1. Introduction
Wind turbines are considered worldwide to be the most promising renewable energy technology, and wind energy is therefore fundamental in the present energy transition era. In [
1], it is reported that the installed capacity grows on average by 30% every year, and the trend was already accelerating before the war in Ukraine. For example, the wind power growth almost doubled from 2019 (58 GW) to 2020 (111 GW) [
2].
In this context, the importance of intelligent operation and maintenance (O&M) strategies [
3] has been only growing. In [
4], it is estimated that advanced monitoring and predictive maintenance strategies can save 8% of the O&M costs and can help recovering 11% of producible energy which would be lost otherwise, provided that 25% of major drivetrain failures can be diagnosed sufficiently early. The widespread use of supervisory control and data acquisition (SCADA) systems has launched wind energy into the era of data analysis, but it is far from trivial to convert the information of the SCADA-collected measurements into reliable solutions for intelligent O&M [
5], which in turn could lead to the decrease of the levelized cost of energy.
The above premises explain why there is an abundant literature about SCADA data analysis applied to wind turbine condition monitoring [
6,
7,
8]. Actually, significant progress has been made, but there are also several open issues.
1.1. SCADA-Based Condition Monitoring and General Motivations of the Present Work
Wind turbine SCADA control systems typically acquire raw measurements with a sampling frequency in the order of the Hz. Nevertheless, this type data is not much exploited for condition monitoring and performance analysis (except for a few meaningful studies, such as [
9,
10]), mainly for practical reasons. In reality, industrial SCADA systems are still quite cumbersome regarding data storage and with regard to the harmonization of the different sampling frequencies for the various channels. Therefore, the SCADA-based condition monitoring is mostly performed by using an industrial standard, which is data averaging with a ten-minute basis. However, such an averaging time leads to the drawback that SCADA-based methods are considered to provide a late-stage indication of incoming faults.
The point, in a nutshell, is that the data frequency and achievable advance time become higher due to better understood machine dynamics. Nevertheless, SCADA data is still being widely used [
11,
12,
13,
14] because of being extremely practical and having a low cost for the end user. However, the main challenge related to the application of SCADA for fault diagnosis is the achievement of accurate and well-in-advance fault prediction, which is compatible with the requirements and needs of wind farm management.
Today, there are no established standards about the desirable performances of a SCADA-based condition monitoring for fault diagnosis. A fault-diagnosis method is always implementing a tradeoff between (1) a fault which does not occur in reality (false positive), and (2) not predicting an occurring fault (false negative). It depends on the requirements of the end-user practitioner whether a higher cost is associated with a false positive or a false negative, which means preferring high precision or high recall of the model. In this regard, an interesting methodology is proposed in [
15], in which an objective function is formulated by assuming a saving for true positive identification and a cost for false positives and false negatives. The rationale behind this is based on the assumption that detecting a true failure is far more beneficial than reducing a few additional false positives. Therefore, for addressing the suitability of SCADA-based condition monitoring it is essential to have a fair evaluation of its performance in terms of true positive identification.
Another challenge with regard to wind turbine SCADA-based condition monitoring is that there is no ground truth for training the models, which means absence of data labelling. In general, SCADA data is typically highly imbalanced [
16,
17,
18,
19,
20], due to the fact that (hopefully) the wind turbine has been operating normally for most of the time. The best approach to tackle this is by constructing a normal-behavior model [
21,
22,
23] relying on non-labelled data collected during regular operation periods. The fault is then detected by evaluating the residual between predictions and measurements. It is evident that this approach needs to sort out several open problems e.g., the definition of normal-behavior and the characterization of failure patterns.
Most of the literature studies dealing with SCADA data analysis are structured as success stories based on observations limited in time and focusing on a very circumscribed number of turbines. Such approaches are fundamentally flawed because they do not provide in-depth analysis of the critical validation points highlighted above. On the contrary, this paper offers formal investigation of the suitability of the SCADA-based condition monitoring for wind turbine fault diagnosis. More specifically, this paper performs a controlled experiment for the fair evaluation of SCADA-based condition monitoring-based, temperature-related anomaly identification. The academia–industry collaboration of this paper comes at hand for structuring the qualifying points of our controlled experiment. Courtesy of ENGIE Italia, we have had at disposal more than 11 years of SCADA data of a wind farm sited in Italy, as well as the list of failures and replacements of the most important drivetrain subcomponents. In the following
Section 1.2, we report on the most meaningful recent studies which motivate the selection of data type, features, and methods of this work.
