1. Introduction
In the current global context of the growing complexity of electricity markets, trying to predict electricity prices is essential for all market agents. However, this is not an easy task, since the price of electricity is far more volatile than other commodities. The presence of extremely high prices has been a recurrent phenomenon in markets worldwide. Nevertheless, the recent increasing deployment of non-dispatchable generation is also leading to the appearance of extremely low prices (zero or even negative prices depending on the considered regulatory framework).
This paper focuses on improving the understanding of the factors that contribute to the occurrence of these extreme price events and also their accurate forecasting with a medium-term scope. More specifically, the aim of this paper is to propose a novel methodology that allows one to predict not only the expected number of hours with very low prices in the medium term, but also the associated probability density function. The proposed methodology relies on a thorough in-sample analysis to adjust the models and an out-sample simulation approach to test its performance when making real ex ante forecasts.
The covered time horizon is from one month up to one year. In general, retailers and large consumers need reliable medium-term predictions to optimize their operation, as well as to properly negotiate in the short-term market and accomplish beneficial bilateral contracts. In addition, producers need medium-term predictions to optimize their generation programs and negotiate favorable bilateral and financial contracts. On the other hand, it is essential to anticipate the occurrence of these abnormally low priced hours, because this situation significantly increases the exposure of industry participants to price risk. Even in extreme cases, these unanticipated large changes in the spot price can lead to bankruptcies of energy companies if they are not prepared to tackle such risks. For this reason, an effective risk management support for the operation of electrical systems must also be able to foresee extremely low values.
The proposed methodology, which is currently in operation in one of the major Spanish electricity companies, is tested in a real case: the Spanish electricity market. The Spanish electricity market constitutes one of the most interesting cases in which the remarkable growth of renewable energy production frequently pushes the most expensive thermal power stations outside the generation program of the wholesale market. The consequent reduction in thermal production, coupled with a decline in the demand curve (especially in off-peak hours) due to the financial crisis and a low interconnection capacity to evacuate the surplus of non-dispatchableenergy, causes at certain times a sharp reduction in the clearing price. Apart from the oversupply of generation technologies with zero opportunity cost (renewable energy sources (RES), run-of-the-river hydro and nuclear), an excess of gas (due to take or pay clauses) can make combined cycles have zero opportunity cost. The conjunction of these events causes the emergence of a scenario in which the matching of supply and demand is occurring at 0 €/MWh (note that in Spain, unlike other countries, such as Australia and Germany, negative prices are not allowed).
The main contributions of this paper can be summarized as follows:
A general methodology has been developed to make real ex ante forecasts (point and probabilistic) of extremely low prices for a mid-term horizon on an hourly basis. The methodology combines different forecasting methods and spatial interpolation techniques within a Monte Carlo simulation of multiple predicted scenarios for the considered risk factors.
The accuracy of a novel hybrid approach that integrates fundamental and behavioral information, logistic regressions, decision trees and multilayer perceptrons has been compared to the results obtained by means of a traditional Markov regime switching model and different naive methods. This comprehensive comparison has been carried out in both in-sample and out-of-sample datasets. It has also been examined if the use of periodic models helps to improve prediction capabilities.
The performance of the proposed methodology has been tested in a real-sized electricity system. Note that the empirical application presented in this paper is in a single price market that does not incorporate distribution network constraints in the market clearance. In the Spanish electricity market, the high complexity of the electricity price dynamics is mainly due to the huge penetration of renewable energy sources in the generation mix and the limited interconnection capacity with France. These aspects have been taken into account in all of the forecasting models presented in this paper. However, in order to extend the methodology to other markets, where locational marginal prices may exist, and for which this methodology could be applicable, the impact of variables related to local distributed generation should be taken into account (as [
1] investigates in the electrical system in Italy). In this sense, another paper that presents the influence of distributed generation (DG) on congestion and locational marginal price (LMP) is [
2].
The paper is structured as follows. After a state of the art review,
Section 3 describes the methodology developed in the paper.
Section 4 introduces the proposed forecasting techniques, as well as the in-sample results obtained. In
Section 5, the case study and the real
ex ante forecasting results are presented. Finally, the conclusions and the main contributions of the paper are summarized in
Section 6.
2. Previous Work
Diverse models have been proposed in the literature to forecast electricity prices with different aims and time horizons. The wide number of forecasting techniques is likely to be grouped by various criteria that have been proposed in several studies [
3,
4]. According to [
5], electricity price forecasting models include statistical and non-statistical models. The latter group, which is classified in more detail in [
6], comprehends simulation models and equilibrium analysis models [
7]. These approaches are preferred in a medium- to long-term horizon, as they can provide price predictions even when there are structural or regulatory changes in the market. However, as they are highly demanding computationally, they tend to group hours of similar characteristics. The latter makes that the forecasts not be as accurate as data-driven methods [
8]. On the other hand, statistical methods, which rely on historical data, are useful for short-term price forecasting, but they degrade when are used for medium- or long-term horizons [
9]. They include time series models and artificial intelligence techniques.
A great number of time series models has been successfully implemented. In this way, the ARIMA (autoregressive integrated moving average) models are the most representative, with different particularizations. Thus, there are references that accommodate the seasonality using the same set of parameters for all hours of the day [
10,
11]; and others that perform ARIMA model fitting (or its variants, AR or ARMA) for each time slot of the day [
12,
13]. Other generalizations of the ARIMA models are the so-called linear transfer function or transfer function models with ARIMA noise [
14,
15], which have the peculiarity of including past and present influence of other series. Other kinds of time series are the multiple-input multiple-output models, which predict the n-dimensional price vector in a single step [
16]. Artificial intelligence techniques, which can be classified into artificial neural networks (ANN) [
17], fuzzy logic and their combination, the neuro-fuzzy method [
18], are more powerful for complex, nonlinear time series analysis than the rest of the statistical models. The methods presented before show a considerable ability to forecast the expected electricity prices under normal market conditions. So far, however, none of these techniques can effectively deal with spikes or extreme prices in electricity markets [
19]. Among the first references that address these specific features of electricity prices is [
20], where spikes are modeled by introducing large positive jumps together with a high speed of mean reversion. Other authors model spikes by allowing signed jumps [
21]. According to [
22], spike forecasting techniques can be classified into traditional and non-traditional approaches. Traditional approaches fall, broadly speaking, into three categories: (i) traditional autoregressive time series models; (ii) nonlinear time series models with particular emphasis on Markov-switching models; and (iii) continuous-time diffusion or jump diffusion models. Non-traditional approaches include artificial neural networks or other data-mining techniques.
Traditional autoregressive time series models treat spikes through Poisson and Bernoulli jump processes [
23], the inclusion of thresholds [
24] or the use of different multivariate error distributions [
16]. Meanwhile, regime-switching models are the nonlinear extension of traditional time series. These models are capable of identifying the nonlinearities of the dynamics and distinguish the normal chaotic motion from the turbulent and spike regime. One of the most representative model of this class is the threshold autoregressive (TAR) one, which determines the regime by the value of an observable variable corresponding to a threshold value. In the case of including exogenous (fundamental) variables, TAR processes lead to the TARX model. An alternative is the self-exciting threshold autoregressive (SETAR) model, which arises when the threshold variable is taken as the lagged value of the price series itself [
25]. Markov switching models are the most prominent among those in which the switching mechanism between the states cannot be determined by an observable variable. For the treatment of spikes, they suggest different states in which at least one is consistent with its appearance [
26]. With regard to continuous-time diffusion processes, spikes are essentially captured by the combination of a Poisson jump component and an intensity parameter. This parameter can be constant [
27] or can be driven by deterministic seasonal variables [
28]. Recently, in [
22], a nonlinear variant of the autoregressive conditional hazard model has been used to estimate the probability of a spike with a short-term horizon, and in [
29], a spike component is predicted in the short term using a linear approximation based on consumption and wind.
Some other approaches are based on the namely nontraditional techniques, which include: decision trees and rule-based approaches; probability methods, such as Bayesian classifiers [
30]; neural network (NN) methods, such as spiking NN [
31]; example-based methods, such as k-nearest neighbors [
19,
32]; and SVM (support vector machine) [
33].
To the best knowledge of the authors, no references have been published dealing with the problem of medium-term price spikes or extreme price forecasting. The proposed work is unique in the sense that it proposes to use several forecasting techniques for making both point and probabilistic medium-term prediction of extremely low prices with an hourly accuracy.
3. Methodology
Essentially, the steps of the methodology suggested in this paper are the following:
The choice of a threshold to define what is considered as an extreme low price event. This point is discussed in depth in
Section 3.2. It is important to point out that the methodology is not materially affected by the choice of the threshold.
The selection of explanatory variables that contribute to explain the phenomenon of the emergence of very low prices from a perspective that takes into account the market behavior and their statistical significance. This is further discussed in
Section 3.3.
The adjustment of a forecasting technique for predicting the occurrence of extremely low variables in terms of a probability value from actual market data (in-sample dataset). In
Section 4, we detail all of the forecasting techniques that have been used and calibrated for this purpose. Due to the fact that in our study, the dependent variable (occurrence of extremely low prices) is dichotomous in nature, the potential models to apply for the analysis are restricted to binary choice models. The proposed models classify observations based on a cutoff value. If the probability predicted by the model is greater than this cutoff value, the observation will be classified as a normal price. Otherwise, it will be deemed as an extremely low price. The choice of this cutoff point is discretional, and it will influence the sensitivity and specificity, which vary inversely with the probability value chosen. These statistics, as well as the rest of the Cooper statistics [
34], can be calculated from a contingency table (
Table 1) as shown in
Table 2. In this paper, the cutoff point was chosen so as to provide a balance between sensitivity and positive predictivity (
i.e., a failure to predict an actual extremely low price is penalized as heavily as a false alarm). As a result of this step, the parameters and the optimal cutoff value for each forecasting technique are obtained and will be used in the following stage.
