

Effect of Machine Learning Algorithms on Prediction of In-Cylinder Combustion Pressure of Ammonia–Oxygen in a Constant-Volume Combustion Chamber †
 , , and
, , and
Abstract
:1. Introduction
2. Methodology
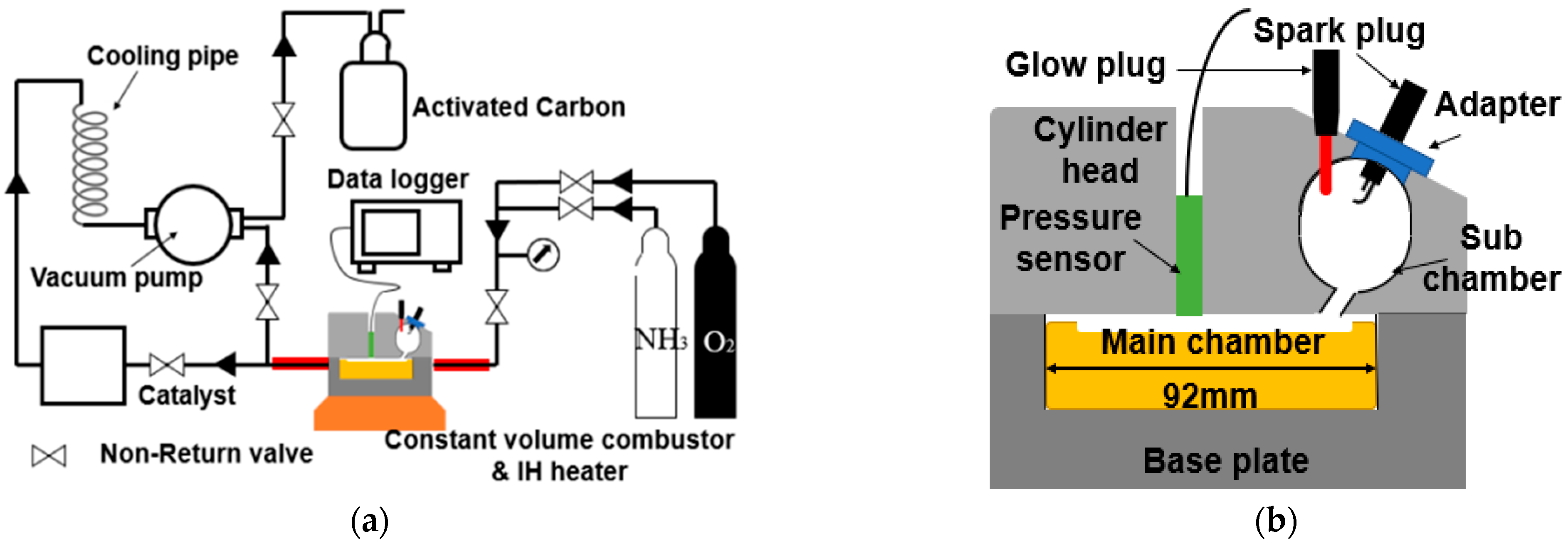
2.1. Experimental Bench Test
2.1.1. Procedure
2.1.2. Experimental Conditions
2.1.3. Analysis Methods
