
Optimizing Mixed-Model Synchronous Assembly Lines with Bipartite Sequence-Dependent Setup Times in Advanced Manufacturing


Abstract
:1. Introduction
2. Simulation
2.1. Problem Description and Notations
2.2. Mathematical Formulation
2.2.1. Sequencing Models
2.2.2. Demand Satisfaction for Minimal Part-Set
2.2.3. Maintaining the Sequence of Products
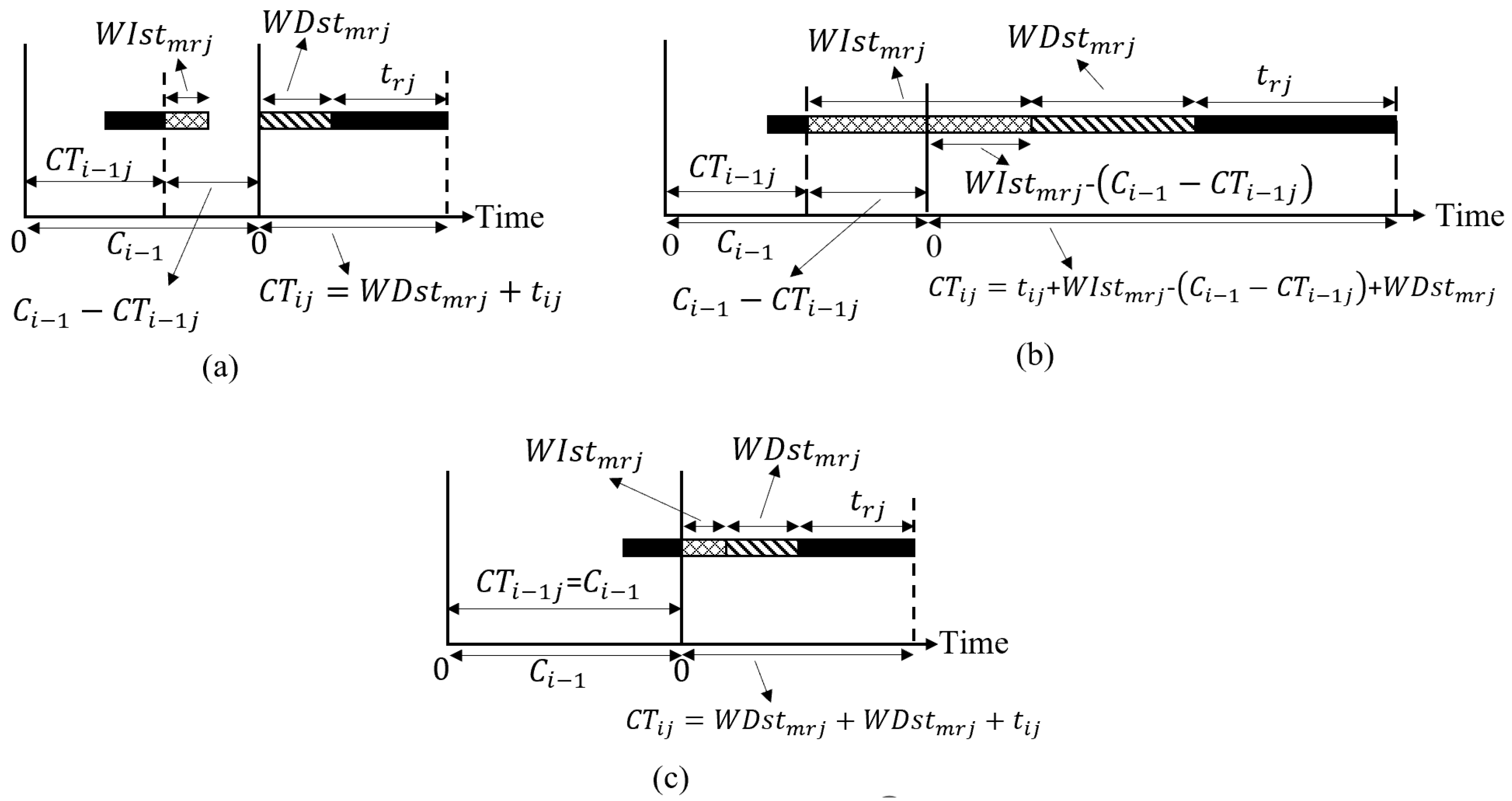
2.2.4. Completion Time
2.2.5. The Interval between Consecutive Movements of the Conveyor Belt
3. Proposed Algorithm and Mathematical Result
3.1. Basic Genetic Algorithm Structure
- (1)
- Generate the initial population by creating random numbers (chromosomes).