The development of probabilistic real
ex ante forecasts through cross scenario analysis, which is the basis of
Section 5. In order to use Monte Carlo simulation to tackle uncertainty in the medium term, a large number of realizations of the model are needed, usually entailing a huge computational time and effort. In order to cope with this inconvenience, we have adapted an efficient method proposed in [
35] for making market equilibrium models tractable (a practical implementation can be also found in [
7]) to other forecasting techniques. This method, which is illustrated schematically in
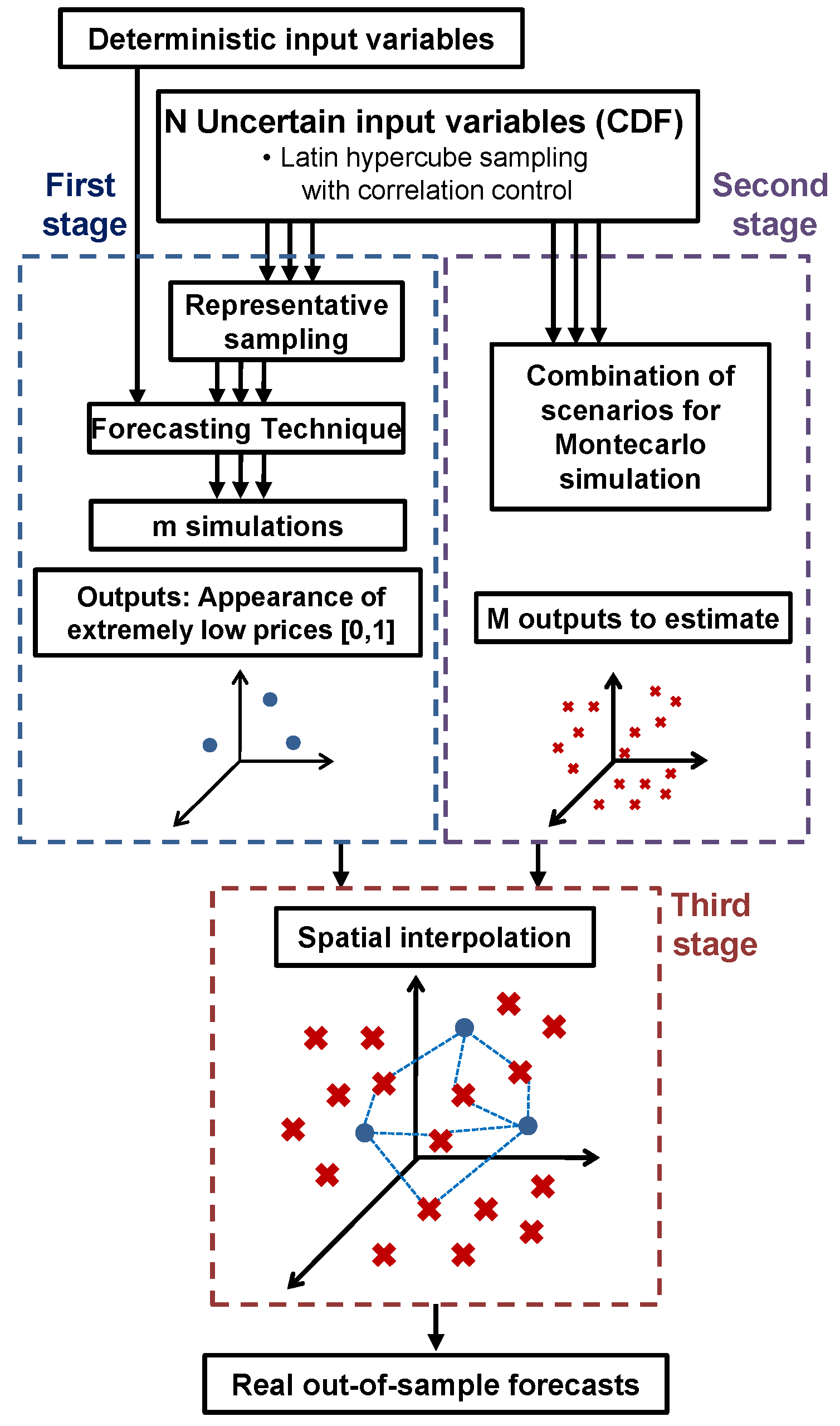
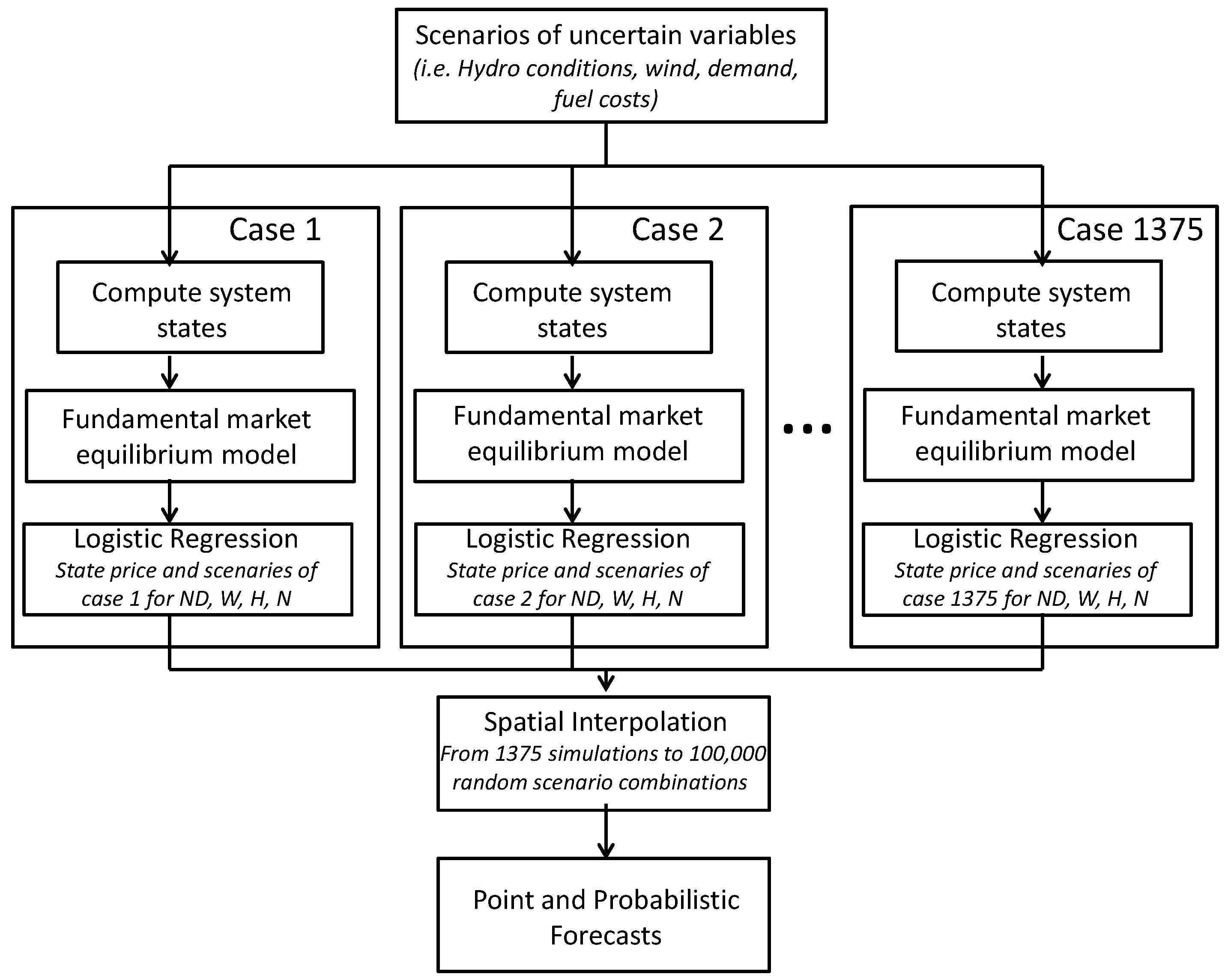
Figure 1, allows one to compute a huge number of simulations by decreasing the computational time and without a major loss of accuracy. As can be seen in the figure, the first step of the methodology consists of computing a reduced number of executions (m simulations) of each of the proposed forecasting models. As a result, we obtain m result matrices about the appearance or not of extremely low prices (the classification is made with the cutoff value previously estimated) in each specific hour of the simulation time horizon. These initial m simulations of the model are spatially placed in a hypercube of N dimensions according to the combinations of scenarios. More specifically, each dimension of the hypercube corresponds to an uncertain variable. For the sake of clarity, N is equal to three in
Figure 1. Note that each risk factor is distinguished by its cumulative distribution function (CDF), and a particular scenario is defined by the pertinent percentiles of the considered risk factors. Latin hypercube sampling with correlation control techniques has been used with the aim of having a well-sampled hypercube in which each scenario is used at least once in the m executions of the statistical models. In the second stage, a vast amount (M >> m) of correlated random scenario combinations of the risk factors is generated to establish those unobserved areas of the hypercube. Here, the correlation structure between the variables is determined by using historical data. In the third step, these unsimulated areas (M feasible matrices about the appearance of extremely low prices) of the hypercube are interpolated from the initial executions by means of an interpolator based on local regression that considers the spatial structure of these initial executions. Finally, as the scenario definition is random and considers the correlation structure between the uncertain variables, all of the scenarios can be considered to be equally probable, and thus, it is possible to make both point and probabilistic forecasts of the variables of interest.
3.1. The Times Series Dataset
In this paper, a dataset from the Spanish day-ahead market, which comprises the period ranging between 1 January 2009 and 31 March 2012, is used. This period has been chosen because it is the moment that marked the inflexion point in relation to the appearance of extremely low prices in the Spanish market. However, the methodology would be equally extrapolated to other subsequent time periods. The complete data consisted of hourly spot prices and the actual production for each technology. The data corresponding to the Spanish market are available from the Iberian Energy Market Operator (OMIE [
54]).
In order to thoroughly investigate the forecasting capability of each model, the data were divided into in-sample and out-of-sample datasets. The former set, which includes the training and testing sets, encompasses from 1 January 2009–30 November 2011. Thus, in
Section 4, the generalization capabilities of the models with the actual data of the exogenous variables are carried out. In
Section 5, an out-of-sample analysis for the period ranging between 1 December 2011 and 31 March 2012 with estimated scenarios of the explanatory variables is conducted. As no major structural or regulatory changes occurred during this period, it can be possible to capture the price dynamics by using a common statistical model.
A more detailed statistical analysis of the in-sample dataset is presented in
Table 3. As noted, the distribution of electricity prices is not normal, presenting excess kurtosis and negative skewness. This means that excessively high or low prices have a higher probability of occurrence than in the case of a normal distribution. Moreover, prices below the average are more likely to occur than prices above the mean value.