1.2. Literature Review
As we discussed in [
24,
25], the selection of features which are most important for fault diagnosis of the component of interest depends on the sampling time of the available data. For example, vibrations collected at important subcomponents of the machine are a very powerful source for diagnostics if the sampling frequency is at least on the order of dozens of Hz, whereas in [
24] it is discussed that the use of vibration data with an average time of 10 minutes is not so meaningful. In fact, the attempts in the literature at using temperature and sound and vibration data [
26] are usually based on the integration of multiple time scale analysis, as in [
25] or in [
27], where the vibration data have a sampling frequency in the order of KHz.
Given that this paper deals only with SCADA-collected data with an averaging time of 10 minutes (as is typical in industrial systems), the soundest approach for fault diagnosis is the use of internal temperatures and working parameters, about which there is a vast literature that deserves to be summarized through some representative examples. One of the most influential studies about wind turbine fault diagnosis based on temperature data analysis is [
28]. In that study, artificial neural networks (ANN) are employed for training a normal behavior model for gearbox oil temperature, gearbox bearing temperature, and generator winding temperature, where the input variables are the produced power, the ambient temperature, and the target themselves at one and two timestamps before. In [
29], a simple method based on the average curves of internal temperatures per power intervals is shown to be effective for diagnosing main bearing faults with an acceptable advance. The study in [
30] is a mature analysis on the selection of training periods and thresholds for normal behavior modelling of various subcomponents’ temperature.s A random forest regressive model is set up upon feature selection, and alarm thresholds are formulated based on the temperature error residual distribution. It is shown that if the threshold is based on the 90th percentile, less than 120 days of training data can be acceptable, whereas up to or more than 250 days of data are needed for a 2% convergence criterion. In [
31], it is shown that physical thermal modelling can be useful for fault diagnosis on its own and also in combination with machine learning in order to disengage from a purely black box approach. Similarly, a dynamic model sensor method is formulated in [
32]. In [
33], the internal temperatures are used as independent variables, rather than dependent, and a Chow test is used to detect structural breaks in the relation between gearbox and generator temperature data as the independent variables and generator speed data as the dependent variable.
There is relatively little literature on the application of deep learning methods, which use is in general growing immensely in data science. For example, in [
34], a method based on convolutional neural network (CNN) and long short-term memory (LSTM) network is employed for constructing a normal behavior model of wind turbine internal temperatures and the threshold for alarm is individuated based on the trend and the mutation degree of the root mean square error (RMSE). In [
35], graph convolutional autoencoders are used to model the sensor network as a dynamical functional graph. A global Mahalanobis indicator for the whole set of monitored SCADA-collected channel and a local residual indicator for each channel are formulated; 12 failures on the most critical components (generator, gearbox, and transformer) that occurred over 20 months of operation are analyzed.
1.3. Novelty of the Research and Paper Structure
In this work, we concentrate for several reasons on wind turbine drivetrain failures. The most general is that, as reported in [
36], this kind of damage is associated with the highest downtime and therefore productive energy loss. Furthermore, the drivetrain failures are the most appropriate to individuate using the type of SCADA-collected data (internal temperatures and working parameters) at disposal for this study [
37], because in general large rotating components are expected to release much heat in proximity to a fault. Nevertheless, it should be noticed that the methodology we propose is general in nature and might be applied for monitoring other components [
38].
As anticipated above, a qualifying point of innovation of this work lies in the strong validation activity as we analyze a very extensive time window (more than 11 years of data) from a fleet of eight wind turbines, for which the list of the main failures and component replacements are available. This allowed us to set up a controlled experiment based on a minimal amount of information. The wind turbines which have not been affected by major component replacements are individuated as a control group, whereas those affected by replacements are the target group. For the controlled experiment, a weakly supervised method was used. Indeed, the data of a wind turbine are labelled as normal based on weak (incomplete) information (the absence of component replacements). Therefore, the envisioned method solves the data set imbalance issues by leveraging on classic normal behaviour modelling for anomaly detection [
16,
17]. In this type of architecture, the data-driven model is trained by using the turbine data when its behaviour is considered normal. Once trained, the model is used to monitor the difference—residual—between the expected behavior and the observed one. The work devotes particular attention to the fair evaluation of the methodology. The main finding of this work is that the data-driven SCADA-based condition monitoring is suitable for individuating occurring drivetrain faults with at least months of advance, provided that qualifying points are addressed, such as the selection of the target temperature to monitor and of the input features, the implementation of a rigorous methodology for normal-behavior modelling and threshold identification. This supports the idea that state-of-the-art developments allow one to overcome the prejudice regarding the fact that SCADA data provide late-stage indications of occurring faults. At present, the main limitation observed in our analysis, as well as similar ones, is related to the prognosis. Indeed, we have reported a wide variability between the various identified faults, with regard to the time between the alarm onset and the component replacement.
