Review of Energy-Related Machine Learning Applications in Drying Processes

 ,
,
Abstract
:1. Introduction
- –
- evaporation load reduction, which can be accomplished by minimizing the initial moisture content or by avoiding over-drying;
- –
- enhancement of the dryer efficiency by reducing heat losses, implementing heat recovery, or changing operating parameters;
- –
- improving the energy supply utility system through the strategies of increasing boiler efficiency, reducing distribution losses, adopting combined heat and power (CHP) systems, incorporating heat pumps, utilizing waste incineration, or exploring low-cost fuel alternatives.
2. Methodology
2.1. Decision Tree
- The construction of a tree is done by the algorithm using a recursive partitioning of the data into the subsets based on the values of the input features. At each node of the tree, the algorithm selects the best feature to split the data based on a criterion (e.g. information gain or Gini impurity).
- The splitting of the decision tree algorithm data is being continued until a stopping criterion is reached. It can be a maximum tree depth, a minimum number of samples per leaf node, or a minimum information gain.
- After the construction of the tree, the algorithm can be used to predict new instances. Root node of the tree is a start point for prediction making. Then the decision rules are followed until a leaf node is reached, which label or value is then considered to be the prediction.
- The missing values in the input features can be handled by using various strategies (e.g., surrogate splits, which use alternative features to make the decision, or imputation of the missing values based on the values of other features).
- Regularization of the algorithm can be done by pruning the tree. It is done in order to remove unnecessary branches, which is the way to prevent overfitting and to reduce the complexity of the model.
- The hyperparameters which can be tuned in order to optimize the performance of the algorithm are: the maximum tree depth, the minimum number of samples per leaf node, and the criterion used for splitting the data.
- –
- Recursive partitioning of the data into the subsets based on the values of the input features;
- –
- Stop when a stopping criterion is met.
- –
- Prediction: Start at the root node of the tree;
- –
- Follow the decision rules until reaching a leaf node;
- –
- Use the label or value at the leaf node as the prediction.
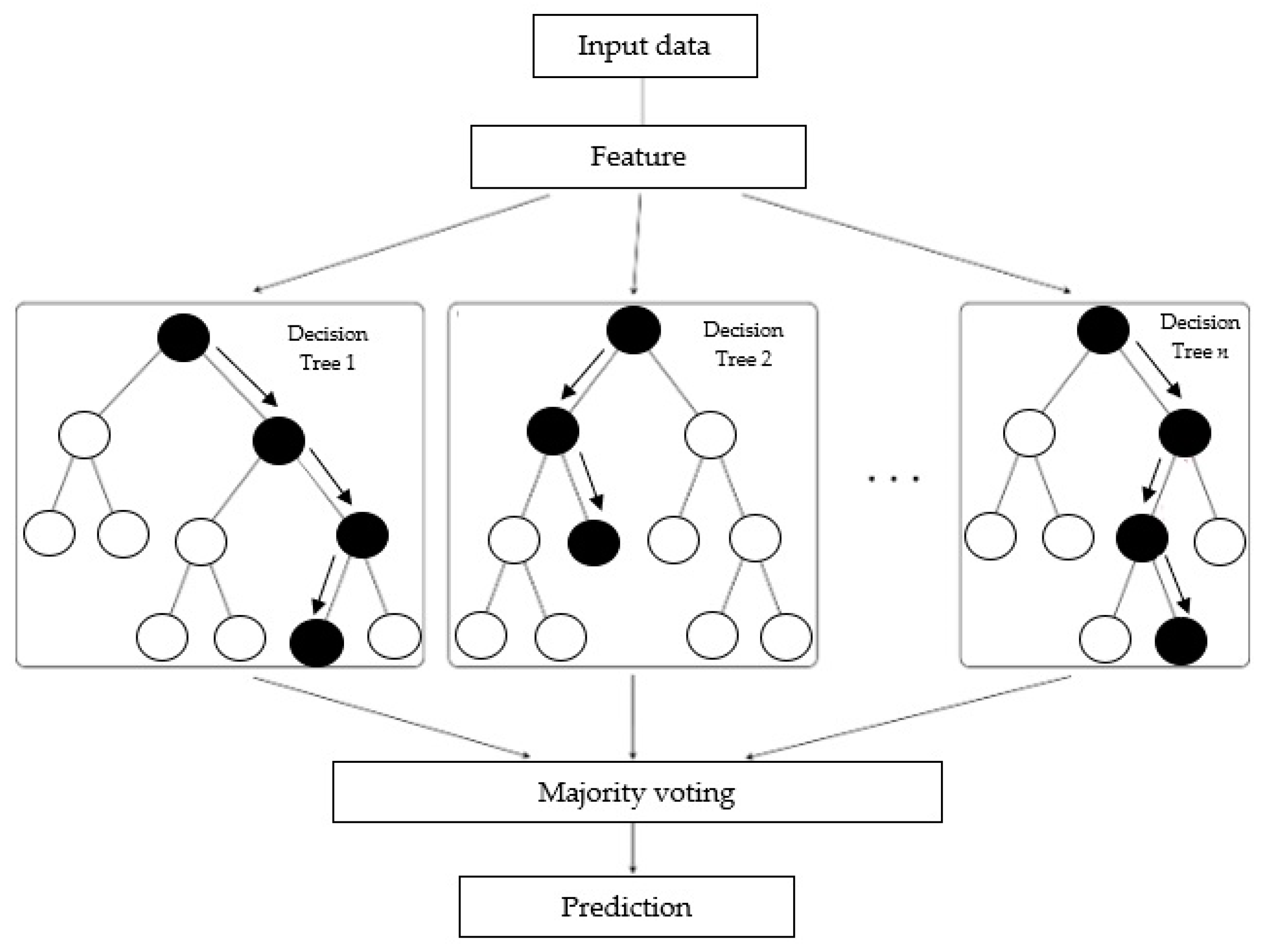
2.2. Random Forest
- Random forest uses a technique called bagging (bootstrap aggregating) for creation of a collection of the decision trees. It involves multiple random subsets of the training data creation, and training a decision tree on each subset. Averaging of the predictions of all the trees results in the final prediction.
- A random subset of the input features which could be considered to be the best split is selected by the algorithm at each node of each decision tree. This is the way to improve the overall model performance and to help reduction of the correlation among the trees.
- In order to provide a prediction, random forest calculates the average prediction of all the decision trees (for regression tasks), or takes a majority vote (for classification tasks).
- Handling of the missing values in input features can be fulfilled through different strategies, either by so called surrogate splits or imputation of the missing values based on the values of other features.
- Regularization of random forest can be done by tuning the hyperparameters. They can be, e.g., the number of the trees in the forest, the maximum tree depth, and the number of features to consider at each node.
- There hyperparameters can be, also, tuned for optimization of the performance of the algorithm’s performance.
2.3. Support Vector Machine (SVM)
- Kernel function calculation: the kernel function is calculated because it maps the input data into a higher-dimensional space in which is easier to find a hyperplane that separates the data into different classes.
- The hyperplane that maximally separates the data into different classes is found. The hyperplane is chosen in that way that it has the largest distance to the nearest data point from each class.
- The hyperplane is the base for the prediction of the algorithm.