- (2)
- Determine the fitness value for each chromosome.
- (3)
- Continue the process until a termination condition is reached:
- a.
- Select parents from the population.
- b.
- Apply crossover to the selected parents.
- c.
- Perform mutations on the chromosomes.
- d.
- Calculate the fitness value for each new chromosome.
- e.
- Select the offspring to form the next generation.
3.2. Proposed Genetic Algorithm
3.2.1. Initial Population
3.2.2. Selection
3.2.3. Crossover
3.2.4. Inversion
3.2.5. Mutation
3.3. Numerical Experiment and Discussion
- (1)
- The setup times () were generated from a uniform distribution of U(4,9), and the setup times () from U(2,4), respectively.
- (2)
- The parameters for GA, including (population size), (the power-law scaling), (crossover probability), (inversion probability), (mutation probability), and (maximum number of algorithm iterations) were set as 40, 1.005, 0.7, 0.5, 0.1, and 1000, respectively. Parameter setting can follow either offline or online strategies. With offline parameter initialization, the values are set before the meta-heuristic’s execution. However, the online strategy allows parameters to be dynamically or adaptively adjusted during the run. This study utilized the offline method, determining the optimal parameters by solving two test problems—one small-sized and one large-sized—using a set of different parameters. The best-performing parameters were then selected for the proposed GA.
- (3)
- Each test problem was subjected to ten GA runs.
- Consistency of solutions: The GA was run multiple times (ten runs) for each problem instance. The low coefficient of variation values indicate that the GA consistently produced similar high-quality solutions across different runs, demonstrating its reliability.
- Performance metrics: The comparison included the objective function values, computational times, and the convergence characteristics of the GA. The proposed GA showed faster convergence and required less computational time, which is crucial for practical applications.
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Renna, P.; Materi, S. A literature review of energy efficiency and sustainability in manufacturing systems. Appl. Sci. 2021, 11, 7366. [Google Scholar] [CrossRef]
- Gielen, D.; Gorini, R.; Wagner, N.; Leme, R.; Gutierrez, L.; Prakash, G.; Asmelash, E.; Janeiro, L.; Gallina, G.; Vale, G.; et al. Global Energy Transformation: A Roadmap to 2050; International Renewable Energy Agency: Masdar City, United Arab Emirates, 2019. [Google Scholar]
- Zheng, Y.; Shan, R.; Xu, W.; Qiu, Y. Effectiveness of carbon dioxide emission target is linked to country ambition and education level. Commun. Earth Environ. 2024, 5, 209. [Google Scholar] [CrossRef]
- Spence, A.; Leygue, C.; Bedwell, B.; O’Malley, C. Engaging with energy reduction: Does a climate change frame have the potential for achieving broader sustainable behaviour? J. Environ. Psychol. 2014, 38, 17–28. [Google Scholar] [CrossRef]
- Akerman, P.; Cazzola, P.; Christiansen, E.S.; Van Heusden, R.; Kolomanska-van Iperen, J.; Christensen, J.; Crone, K.; Dawe, K.; De Smedt, G.; Keynes, A. Reaching Zero with Renewables; International Renewable Energy Agency: Masdar City, United Arab Emirates, 2020. [Google Scholar]