3.2. Extremely Low Prices Threshold
Due to the fact that market agents are not only interested in trying to model the incidence of zero prices, the objective of this section is the choice of a threshold for distinguishing extremely low prices from the rest. There are several approaches in the literature to classify whether an observation is extreme or not [
36,
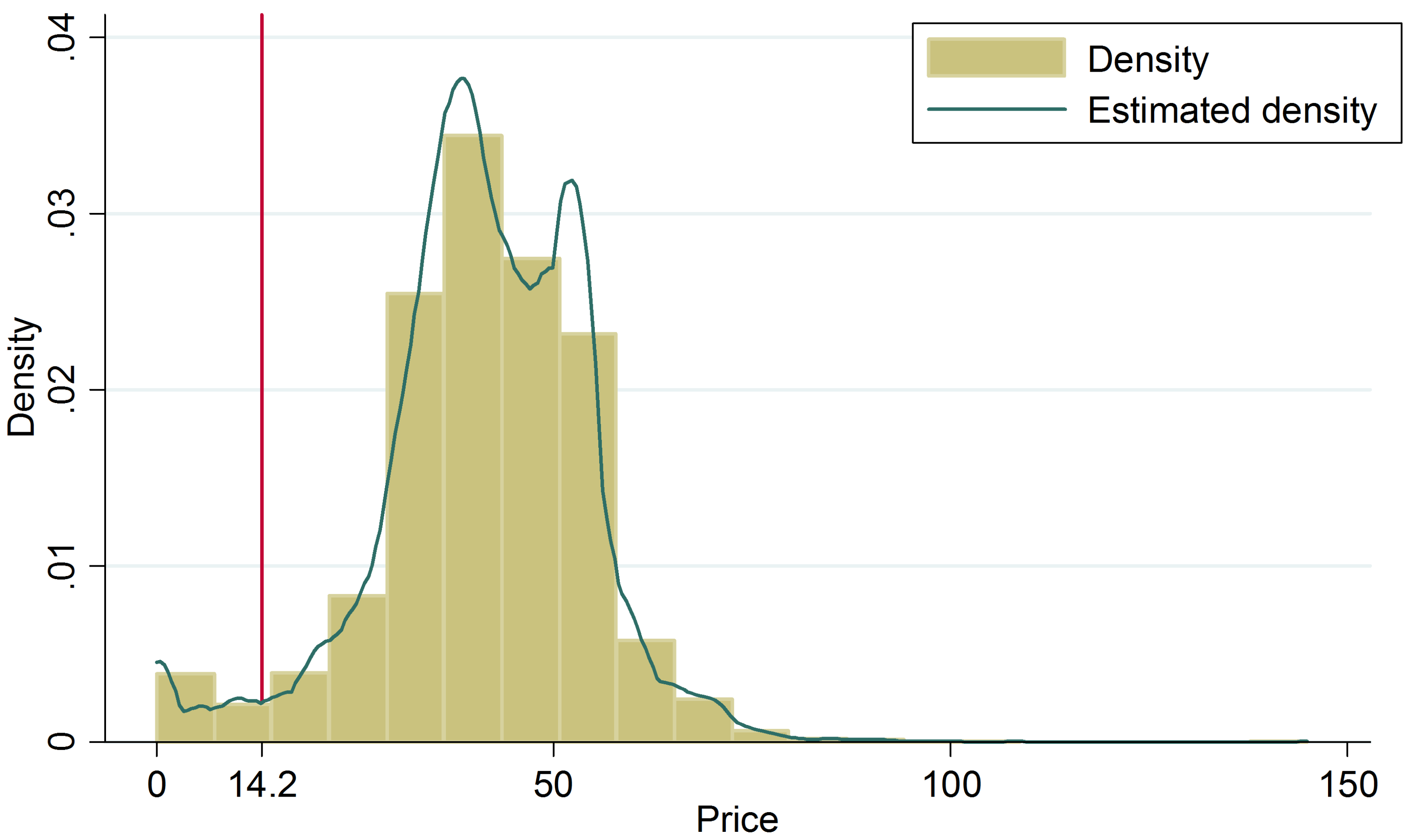
37]. In fact, the choice of a reasonable threshold is still a subjective choice. In Spain, for instance, the threshold defining an extreme low price event is generally regarded between 10 and 15 €/MWh. In this article, a point of the characteristic modes of the distribution function has been used. In order to estimate the probability density function, the Epanechnikov kernel, which minimizes the asymptotic mean integrated squared error, has been used.
Figure 2 illustrates a graphical representation of the distribution function. This representation enables one to derive a threshold of 14.2 €/MWh. This point, which lies below the 5th percentile of the the unconditional distribution of the price series, fulfills two features. On the one hand, it is an inflection point of the density function on the left tail. On the other hand, it is a point that is away from the average a distance of more than two standard deviations. The last premise is consistent with that adopted in [
19]. It should be noted that the methodology is not restricted by the choice of the threshold. The resulting indicator variable is coded 0 for extremely low prices and 1 for the remainder prices.
3.3. Explanatory Variables
Several studies have been conducted in order to detail the explanatory variables affecting spot market prices [
28,
38,
39,
40] and price spikes [
41]. However, none of these references focus on the appearance of extremely low priced hours in the medium term. Therefore, in this paper, a critical point is not only the choice of the variables that help to better explain the aforementioned phenomenon, but also those factors that allow one to operationalize the forecasting model in a feasible way. This entails that it is possible to use only those variables that can be characterized with a reasonable accuracy at this medium-term time horizon. This is, for instance, the case of technologies that usually behave as price takers.
In the particular case of Spain, where most of the electricity is priced at the day-ahead hourly market, the price is set by the marginal generator bid. Among the power plants with the lowest short-opportunity costs are renewable energy sources (RES), nuclear and run-of-the-river hydro. On the contrary, the plants with the highest opportunity costs are gas, coal, head-dependent hydro and fuel oil. During the horizon of the study, RES were legislated under what was referred to as a special regime, promoted through a feed-in tariff system. Thus, apart from the special regime, the technologies that usually behave as price takers are run-of-the-river hydro and nuclear. Due to the zero variable cost of the former and the inflexibility of the latter, both of them usually bid at low prices to collect then the marginal price. It should be noted that it is well known that hydro conditions are one of the most important sources of uncertainty in the Spanish market. In this study, run-of-the-river hydro production has been considered as a reasonable approach for hydro conditions. This is because, run-of-the-river hydro production, unlike head-dependent hydro, behaves as a price taker, and therefore, it is expected to be relevant for the appearance of extremely low prices.
The selection of explanatory variables, which has been done taking into account the principle of parsimony, was based on backward elimination methods, which evaluate different statistics in order to control the exit of variables. Thus, the adjusted coefficient of determination and several model selection criteria (such as AIC and BIC) were measured.
Before constructing the proposed models, the presence of unit roots in the candidates for exogenous variables has been tested. To this end, augmented Dickey–Fuller has been used. For all considered explanatory variables, the absence of stationarity was strongly rejected beyond a 5% significance level. The absence of multicollinearity between the regressors has also been confirmed by applying the variance inflation factor.
4. Forecasting Techniques
The main target of this section is to compare several novel models with one of the most prominent models used in the prediction of spikes: Markov regime-switching models. In order to estimate their generalization capabilities, the in-sample data were divided into two different sets: 80% for training and 20% for testing. The validation set comprises the training and testing sets (from 1 January 2009–30 November 2011). Note that this section analyzes the models’ generalization capabilities with actual data of the exogenous variables.
It is well known that electricity prices exhibit seasonal fluctuations, which can be collected by including relevant explanatory variables. Still, despite a well-specified inclusion of demand in the models that could explain the weekly effects, a separate modeling for (1) working days, (2) Saturdays and (3) Sundays and holidays has also been carried out with the aim of testing if the forecasting performance is improved. The main benefit of this approach, which uses periodic models, is that it allows the model parameters to switch according to the different behaviors identified in the course of the week. Moreover, the construction of separate models has the advantage of selecting an optimum and specific threshold value for classifying an observation as a very low price or not depending on the predicted likelihood given by the statistical technique used in each case. This could be particularly relevant for the accuracy of the forecasts.
4.1. Logistic Regression
Logistic regression is a well-known supervised learning algorithm that can allow us to estimate the probability of the occurrence of extremely low prices, which is a dichotomous outcome. This technique is very useful to analyze the potential impact of the independent variables on the dependent variable. For each constructed model, the estimated coefficients of the explanatory variables are also shown. The Wald test was utilized to check their validity. The models goodness-of-fit is checked by means of the Cox and Snell R square and the Nagelkerke R square.
4.1.1. Model 1
As has been shown previously, the addressed classification problem is unbalanced with a proportion of hours with very low prices only accounting for 4.32%. For this reason, a model based on the traditional logistic regression procedures could sharply underestimate the probability of this rare event, and therefore, it could lead to erroneous results. One of the most popular techniques to correct these effects when the occurrence of the events is less than 5% was the bias correction method proposed in [
42]. This procedure estimates the same logit model as the traditional one, but with an estimator that provides lower mean square error in the presence of rare events data for coefficients, probabilities and other quantities of interest.
Model 1 uses the explanatory variables referred to in
Table 4 without taking into account the effects of work activity in a specific way.
Table 5 and
Table 6 show that the overall accuracy of the model is acceptable. Note that a naive model, for simple chance, would have a specificity and sensitivity of 50%. For example, the statistic R square is 65.6%, which is quite acceptable in predictive terms. According to
Table 4, the estimated coefficient of the dependent variables, as shown by the Wald test, are significant from a statistical point of view.
4.1.2. Model 2
This model is an extension of the previous one. The novelty is that the effect of the working patterns in prices has been incorporated by using a periodic logistic regression model. Thus, a regression model is estimated for weekdays, another one for Saturdays and a different one for the holidays.
Table 7 shows that the model goodness-of-fit is better, and the variation explained by the model is slightly higher than the previous one.
In accordance with
Table 8, the explanatory variables are significant from a statistical point of view (except the constant term in the case of the working days).
Table 9 shows the performance of the three models separately and for the global model. Furthermore, the optimal cutoff points that have been calculated are presented in parenthesis. As seen, this model presents a power for prediction slightly higher than Model 1.
