
Reinforcement Learning-Based Intelligent Control Strategies for Optimal Power Management in Advanced Power Distribution Systems: A Survey




Abstract
:1. Introduction
- In general, they are slow and cannot be operated online, whereas online operation accomplishes more economical implementation, due to there being no need for a devoted computer of offline optimization.
- An economic issue, due to the absence of learning components. Hence, optimization iteration is mandatory at every change in the generation or load profiles.
- A separate forecasting algorithm is compulsory for the state variables prediction.
- The qualification for the offline attainment of generation and load measurements, and applicating them for any expected online generation or load.
- An accurate model is not mandatory for achieving the optimal solution of solving power management problems.
- More precise predictions can be accomplished through the application of an artificial neural network (ANN) and attain a modernized intelligent application, due to eliminating the need for a separate forecasting model.
2. Background
2.1. Agent and Agent-Based Modeling
- Mobility: The agent is flexible to move from one location to another within a specified operational framework or environment.
- Communication: The agent can communicate with the environment, in addition to other active agents.
- Autonomy: The independence of the agent to do tasks or make actions on behalf of the administrator.
- Rationality: The agent should hold a level of intelligence to decide or collaborate of deciding regarding completing a task for the administrator.
- Reactivity: The quality of the agent to monitor the environment and respond to its changes.
- Sociality: The collaboration of the agent with the human and other active agents in accomplishing the mandatory tasks.
- Self-learning: The agent learns from the surrounding environment to make an independent improvement or adaptation in the environment.
2.2. Markov Decision Process Models
- The state space (S): The set of possible states, that holds several versions based on the level number of the states included, such as finite, denumerable, compact, etc. Where each of the states can be observed at any time point when a decision or action is being made regarding a task to make a specific change in the environment.
- The action sets (A): It refers to a set of actions and holds similar versions for the state space based on the level number of the actions involved. Wherein each action is taken depending on an observed state.
- The decision time point: It is the time interval between the decisions. Accordingly, the model is an MDP if the decision time points are constant. Otherwise, the model is semi-MDP.
- The immediate reward (R): The reward is a function of the action and the state. Where an immediate reward is earned for the given model state and action, that is inversely proportional to the cost and can be determined by the reward function in Equation (1).
- The transition probabilities : It implies the probabilities of the possible various next state, due to the difference between the deterministic and Markovian, environments, wherein the state transition in the Markovian environment is probabilistic. Equation (2) demonstrates the transition function for the distribution of the probability over the next coming state.
- The planning horizon: The horizon of the controlled time points is planned by the suggested RL agent based on the problem solver.
2.3. Markov Game
2.4. Outliers of Reinforcement Learning and Detection Methods
- Global outliers: The data point is a global outlier if the value is far from the whole data of the specific set.
- Contextual outliers: The outlier is contextual if its value significantly deviates from the other data of the set.
- Collective Outliers: A group of data points represents a collective outlier if their values are close to each other, and they are, as a collection, significantly deviating from all the other data of the set.
- Statistical approach: The statical approach refers to the statical computation of parameters in a statical distribution, where examples of it are mean and standard deviation, wherein outliers represent the observations that cannot be classified after some iterations.
- Depth approach: It refers to the classification of the observations based on the depth, where data points are organized as convex hill layers. Accordingly, observations of the same depth are of the same class. Furthermore, observation is classified as an outlier if it lies in the utmost of these classes.
- Distance approach: In this method, the distance between the observations is the enabler of distinguishing an outlier. Where the class here represents a group of observations with a similar distance between neighbors. Accordingly, the observation is detected as an outlier if the distance from the neighbors of the class is different.
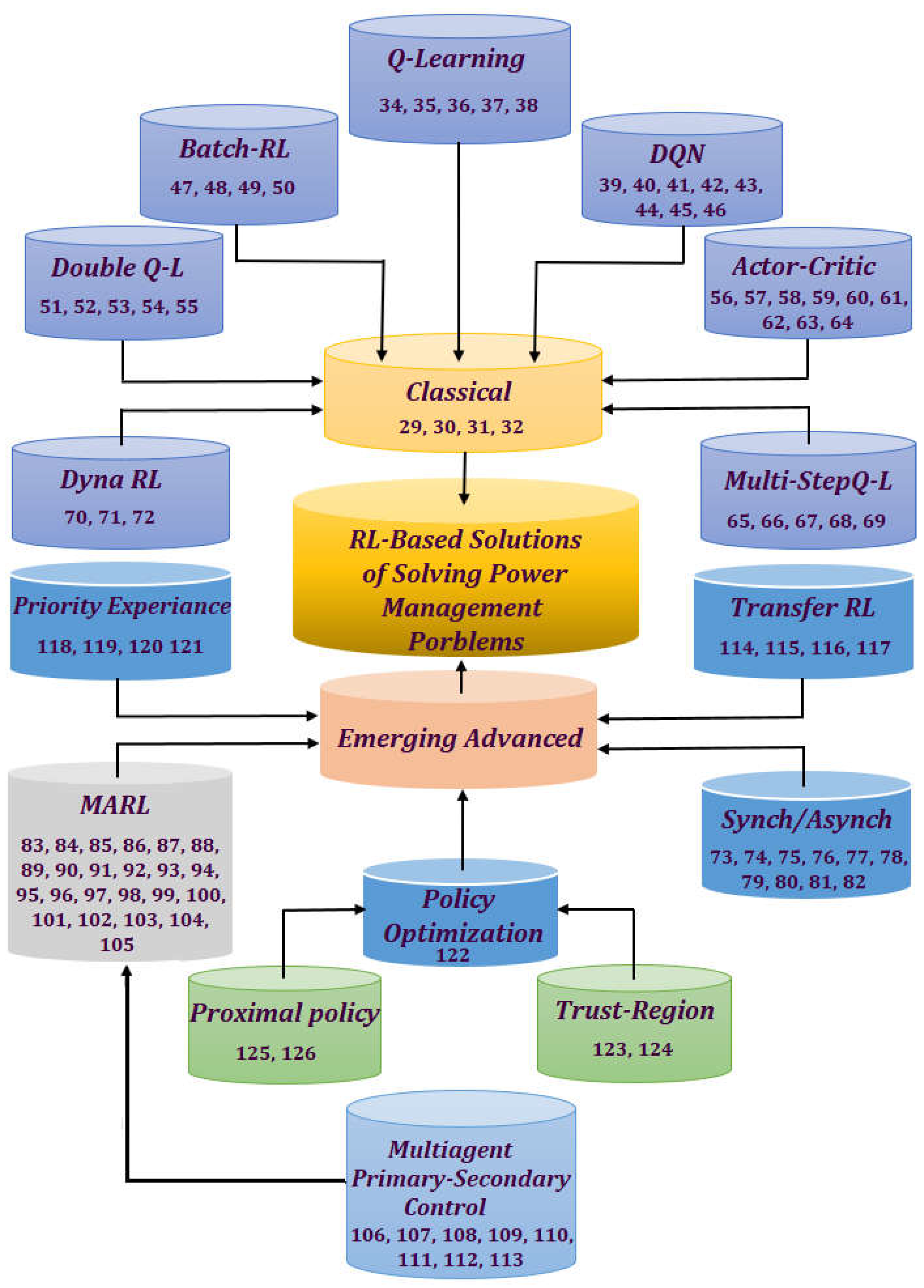
3. Classical Solutions Based on Reinforcement Learning of Power Management Problems
- The difficulty and complexity of obtaining a model of the environment.
- An error in the model is highly expected, because of the sensitive quality of the solution.