- Paprocka, I.; Krenczyk, D. On Energy Consumption and Productivity in a Mixed-Model Assembly Line Sequencing Problem. Energies 2023, 16, 7091. [Google Scholar] [CrossRef]
- Gupta, M.K.; Korkmaz, M.E.; Yılmaz, H.; Şirin, Ş.; Ross, N.S.; Jamil, M.; Królczyk, G.M.; Sharma, V.S. Real-time monitoring and measurement of energy characteristics in sustainable machining of titanium alloys. Measurement 2024, 224, 113937. [Google Scholar] [CrossRef]
- Baldwin, R.; Freeman, R. Risks and global supply chains: What we know and what we need to know. Annu. Rev. Econ. 2022, 14, 153–180. [Google Scholar] [CrossRef]
- Sun, L.; Yuan, G.; Gao, L.; Yang, J.; Chhowalla, M.; Gharahcheshmeh, M.H.; Gleason, K.K.; Choi, Y.S.; Hong, B.H.; Liu, Z. Chemical vapour deposition. Nat. Rev. Methods Prim. 2021, 1, 5. [Google Scholar] [CrossRef]
- Heydari Gharahcheshmeh, M.; Gleason, K.K. Device fabrication based on oxidative chemical vapor deposition (oCVD) synthesis of conducting polymers and related conjugated organic materials. Adv. Mater. Interfaces 2019, 6, 1801564. [Google Scholar] [CrossRef]
- Chowdhury, K.; Behura, S.K.; Rahimi, M.; Heydari Gharahcheshmeh, M. oCVD PEDOT-Cl Thin Film Fabricated by SbCl5 Oxidant as the Hole Transport Layer to Enhance the Perovskite Solar Cell Device Stability. ACS Appl. Energy Mater. 2024, 7, 1068–1079. [Google Scholar] [CrossRef]
- Sun, Y.; Rogers, J.A. Inorganic semiconductors for flexible electronics. Adv. Mater. 2007, 19, 1897–1916. [Google Scholar] [CrossRef]
- Heydari Gharahcheshmeh, M.; Tavakoli, M.M.; Gleason, E.F.; Robinson, M.T.; Kong, J.; Gleason, K.K. Tuning, optimization, and perovskite solar cell device integration of ultrathin poly (3,4-ethylene dioxythiophene) films via a single-step all-dry process. Sci. Adv. 2019, 5, eaay0414. [Google Scholar] [CrossRef] [PubMed]
- Heydari Gharahcheshmeh, M.; Gleason, K.K. Recent Progress in Conjugated Conducting and Semiconducting Polymers for Energy Devices. Energies 2022, 15, 3661. [Google Scholar] [CrossRef]
- Gharahcheshmeh, M.H.; Gleason, K.K. Conjugated polymers for flexible energy harvesting and storage devices. In Conjugated Polymers for Next-Generation Applications; Elsevier: Amsterdam, The Netherlands, 2022; pp. 283–311. [Google Scholar]
- Gleason, K.K.; Gharahcheshmeh, M.H. Conjugated Polymers at Nanoscale: Engineering Orientation, Nanostructure, and Properties; Walter de Gruyter GmbH & Co KG: Berlin, Germany, 2021. [Google Scholar]
- Tavakoli, M.M.; Gharahcheshmeh, M.H.; Moody, N.; Bawendi, M.G.; Gleason, K.K.; Kong, J. Efficient, Flexible, and Ultra-Lightweight Inverted PbS Quantum Dots Solar Cells on All-CVD-Growth of Parylene/Graphene/oCVD PEDOT Substrate with High Power-per-Weight. Adv. Mater. Interfaces 2020, 7, 2000498. [Google Scholar] [CrossRef]
- Heydari Gharahcheshmeh, M.; Chowdhury, K. Enhancing Capacitance of Carbon Cloth Electrodes via Highly Conformal PEDOT Coating Fabricated by the OCVD Method Utilizing SbCl5 Oxidant. Adv. Mater. Interfaces 2024, 2400118. [Google Scholar] [CrossRef]
