
Detection Method for Inter-Turn Short Circuit Faults in Dry-Type Transformers Based on an Improved YOLOv8 Infrared Image Slicing-Aided Hyper-Inference Algorithm


Abstract
1. Introduction
2. Research on the Improved Yolov8 Slicing-Aided Hyper-Inference Algorithm
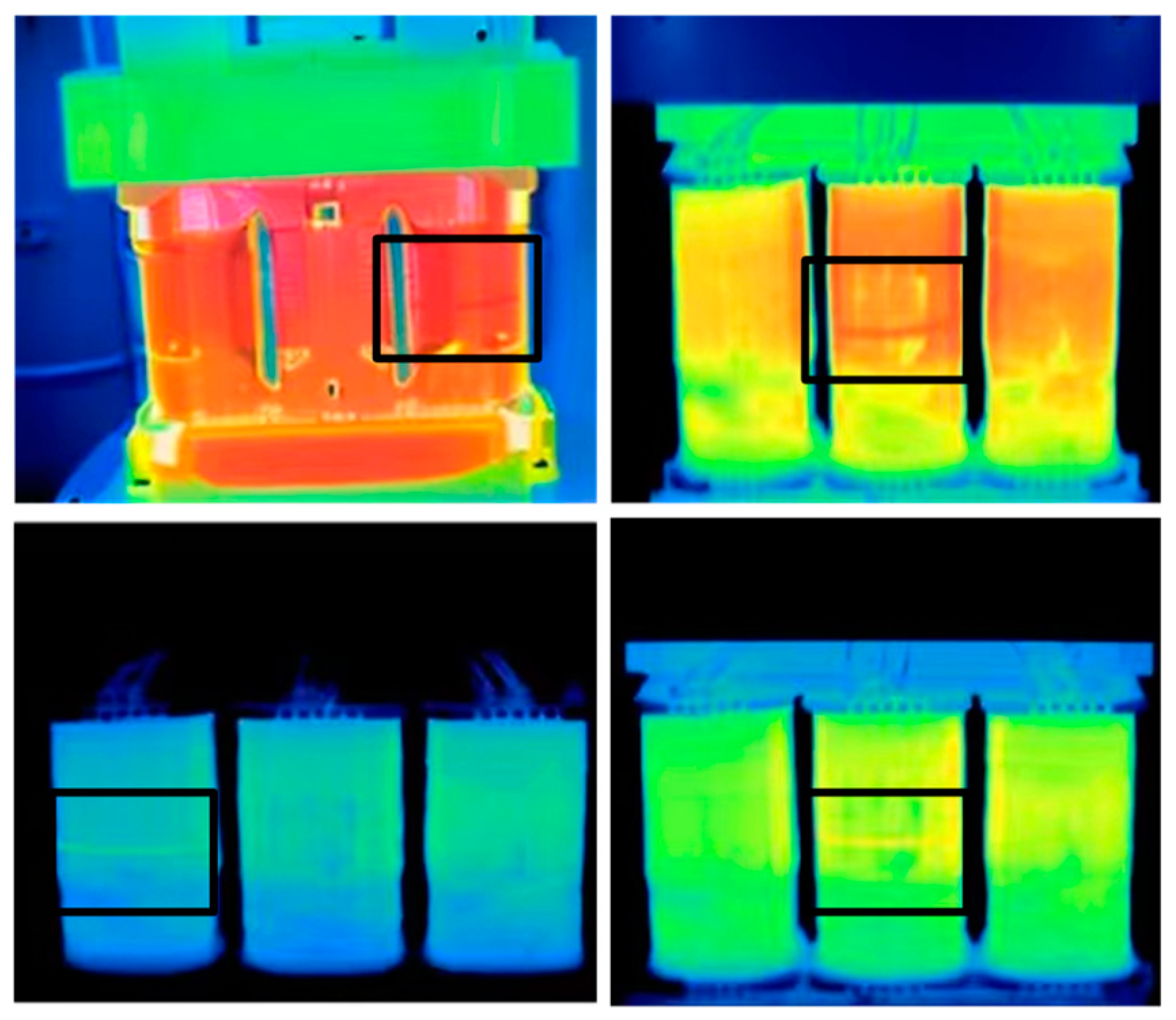
2.1. Data Collection and Dataset Production
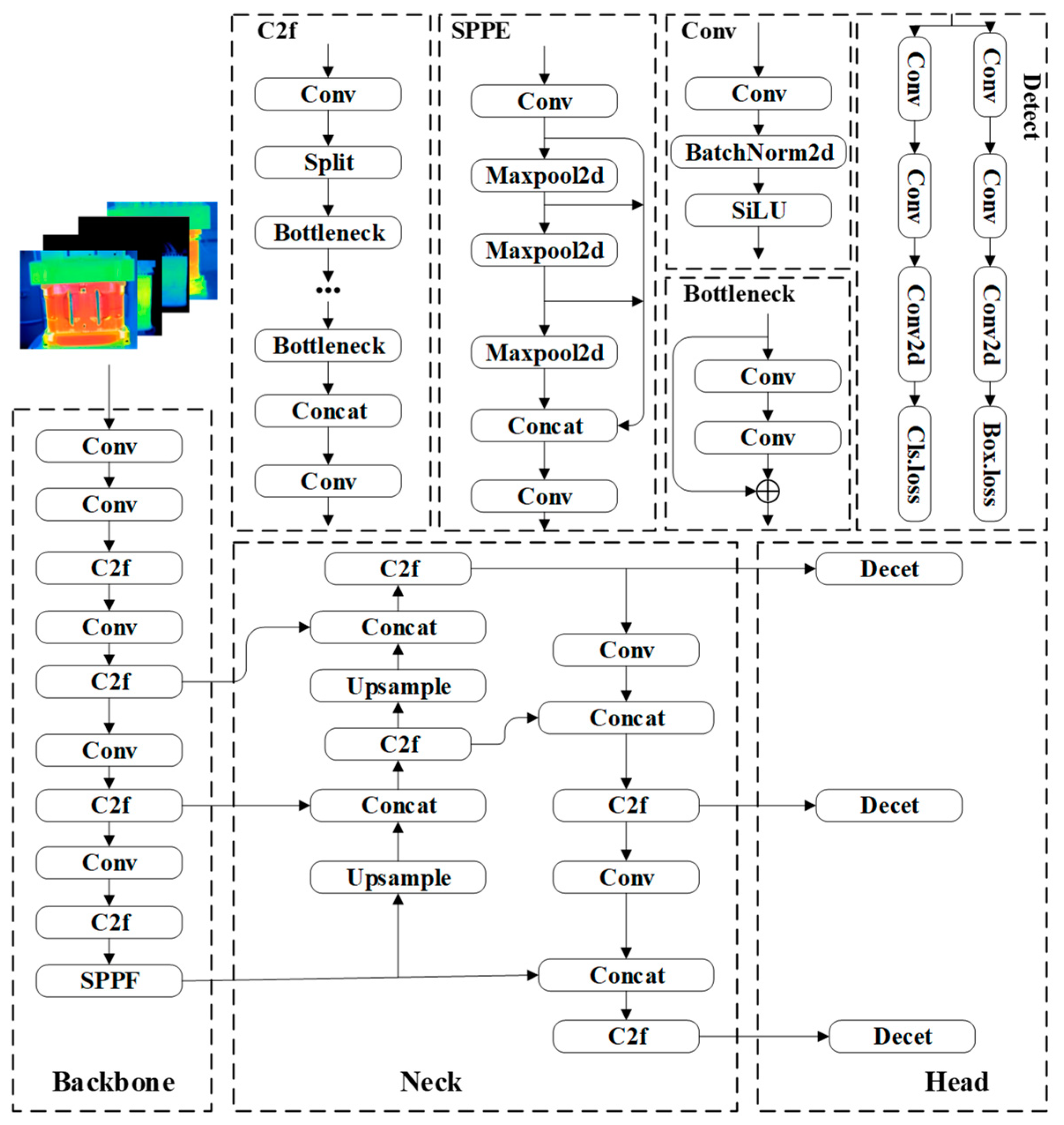
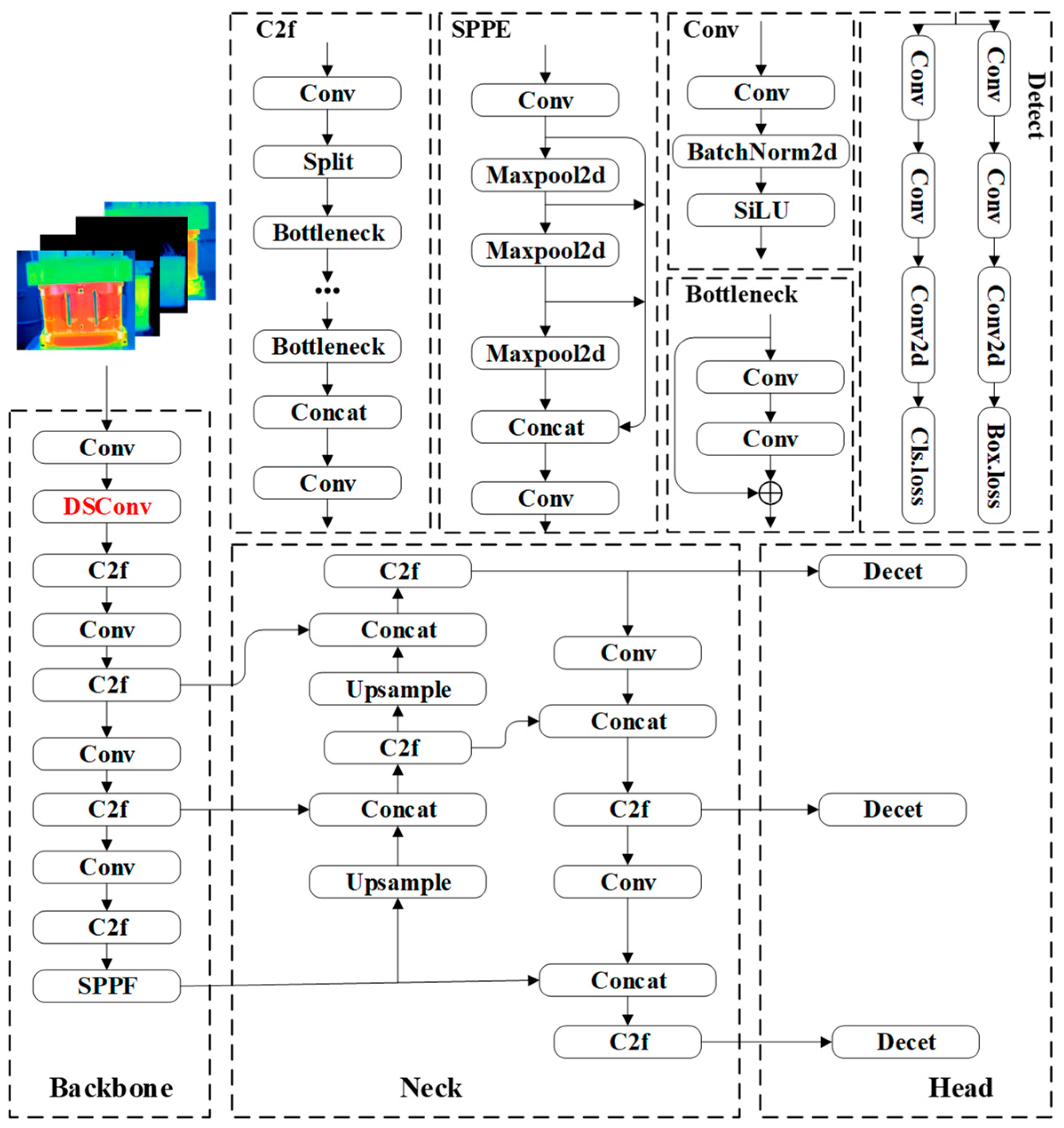
2.2. Network Structure of YOLOv8
2.3. Improvement of YOLOv8 Algorithm
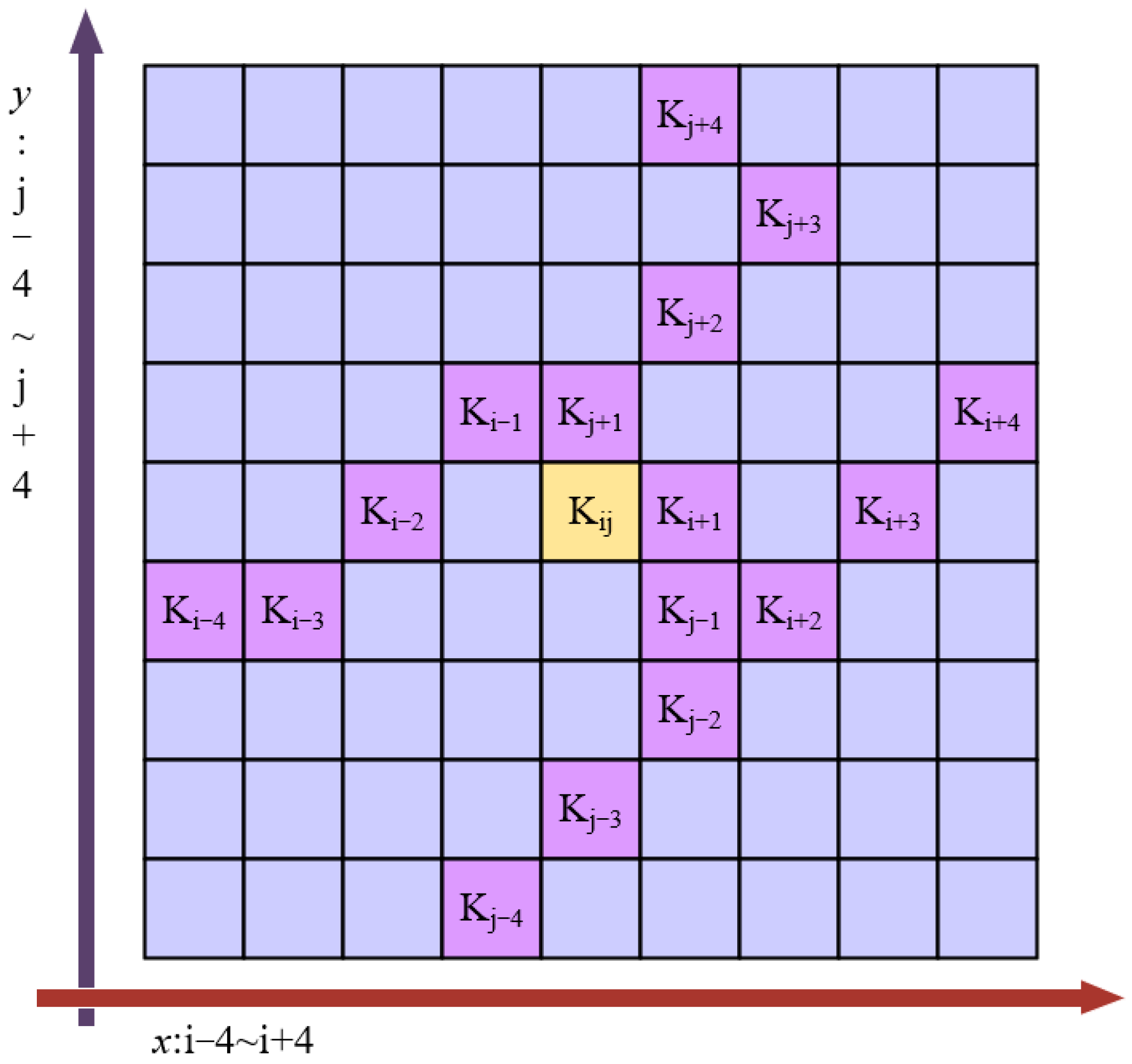
2.3.1. Dynamic Snake Convolution
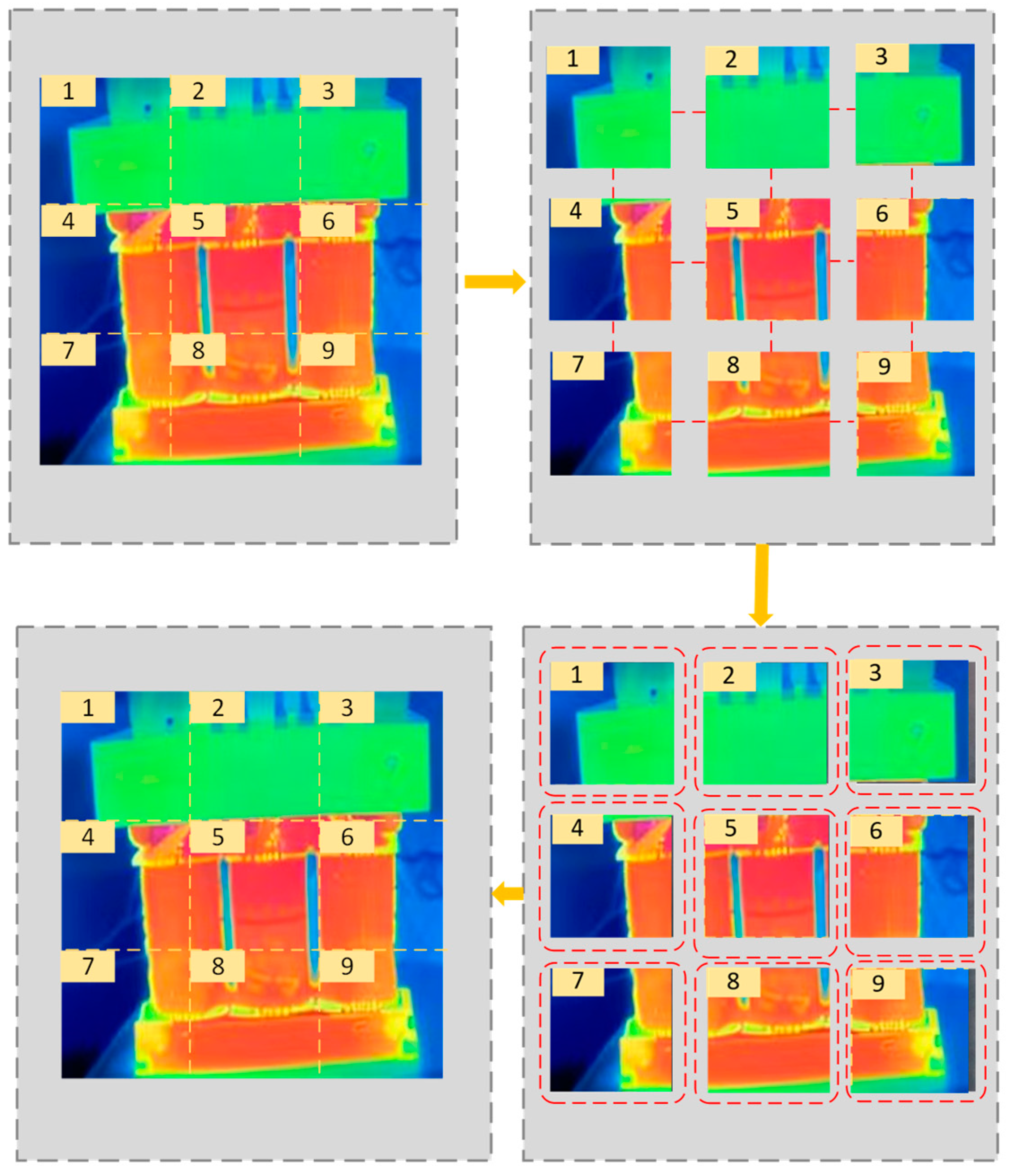
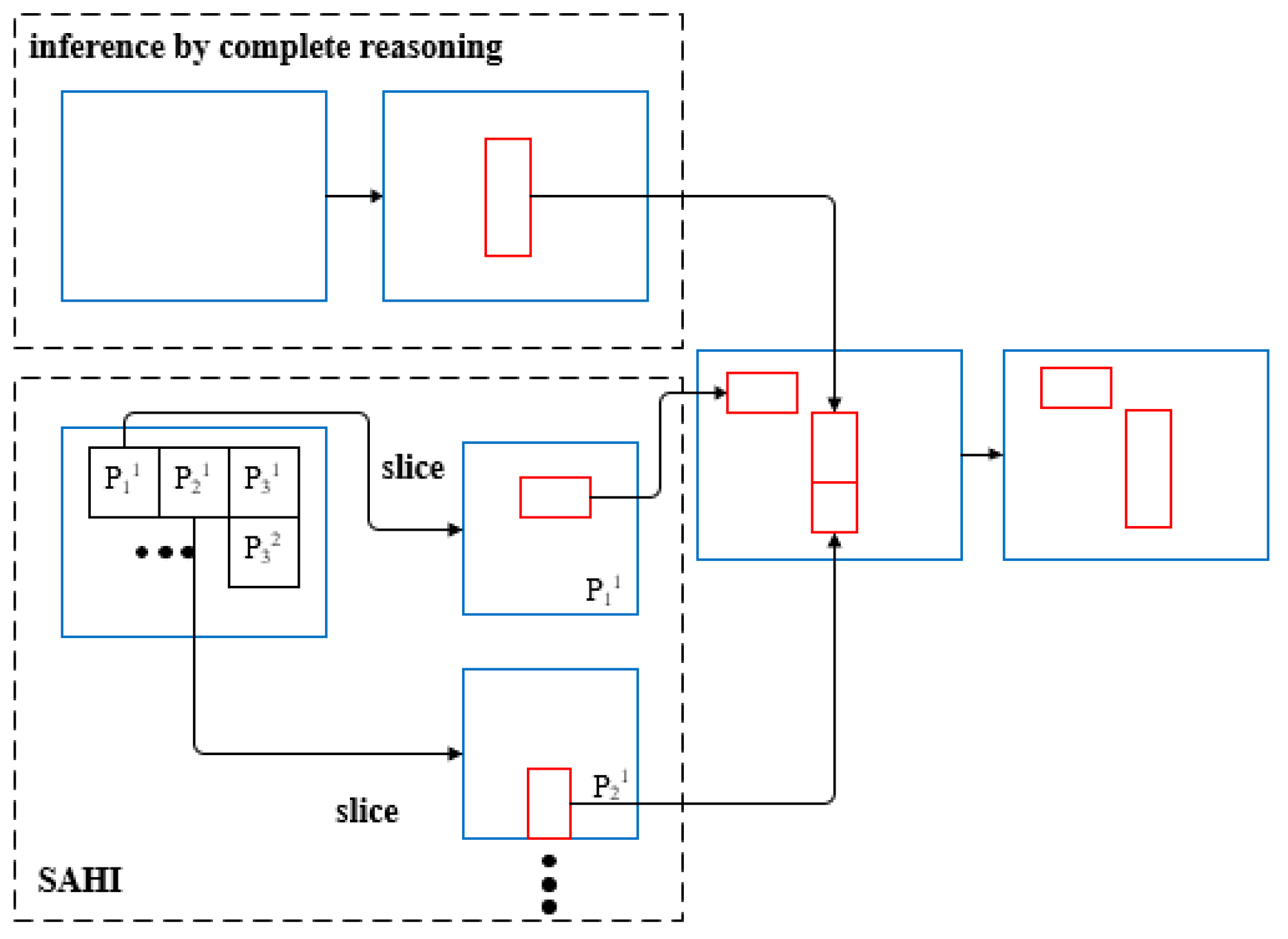
2.3.2. Slicing-Aided Hyper-Inference Algorithm
2.3.3. Improved YOLOv8 Slicing-Aided Hyper-Inference Algorithm
3. Model Generation and Evaluation
4. Conclusions
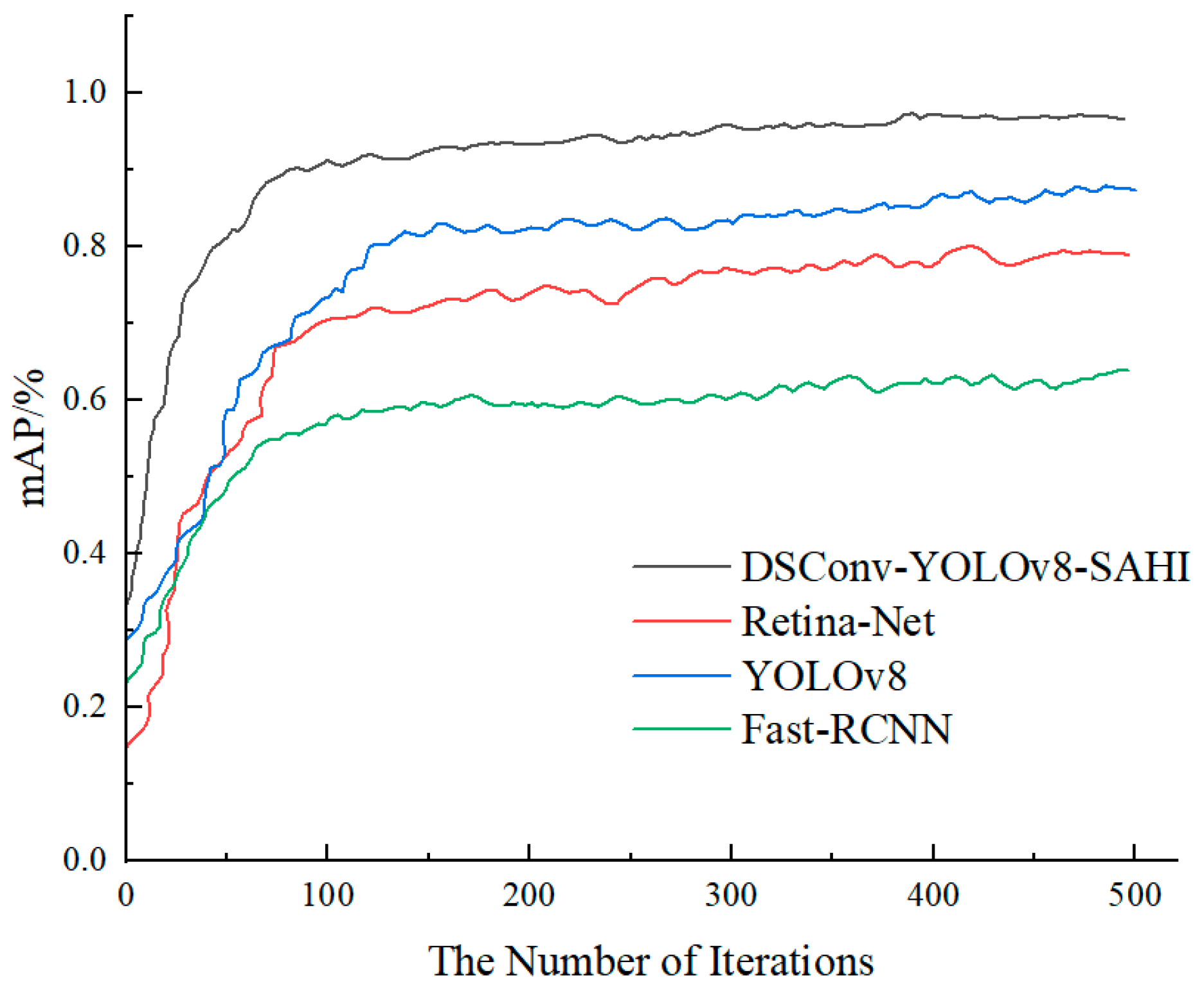
- No overfitting or underfitting occurred during the training process. Experimental validation results demonstrate that the average accuracy of the proposed improved YOLOv8 slicing-aided hyper-inference algorithm exceeds 97%. This algorithm effectively detects the trajectory of inter-turn short circuit faults in dry-type transformers and shows strong potential for practical application;
