
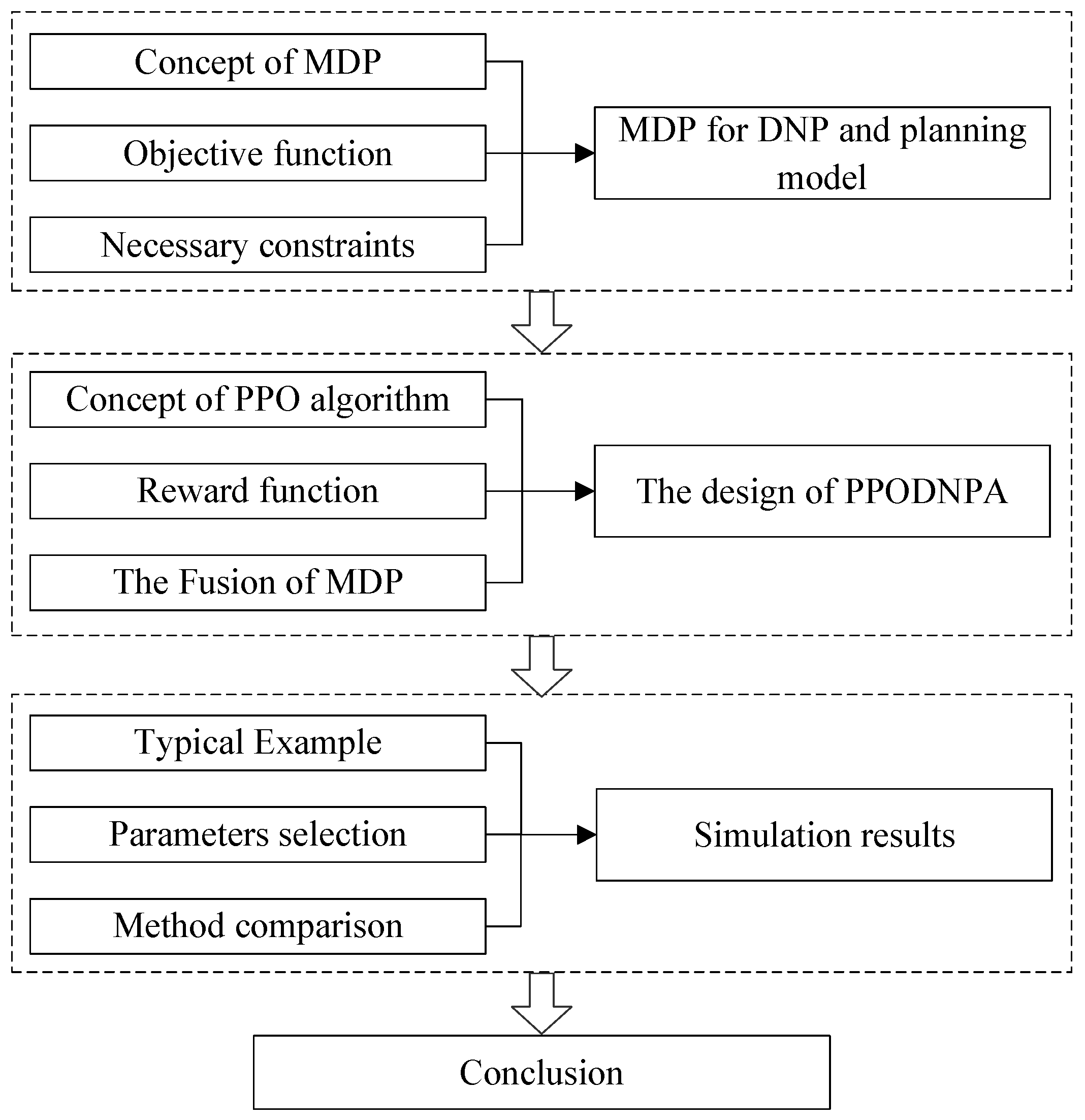
Deep Reinforcement Learning-Based Distribution Network Planning Method Considering Renewable Energy


Abstract
:1. Introduction
- (1)
- By designing the action space and state space, we construct a Markov decision process (MDP) for DNP. Through this transformation, the problem of DNP can thus be integrated into the DRL framework.
- (2)
- Considering line construction costs, voltage deviation, renewable energy subsidies, and electricity purchasing costs, a multi-objective optimization function is designed. Additionally, a multi-reward function is developed to guide the agent to learn the optimal policy. After sufficient training, the agent can generate optimized planning schemes.
- (3)
- Based on the AC architecture, a PPO-based DNP algorithm (PPODNPA) is designed. The actor network (AN) generates planning schemes upon receiving reward signals and environmental states, while the critic network (CN) further evaluates these schemes to optimize the AN, which achieves the autonomous generation and adaptive tuning of the planning scheme. Simulation results validate the superiority of the proposed algorithm.
