Relevance-Based Reconstruction Using an Empirical Mode Decomposition Informer for Lithium-Ion Battery Surface-Temperature Prediction

Abstract
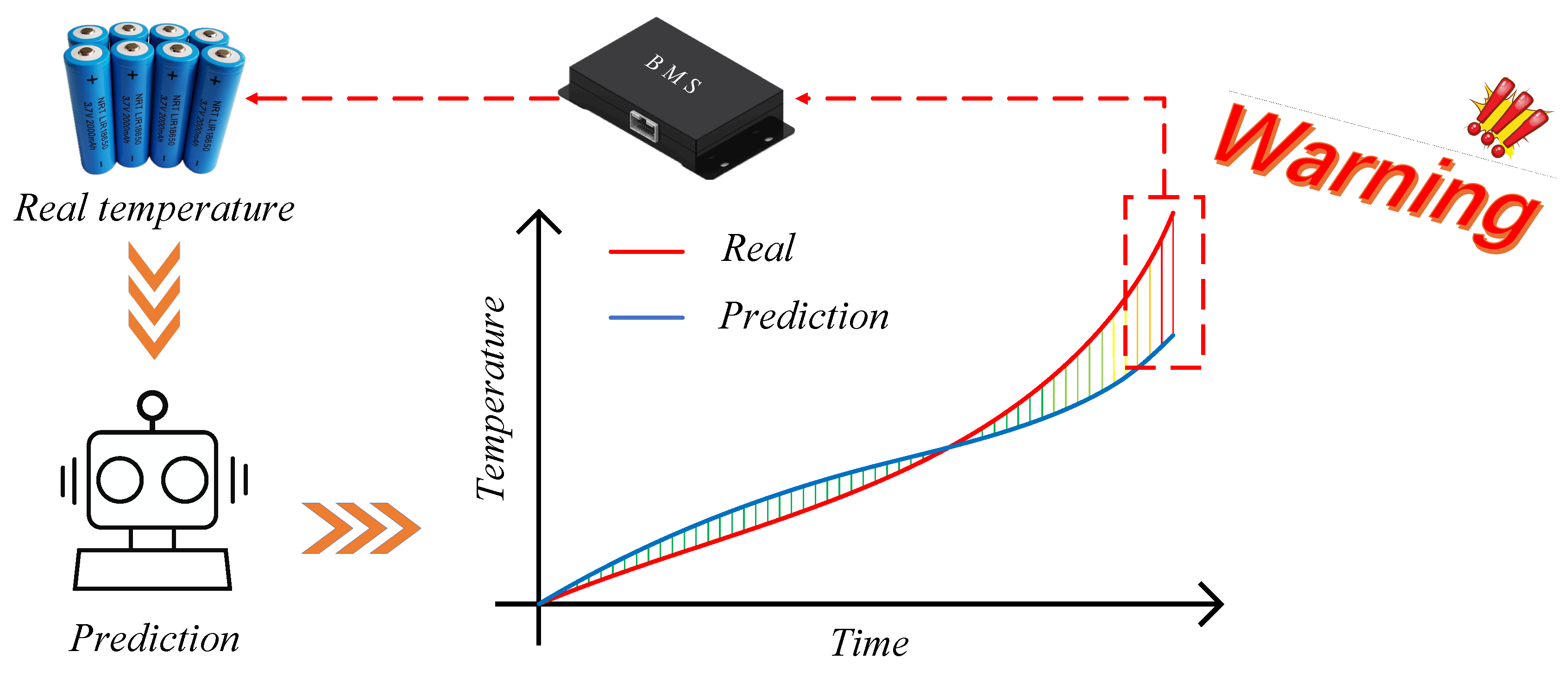
1. Introduction
2. Surface Temperature Prediction Model
2.1. The Empirical Mode Decomposition
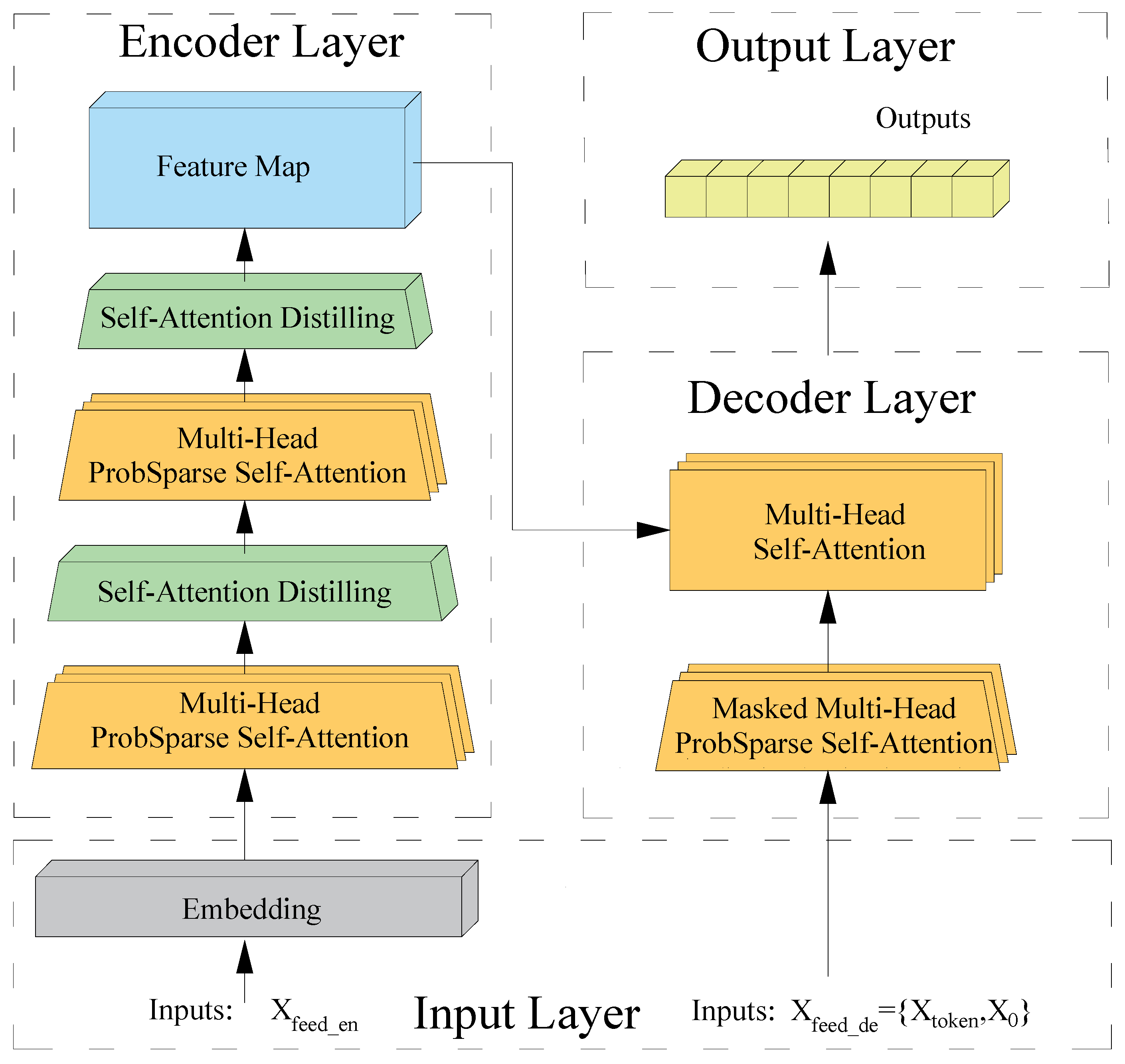
2.2. The Informer Framework
2.2.1. Input Layer
2.2.2. Encoder Layer
2.2.3. Decoder Layer
2.2.4. Output Layer
2.3. The EMD-Informer Model
2.3.1. Data Processing
2.3.2. The EMD-Informer Model Architecture
- Use EMD to decompose the temperature data into several IMFs;
- Calculate the PCC between the IMFs and the original temperature data, and reconstruct the IMFs into low-, medium-, and high-correlation components based on the level of correlation;
- The reconstructed components with different correlation degrees, along with the feature data of current and voltage, are used as inputs for the sub-models;
- Calculate the outputs of the sub-models and reconstruct them to obtain the final prediction output.
3. Dataset and Evaluation Metrics
3.1. Dataset
3.2. Evaluation Criteria
4. Experimental Analysis
4.1. Model Training and Parameter Optimization
- For sub-model 1, the optimal model dimension and batch size for the evaluation metrics are 1024 and 32, respectively;
- For sub-model 2, the optimal model dimension and batch size for the evaluation metrics are 1024 and 16, respectively;
- For sub-model 3, the optimal model dimension and batch size for the evaluation metrics are 512 and 32, respectively;
4.2. Lithium-Ion Battery Surface Temperature Prediction Comparison Analysis
- MSE is reduced by 82.31%, 75.83%, and 63.74%, respectively;
- MAE is reduced by 60.01%, 59.82%, and 47.52%, respectively;
- MAXE is reduced by 34.64%, 19.25%, and 12.33%, respectively.