4.1.3. Model 3
This particular case is a variant of Model 2, not considering the correction proposed in [
42]. Instead, it was decided to reduce the data with the aim that the number of low prices had a greater significance in the sample. In this way, according to
Table 10, those intervals of data in which it is guaranteed the absence of extremely low prices in the dataset were eliminated. Hence, the sample was reduced by 42.3%. The model, although still slightly better than Model 1, cannot overcome the suitability of Model 2.
Table 11 presents Cooper statistics broken down individually and globally. Note that there are categories with two values. The values on the left side refer to those corresponding to the simplified model, while the values on the right side refer to the correction made taking into account that the removed values of the training set have been successfully predicted. Meanwhile,
Table 12 confirms the goodness-of-fit of each one of the regression models. Furthermore,
Table 13 presents the coefficients associated with each explanatory variable, as well as the statistical significance of each one of them. As in Model 2, the constant term for weekdays is not significant.
4.1.4. Comparison between the Models
As seen, the three models have a quite acceptable predictive accuracy. Note that Model 1 showed slightly worst global performance than the other models. However, it presents the advantage that it is a much simpler model. The results obtained in this comparison demonstrate that the inclusion of weekly seasonality slightly improves the predictive capabilities of the forecasting methods. A remarkable fact is that there are discrepancies regarding the significance of the explanatory variables depending on the day of the week under consideration. Another finding to note is that the correction proposed in [
42] is an effective tool when dealing with unbalanced problems. Finally, a greater difficulty in achieving effective predictions on Sundays and holidays has been found. This may be explained by a different market behavior during these days.
4.2. Decision Trees
Decision trees classify observations based on a set of decision rules, applied in a sequential manner. The probability of occurrence of extremely low prices is allocated to each end of a branch in the tree. The way of estimating probabilities does not require the assumption of specific probability distributions for the variables, which is an advantage of this methodology. In order to not over-fit the data, stopping rules control the growing process, and the over-fitted parts were pruned. In this paper, an ID3 (Iterative Dichotomiser 3) algorithm has been used, with splitting criteria based on the entropy [
43].
4.2.1. Model 1
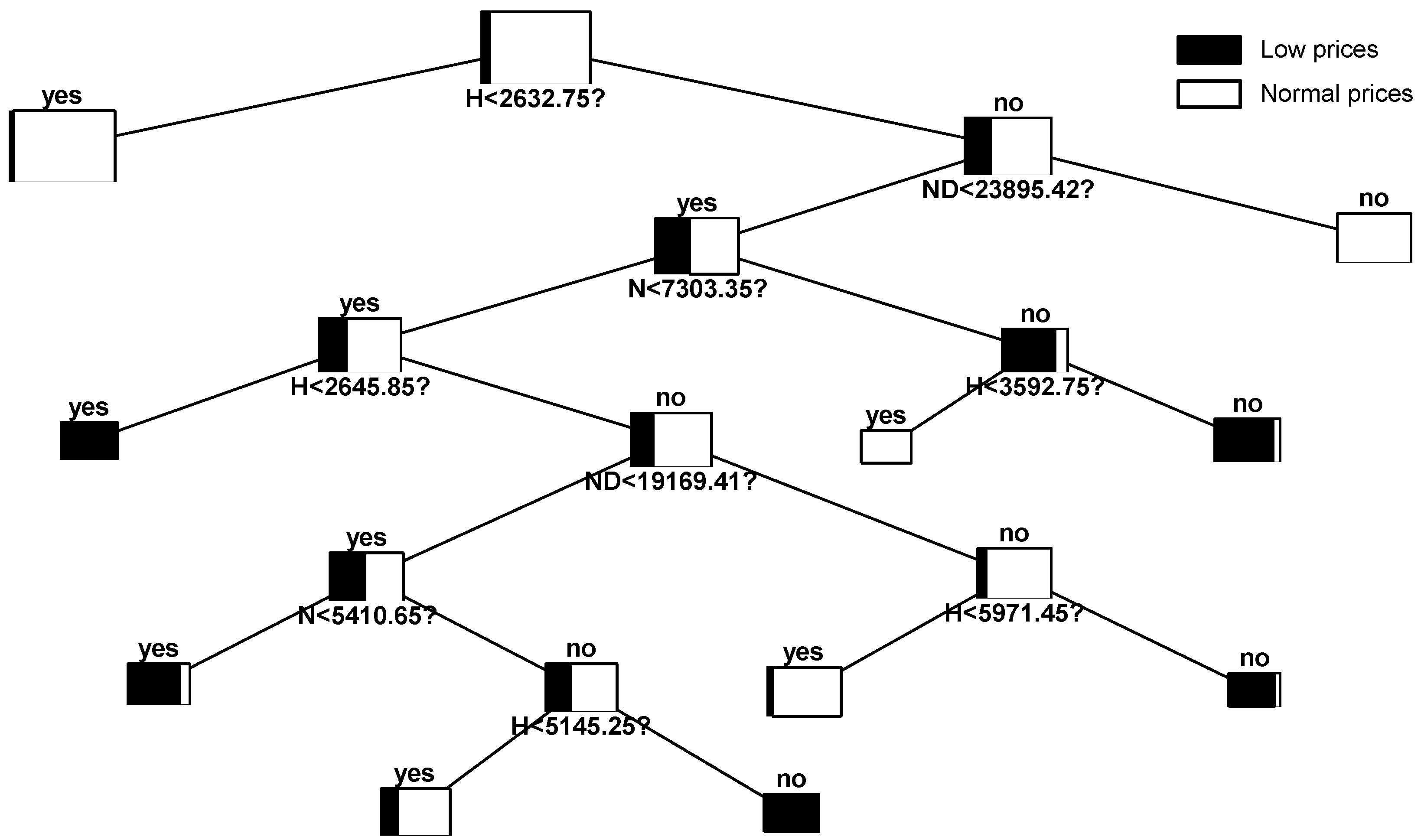
A global model ignoring the effects of weekly patterns has been built. According to
Figure 3, the most representative variable is the hydro production. Note that under a scenario below the 88th centile, there is a negligible probability of occurrence of very low prices. Another interesting aspect is that nuclear production is not representative in this case.
Table 14 shows the classification success rate of the tree. As seen, the model is able to accurately predict an acceptable number of the events that occurred during this period of time.
4.2.2. Model 2
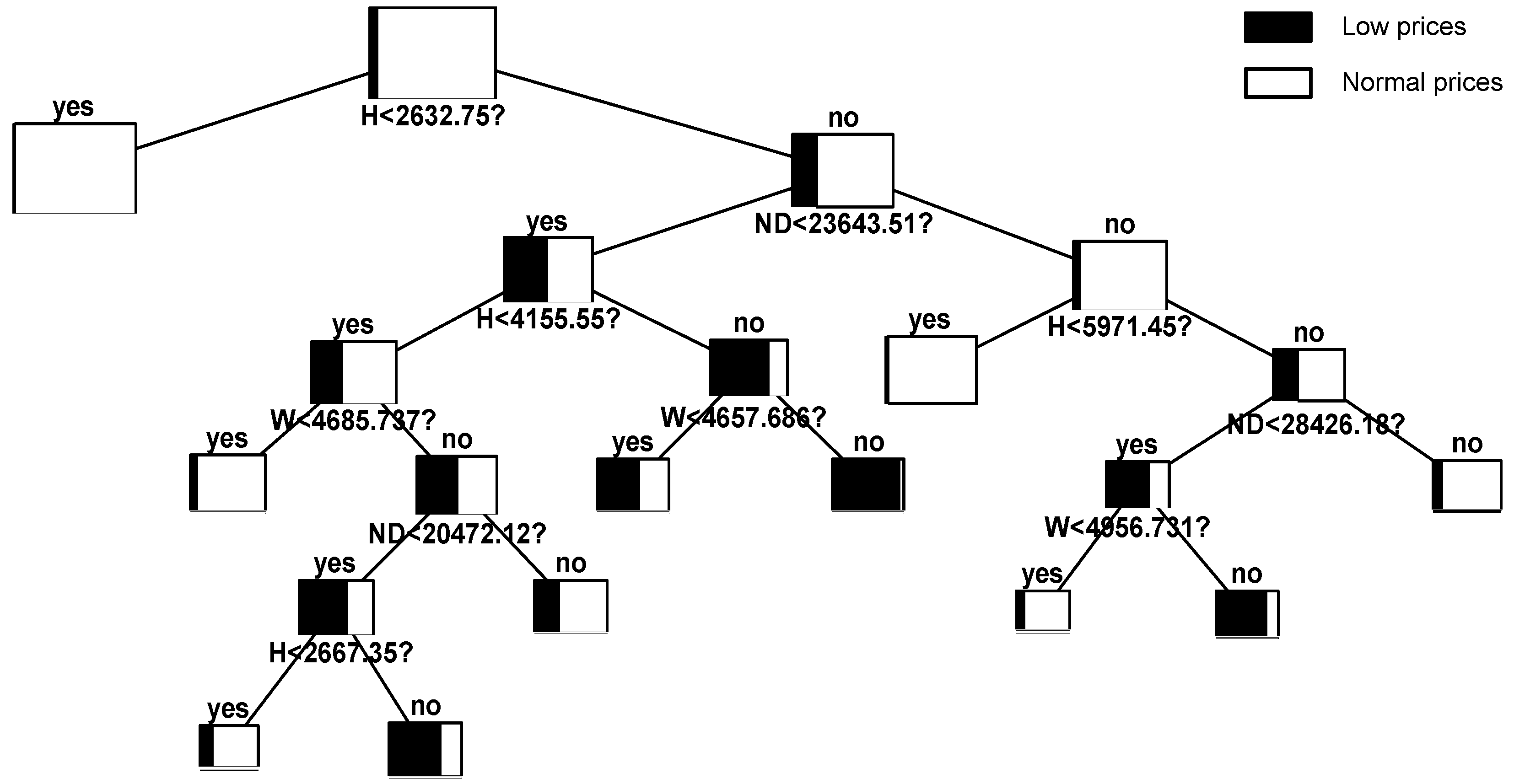
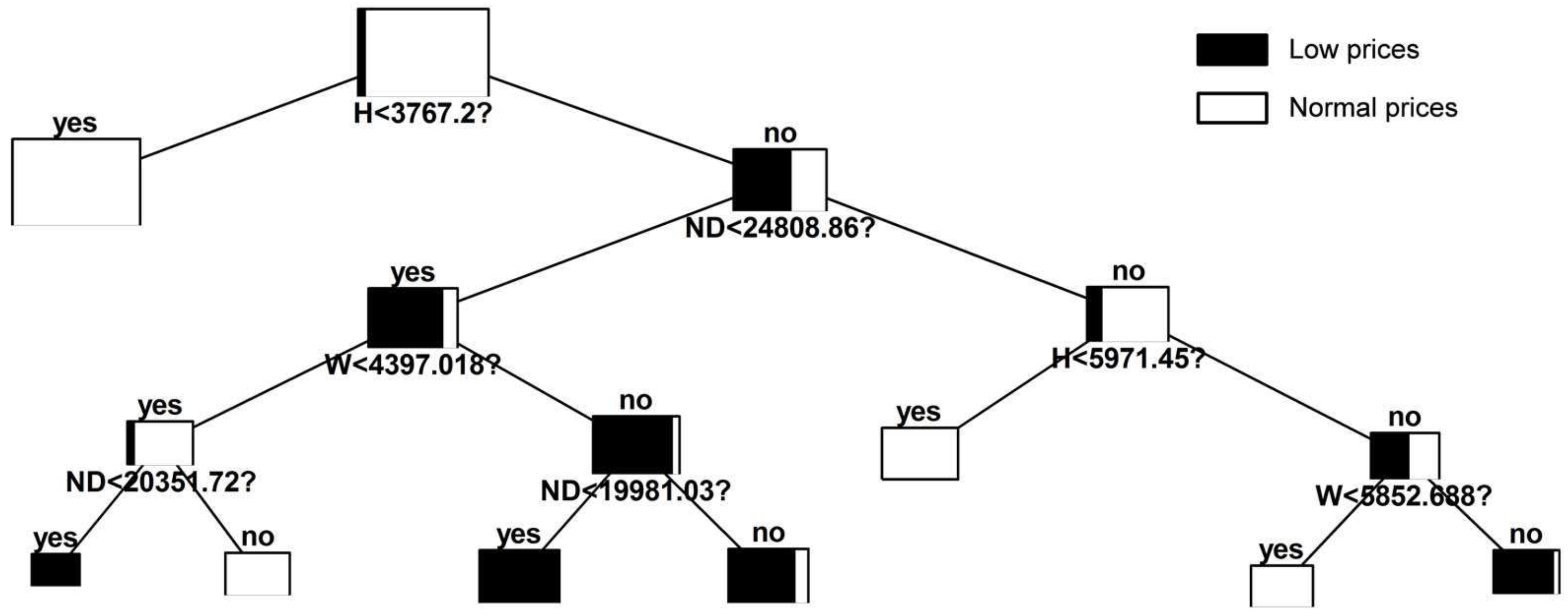
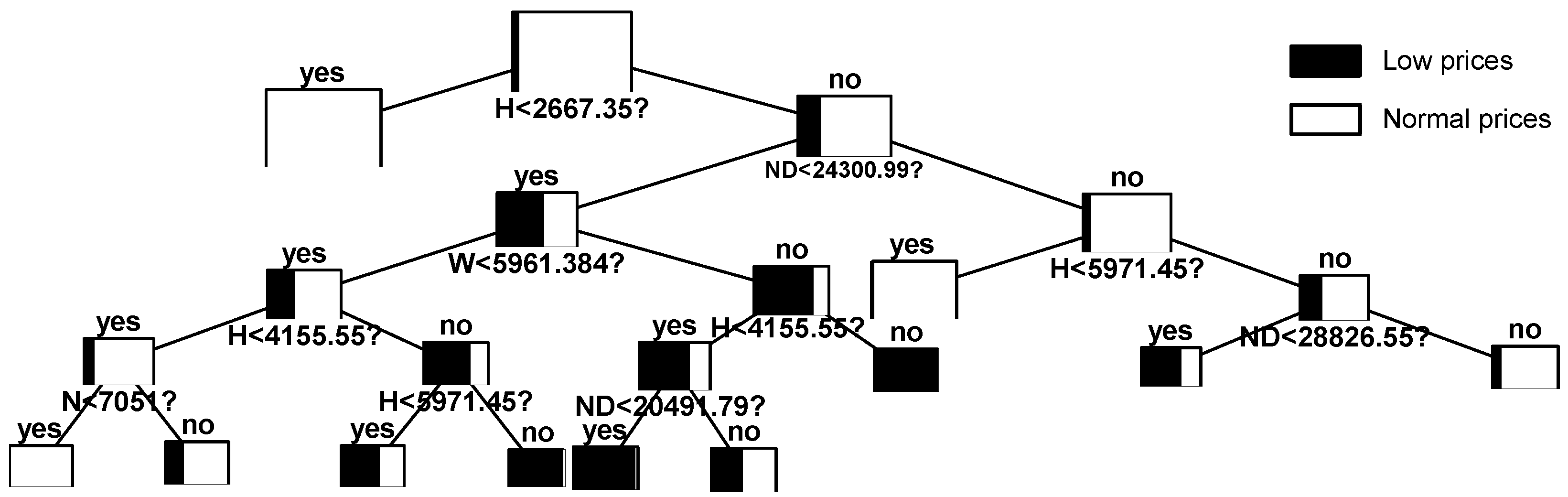
In this case, the weekly seasonality has been taken into account by building three different trees. If we analyze the constructed trees in comparative terms, we can observe clear similarities and differences between them. First, it is clear that hydro production is the most relevant variable. Moreover, the scenarios that lead to hours with very low prices are similar. However, a more detailed individual analysis of each tree allows one to establish significant differences in the representativeness of the explanatory variables and characteristic values of the selected splits.
Figure 4 shows the tree for Saturdays. As can be seen in the figure, those hourly scenarios of hydro production that fall below 3767.2 MW have a negligible probability of occurrence of very low prices. One of the most remarkable facts is that, from a statistical point of view, hydro production seems to be even more important than in the other types of days, such as Sundays and holidays. Furthermore, nuclear production is irrelevant. The typical behavior of Sundays and holidays is reflected in
Figure 5. An interesting aspect is that wind power is not significant. In contrast, nuclear production itself is useful in explaining the output’s behavior. Finally,
Figure 6 corresponds to working days. According to the figure, the main factors influencing the appearance of low priced hours are the hydro production and the system net demand.
Table 15 shows the global performance of the model derived from each of the trees, which has been constructed separately. As the optimal cutoff value was set independently for each tree, it is not possible to achieve a balance between positive and negative predictivity.
4.2.3. Comparison between the Models
Table 16 shows a comparison between the proposed models. The percentages of success in the training, test and validation sets are shown, as well as the optimal cutoff value for each tree. In general, both models are acceptable, since the overall accuracy is superior to that obtained by chance (95.68%). The second model performs slightly better. A remarkable aspect is that the tree constructed for Sundays and holidays is only able to identify 50% of the hours with very low prices.