- An expected loss of computational efficiency in the case of a highly complex model and a simple application.
3.1. Q-Learning
3.2. Deep Q-Network
- An approximated action value function through the replacement of the conventional Q-learning table by an ANN.
- Improved exploration, because of the different agents involved.
- Enhanced exploitation through updating the Q-values by the best solution accomplished.
3.3. Batch Reinforcement Learning
3.4. Double Q-Learning
3.5. Actor–Critic
3.6. Multi-Step Q-Learning
3.7. Dyna Algorithm
4. Emerging Advanced Reinforcement Learning-Based Solutions of Power Management Problems
4.1. Synchronous and Asynchronous RL Solutions
4.2. Multiagent RL Solutions
- Stationarity: In MARL solutions, all the interacting agents can make a modification in the environment, which differs from the non-stationarity single-agent solutions, wherein the environment can be influenced by only one agent [85].
- Scalability: The algorithms for implementing the MARL need to be scalable to a high number of agents, exchanging information between them, in addition to the environment. Accordingly, most MARL approaches to attain scalability are decentralized because of the absence of a central controller and the uncertainty of communication links [86].
- Partial observability: The observability is set to be partial when correlated with a limited geographical due to the vision of the agent on only the surrounding. This can be recovered in the MARL by the similar solution that is followed in setting the DQN, which is that the first layer is replaced by a long short-term memory (LSTM) to enhance the non-observability that is occurred [87].
4.3. The Decentralized Multiagent Primary–Secondary Control
The Adaptive Multiagent Primary–Secondary Control
4.4. Transfer Learning Solutions
4.5. Priority Experience Replay RL Solutions
4.6. Policy Optimization Methods
4.6.1. Trust Region Policy Optimization
4.6.2. Proximal Policy Optimization
5. Conclusions and Summary
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Nomenclature
| EV | Electric vehicle |
| EVs | Electric vehicles |
| ESS | Energy storage system |
| ESSs | Energy storage systems |
| BESS | Battery energy storage system |
| BESSs | Battery energy storage systems |
| SOC | State of charge |
| GAs | Genetic algorithms |
| SI | Swarm intelligence |
| RL | Reinforcement learning |
| ANN | Artificial neural network |
| ABM | Agent based modeling |
| MSDP | Multistage decision problem |
| AI | Artificial intelligence |
| AOP | Agent-oriented programming |
| MDP | Markov decision process |
| semi-MDP | Semi Markov decision process |
| S | State space |
| A | Action sets |
| R | Immediate reward |
| T | State transition equation |
| p(s) | Transition probabilities |
| Value of the state | |
| Reward for the new state-action pair | |
| ) | Maximum Q-value for all expected state-action pars |
| Q(s, a) | Current Q-value |
| Optimal strategy | |
| Discount rate | |
| ∝ | Learning rate |
| MG | Stochastic game |
| MARL | Multiagent reinforcement learning system |
| ML | Machine learning |
| ANFIS | Adaptive fuzzy network inference system |
| QLFIS | Q-learning fuzzy inference system |
| HEV | Hybrid electric vehicle |
| HEVs | hybrid electric vehicles |
| HVAC | Heating, ventilation, and air conditioning |
| OMS-QL | Intelligent Q learning |
| FMP | Forecasting model pool |
| FCS | Fuel cell |
| FCHEVs | Fuel cell hybrid electric vehicles |
| DQN | Deep Q-learning |
| M-SOPs | Multi-terminal soft open points |
| DGs | Distributed generators |
| DDPG | Deep deterministic policy gradient network |
| LSTM | Long short-term memory |
| ICE | Internal combustion engine |
| EM | Electrical motor |
| KL | Kullback–Leibler |
| DDQN | Double deep Q learning |
| PHEV | Plug-in hybrid electric vehicle |
| EMS | Energy management system |
| HEM | Home energy management |
| MPC | Module predictive controller |
| PDQL | Predictive double Q learning |
| SDQL | Standard double Q-learning |
| HDNs | Hybrid AC-DC networks |
| SAC | Soft actor–critic |
| MSAC | Mechanism soft actor–critic |
| PER | Posturized experience replay |
| Dyna-H | New version of the Dyna algorithm |
| AMSGard | Optimization method of updating ANN |
| A3C | Asynchronous actor–critic |
| A3C+ | Asynchronous advantage actor–critic |
| A2C | Synchronous actor–critic |
| MCM | Markov chain model |
| M-A3C | Asynchronous memory actor–critic |
| DSM | Demand side management |
| MA2C | Multiagent synchronous actor–critic |
| FCS-MPC | Learning-based MPC |
| ADP | Adaptive dynamic programming |
| PSO | Particle swarm optimization |
| PEVs | Plug-in electric vehicles |
| SSA | Security situational awareness |
| MADDPG | Multiagent deep deterministic policy gradient |
| BES | Building energy system |
| LOL | Accelerated loss of life |
| ECL | Evolutionary curriculum learning |
| AMoD | Autonomous mobility on demand system |
| EVCS | Electric vehicle charging system |
| APT | Advanced mitigate persistent threats |
| TD3 | Twin delayed deep deterministic policy gradient |
| MATL | Multiagent transfer learning |
| TL-LSTM | Transfer learning long-short term memory |
| UAV | Unnamed aerial vehicle |
| DRL | Deep reinforcement learning |
| QiER | Quantum-inspired experience replay |
| PESA | Prioritized replay evolutionary and swarm algorithm |
| TRPO | Trust-region policy optimization |
| IoV | Internet of vehicles |
| DARC | Dedicated short-range communication |
| C-V2X | Cellular vehicle-to-everything |
| ITS | Intelligent transportation system |
| IoT | Internet of things |
| V2V | Vehicle-to-vehicle communications |
| V2I | Vehicle-to-infrastructure communications |
| AOI | Average age of information |
| PPO | Proximal policy optimization |
References
- Rehman, U.; Yaqoob, K.; Khan, M.A. Optimal power management framework for smart homes using electric vehicles and energy storage. Int. J. Electr. Power Energy Syst. 2022, 134, 107358. [Google Scholar] [CrossRef]
- Zhang, J.; Jia, R.; Yang, H.; Dong, K. Does electric vehicle promotion in the public sector contribute to urban transport carbon emissions reduction? Transp. Policy 2022, 125, 151–163. [Google Scholar] [CrossRef]
- Merabet, A.; Al-Durra, A.; El-Saadany, E.F. Improved Feedback Control and Optimal Management for Battery Storage System in Microgrid Operating in Bi-directional Grid Power Transfer. IEEE Trans. Sustain. Energy 2022, 13, 2106–2118. [Google Scholar] [CrossRef]
- Liu, L.-N.; Yang, G.-H. Distributed optimal energy management for integrated energy systems. IEEE Trans. Ind. Inform. 2022, 18, 6569–6580. [Google Scholar] [CrossRef]
- Arwa, E.O.; Folly, K.A. Reinforcement learning techniques for optimal power control in grid-connected microgrids: A comprehensive review. IEEE Access 2020, 8, 208992–209007. [Google Scholar] [CrossRef]
- Al-Saadi, M.; Al-Greer, M.; Short, M. Strategies for controlling microgrid networks with energy storage systems: A review. Energies 2021, 14, 7234. [Google Scholar] [CrossRef]
- Attiya, I.; Abd Elaziz, M.; Abualigah, L.; Nguyen, T.N.; Abd El-Latif, A.A. An improved hybrid swarm intelligence for scheduling iot application tasks in the cloud. IEEE Trans. Ind. Inform. 2022, 18, 6264–6272. [Google Scholar] [CrossRef]