2.2. Machine Learning Prediction Model
2.2.1. Prediction Conditions
2.2.2. Error Analysis
2.2.3. Algorithms Applied
Support Vector Regression
Random Forest
Linear Regression
Gradient Boosting
3. Result and Discussion
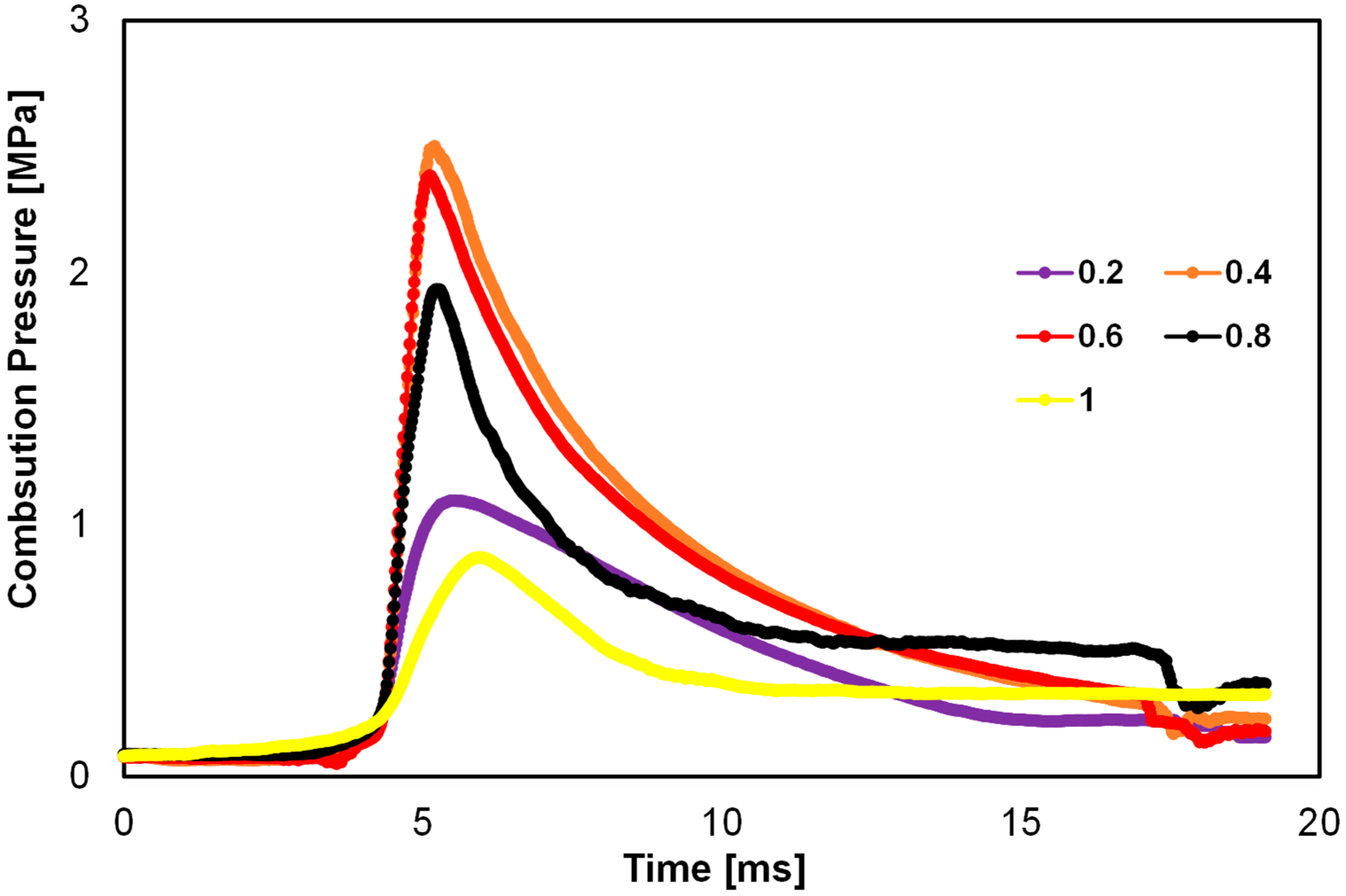
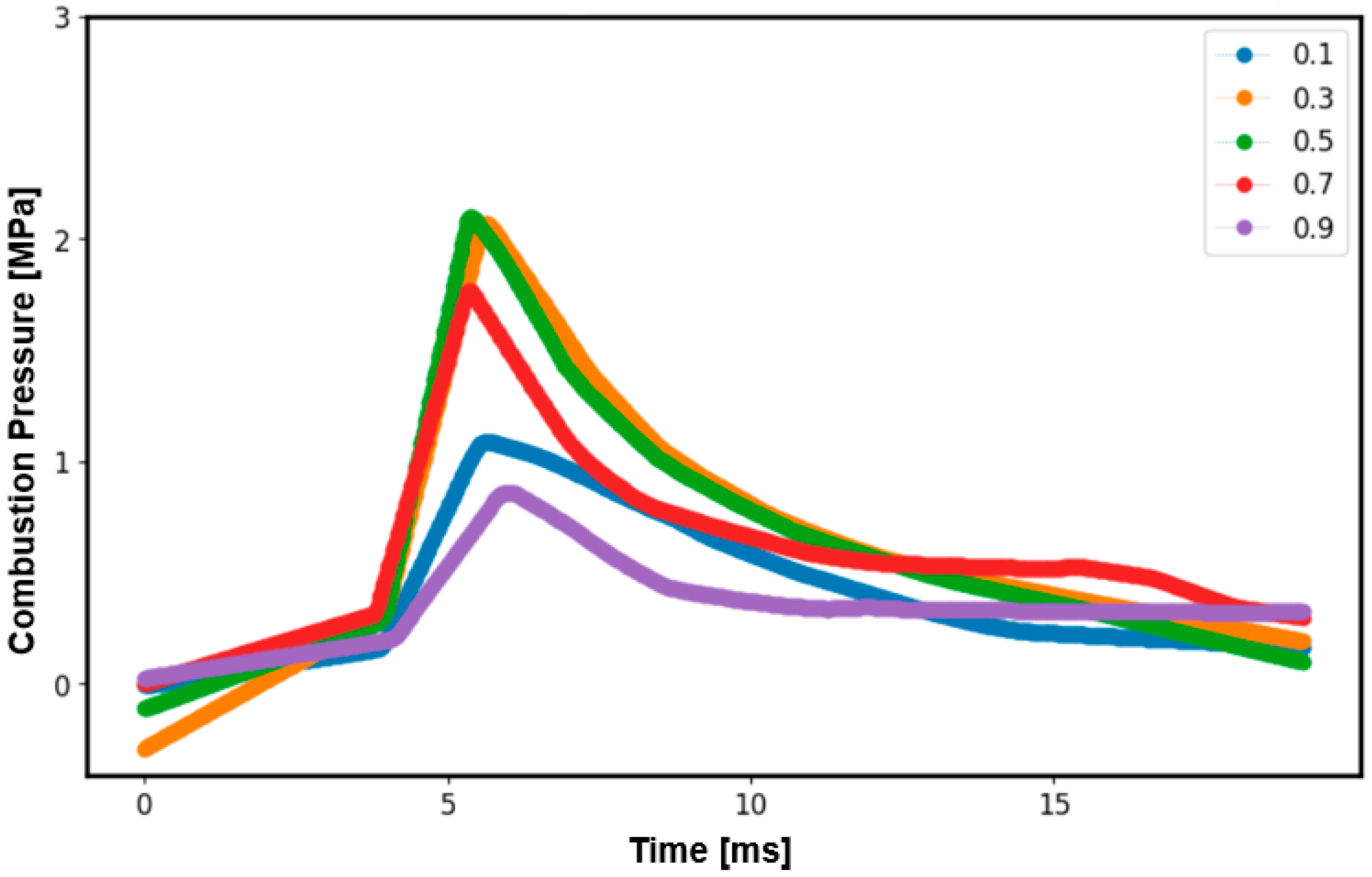
3.1. Experimental Results at Various Equivalence Ratios