The structure of the manuscript is organised as follows. In
Section 2, the methodology of the controlled experiment is described in general; in
Section 3, the test case wind farm, the dataset and the concrete instantiation of the methodology on the test case are reported;
Section 4 is devoted to the presentation and discussion of the results; conclusions are drawn and further directions are outlined in
Section 5.
2. Methodology
This section presents the methodology we envisioned to perform a controlled experiment able to fairly evaluate the suitability of the SCADA-based condition monitoring system for fault diagnosis. Such a system is implemented as a data-driven method, based on a normal behavior modelling, for detection of temperature-related anomalies in turbine components. (It is important to note that we decided to implement a data-driven method because it has been proven that data-driven models can satisfactorily model complex systems such as wind turbines [
39]) As a consequence, the methodology can be used for controlled experiments related to anomaly detection in components such as drivetrain, generators [
32,
40,
41], blade pitch [
42], and blades [
43,
44].
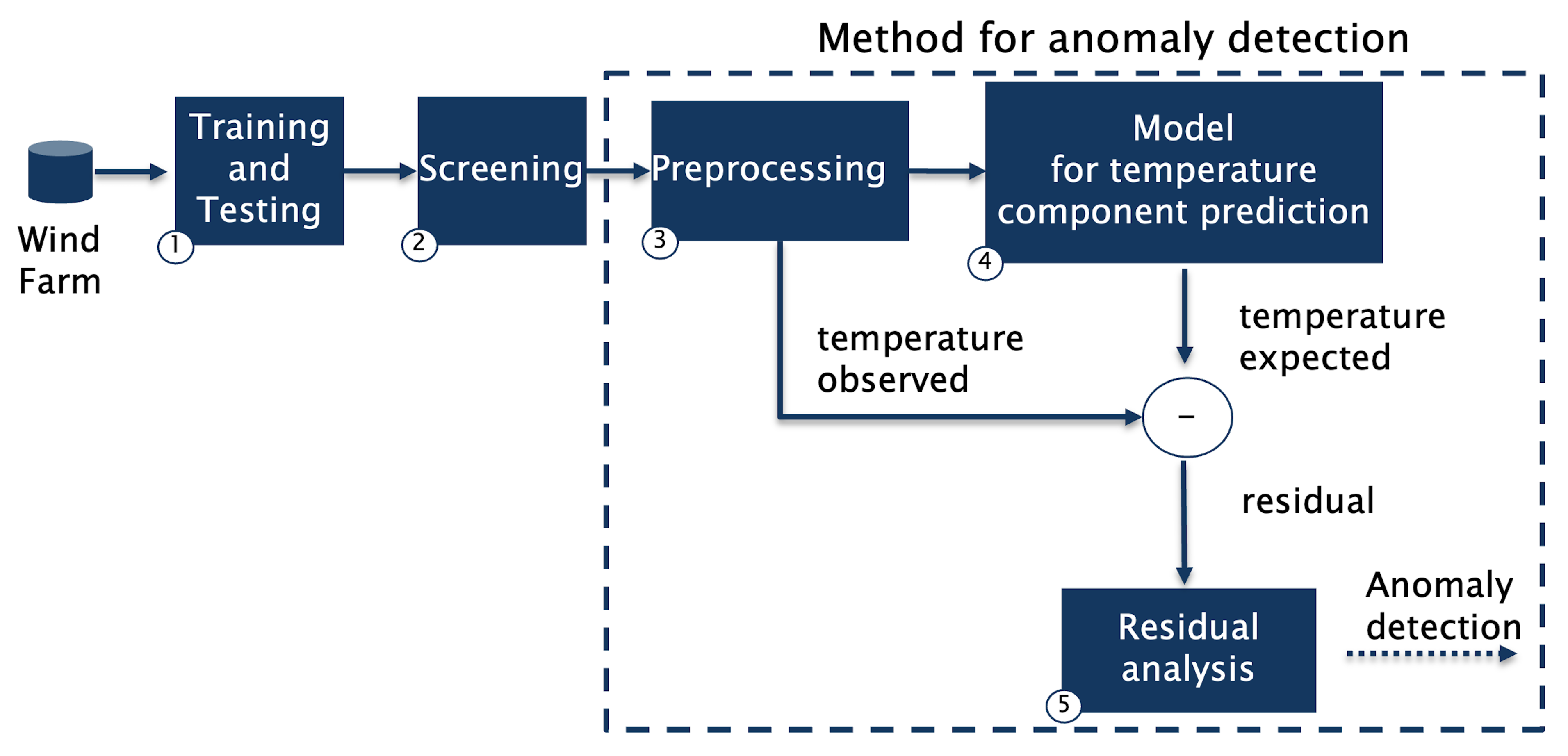
Our controlled experiment, the workflow of which is presented in
Figure 1, is divided into five steps.
