1. Introduction
According to the second-quarterly (Q2) data of 2021 from the Alternative Fuels Data Center, the United States hosts 128,474 public and private electric vehicle charging station (EVCS) ports in 50,054 different station locations [
1]. In 2021 alone, charging stations increased by more than 55% in the United States. This upsurge is anticipated to grow further along with the announcement of the Bipartisan Infrastructure law to build out the nationwide electric vehicle network in April 2021 [
2]. In February of 2022, USDOT and USDOE announced
$5 billion over five years for the new National Electric Vehicle Infrastructure (NEVI) program. In February of 2022, USDOT and USDOE announced
$5 billion over five years for the new National Electric Vehicle Infrastructure (NEVI) program under the Bipartisan law to create a network of electric vehicle (EV) charging stations and designated alternative fuel corridors on the interstate highway [
3].
In contrast with the broad interest and investment in transportation electrification and EVCS deployment, the cyber-physical security hygiene of EVCS standalone/network is often slow-paced, poorly defined, and understudied [
4,
5,
6,
7]. The internet-facing elements of EVCS are primarily designed for communications and controls with other internet of things (IoTs) and stakeholders such as EV, EV operators, grid, Supervisory Control and Data Acquisition (SCADA), EVCS owners, and push the air-gapped critical physical infrastructures to the internet [
8]. It could potentially open up large attack vectors for the interconnected systems of the EVCS. We present a brief review of the cyberattack detections and mitigations efforts in EVCS from the next paragraph that lays the foundation towards automated cyberattacks mitigation in EVCS.
The works of [
9,
10,
11,
12,
13] assessed the impacts of cyber-enabled physical attacks on EVCS infrastructures ranging from disruption, damage, hijack, and so on. On that note, researchers have worked on numerous detection methods implementing different computational intelligence algorithms, including machine learning and deep learning [
7,
9,
13,
14,
15]. Reference [
7] designed and engineered a deep learning-powered [deep neural network (DNN), long short-term memory (LSTM)] network intrusion detection system that could detect DDoS attacks for the EVCS network based on network fingerprint with nearly 99% accuracy. Similarly, ref. [
9] developed a stacked LSTM-based host intrusion detection system solely based on a local electrical fingerprint that could detect stealthy 5G-borne distributed denial of service (DDoS) and false data injection (FDI) attacks targeting the legacy controllers of EVCS with nearly 100% accuracy. Furthermore, several deep learning-based ransomware detection engines have been proposed, tested, and evaluated that can share the information in a cloud-based or distributed ransomware detection framework for EVCS [
10]. Recently, generative AI models were deployed to train the detectors to tackle the cyberattack data scarcity problem. Our previous work successfully achieved more than 99% performance metrics in detecting the DDoS attacks on EVCS infrastructure [
13].
De et al. designed a control-oriented model-based static detector (deviation in battery cell voltage) and a dynamic detector (using system dynamics) algorithm to detect denial of charging attacks and overcharging attacks on plug-in electric vehicle (PEV) battery packs [
14]. The threshold-based static and filter-based dynamic detection techniques have the least flexibility toward advanced persistent threats (APT) and evolving zero-day attacks.
There have been attempts to address the mitigation of cyberattacks on smart grid paradigms [
15,
16,
17,
18,
19,
20,
21,
22,
23]. However, no works have exactly addressed the mitigation, defense, and correction for the cyber-physical attacks on EV charging infrastructures. Girdhar et al. used the Spoofing, Tampering, Repudiation, Information Disclosure, Denial of service, Elevation of privilege (STRIDE) method for threat modeling and a weighted attack defense tree for vulnerability assessment in the ultra-fast charging (XFC) station [
15]. The Hidden Markov Model (HMM)-based detection and prediction system for a multi-step attack scenario was proposed. The proposed defense strategy optimizes the objective function to minimize the defense cost added by the cost of reducing the vulnerability index. As a means of defense/mitigation, the authors recommended isolating and taking the compromised EVCS off the interconnections and intercommunication. The traditional isolation-based protection approach fails miserably in the smart grid due to the availability constraints of electricity and few reserved physical backups. On this note, Mousavian et al. implemented mixed-integer linear programming (MILP) that jointly optimizes security risk and equipment availability in grid-connected EVCS systems [
16]. Still, their model aimed to isolate a subset of compromised and likely compromised EVCS, ensuring minimal attack propagation risk with a satisfactory level of equipment available for supply demand.