2. MDP for DNP and Planning Model
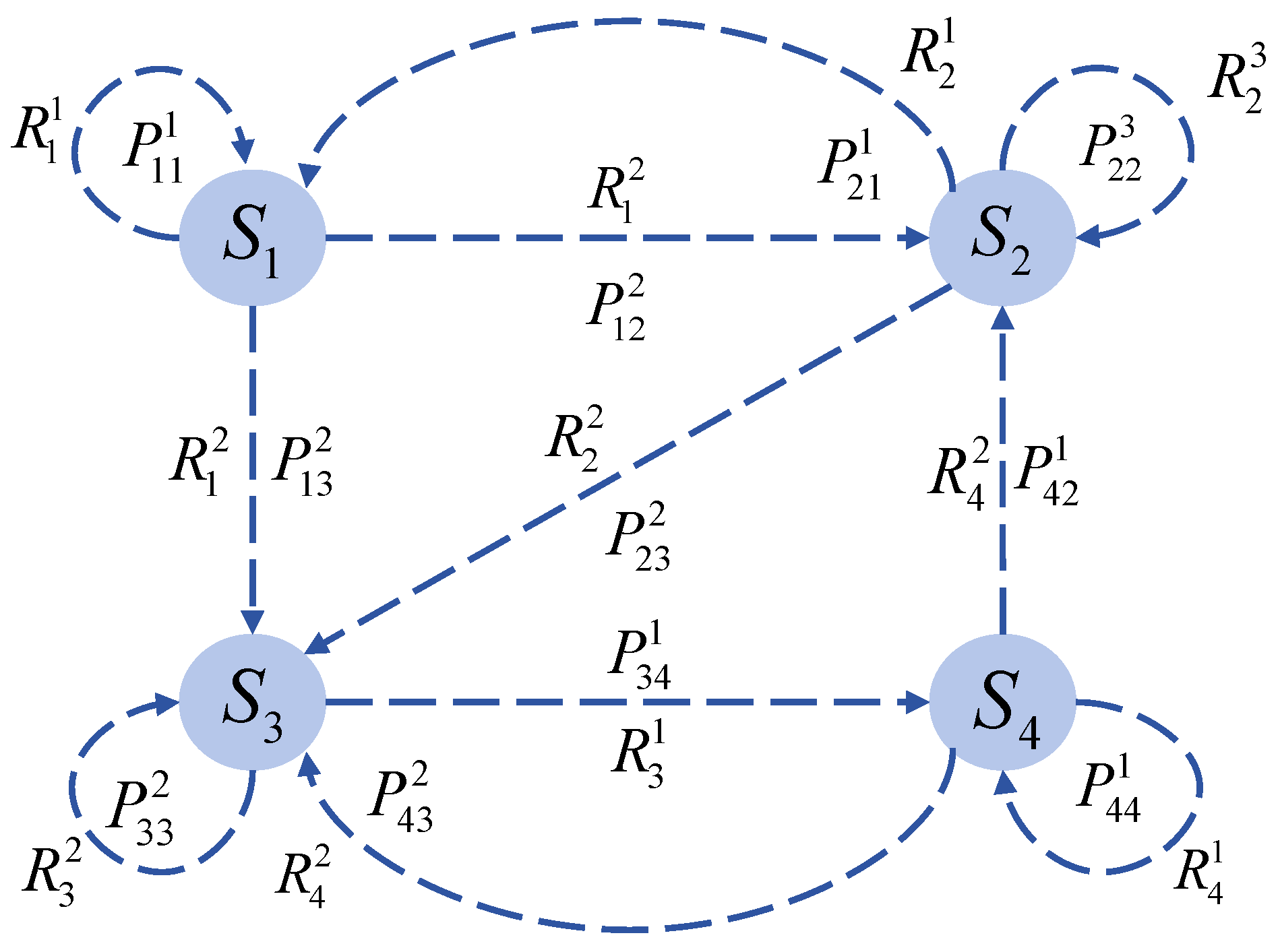
2.1. MDP for DNP
2.2. Planning Model
- (1)
- Power balance constraints [40]where is the voltage magnitude, and are the resistance and reactance, respectively. and are the active and reactive power flow, respectively. and are the output of the distributed generation and active load, respectively. and are the predicted wind power and curtailed wind power, respectively. and are the reactive power of diesel engines and the reactive load, respectively. Equation (4) ensures that the power flowing into each node balances the load, generation, and line losses, which reflects Kirchhoff’s current and voltage laws.
- (2)
- The line current constraint and voltage constraint are calculated as follows:where and are the maximum and minimum values of the current, respectively, which reflect the thermal limits of the overhead line and cable. and are the maximum and minimum values of the voltage, respectively, which ensure power quality. Considering Equation (5) can prevent the overheating of lines and maintain the node voltage within safe ranges.
- (3)
- The active power constraint is calculated as follows:where is the active power of the line and is the maximum active power. This constraint ensures that no line is influenced by real-power flows beyond its rated capability.
- (4)
- Line flow constraintswhere is the line flow, and is the maximum value of the line flow. Considering Equation (7) can limit the power flow to safe levels considering both real power and reactive power.
- (5)
- Radial grid constraintwhere n is the number of nodes in the distribution network, and m is the sum of the original and future lines. This constraint ensures a radial topology of grid structure, which is a common structural requirement in DNP.