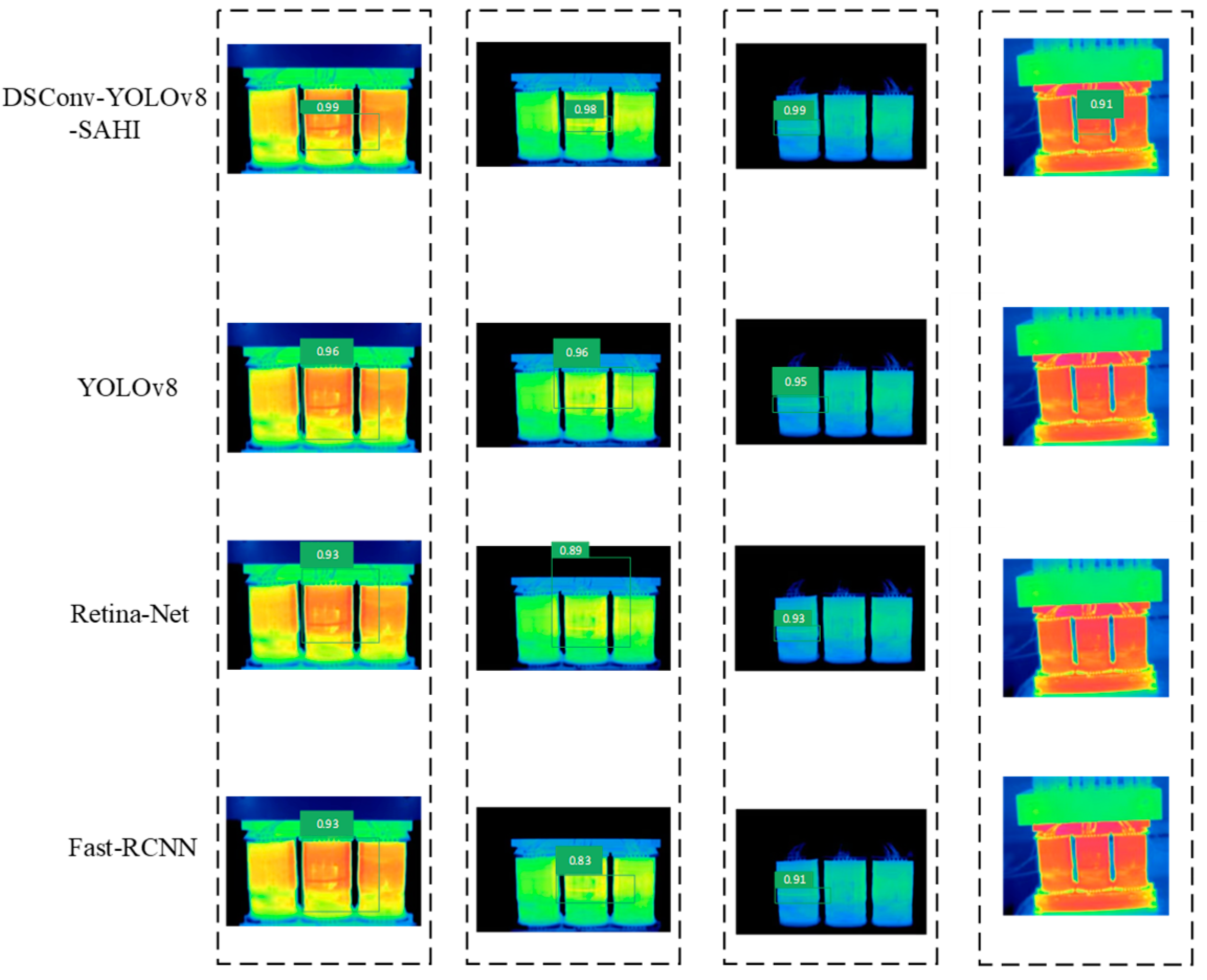
- The enhanced YOLOv8 model shows a 5.74% improvement in average accuracy compared to the original YOLOv8 model in horizontal ablation tests. In vertical network evaluations, the accuracy of the enhanced YOLOv8 model improves by 13.51% over Fast-RCNN and by 8.08% over Retina-Net. Overall, the improved YOLOv8 slicing-aided hyper-inference algorithm demonstrates superior prediction accuracy and stability compared to other models, offering a robust algorithmic foundation for detecting defects in small targets and complex backgrounds;
- The proposed method for detecting inter-turn short circuit fault trajectories in dry-type transformers is valuable for enhancing transformer operation and maintenance efficiency. Additionally, it offers significant reference value for fault detection in other electrical equipment and introduces a new approach to unmanned power equipment inspection.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhu, B.; Xian, R.; Fan, H.; Liu, X.; Gao, H.; Chen, L. Transformer fault diagnosis technology based on the fusion of WRSR and improved naive Bayes. Power Syst. Prot. Control 2021, 49, 120–128. [Google Scholar]
