
DagTM: An Energy-Efficient Threads Grouping Mapping for Many-Core Systems Based on Data Affinity

Abstract
:1. Introduction
2. Related Work
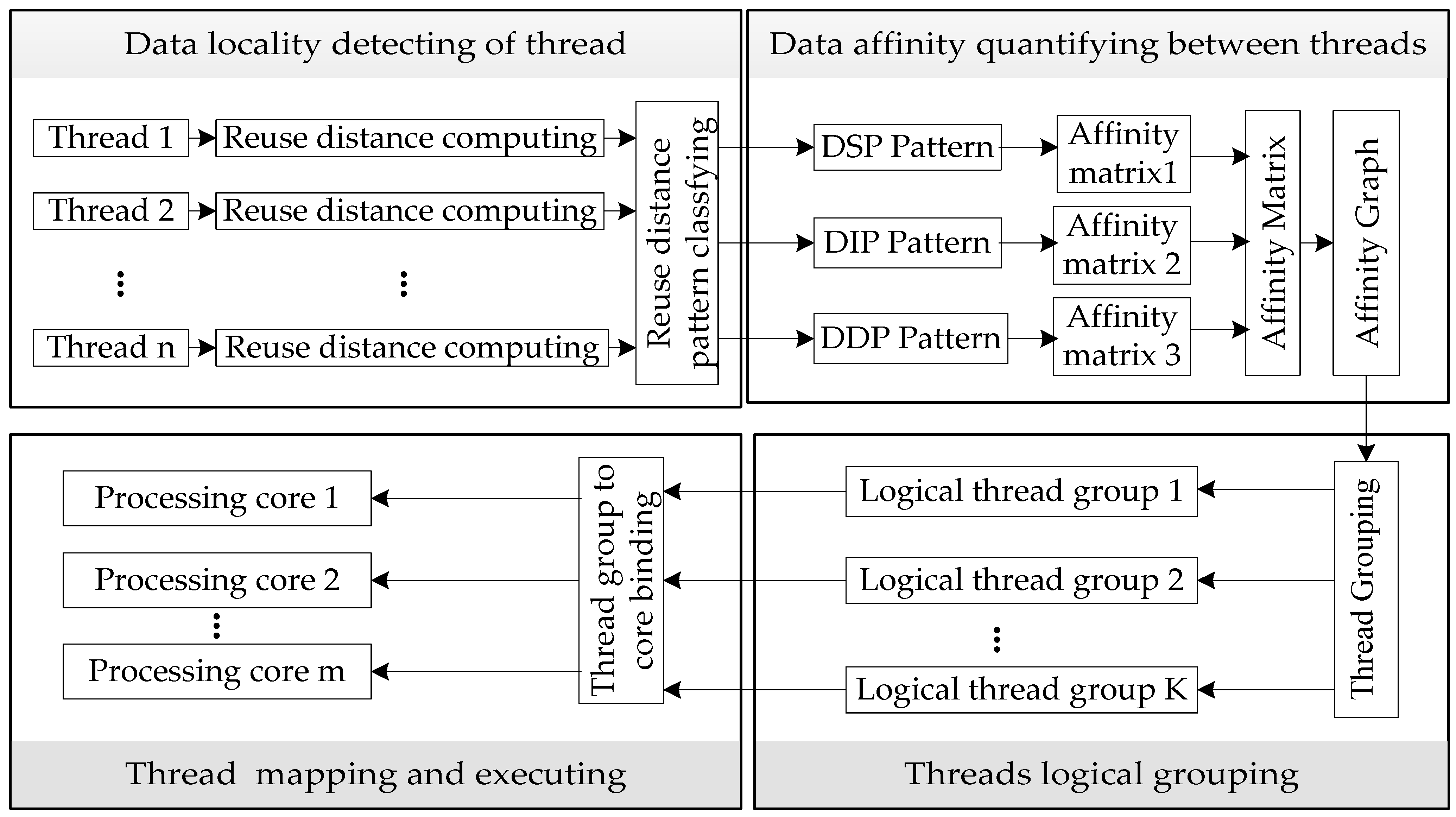
3. Threads Grouping Mapping Framework
4. Detecting Thread Data Locality
4.1. Calculating Data Reuse Distance
struct Node
{int TS; //time stamp that records the access order of data.
float Element; //records the accessed data.
int Frequency; //records the access times of memory access data.
int Weight; //records the number of sub-node contained in the current node.
int RD; //records the data reuse distance of the current node.