As a first step, wind farm data is divided into training and testing periods. The length of the training period is defined, taking into account two factors. On the one hand, the training period needs to be long enough to expose turbines to the typical weather conditions that they can experience during their lifetime. On the other hand, the training period cannot be too long because this would delay the possibility of using the model for anomaly detection in production. As rule of the thumb, the length of the training period should be of at least one year because this allows the turbine to experience the typical weather seasonality. Furthermore, the time window of the training period needs to be as common as possible across all turbines of the fleet so that all models for temperature component prediction are trained on the data collected in the same weather conditions. This has the benefit of allowing a direct comparison of the model behaviors factoring out the environmental conditions, i.e., a difference in model predictions does not depend on the fact that the models are trained in different conditions.
As a second step, the screening activity is performed. This activity consists in analysing the maintenance records to label the turbines as normal or abnormal:
All turbines which in the training period have no failure or maintenance activity related to the turbine component of interest are retained. Subsequently, if in the testing period the turbine continues to not have any record related to a failure or maintenance activity, then the turbine is labelled as normal. All other retained turbines are labelled as abnormal.
All turbines that are not retained are discarded from the controlled experiment.
The group of normal turbines represents a control group and plays a crucial role for the controlled experiment. Indeed, the models for SCADA-based condition monitoring (e.g., for drivetrain failure detection) need to be evaluated not only in terms of failures correctly identified but also in terms of false alarms eventually raised in (failure-free) control turbines.
As a third step, the SCADA data is preprocessed. This step consists in retaining only the time stamps where the component is “active” (see
Section 3). Furthermore, for each turbine, sensor values are standardized by using a z-score based on the training period so that it can be fed to the model.
The fourth step focuses on the model for temperature component prediction. During the training phase, the training data is used to train a model able to predict the temperature expected by the component. Such a model predicts the temperature as a continuous variable. An important aspect to consider for the development of the model is whether it predicts discrete values (i.e., binary classification) or continuous one (i.e., regression) [
45]. In our case, we opted for predicting continuous values because turbine behaviour is expected to drift from normal to abnormal in a continuous manner (e.g., due to aging) and not via a sudden change. In this step, the critical point is the identification of the right temperature sensors, which can be used as a proxy to reveal the abnormal behavior of the component. The choice of the model to predict component temperature depends on multiple factors such as the amount of data available, model understandability, the computational resources available, etc. However, based on the current results presented in the literature, deep learning models are a quite common choice thanks to their ability to correctly model nonlinear and complex relationships among variables [
39]. Once trained, the model is ready to compute the expected component temperature.
As a final step, the preprocessed data is used for residual analysis. This analysis consists in either failure fingerprinting or residual monitoring.
2.1. Failure Fingerprinting
The trained model is fed with the testing data to estimate the expected temperature. The difference between the observed and the expected temperature is then used to compute the residuals. Then, the residuals are explored to verify whether at least one of three possible failure fingerprints presented in
Figure 2 is present. These fingerprints describe how temperature-related failures (such as drivetrain failures) influence the residual evolution. These patterns are generally referred to as trend, increase in variability, and spike. Failure fingerprinting is a fundamental activity for the controlled experiment. Indeed, if none of the known fingerprints is present in the testing data, then it is not possible to truly validate a SCADA-based condition monitoring.
2.2. Residual Monitoring
Residuals are analyzed to identify any of the failure patterns identified during the failure fingerprinting. For instance, in the case of impending failures which cause upward or downwards trends, residual monitoring is instantiated as a threshold-based approach which raises an alarm when the residual goes above a certain threshold.
3. Experimental Setup
This section provides details on how the general methodology presented in
Section 2 can be instantiated for the detection of drivetrain failures.
3.1. Dataset
The dataset used in the analysis consists of 10-min aggregated SCADA data from an onshore wind farm. For all turbines we have 11.5 years of recorded data. For our experiment, the first two years of data are used as training, the third year is used for validation, and the remaining eight-and-a-half years are used for testing. The turbines have variable speed, hydraulic pitch regulated, rated power of 2 MW, and are equipped with a three-stage gearbox, a permanent magnet generator, and a full-scale converter. The list of available sensors in the SCADA system is reported in
Table 1.
There are only three temperature sensors available in the gearbox—one on the gear main bearing, one on the high-speed shaft bearing, and one in the gearbox oil sump. In this farm, we also had access to maintenance records (i.e., failure and replacement dates of critical components), which are summarized in
Table 2 for the target wind turbines.
