1. Introduction
In today’s society, the urgent need to address global climate change and the demand for sustainable energy sources have brought clean, renewable energy forms to the forefront [
1,
2]. As we strive to reduce our reliance on traditional fossil fuels, cut down greenhouse gas emissions, and work towards achieving carbon neutrality goals, wind energy is gaining widespread attention and acclaim. Wind energy, as a clean, economical, and renewable energy source, holds immense potential to provide us with clean electricity while alleviating our carbon footprint and meeting the ever-growing power requirements [
3].
However, despite the significant advantages of wind energy, it comes with its own set of challenges, one of which is its inherent uncertainty and variability. Wind energy generation is influenced by fluctuations in wind speeds, posing challenges for its effective integration into the power grid. Consequently, in the wind energy sector, wind speed forecasting has become a critical component. Wind speed directly impacts the output of wind turbines, which are at the heart of wind energy conversion systems. Therefore, accurate wind speed prediction is crucial for the safety of the electrical grid and the efficient operation of wind power systems. Precise wind speed forecasting contributes not only to ensuring the reliability of wind energy systems but also to enhancing energy supply stability, reducing operational costs, and aiding in the pursuit of carbon neutrality goals. Additionally, possessing reliable uncertainty information in forecasts can mitigate risks in the planning of wind energy systems, instilling confidence and feasibility for investors and operators.
To meet the demands of wind speed prediction, researchers and engineers have been exploring various wind speed forecasting methods. These methods can be broadly categorized into three major classes: statistical learning methods, traditional machine learning methods, and deep learning methods. Although various methods exhibit potential in the field of wind speed prediction, there is currently a lack of comprehensive comparison among them. Understanding the performance and advantages of different methods is crucial for determining which one to choose in specific circumstances. Therefore, this study aims to conduct a comprehensive comparative analysis of eight wind speed prediction models: AutoRegressive Integrated Moving Average (ARIMA) and the Grey Model (GM), Linear Regression (LR), random forest (RF), Support Vector Regression (SVR), Long Short-Term Memory (LSTM), Artificial Neural Network (ANN), and Convolutional Neural Network (CNN). The objective of this research is to determine which model performs best in various scenarios, providing more accurate wind speed forecasting tools for the wind energy industry and contributing to the achievement of carbon neutrality goals. Through in-depth performance comparisons, our study will offer valuable insights for decision makers, engineers, and investors, optimizing the operation and planning of wind power systems, and advancing a cleaner and more sustainable future, thereby contributing to the realization of carbon neutrality goals.
In recent years, the field of wind speed prediction has witnessed significant advancements, with researchers proposing various models to address this challenge. These models can be broadly categorized into three types: statistical models, traditional machine learning models, and deep learning models. Statistical models encompass traditional time series methods such as ARIMA and models based on physical principles. Traditional machine learning models include decision trees, random forests, support vector machines, and others, showcasing a strong performance in data-driven wind speed prediction. Simultaneously, deep learning models like Recurrent Neural Networks (RNNs) and CNNs have garnered considerable attention due to their proficiency in handling complex nonlinear relationships. The following literature review will delve into the applications and performances of these three major model categories, aiming to provide a comprehensive understanding of their utility.
In the field of wind speed prediction, the application of statistical models exhibits varied and significant potential. Ref. [
4] introduced a short-term wind speed prediction method based on gray system theory, successfully applied in the Dafeng region of Jiangsu province, China, and providing accurate data for short-term wind energy assessment. Ref. [
5] proposed an innovative wind speed prediction method that utilizes Variational Mode Decomposition (VMD) to decompose wind speed into nonlinear, linear, and noise components. Models for each component were constructed, enhancing the stability of wind power systems. However, ref. [
6] investigated nested ARIMA models, which effectively captured wind speed fluctuations but exhibited notable differences in extreme fluctuation distributions. Ref. [
7] compared various time series models and found that BATS and ARIMA performed best on test data. Ref. [
8] further improved the gray system model by introducing fractional-order gray system models and a neural network-based combination prediction model, significantly enhancing prediction accuracy. Finally, ref. [
9] employed a Polynomial AutoRegressive (PAR) model for wind speed and power prediction, and the results demonstrated the superiority of the PAR model when predicting wind speed and power, with a forecast horizon exceeding 12 h. These studies provide a range of methods for wind speed prediction, although their performance and applicability are influenced by variations in data and geographical locations, collectively offering substantial support to the wind energy industry.