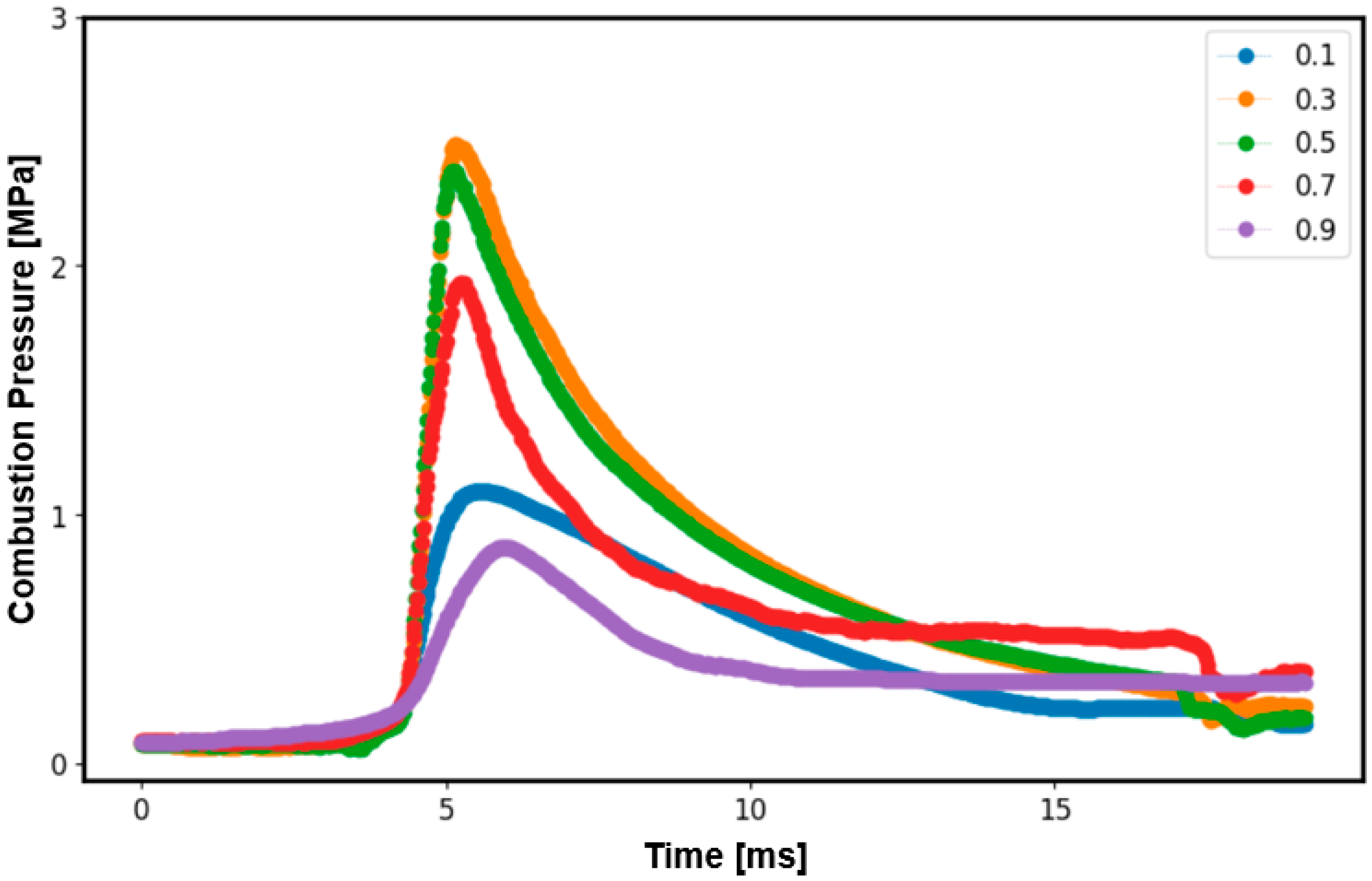
3.2. Predicted at Various Equivalence Ratios
3.3. Identification of the Overall Fit and Performance for Various Algorithms
4. Conclusions
- (a)
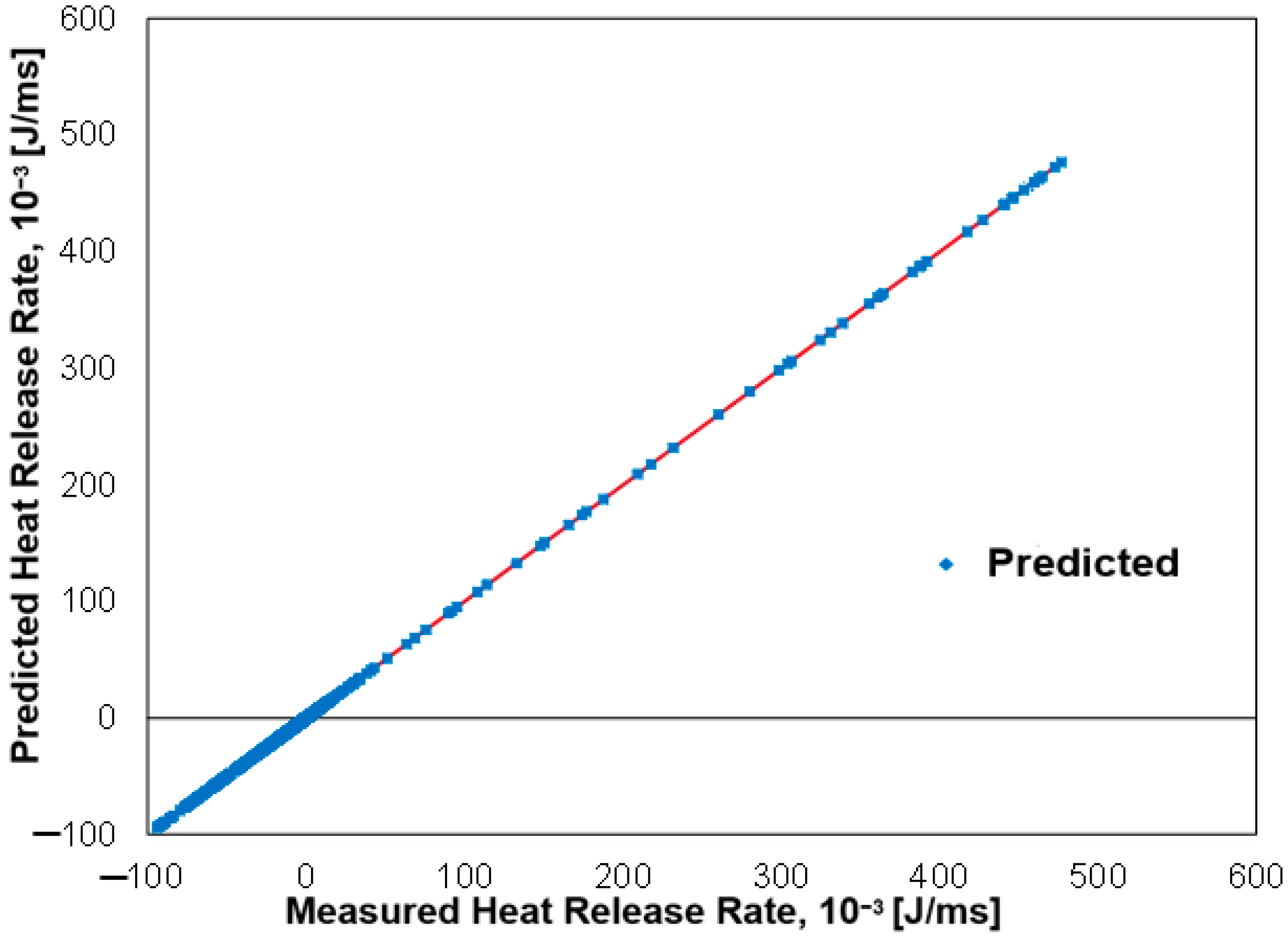
- In order to have confidence in machine learning algorithms, the authors evaluated both experimental and predicted heat release rates at an equivalence ratio of 0.4 and then compared each for error analysis, which was negligible.
- (b)
- As equivalence ratio plays a crucial role in combustion pressure, the analysis was carried out for those equivalence ratios which were skipped during the experimental analysis.
- (c)
- The maximum pressure induced during experimentation at an equivalence ratio of 0.4 was 2.50 MPa. However, in machine learning prediction, the values were 2.37 MPa and 2.48 MPa at equivalence ratios of 0.5 and 0.3, respectively.
- (d)
- The combustion pressure was evaluated using Random Forest and artificial neural network algorithms. However, the ANN algorithm illustrated a poor fit.