For the turbines T6 and T7, we have the timestamps of the failures. For T5 and T8, this information is not available. For this reason, we use as a proxy the timestamps of maintenance activity. We suppose that the maintenance activity on the drivetrain is allegedly connected to an impending failure of the drivetrain. We consider this assumption likely because replacing a gearbox or shaft is a quite expensive activity which is not performed on a regular basis just for preventive maintenance.
It is important to notice that there is a perfect overlap in the three years of data used for training and validation for all turbines, including control turbines T1–T4, except for T6. For the latter turbine, the training period is shifted six months ahead because in the first six months a major maintenance activity was performed. As a consequence, all models are trained when the turbines are experiencing the same environmental conditions.
The experiment set up through the above described test case is vaster than most of the state-of-the-art works. To the best of our knowledge, there are no studies dealing with 11.5 years of SCADA data. With regard to the number of selected target wind turbines, from the literature review it arises that most studies employ even only one validation case (as, for example, [
12,
13] and many other studies), three in [
14,
18], four in [
15], and so on.
3.2. Screening and Preprocessing
In the screening activity we selected four turbines as abnormal and four turbines as normal (i.e., control turbines). As preprocessing, we retain only the timestamps where the temperature of gear bearing, gear oil, and generator bearing is above 30 C. We consider this threshold as a proxy to identify when the drivetrain is active, i.e., it is actually used for energy production.
3.3. Model for Temperature Component Prediction
The first step for instantiating the model for temperature component prediction is the selection of the sensors that can be used as a proxy to detect drivetrain anomalies. For this purpose, we decided to focus on gear oil, gear bearing, and generator bearing. We refer to these variables as target variables of the model. The selection of these sensors is made based on the fact that they are located in the drivetrain. As input variables to predict the target variables, we use the one reported in
Table 3 (left column). These variables are chosen because they correlate, to different extents, with the different target variables, as shown in
Figure 3. As can be seen, almost all input variables have a good correlation with the output variables. The only exception is represented by the outside temperature which presents no linear correlation with the target variables’ gear bearing and gear oil temperature. We still included the outside temperature as an input variable, because it is known that this has a nonlinear influence on the internal temperatures [
46].
For each one of the target variables, we use a deep learning algorithm to model their expected behavior. The typically used deep learning models can be divided into three typical architectures: the feed-forward neural network (FFNN), the recurrent neural network (RNN), and a convolutional neural network (CNN). This paper uses a CNN architecture because it can exploit, unlike the FFNN, the temporal aspect of the different time series, and there is evidence that CNNs have similar performance to RNNs for sequence modelling [
47,
48] while being computationally cheaper. For each turbine, a 1D CNN model is created, whose architecture is reported in
Figure 4. The CNN is trained on the first two years of data, validated on the third one, and finally tested on the remaining nine years. The usage of two years for training is based on the need to create a rather reliable and robust model. On the one hand, one year of data should suffice to train the model on all typical weather conditions which a turbine can experience over the seasons. On the other hand, we decided to use two years to (1) reduce the chance of selecting one year for training characterized by weather conditions which are outliers and (2) to better handle the downtime present in the training period. The latter is due to the fact that turbines can shut down for some time periods. Although for most turbines, this time period in the training time was typically only a few days or weeks, T5 was not operational from July 2011 until January 2012. By choosing two years of training data, we ensured that there was data for each season for each data. Each input sample consists of six timestamps (i.e., 1 h), with the different input variables put in different channels. If a sample any of the input variables has missing data during that time window, it is discarded. Although the input sample consists of multiple timestamps, the target value corresponds to just one timestamp: the final timestamp of the corresponding input sample. Given the number of timestamps and input features, the input shape of each sample is
. This can be seen schematically in
Figure 5. The model is trained by minimizing the mean squared error (MSE). This loss function was chosen so that high errors in the prediction are penalized more compared to other loss functions like the mean absolute error. The training was done over 100 epochs, but was stopped early if the validation loss did not improve over 10 epochs. This was done to prevent overfitting. The model was implemented and trained by using Keras [
49], and the details of its architecture are reported in
Figure 4.