- Zheng, Y.; Gong, X.; Pan, S.; Sun, J. Analysis on Leakage Flux Characteristics of turn-to-turn short-circuit fault for power transformer. Autom. Electr. Power Syst. 2022, 46, 121–127. [Google Scholar]
- Chen, H.; Wang, Q.; Liu, X. Transformer fault diagnosis based on BAS-BP model. J. Xinyang Norm. Univ. (Nat. Sci. Ed.) 2020, 33, 635–639. [Google Scholar]
- Zhang, H.; Wang, X.; Gong, R.; Long, R.; Jian, Z. Influence of support failure on short-circuit dynamic characteristics of transformer winding. Transformer 2024, 61, 22–28. [Google Scholar]
- Xian, R.; Chen, L.; Geng, K.; Fan, H.; Zhang, B.; Gao, H. Research on electromagnetic characteristics of short circuit faults in low-voltage windings of grounding transformers. Power Syst. Prot. Control 2021, 49, 74–82. [Google Scholar]
- Ballal, M.S.; Suryawanshi, H.M.; Mishra, M.K.; Chaudhari, B.N. Interturn faults detection of transformers by diagnosis of neutral current. IEEE Trans. Power Deliv. 2016, 31, 1096–1105. [Google Scholar] [CrossRef]
- Li, D.; Liu, Y.; Fan, X.; Li, H.; Li, Y.; Liu, H. Discrimination and degree detection of axial and radial deformation in transformer windings based on distributed sensing of ribbon optical fibers. Proc. CSEE 2024, 1–11. [Google Scholar]
- Cui, J.; Ma, H. Voiceprint Recognition model of transformer core looseness fault based on improved MFCC and 3D-CNN. Electr. Mach. Control 2022, 26, 150–160. [Google Scholar]
- Zhou, L.; Li, W.; Jiang, J.; Gao, S.; Yan, J. Improved FRA modeling and radial deformation fault analysis of traction transformer windings. Electr. Power Autom. Equip. 2019, 39, 213–218. [Google Scholar]
- Meira, M.; Bossio, G.; ÁLvarez, R.; Mombello, E.; Verucchi, C. Differential current monitoring for the detection of inter-turns short circuits in power transformers. In Proceedings of the 2020 IEEE Biennial Congress of Argentina (ARGENCON), Resistencia, Argentina, 1–4 December 2020; pp. 1–7. [Google Scholar]
- Santos, M.G.; Aquino, B.R.R.; Lira, S.M.M. Thermography and artificial intelligence in transformer fault detection. Electr. Eng. 2018, 100, 1317–1325. [Google Scholar] [CrossRef]
- Chen, S.; Sheng, G.; Zhang, L.; Wang, F. Fast Simulation method of temperature field distribution for dry-type transformer based on equivalent thermal parameters of windings. High Volt. Eng. 2024, 1–13. [Google Scholar]