- (e)
- Finally, based on the RMSE and R2 values, the Linear Regression model appeared to have the best performance in machine learning with the ANN. In both the cases, it had the lowest RMSE and a perfect R2 value of 1.0, followed by Random Forest.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ministry of Land, Infrastructure, Transport and Tourism, Japan. Available online: https://theicct.org/chart-gfe-nedc-standards-aug20/ (accessed on 9 August 2021).
- Buruiana, D.L.; Sachelarie, A.; Butnaru, C.; Ghisman, V. Important Contributions to Reducing Nitrogen Oxide Emissions from Internal Combustion Engines. Int. J. Environ. Res. Public Health 2021, 18, 9075. [Google Scholar] [CrossRef] [PubMed]
- Xu, H.; Lee, U.; Wang, M. Life-cycle energy use and greenhouse gas emissions of palm fatty acid distillate derived renewable diesel. Renew. Sustain. Energy Rev. 2020, 134, 110144. [Google Scholar] [CrossRef]
- Agency for Natural Resources and Energy, Japan. Available online: https://www.enecho.meti.go.jp/statistics/electric_power/ep002/pdf/2020/0-2020.pdf (accessed on 10 August 2021).
- Koike, M.; Miyagawa, H.; Suzuoki, T.; Ogasawara, K. Ammonia as a Hydrogen Energy Carrier and Its Application to Internal Combustion Engines. J. Combust. Soc. Jpn. 2016, 58, 99–106. [Google Scholar] [CrossRef]
- Obreja, C.D.; Buruiana, D.L.; Mereuta, E.; Muresan, A.; Ceoromila, A.M.; Ghisman, V.; Axente, R.E. Detection of reed using cnn method and analysis of the dry reed (Phragmites australis) for a sustainable lake area. Plant Methods 2023, 19, 61. [Google Scholar] [CrossRef] [PubMed]
- Zou, H.; Chen, C.; Zha, M.; Zhou, K.; Xiao, R.; Feng, Y.; Qiu, L.; Zhang, X. A Neural Regression Model for Predicting Thermal Conductivity of CNT Nanofluids with Multiple Base Fluids. J. Therm. Sci. 2021, 30, 1908–1916. [Google Scholar] [CrossRef]
- Fang, X.; Papaioannou, N.; Leach, F.; Davy, M.H. On the application of artificial neural networks for the prediction of NOx emissions from a high-speed direct injection diesel engine. Int. J. Engine Res. 2021, 22, 1808–1824. [Google Scholar] [CrossRef]
- Mauro, A.D.; Chen, H.; Sick, V. Neural network prediction of cycle-to-cycle power variability in a spark-ignited internal combustion engine. Proc. Combust. Inst. 2019, 37, 4937–4944. [Google Scholar] [CrossRef]
- Hlaing, P.; Marquez, M.E.; Singh, E.; Almatrafi, F.; Houidi, M.B.; Johansson, B. Effect of Pre-Chamber Enrichment on Lean Burn Pre-Chamber Spark Ignition Combustion Concept with a Narrow-Throat Geometry. SAE Tech. Pap. 2020. [Google Scholar] [CrossRef]
- Jafarzadeh, H.; Karaman, C.; Güngör, A.; Karaman, O.; Show, P.; Sami, P.; Mehrizi, A.A. Hydrogen production via sodium borohydride hydrolysis catalyzed by cobalt ferrite anchored nitrogen-and sulfur co-doped graphene hybrid nano catalyst. Artificial neural network modeling approach. Chem. Eng. Res. Des. 2022, 183, 557–566. [Google Scholar] [CrossRef]
- Papaioannou, N.; Fang, X.; Leach, F.; Lewis, A.; Akehurst, S.; Turne, J.A. Random Forest Algorithmic Approach to Predicting Particulate Emissions from a Highly Boosted GDI Engine. SAE Tech. Pap. 2021. [Google Scholar] [CrossRef]