4.3. Multilayer Perceptron
Multilayer perceptrons constitute a useful tool for regression and classification [
44]. In this case, its use is justified because we expect that there could exist a nonlinear relationship between the proposed inputs and output.
There are several problems associated with local minima and decisions over the size of the network to use. Thus, the use of this technique usually implies experimenting with different architectures, as the determination of the number of hidden layers and the number of hidden neurons in each hidden layer. It has been shown in practice that one hidden layer configuration is enough for most applications. For this reason, a topology with two layers of adaptive weights (a hidden layer and an output layer) has been selected.
The activation function of neurons is the hyperbolic tangent, both for the hidden and the output layer. With the aim of providing a probabilistic interpretation, the outputs have been scaled to the interval [0,1].
Regarding the proper number of hidden neurons to be used, a sweep computing the validation error was carried out to find its optimal value. As said, one of the main problems in the multilayer perceptron is getting stuck in local minima. This problem has been solved by initializing the weights with random values and by repeating the process several times. Before training, the inputs were normalized by a simple linear rescaling. The fitting criterion was the quadratic error minimization, as it penalizes large errors more than small ones.
Using this technique, two models were constructed: a single MLP for the whole set of data and three different MLP to take into account the weekly seasonality. In
Table 17, the structure of the proposed models is summarized. In order to evaluate the forecast performance, the Cooper statistics are displayed for the optimal cutoff value that has been computed. It is evident that the prediction ability of this model is significantly improved if the weekly seasonality is included. In any case, each of the models based on MLP is clearly superior in terms of prediction performance to the other proposed techniques. Curiously, this model demonstrates a better ability to capture the dynamics of the very low prices on Sundays and holidays.
4.4. Hybrid Approach
The hybrid approach presented in this section is a novel forecasting methodology that combines a fundamental market equilibrium model with the logistic regression approach implemented in
Section 4.1.1, with the ultimate objective of benefiting from the advantages that each of them offers separately. Fundamental models, which are preferred in a medium- and long-term horizon, can provide useful insights for the analysis of the strategic behavior in electricity markets and constitute a valuable tool to represent the electricity market with its main technical and economic characteristics, especially when there are structural or regulatory changes in the market. However, as stated in [
7], market equilibrium models fail when the aim is to capture the high-order moments of the probability distribution functions compared to the data-driven methods. This is because in the tails of the distribution, fundamentals are less important than behavioral factors. This naturally leads to complementing the fundamental approach with some of the statistical methods discussed before, which is one of the ultimate goals of this paper.
4.4.1. Fundamental Market Equilibrium Model
In the first step of the methodology, the operation and the behavior of the Spanish electric power system are fairly represented using a fundamental market equilibrium model based on conjectural variations as stated in [
45,
46]. The model, which is equivalent to the one used in [
7], is formulated as a traditional cost-based optimization problem where each generation company
i tries to maximize its own profit. In this model, the strategic behavior of each generation company
i is represented by means of a parameter known as the conjectured-price response
. This exogenous positive parameter has been valued by using historical data following [
47,
48]. This parameter, which measures the market power of the various companies taking part in the market, is the minus derivative of the electricity market price
λ with respect to the production
of the generation company (Equation (
1)).
As was shown in [
45], the market equilibrium (note that under game theory, the market equilibrium is the point in which each market agent maximizes its own profit, but bearing in mind that the rest of the agents also maximize their profits) can be calculated by solving an equivalent quadratic optimization problem (Equations (2)–(4)):
The term
is the so-called effective cost function of agent
i, which is defined as:
As seen, the effective cost function takes into account a linear or quadratic cost function and a term that models the strategic behavior of the company i. Therefore, the minimization problem Equations (2)–(4) is a quadratic optimization problem that can be effectively solved using readily available commercial software. The decision variables of this problem are the dispatch of the generators, subject to the demand-balance equation (Equation (3)) and the technical constraints (Equation (4)) of the operation of all hydro and thermal groups (emission limits, variable costs, minimum and maximum power, efficiency, etc.).