3. The Design of the PPODNPA
3.1. PPO Algorithm
3.2. PPODNPA
| Algorithm 1 PPODNPA Algorithm Procedure |
|
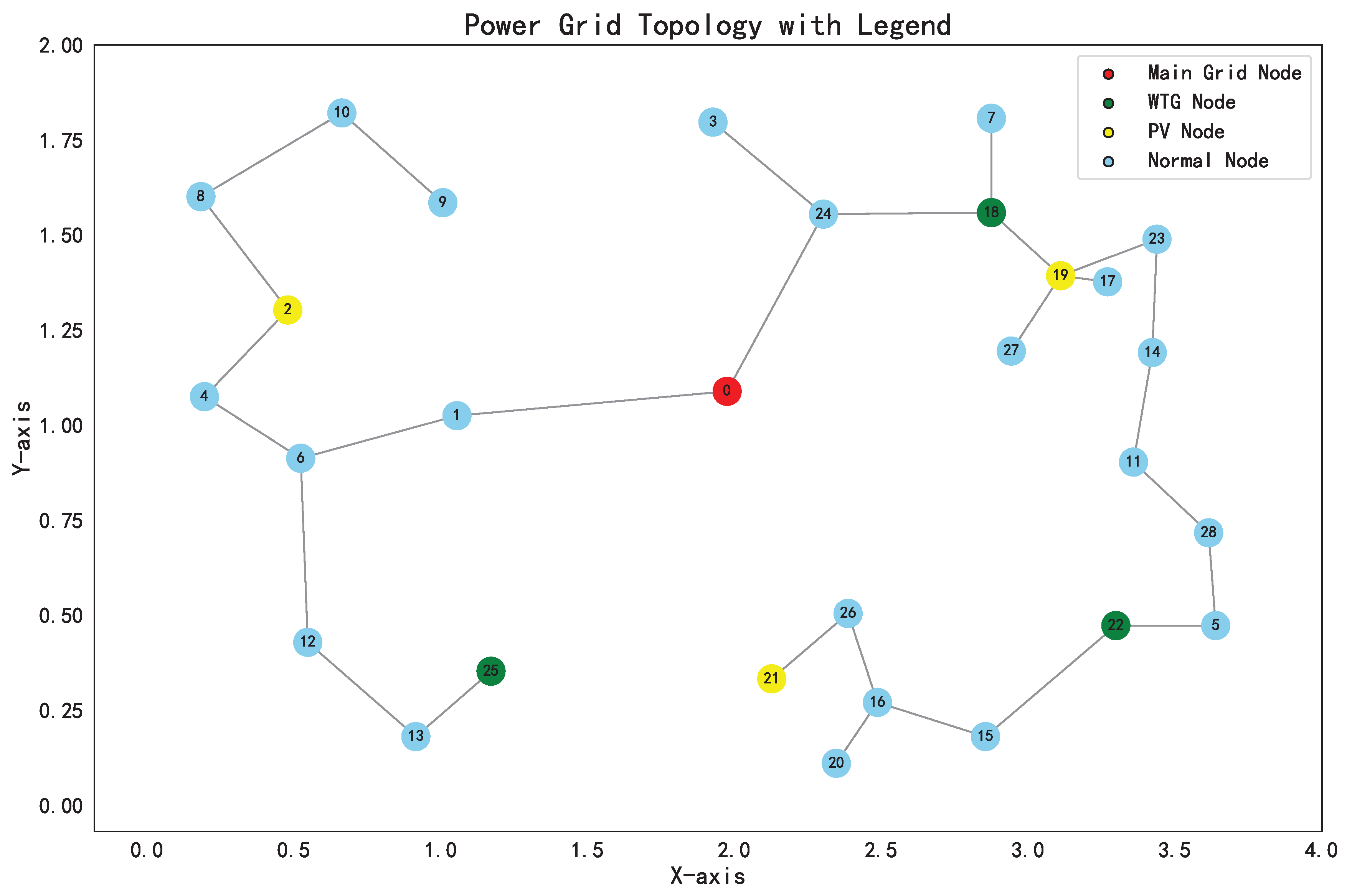
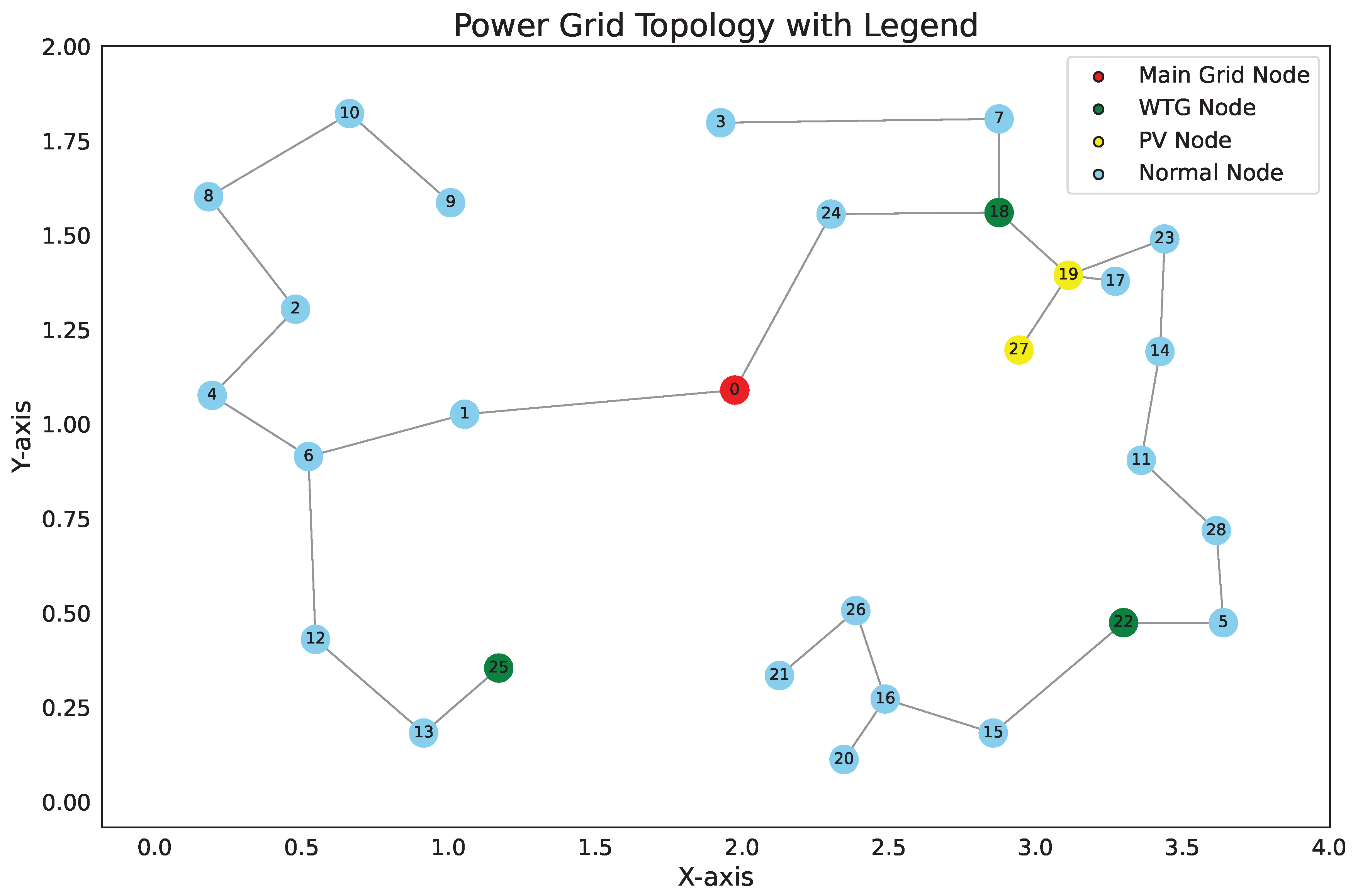
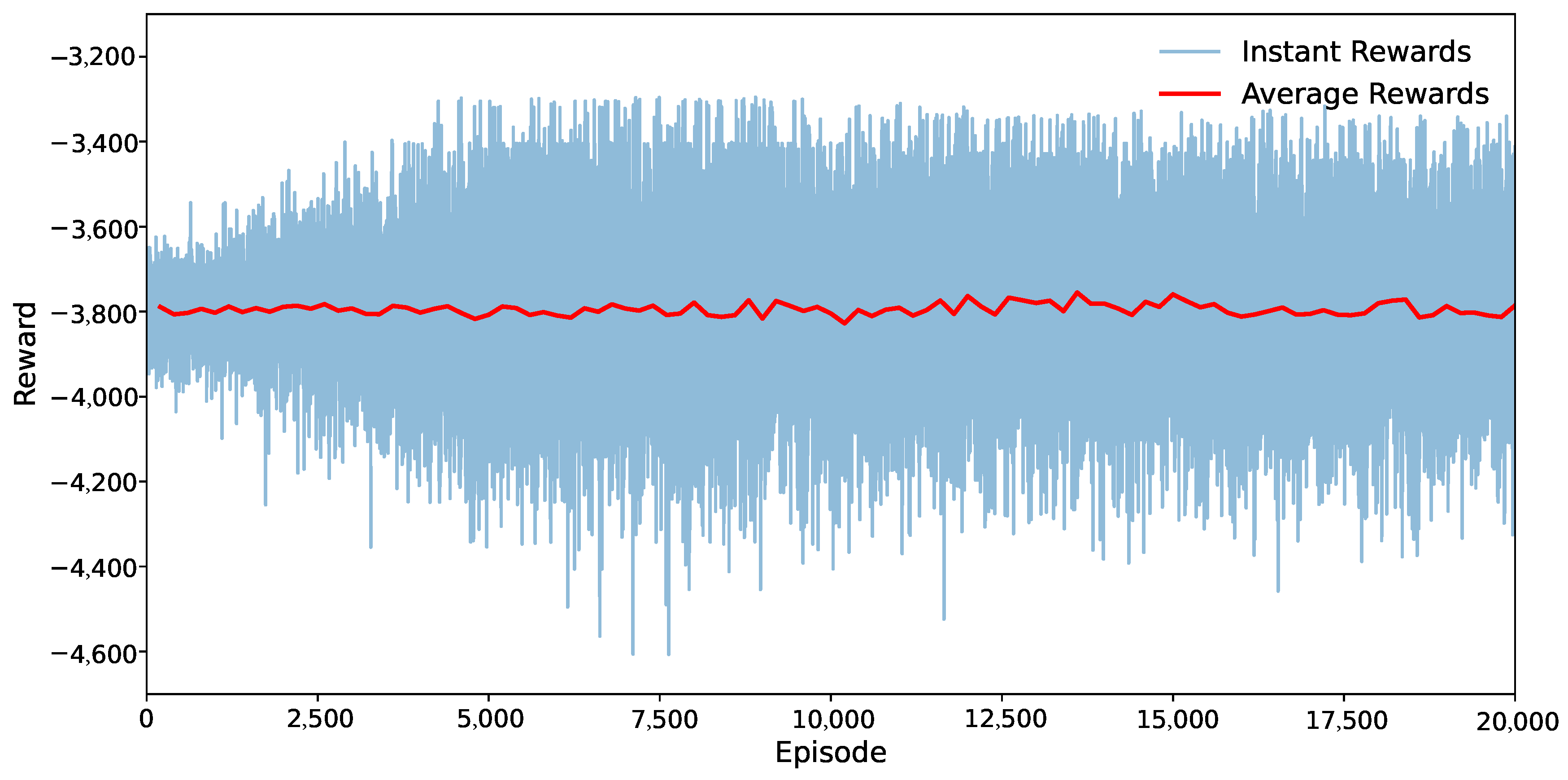
4. Simulation Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, P.; Yi, J.; Zangiabadi, M.; Lyons, P.; Taylor, P. Evaluation of voltage control approaches for future smart distribution networks. Energies 2017, 10, 1138. [Google Scholar] [CrossRef]
- Liao, H. Review on distribution network optimization under uncertainty. Energies 2019, 12, 3369. [Google Scholar] [CrossRef]
- Shen, X.; Shahidehpour, M.; Zhu, S.; Han, Y.; Zheng, J. Multi-stage planning of active distribution networks considering the co-optimization of operation strategies. IEEE Trans. Smart Grid 2018, 9, 1425–1433. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, Y.; Liang, D.; Kou, P.; Wang, Y.; Gao, Y. Local and remote cooperative control of hybrid distribution transformers integrating photovoltaics in active distribution networks. IEEE Trans. Sustain. Energy 2022, 13, 2012–2026. [Google Scholar] [CrossRef]
- Ding, T.; Liu, S.; Yuan, W.; Bie, Z.; Zeng, B. A two-stage robust reactive power optimization considering uncertain wind power integration in active distribution networks. IEEE Trans. Sustain. Energy 2015, 7, 301–311. [Google Scholar] [CrossRef]
- Pucuhuayla, F.; Correa, C.; Huatuco, D.; Rodriguez, Y. Optimal reconfiguration of electrical distribution networks using the improved simulated annealing algorithm with hybrid cooling (ISA-HC). Energies 2024, 17, 4477. [Google Scholar] [CrossRef]
- Cadenovic, R.; Jakus, D.; Sarajcev, P.; Vasilj, J. Optimal distribution network reconfiguration through integration of cycle-break and genetic algorithms. Energies 2018, 11, 1278. [Google Scholar] [CrossRef]
- Valderrama, D.; Alonso, J.; de Mora, C.; Robba, M. Scenario generation based on ant colony optimization for modelling stochastic variables in power systems. Energies 2024, 17, 5293. [Google Scholar] [CrossRef]