2.4. Support Vector Regression (SVR)
- Kernel function is calculated. It maps input data into a higher-dimensional space. It is done because it is easier there to find a hyperplane which approximates the data.
- The hyperplane approximating the data with the smallest error is found.
- The hyperplane is the base for the prediction of the algorithm.
- The error between the predicted and true values is calculated.
- The hyperplane is updated based on the calculated error.
2.5. k-Nearest Neighbors (kNN)
- Calculation of the distance between the input data and all the training data.
- K training data points that are closest to the input data are selected.
- The output based on the K-nearest neighbors is calculated (if the kNN algorithm is used for classification, the class having the most representatives among the K-nearest neighbors will be predicted).
- Finally, a prediction based on the calculated output is made.
2.6. Artificial Neural Networks (ANN)
- Feedforward neural networks (FNNs), which are the simplest type of ANN. The information goes in one direction, from the input layer to the output layer, without any feedback loops. FNNs have an input, one or more hidden layers, and an output layer. Each node in a layer is connected to all of the nodes in the next layer. The weights of the connections are adjusted during training in order to minimize the error between the predicted and actual outputs.
- Recurrent neural networks (RNNs) are a type of ANN with the feedback loops, allowing the information to flow in a circular fashion. RNNs are well-suited for processing sequential data (e.g., time series), since they can maintain a memory of the previous inputs. RNNs have a temporal dimension, where the hidden state at time t is a function of the hidden state and input at time t − 1.
- Convolutional neural networks (CNNs) are a ANNs designed for processing grid-like data, such as images. CNNs consist of convolutional, pooling, and fully connected layers. The convolutional layers apply a set of filters or kernels to the input data, which detect local patterns or features. The pooling layers are used to reduce the spatial dimensions of the data, while preserving the most important features. The final classification or regression task is performed by fully connected layers.
- Autoencoders (AEs) are type of ANNs used for unsupervised learning, where the goal is to learn a compact representation of the input data. AEs consist of an encoder and a decoder, where the encoder maps the input data to a lower-dimensional latent space, and the decoder maps the latent space back to the original data. AEs are often used for dimensionality reduction, denoising, and generative modeling.
- There are two components that make up Generative adversarial networks (GANs).
2.7. Feedforward ANN
- Input of the data into the input layer.
- Calculation of the output of the input data
- The output of each of the hidden layers is based on the output of the previous layer and the weights of the connections between the layers.
- The output of the output layer based on the output of the previous layer and the weights of the connections between the layers are calculated.
- The prediction represents the output of the algorithm.
2.8. Backpropagation ANN
- The algorithm inputs the data into the input layer.
- The output of each layer based on the output of the previous layer and the weights of the connections between the layers are calculated.
- The prediction is obtained as the output.
- The error between the predicted output and the true output is calculated. After that, this error is propagated backwards through the network, adjusting the weights of the connections as it goes.
- The error between the predicted output and the true output is calculated.
2.9. Recurrent Neural Network (RNN)
- The algorithm inputs the data into the input layer.
- The output of each layer, based on the output of the previous layer, the weights of the connections between the layers, and the previous state of the hidden layer is calculated.
- The prediction is the output.
- The error between the predicted output and the true output is calculated. After that, this error is propagated backwards through the network, adjusting the weights of the connections as it goes.
- The error between the predicted output and the true output is calculated by the algorithm.
2.10. Long Short-Term Memory (LSTM)
- The algorithm inputs the data into the LSTM cell.
- The cell state and output based on the input data and the previous cell state are calculated by the algorithm.
- The cell state based on the calculated cell state and output are calculated by the algorithm.
- The calculated output is outputted by the algorithm.
2.11. eXtreme Gradient Boosting (XGBoost)
2.12. CatBoost
3. Key Insights and Discussion
3.1. Application of Artificial Neural Networks for Drying
- R2max—maximum value of R2 = 1
- R2predicted—value of R2 from evaluation of model performance
- n—number of data
- Establishment of the time series model;
- The model is used to fit historical data on energy consumption + continuous adjustment of the parameters based on the prediction results;
- Feedback on potential causes if energy consumption prediction did not meet the requirements;
- Readjustment of the parameters and models based on visual prediction results and problems.
- g(t)—a trend function that represents time series data;
- s(t)—a seasonal change that reflects the nature of daily, weekly, monthly, or annual changes in the data;
- h(t)—holiday term of the data (indicating the occurrence of irregular holiday effects on certain days);
- e(t)—error term which indicates special variations or random features that cannot be accommodated by the model.
- –
- Data collection (data gathering for the drying process, including moisture content, temperature, humidity, and energy consumption from literature reviews, experiments, or some existing or made databases).
- –
- Feature selection (identification of the most relevant features influencing the power consumption, e.g., in solar-based dryers these features are solar irradiance, temperature, humidity, and the properties of drying material).
- –
- Model development (of a predictive power consumption model for identification of patterns and relationships between the features and power consumption)
- –
- Model evaluation (through the performance assessment of the developed model using metrics—accuracy, precision, recall, and F1-score; by comparisons of the predicted values with the actual power consumption data).
- –
- Model optimization (by fine-tuning of the model parameters and hyperparameters using grid search, random search, or Bayesian optimization techniques).
- –
- Model deployment (integration of the developed model into a user-friendly interface or system allowing regular users to obtain power consumption predictions based on their input data).
- –
- Continuous monitoring and update (update if needed in order to take into account the factors influencing power consumption).
3.2. The Applications of Other Machine Learning Algorithms for Energy Issues
3.3. Mathematical Modeling
- —the output of neuron i;
- —the set of other neurons which it gets input from;
- —an adjustable “weight” representing the strength of the connection from neuron j to neuron i;
- —the function defined by:
- when
- when .
- —trend for modeling of non-periodic changes;
- —seasonality;
- —holidays (effects of potentially irregular schedules longer than a day);
- —errors (for the changes not accommodated by the model).
- –
- a saturating growth model;
- –
- a piecewise linear model.
- —carrying capacity (not constant, hence it is replaced by );
- —growth rate (not constant, hence a vector of rate adjustments is defined , where are the changepoints at times and is the change in rate that occurs at time );
- —offset parameter.
- is the rate of adjustment, and for making a continuous function is set to .
3.3.1. The Applications of Machine Learning for Solar Energy Issues
3.3.2. Heat Pump Drying System and Mathematical Modeling
3.3.3. Energy Efficiency Issues of Drying
3.4. Observations about the Scientific Potential of AI (ML)-Based Approaches
3.5. Identified Challenges
3.6. Identified Opportunities
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mujumdar, A.S. Handbook of Industrial Drying, 4th ed.; CRC Press: Boca Raton, FL, USA; Taylor & Francis Group: London, UK; New York, NY, USA, 2015. [Google Scholar]
- Claussen, I.C.; Sannan, S.; Bantle, M.; Lauermann, M.; Wilk, V. DryFiciency Waste Heat Recovery in Industrial Drying Processes. In Specification of Performance Indicators and Validation Requirements D1.2; EU Project No.: 723576; European Union: Maastricht, The Netherlands.