4.3. Multi-Step Prediction of Battery Surface Temperature
5. Conclusions
- (1)
- Under complex operating conditions, changes in the surface temperature of the battery exhibit high nonlinearity. The original temperature data were decomposed using the EMD algorithm and then reconstructed into features with varying correlation degrees. These features were combined with voltage and current data to serve as inputs for the sub-models, enabling them to learn from diverse characteristics. Single-step predictions indicate that the EMD–Informer model demonstrates higher predictive accuracy.
- (2)
- Multi-step predictions demonstrate that the performance of the EMD-Informer model, as well as the comparative models, deteriorates with an increase in prediction horizon, indicating a conflict between high predictive accuracy and a broad predictive range; the prediction horizon must be chosen appropriately to balance this conflict. Multi-step predictions show that, under the condition that the maximum absolute error is less than 0.5 °C, the hit rate for a 12-step prediction is better than that for 18-step and 24-step predictions. This achieves high predictive accuracy and a sufficiently broad prediction range, which helps in early detection of potential temperature anomalies and effectively reduces the risk of thermal runaway in the battery.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, B.; Feng, Y.; Wang, S. Two-phase separation based spatiotemporal modeling of thermal processes with applications to lithium-ion batteries. Energy Storage 2022, 49, 104050. [Google Scholar] [CrossRef]
- Cen, J.; Li, Z.; Jiang, F. Experimental Investigation on Using the Electric Vehicle Air Conditioning System for Lithium-Ion Battery Thermal Management. Energy Sustain. Dev. 2018, 45, 88–95. [Google Scholar] [CrossRef]
- Feng, Y.; Zhou, L.; Ma, H.; Wu, Z.; Zhao, Q.; Li, H.; Zhang, K. Challenges and advances in wide-temperature rechargeable lithium batteries. Energy Environ. Sci. 2022, 15, 1711–1759. [Google Scholar] [CrossRef]
- Zhu, S.; He, C.; Zhao, N.; Sha, J. Data-driven analysis on thermal effects and temperature changes of lithium-ion battery. J. Power Sources 2021, 482, 228983. [Google Scholar] [CrossRef]
- Wang, Q.; Ping, P.; Zhao, X.; Chu, G.; Sun, J.; Chen, C. Thermal runaway caused fire and explosion of lithium-ion battery. J. Power Sources 2012, 208, 210–224. [Google Scholar] [CrossRef]
- Sun, J.; Ren, S.; Shang, Y.; Zhang, X.; Liu, Y.; Wang, D. A novel fault prediction method based on convolutional neural network and long short-term memory with correlation coefficient for lithium-ion battery. J. Energy Storage 2023, 62, 106811. [Google Scholar] [CrossRef]
- Zhu, G.; Kong, C.; Wang, J.; Kang, J.; Wang, Q.; Qian, C. A fractional-order electrochemical lithium-ion batteries model considering electrolyte polarization and aging mechanism for state of health estimation. J. Energy Storage 2023, 72, 108649. [Google Scholar] [CrossRef]
- Miaari, A.; Ali, H. Batteries temperature prediction and thermal management using machine learning: An overview. Energy Rep. 2023, 10, 2277–2305. [Google Scholar] [CrossRef]
- Lee, G.; Kwon, D.; Lee, C. A convolutional neural network model for SOH estimation of Li-ion batteries with physical interpretability. Mech. Syst. Signal Process. 2023, 188, 110004. [Google Scholar] [CrossRef]
- Wu, T.; Wang, C.; Hu, Y.; Liang, Z.; Fan, C. Research on electrochemical characteristics and heat generating properties of power battery based on multi-time scales. Energy 2023, 265, 126416. [Google Scholar] [CrossRef]