- Nahman, J.; Peric, D. Optimal planning of radial distribution networks by simulated annealing technique. IEEE Trans. Power Syst. 2008, 23, 790–795. [Google Scholar] [CrossRef]
- Jo, S.; Oh, J.; Lee, J.; Oh, S.; Moon, H.; Zhang, C.; Gadh, R.; Yoon, Y. Hybrid genetic algorithm with k-nearest neighbors for radial distribution network reconfiguration. IEEE Trans. Smart Grid 2024, 15, 2614–2624. [Google Scholar] [CrossRef]
- Falaghi, H.; Haghifam, M.; Singh, C. Ant colony optimization-based method for placement of sectionalizing switches in distribution networks using a fuzzy multiobjective approach. IEEE Trans. Power Del. 2009, 24, 268–276. [Google Scholar] [CrossRef]
- Harsh, P.; Das, D. A simple and fast heuristic approach for the reconfiguration of radial distribution networks. IEEE Trans. Power Syst. 2023, 38, 2939–2942. [Google Scholar] [CrossRef]
- Mazhari, S.; Monsef, H.; Romero, R. A hybrid heuristic and evolutionary algorithm for distribution substation planning. IEEE Syst. J. 2015, 9, 1396–1408. [Google Scholar] [CrossRef]
- Ahmadian, A.; Elkamel, A.; Mazouz, A. An improved hybrid particle swarm optimization and tabu search algorithm for expansion planning of large dimension electric distribution network. Energies 2019, 12, 3052. [Google Scholar] [CrossRef]
- Lu, D.; Li, W.; Zhang, L.; Fu, Q.; Jiao, Q.; Wang, K. Multi-objective optimization and reconstruction of distribution networks with distributed power sources based on an improved BPSO algorithm. Energies 2024, 17, 4877. [Google Scholar] [CrossRef]
- Martinez, M.; Mateo, C.; Gomez, T.; Alonso, B.; Frias, P. A hybrid particle swarm optimization approach for explicit flexibility procurement in distribution network planning. Int. J. Electr. Power Energy Syst. 2024, 161, 110215. [Google Scholar] [CrossRef]
- Moradi, M.; Abedini, M. A combination of genetic algorithm and particle swarm optimization for optimal DG location and sizing in distribution systems. Int. J. Electr. Power Energy Syst. 2012, 34, 66–74. [Google Scholar] [CrossRef]
- Yang, M.; Li, J.; Li, J.; Yuan, X.; Xu, J. Reconfiguration strategy for DC distribution network fault recovery based on hybrid particle swarm optimization. Energies 2021, 14, 7145. [Google Scholar] [CrossRef]