- Dashtdar, M.; Flah, A.; Hosseinimoghadam, S.M.S.; Reddy, C.R.; Kotb, H.; AboRas, K.M.; Bortoni, E.C. Improving the power quality of island microgrid with voltage and frequency control based on a hybrid genetic algorithm and PSO. IEEE Access 2022, 10, 105352–105365. [Google Scholar] [CrossRef]
- Tulbure, A.-A.; Tulbure, A.-A.; Dulf, E.-H. A review on modern defect detection models using DCNNs–Deep convolutional neural networks. J. Adv. Res. 2022, 35, 33–48. [Google Scholar] [CrossRef]
- Cao, D.; Hu, W.; Zhao, J.; Zhang, G.; Zhang, B.; Liu, Z.; Chen, Z.; Blaabjerg, F. Reinforcement learning and its applications in modern power and energy systems: A review. J. Mod. Power Syst. Clean Energy 2020, 8, 1029–1042. [Google Scholar] [CrossRef]
- Zhang, Q.; Dehghanpour, K.; Wang, Z.; Huang, Q. A learning-based power management method for networked microgrids under incomplete information. IEEE Trans. Smart Grid 2019, 11, 1193–1204. [Google Scholar] [CrossRef]
- Šešelja, D. Agent-based models of scientific interaction. Philos. Compass 2022, 17, e12855. [Google Scholar] [CrossRef]
- Janssen, M.A. Agent-based modelling. Model. Ecol. Econ. 2005, 155, 172–181. [Google Scholar]
- Orozco, C.; Borghetti, A.; De Schutter, B.; Napolitano, F.; Pulazza, G.; Tossani, F. Intra-day scheduling of a local energy community coordinated with day-ahead multistage decisions. Sustain. Energy Grids Netw. 2022, 29, 100573. [Google Scholar] [CrossRef]
- Naeem, M.; Rizvi, S.T.H.; Coronato, A. A gentle introduction to reinforcement learning and its application in different fields. IEEE Access 2020, 8, 209320–209344. [Google Scholar] [CrossRef]
- Abar, S.; Theodoropoulos, G.K.; Lemarinier, P.; O’Hare, G.M. Agent Based Modelling and Simulation tools: A review of the state-of-art software. Comput. Sci. Rev. 2017, 24, 13–33. [Google Scholar] [CrossRef]
- Burattini, S.; Ricci, A.; Mayer, S.; Vachtsevanou, D.; Lemee, J.; Ciortea, A.; Croatti, A. Agent-Oriented Visual Programming for the Web of Things. 2022. Available online: https://emas.in.tu-clausthal.de/2022/papers/paper3.pdf (accessed on 25 December 2022).
- Shoham, Y. Agent-oriented programming. Artif. Intell. 1993, 60, 51–92. [Google Scholar] [CrossRef]
- Alsheikh, M.A.; Hoang, D.T.; Niyato, D.; Tan, H.-P.; Lin, S. Markov decision processes with applications in wireless sensor networks: A survey. IEEE Commun. Surv. Tutor. 2015, 17, 1239–1267. [Google Scholar] [CrossRef]
- Lourentzou, I. Markov Games and Reinforcement Learning. Available online: https://isminoula.github.io/files/games.pdf (accessed on 22 December 2022).
- Canese, L.; Cardarilli, G.C.; Di Nunzio, L.; Fazzolari, R.; Giardino, D.; Re, M.; Spanò, S. Multi-agent reinforcement learning: A review of challenges and applications. Appl. Sci. 2021, 11, 4948. [Google Scholar] [CrossRef]
- Rashedi, N.; Tajeddini, M.A.; Kebriaei, H. Markov game approach for multi-agent competitive bidding strategies in electricity market. IET Gener. Transm. Distrib. 2016, 10, 3756–3763. [Google Scholar] [CrossRef]
- Liu, Q.; Wang, Y.; Jin, C. Learning markov games with adversarial opponents: Efficient algorithms and fundamental limits. arXiv 2022, arXiv:2203.06803. [Google Scholar]
- Liu, W.; Dong, L.; Niu, D.; Sun, C. Efficient Exploration for Multi-Agent Reinforcement Learning via Transferable Successor Features. IEEE/CAA J. Autom. Sin. 2022, 9, 1673–1686. [Google Scholar] [CrossRef]
- Shawon, M.H.; Muyeen, S.; Ghosh, A.; Islam, S.M.; Baptista, M.S. Multi-agent systems in ICT enabled smart grid: A status update on technology framework and applications. IEEE Access 2019, 7, 97959–97973. [Google Scholar] [CrossRef]
- How to Remove Outliers for Machine Learning? Available online: https://medium.com/analytics-vidhya/how-to-remove-outliers-for-machine-learning-24620c4657e8 (accessed on 19 January 2023).
- Yang, J.; Rahardja, S.; Fränti, P. Outlier detection: How to threshold outlier scores? In Proceedings of the International Conference on Artificial Intelligence, Information Processing and Cloud Computing, Sanya, China, 19–21 December 2019; pp. 1–6. [Google Scholar]
- Dwivedi, R.K.; Pandey, S.; Kumar, R. A study on machine learning approaches for outlier detection in wireless sensor network. In Proceedings of the 2018 8th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 1–12 January 2018; pp. 189–192. [Google Scholar]
- Lodhia, Z.; Rasool, A.; Hajela, G. A survey on machine learning and outlier detection techniques. IJCSNS 2017, 17, 271. [Google Scholar]
- Yang, N.; Han, L.; Xiang, C.; Liu, H.; Ma, T.; Ruan, S. Real-Time Energy Management for a Hybrid Electric Vehicle Based on Heuristic Search. IEEE Trans. Veh. Technol. 2022, 71, 12635–12647. [Google Scholar] [CrossRef]
- Cristaldi, L.; Faifer, M.; Laurano, C.; Petkovski, E.; Toscani, S.; Ottoboni, R. An Innovative Model-Based Algorithm for Power Control Strategy of Photovoltaic Panels. In Proceedings of the 2022 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Ottawa, ON, Canada, 16–19 May 2022; pp. 1–6. [Google Scholar]
- Dayan, P.; Berridge, K.C. Model-based and model-free Pavlovian reward learning: Revaluation, revision, and revelation. Cogn. Affect. Behav. Neurosci. 2014, 14, 473–492. [Google Scholar] [CrossRef] [PubMed]
- Heidari, A.; Maréchal, F.; Khovalyg, D. An occupant-centric control framework for balancing comfort, energy use and hygiene in hot water systems: A model-free reinforcement learning approach. Appl. Energy 2022, 312, 118833. [Google Scholar] [CrossRef]
- Mason, K.; Grijalva, S. A review of reinforcement learning for autonomous building energy management. Comput. Electr. Eng. 2019, 78, 300–312. [Google Scholar] [CrossRef]
- Xu, B.; Zhou, Q.; Shi, J.; Li, S. Hierarchical Q-learning network for online simultaneous optimization of energy efficiency and battery life of the battery/ultracapacitor electric vehicle. J. Energy Storage 2022, 46, 103925. [Google Scholar] [CrossRef]
- Bo, L.; Han, L.; Xiang, C.; Liu, H.; Ma, T. A Q-learning fuzzy inference system based online energy management strategy for off-road hybrid electric vehicles. Energy 2022, 252, 123976. [Google Scholar] [CrossRef]
- Kosana, V.; Teeparthi, K.; Madasthu, S.; Kumar, S. A novel reinforced online model selection using Q-learning technique for wind speed prediction. Sustain. Energy Technol. Assess. 2022, 49, 101780. [Google Scholar] [CrossRef]
- Li, W.; Ye, J.; Cui, Y.; Kim, N.; Cha, S.W.; Zheng, C. A speedy reinforcement learning-based energy management strategy for fuel cell hybrid vehicles considering fuel cell system lifetime. Int. J. Precis. Eng. Manuf.-Green Technol. 2022, 9, 859–872. [Google Scholar] [CrossRef]
- Ganesh, A.H.; Xu, B. A review of reinforcement learning based energy management systems for electrified powertrains: Progress, challenge, and potential solution. Renew. Sustain. Energy Rev. 2022, 154, 111833. [Google Scholar] [CrossRef]
- Montavon, G.; Binder, A.; Lapuschkin, S.; Samek, W.; Müller, K.-R. Layer-wise relevance propagation: An overview. Explain. AI: Interpret. Explain. Vis. Deep Learn. 2019, 11700, 193–209. [Google Scholar]