In the field of wind speed prediction, research on traditional machine learning models has made significant strides, providing robust tools to enhance prediction accuracy and reliability. Ref. [
10] introduced a wind speed probability distribution estimation method based on the law of large numbers and integrated it with an SVR model, demonstrating its remarkable effectiveness through experimental results. Ref. [
11] applied the ANN model to wind speed prediction at micro-level locations, serving as a decision support tool for early warning systems and underscoring the feasibility of ANNs in the prediction process. Ref. [
12] introduced a weighted RF model optimized by wavelet decomposition and a specialized algorithm for ultra-short-term wind power prediction, exhibiting exceptional accuracy and stability in the presence of noise and unstable factors. Ref. [
13] proposed a short-term wind power prediction model that employs two-stage feature selection and supervised RF optimization, showing superior accuracy, efficiency, and stability, particularly in scenarios with high noise data and wind power curtailment. Additionally, ref. [
14] introduced a ν-SVR model tailored for complex noise in short-term wind speed forecasting, achieving significant performance improvements. Finally, ref. [
15] employed kernel-based Support Vector Machine Regression models, comparing various kernel functions and highlighting the superior performance of the Pearson VII SVR model. Collectively, these studies underscore the pivotal role of traditional machine learning models in the field of wind speed prediction, providing diverse methods and pathways for various application scenarios, thereby enhancing prediction accuracy and positively impacting the wind energy industry and renewable energy management.
Deep learning models have achieved remarkable advancements in the field of wind speed prediction, offering powerful tools to enhance prediction accuracy and reliability. Ref. [
16] utilized 13 years of wind speed data from the Qaisumah region and established an Artificial Neural Network model, demonstrating its outstanding performance with low mean square error (MSE) and mean absolute percentage error (MAPE) values. Ref. [
17] introduced a multi-wind farm wind speed prediction strategy tailored to centralized control centers, leveraging the deep learning model Bi-LSTM and transfer learning to achieve high accuracy and broad applicability. Ref. [
18] presented a hybrid model for wind speed interval prediction, using an autoencoder and bidirectional LSTM neural network, highlighting the feature extraction effectiveness of the autoencoder in time series forecasting. Ref. [
19] focused on the prediction of wind speeds at multiple locations, introducing a two-layer attention-based LSTM model named 2Attn-LSTM, which encodes spatial features and decodes temporal features through variational mode decomposition, outperforming four baseline methods. Ref. [
20] proposed an indirect approach to wind direction prediction by decomposing wind speed into crosswind and along-wind components, utilizing LSTM models and Empirical Mode Decomposition (EMD) to predict these components, thereby enabling wind direction prediction. The effectiveness of this approach was demonstrated using one month of wind monitoring data. Ref. [
21] introduced a wind speed prediction model based on an LSTM neural network optimized using the Firework Algorithm (FWA) to enhance hyperparameter performance. Focusing on the real-time dynamics and dependencies in wind speed data, the optimized model demonstrated a reduction in prediction errors and improved accuracy compared with other deep neural architectures and regression models. Ref. [
22] presented a hybrid PCA and LSTM prediction method, leveraging PCA for meteorological data preprocessing and optimizing LSTM with the DE algorithm for superior predictive performance, particularly in wind speed prediction. Ref. [
23] developed a hybrid deep learning model for short-term wind speed forecasting, with a comparative analysis showing that the CNN-BLSTM consistently outperformed other models across various time series and heights. Ref. [
24] introduced a custom-designed CNN-based deep learning model for solar wind prediction, effectively tracking solar wind back to its source at the Sun, derived from AIA images, and predicting solar wind speed. Ref. [
25] presented a hybrid deep learning model for wind speed prediction, combining CNN and LSTM architectures, achieving a test RMSE of 1.84 m/s. The model’s track-wise processing approach outperformed other models, showcasing the potential of capturing spatiotemporal correlations among data along a trajectory for improved accuracy. Ref. [
26] introduced an improved wind power prediction model using a combination of Convolutional Neural Networks and the Informer model to enhance prediction accuracy, based on real wind farm data from China. Ref. [
27] employed deep learning and extreme ultraviolet images to predict solar wind properties, outperforming traditional models with a correlation of 0.55 ± 0.03. Model analysis revealed its ability to capture correlations between solar corona structures and wind speeds, offering potential data relationships for solar physics research. These studies collectively highlight the outstanding performance and extensive applicability of deep learning models in the domain of wind speed prediction, providing robust support for the wind energy industry and renewable energy management. Different models and approaches offer different advantages in various application scenarios, contributing to the continuous improvement of wind speed prediction accuracy.