Acharya et al. derived the optimal cyber insurance premium for public EVCS to deal with the financial loss incurred by cyberattacks [
17]. However, the cyber insurance does not address the mitigation of attack impacts. Reference [
18] proposed the proportional-integral (PI) controller-based mitigation approach for the FDI attack on microgrids. This method is based on the reference tracking application. A feed-forward neural network produces the reference voltage required for the PI controller, and the PI controller injects the signal to nullify the FDI. The problem with the method is that the neural networks optimized under the microgrid’s normal operating conditions may produce unreliable reference signals under adversarial conditions such as manipulated inputs. Recurrent neural networks better deal with reference tracking problems than regular feed-forward networks. The proposed model imposes additional hardware requirements and is not efficient enough to deal with non-linear and periodic FDI attacks. Reference [
19] implemented the DRL-based approach for mitigating oscillations of unstable smart inverters in distributed energy resources (DER) caused by cyberattacks. The adversary who gained system access can reconfigure the control settings of the smart grid to disrupt the distribution grid operations. To mitigate the impact, the authors trained the actor-critic-based proximal policy optimization (PPO) DRL to develop the optimal control policy to reconfigure the control settings of uncompromised DERs. However, this article has not presented the DRL efficacy of mitigation methods. Reference [
20] proposed the concept of an Autonomous Response Controller that uses the hierarchical risk correlation tree to model the paths of an attacker and measures the financial risk at cyber physical systems (CPS) assets. Recently, deep learning powered mitigations engine are evolving with improved adaptation to system dynamics and control actions [
24].
Based on the above discussions, it appears that state-of-the-art algorithms have progressed well for attack detection and prediction in EVCS, aided by cutting-edge computational intelligence at in-network and standalone levels. However, the current state-of-the-art lacks a proactive vision for developing embedded intelligence that could defend/correct the attacks on the EVCS controllers.