- Li, W.; Rentemeister, M.; Badeda, J.; Jost, D.; Schulte, D.; Sauer, D. Digital twin for battery systems: Cloud battery management system with online state-of-charge and state-of-health estimation. J. Energy Storage 2020, 30, 101557. [Google Scholar] [CrossRef]
- Sun, J.; Zhu, C.; Li, L.; Li, Q. Online Temperature Estimation Method for Electric Vehicle Power Battery. CES Trans. Electr. Mach. Syst. 2017, 32, 197–203. [Google Scholar]
- Liu, M.; Zhou, X.; Yang, L.; Ju, X. A novel Kalman-filter-based battery internal temperature estimation method based on an enhanced electro-thermal coupling model. J. Energy Storage 2023, 71, 108241. [Google Scholar] [CrossRef]
- Qi, X.; Hong, C.; Ye, T.; Gu, L.; Wu, W. Frequency reconstruction oriented EMD-LSTM-AM based surface temperature prediction for lithium-ion battery. J. Energy Storage 2024, 84, 111001. [Google Scholar] [CrossRef]
- Álvarez Antón, J.C.; García Nieto, P.J.; de Cos Juez, F.J.; Sánchez Lasheras, F.; González Vega, M.; Roqueñí Gutiérrez, M.N. Battery state-of-charge estimator using the SVM technique. Appl. Math. Model. 2013, 37, 6244–6253. [Google Scholar] [CrossRef]
- Guo, Y.; Zhao, Z.; Huang, L. SoC Estimation of Lithium Battery Based on Improved BP Neural Network. Energy Procedia 2017, 105, 4153–4158. [Google Scholar] [CrossRef]
- Li, W.; Zhu, J.; Xia, Y.; Gorji, M.B.; Wierzbicki, T. Data-driven safety envelope of lithium-ion batteries for electric vehicles. Joule 2019, 3, 2703–2715. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, X.; Li, C.; Yu, Y.; Zhou, G.; Wang, C.; Zhao, W. Temperature prediction of lithium-ion battery based on artificial neural network model. Appl. Therm. Eng. 2023, 228, 120482. [Google Scholar] [CrossRef]
- Jiang, Y.; Yu, Y.; Huang, J.; Cai, W.; Marco, J. Li-Ion Battery Temperature Estimation Based on Recurrent Neural Networks. Sci. China Technol. Sci. 2021, 64, 1335–1344. [Google Scholar] [CrossRef]
- Jiang, L.; Yan, C.; Zhang, X.; Zhou, B.; Cheng, T.; Zhao, J.; Gu, J. Temperature Prediction of Battery Energy Storage Plant Based on EGA-BiLSTM. Energy Rep. 2022, 8 (Suppl. S5), 1009–1018. [Google Scholar] [CrossRef]
- Brian, B.; Chetan, K.; Matthew, D. Adaptation of an Electrochemistry-based Li-Ion Battery Model to Account for Deterioration Observed Under Randomized Use. In Proceedings of the Annual Conference of the Prognostics and Health Management Society, Fort Worth, TX, USA, 29 September–2 October 2014. [Google Scholar]
- Liu, C.; Ge, X.; Zhang, X.; Yang, C.; Liu, Y. Research on the Characteristics of Oscillation Combustion Pulsation in Swirl Combustor. Energies 2024, 17, 4164. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiser, L.; Polosukhin, L. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, arXiv:1706.03762. [Google Scholar]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting. AAAI Conf. Artif. Intell. 2021, 35, 11106–11115. [Google Scholar] [CrossRef]
- Rdahi, S.; AI-Majidi, S.; Abbod, M.; AI-Raweshidy, H. Machine Learning Approaches for Short-Term Photovoltaic Power Forecasting. Energies 2024, 17, 4301. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | PCC |
|---|---|
| −0.01238 | |
| 0.00190 | |
| 0.03288 | |
| 0.12448 | |
| 0.21860 | |
| 0.37338 | |
| 0.49136 | |
| 0.45558 | |
| 0.45950 | |
| 0.23390 | |
| 0.23561 |
| Dimension of Model | 256 | 512 | 1024 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Batch Size | 16 | 32 | 64 | 16 | 32 | 64 | 16 | 32 | 64 | |