Since in medium-term market equilibrium models, an hourly representation is not often used in practice because the size and resolution times increase considerably for a real-sized electricity systems, the hours within each month have been grouped into l = 1,2,…,16 net demand levels (denoted as ND in this paper), or system states, by means of a k-means clustering process, as explained in [
49]. System states consist of a number of hours in which market conditions are considered to be the same.
The use of system states as proposed in [
49] is an alternative approach to the traditional representation based on load levels, which prevents the loss of chronological information between individual hours. This is very important for decision variables, such as the starting-up and the shutting-down of thermal groups. It should be noted that load levels, unlike system states, are only defined based on system demand. The consideration of the net demand for the computation of system states allows us to better represent the operation in power systems with a high penetration of renewable energy sources. Furthermore, as stated in [
7], this novel approach based on system states enables one to reach a better forecasting accuracy and allows one to successfully capture the so-called stylized facts [
50] of electricity prices. However, even in this complex model, there are many difficulties to properly account for the occurrence of extreme events, and that is why a complementary approach with a statistical model is needed.
4.4.2. Communication between the Models
For the hybridization of the models, the system marginal price for each state
λ is firstly estimated by computing the dual variable of the power-balance constrain (Equation (3)) of the market equilibrium model. Hereinafter, the price is allocated to the hours that belong to the corresponding state, and it is used as an explanatory variable in the logistic regression model for rare events, which was detailed above in
Section 4.1.1. As stated in
Table 18, the market price
λ shows the statistical significance thereof. Another factor to highlight is that the sign of the considered variables coincides with what would be expected
a priori. The fact that the fundamental model seems not to add very much to the logistic model implies, as was expected, poor fundamental specification at low prices. However, as can be seen in
Table 19, the obtained results suggest that this approach performs slightly better than the individual models presented in
Section 4.1. This finding suggests that
λ, which simultaneously captures the production cost and the strategic behavior of market agents, can provide useful insights to predict extremely low prices.
It should be stressed that the hybridization may also be performed with the rest of the techniques that have been previously presented. The major reasons why logistic regression has been used are based on the commitment between accuracy, transparency and simplicity of implementation that this technique has demonstrated. This is of great importance, since, as will be explained ahead in
Section 5, the implementation of the methodology to make real predictions in the medium term requires simulating multiple scenarios of the variables subject to uncertainty, which is computationally highly intensive in real-sized electricity systems. Note that although the problem size using system states is much lower than the hourly representation, the model for the Spanish electricity market consists of more than 300,000 equations and 800,000 variables. The optimization problem is formulated in GAMS (General Algebraic Modeling System) and is solved using CPLEX 12.4. The resolution time is almost two minutes for just one realization of the risk factors using a PC with Intel Core Duo i7-4790 CPU @3.6 GHz CPU and 32.0 GB RAM.
4.5. Markov Regime-Switching Model
Markov regime-switching models (MRS) assume the existence of an unobserved variable representing the state or regime, which governs a given dataset at each point in time. The usefulness of MRS models for power market applications has already been recognized. However, their effectiveness for forecasting has been vaguely proven, and only lately has this issue been approached in the literature [
39,
41,
51].
Markov switching models do not require a previous dating of which periods are considered extreme. Therefore, fixed imposed thresholds are not needed. The model is able to capture changes in the mean and the variance between state processes. The motions of the state variable between the regimes are governed by an underlying Markov process.
In this paper, one of the most popular specifications of MRS models in the energy economics literature is followed. Specifically, as proposed in [
51,
52], the specification includes two independent regimes (
and
) and a mean-reverting heteroskedastic process for the base regime dynamics. In Equation (6), where the base regime is described,
is supposed to be N(0,1)-distributed. On the other hand, a Gaussian distributed spike regime is assumed (Equation (7)).
Following the recommendations provided in [
51], the prices themselves instead of the log-prices are modeled. Moreover, the deseasonalization of prices is conducted in a similar way as was stated in [
51]. Thus, an additive model is considered. Equation (
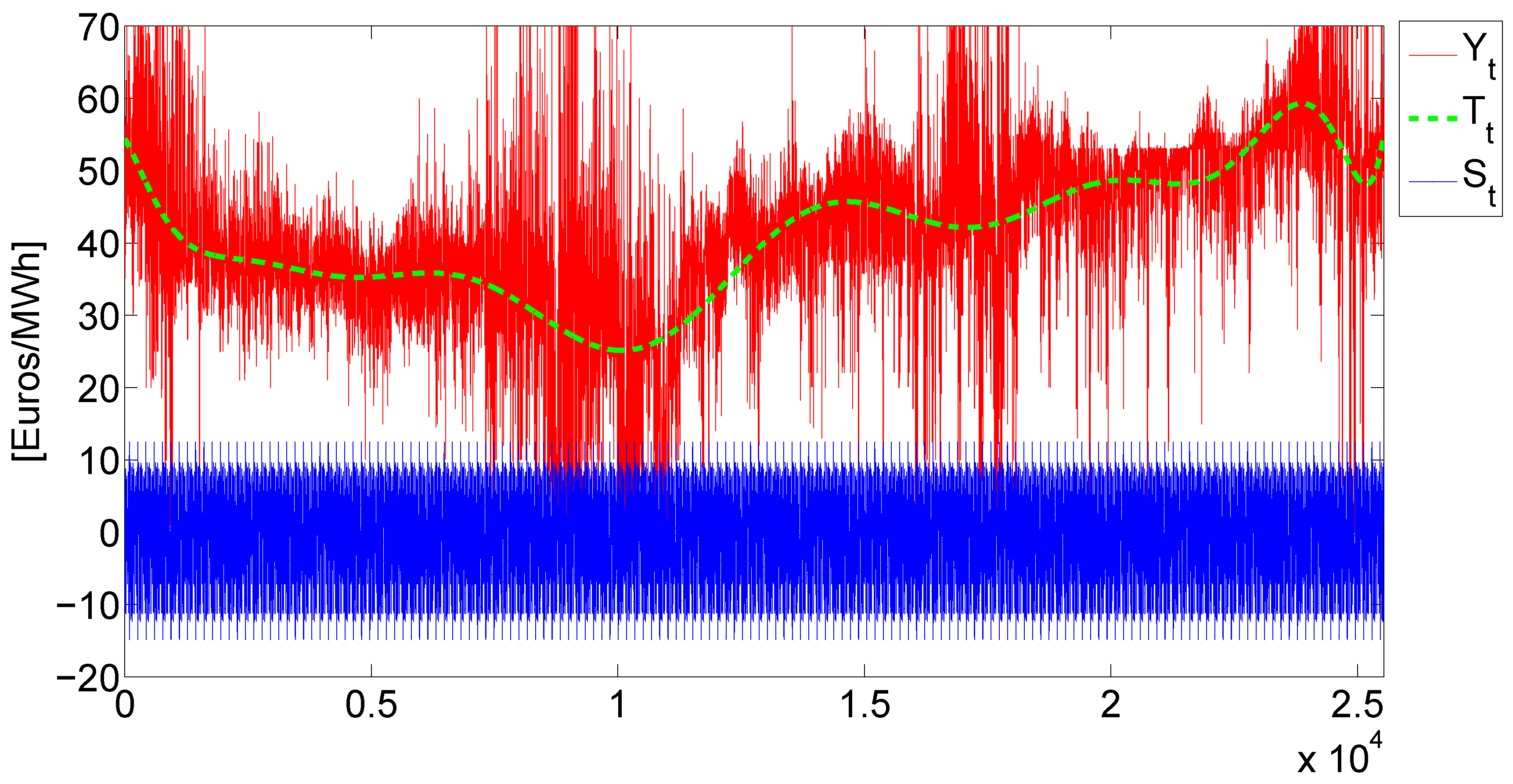
8) represents that the hourly spot price
can be decomposed into a stochastic part
and a predictable component (trend and seasonal component). On the one hand, for estimating the trend
, a wavelet filtering-annual-smoothing technique is used. On the other hand, weekly periodicity is considered for the seasonal component
. This component is removed by applying a variation of the moving average technique, using the median instead of the mean value. The reason is that the median is more robust than the mean in the presence of outliers.
Figure 7 graphically shows the decomposition process, which has been performed.
Next, MRS models are fitted to deseasonalized prices
. The calibration of parameters is accomplished by an iterative procedure based on the application of the expectation-maximization algorithm proposed in [
53]. The estimated model parameters are given in
Table 20. As can be seen, the parameters obtained for the base regime suggest a high speed of mean-reversion (which is represented by the parameter
) and that extremely low prices increase volatility more than extremely high prices (this is captured by the parameter
). Regarding the probabilities
of staying in the same regime, high values in both regimes are observed. This suggests that several consecutive observations in each regime will be appreciated, which represent an advantage in comparison to jump diffusion models.