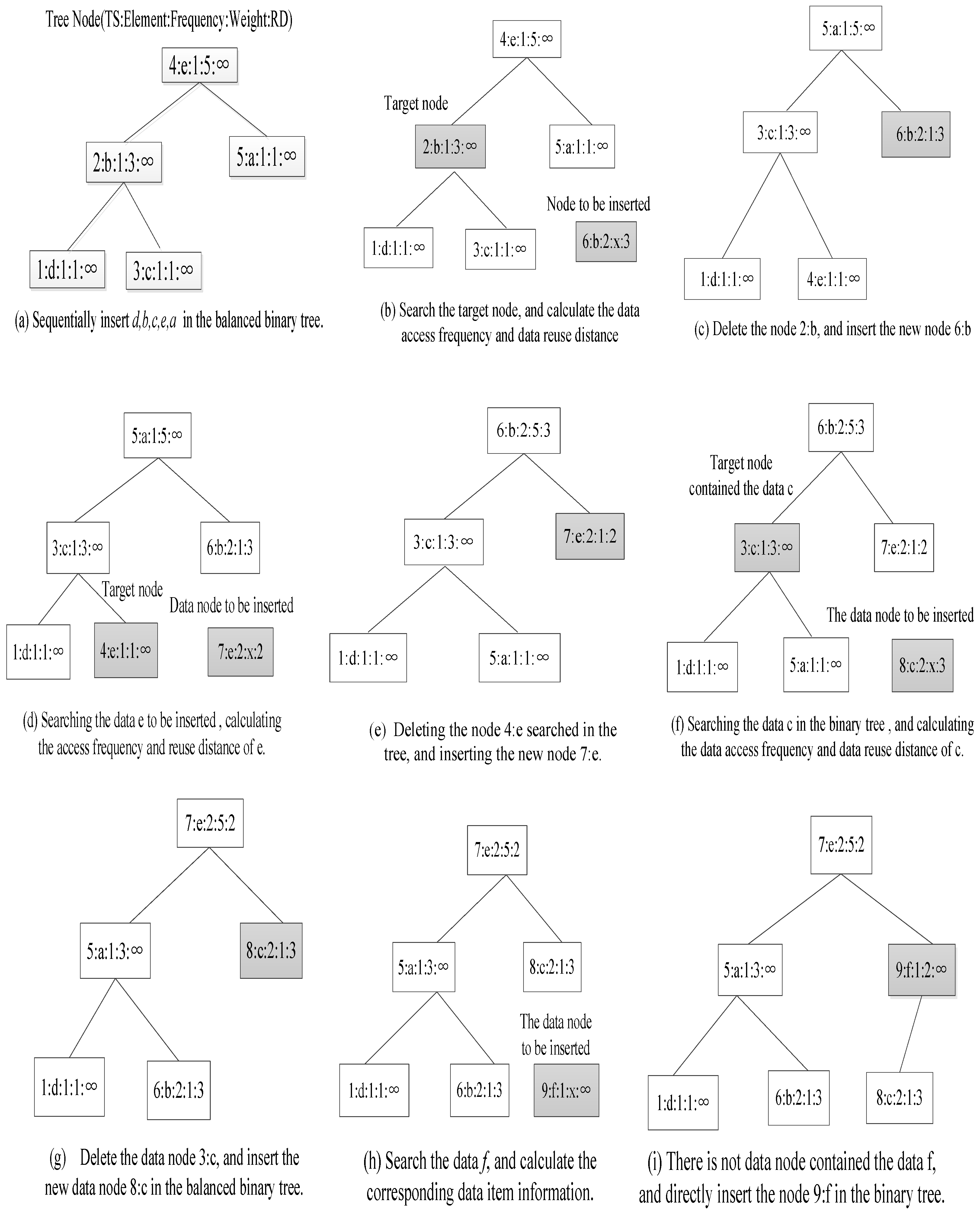
}.4.1.1. Collecting Thread Access Data
- (1)
- Initialization: define the data structure of new data node: Node (TS; Element; Frequency; Weight; RD), an empty binary tree.