- Huang, C.; Bu, S.; Chen, W.; Wang, H.; Zhang, Y. Deep reinforcement learning-assisted federated learning for robust short-term load forecasting in electricity wholesale markets. IEEE Trans. Netw. Sci. Eng. 2024, 11, 5073–5086. [Google Scholar] [CrossRef]
- Hossain, R.; Huang, Q.; Huang, R. Graph convolutional network-based topology embedded deep reinforcement learning for voltage stability control. IEEE Trans. Power Syst. 2021, 36, 4848–4851. [Google Scholar] [CrossRef]
- Chen, Y.; Zhu, J.; Liu, Y.; Zhang, L.; Zhou, J. Distributed hierarchical deep reinforcement learning for large-scale grid emergency control. IEEE Trans. Power Syst. 2023, 39, 4446–4458. [Google Scholar] [CrossRef]
- Al-Ani, O.; Das, S. Reinforcement learning: Theory and applications in HEMS. Energies 2022, 15, 6392. [Google Scholar] [CrossRef]
- Toubeau, J.; Zad, B.; Hupez, M.; De Greve, Z.; Vallee, F. Deep reinforcement learning-based voltage control to deal with model uncertainties in distribution networks. Energies 2020, 13, 3928. [Google Scholar] [CrossRef]
- Yan, Z.; Xu, Y. A multi-agent deep reinforcement learning method for cooperative load frequency control of a multi-area power system. IEEE Trans. Power Syst. 2020, 35, 4599–4608. [Google Scholar] [CrossRef]
- Li, J.; Chen, S.; Wang, X.; Pu, T. Load shedding control strategy in power grid emergency state based on deep reinforcement learning. CSEE J. Power Energy 2021, 8, 1175–1182. [Google Scholar]
- Jin, J.; Xu, Y. Optimal policy characterization enhanced actor-critic approach for electric vehicle charging scheduling in a power distribution network. IEEE Trans. Smart Grid 2021, 12, 1416–1428. [Google Scholar] [CrossRef]
- Wang, R.; Bi, X.; Bu, S. Real-time coordination of dynamic network reconfiguration and volt-VAR control in active distribution network: A graph-aware deep reinforcement learning approach. IEEE Trans. Smart Grid 2024, 15, 3288–3302. [Google Scholar] [CrossRef]
- Wang, W.; Yu, N.; Gao, Y.; Shi, J. Safe off-policy deep reinforcement learning algorithm for volt-VAR control in power distribution systems. IEEE Trans. Smart Grid 2020, 11, 3008–3018. [Google Scholar] [CrossRef]