- Hou, T. Simulation of Dry-type Transformer Drying and DC Heating Temperature Field. Electr. Switchg. 2024, 62, 47–51+55. [Google Scholar]
- Li, X.; Su, B.; Chen, W.; Yi, J.; Yao, X. Simulation analysis of temperature field of dry-type transformer under natural cooling. Mech. Electr. Eng. Technol. 2024, 53, 253–256+282. [Google Scholar]
- Yang, G.; Wang, J.; Nie, Z.; Yang, H.; Yu, S. A Lightweight YOLOv8 tomato detection algorithm combining feature enhancement and attention. Agronomy 2023, 13, 1824. [Google Scholar] [CrossRef]
- Zhao, P.; Wang, J.; Xia, H.; He, W. A Novel Industrial Magnetically Enhanced Hydrogen Production Electrolyzer and Effect of Magnetic Field Configuration. Appl. Energy 2024, 367, 123402. [Google Scholar] [CrossRef]
- Jia, S.; Tian, M.; Lu, H. Combined neural network anomaly detection algorithm based on data augmentation. Inf. Technol. Informatiz. 2023, 187–190. [Google Scholar]
- Sheng, X.; Shen, H. Semi-supervised text classification algorithm with data augmentation and similar pseudo-labels. Appl. Res. Comput. 2023, 40, 1019–1023+1051. [Google Scholar]