In summary, the field of wind speed prediction has seen significant advancements, with the emergence of various promising models and methods, including statistical models, traditional machine learning models, and deep learning models. These studies have greatly improved the accuracy and reliability of wind speed prediction, providing essential impetus for the wind energy industry and renewable energy management. However, despite the distinct advantages exhibited by different types of models in specific contexts, there is currently a lack of comprehensive model comparison research that can assist researchers in selecting the most suitable models for their specific application needs. This is where the value of our study lies. We will conduct a comprehensive comparative analysis of statistical models, traditional machine learning models, and deep learning models to evaluate their performance. By addressing this research gap, our study will provide a comprehensive model comparison framework for other scholars, aiding them in making better-informed choices for wind speed prediction models that align with their research and practical applications. This will further drive advancements in the field of wind speed prediction and promote the sustainable growth of the renewable energy industry.
The main contributions of this paper are as follows: (1) A comprehensive performance comparison: This study plans to conduct an extensive comparative analysis, including eight different wind speed prediction models, spanning statistical models, traditional machine learning, and deep learning methods. This comprehensive performance comparison aims to provide in-depth insights into the performance of different models, helping decision makers determine which model is most suitable for short-term wind speed forecasting in various contexts. (2) Real-world validation and performance optimization: The research validates the performance of eight machine learning models in short-term wind speed prediction using real-world case study data. This practical validation not only underscores the feasibility of these models but also offers robust support and profound insights for optimizing the performance of actual wind energy systems.
The remainder of this article is arranged as follows: In
Section 2, an initial presentation of the technical roadmap for the research framework will be provided, followed by a detailed description of eight distinct wind speed prediction models, encompassing statistical models, traditional machine learning, and deep learning models. Additionally, this section will outline the data sources and experimental design used for model training and evaluation. In
Section 3, we will present the primary findings of the study, including a performance comparison of the various models, utilizing charts, data analysis, and performance metrics to showcase the models’ performance. Finally, in
Section 4, the article will summarize the main findings, emphasize key insights from the model comparisons, provide an in-depth discussion of these results, and also consider the limitations of the study and directions for future work.
3. Results
We conducted model training and testing on data from two different power plants, involving a total of eight distinct wind speed prediction models. The code for these models was developed and executed within Jupyter Notebook 6.4.12. The optimal results of the models, achieved through multiple rounds of parameter tuning, are detailed in
Table A1,
Table A2,
Table A3,
Table A4,
Table A5 and
Table A6. We employed five evaluation metrics to comprehensively assess the performance of each model. The specific model results are presented in
Table 2 and
Table 3, which provide valuable insights for evaluating the quality of the models.
After a comprehensive evaluation of the wind speed prediction performance of power plant 1, we found that deep learning models excelled in several key metrics. Among these deep learning models, the CNN model stood out with outstanding performance in wind speed prediction. The CNN model exhibited low values in MSE, RMSE, and MAE, with respective values of 0.0124, 0.1112, and 0.0855, highlighting its remarkable accuracy in wind speed forecasting. Additionally, the CNN model achieved the highest R-square value of 0.9274, further underscoring its exceptional performance in capturing the variability of wind speed data. These numerical values underscore the robust performance of the CNN model in capturing wind speed fluctuations and variations, providing a reliable tool for wind energy and wind power generation in the renewable energy industry. It is worth noting that although the CNN model excelled, the LSTM model also demonstrated a satisfactory performance on the same dataset, ranking second. LSTM exhibited competitive values in metrics like , indicating its contribution to the accuracy and stability of wind speed prediction. In contrast, the statistical models achieved the poorest performance, with higher values in MSE, RMSE, and MAE and a lower , reflecting a relatively lower predictive accuracy. This result further emphasizes the superior performance of deep learning models in handling complex wind speed data and temporal relationships.