- Ruan, J.; Wu, C.; Liang, Z.; Liu, K.; Li, B.; Li, W.; Li, T. The application of machine learning-based energy management strategy in a multi-mode plug-in hybrid electric vehicle, part II: Deep deterministic policy gradient algorithm design for electric mode. Energy 2023, 269, 126972. [Google Scholar] [CrossRef]
- Zhang, J.; Li, Y.; Wu, Z.; Rong, C.; Wang, T.; Zhang, Z.; Zhou, S. Deep-reinforcement-learning-based two-timescale voltage control for distribution systems. Energies 2021, 14, 3540. [Google Scholar] [CrossRef]
- Zhu, Z.; Gao, X.; Bu, S.; Chan, K.; Zhou, B.; Xia, S. Cooperative dispatch of renewable-penetrated microgrids alliances using risk-sensitive reinforcement learning. IEEE Trans. Sustain. Energy 2024, 15, 2194–2208. [Google Scholar] [CrossRef]
- Qi, T.; Ye, C.; Zhao, Y.; Li, L.; Ding, Y. Deep reinforcement learning based charging scheduling for household electric vehicles in active distribution network. J. Mod. Power Syst. Clean Energy 2023, 11, 1890–1901. [Google Scholar] [CrossRef]
- Sun, X.; Han, S.; Wang, Y.; Shi, Y.; Liao, J.; Zheng, Z.; Wang, X.; Shi, P. Proximal policy optimization-based power grid structure optimization for reliable splitting. Energies 2024, 17, 834. [Google Scholar] [CrossRef]
- Fang, X.; Hong, P.; He, S.; Zhang, Y.; Tan, D. Multi-layer energy management and strategy learning for microgrids: A proximal policy optimization approach. Energies 2024, 17, 3990. [Google Scholar] [CrossRef]
- Meng, J.; Yang, F.; Peng, J.; Gao, F. A proximal policy optimization based control framework for flexible battery energy storage system. IEEE Trans. Energy Convers. 2024, 39, 1183–1191. [Google Scholar] [CrossRef]
- Wang, Y.; Qiu, D.; Wang, Y.; Sun, M.; Strbac, G. Graph learning-based voltage regulation in distribution networks with multi-microgrids. IEEE Trans. Power Syst. 2024, 39, 1881–1895. [Google Scholar] [CrossRef]
- Zhao, Y.; Liu, J.; Liu, X.; Yuan, K.; Ding, T. Enhancing the tolerance of voltage regulation to cyber contingencies via graph-based deep reinforcement learning. IEEE Trans. Power Syst. 2024, 39, 4661–4673. [Google Scholar] [CrossRef]