- Tsotsas, E.; Mujumdar, A.S. (Eds.) Modern Drying. Technology; Volume 4: Energy Savings; WILEY-VCH: Weinheim, Germany, 2012. [Google Scholar]
- Samuel, A.L. Some studies in machine learning using the game of checkers. IBM J. Res. Dev. 1959, 44, 206–226. [Google Scholar] [CrossRef]
- Jinescu, G.; Lavric, V. The artificial neural networks and the drying process modeling. Dry Technol. 1995, 13, 1579–1586. [Google Scholar] [CrossRef]
- Martynenko, A.; Misra, N.N. Machine learning in drying. Dry Technol. 2019, 38, 596–609. [Google Scholar] [CrossRef]
- Aghbashlo, M.; Hosseinpour, S.; Mujumdar, A.S. Application of Artificial Neural Networks (ANNs) in Drying Technology-A Comprehensive Review. Dry Technol. 2015, 33, 1397–1462. [Google Scholar] [CrossRef]
- Sun, Q.; Zhang, M.; Mujumdar, A.S. Recent developments of artificial intelligence in drying of fresh food: A review. Crit. Rev. Food Sci. Nutr. 2018, 59, 2258–2275. [Google Scholar] [CrossRef] [PubMed]
- Klyuev, R.V.; Morgoev, I.D.; Morgoeva, A.D.; Gavrina, O.A.; Martyushev, N.V.; Efremenkov, E.A.; Mengxu, Q. Methods of Forecasting Electric Energy Consumption: A Literature Review. Energies 2022, 15, 8919. [Google Scholar] [CrossRef]
- Guo, Y.; Lv, M.; Wang, C.; Ma, J. Energy controls wave propagation in a neural network with spatial stimuli. Neural. Netw. 2023, 171, 1–13. [Google Scholar]
- Quinlan, J.R. A task-independent experience gathering scheme for a problem solver. In Proceedings of the First International Joint Conference on Artificial Intelligence, Washington, DC, USA, 7–9 May 1969; Morgan Kaufmann: Washington, DC, USA, 1969. [Google Scholar]
- Quinlan, J.R. Induction of Decision Trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Vapnik, V.N.; Chervonenkis, A.Y. A class of algorithms for pattern recognition learning. Avtom Telemekh 1964, 25, 937–945. (In Russian) [Google Scholar]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Fix, E.; Hodges, J.L. Discriminatory Analysis, Nonparametric Discrimination: Consistency Properties; Technical Report 4; USAF School of Aviation Medicine: Randolph Field, TX, USA, 1951. [Google Scholar]
- Cover, T.M.; Hart, P.E. Nearest Neighbor Pattern Classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- McCulloch, W.S.; Pitts, W.H. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Werbos, P.J. Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Sciences. Ph.D. Thesis, Harvard University, Cambridge, MA, USA, 1974. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural. Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Krishnapuram, B., Shah, M., Smola, A.J., Aggarwal, C.C., Shen, D., Rastogi, R., Eds.; pp. 785–794. [Google Scholar]
- Khan, M.I.H.; Sablani, S.S.; Nayak, R.; Gu, Y. Machine learning-based modeling in food processing applications: State of the art. Compr. Rev. Food Sci. Food Saf. 2022, 21, 1409–1438. [Google Scholar] [CrossRef] [PubMed]
- Tagnamas, Z.; Idlimam, A.; Lamharrar, A. Predictive models of beetroot solar drying process through machine learning algorithms. Renew. Energy 2023, 219, 119522. [Google Scholar] [CrossRef]
- Zou, Z.; Wu, Q.; Chen, J.; Long, T.; Wang, J.; Zhou, M.; Zhao, Y.; Yu, T.; Wang, Y.; Xu, L. Rapid determination of water content in potato tubers based on hyperspectral images and machine learning algorithms. Food Sci. Technol. 2022, 42, e46522. [Google Scholar] [CrossRef]
- Karthik, C.; Valarmathi, K.; Rajalakshmi, M. Support vector regression and model reference adaptive control for optimum control of nonlinear drying process. Process. Control 2016, 15, 111–126. [Google Scholar]
- Rahimi, S.; Nasir, V.; Avramidis, S.; Sassani, F. The Role of Drying Schedule and Conditioning in Moisture Uniformity in Wood: A Machine Learning Approach. Polymers 2023, 15, 792. [Google Scholar] [CrossRef]
- Karaağaç, M.O.; Ergün, A.; Ağbulut, Ü.; Gürel, A.E.; Ceylan, İ. Experimental analysis of CPV/T solar dryer with nano-enhanced PCM and prediction of drying parameters using ANN and SVM algorithms. Sol. Energy 2021, 218, 57–67. [Google Scholar] [CrossRef]
- Sun, Y.; Zhang, M.; Mujumdar, A.S.; Yu, D. Pulse-spouted microwave freeze drying of raspberry: Control of moisture using ANN model aided by LF-NMR. J. Food Eng. 2021, 292, 110354. [Google Scholar] [CrossRef]
- Fabani, M.P.; Capossio, J.P.; Román, M.C.; Zhu, W.; Rodriguez, R.; Mazza, G. Producing non-traditional flour from watermelon rind pomace: Artificial neural network (ANN) modeling of the drying process. J. Environ. Manag. 2021, 281, 111915. [Google Scholar] [CrossRef] [PubMed]
- Kaveh, M.; Chayjan, R.A.; Golpour, I.; Poncet, S.; Seirafi, F.; Khezri, B. Evaluation of exergy performance and onion drying properties in a multi-stage semi-industrial continuous dryer: Artificial neural networks (ANNs) and ANFIS models. Food Bioprod. Process. 2021, 127, 58–76. [Google Scholar] [CrossRef]
- Beigi, M.; Torki-Harchegani, M.; Tohidi, M. Experimental and ANN modeling investigations of energy traits for rough rice drying. Energy 2017, 141, 2196–2205. [Google Scholar] [CrossRef]
- Meerasri, J.; Sothornvit, R. Artificial neural networks (ANNs) and multiple linear regression (MLR) for prediction of moisture content for coated pineapple cubes. Case. Stud. Therm. Eng. 2022, 33, 101942. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, M.; Mujumdar, A.S.; Yu, D. Advanced Detection Techniques Using Artificial Intelligence in Processing of Berries. Food Eng. Rev. 2022, 14, 176–199. [Google Scholar] [CrossRef]
- Przybył, K.; Koszela, K. Applications MLP and Other Methods in Artificial Intelligence of Fruit and Vegetable in Convective and Spray Drying. Appl. Sci. 2023, 13, 2965. [Google Scholar] [CrossRef]
- Khan, M.I.H.; Batuwatta-Gamage, C.P.; Karim, M.A.; Gu, Y. Fundamental Understanding of Heat and Mass Transfer Processes for Physics-Informed Machine Learning-Based Drying Modelling. Energies 2022, 15, 9347. [Google Scholar] [CrossRef]
- Cavalcante, E.S.; Sales Vasconcelos, L.G.; Brito, K.D.; Brito, R.P. Neural network predictive control applied to automotive paint drying and curing processes. Prog. Org. Coat. 2023, 183, 107773. [Google Scholar] [CrossRef]
- Chokphoemphun, S.; Hongkong, S.; Chokphoemphun, S. Evaluation of drying behavior and characteristics of potato slices in multi–stage convective cabinet dryer: Application of artificial neural network. Inf. Process. Agric. 2023, in press. [Google Scholar] [CrossRef]
- Chuwattanakul, V.; Wongcharee, K.; Pimsarn, M.; Chokphoemphun, S.; Chamoli, S.; Eiamsa-ard, S. Effect of conical air distributors on drying of peppercorns in a fluidized bed dryer: Prediction using an artificial neural network. Case Stud. Therm. Eng. 2022, 36, 102188. [Google Scholar] [CrossRef]