3.4. Failure Fingerprinting
For each turbine, the maintenance records are manually scrutinized to identify failures which are connected to the drivetrain (e.g., failure of high speed shaft or gearbox). Then, the residual evolution related to gear oil, gear bearing, and generator bearing is visually analyzed to identify whether impending failures on the drivetrain have one of the expected temperature-related fingerprints. During this step, we identified multiple cases in which the residual evolution presents an upward trend before a failure connected to the drivetrain. An example in this respect is presented by the clear upward trend (red solid line) of the gear bearing temperature residuals in
Figure 6. As
Figure 6 shows, the original residuals (black dots) present a certain level variability which hinders the possibility to highlight its trend. As a consequence, we decided to smooth the residual by applying a yearly rolling average. To perform the smoothing, the standard implementation in the Python package Pandas was used. Pandas allows us to compute the mean average even for timestamps for which there is less than one full year of data available. In this case, the mean is computed by considering all previous timestamps. The choice of a time window of one year was made based on a tradeoff. On the one hand, if the time window is too short (e.g., one month), then the smoothing process would be too mild and it will lose its primary objective of highlighting the trend. On the other hand, if the time window is too large (e.g., more than one year) then the trend would not be able to show a sudden change (e.g., due to a break down). Taking into account these conditions, the smoothing process was decided based on the analysis of the residuals in the training period. In addition to trend, we also scrutinized residuals looking for increase in variability or spike before a maintenance activity. However, for this test case, these manifestations have not been observed.
3.5. Residual Monitoring
During the failure fingerprinting, the analysis of the residuals provides only evidence of the presence of trends associated with impending failures. This suggests that a SCADA-based condition monitoring relying on thresholds can be implemented to detect drivetrain failures. However, the identification of this threshold is not trivial, and it represents a challenge for any condition-monitoring system, which is threshold-based. Indeed, if the threshold is set too low, this can cause too many false alarms. On the other hand, if the threshold is too high, this can cause missing anomalies, which are supposed to be investigated. In this work, as a compromise, we use a 3 sigma-rule (a simple and widely used heuristic for anomaly detection [
50]) to set up a starting reference threshold as an upper bound, which can eventually be updated by the operator over time or based on their experience. These thresholds should be considered as a starting reference point for the operator monitoring turbine behavior. Indeed, when the alarm is raised, the operator may further inspect the behavior of the turbine (e.g., power curve, torque, etc.) and decide whether or not it requires maintenance activity. On the one hand, if it is decided that no maintenance activity is required, then the threshold can be raised further by the operator in order to trigger an alarm in case the drift further increases. On the other hand, if the maintenance activity was required, the operator can look back at the residual evolution to see when the drift started and accordingly lower down the threshold for the next time. An example of thresholds based on the 3 sigma-rule is presented in
Figure 7. This figure illustrates that the trend of the gear bearing temperature (red solid line) going beyond the threshold (horizontal dash-dotted red line) is observable several months before the replacement of the gearbox (vertical red dashed line). The thresholds are turbine-dependent, i.e., they are computed by taking into account the typical residual variability of each turbine in the training period. The tuning of the threshold can be derived on a subset of turbines (e.g., based on model performance metrics such as precision, recall, accuracy, etc.) and then tested on the remaining turbines. However, in this use case, the number of anomalous turbines is too small to further split anomalous turbines in two groups.
4. Results & Discussion
This section evaluates to what extent the instantiated SCADA-based condition monitoring is suitable for drivetrain fault diagnosis.
4.1. Model for Temperature Component Prediction
In this section, we investigate whether the instantiated models for the prediction of component temperatures are suitable for normal behavior modelling. This is the primary step by which to verify whether the extracted residuals are meaningful, i.e., whether they can be trusted for detecting anomalies.
Table 4 reports the mean absolute error (MAE) and R2-score for the trained and tested 24 models (8 turbines × 3 predicted temperatures). The validation data was used to monitor overfitting and an early stopping criterion was used to stop further training once the validation loss is no longer improved. On the one hand, the normal turbines (marked as N) show very good prediction of the gear bearing temperature and gear oil temperature (MAE
C and R2
) for the testing period. These results are aligned or even better than the ones presented in literature. For example, in [
14] the achieved mean square errors range from
C to
C and the mean absolute errors in [
25] for the reference healthy wind turbines are in the order of
C. This supports that once trained, the normal data-driven behaviour model can correctly predict the normal gear bearing and gear oil temperatures. On the other hand, abnormal turbines (marked as A) generally present worse MAE and R2 during testing. This is a good result because it highlights that the observed temperature drifts from the one expected in case of impending failures.
Looking at the generator bearing temperature, we can see that models’ predictions are much worse for normal and abnormal wind turbines in the testing period. These results can be explained by the fact that relying only on SCADA data to model the thermal behavior of the high-speed drive is not sufficient. Indeed, further information sources (like vibrations or currents) are often employed for the monitoring of the generator bearing [
51].