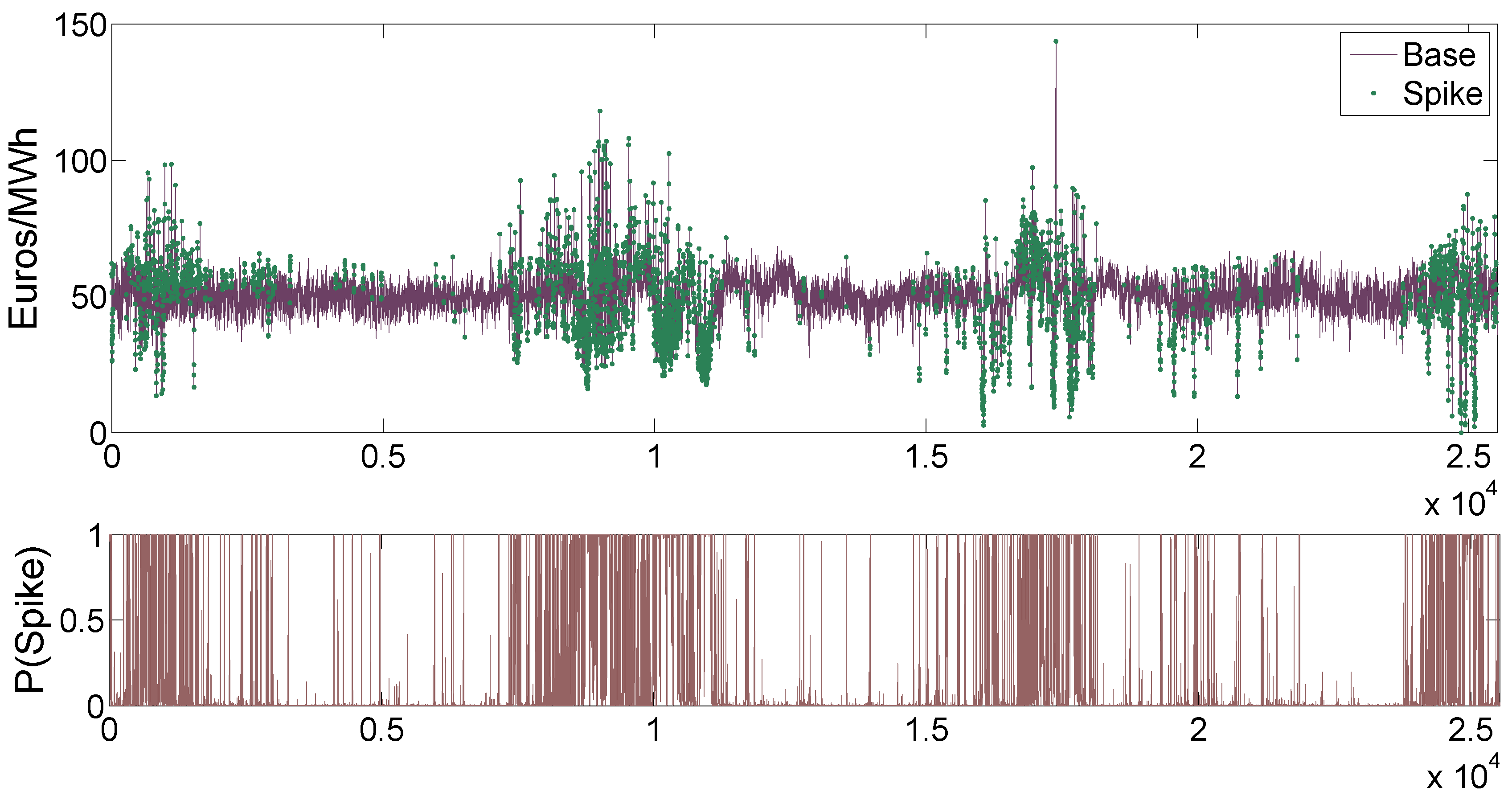
Figure 8 shows the deseasonalized prices
and the spikes that have been identified. The lower picture displays the probabilities of being in the spike regime. The deseasonalized series has been shifted so that its minimum coincides with that of the original series
.
In order to test the ability of the model to predict extremely low prices in the in-sample dataset, 5000 price trajectories have been simulated. The performance of the model is analyzed with two measures typically used in spike classification: sensitivity (85.75%) and positive predictivity (45.88%). Although the model is able to predict many of the extremely low prices correctly, this technique tends to classify many non-spikes as spikes. Therefore, it seems that this model has no advantages over the other proposed models.
5. Real Ex Ante Forecasts
This section is aimed at making real
ex ante forecasts in a probabilistic way by using predicted scenarios of the risk factors and the parameters that have been estimated for the forecasting techniques presented in
Section 4. On the one hand,
Section 5.1 presents a description of how the last stage of the methodology explained in
Section 3 is actually implemented with the proposed forecasting techniques. On the other hand, in
Section 5.2, we briefly discuss the simulation with the MRS model, which is used as a benchmark. Finally, the presented case study is presented in
Section 5.3.
It is important to highlight that the medium-term horizon is referred here to a forecasting scope that varies from one to two months. More specifically, if the primary objective is the prediction of extreme hourly prices for month m, the simulations are carried out in a single step in the first hour of month m-1.
5.1. Simulation with the Proposed Models
In order to make simulations with the proposed models, a multi-scenario analysis has been conducted. Therefore, the first step of this methodology is to generate scenarios for those random variables based on historical data. As was stated in
Section 3, all risk factors are represented by their corresponding cumulative distribution function (CDF) in such a way that each scenario corresponds to a percentile. Different strategies have been used for the hybrid approach and the remaining techniques. This is because in the market equilibrium model, it is also important to incorporate the uncertainty related to fuel prices and the unavailability of thermal plants.
5.1.1. Logistic Regression, Decision Trees and Multilayer Perceptrons
In the presented case study, possible hourly realizations for water inflows (five scenarios), power demand (five scenarios) and wind production (55 scenarios) have been generated. In order to obtain a well-sampled spatial structure, representative percentiles ranging from the 1st to the 99th of its CDF have been chosen. Meanwhile, it is assumed that the international exchanges, as well as the production of the rest of the technologies belonging to the special regime are completely determined by their expected values. It should be noted that it is out of the scope of this work to understand how the prediction errors in the generation of scenarios contribute to the error of
ex ante forecasts. Taking into account all of the possible combinations of the generated scenarios, a total of 1375 simulations have been performed with each forecasting technique. For each scenario and for each hour, the likelihood of the appearance of low priced hours has been computed. If this value is lower than the optimal cutoff value defined for each particular model in
Section 4, the observation is classified as an extremely low price. Because of its practical interest, an additional variable that indicates the number of extremely low prices per month has also been constructed for every simulation on the basis of the sum of all hourly indicator variables. In the next step, a huge amount (more specifically, 100,000) of random scenario combinations of the percentiles of the well-known uncertain variables is generated in order to establish the unobserved areas of the hypercube, which have to be estimated by means of the spatial interpolator. Finally, probabilistic forecasts are calculated taking into account that all of the 100,000 scenarios are equiprobable.
5.1.2. Hybrid Approach
In the specific case of the hybrid approach, we have taken into account as medium-term risk factors, in addition to the three variables considered in
Section 5.1.1, the natural gas prices (11 scenarios), the CO
2 emission allowance prices (11 scenarios), the coal prices (11 scenarios) and the unplanned unavailability of thermal power plants (three scenarios). As a result, there are 5,490,375 possible combinations of uncertain variables. In the initial stage, a representative sample of 1375 uncorrelated scenario combinations has been defined by means of Latin hypercube sampling as stated in
Section 3. The next step is to perform 1375 simulations of the hybrid approach by including the well-sampled scenario combinations of the uncertain variables and the deterministic inputs. Finally, probabilistic forecasts are computed in a similar way to what is done in the previous section. The main difference is that in this case, the 100,000 random scenario combinations that have been generated for the Monte Carlo simulation present a correlated structure. This is particularly important, since it is well established that commodity prices are correlated, and it would be unrealistic to consider certain combinations when making the spatial interpolation. For the sake of clarity, a general outline of the methodology followed is provided in
Figure 9.
5.2. Simulation with the Markov Regime-Switching Model
Several price trajectories are simulated in order to guarantee the stability of the results. Specifically, 5000 different paths have been used for each month. Then, using the simulated forecasts for the spot price, the corresponding probabilistic forecasts have been determined. Forecasting based on decomposition methods has been performed by extending each of the predictable components. The trend is the component that presents major problems, since wavelets are functions that are quite localized in time and space. In order to extend the signal, polynomial extrapolation or a spline fit might be utilized. In this case, as this component is closely related to expectations about fuel price levels, climate and consumption conditions, an adjusted linear model based on futures prices information being traded is used. This approach is suitable to properly internalize the expectations of all market agents. Regarding the seasonal component, it has been extended through the duplication of the last seasonal period. This can be considered as appropriate, since the seasonal component does not vary with time.
5.3. Case Study and Results Analysis
This section firstly assesses the capabilities of the proposed techniques to provide real ex ante point forecasts. The number of hours with very low prices per month has been selected, due to its interest in practical applications, as accuracy measure to evaluate the performance of the different approaches. For this assessment, a comparative study with two naive methods has been conducted. On the one hand, Naive 1 makes forecasts for month m by taking into account the proportion of extreme low prices that have taken place from 1 January 2009 to the last hour of month m-2. On the other hand, Naive 2 considers the proportion of events in similar months of the in-sample dataset.
In
Table 21, the values of these measures are provided. Comparing the predictions of each proposed model with those that actually occurred, it can be concluded that the hybrid approach seems to be superior to the rest of models. This result suggests that the inclusion of the prediction of the market equilibrium price as an input of logistic regression in each scenario can provide useful information about the economic and technical characteristics of the market. This is even more important when possible structural changes can occur in the market. As can be seen, models based on logistic regression are able to achieve high levels of accuracy and slightly outperform multilayer perceptrons. Furthermore, note that MLP models perform significantly worse in the out-of-sample test. Regarding decision trees, it seems that they do not provide satisfactory results from the constructed scenarios. In turn, Markov regime-switching models show acceptable results. However, they have the well-known disadvantage of being very sensitive to the predictable component estimation. As seen, all models are successful when facing the naive test. It is also interesting that, unlike in the in-sample dataset, the prediction ability is not improved when periodic models are used.
Since probabilistic forecasts are crucial for an adequate risk management, the proposed methodology has also been used to compute the probability of an extremely low price for each hour in the forecast period.