- Kong, Y.K.; Kurumisawa, K. Prediction of the drying shrinkage of alkali-activated materials using artificial neural networks. Case Stud. Constr. Mater. 2022, 17, e01166. [Google Scholar] [CrossRef]
- George, O.A.; Putranto, A.; Xiao, J.; Olayiwola, P.S.; Dong Chen, X.; Ogbemhe, J.; Akinyemi, T.J.; Kharaghani, A. Deep neural network for generalizing and forecasting on-demand drying kinetics of droplet solutions. Powder Technol. 2022, 403, 117392. [Google Scholar] [CrossRef]
- Voca, N.; Pezo, L.; Peter, A.; Suput, D.; Loncar, B.; Kricka, T. Modeling of corn kernel pre-treatment, drying and processing for ethanol production using artificial neural networks. Ind. Crops. Prod. 2021, 162, 113293. [Google Scholar] [CrossRef]
- Nanvakenari, S.; Movagharnejad, K.; Latifi, A. Evaluating the fluidized-bed drying of rice using response surface methodology and artificial neural network. LWT 2021, 147, 111589. [Google Scholar] [CrossRef]
- Tarafdar, A.; Jothi, N.; Kaur, B.P. Mathematical and artificial neural network modeling for vacuum drying kinetics of Moringa olifera leaves followed by determination of energy consumption and mass transfer parameters. J. Appl. Res. Med. Aromat. Plants 2021, 24, 100306. [Google Scholar] [CrossRef]
- Bhagya Raj, G.V.S.; Dash, K.K. Microwave vacuum drying of dragon fruit slice: Artificial neural network modelling, genetic algorithm optimization, and kinetics study. Comput. Electron. Agric. 2020, 178, 105814. [Google Scholar] [CrossRef]
- Chasiotis, V.K.; Tzempelikos, D.A.; Filios, A.E.; Moustris, K.P. Artificial neural network modelling of moisture content evolution for convective drying of cylindrical quince slices. Comput. Electron. Agric. 2020, 172, 105074. [Google Scholar] [CrossRef]
- Perazzini, H.; Bitti Perazzini, M.T.; Meili, L.; Freire, F.B.; Freire, J.T. Artificial neural networks to model kinetics and energy efficiency in fixed, fluidized and vibro-fluidized bed dryers towards process optimization. Chem. Eng. Process. 2020, 156, 108089. [Google Scholar] [CrossRef]
- Garavand, A.T.; Mumivand, H.; Fanourakis, D.; Fatahi, S.; Taghipour, S. An artificial neural network approach for non-invasive estimation of essential oil content and composition through considering drying processing factors: A case study in Mentha aquatica. Ind. Crops. Prod. 2021, 171, 113985. [Google Scholar] [CrossRef]
- Çağatay Selvi, K.; Alkhaled, A.Y.; Yıldız, T. Application of Artificial Neural Network for Predicting the Drying Kinetics and Chemical Attributes of Linden (Tilia platyphyllos Scop.) during the Infrared Drying Process. Processes 2022, 10, 2069. [Google Scholar] [CrossRef]
- Sarkar, T.; Salauddin, M.; Hazra, S.K.; Chakraborty, R. Artificial neural network modelling approach of drying kinetics evolution for hot air oven, microwave, microwave convective and freeze dried pineapple. Appl. Sci. 2020, 2, 1621. [Google Scholar] [CrossRef]
- Subramanyam, R.; Narayanan, M. Artificial neural network modeling for drying kinetics of paddy using a cabinet tray dryer. Chem. Ind. Chem. Eng. Q. 2023, 29, 87–97. [Google Scholar] [CrossRef]
- Loan, L.T.K.; Thuy, N.M.; Tai, N.V. Mathematical and artificial neural network modeling of hot air drying kinetics of instant “Cẩm” brown rice. Braz. Food Sci. Technol. 2023, 43, e27623. [Google Scholar] [CrossRef]
- Tran, D.A.T.; Nguyen, V.T.; Le, D.N.H.; Ho, T.K.P. Application of Generalized Regression Neural Network for drying of sliced bitter gourd in a halogen dryer. Braz. J. Food Technol. 2023, 26, e2022142. [Google Scholar] [CrossRef]
- Nayak, P.; Rayaguru, K.; Bal, L.M.; Das, S.; Dash, S.K. Artificial Neural Network Modeling of Hot-air Drying Kinetics of Mango Kernel. J. Sci. Ind. Res. 2021, 80, 750–758. [Google Scholar]
- Lu, Y.; Sheng, B.; Fu, G.; Luo, R.; Chen, G.; Huang, Y. Prophet-EEMD-LSTM based method for predicting energy consumption in the paint workshop. Appl. Soft. Comput. 2023, 143, 110447. [Google Scholar] [CrossRef]
- Ma, S.; Jiang, Z.; Liu, W. Modeling drying-energy consumption in automotive painting line based on ANN and MLR for real-time prediction. Int. J. Precis. Eng. Manuf. Green. Technol. 2019, 6, 241–254. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, X.; Zhang, Q.; Huang, C. Empirical mode decomposition based hybrid ensemble model for electiral energy consumption forecasting of the cement grinding process. Measurement 2019, 138, 314–324. [Google Scholar] [CrossRef]
- Lu, H.; Cheng, F.; Ma, X.; Hu, G. Short-term prediction of building energy consumption employing an improved extreme gradient boosting model: A case study of an intake tower. Energy 2020, 203, 117756. [Google Scholar] [CrossRef]
- Xu, Y.; Gao, W.J.; Qian, F.Y.; Li, Y. Potential analysis of the attention-based LSTM model in ultra-short-term-forecasting of building HVAC energy consumption. Front. Energy Res. 2021, 9, 730640. [Google Scholar] [CrossRef]
- Taylor, S.J.; Letham, B. Forecasting to Scale. PeerJ Prepr. 2017, e3190v2. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.-C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. Lond. Ser. A Math. Phys. Eng. Sci. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Ifaei, P.; Nazari-Heris, M.; Charmchi, A.S.T.; Asadi, S.; Yoo, C.K. Sustainable energies and machine learning: An organized review of recent applications and challenges. Energy 2023, 266, 126432. [Google Scholar] [CrossRef]
- Das, M.; Alic, E.; Akpinar, E.K. Detailed Analysis of Mass Transfer in Solar Food Dryer with Different Methods. Int. Commun. Heat. Mass. Transfer. 2021, 128, 105600. [Google Scholar] [CrossRef]
- Werbos, P. Neural networks as a path so self-awareness. In Proceedings of the 2011 International Joint Conference on Neural Networks, San Jose, CA, USA, 31 July–5 August 2011. [Google Scholar]
- Minsky, M.; Papert, S. Perceptrons: An Introduction to Computational Geometry; MIT Press: Cambridge, MA, USA, 1969. [Google Scholar]
- Wu, Z.; Huang, N.E. Ensemble Empirical Mode Decomposition: A Noise-Assisted Data Analysis Method. Adv. Adapt. Data Anal. 2009, 1, 1–41. [Google Scholar] [CrossRef]
- Raza, M.Q.; Nadarajah, M.; Ekanayake, C. On recent advances in PV output power forecast. Sol. Energy 2016, 136, 125–144. [Google Scholar] [CrossRef]
- Lin, F.; Zhang, Y.; Wang, J. Recent advances in intra-hour solar forecasting: A review of ground-based sky image methods. Int. J. Forecast. 2023, 39, 244–265. [Google Scholar] [CrossRef]
- Cetina-Quinones, A.J.; Santamaria-Bonfil, G.; Medina-Esquivel, R.A.; Bassam, A. Techno-economic analysis of an indirect solar dryer with thermal energy storage: An approach with machine learning algorithms for decision making. Therm. Sci. Eng. Prog. 2023, 45, 102131. [Google Scholar] [CrossRef]