- Nie, Y.; Liu, J.; Liu, X.; Zhao, Y.; Ren, K.; Chen, C. Asynchronous multi-agent reinforcement learning-based framework for bi-level noncooperative game-theoretic demand response. IEEE Trans. Smart Grid 2024, 15, 5622–5637. [Google Scholar] [CrossRef]
- Tahir, I.; Nasir, A.; Algethami, A. Optimal control policergy management of a commercial bank. Energies 2022, 15, 2112. [Google Scholar] [CrossRef]
- Liang, Z.; Chung, C.; Zhang, W.; Wang, Q.; Lin, W.; Wang, C. Enabling high-efficiency economic dispatch of hybrid AC/DC networked microgrids: Steady-state convex bi-directional converter models. IEEE Trans. Smart Grid 2025, 16, 45–61. [Google Scholar] [CrossRef]
- Vlachogiannis, J.; Lee, K. A comparative study on particle swarm optimization for optimal steady-state performance of power systems. IEEE Trans. Power Syst. 2006, 21, 1718–1728. [Google Scholar] [CrossRef]
- Mohamed, A.; Berzoy, A.; Mohammed, O. Design and hardware implementation of FL-MPPT control of PV systems based on GA and small-signal analysis. IEEE Trans. Sustain. Energy 2017, 8, 279–290. [Google Scholar] [CrossRef]
- Priyadarshi, N.; Ramachandaramurthy, V.; Padmanaban, S.; Azam, F. An ant colony optimized MPPT for standalone hybrid PV-Wind power system with single cuk converter. Energies 2019, 12, 167. [Google Scholar] [CrossRef]
- Ye, H. Surrogate affine approximation based co-optimization of transactive flexibility, uncertainty, and energy. IEEE Trans. Power Syst. 2018, 33, 4084–4096. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
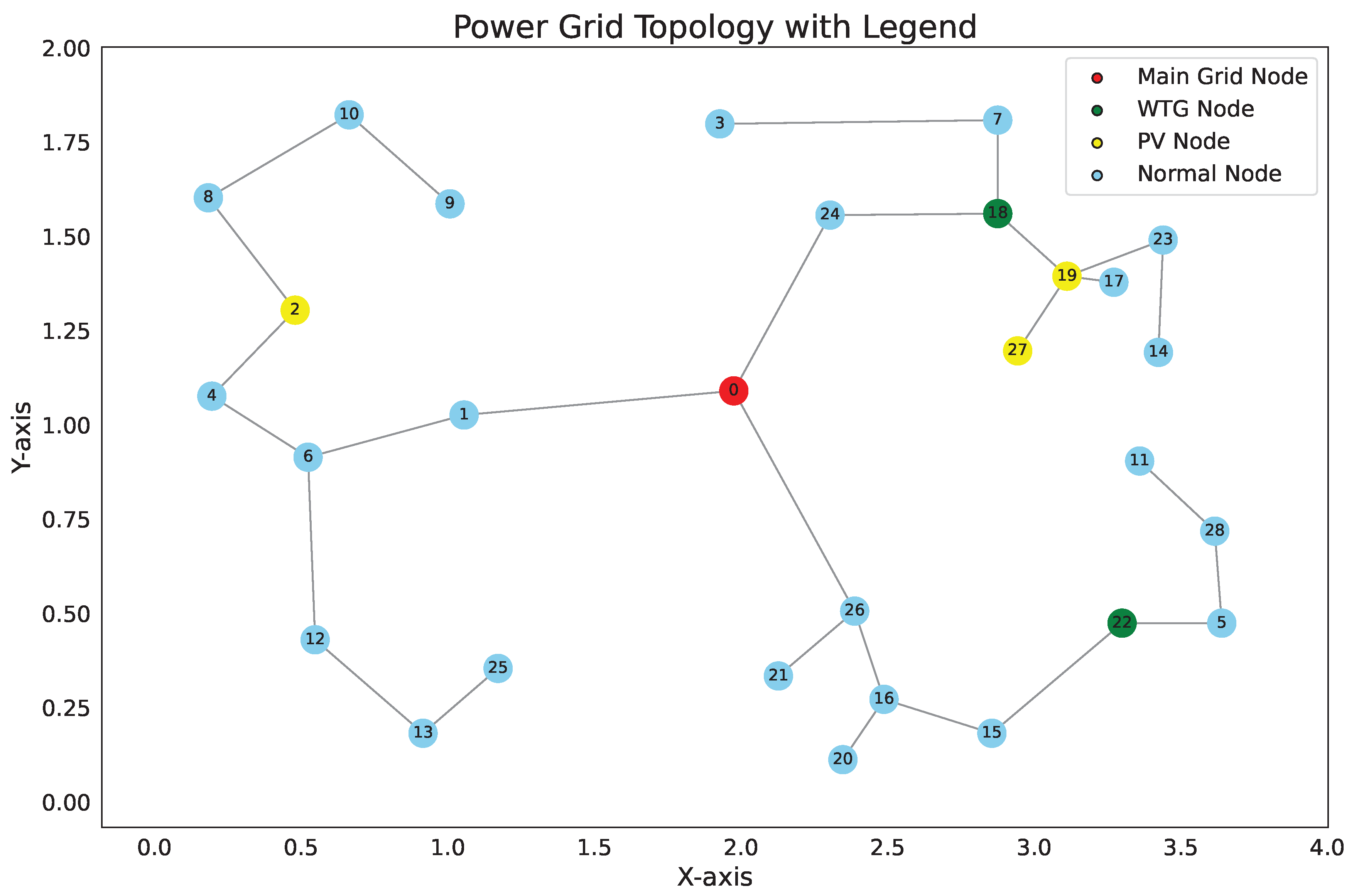
| Node Number | Node Coordinates/km | Active Load/kW | Reactive Load/kvar |
|---|---|---|---|
| 1 | (1.976, 1.090) | 0 | 0 |
| 2 | (1.056, 1.026) | 439.92 | 273.78 |
| 3 | (0.480, 1.304) | 421.20 | 262.08 |
| 4 | (1.928, 1.798) | 318.24 | 196.56 |
| 5 | (0.196, 1.076) | 430.56 | 266.76 |
| 6 | (3.640, 0.474) | 374.40 | 231.66 |
| 7 | (0.524, 0.914) | 402.48 | 250.38 |
| 8 | (2.876, 1.808) | 383.76 | 238.68 |
| 9 | (0.184, 1.602) | 570.96 | 353.34 |
| 10 | (1.008, 1.586) | 589.68 | 365.04 |