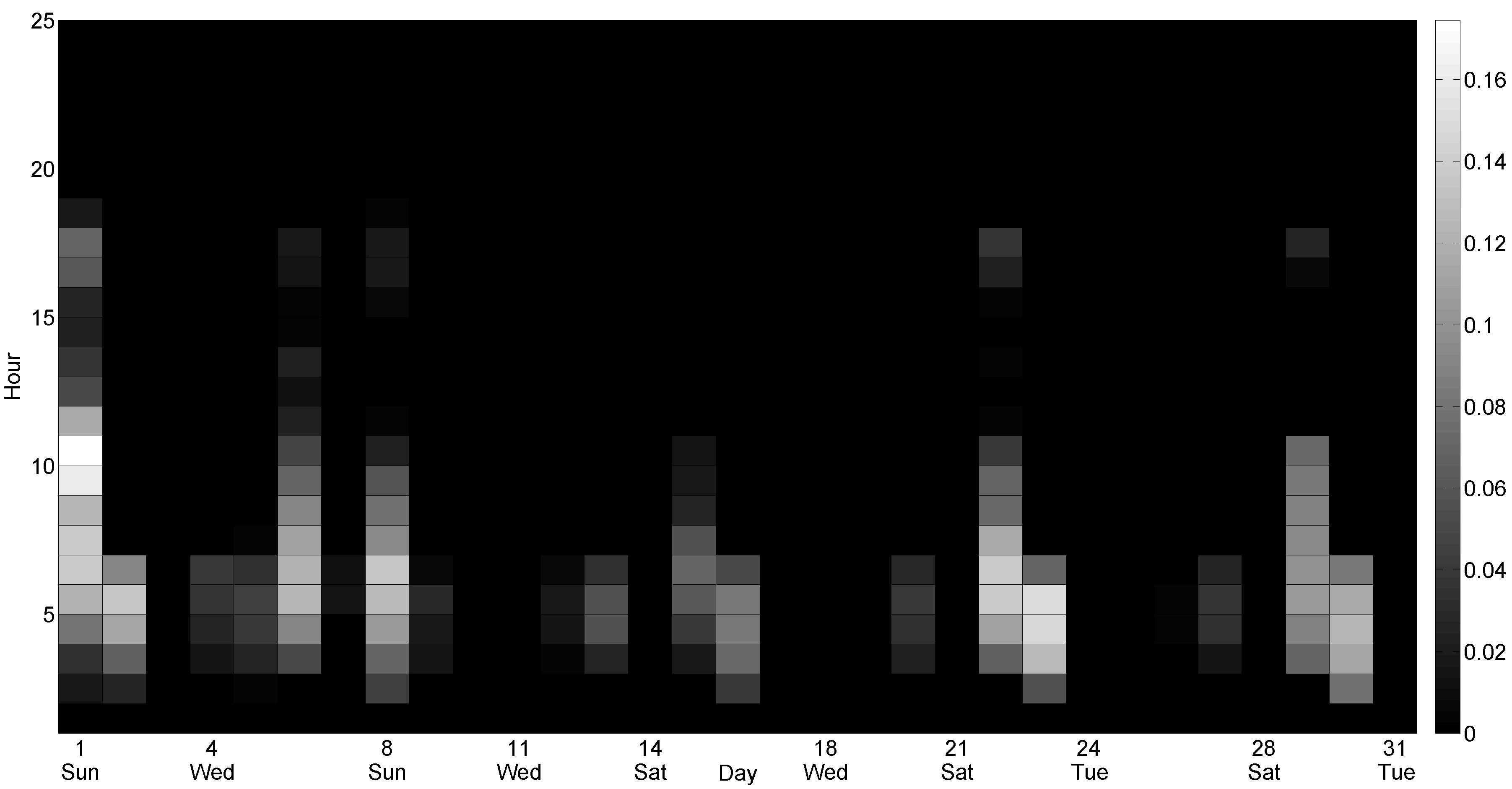
Figure 10 shows the probability of the appearance of extremely low prices, which has been estimated on an hourly basis during a representative month.
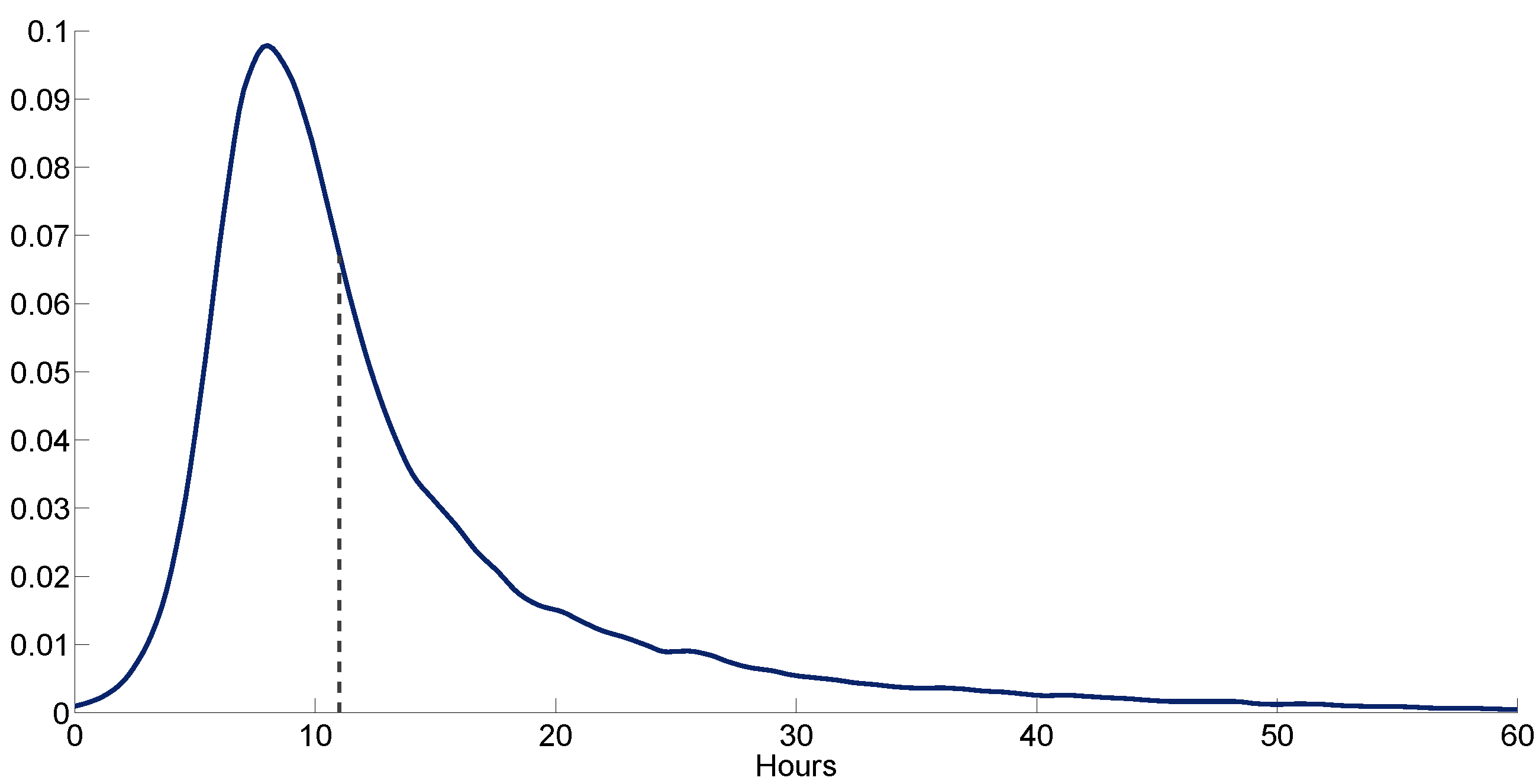
Similarly, the proposed methodology has been applied to estimate the probability density function (PDF) associated with the number of hours with very low prices throughout the projection period. An illustrative example of the forecasted PDF for February 2012 by using the hybrid approach appears in
Figure 11. In this figure, the dashed line represents the actual number of hours that occurred in the market. As shown, the distribution is unimodal and right-skewed. In this particular case, it is evident that the actual value always falls under the range of the most likely values. The real value (11 h) is near the mode value (8 h) and the expected value (11.59 h).
In order to compare the forecast quality of the proposed models, the Brier Score (BS) has been used. The BS is probably the most commonly-used verification measure for assessing the accuracy of binary probabilistic predictions. It is the mean squared error of the probability forecasts over the verification sample and it is expressed as:
where
S is the sample size,
is the predicted probability of the event occurring according to the
i-th hourly forecast and
is equal to one or zero, depending on whether the event subsequently occurred or not during that hour. The BS ranges from zero for a perfect forecast to one for the worst possible forecast.
With the objective of making it easier to interpret the results, two naive models have also been used as benchmarks. Naive 3 is based on the previous similar month, while Naive 4 relies on taking the historical values of month m-2 as forecasts of future prices for month m. A comparison of the results for the probabilistic estimates for all specifications is reported in
Table 22. As can be seen, the obtained results suggest that the proposed hybrid methodology produces superior probabilistic forecasts than the rest of the alternative techniques. Naive techniques are clearly outperformed by all of the proposed procedures, which demonstrates the practical interest of the developed methodology. In this case, a slight increase in accuracy was obtained when considering different dynamics for each day of the week through the periodic models.
6. Conclusions
In this paper, a novel methodological approach to analyze and make real ex ante forecasts of the occurrence of extremely low prices in electricity markets with a medium-term horizon has been presented. The proposed methodology, which is a mixture of different forecasting techniques with a Monte Carlo simulation that integrates a spatial interpolation tool, is able to simultaneously perform punctual and probabilistic predictions with an hourly basis. The methodology has been specifically applied to the Spanish wholesale market, but may be extended equally to other electricity markets worldwide.
Logistic regression for rare events, decision trees, multilayer perceptrons and a novel hybrid approach, which is able to incorporate both fundamental and behavioral information, have been compared to a Markov regime switching model and several naive methods. Further research has been undertaken in order to evaluate whether periodic models, in which parameters switch according to the day of the week, can provide better prediction capabilities.
Overall, all of the proposed models present reasonable errors taking into account the complex nature of the phenomenon and substantially outperform naive techniques in both the in- and out-of-sample datasets. Encouraging results have been obtained from real ex ante forecasts of the distribution function of the exogenous variables used to predict the phenomenon. The results reveal that the integration of a market equilibrium model and logistic regression in a hybrid approach provides a significant improvement in the prediction accuracy in comparison to the individual models. We also found that the inclusion of a prior estimation of the market equilibrium price can provide valuable information when used as an input in a statistical technique, such as logistic regression, especially when there are structural or regulatory changes in the market. Logistic regression with the correction for rare events data has proven to be a simple, but effective tool enabling one to outperform multilayer perceptrons and decision trees in terms of forecasting accuracy. When the real explanatory variables are used, it is clear that MLP performs better than the other models, but it behaves significantly worse when making real ex ante forecasts. However, still, MLP is superior to decision trees. With respect to decision trees, they have shown that they can provide valuable information and offer great interpretability for probabilistic approaches.
Another interesting conclusion is that a meaningful improvement of the prediction capability is reached when considering different dynamics for working days, Saturdays, Sundays and holidays. Open research lines may include the extension of this methodology to extremely high priced hours and to other markets, where locational marginal prices may exist and for which the impact of variables related to local distributed generation should be taken into account.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}