- Liu, S.; Li, X.; Song, M.; Li, H.; Sun, Z. Experimental investigation on drying performance of an existed enclosed fixed frequency air source heat pump drying system. Appl. Therm. Eng. 2018, 130, 735–744. [Google Scholar]
- Peter, M.; Liu, Z.; Fang, Y.; Dou, X.; Awuah, E.; Soomro, S.A.; Chen, K. Computational intelligence and mathematical modelling in chanterelle mushrooms’ drying process under heat pump dryer. Biosyst. Eng. 2021, 212, 143–159. [Google Scholar] [CrossRef]
- Hamid, K.; Sajjad, U.; Yang, K.S.; Wu, S.; Wang, C. Assessment of an energy efficient closed loop heat pump dryer for high moisture contents materials: An experimental investigation and AI based modelling. Energy 2022, 238, 121819. [Google Scholar] [CrossRef]
- Doder, Đ.D.; Đaković, D.D. Energy Savings in Convective Drying of Various Materials Using Variable Temperature Conditions. Environ. Prog. Sustain. Energy 2020, 39, 13277. [Google Scholar] [CrossRef]
- Menon, A.; Stojceska, V.; Tassou, S.A. A Systematic Review on the Recent Advances of the Energy Efficiency Improvements in Non-Conventional Food Drying Technologies. Trends Food.Sci. Technol. 2020, 100, 67–76. [Google Scholar] [CrossRef]
- Zhu, L.; Spachos, P.; Pensini, E.; Plataniotis, K.N. Deep Learning and Machine Vision for Food Processing: A Survey. Curr. Res. Food Sci. 2021, 4, 233–249. [Google Scholar] [CrossRef] [PubMed]
- Moscetti, R.; Raponi, F.; Cecchini, M.; Monarca, D.; Massantini, R. Feasibility of Computer Vision as Process Analytical Technology Tool for the Drying of Organic Apple Slices. Acta Hortic. 2021, 433–438. [Google Scholar] [CrossRef]
- Pinheiro, R.d.M.; Gadotti, G.I.; Bernardy, R.; Tim, R.R.; Pinto, K.V.A.; Buck, G. Computer Vision by Unsupervised Machine Learning in Seed Drying Process. Cienc. Agrotecnologia 2023, 47, e018922. [Google Scholar] [CrossRef]
- Fracarolli, J.A.; Pavarin, F.F.A.; Castro, W.; Blasco, J. Computer Vision Applied to Food and Agricultural Products. Cienc. Agron. 2020, 51. [Google Scholar] [CrossRef]
- Wang, H.; Gu, J.; Wang, M. A Review on the Application of Computer Vision and Machine Learning in the Tea Industry. Front. Sustain. Food Syst. 2023, 7, 1172543. [Google Scholar] [CrossRef]
- Kakani, V.; Nguyen, V.H.; Kumar, B.P.; Kim, H.; Pasupuleti, V.R. A Critical Review on Computer Vision and Artificial Intelligence in Food Industry. J. Agric. Food Res. 2020, 2, 100033. [Google Scholar] [CrossRef]
- Keramat-Jahromi, M.; Mohtasebi, S.S.; Mousazadeh, H.; Ghasemi-Varnamkhasti, M.; Rahimi-Movassagh, M. Real-Time Moisture Ratio Study of Drying Date Fruit Chips Based on on-Line Image Attributes Using kNN and Random Forest Regression Methods. Measurement 2021, 172, 108899. [Google Scholar] [CrossRef]
- Nayak, J.; Vakula, K.; Dinesh, P.; Naik, B.; Pelusi, D. Intelligent Food Processing: Journey from Artificial Neural Network to Deep Learning. Comput. Sci. Rev. 2020, 38, 100297. [Google Scholar] [CrossRef]
- Ortiz-Rodríguez, N.M.; Condorí, M.; Durán, G.; García-Valladares, O. Solar Drying Technologies: A Review and Future Research Directions with a Focus on Agroindustrial Applications in Medium and Large Scale. Appl. Therm. Eng. 2022, 215, 118993. [Google Scholar] [CrossRef]
- Olivares, J.C.; Guerrero, A.R.; Gonzalez, J.G.B.; Silva, R.L.; Piocchardod, J.F.B.; Alonso, C.P. Importance of computational tools and artificial intelligence to improve drying processes for food preservation. S. Fla. J. Dev. 2023, 4, 1981–1993. [Google Scholar] [CrossRef]
- Liu, Z.; Xu, Y.; Han, F.; Zhang, Y.; Wang, G.; Wu, Z.; Wu, W. Control Method for Continuous Grain Drying Based on Equivalent Accumulated Temperature Mechanism and Artificial Intelligence. Foods 2022, 11, 834. [Google Scholar] [CrossRef]
- Ben Ayed, R.; Hanana, M. Artificial Intelligence to Improve the Food and Agriculture Sector. J. Food Qual. 2021, 5584754. [Google Scholar] [CrossRef]
- Kaveh, M.; Çetin, N.; Khalife, E.; Abbaspour-Gilandeh, Y.; Sabouri, M.; Sharifian, F. Machine Learning Approaches for Estimating Apricot Drying Characteristics in Various Advanced and Conventional Dryers. J. Food Process. Eng. 2023, 46, e14475. [Google Scholar] [CrossRef]
- Li, Z.; Feng, Z.; Zhang, Z.; Sun, S.; Chen, J.; Gao, Y.; Zhao, H.; Lv, H.; Wu, Y. Analysis of energy consumption of tobacco drying process based on industrial big data. Dry Technol. 2023. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Wet Material | Type of Dryer | Artificial Neural Network Type | Training Algorithm | Activation Function | Output | Ref. |
|---|---|---|---|---|---|---|
| Automotive Paint | Industrial electrodeposition oven | Feedforward Multi-layer Perceptron | Backpropagation | Hyperbolic tangent | Drying temperature | [36] |
| Potato slices | Multi–stage convective cabinet dryer | Feedforward Multi-layer Perceptron | Backpropagation | - | Moisture ratio Area ratio shrinkage | [37] |
| Pepper | Fluidized-bed dryer | Feedforward Multi-layer Perceptron | Backpropagation | - | Moisture content | [38] |
| Alkali-activated materials—Geopolymers | - | Feedforward Multi-layer Perceptron | Backpropagation | Tangent Sigmoid | Drying shrinkage | [39] |
| Droplet solutions | Spray dryer | Long short-term memory neural network | - | - | Drying kinetics | [40] |
| Pineapple cubes | Hot-air dryer | Feedforward Multi-layer Perceptron | Levenberg–Marquardt | Sigmoid Hyperbolic tangent | Moisture ratio Drying rate | [41] |
| Corn kernel | - | Feedforward Multi-layer Perceptron | Broyden–Fletcher–Goldfarb–Shanno algorithm | Logarithmic Logistic Tangent Hyperbolic | Moisture content Corn kernel weight | [32] |
| Rice | Fluidized-bed dryer | Feedforward Multi-layer Perceptron | Backpropagation | - | Drying time Head rice yield Whiteness index Water uptake ratio Elongation ratio | [42] |
| Watermelon | Solar dryer | Feedforward Multi-layer Perceptron | Levenberg–Marquardt Backpropagation Genetic algorithm | Sigmoid Linear | Moisture ratio | [29] |
| Moringa oleifera | Vacuum dryer | Feedforward Multi-layer Perceptron | Levenberg–Marquardt | Hyperbolic tangent sigmoid Logarithmic sigmoid Linear | Moisture ratio Moisture content | [43] |
| Onion | Multi-stage semi-industrial continuous dryer | Feedforward Multi-layer Perceptron Cascade Forward Neural Network (CFNN) | Backpropagation Bayesian regulation Levenberg–Marquardt | Hyperbolic tangent sigmoid Logarithmic sigmoid Linear | Moisture ratio Energy utilization Energy utilization ratio Exergy loss Exergy efficiency | [30] |
| Dragon Fruit | Microwave vacuum dryer | Feedforward Multi-layer Perceptron | Backpropagation | Sigmoid | Drying efficiency Rehydration ratio | [44] |