| 11 | (0.664, 1.822) | 421.20 | 262.08 |
| 12 | (3.360, 0.904) | 477.36 | 231.66 |
| 13 | (0.548, 0.430) | 580.32 | 360.36 |
| 14 | (0.916, 0.182) | 374.40 | 231.66 |
| 15 | (3.424, 1.192) | 458.64 | 285.48 |
| 16 | (2.856, 0.182) | 336.96 | 208.26 |
| 17 | (2.488, 0.272) | 402.48 | 250.38 |
| 18 | (3.272, 1.738) | 439.92 | 273.78 |
| 19 | (2.876, 1.560) | 402.48 | 250.38 |
| 20 | (3.112, 1.394) | 683.28 | 423.54 |
| 21 | (2.348, 0.112) | 449.28 | 278.46 |
| 22 | (2.128, 0.334) | 486.72 | 301.86 |
| 23 | (3.300, 0.474) | 318.24 | 196.56 |
| 24 | (3.440, 1.490) | 393.12 | 243.36 |
| 25 | (2.304, 1.556) | 276.12 | 170.82 |
| 26 | (1.172, 0.354) | 159.12 | 98.28 |
| 27 | (2.388, 0.506) | 313.56 | 194.22 |
| 28 | (2.944, 1.196) | 480.18 | 402.32 |
| 29 | (3.616, 0.718) | 159.12 | 98.28 |
| Method | LCC/million CNY | VD | EPC/CNY | RES/CNY |
|---|---|---|---|---|
| PPODNPA | 10.87 | 2.0744 | 78,857 | 16,320 |
| PSO | 11.37 | 2.3352 | 83,298 | 14,880 |
| GA | 11.83 | 0.5897 | 85,184 | 14,400 |
| ACO | 11.79 | 0.5105 | 77,620 | 15,840 |
| SAA | 12.05 | 0.3003 | 81,699 | 13,920 |
| DQN | 11.59 | 2.6364 | 96,241 | 9120 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, L.; Si, C.; Wang, K.; Luo, J.; Jiang, S.; Song, Y. Deep Reinforcement Learning-Based Distribution Network Planning Method Considering Renewable Energy. Energies 2025, 18, 1254. https://doi.org/10.3390/en18051254
Ma L, Si C, Wang K, Luo J, Jiang S, Song Y. Deep Reinforcement Learning-Based Distribution Network Planning Method Considering Renewable Energy. Energies. 2025; 18(5):1254. https://doi.org/10.3390/en18051254
Chicago/Turabian StyleMa, Liang, Chenyi Si, Ke Wang, Jinshan Luo, Shigong Jiang, and Yi Song. 2025. "Deep Reinforcement Learning-Based Distribution Network Planning Method Considering Renewable Energy" Energies 18, no. 5: 1254. https://doi.org/10.3390/en18051254
APA StyleMa, L., Si, C., Wang, K., Luo, J., Jiang, S., & Song, Y. (2025). Deep Reinforcement Learning-Based Distribution Network Planning Method Considering Renewable Energy. Energies, 18(5), 1254. https://doi.org/10.3390/en18051254