- Ohnishi, S.; Uchibe, E.; Yamaguchi, Y.; Nakanishi, K.; Yasui, Y.; Ishii, S. Constrained deep q-learning gradually approaching ordinary q-learning. Front. Neurorobot. 2019, 13, 103. [Google Scholar] [CrossRef] [PubMed]
- Suanpang, P.; Jamjuntr, P.; Jermsittiparsert, K.; Kaewyong, P. Autonomous Energy Management by Applying Deep Q-Learning to Enhance Sustainability in Smart Tourism Cities. Energies 2022, 15, 1906. [Google Scholar] [CrossRef]
- Zhu, Z.; Weng, Z.; Zheng, H. Optimal Operation of a Microgrid with Hydrogen Storage Based on Deep Reinforcement Learning. Electronics 2022, 11, 196. [Google Scholar] [CrossRef]
- Li, P.; Wei, M.; Ji, H.; Xi, W.; Yu, H.; Wu, J.; Yao, H.; Chen, J. Deep reinforcement learning-based adaptive voltage control of active distribution networks with multi-terminal soft open point. Int. J. Electr. Power Energy Syst. 2022, 141, 108138. [Google Scholar] [CrossRef]
- Sun, M.; Zhao, P.; Lin, X. Power management in hybrid electric vehicles using deep recurrent reinforcement learning. Electr. Eng. 2022, 104, 1459–1471. [Google Scholar] [CrossRef]
- Forootani, A.; Rastegar, M.; Jooshaki, M. An Advanced Satisfaction-Based Home Energy Management System Using Deep Reinforcement Learning. IEEE Access 2022, 10, 47896–47905. [Google Scholar] [CrossRef]
- Chen, J.; Jiang, N. Information-theoretic considerations in batch reinforcement learning. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 1042–1051. [Google Scholar]
- Zhang, C.; Kuppannagari, S.R.; Prasanna, V.K. Safe Building HVAC Control via Batch Reinforcement Learning. IEEE Trans. Sustain. Comput. 2022, 7, 923–934. [Google Scholar] [CrossRef]
- Liu, H.-Y.; Balaji, B.; Gao, S.; Gupta, R.; Hong, D. Safe HVAC Control via Batch Reinforcement Learning. In Proceedings of the 2022 ACM/IEEE 13th International Conference on Cyber-Physical Systems (ICCPS), Milano, Italy, 4–6 May 2022; pp. 181–192. [Google Scholar]
- Lesage-Landry, A.; Callaway, D.S. Batch reinforcement learning for network-safe demand response in unknown electric grids. Electr. Power Syst. Res. 2022, 212, 108375. [Google Scholar] [CrossRef]
- Ren, Z.; Zhu, G.; Hu, H.; Han, B.; Chen, J.; Zhang, C. On the Estimation Bias in Double Q-Learning. Adv. Neural Inf. Process. Syst. 2021, 34, 10246–10259. [Google Scholar]
- Zhang, Y.; Sun, P.; Yin, Y.; Lin, L.; Wang, X. Human-like autonomous vehicle speed control by deep reinforcement learning with double Q-learning. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1251–1256. [Google Scholar]
- Chen, Z.; Gu, H.; Shen, S.; Shen, J. Energy management strategy for power-split plug-in hybrid electric vehicle based on MPC and double Q-learning. Energy 2022, 245, 123182. [Google Scholar] [CrossRef]
- Shuai, B.; Li, Y.-F.; Zhou, Q.; Xu, H.-M.; Shuai, S.-J. Supervisory control of the hybrid off-highway vehicle for fuel economy improvement using predictive double Q-learning with backup models. J. Cent. South Univ. 2022, 29, 2266–2278. [Google Scholar] [CrossRef]
- Han, L.; Yang, K.; Zhang, X.; Yang, N.; Liu, H.; Liu, J. Energy management strategy for hybrid electric vehicles based on double Q-learning. In Proceedings of the International Conference on Mechanical Design and Simulation (MDS 2022), Wuhan, China, 18–20 March 2022; pp. 639–648. [Google Scholar]
- Mocanu, E.; Mocanu, D.C.; Nguyen, P.H.; Liotta, A.; Webber, M.E.; Gibescu, M.; Slootweg, J.G. On-line building energy optimization using deep reinforcement learning. IEEE Trans. Smart Grid 2018, 10, 3698–3708. [Google Scholar] [CrossRef]
- Du, Y.; Zandi, H.; Kotevska, O.; Kurte, K.; Munk, J.; Amasyali, K.; Mckee, E.; Li, F. Intelligent multi-zone residential HVAC control strategy based on deep reinforcement learning. Appl. Energy 2021, 281, 116117. [Google Scholar] [CrossRef]
- Kou, P.; Liang, D.; Wang, C.; Wu, Z.; Gao, L. Safe deep reinforcement learning-based constrained optimal control scheme for active distribution networks. Appl. Energy 2020, 264, 114772. [Google Scholar] [CrossRef]
- Wu, T.; Wang, J.; Lu, X.; Du, Y. AC/DC hybrid distribution network reconfiguration with microgrid formation using multi-agent soft actor-critic. Appl. Energy 2022, 307, 118189. [Google Scholar] [CrossRef]
- Han, K.; Yang, K.; Yin, L. Lightweight actor-critic generative adversarial networks for real-time smart generation control of microgrids. Appl. Energy 2022, 317, 119163. [Google Scholar] [CrossRef]
- Hu, C.; Cai, Z.; Zhang, Y.; Yan, R.; Cai, Y.; Cen, B. A soft actor-critic deep reinforcement learning method for multi-timescale coordinated operation of microgrids. Prot. Control Mod. Power Syst. 2022, 7, 29. [Google Scholar] [CrossRef]
- Xu, D.; Cui, Y.; Ye, J.; Cha, S.W.; Li, A.; Zheng, C. A soft actor-critic-based energy management strategy for electric vehicles with hybrid energy storage systems. J. Power Sources 2022, 524, 231099. [Google Scholar] [CrossRef]
- Sun, W.; Zou, Y.; Zhang, X.; Guo, N.; Zhang, B.; Du, G. High robustness energy management strategy of hybrid electric vehicle based on improved soft actor-critic deep reinforcement learning. Energy 2022, 258, 124806. [Google Scholar] [CrossRef]
- Cao, Y.; Wang, H.; Li, D.; Zhang, G. Smart online charging algorithm for electric vehicles via customized actor–critic learning. IEEE Internet Things J. 2021, 9, 684–694. [Google Scholar] [CrossRef]
- Peng, J.; Williams, R.J. Incremental multi-step Q-learning. In Machine Learning Proceedings 1994; Elsevier: Amsterdam, The Netherlands, 1994; pp. 226–232. [Google Scholar]
- Jang, B.; Kim, M.; Harerimana, G.; Kim, J.W. Q-learning algorithms: A comprehensive classification and applications. IEEE Access 2019, 7, 133653–133667. [Google Scholar] [CrossRef]
- Xi, L.; Zhou, L.; Xu, Y.; Chen, X. A multi-step unified reinforcement learning method for automatic generation control in multi-area interconnected power grid. IEEE Trans. Sustain. Energy 2020, 12, 1406–1415. [Google Scholar] [CrossRef]
- Ni, Z.; Paul, S. A multistage game in smart grid security: A reinforcement learning solution. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2684–2695. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Q.; Li, J.; Shuai, B.; Williams, H.; He, Y.; Li, Z.; Xu, H.; Yan, F. Multi-step reinforcement learning for model-free predictive energy management of an electrified off-highway vehicle. Appl. Energy 2019, 255, 113755. [Google Scholar] [CrossRef]
- Du, G.; Zou, Y.; Zhang, X.; Liu, T.; Wu, J.; He, D. Deep reinforcement learning based energy management for a hybrid electric vehicle. Energy 2020, 201, 117591. [Google Scholar] [CrossRef]
- Yang, N.; Han, L.; Xiang, C.; Liu, H.; Hou, X. Energy management for a hybrid electric vehicle based on blended reinforcement learning with backward focusing and prioritized sweeping. IEEE Trans. Veh. Technol. 2021, 70, 3136–3148. [Google Scholar] [CrossRef]
- Jia, Q.; Li, Y.; Yan, Z.; Xu, C.; Chen, S. A Reinforcement-Learning-Based Bidding Strategy for Power Suppliers with Limited Information. J. Mod. Power Syst. Clean Energy 2021, 10, 1032–1039. [Google Scholar] [CrossRef]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1928–1937. [Google Scholar]
- Wu, Y.; Mansimov, E.; Liao, S.; Radford, A.; Schulman, J. Openai Baselines: Acktr & a2c. 2017. Available online: https://openai.com/blog/baselines-acktr-a2c (accessed on 2 December 2022).