| Quince | Hot air chamber dryer | Feedforward Multi-layer Perceptron | Backpropagation Adaptive moment estimation (Adam) | Exponential linear unit Softplus activation Rectified linear unit Hyperbolic tangent Sigmoid Linear | Moisture content | [45] |
| Aluminum oxide particles (Al2O3) | Fluidized bed dryer Fixed bed dryer Vibro-fluidized bed dryer | Feedforward Multi-layer Perceptron | Backpropagation Levenberg–Marquardt Bayesian regulation | Hyperbolic tangent sigmoid Linear | Moisture ratio Energy efficiency | [46] |
| Water mint (Mentha aquatica) | Hot air chamber dryer | Feedforward Multi-layer Perceptron | Backpropagation | - | Moisture ratio and 11 other herb quality aspects | [47] |
| Linden | Infrared dryer | Feedforward Multi-layer Perceptron | Backpropagation | Sigmoid | Moisture ratio Total phenolic content Total flavonoid content Total flavonoid assay DPPH | [48] |
| Pineapple | Hot air oven dryer Microwave dryer Microwave convective dryer Freeze dryer | Feedforward Multi-layer Perceptron | Backpropagation Levenberg–Marquardt | Sigmoid | Moisture ratio Drying time Effective moisture diffusivity Rehydration ratio Coefficient of rehydration | [49] |
| Rice | Cabinet hot air tray dryer | Feedforward Multi-layer Perceptron | Backpropagation | Logarithmic sigmoid Hyperbolic tangent sigmoid | Moisture ratio Drying rate | [50] |
| “Cẩm” brown rice | Cabinet hot air tray dryer | Feedforward Multi-layer Perceptron | Backpropagation | Logarithmic sigmoid Hyperbolic tangent sigmoid Linear | Moisture ratio Moisture content | [51] |
| Bitter gourd | Halogen dryer | Generalized Regression Neural Network | - | Radial basis Linear | Moisture content | [52] |
| Mango kernel | Convective hot air dryer | Feedforward Multi-layer Perceptron | Backpropagation | Hyperbolic tangent sigmoid Logarithm sigmoid Linear | Moisture ratio | [53] |
| Artificial Neural Network Type | ANN Architecture [Input Layer–Hidden Layers–Output Layer] | Artificial Neural Network Training Algorithm | Output | Statistical Parameters | Ref. |
|---|---|---|---|---|---|
| Feedforward Multi-layer Perceptron | 2–10–8 10–10–8 | Backpropagation | Drying temperature | Mean absolute percentage error (MAPE) Mean absolute error (MAE) Mean square error (MSE) Integral absolute error (IAE) | [36] |
| Feedforward Multi-layer Perceptron | Moisture ratio Input nodes 4 Hidden nodes 4, 5, 8 16 Output nodes 1 Area ratio Input nodes 6 Hidden nodes 4, 5, 8, 16 Output nodes 1 | Backpropagation | Moisture ratio Area ratio Shrinkage | Mean absolute error (MAE) Coefficient of determination (R2) Root mean squared error (RMSE) Reduced chi-square [χ2] | [37] |
| Feedforward Multi-layer Perceptron | Input nodes 4 Hidden nodes 2, 3, 4, 5 Output nodes 1 | Backpropagation | Moisture content | Mean square error (MSE) Root mean squared error (RMSE) Coefficient of determination (R2) | [38] |
| Feedforward Multi-layer Perceptron | Input nodes 8 Hidden nodes: 1. Hidden layer 10 2. Hidden layer 6 Output nodes 1 | Backpropagation | Drying shrinkage | Mean absolute error (MAE) Root mean squared error (RMSE) Coefficient of determination (R2) | [39] |
| Long short-term memory neural network | - | - | Drying kinetics | Coefficient of determination (R2) | [40] |
| Feedforward Multi-layer Perceptron | Input nodes 3 Hidden nodes: 2–20 Output nodes 1 | Levenberg–Marquardt | Moisture ratio Drying rate | Mean absolute error (MAE) Root mean squared error (RMSE) Coefficient of determination (R2) | [32] |
| Feedforward Multi-layer Perceptron | Input nodes 1–20 Hidden nodes: 1–20 Output nodes 1–20 | Broyden-Fletcher-Goldfarb-Shanno algorithm | Moisture content Corn kernel weight | Reduced chi-square (χ2) Root mean squared error (RMSE) Coefficient of determination (R2) Mean bias error (MBE) Mean percentage error (MPE) | [41] |
| Feedforward Multi-layer Perceptron | 2–8–7–5 | Backpropagation | Drying time Head rice yield Whiteness index Water uptake ratio Elongation ratio | Coefficient of determination (R2) Mean square error (MSE) Average absolute relative deviation percent (AARD) | [42] |
| Feedforward Multi-layer Perceptron | Input nodes 2 Hidden layers: 2 Nodes in hidden layers: 1–15 Output nodes 1–20 | Levenberg–Marquardt Backpropagation Genetic algorithm | Moisture ratio | Sum of squared errors (SSE) Root mean squared error (RMSE) Mean square error (MSE) Coefficient of determination (R2) Reduced chi-square (χ2) | [29] |
| Feedforward Multi-layer Perceptron | 2–6–2 | Levenberg–Marquardt | Moisture ratio Moisture content | Mean square error (MSE) Coefficient of determination (R2) | [43] |
| Feedforward Multi-layer Perceptron Cascade Forward Neural Network | 20–1 20–20–1 | Backpropagation Bayesian regulation Levenberg–Marquardt | Moisture ratio Energy utilization Energy utilization ratio Exergy loss Exergy efficiency | Root mean squared error (RMSE) Coefficient of determination (R2) Percentage of mean relative error (ε) | [30] |
| Feedforward Multi-layer Perceptron | 3–11–4 | Backpropagation | Drying efficiency Rehydration ratio | Mean square error (MSE) Coefficient of determination (R2) | [44] |
| Feedforward Multi-layer Perceptron | Input nodes: 3 1. Hidden layer: 100 2. Hidden layer: 100 Output nodes: 1 | Backpropagation Adaptive moment estimation (Adam) | Moisture content | Coefficient of determination (R2) Mean square error (MSE) Root mean squared error (RMSE) Residual sum of squares (RSS) Standard error (SE) | [45] |
| Feedforward Multi-layer Perceptron | 5–7–1 | Backpropagation Levenberg–Marquardt Bayesian regulation | Moisture ratio Energy efficiency | Coefficient of determination (R2) Root mean squared error (RMSE) | [46] |
| Feedforward Multi-layer Perceptron | 2–10–12 | Backpropagation | Moisture ratio and 11 other herb quality aspects | Correlation coefficient (R) Coefficient of determination (R2) Root mean squared error (RMSE) Mean average error (MAE) Standard error of prediction (SEP) Absolute average deviation (AAD) | [47] |
| Feedforward Multi-layer Perceptron | 2–7–8–5 | Backpropagation | Drying time Head rice yield Whiteness index Water uptake ratio Elongation ratio | Coefficient of determination (R2) Average absolute relative deviation (AARD) Mean square error (MSE) | [48] |
| Feedforward Multi-layer Perceptron | Input nodes: 3 Hidden layers: 3 Nodes in hidden layers: 327 Output nodes: 5 | Backpropagation | Moisture ratio Total phenolic content Total flavonoid content Total flavonoid assay DPPH | Coefficient of determination (R2) Root mean squared error (RMSE) | [49] |
| Feedforward Multi-layer Perceptron | 1–9–1 | Backpropagation Levenberg–Marquardt | Moisture ratio Drying time Effective moisture diffusivity Rehydration ratio Coefficient of rehydration | Coefficient of correlation (R2) Root mean squared error (RMSE) | [50] |