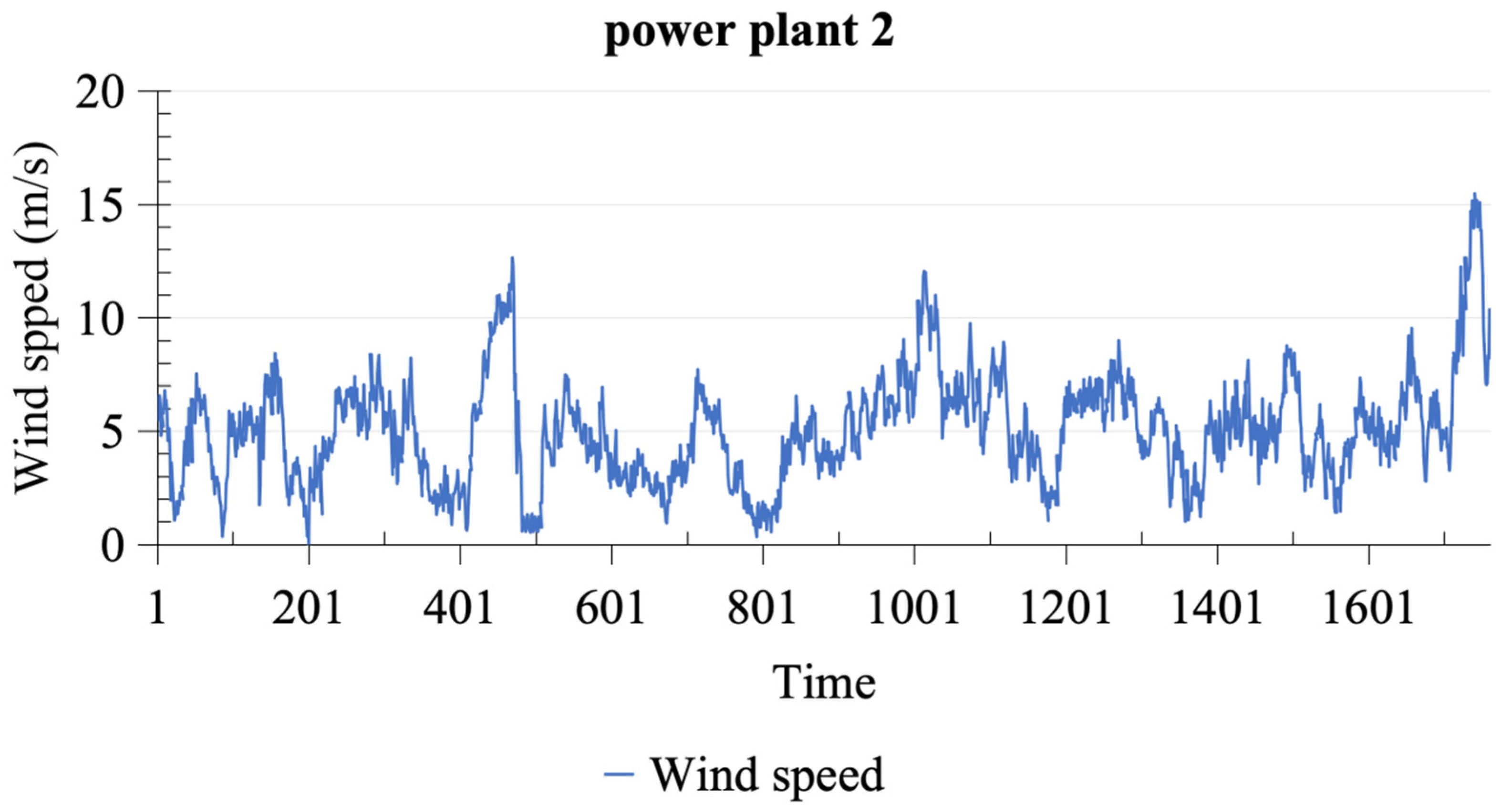
Following a comprehensive assessment of wind speed prediction performance at power plant 2, it becomes evident that deep learning models shine across various critical metrics. Notably, the CNN model emerges as a standout performer in the realm of wind speed prediction, boasting the lowest recorded values for MSE, RMSE, MAE, and MAPE and the highest , with exceptional scores of 0.0083, 0.0913, 0.0724, 0.4840, and 0.9211, respectively. In addition, both the LSTM and ANN models exhibit commendable performance on the same dataset, characterized by competitive error values, underscoring their significant contributions to enhancing prediction accuracy and stability. In contrast, statistical and machine learning models exhibit relatively subpar performance, marked by higher error values, indicating their diminished predictive accuracy in comparison to their deep learning counterparts.
Taking into consideration the wind speed prediction performance on two different power plants, deep learning models, especially the CNN model, demonstrate outstanding results, with exceptional accuracy and stability. Additionally, the LSTM and ANN models also exhibit a satisfactory performance on the same datasets. In contrast, traditional statistical models perform relatively poorly, with higher errors. This underscores the superior capabilities of deep learning models in handling wind speed data, providing strong support for improving renewable energy efficiency and the reliability of wind power generation.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}