- Biswas, A.; Anselma, P.G.; Emadi, A. Real-Time Optimal Energy Management of Multimode Hybrid Electric Powertrain with Online Trainable Asynchronous Advantage Actor–Critic Algorithm. IEEE Trans. Transp. Electrif. 2021, 8, 2676–2694. [Google Scholar] [CrossRef]
- Zhou, J.; Xue, Y.; Xu, D.; Li, C.; Zhao, W. Self-learning energy management strategy for hybrid electric vehicle via curiosity-inspired asynchronous deep reinforcement learning. Energy 2022, 242, 122548. [Google Scholar] [CrossRef]
- Sanayha, M.; Vateekul, P. Model-based deep reinforcement learning for wind energy bidding. Int. J. Electr. Power Energy Syst. 2022, 136, 107625. [Google Scholar] [CrossRef]
- Sang, J.; Sun, H.; Kou, L. Deep Reinforcement Learning Microgrid Optimization Strategy Considering Priority Flexible Demand Side. Sensors 2022, 22, 2256. [Google Scholar] [CrossRef] [PubMed]
- Yu, L.; Yue, L.; Zhou, X.; Hou, C. Demand Side Management Pricing Method Based on LSTM and A3C in Cloud Environment. In Proceedings of the 2022 4th International Conference on Power and Energy Technology (ICPET), Beijing, China, 28–31 July 2022; pp. 905–909. [Google Scholar]
- Sun, F.; Kong, X.; Wu, J.; Gao, B.; Chen, K.; Lu, N. DSM pricing method based on A3C and LSTM under cloud-edge environment. Appl. Energy 2022, 315, 118853. [Google Scholar] [CrossRef]
- Melfald, E.G.; Øyvang, T. Optimal operation of grid-connected hydropower plants through voltage control methods. Scand. Simul. Soc. 2022, 101–108. [Google Scholar] [CrossRef]
- Zhou, W.; Chen, D.; Yan, J.; Li, Z.; Yin, H.; Ge, W. Multi-agent reinforcement learning for cooperative lane changing of connected and autonomous vehicles in mixed traffic. Auton. Intell. Syst. 2022, 2, 5. [Google Scholar] [CrossRef]
- Zhang, K.; Yang, Z.; Başar, T. Multi-agent reinforcement learning: A selective overview of theories and algorithms. Handb. Reinf. Learn. Control 2021, 325, 321–384. [Google Scholar]
- Oroojlooy, A.; Hajinezhad, D. A review of cooperative multi-agent deep reinforcement learning. Appl. Intell. 2022, 1–46. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar] [CrossRef]
- Kar, S.; Moura, J.M.; Poor, H.V. QD-Learning: A Collaborative Distributed Strategy for Multi-Agent Reinforcement Learning through Consensus + Innovations. IEEE Trans. Signal Process. 2013, 61, 1848–1862. [Google Scholar] [CrossRef]
- Omidshafiei, S.; Pazis, J.; Amato, C.; How, J.P.; Vian, J. Deep decentralized multi-task multi-agent reinforcement learning under partial observability. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 2681–2690. [Google Scholar]
- Mi, Y.; Deng, J.; Wang, X.; Lin, S.; Su, X.; Fu, Y. Multiagent Distributed Secondary Control for Energy Storage Systems with Lossy Communication Networks in DC Microgrid. IEEE Trans. Smart Grid 2022. [Google Scholar] [CrossRef]
- Mo, S.; Chen, W.-H.; Lu, X. Hierarchical Hybrid Control for Scaled Consensus, and Its Application to Secondary Control for DC Microgrid. IEEE Trans. Cybern. 2022. [Google Scholar] [CrossRef] [PubMed]
- Sorouri, H.; Oshnoei, A.; Novak, M.; Blaabjerg, F.; Anvari-Moghaddam, A. Learning-Based Model Predictive Control of DC-DC Buck Converters in DC Microgrids: A Multi-Agent Deep Reinforcement Learning Approach. Energies 2022, 15, 5399. [Google Scholar] [CrossRef]
- Abianeh, A.J.; Wan, Y.; Ferdowsi, F.; Mijatovic, N.; Dragičević, T. Vulnerability Identification and Remediation of FDI Attacks in Islanded DC Microgrids Using Multiagent Reinforcement Learning. IEEE Trans. Power Electron. 2021, 37, 6359–6370. [Google Scholar] [CrossRef]
- Xia, Y.; Xu, Y.; Wang, Y.; Mondal, S.; Dasgupta, S.; Gupta, A.K. Optimal secondary control of islanded AC microgrids with communication time-delay based on multi-agent deep reinforcement learning. CSEE J. Power Energy Syst. 2022. [Google Scholar] [CrossRef]
- Vanashi, H.K.; Mohammadi, F.D.; Verma, V.; Solanki, J.; Solanki, S.K. Hierarchical multi-agent-based frequency and voltage control for a microgrid power system. Int. J. Electr. Power Energy Syst. 2022, 135, 107535. [Google Scholar] [CrossRef]
- Chen, P.; Liu, S.; Chen, B.; Yu, L. Multi-Agent Reinforcement Learning for Decentralized Resilient Secondary Control of Energy Storage Systems Against DoS Attacks. IEEE Trans. Smart Grid 2022, 13, 1739–1750. [Google Scholar] [CrossRef]
- Xu, Y.; Yan, R.; Wang, Y.; Jiahong, D. A Multi-Agent Quantum Deep Reinforcement Learning Method for Distributed Frequency Control of Islanded Microgrids. IEEE Trans. Control Netw. Syst. 2022, 9, 1622–1632. [Google Scholar]
- Deshpande, K.; Möhl, P.; Hämmerle, A.; Weichhart, G.; Zörrer, H.; Pichler, A. Energy Management Simulation with Multi-Agent Reinforcement Learning: An Approach to Achieve Reliability and Resilience. Energies 2022, 15, 7381. [Google Scholar] [CrossRef]
- Wan, Y.; Qin, J.; Ma, Q.; Fu, W.; Wang, S. Multi-agent DRL-based data-driven approach for PEVs charging/discharging scheduling in smart grid. J. Frankl. Inst. 2022, 359, 1747–1767. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, Q.; An, D.; Li, D.; Wu, Z. Multistep Multiagent Reinforcement Learning for Optimal Energy Schedule Strategy of Charging Stations in Smart Grid. IEEE Trans. Cybern. 2022. [Google Scholar] [CrossRef]
- Lei, W.; Wen, H.; Wu, J.; Hou, W. MADDPG-based security situational awareness for smart grid with intelligent edge. Appl. Sci. 2021, 11, 3101. [Google Scholar] [CrossRef]
- Shen, R.; Zhong, S.; Wen, X.; An, Q.; Zheng, R.; Li, Y.; Zhao, J. Multi-agent deep reinforcement learning optimization framework for building energy system with renewable energy. Appl. Energy 2022, 312, 118724. [Google Scholar] [CrossRef]
- Homod, R.Z.; Togun, H.; Hussein, A.K.; Al-Mousawi, F.N.; Yaseen, Z.M.; Al-Kouz, W.; Abd, H.J.; Alawi, O.A.; Goodarzi, M.; Hussein, O.A. Dynamics analysis of a novel hybrid deep clustering for unsupervised learning by reinforcement of multi-agent to energy saving in intelligent buildings. Appl. Energy 2022, 313, 118863. [Google Scholar] [CrossRef]
- Qiu, D.; Wang, Y.; Zhang, T.; Sun, M.; Strbac, G. Hybrid Multi-Agent Reinforcement Learning for Electric Vehicle Resilience Control Towards a Low-Carbon Transition. IEEE Trans. Ind. Inform. 2022, 18, 8258–8269. [Google Scholar] [CrossRef]
- Li, S.; Hu, W.; Cao, D.; Zhang, Z.; Huang, Q.; Chen, Z.; Blaabjerg, F. EV Charging Strategy Considering Transformer Lifetime Via Evolutionary Curriculum Learning-based Multi-agent Deep Reinforcement Learning. IEEE Trans. Smart Grid 2022, 13, 2774–2787. [Google Scholar] [CrossRef]
- He, S.; Wang, Y.; Han, S.; Zou, S.; Miao, F. A Robust and Constrained Multi-Agent Reinforcement Learning Framework for Electric Vehicle AMoD Systems. arXiv 2022, arXiv:2209.08230. [Google Scholar]