| Feedforward Multi-layer Perceptron | 3–9–2 3–5–2 | Backpropagation | Moisture ratio Drying rate | Coefficient of determination (R2) Root mean squared error (RMSE) Mean average error (MAE) | [51] |
| Feedforward Multi-layer Perceptron | 2–10–1 | Backpropagation | Moisture ratio Moisture content | Coefficient of determination (R2) Mean square error (MSE) | [52] |
| Generalized Regression Neural Network | 1 input layer 2 hidden layers 1 output layer | - | Moisture content | Coefficient of determination (R2) Root mean squared error (RMSE) Mean relative percent error (P) | [53] |
| Type of Neural Network | Training Algorithm | Wet Material | ANN Architecture for the Best Performance | Output Value | Values of Statistical Parameters | Ref. | |
|---|---|---|---|---|---|---|---|
| R2 | RMSE | ||||||
| Feedforward Neural Network | Backpropagation | Potato slices | 4–4–1 | MR | 0.996 | 0.015 | [37] |
| MC | - | - | |||||
| DR | - | - | |||||
| Pepper | 4–4–1 | MR | - | - | [38] | ||
| MC | 0.996 | - | |||||
| DR | - | - | |||||
| Pineapple cubes | 3–14–14–1 3–14–14–1 | MR | 0.9999 | 0.0008 | [32] | ||
| MC | - | - | |||||
| DR | 0.9985 | 0.0005 | |||||
| Watermelon rind pomace | 2–15–15–1 | MR | 0.9996 | - | [29] | ||
| MC | - | - | |||||
| DR | - | - | |||||
| Moringa olifera leaves | 2–6–2 2–6–2 | MR | 0.998 | - | [43] | ||
| MC | 0.992 | - | |||||
| DR | - | - | |||||
| Onion | 4–6–6–1 | MR | 0.9995 | 0.0019 | [30] | ||
| MC | - | - | |||||
| DR | - | - | |||||
| Quince | 3–90–90–1 | MR | - | - | [45] | ||
| MC | 0.99 | <0.08 | |||||
| DR | - | - | |||||
| Water mint (Mentha aquatica) | 2–10–12 - - | MR | 0.966393 | 0.041556 | [47] | ||
| MC | - | - | |||||
| DR | - | - | |||||
| Pineapple | 1–9–1 - - | MR | 0.99936 | 0.006 | [49] | ||
| MC | - | - | |||||
| DR | - | - | |||||
| Rice | 3–5–2 - 3–9–2 | MR | 0.9976 | 0.0360 | [50] | ||
| MC | - | - | |||||
| DR | 0.9696 | 0.0916 | |||||
| “Cẩm” brown rice | 2–10–1 | MR | 0.99743 | - | [51] | ||
| MC | - | - | |||||
| DR | - | - | |||||
| Mango kernel | 3–10–1 | MR | 0.9988 | 0.0104 | [52] | ||
| Reference | Scientific Novelty | Directions for Future Research |
|---|---|---|
| [36] | Developing and implement a neural network predictive control (NNPC) system for the drying and curing process in automotive paint, for temperature prediction, and control of specific BIW (Body-in-White) parts. | Research on further optimization of models, such as fine-tuning the parameters of the ant colony optimization (ACO) method. |
| [37] | This research focuses on studying the drying behavior of drying material (potato slices) in different drying tray layers combined with drying characteristics of material arranged in different positions in each drying tray under different drying conditions. Previous works only presented the influence of different drying tray layers on the behavior and/or characteristics of the drying material. | |
| [38] | Previous studies demonstrated that high turbulence/swirl of hot air injected into fluidized bed dryers resulted in enhanced drying rates. In the present work, a fluidized bed dryer with conical air distributors consisting of a solid bottom cone and a perforated cone on top of a perforated sheet was applied for drying enhancement. Perforated cones with various heights relating to the angles of airflow were comparatively tested to determine optimal geometries. It was proposed that they provide good contact between hot air and peppercorns. Additionally, a solid cone having a height of two-thirds of the column diameter was installed at the bottom of the column. The solid cone was designed as the first air distributor and the perforated cone functioned as a second air distributor. It was expected that the dual distributors would give better air distribution. | |
| [39] | Advancement in understanding of the drying shrinkage behaviors of AAMs (alkali-activated materials) and providing practical guidelines for designing AAM mixtures with high durability. It is firmly believed that this research could provide guidance on the scientific and sustainable mix design and widen the commercial application of AAMs. | |
| [40] | The existing methods comprise physics-based models (e.g., CDRC, reaction engineering approach (REA), diffusion and receding interface-based models) and machine learning models (e.g., regression models and artificial neural networks such as multi-layer perceptron and recurrent neural networks). The current approach is a special kind of recurrent neural network, called long short-term memory (LSTM). One key attribute of this initiative is that the method does not always rely on measured material drying kinetics data to provide predictions. That is, reliable and/or “finger-tip” forecasting of materials’ drying curves of any milk composition or material of interest is still possible even when the actual drying kinetics data are not known. | Research on new deep learning models which would be able to investigate the actual attributes of material mixing such as color, texture, and taste |
| [32] | In previous studies, there were no reports on the use of ANNs and the MLR model to estimate the effect of edible coating on the drying process. Thus, the goal of the current work was to evaluate the effect of temperatures and edible coating on the process of drying pineapple cubes. | The suggested future work is to study the effect of sample size and number of coating layers in the model. |
| [41] | Applying the multi-objective optimization analysis coupled with an ANN and genetic algorithm (GA) to the drying process, knowing that there could not be a single solution due to the conflicting objective functions. On the basis of the developed ANN model, multi-objective optimization was performed, showing the possible practical use in the corn kernel drying process. | |
| [42] | Ample research has been carried out on fluidized bed drying techniques and its potential use, but the effects of some major operation parameters on the quality of rough rice such as fluidized bed temperature in different fluidization regimes have not been investigated. The aim of this research is to enhance knowledge about rice drying in a fluidized bed tubular chamber in fluidization regimes and different temperatures with and without ventilation. | |
| [29] | The main objective of this work was to develop a data-based artificial neural network (ANN) model for the watermelon pomace drying process and compare it with several semi-theoretical and empirical models of the same process to determine (i) if there is any improvement in its error performance; and (ii) if its simulation capabilities are acceptable because, additionally, an expanded drying process model could be developed with an ANN to include, for instance, the influence of the superficial air velocity and sample size in the drying kinetics. | |