- Heydari Gharahcheshmeh, M.; Robinson, M.T.; Gleason, E.F.; Gleason, K.K. Optimizing the optoelectronic properties of face-on oriented poly (3,4-ethylenedioxythiophene) via water-assisted oxidative chemical vapor deposition. Adv. Funct. Mater. 2021, 31, 2008712. [Google Scholar] [CrossRef]
- Pilati, F.; Lelli, G.; Regattieri, A.; Ferrari, E. Assembly line balancing and activity scheduling for customised products manufacturing. Int. J. Adv. Manuf. Technol. 2022, 120, 3925–3946. [Google Scholar] [CrossRef]
- Akpinar, S.; Bayhan, G.M. Performance evaluation of ant colony optimization-based solution strategies on the mixed-model assembly line balancing problem. Eng. Optim. 2014, 46, 842–862. [Google Scholar] [CrossRef]
- Bortolini, M.; Ferrari, E.; Gamberi, M.; Pilati, F.; Faccio, M. Assembly system design in the Industry 4.0 era: A general framework. Ifac-Papersonline 2017, 50, 5700–5705. [Google Scholar] [CrossRef]
- Kim, S.H.; Lee, Y.H. Synchronized production planning and scheduling in semiconductor fabrication. Comput. Ind. Eng. 2016, 96, 72–85. [Google Scholar] [CrossRef]
- Liu, Q.; Wang, W.-x.; Zhu, K.-r.; Zhang, C.-y.; Rao, Y.-q. Advanced scatter search approach and its application in a sequencing problem of mixed-model assembly lines in a case company. Eng. Optim. 2014, 46, 1485–1500. [Google Scholar] [CrossRef]
- Buzacott, J.A.; Shanthikumar, J.G. Stochastic Models of Manufacturing Systems; Prentice Hall: Upper Saddle River, NJ, USA, 1993. [Google Scholar]
- Lin, L.; Drury, C.; Kim, S.W. Ergonomics and quality in paced assembly lines. Hum. Factors Ergon. Manuf. Serv. Ind. 2001, 11, 377–382. [Google Scholar] [CrossRef]
- Chiang, W.-C.; Urban, T.L.; Xu, X. A bi-objective metaheuristic approach to unpaced synchronous production line-balancing problems. Int. J. Prod. Res. 2012, 50, 293–306. [Google Scholar] [CrossRef]
- Bard, J.F.; Dar-Elj, E.; Shtub, A. An analytic framework for sequencing mixed model assembly lines. Int. J. Prod. Res. 1992, 30, 35–48. [Google Scholar] [CrossRef]
- Rauf, M.; Guan, Z.; Sarfraz, S.; Mumtaz, J.; Shehab, E.; Jahanzaib, M.; Hanif, M. A smart algorithm for multi-criteria optimization of model sequencing problem in assembly lines. Robot. Comput.-Integr. Manuf. 2020, 61, 101844. [Google Scholar] [CrossRef]
- Mosadegh, H.; Ghomi, S.F.; Süer, G.A. Stochastic mixed-model assembly line sequencing problem: Mathematical modeling and Q-learning based simulated annealing hyper-heuristics. Eur. J. Oper. Res. 2020, 282, 530–544. [Google Scholar] [CrossRef]
- Emde, S.; Polten, L. Sequencing assembly lines to facilitate synchronized just-in-time part supply. J. Sched. 2019, 22, 607–621. [Google Scholar] [CrossRef]
- Aroui, K.; Alpan, G.; Frein, Y. Minimising work overload in mixed-model assembly lines with different types of operators: A case study from the truck industry. Int. J. Prod. Res. 2017, 55, 6305–6326. [Google Scholar] [CrossRef]
- Mosadegh, H.; Fatemi Ghomi, S.; Süer, G.A. Heuristic approaches for mixed-model sequencing problem with stochastic processing times. Int. J. Prod. Res. 2017, 55, 2857–2880. [Google Scholar] [CrossRef]
- Fattahi, P.; Beitollahi Tavakoli, N.; Fathollah, M.; Roshani, A.; Salehi, M. Sequencing mixed-model assembly lines by considering feeding lines. Int. J. Adv. Manuf. Technol. 2012, 61, 677–690. [Google Scholar] [CrossRef]