4.2. Residual Monitoring
In this section, we evaluate whether all residual trends associated with component temperatures are suitable to distinguish normal turbines from abnormal ones. This is another fundamental step to verify whether the instantiated SCADA-based condition monitoring can equally distinguish true positives (failures) and true negative (nonfailures). For this reason,
Figure 8 shows the residual trends for all turbines for the three predicted temperatures. Normal turbines, T1–T4, are shown in green, and the abnormal ones, T5–T8, are shown in separate colours. The time of the failures or maintenance activity is shown for each turbine in its corresponding color.
As a first step, we analyze the evolution of the gear bearing temperature. As the top panel of
Figure 8 shows, all turbines exhibit residuals close to 0 in the training period (shown as dotted lines). Then, the abnormal turbines (T5–T8) present a trend increase of the residuals whereas the control group of turbines (T1–T4 ) continue to have low residuals till 2020. It is worth recalling that based on the setup of the experiment, the environmental conditions are factored out (see
Section 2). As a consequence, we infer that the different model behaviors, i.e., residuals, are likely caused by anomalies or impending failures. Focusing on abnormal turbines, we notice that these linear-like trends are observable before the failure is reported in the drivetrain. A special case is represented by turbine T8 which has a sudden "bump" around mid-2014. This behavior occurs upon a blade replacement. We do not have information whether, contextually, other interventions have been performed on the wind turbine. By including as a point of reference the control group, and observing on the entire time window of the controlled experiment, it is possible to highlight that there is a contiguity in terms of behavioural drift between turbines with and without drivetrain failures. On the one hand, these results prove that the residual trend of the gear bearing temperature can be exploited for highlighting temperature-related issues affecting the drivetrain, i.e., it can be used to a certain extent to distinguish normal and abnormal turbines. On the other hand, these results also highlight that a common threshold for all turbines should not be used to raise alarms as sometimes proposed in literature [
21]. Indeed, a threshold that works for T5 and T6 would raise the alarm years before the failure for T7 and T8. Finally, we can also observe that for normal turbines the trend becomes larger than 1
C during the final year of data. This could indicate an upcoming failure as we explain in the next subsection.
As a second step, we analyze the gear oil temperature, shown in the middle panel of
Figure 8. In this case, the residuals associated with abnormal turbine T7 present a clear drift from the control turbines, whereas abnormal turbines T5, T6, and T8 have residual trends, which are comparable with control turbines. This shows that the residual trend of the gear oil temperature can be exploited to a lesser extent for detecting temperature-related issues affecting the drivetrain. For this reason, we will not rely on this model for our further analysis. It is interesting to notice that for the gear oil temperature, the trend is negative, meaning that the deviation from normal expected behaviour is due to the gear oil temperature being lower than expected. A possible explanation for this result is that the gear bearing temperature increases, which means that heat is dispersed at the bearing, and this temperature is used as input variable for the gear oil temperature modelling. Recalling
Figure 3, the input variable which has the highest correlation with the gear oil temperature is exactly the gear bearing temperature and, as the latter increases, the model would likely predict an increase of the former as well. In case this does not occur as expected, because the heat is dispersed at the bearing, the observed residual between gear oil temperature measurement and prediction is negative.
As the final step, for completeness we report in the bottom panel
Figure 8 the generator bearing temperature also. As can be seen the trends of the turbines without failure reach higher values (up to ∼
C) with respect to the turbines with failure. This further confirms that the model for predicting generator bearing temperature cannot be used for anomaly detection.
4.3. Threshold-Based Anomaly Detection
In this section we evaluate whether a threshold-based approach can be used to detect anomalies based on gear bearing temperature. This is the final step to validate the suitability of a SCADA-based condition monitoring system relying on thresholds for the identification of temperature-related anomalies.
Figure 9 shows for all turbines the residual trends of the predicted gear bearing temperatures along with the 3-sigma threshold.
As a first step, we focus on the thresholds on both normal and abnormal turbines. By comparing their values, we observe that thresholds are rather similar. Indeed, they differ for less than 0.5 C. This can be explained by the fact that the thresholds are computed during the training phase, i.e., during the first two years of data where all turbines were behaving normally.
As a second step, we focus on the abnormal turbines.
Figure 9 shows that for all turbines with a drivetrain failure the residual goes above the thresholds. A special case is represented by turbine T8. Looking at the biweekly trend (solid gray line), we can see the residuals suddenly increase above the threshold at the beginning of 2014, upon a maintenance intervention, which is not related to the drivetrain (as far as we know). The presence of this bump, however, does not affect the line of reasoning. If we remove the first six months of 2014, we can still observe an upward trend of the residuals which would have eventually raised the alarm. In this sense, for T8 we can also conclude that the residual goes above the threshold before the drivetrain failure. These results highlight that the threshold-based approach which relies on gear bearing temperature can correctly detect all failures, i.e., it is suitable for condition monitoring [
15]. However, we can also observe that the time span between the time the alarm is raised and the time the failure is observed can be very different across turbines. In some cases the time span can be a few months, and in other cases it can be years. This is a critical point which shows that the threshold-based approach is not suitable to determine the remaining useful life time of the component, i.e., it does not allow predictive maintenance.