- Basnet, M.; Ali, M.H. Multi-Agent Deep Reinforcement Learning-Driven Mitigation of Adverse Effects of Cyber-Attacks on Electric Vehicle Charging Station. arXiv 2022, arXiv:2207.07041. [Google Scholar]
- Al-Saadi, M.; Al-Greer, M. Adaptive Multiagent Primary Secondary Control for Accurate Synchronized Charge-Discharge Scenarios of Battery Distributed Energy Storage Systems in DC Autonomous Microgrid. In Proceedings of the 2022 57th International Universities Power Engineering Conference (UPEC), Istanbul, Turkey, 30 August–2 September 2022; pp. 1–6. [Google Scholar]
- Chen, X.; Qu, G.; Tang, Y.; Low, S.; Li, N. Reinforcement learning for selective key applications in power systems: Recent advances and future challenges. IEEE Trans. Smart Grid 2022, 13, 2935–2958. [Google Scholar] [CrossRef]
- Morstyn, T.; Hredzak, B.; Demetriades, G.D.; Agelidis, V.G. Unified distributed control for DC microgrid operating modes. IEEE Trans. Power Syst. 2015, 31, 802–812. [Google Scholar] [CrossRef]
- Li, C.; Coelho, E.A.A.; Dragicevic, T.; Guerrero, J.M.; Vasquez, J.C. Multiagent-based distributed state of charge balancing control for distributed energy storage units in AC microgrids. IEEE Trans. Ind. Appl. 2016, 53, 2369–2381. [Google Scholar] [CrossRef]
- Wu, T.; Xia, Y.; Wang, L.; Wei, W. Multiagent based distributed control with time-oriented SoC balancing method for DC microgrid. Energies 2020, 13, 2793. [Google Scholar] [CrossRef]
- Morstyn, T.; Savkin, A.V.; Hredzak, B.; Agelidis, V.G. Multi-agent sliding mode control for state of charge balancing between battery energy storage systems distributed in a DC microgrid. IEEE Trans. Smart Grid 2017, 9, 4735–4743. [Google Scholar] [CrossRef]
- Zhou, L.; Du, D.; Fei, M.; Li, K.; Rakić, A. Multiobjective Distributed Secondary Control of Battery Energy Storage Systems in Islanded AC Microgrids. In Proceedings of the 2021 40th Chinese Control Conference (CCC), Shanghai, China, 26–28 July 2021; pp. 6981–6985. [Google Scholar]
- Zeng, Y.; Zhang, Q.; Liu, Y.; Zhuang, X.; Lv, X.; Wang, H. Distributed secondary control strategy for battery storage system in DC microgrid. In Proceedings of the 2021 IEEE 4th International Electrical and Energy Conference (CIEEC), Wuhan, China, 28–30 May 2021; pp. 1–7. [Google Scholar]
- Liang, H.; Fu, W.; Yi, F. A survey of recent advances in transfer learning. In Proceedings of the 2019 IEEE 19th International Conference on Communication Technology (ICCT), Xi’an, China, 16–19 October 2019; pp. 1516–1523. [Google Scholar]
- Wu, J.; Wang, J.; Kong, X. Strategic bidding in a competitive electricity market: An intelligent method using Multi-Agent Transfer Learning based on reinforcement learning. Energy 2022, 256, 124657. [Google Scholar] [CrossRef]
- Ahn, Y.; Kim, B.S. Prediction of building power consumption using transfer learning-based reference building and simulation dataset. Energy Build. 2022, 258, 111717. [Google Scholar] [CrossRef]
- Li, C.; Li, G.; Wang, K.; Han, B. A multi-energy load forecasting method based on parallel architecture CNN-GRU and transfer learning for data deficient integrated energy systems. Energy 2022, 259, 124967. [Google Scholar] [CrossRef]
- Foruzan, E.; Soh, L.-K.; Asgarpoor, S. Reinforcement learning approach for optimal distributed energy management in a microgrid. IEEE Trans. Power Syst. 2018, 33, 5749–5758. [Google Scholar] [CrossRef]
- Anzaldo, A.; Andrade, Á.G. Experience Replay-based Power Control for sum-rate maximization in Multi-Cell Networks. IEEE Wirel. Commun. Lett. 2022, 11, 2350–2354. [Google Scholar] [CrossRef]
- Li, Y.; Aghvami, A.H.; Dong, D. Path Planning for Cellular-Connected UAV: A DRL Solution with Quantum-Inspired Experience Replay. IEEE Trans. Wirel. Commun. 2022, 21, 7897–7912. [Google Scholar] [CrossRef]
- Radaideh, M.I.; Shirvan, K. PESA: Prioritized experience replay for parallel hybrid evolutionary and swarm algorithms-Application to nuclear fuel. Nucl. Eng. Technol. 2022, 54, 3864–3877. [Google Scholar] [CrossRef]
- Ratcliffe, D.S.; Hofmann, K.; Devlin, S. Win or learn fast proximal policy optimization. In Proceedings of the 2019 IEEE Conference on Games (CoG), London, UK, 20–23 August 2019; pp. 1–4. [Google Scholar]
- Li, H.; Wan, Z.; He, H. Real-time residential demand response. IEEE Trans. Smart Grid 2020, 11, 4144–4154. [Google Scholar] [CrossRef]
- Peng, N.; Lin, Y.; Zhang, Y.; Li, J. AoI-aware Joint Spectrum and Power Allocation for Internet of Vehicles: A Trust Region Policy Optimization based Approach. IEEE Internet Things J. 2022, 9, 19916–19927. [Google Scholar] [CrossRef]
- Peirelinck, T.; Hermans, C.; Spiessens, F.; Deconinck, G. Combined Peak Reduction and Self-Consumption Using Proximal Policy Optimization. arXiv 2022, arXiv:2211.14831. [Google Scholar]
- Hou, J.; Yu, Z.; Zheng, Q.; Xu, H.; Li, S. Tie-line Power Adjustment Method Based on Proximal Policy Optimization Algorithm. J. Phys. Conf. Ser. 2021, 1754, 012229. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Strategy/Application | Strengths | Weaknesses |
|---|---|---|
| Ref. [35] EVs | 12%, and 8% Reduction of battery capacity and battery capacity loss, respectively. Extended vehicle’s range and batteries life. Qualified for different driving cycles and measurement noises. Extendable to different hybrid power systems. | More state variables consideration is mandatory. Not validated for some experimental data from externally introduced models. |
| Ref. [36] HEVs | Improved dynamic performance. Reduced fuel consumption and calculation time. | The attained power response performance is close to the existing DP-based strategy. |
| Ref. [37] Wind turbines system Integrated to grid | Optimized wind speed forecasting by 48% and 67% of two case studies in comparison with 9 previously existing methods. | Optimization is mandatory regarding the online selection of the model and the application of dynamic ensemble approaches. |
| Ref. [38] FCHVs | 5.59%, and 13% reduction of fuel consumption and power fluctuation, respectively. 69% increase in convergence speed. | Real-time applications are mandatory. |
| Ref. [42] Microgrid | 13.19% saved energy costs. Extendable to other industries require energy management. | Instability and sluggish convergence in real-time. Prediction of energy price is not considered. |
| Ref. [43] Microgrid | 5% reduced operation cost. Enhanced generalization capability. | PV and load uncertainties are not included. Ignored fuel efficiency. |
| Ref. [44] Distribution networks | Enhanced regulation of voltage fluctuation due to the high penetration of DGs. | Further modification can be achieved of the reward function. |
| Ref. [45] HEVs | Efficient utilization of learned information. Enhanced computational speed. Improved fuel economy. Independence of prior knowledge in driving cycles. | Unextendible to other applications. Participation in the electricity market is not included. |