- Fattahi, P.; Salehi, M. Sequencing the mixed-model assembly line to minimize the total utility and idle costs with variable launching interval. Int. J. Adv. Manuf. Technol. 2009, 45, 987–998. [Google Scholar] [CrossRef]
- Kim, S.; Jeong, B. Product sequencing problem in Mixed-Model Assembly Line to minimize unfinished works. Comput. Ind. Eng. 2007, 53, 206–214. [Google Scholar] [CrossRef]
- Sarker, B.R.; Pan, H. Designing a mixed-model assembly line to minimize the costs of idle and utility times. Comput. Ind. Eng. 1998, 34, 609–628. [Google Scholar] [CrossRef]
- Bolat, A. Stochastic procedures for scheduling minimum job sets on mixed model assembly lines. J. Oper. Res. Soc. 1997, 48, 490–501. [Google Scholar] [CrossRef]
- Xiaobo, Z.; Ohno, K. Algorithms for sequencing mixed models on an assembly line in a JIT production system. Comput. Ind. Eng. 1997, 32, 47–56. [Google Scholar] [CrossRef]
- Xiaobo, Z.; Ohno, K. A sequencing problem for a mixed-model assembly line in a JIT production system. Comput. Ind. Eng. 1994, 27, 71–74. [Google Scholar] [CrossRef]
- Yano, C.A.; Rachamadugu, R. Sequencing to minimize work overload in assembly lines with product options. Manag. Sci. 1991, 37, 572–586. [Google Scholar] [CrossRef]
- Bard, J.; Shtub, A.; Joshi, S.B. Sequencing mixed-model assembly lines to level parts usage and minimize line length. Int. J. Prod. Res. 1994, 32, 2431–2454. [Google Scholar] [CrossRef]
- Rahimi-Vahed, A.R.; Rabbani, M.; Tavakkoli-Moghaddam, R.; Torabi, S.A.; Jolai, F. A multi-objective scatter search for a mixed-model assembly line sequencing problem. Adv. Eng. Inform. 2007, 21, 85–99. [Google Scholar] [CrossRef]
- Rahimi-Vahed, A.; Mirzaei, A.H. A hybrid multi-objective shuffled frog-leaping algorithm for a mixed-model assembly line sequencing problem. Comput. Ind. Eng. 2007, 53, 642–666. [Google Scholar] [CrossRef]
- Tavakkoli-Moghaddam, R.; Rahimi-Vahed, A. Multi-criteria sequencing problem for a mixed-model assembly line in a JIT production system. Appl. Math. Comput. 2006, 181, 1471–1481. [Google Scholar] [CrossRef]
- Giard, V.; Jeunet, J. Optimal sequencing of mixed models with sequence-dependent setups and utility workers on an assembly line. Int. J. Prod. Econ. 2010, 123, 290–300. [Google Scholar] [CrossRef]
- Chutima, P.; Naruemitwong, W. A Pareto biogeography-based optimisation for multi-objective two-sided assembly line sequencing problems with a learning effect. Comput. Ind. Eng. 2014, 69, 89–104. [Google Scholar] [CrossRef]
- Varyani, A.; Jalilvand-Nejad, A.; Fattahi, P. Determining the optimum production quantity in three-echelon production system with stochastic demand. Int. J. Adv. Manuf. Technol. 2014, 72, 119–133. [Google Scholar] [CrossRef]
- Kouvelis, P.; Karabati, S. Cyclic scheduling in synchronous production lines. IIE Trans. 1999, 31, 709–719. [Google Scholar] [CrossRef]
- Salehi, M.; Fattahi, P.; Roshani, A.; Zahiri, J. Multi-criteria sequencing problem in mixed-model synchronous assembly lines. Int. J. Adv. Manuf. Technol. 2013, 67, 983–993. [Google Scholar] [CrossRef]