- Zhao, P.; Wang, J.; He, W.; Xia, H.; Cao, X.; Li, Y.; Sun, L. Magnetic Field Pre-Polarization Enhances the Efficiency of Alkaline Water Electrolysis for Hydrogen Production. Energy Convers. Manag. 2023, 283, 116906. [Google Scholar] [CrossRef]
- Su, J.; Jia, Z.; Qin, Y.; Zhang, J. Improved YOLOv8 algorithm for industrial surface defect detection. Comput. Eng. Appl. 2024, 1–15. [Google Scholar] [CrossRef]
- Hu, X.; Chang, Y.; Qin, H.; Xiao, J.; Cheng, H. Binocular ranging method based on improved YOLOv8 and GMM image point set matching. J. Graph. 2024, 1–14. [Google Scholar]
- Long, Y.; Xiao, X. Improved YOLOv8 metal surface defect detection model. Manuf. Technol. Mach. Tool 2024, 1–12. [Google Scholar]
- Wang, M.; Wu, B. Application of building concrete crack detection technology based on YOLOv8. Inter. Archit. China 2024, 181–183. [Google Scholar]
- Zhao, P.; Wang, J.; Sun, L.; Li, Y.; Xia, H.; He, W. Optimal Electrode Configuration and System Design of Compactly-Assembled Industrial Alkaline Water Electrolyzer. Energy Convers. Manag. 2024, 299, 117875. [Google Scholar] [CrossRef]