| Ref. [46] HEM | Reduced electricity costs. Enhanced customer satisfaction. | Participation in the electricity market is not included. |
| Ref. [48] Building HVAC | 12%-35%, 3%-10%, and 3%-8% reduction in ramping, 1 h factor, and daily peak at deployment, respectively. Improved performance degradation compared to the existing strategy. | Still an existing performance degradation. |
| Ref. [49] Building HVAC | 7.2%, and 16.7% reduction of energy consumption compared to the existing batch algorithm and the rule-based algorithm, respectively. Enhanced thermal comfort. | A more frequent data writing rate is mandatory. |
| Ref. [50] Unknown electric grids | 95% reduction of the total number of rounds with at least one constraint violation. | Low setpoint tracking performance. |
| Ref. [53] PHEV | A superior optimization of fuel economy. Perfect adaptability to different SOC reference trajectories. | Real-time speed reduction under complex traffic conditions is not considered. |
| Ref. [55] HEVs | Only half of the learning iterations are needed to attain battery efficiency. 1.75%, and 5.03% improvement in vehicle energy efficiency and energy saving, respectively. | Despite an improvement achieved in energy efficiency, it is still low. |
| Ref. [55] HEVs | Improved fuel economy. Enhanced SOC stability. | Computational speed is not taken. |
| Ref. [57] Residential building HVAC | 15% reduced energy consumption. 79%, and 98% reduced comfort violation compared to DQN and rule-based, respectively. | Different seasoning scenarios are not considered. Various user preferences are not included. |
| Ref. [58] Active distribution network | Balanced bus voltage to the allowed range. 15% reduction of system loss. | Many training episodes are required to achieve the solutions. Slow convergence. |
| Ref. [59] Hybrid AC-DC networks (HDNs) with microgrid | Optimized computation efficiency. Enhanced stability. Solutions can be used as an initial value to accelerate the existing traditional method. Active in various states and scales. | The accomplished optimization is similar to the existing single-agent DRL algorithm. |
| Ref. [60] Microgrid | Improved dynamic performance. Enhanced online learning capabilities. High control performance. Low economic costs. | The dynamic topology of the microgrid is not considered. Repeated tests in different real-life systems are essential. |
| Ref. [61] Microgrid | Fast convergence. Efficient addressing of exploration-exploitation defect. Improved robustness in making decisions. | Different types of energy storage systems are not considered. |
| Ref. [62] EV with hybrid energy storage system | 8.75%, 6.09%, and 5.19% reduction of energy storage system loss compared to DQN, DDPG, and DP-based, respectively. Faster convergence compared to DDPG by 205.66% 32.24% improved energy saving. | The difficulty of tuning parameters. Tedious training time. Real-time performance is not verified. |
| Ref. [63] HEVs | Reduced fuel consumption. Improved robustness under different driving cycles. | Real-world validation is not attained. Platoon control is not introduced. |
| Ref. [64] EVs | 24.03%, 21.49%, and 13.8 reduced energy costs compared to EC, OA, and AEM algorithms, respectively. 7.24% reduced charging cost compared to AEM. | 5.56% increased charging cost in CALC compared to SCA. The coordination of multiple charging stations is not considered. |
| Ref. [67] multi-area energy system | Reduced random disturbance. Enhanced frequency stability. Fast convergence. | An increase in the time consumption for the convergence when the problem size is large. |
| Ref. [68] Smart grid | Optimal identification of the attack sequence under several attack objectives. Enhanced system security. | The performance of identifying vulnerable branches is required to be improved. |
| Ref. [69] Electrified off-highway vehicle | Optimized energy efficiency. Optimized real-time prediction. Enhanced energy saving. | The optimized energy efficiency takes long real-time learning (5 h) to be achieved. |
| Ref. [70] HEVs | Optimized energy management. Faster training speed. Lower fuel consumption. Adaptive to different driving cycles. | Incompatible sample selection in the planning process. |
| Ref. [71] HEVs | Fast learning. Satisfiable fuel consumption. | More optimized fuel consumption is needed. |
| Ref. [72] Power suppliers with limited information | Effective under both stationary and nonstationary environments. | Lack of reliability for virtual experience in nonstationary environments. Further validation is mandatory for scalability in more complex and variable environments. |
| Strategy/Application | Strengths | Weaknesses |
|---|---|---|
| Ref. [75] Hybrid electric powertrain | 99% of the fuel economy is achieved. 0.12% Reduced deviation from charge sustainability. | Sensitivity of the DRL algorithms is not included. |
| Ref. [76] Hybrid powertrain | 92% and 88% of fuel economy are achieved under training, and test cycles, respectively. Optimized training and running efficiency. | Reduction of fuel economy lower than 75% relative to DP EMS. |
| Ref. [77] Wind energy system | Reduced average per-day bidding cost. Optimized profit. Lowered uncertainties. | A very slight reduction in bidding cost compared to conventional existing A3C (nearly the same). |
| Ref. [78] Microgrid | Optimized performance in terms of convergence and economics. | A further enhancement is mandatory for the generalization ability of the model. |
| Ref. [79] Demand side management system | Faster learning process. Guaranteed users’ privacy. More economic decision-making. | Extra improvement to the decision-making is required by the separate training in each period. |
| Ref. [80] Demand side management system | High day-ahead achieved profit. Less required historical data. | Improvement is mandatory for real-time pricing decisions. |
| Ref. [81] Grid-connected hydropower plant | Optimal control policy. Maximized system efficiency. | Higher variation of the generator bus voltage. Voltage restrictions need to be improved. |
| Ref. [82] Autonomous vehicle | Enhanced system efficiency. Improved safety and driver comfort. | More attention is needed on fuel consumption. |
| Ref. [88] DC microgrid | Optimized voltage regulation and current sharing. | Requires more accurate compensation for packet loss data. |
| Ref. [89] DC microgrid | Improved balance of current sharing. Enhanced communication. | Communication delay. The presence of external disturbances is not considered. |
| Ref. [90] DC microgrid | The dependency of converter control on the operating set-point conditions is resolved. plug-and-play feature. Robust against uncertainties. | Unextendible strategy. |