- Karabati, S.; Tan, B. Stochastic cyclic scheduling problem in synchronous assembly and production lines. J. Oper. Res. Soc. 1998, 49, 1173–1187. [Google Scholar] [CrossRef]
- Oliveira, C.; Lima, T.M. Setup Time Reduction of an Automotive Parts Assembly Line Using Lean Tools and Quality Tools. Eng 2023, 4, 2352–2362. [Google Scholar] [CrossRef]
- Lopes, T.C.; Michels, A.S.; Brauner, N.; Magatão, L. Balancing-sequencing paced assembly lines: A multi-objective mixed-integer linear case study. Int. J. Prod. Res. 2023, 61, 5901–5917. [Google Scholar] [CrossRef]
- McMullen, P.R.; Tarasewich, P. A beam search heuristic method for mixed-model scheduling with setups. Int. J. Prod. Econ. 2005, 96, 273–283. [Google Scholar] [CrossRef]
- Özcan, U. Balancing and scheduling tasks in parallel assembly lines with sequence-dependent setup times. Int. J. Prod. Econ. 2019, 213, 81–96. [Google Scholar] [CrossRef]
- Yang, W.; Cheng, W. Modelling and solving mixed-model two-sided assembly line balancing problem with sequence-dependent setup time. Int. J. Prod. Res. 2020, 58, 6638–6659. [Google Scholar] [CrossRef]
- Chang, P.-C.; Hsieh, J.-C.; Wang, Y.-W. Genetic algorithms applied in BOPP film scheduling problems: Minimizing total absolute deviation and setup times. Appl. Soft Comput. 2003, 3, 139–148. [Google Scholar] [CrossRef]
- Kim, D.-W.; Kim, K.-H.; Jang, W.; Chen, F.F. Unrelated parallel machine scheduling with setup times using simulated annealing. Robot. Comput.-Integr. Manuf. 2002, 18, 223–231. [Google Scholar] [CrossRef]
- Schaller, J.E.; Gupta, J.N.; Vakharia, A.J. Scheduling a flowline manufacturing cell with sequence dependent family setup times. Eur. J. Oper. Res. 2000, 125, 324–339. [Google Scholar] [CrossRef]
- Laguna, M. A heuristic for production scheduling and inventory control in the presence of sequence-dependent setup times. IIE Trans. 1999, 31, 125–134. [Google Scholar] [CrossRef]
- Allahverdi, A.; Soroush, H. The significance of reducing changeover times/changeover costs. Eur. J. Oper. Res. 2008, 187, 978–984. [Google Scholar] [CrossRef]
- Akgündüz, O.S.; Tunalı, S. A review of the current applications of genetic algorithms in mixed-model assembly line sequencing. Int. J. Prod. Res. 2011, 49, 4483–4503. [Google Scholar] [CrossRef]
- Aslan, Ş. Mathematical model and a variable neighborhood search algorithm for mixed-model robotic two-sided assembly line balancing problems with sequence-dependent setup times. Optim. Eng. 2023, 24, 989–1016. [Google Scholar] [CrossRef]
- McMullen, P.R. JIT sequencing for mixed-model assembly lines with setups using tabu search. Prod. Plan. Control 1998, 9, 504–510. [Google Scholar] [CrossRef]
- Drexl, A.; Kimms, A. Sequencing JIT mixed-model assembly lines under station-load and part-usage constraints. Manag. Sci. 2001, 47, 480–491. [Google Scholar] [CrossRef]
- Boysen, N.; Fliedner, M.; Scholl, A. Sequencing mixed-model assembly lines to minimize part inventory cost. Or Spectr. 2008, 30, 611–633. [Google Scholar] [CrossRef]
- Defersha, F.M.; Mohebalizadehgashti, F. Simultaneous balancing, sequencing, and workstation planning for a mixed model manual assembly line using hybrid genetic algorithm. Comput. Ind. Eng. 2018, 119, 370–387. [Google Scholar] [CrossRef]
