., Cao, Z., Chen, F., Li, Y., & Yan, J. (2023). Feature Transfer and Rapid Adaptation for Few-Shot Solar Power Forecasting. Energies, 16(17), 6211. https://doi.org/10.3390/en16176211