As a third step, we focus on the turbines in the control group. Here we can see that for T4 a temperature-related alarm is raised (due to the trend which goes above the threshold). Upon private discussion with the turbine owner, there is no report which can confirm the presence of an anomaly. However, it is still possible that an impending fault at an early stage is present but not yet noticed by the maintenance team. This is a likely scenario because the threshold-based approach already proved to be able to detect in advance all failures in abnormal turbines. In any case, the turbine owner will closely continue to monitor the turbine because avoiding false negatives is crucial for preventive maintenance [
15].
5. Conclusions
This paper focuses on the suitability of data-driven SCADA-based condition monitoring for wind turbine fault diagnosis. As discussed in detail in
Section 1, the temperatures collected at meaningful subcomponents are widely used for this purpose.
The method applied in this paper can be considered weakly supervised because it is based on modelling the normal behavior of each wind turbine, in which the models are trained by using datasets about which weak information is known (absence of component replacements) and weak assumptions are made (absence of component replacements indicate normality). The paper is built around a controlled experiment in which the suitability of SCADA-based condition-monitoring system is evaluated by using turbines with and without failures or replacements. Such a system, instantiated as a threshold-based alarm-raising model, proved to be suitable for the identification of all drivetrain failures with a considerable advance time (at least months, if not even years), and this is the most important priority (diagnosis) for wind farm operators.
In
Section 1, it has been discussed that the use of SCADA data for wind turbine fault diagnosis has been for a long time undermined by the prejudice that it is prohibitive to obtain a sufficient advance time with respect to the fault. The results collected in
Section 4 support that this prejudice becomes obsolete if state-of-the-art methods in artificial intelligence are employed for implementing a well-designed, data-driven methodology following formal training and validation principles, as is done in the present work. Nevertheless, the advance times obtained for the test case of this study go from weeks to years, which suggests that the threshold-based methodology proposed in this paper is more appropriate for the diagnosis than for the prognosis (i.e., predictive maintenance). With regard to the application for the prognosis, indeed, the alarm raising can be considered weak information because, at this stage of development, it is critical to employ it for intelligent O&M algorithms. However, it should be pointed out that weak does not mean useless, because such a high identification of true positives suggests that the use of SCADA data constitutes at least an excellent first advice for further inspections on wind turbines suspected of anomaly.
There are several further directions of this paper which are worth pursuing. The most straightforward ones deal with how to implement practically such a method in the industry and how to generalize it to other components. Actually, in this work we have employed quite long datasets for training the model, which led us to appreciably low average prediction errors. A deeper analysis of the statistical significance of the results in relation to the size of the training period (as done in [
30]) would be beneficial. The rigorous methodology implemented in this work should allow replicating it, using appropriately different features, for monitoring other important wind turbine components, for example, the blade pitch [
38,
42,
52,
53,
54].
The general perspective to pursue further involves how to extend the suitability of a SCADA-based condition-monitoring system for prognosis, which is a topic at the early stages in wind energy literature [
10,
55]. The results of this study have been achieved by monitoring the main gear bearing temperature, similar to what was reported in several studies in the literature [
56], which makes sense because such an important component releases more heat when rotating, especially in the presence of damage. For example, in the recent study [
57], the authors identify a generator stator fault by using the main gear bearing temperature. Higher specificity of the alarm raising would likely be achieved by targeting more precisely located temperatures, which is challenging, as the less accurate results about the generator bearing temperature monitoring in
Section 4 suggest. The solution to this issue which is proposed in [
25] is combining several data sources with different sampling time, as SCADA data and vibrations collected by the turbine condition monitoring (TCM) system. Focusing instead on the use of only SCADA data, a physical model of the heat flow in the drivetrain could be a good step forward and first achievements are being reached in this regard [
31,
58]. For several reasons, however, it is more practical to employ models that are solely data-driven and, in this sense, the progresses in explainable artificial intelligence [
59] are promising for understanding the causal relations between multifeatures of complex systems. First results have been achieved in the use of Granger causality tests [
60] and Shapley coefficients [
61] for the comprehension of wind turbine performance. This kind of method, as well as a more systematic analysis, should be applied also to wind turbine condition-monitoring problems.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}