- Zhang, B.; Xu, L.; Zhang, J. A multi-objective cellular genetic algorithm for energy-oriented balancing and sequencing problem of mixed-model assembly line. J. Clean. Prod. 2020, 244, 118845. [Google Scholar] [CrossRef]
- Huang, Y.D.; Bian, R.H.; Xu, Z. Sequencing mixed model assembly lines based on genetic algorithm optimization. Adv. Mater. Res. 2011, 279, 412–417. [Google Scholar] [CrossRef]
- Monden, Y. Toyota Production System. An Integrated Apprpach to Just-In-Time; Springer: Berlin/Heidelberg, Germany, 1983. [Google Scholar]
- Wang, B.G. Sequencing mixed-model assembly lines to minimize the variation of parts consumption by hybrid genetic algorithms. Adv. Mater. Res. 2012, 566, 253–256. [Google Scholar] [CrossRef]
- uz Zaman, U.K.; Baqai, A.A. Mixed Model Assembly Line Sequencing by Minimizing Utility Work and Using Genetic Algorithm. In Proceedings of the ASME International Mechanical Engineering Congress and Exposition, Montreal, QC, Canada, 14–20 November 2014; p. V011T014A030. [Google Scholar]
- Özcan, U.; Kellegöz, T.; Toklu, B. A genetic algorithm for the stochastic mixed-model U-line balancing and sequencing problem. Int. J. Prod. Res. 2011, 49, 1605–1626. [Google Scholar] [CrossRef]
- Moradi, H.; Zandieh, M.; Mahdavi, I. Non-dominated ranked genetic algorithm for a multi-objective mixed-model assembly line sequencing problem. Int. J. Prod. Res. 2011, 49, 3479–3499. [Google Scholar] [CrossRef]
- Erel, E.; Gocgun, Y.; Sabuncuoğlu, İ. Mixed-model assembly line sequencing using beam search. Int. J. Prod. Res. 2007, 45, 5265–5284. [Google Scholar] [CrossRef]
- Alpay, Ş. GRASP with path relinking for a multiple objective sequencing problem for a mixed-model assembly line. Int. J. Prod. Res. 2009, 47, 6001–6017. [Google Scholar] [CrossRef]
- Ponnambalam, S.; Aravindan, P.; Rao, M.S. Genetic algorithms for sequencing problems in mixed model assembly lines. Comput. Ind. Eng. 2003, 45, 669–690. [Google Scholar] [CrossRef]
- Gillies, A.M. Machine Learning Procedures for Generating Image Domain Feature Detectors; University of Michigan: Ann Arbor, MI, USA, 1985. [Google Scholar]
- Michalewicz, Z. GAs: Why Do They Work? In Genetic Algorithms + Data Structures = Evolution Programs; Springer: Berlin/Heidelberg, Germany, 1996; pp. 45–55. [Google Scholar]
- Mansouri, S.A. A multi-objective genetic algorithm for mixed-model sequencing on JIT assembly lines. Eur. J. Oper. Res. 2005, 167, 696–716. [Google Scholar] [CrossRef]
- Fattahi, P.; Jolai, F.; Arkat, J. Flexible job shop scheduling with overlapping in operations. Appl. Math. Model. 2009, 33, 3076–3087. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. of Products | Station #1 | Station #2 | … | Station #K | Launch Interval (Ci) |
|---|---|---|---|---|---|
| 1 | … | ||||
| 2 | … | ||||
| … | … | … | … | … | … |
| I | … |
| Indices | |
| Input parameters | |
| The time required to perform the workpiece-independent part of the setup | |
| The time required to perform the workpiece-dependent part of the setup | |
| Decision variables | |
| , respectively, 0 otherwise | |
| Problem Information | Result of Lingo Software Using B&B | Result of the Proposed GA | (%) | |||||