- Fang, L.; Singh, H.; Ichiyanagi, M.; Suzuki, T.; Raboaca, M.S.; Filote, C.; Verma, C. Prediction of Heat Energy Release Rate for Ammonia Combustion in a Constant Volume Combustion Chamber: A Machine Learning Approach. In Proceedings of the 2023 15th International Conference on Electronics, Computers and Artificial Intelligence (ECAI), Bucharest, Romania, 29–30 June 2023; pp. 1–4. [Google Scholar] [CrossRef]
- Smola, A.; Olkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef]
- Duda, R.O.; Hart, P.E.; Stork, G.S. Stork Pattern Classification; John Wiley & Sons: Hoboken, NJ, USA, 2000. [Google Scholar]
- Chung, W.T.; Mishra, A.A.; Perakis, N.; Ihme, M. Data-assisted combustion simulations with dynamic sub model assignment using random forests. Combust. Flame 2021, 227, 172–185. [Google Scholar] [CrossRef]
- Chayalakshmi, C.L.; Jangamshetti, D.S.; Savita, S. Multiple Linear Regression Analysis for Prediction of Boiler Losses and Boiler Efficiency. Int. J. Instrum. Control. Syst. (IJICS) 2018, 8, 1–9. [Google Scholar] [CrossRef]
- Yao, S.; Kronenburg, A.; Shamooni, A.; Stein, O.T.; Zhang, W. Gradient boosted decision trees for combustion chemistry integration. Appl. Energy Combust. Sci. 2022, 11, 100077. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Initial Pressure [MPa] | Initial Temperature [K] | Equivalence Ratio [-] |
|---|---|---|
| 0.2 | 298 | 0.2, 0.4, 0.6, 0.8, 1.0 |
| Equivalence Ratio [-] | Ammonia Pressure [MPa] | Oxygen Pressure [MPa] |
|---|---|---|
| 0.1 | 0.0235 | 0.129 |
| 0.2 | 0.0421 | 0.111 |
| 0.4 | 0.0696 | 0.083 |
| 0.6 | 0.0889 | 0.064 |
| 0.8 | 0.1032 | 0.050 |
| 1.0 | 0.1143 | 0.039 |
| 1.2 | 0.1231 | 0.030 |
| 1.4 | 0.1302 | 0.023 |
| Initial Pressure [MPa] | Initial Temperature [K] | Equivalence Ratio [-] |
|---|---|---|
| 0.2 | 298 | 0.3, 0.5, 0.7, 0.9 |
| Algorithm | R2 | RMSE |
|---|---|---|
| Random Forest | 0.9999947 | 0.0001636 |
| Gradient Boosting | 0.9999186 | 0.0025123 |
| Support Vector Machine | 0.9997530 | 0.0076229 |
| Linear Regression | 1.0 | 1.337 × 10−30 |
| Artificial Neural Network | 0.999588828 | 0.012686911 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, L.; Singh, H.; Ohashi, T.; Sanno, M.; Lin, G.; Yilmaz, E.; Ichiyanagi, M.; Suzuki, T. Effect of Machine Learning Algorithms on Prediction of In-Cylinder Combustion Pressure of Ammonia–Oxygen in a Constant-Volume Combustion Chamber. Energies 2024, 17, 746. https://doi.org/10.3390/en17030746
Fang L, Singh H, Ohashi T, Sanno M, Lin G, Yilmaz E, Ichiyanagi M, Suzuki T. Effect of Machine Learning Algorithms on Prediction of In-Cylinder Combustion Pressure of Ammonia–Oxygen in a Constant-Volume Combustion Chamber. Energies. 2024; 17(3):746. https://doi.org/10.3390/en17030746
Chicago/Turabian StyleFang, Lijia, Hardeep Singh, Takuma Ohashi, Masato Sanno, Guansen Lin, Emir Yilmaz, Mitsuhisa Ichiyanagi, and Takashi Suzuki. 2024. "Effect of Machine Learning Algorithms on Prediction of In-Cylinder Combustion Pressure of Ammonia–Oxygen in a Constant-Volume Combustion Chamber" Energies 17, no. 3: 746. https://doi.org/10.3390/en17030746