| Sub-model 1 | MSE | 0.00080 | 0.00080 | 0.00081 | 0.00077 | 0.00080 | 0.00080 | 0.00080 | 0.00076 | 0.00085 |
| MAE | 0.01588 | 0.01614 | 0.01625 | 0.01547 | 0.01619 | 0.01607 | 0.01617 | 0.01602 | 0.01720 | |
| MAXE | 0.34059 | 0.35343 | 0.34334 | 0.34732 | 0.32537 | 0.35882 | 0.32567 | 0.31090 | 0.33378 | |
| Sub-model 2 | MSE | 0.00045 | 0.00095 | 0.00090 | 0.00047 | 0.00069 | 0.00086 | 0.00032 | 0.00077 | 0.00097 |
| MAE | 0.01542 | 0.02306 | 0.02151 | 0.01640 | 0.02018 | 0.02109 | 0.01345 | 0.02179 | 0.02400 | |
| MAXE | 0.10481 | 0.13279 | 0.14734 | 0.08276 | 0.11686 | 0.14080 | 0.07268 | 0.09697 | 0.11312 | |
| Sub-model 3 | MSE | 0.00049 | 0.00065 | 0.00125 | 0.00061 | 0.00030 | 0.00073 | 0.00051 | 0.00038 | 0.00094 |
| MAE | 0.01567 | 0.02013 | 0.02612 | 0.02039 | 0.01395 | 0.02146 | 0.01853 | 0.01625 | 0.02406 | |
| MAXE | 0.11184 | 0.12009 | 0.15740 | 0.09903 | 0.08033 | 0.14252 | 0.06930 | 0.06121 | 0.12526 | |
| Parameters | Sub-Model 1 | Sub-Model 2 | Sub-Model 3 |
|---|---|---|---|
| Input Sequence Length | 14 | ||
| Start Token Length | 7 | ||
| Prediction Sequence Length | 1 | ||
| Factor | 5 | ||
| Numbers of Heads | 8 | ||
| Encoder Layers Number | 2 | ||
| Decoder Layers Number | 1 | ||
| Dimension of fcn in Model | 2048 | ||
| Dropout | 0.05 | ||
| Learning Rate | 0.00005 | ||
| Batch Size | 32 | 16 | 32 |
| Dimension of Model | 1024 | 1024 | 512 |
| Method | Sub-Model 1 | Sub-Model 2 | Sub-Model 3 | Reconstructed |
|---|---|---|---|---|
| MSE | 0.00076 | 0.00032 | 0.00030 | 0.00095 |
| MAE | 0.01602 | 0.01345 | 0.01395 | 0.02114 |
| MAXE | 0.31090 | 0.07268 | 0.08033 | 0.32165 |
| Method | LSTM | GRU | Informer | EMD–Informer |
|---|---|---|---|---|
| MSE | 0.00537 | 0.00393 | 0.00262 | 0.00095 |
| MAE | 0.05286 | 0.05261 | 0.04028 | 0.02114 |
| MAXE | 0.49210 | 0.39832 | 0.36686 | 0.32164 |
| Error Range | Maximum Absolute Error < 1 °C | Maximum Absolute Error < 0.5 °C | ||||||
|---|---|---|---|---|---|---|---|---|
| Prediction Horizons | 24 | 18 | 12 | 6 | 24 | 18 | 12 | 6 |
| EMD-Informer hit rate | 98.98% | 99.40% | 99.64% | 100% | 78.43% | 84.32% | 93.57% | 98.32% |
| Informer hit rate | 97.48% | 98.74% | 99.46% | 99.92% | 72.89% | 81.81% | 92.28% | 96.82% |
| LSTM hit rate | 97.35% | 98.68% | 99.22% | 99.82% | 74.80% | 81.60% | 91.27% | 96.69% |
| GRU hit rate | 95.97% | 98.32% | 99.28% | 99.94% | 65.17% | 80.63% | 91.15% | 97.42% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Kong, Y.; Wang, C.; Wang, X.; Wang, M.; Wang, Y. Relevance-Based Reconstruction Using an Empirical Mode Decomposition Informer for Lithium-Ion Battery Surface-Temperature Prediction. Energies 2024, 17, 5001. https://doi.org/10.3390/en17195001
Li C, Kong Y, Wang C, Wang X, Wang M, Wang Y. Relevance-Based Reconstruction Using an Empirical Mode Decomposition Informer for Lithium-Ion Battery Surface-Temperature Prediction. Energies. 2024; 17(19):5001. https://doi.org/10.3390/en17195001
Chicago/Turabian StyleLi, Chao, Yigang Kong, Changjiang Wang, Xueliang Wang, Min Wang, and Yulong Wang. 2024. "Relevance-Based Reconstruction Using an Empirical Mode Decomposition Informer for Lithium-Ion Battery Surface-Temperature Prediction" Energies 17, no. 19: 5001. https://doi.org/10.3390/en17195001
APA StyleLi, C., Kong, Y., Wang, C., Wang, X., Wang, M., & Wang, Y. (2024). Relevance-Based Reconstruction Using an Empirical Mode Decomposition Informer for Lithium-Ion Battery Surface-Temperature Prediction. Energies, 17(19), 5001. https://doi.org/10.3390/en17195001