|---|---|---|---|---|---|---|---|---|
| Problem No. | (M, K, I) | WIst = %ST | OFV | CPU Time1 (s) | CPU Time2 (s) | |||
| SSP1 | 3, 3, 12 | 70 | 100.6 | 58 | 100.6 | 6 | 0 | 0 |
| SSP2 | 3, 5, 10 | 30 | 79.5 | 87 | 79.5 | 7 | 0 | 0 |
| SSP3 | 3, 5, 15 | 30 | 114.3 | 581 | 114.3 | 11 | 0 | 0 |
| SSP4 | 3, 5, 15 | 70 | 140.9 | 235 | 140.9 | 12 | 0 | 0 |
| SSP5 | 3, 6, 10 | 40 | 84 | 82 | 84 | 9 | 0 | 0 |
| SSP6 | 3, 6, 13 | 40 | 103.6 | 281 | 103.6 | 12 | 0 | 0 |
| SSP7 | 3, 6, 14 | 40 | 137 | 617 | 137 | 13 | 0 | 0 |
| SSP8 | 3, 10, 10 | 40 | 95.2 | 539 | 95.2 | 14 | 0 | 0 |
| SSP9 | 3, 10, 15 | 60 | 141.8 | 1165 | 141.8 | 22 | 0 | 0 |
| SSP10 | 4, 3, 12 | 50 | 112.5 | 123 | 112.5 | 6 | 0 | 0 |
| SSP11 | 4, 3, 15 | 50 | 121.5 | 395 | 121.5 | 8 | 0 | 0 |
| SSP12 | 4, 4, 10 | 50 | 99 | 61 | 99 | 6 | 0 | 0 |
| SSP13 | 4, 4, 12 | 30 | 105.6 | 171 | 105.6 | 7 | 0 | 0 |
| SSP14 | 4, 5, 10 | 40 | 90.6 | 441 | 90.6 | 7 | 0 | 0 |
| SSP15 | 5, 5, 10 | 60 | 93 | 93 | 93 | 8 | 0 | 0 |
| Problem Information | Result of Lingo Software Using B&B | Result of the Proposed GA | (%) | |||||
|---|---|---|---|---|---|---|---|---|
| Problem No. | (M, K, I) | WIst = %ST | Best Obj (after 3600 s) | (%) | CPU Time (s) | |||
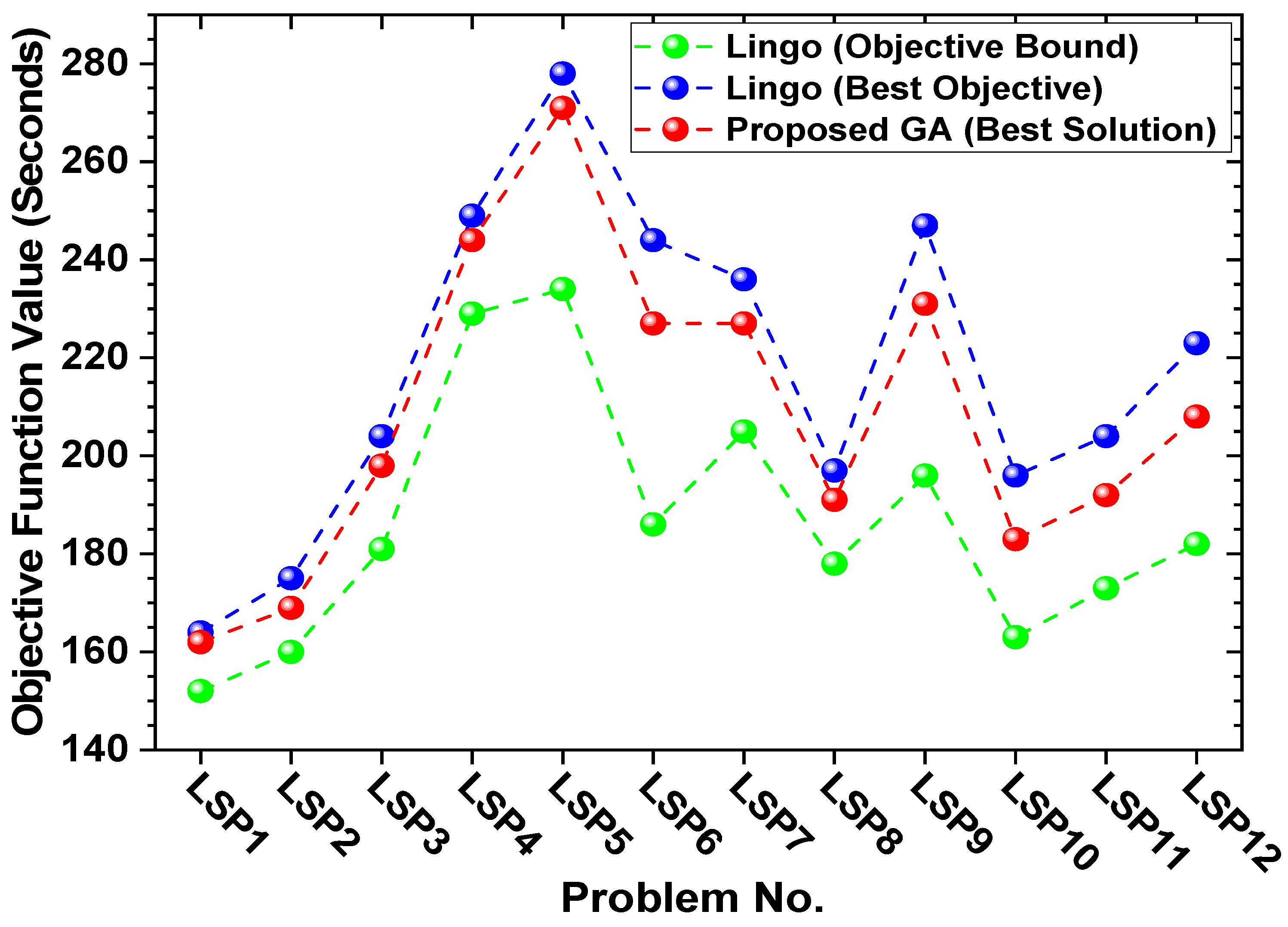
| LSP1 | 5, 10, 17 | 40 | 167.2 | 8.07 | 162.1 | 22 | 0.00002 | 3.05 |
| LSP2 | 5, 10, 18 | 60 | 175.4 | 8.04 | 169.5 | 23 | 0.00004 | 3.36 |
| LSP3 | 5, 10, 20 | 40 | 205.4 | 11.54 | 193.8 | 26 | 0.00004 | 5.65 |
| LSP4 | 5, 10, 25 | 50 | 250 | 8.04 | 241.9 | 32 | 0.00008 | 3.24 |
| LSP5 | 5, 10, 30 | 50 | 277.5 | 14.81 | 269.5 | 39 | 0.00004 | 2.88 |
| LSP6 | 6, 8, 25 | 70 | 245.8 | 24.08 | 226 | 26 | 0.00002 | 8.06 |
| LSP7 | 6, 10, 25 | 60 | 234.6 | 12.57 | 227.7 | 32 | 0.00003 | 2.94 |
| LSP8 | 7, 8, 20 | 50 | 196 | 8.63 | 190.2 | 21 | 0.00012 | 2.96 |
| LSP9 | 7, 8, 25 | 50 | 249 | 20.32 | 228.6 | 27 | 0.00003 | 8.19 |
| LSP10 | 10, 8, 20 | 60 | 196.4 | 16.65 | 185.1 | 22 | 0.00006 | 5.75 |
| LSP11 | 10, 10, 20 | 40 | 204.4 | 15.41 | 188.5 | 27 | 0.00004 | 7.78 |
| LSP12 | 10, 12, 20 | 30 | 224 | 18.21 | 201.1 | 32 | 0.00003 | 10.22 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Varyani, A.; Salehi, M.; Heydari Gharahcheshmeh, M. Optimizing Mixed-Model Synchronous Assembly Lines with Bipartite Sequence-Dependent Setup Times in Advanced Manufacturing. Energies 2024, 17, 2865. https://doi.org/10.3390/en17122865
Varyani A, Salehi M, Heydari Gharahcheshmeh M. Optimizing Mixed-Model Synchronous Assembly Lines with Bipartite Sequence-Dependent Setup Times in Advanced Manufacturing. Energies. 2024; 17(12):2865. https://doi.org/10.3390/en17122865
Chicago/Turabian StyleVaryani, Asieh, Mohsen Salehi, and Meysam Heydari Gharahcheshmeh. 2024. "Optimizing Mixed-Model Synchronous Assembly Lines with Bipartite Sequence-Dependent Setup Times in Advanced Manufacturing" Energies 17, no. 12: 2865. https://doi.org/10.3390/en17122865
APA StyleVaryani, A., Salehi, M., & Heydari Gharahcheshmeh, M. (2024). Optimizing Mixed-Model Synchronous Assembly Lines with Bipartite Sequence-Dependent Setup Times in Advanced Manufacturing. Energies, 17(12), 2865. https://doi.org/10.3390/en17122865