| [43] | The authors of this study did not identify any reported literature on the study of vacuum drying behavior for moringa leaves that encompasses intelligent process modeling, estimation of mass transfer parameters, and drying energy calculations. In view of this limitation, the objectives of this work were (1) to develop a predictive model for the drying behavior of vacuum-dried moringa leaves using an ANN and compare it with semi-empirical models of drying; and (2) determine mass transfer parameters, effective moisture diffusivity, activation energy, and total energy consumption of the drying process. | The authors of this study highly recommends further analysis of the changes in chemical composition of moringa leaves with drying temperature. |
| [30] | To the best of the authors’ knowledge, a detailed analysis of the drying characteristics, and energy and exergy analyses of onion slices by means of designing and developing a multi-stage semi-industrial continuous belt (MSSICB) dryer as a novel hot air-convective drying method, are still missing in the literature, especially using artificial neural networks (ANNs) and ANFIS models. The main objectives of the this work are (1) drying of onion slices using a MSSICB dryer at different air temperatures and velocities, belt linear speeds, and representation of a proper mathematical model to fit the moisture ratio curve; (2) investigating the effective moisture diffusivity coefficient, activation energy, specific energy consumption, color change, and drying ratio of onions under different conditions; (3) assessing the energy utilization, energy utilization ratio, exergy loss, and efficiency parameters of the drying process using the first and second laws of thermodynamics; and (4) predicting indexes of moisture ratio, energy utilization, energy utilization ratio, exergy loss, and efficiency via ANNs and ANFIS models. | Research of possibilities in drying chamber insulation and selection of adequate components of a multi-stage semi-industrial continuous dryer. Optimizing drying conditions using the response surface method should be considered in future research. |
| [44] | Implementation of ANN models to establish the relationship between process parameters and product conditions during microwave drying in order to analyze the effect of citric acid pre-treatment, microwave power, and vacuum level on the physicochemical characteristics of micro vacuum-dried dragon fruit slices. A minimal quantity of data about this topic is available in the literature. | |
| [45] | This study focuses on quince-based products since limited studies on quince convection drying can be found in the literature, and no information is available on quince modeling evaluation using an ANN. The methodology of modeling presented in the present study addresses the previous issues, involving the development of artificial networks that introduce in detail a modified cross-validation technique. | To achieve a better predictive ability of ANN models, future research should consider the dimensions of slices such as the thickness and the slice diameter that could be included as model inputs. |
| [46] | Evaluating the performance of artificial neural networks to simultaneously predict drying kinetics in fixed, fluidized, and vibro-fluidized bed dryers under different operating conditions. | Optimizing the drying process towards reduction of energy consumption with a more efficient database of different combinations of amplitude and frequency of vibration. |
| [47] | Exploring the possibility of determining key herb quality aspects (color, moisture content, essential oil content, and composition) using ANNs with drying process factors such as temperature and drying time. Exploring the capabilities of the proposed ANN model for non-invasive in situ evaluations of a series of critical herb quality features. | |
| [48] | Suggesting an ANN method that may be used to make accurate predictions of the drying kinetics of linden leaf samples subjected to an infrared drying process. | Further research is necessary to determine the capacity of ANNs to accurately forecast the changes that occur in the nutritional profile of fruits and vegetables as a result of drying. |
| [49] | The aim of the study is to observe the effect of the hot-air oven, microwave, microwave-convection, and freeze drying on the dehydration behavior of sliced pineapple, to develop a drying kinetics model applying the ANN methodology, the effective moisture diffusivity, and the rehydration characteristics of the dried product. | Exploration of the possibility of using a neuro-fuzzy system as an alternative approach for building dehydration kinetics models. |
| [50] | Investigation of cabinet tray drying kinetics for a paddy and demonstration of ANN modeling of drying kinetics. | |
| [51] | In this work, drying kinetics of instant “Cẩm” brown rice was investigated, and robust static and dynamic ANN models for predicting the moisture content were developed and compared. | |
| [52] | Drying kinetics analysis of the bitter gourd slices drying process, using a generalized regression neural network (GRNN) model. | |
| [53] | Authors stated that none of the previous researchers examined the use of an artificial neural network to predict the moisture ratio with drying time for mango kernels. | According to authors of this study, the future scope of research of this topic lies in evaluating the physico-chemical properties of the dried mango kernels, which will strengthen the current research. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Đaković, D.; Kljajić, M.; Milivojević, N.; Doder, Đ.; Anđelković, A.S. Review of Energy-Related Machine Learning Applications in Drying Processes. Energies 2024, 17, 224. https://doi.org/10.3390/en17010224
Đaković D, Kljajić M, Milivojević N, Doder Đ, Anđelković AS. Review of Energy-Related Machine Learning Applications in Drying Processes. Energies. 2024; 17(1):224. https://doi.org/10.3390/en17010224
Chicago/Turabian StyleĐaković, Damir, Miroslav Kljajić, Nikola Milivojević, Đorđije Doder, and Aleksandar S. Anđelković. 2024. "Review of Energy-Related Machine Learning Applications in Drying Processes" Energies 17, no. 1: 224. https://doi.org/10.3390/en17010224
APA StyleĐaković, D., Kljajić, M., Milivojević, N., Doder, Đ., & Anđelković, A. S. (2024). Review of Energy-Related Machine Learning Applications in Drying Processes. Energies, 17(1), 224. https://doi.org/10.3390/en17010224