- Chen, Z.; Yang, X.; Chen, X. Collaboration application of YOLO and SAHI models in the detection of apparent damage of building facades. Constr. Technol. 2022, 51, 114–119. [Google Scholar]
- Fan, D.; Yang, Y.; Feng, S.; Dai, W.; Liang, B.; Xiong, J. SIPNet SAHI: Multiscale sunspot extraction for high-resolution full solar images. Appl. Sci. 2023, 14, 7. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Category of Identification | Number of Enhanced Images | Label Name |
|---|---|---|---|
| 1 | winding | 2000 | 0 |
| 2 | fault trajectory | 2000 | 1 |
| Hardware and Software | Versions and Parameters |
|---|---|
| CPU | Intel Core i7 13700F |
| CUDA | 12.2 |
| GPU | NVIDIA GeForce RTX 4070 |
| operating system | Windows 10 |
| Python | Python 3.9 |
| Pytorch | 2.0.0 |
| Pycharm | Pycharm 2019 |
| Model Name | p (%) | R (%) | Map (%) |
|---|---|---|---|
| YOLOv8 | 86.43 | 86.27 | 91.32 |
| Fast-RCNN | 80.21 | 79.15 | 83.55 |
| Retina-Net | 83.02 | 81.19 | 88.98 |
| DSConv-YOLOv8-SAHI | 91.69 | 88.64 | 97.06 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Xia, J.; Wen, Y.; Weng, L.; Ma, Z.; Yang, H.; Yang, H.; Dou, J.; Wang, J.; Zhao, P. Detection Method for Inter-Turn Short Circuit Faults in Dry-Type Transformers Based on an Improved YOLOv8 Infrared Image Slicing-Aided Hyper-Inference Algorithm. Energies 2024, 17, 4559. https://doi.org/10.3390/en17184559