Above all, there is an imminent need to develop data driven distributed intelligence to proactively and independently defend the critical process controllers under the threat incidence. It motivates us to design, implement, and test local, independent agent DRL-based cyber defense clones (software agents) that could detect and mitigate controller-targeted APT in the EVCS charging process.
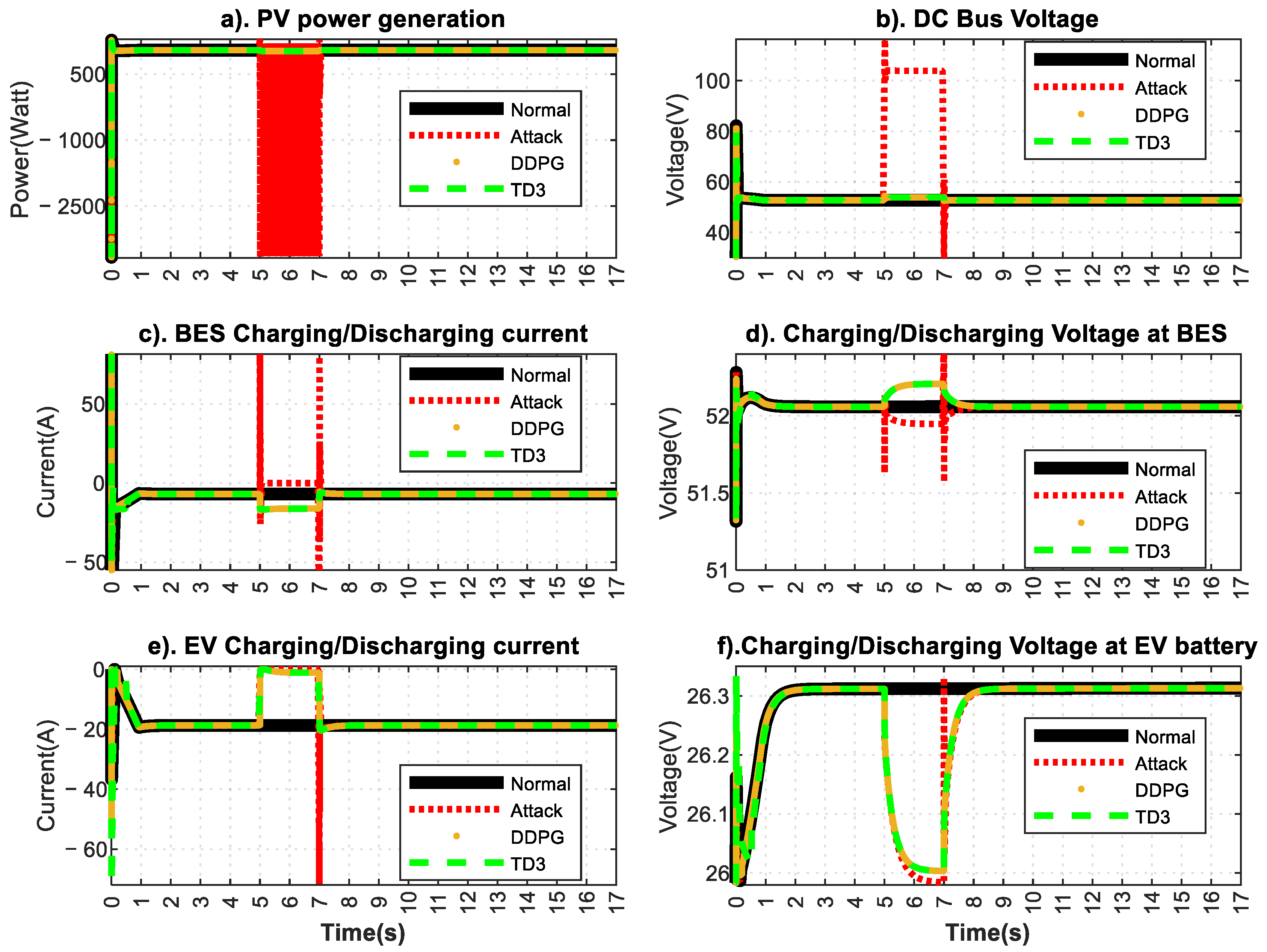
To fill the gap in cyber-physical defense research at EVCS, we propose novel, independent multiple-agent RL-based clones that oversee the critical functionality of all the controllers in the system and corrects and defend them under the detection of threat incidence as well as an anomaly. The proposed software agents operate solely based on the local data at EVCS to be purely air-gapped. Without shutting down the process, they can take over all the infected and frozen controllers under the worst cyberattack, such as ransomware and/or APT. In addition, the proposed TD3-based clones mitigation approach is designed, verified and compared against the benchmark Deep Deterministic Policy Gradient (DDPG) clones. For the verification of proposed algorithms, the PV-powered, off-the-grid standalone EVCS prototype with a battery energy storage (BES) and an EV with the corresponding control circuitry of MPPT controller, PI controller-based BES controller, and EV controller are designed. The APT attacks (Type-I: low-frequency attack, Type-II: constant magnitude attack) are engineered and launched on the duty cycle of the controllers. Since the scope of the paper is defense/mitigation, a threshold-based detection engine is used for simplicity. We summarize the contribution of this paper as follows:
Proposed novel data-driven controller clones with TD3-based algorithm that could correct or take over the legacy controllers under APT detection.
Agents can learn and adapt control policies online, accommodating changes in EVCS dynamics or configurations, a feature lacking in traditional legacy controllers.
The proposed agents successfully restore the regular operation under the APT attacks and system anomaly on the legacy EVCS controllers.
Finally, the proposed digital clones with TD3 outperforms the benchmark DDPG-based clones in terms of stability, convergence, and mitigation performance.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}