| Ref. [91] DC microgrid | Reliable identification. Robust against communication delays and load changes. | Needs more enhancement to the identification of FDI attacks. |
| Ref. [92] AC microgrid | Robust under communication delays. Improved frequency/voltage restoration. Optimized active/reactive power sharing. | Unrobust against different communication topologies. A limitation due to the offline training model. A violation of privacy in communication. |
| Ref. [93] AC microgrid | Improved control performance. Faster reaction against disturbance. | More dependency on network configurations. |
| Ref. [94] AC microgrid | Optimized system performance. Better communication due to the reduction of channel congestion. | More training time compared to FCNN. |
| Ref. [95] AC microgrid | Greater frequency regulation. Better time-delay tolerance. | Real-time validation is not taken. |
| Ref. [96] AC microgrid | Good generalization capabilities. Enhanced reliability and resilience of energy management. | Limited to only three problem instances. Limited experienced energy profiles. Restricted energy management to only 5 agent components in the microgrid. |
| Ref. [97] Smart grid | Optimal charge/discharge. Reduced energy cost within an unknown market environment. | The randomness of PEV charging behavior. |
| Ref. [98] EV charging system in Smart grid | Better economic profits. Higher satisfaction ratio of EVs. | More extensive mathematical analysis is mandatory. Lack of estimation of actor and critic weights. Requires deeper analyzed multiagent energy scheduling. |
| Ref. [99] Smart grid | Faster convergence. Improved real-time protection. | Various grid environments are not considered. |
| Ref. [100] Building energy system | Optimized multi-objective management of the multiagent algorithm. 84%, 43%, and 8% reduction of uncomfortable duration, renewable energy consumption, and energy cost, respectively. | Lack of activity in indoor evaluation and control. Further control parameters of indoor comfort are essential. |
| Ref. [101] Intelligent building | 32%, and 21% enhancement of energy saving and thermal comfort, respectively. | The multiagent approach needs to be extended to more functional agents. Reconfiguration of the RL algorithm and clustering structure is mandatory. |
| Ref. [102] EVs | Better system resilience. Accomplished carbon intensity service. | More enhancement of system resilience is required. Multi-energy systems are not considered. |
| Ref. [103] EVs | Extendable charging performance to a larger number of EVs. More satisfaction of EV owners charging demands. | No improvement in the performance compared to the existing NLopt centralized approach in terms of the test set. |
| Ref. [104] EVs | 19.6% increase in system fairness. Robust against uncertainties. | Slight increase in rebalancing cost compared to the non-constrained MARL. |
| Ref. [105] EV charging station | A successful correction of the control signal. | Further analyze of the cyber security is mandatory. |
| Ref. [109] AC microgrid | Balanced SOC. Regulated active power. | Unrobust against communication failure. Scalability enhancement is mandatory. Plug and play is not included. |
| Ref. [110] DC microgrid | Balanced and fast charge/discharge. Active with different ESS capacities. Enhanced ESS protection. | The speed of SOC balance is still faster in the conventional strategy. |
| Ref. [111] DC microgrid | Balanced SOC. No circulating current and overloading. Activated plug and play. | Solving the overloading defect is prioritized over the accuracy of charge–discharge synchronization to reduce sliding mode chattering. |
| Ref. [112] AC microgrid | Balanced SOC. An enhanced balance of frequency, voltage, and reactive power sharing. | The control with heterogeneous BESSs is not considered. |
| Ref. [113] DC microgrid | Active under various microgrid operating conditions and weak communication. Balanced SOC under different energy storage capacities. The control is independent of line impedance. | Still existing instability of output voltage. |
| Ref. [115] Competitive electricity market | Better performance in terms of accuracy and convergence speed. | Game theory and Nash equilibrium are not introduced to make the entire electricity market closer to reality. More accurate results can be achieved through a more optimized load-forecasting model. |
| Ref. [116] Office buildings | Higher accuracy under different building locations. | Limited to office buildings. Applicable only with the availability of 24 h weather forecast data. |
| Ref. [117] Integrated energy systems | Satisfactory predictions can be achieved with small sample data. | Economic energy price, and demand response factors are not considered. |
| Ref. [119] multi-cell network | Reduced transient time. Improved long-term network performance. | Unadaptive to different network conditions. |
| Ref. [120] Unmanned aerial vehicle | Better learning efficiency. Extendable to other existing frameworks. | Energy saving due to the optimized navigation is not investigated. |
| Ref. [121] Nuclear power plant | Good, achieved scalability. Optimized nuclear fuel. Enhanced competitive performance. | Despite good scalability, still, replay memory management consumes 53% of the computing time. |
| Ref. [124] Internet of vehicles system | Optimized average cumulative reward. Improved convergence speed. Higher scalability. | A still decrease in the reward with the increase in the initial load. Despite it is higher than the random and the DQN. |
| Ref. [125] Residential demand response system | 14.51%, and 6.68% reduction of the cost compared to regular hysteresis controllers and traditional PPO, respectively. | A computation drawback during the inclusion of expert knowledge in the learning pipeline. |
| Ref. [126] Power grid management system | Optimized policy. No reliance on the expert experience. | Imitation learning algorithm is not introduced. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Saadi, M.; Al-Greer, M.; Short, M. Reinforcement Learning-Based Intelligent Control Strategies for Optimal Power Management in Advanced Power Distribution Systems: A Survey. Energies 2023, 16, 1608. https://doi.org/10.3390/en16041608
Al-Saadi M, Al-Greer M, Short M. Reinforcement Learning-Based Intelligent Control Strategies for Optimal Power Management in Advanced Power Distribution Systems: A Survey. Energies. 2023; 16(4):1608. https://doi.org/10.3390/en16041608
Chicago/Turabian StyleAl-Saadi, Mudhafar, Maher Al-Greer, and Michael Short. 2023. "Reinforcement Learning-Based Intelligent Control Strategies for Optimal Power Management in Advanced Power Distribution Systems: A Survey" Energies 16, no. 4: 1608. https://doi.org/10.3390/en16041608