Zhang Z, Xia J, Wen Y, Weng L, Ma Z, Yang H, Yang H, Dou J, Wang J, Zhao P. Detection Method for Inter-Turn Short Circuit Faults in Dry-Type Transformers Based on an Improved YOLOv8 Infrared Image Slicing-Aided Hyper-Inference Algorithm. Energies. 2024; 17(18):4559. https://doi.org/10.3390/en17184559
Chicago/Turabian StyleZhang, Zhaochuang, Jianhua Xia, Yuchuan Wen, Liting Weng, Zuofu Ma, Hekai Yang, Haobo Yang, Jinyao Dou, Jingang Wang, and Pengcheng Zhao. 2024. "Detection Method for Inter-Turn Short Circuit Faults in Dry-Type Transformers Based on an Improved YOLOv8 Infrared Image Slicing-Aided Hyper-Inference Algorithm" Energies 17, no. 18: 4559. https://doi.org/10.3390/en17184559
APA StyleZhang, Z., Xia, J., Wen, Y., Weng, L., Ma, Z., Yang, H., Yang, H., Dou, J., Wang, J., & Zhao, P. (2024). Detection Method for Inter-Turn Short Circuit Faults in Dry-Type Transformers Based on an Improved YOLOv8 Infrared Image Slicing-Aided Hyper-Inference Algorithm. Energies, 17(18), 4559. https://doi.org/10.3390/en17184559