- (2)
- Call Pin tool to scan threads access variables, and record time stamp ti and data element di.
- (3)
- Assign initial values to data item variables of new data node: TS = ti; Element = di; Frequency = 1; Weight = 1; RD = ∞.
- (4)
- Judge whether the data element of new data node is included into the current binary tree, and inorder traverse the binary tree.
- (5)
- If the data element has been contained in the data node of the current binary tree:
- Call the data reuse distance calculation function (shown in Algorithm 1) to calculate current data reuse distance RD.
- Count the data reuse frequency of new data node: the data reuse frequency equals to the data frequency value of current node plus one.
- Delete the current data node in the current binary tree.
- Adjust the balanced binary tree. The conventional AVL algorithm (balanced binary tree algorithm) is used to adjust the balanced binary tree based on the time stamp as a primary key.
- Insert the new node into the current balanced binary tree.
- (6)
- If the node is not contained in the current balanced binary tree, then directly insert the new data node into the binary tree.
- (7)
- Repeat steps (2)–(4), until all the access data of thread have been scanned. Generate the new balanced binary tree which contained all the memory access data, corresponding data access frequency, and corresponding data reuse distance information.
- (8)
- Adjust the data reuse distance which equals ∞ in the data node. The values ∞ are replaced with the M (refers to the number of data nodes in the current binary tree). The M is the value of Weight of root node, and it also refers to the max data reuse distance of current thread.
- (9)
- Finish the collecting access data of thread.
4.1.2. The Algorithm of Calculating Data Reuse Distance
- (1)
- Search the data node which contains the data to be inserted into the current binary tree. If the data node is not included, which means that the data is firstly accessed, and its data reuse distance is set as ∞.
- (2)
- If the data node is found in current binary tree, then the data reuse distance calculating process is as follows:
- (a)
- If the time stamp of the target node (Ntarget) is smaller than the time stamp of the root node (Nroot), it indicates that Ntarget is the left subtree node of Nroot. The data reuse distance equals the number of right subtree nodes plus the number of nodes which are included in the left subtree of Nroot and their time stamps are larger than the time stamp of Ntarget.
- (b)
- If the time stamp of Ntarget is larger than the time stamp of Nroot, it indicates that Ntarget is the right subtree node of Nroot. The data reuse distance is the number of nodes which are included in the right subtree of Nroot and their time stamps are larger than the time stamp of Ntarget.
- (3)
- Compare the data reuse distance of the current data with the original node in the binary tree, and set the smaller value as the final data reuse distance RD of the data node to be inserted in the binary tree in order to ensure the validity of data reuse distance.
- (4)
- In the left or right subtree of Nroot, the calculation process of the number of nodes in which time stamp is larger than the time stamp of Ntarget is as follows. (rd refers to the final number of node).
- (a)
- Set the initial value of rd as 0.
- (b)
- Assign the weight value of the right child node of Ntarget to rd, and set Ntarget as the current node Ncurrent.
- (c)
- Backtrack to the parent node of Ncurrent.
- (d)
- If the Ncurrent is not the root node, and its time stamp is larger than the Ncurrent, the rd equals to the weigh value of Ncurrent subtracts its left child weigh value. Set the current parent node as the Ncurrent, and go to the step (c).
- (e)
- If the time stamp of Ncurrent is smaller than Ntarget, then set the current parent node as the Ncurrent and go to the step (c).
- (f)
- If the Ncurrent is Nroot, then calculation is completed.
| Algorithm 1: Calculating data reuse distance algorithm. |
| 1 Input: Nroot, Ntarget |
| 2 Output: RD |
| 3 Begin |
| 4 RD = 0; |
| 5 if ((Ntarget ->TS) < (Nroot ->TS)) then |
| //Target node time stamp is smaller than the root node time stamp, |
| //the target node is the left subtree node. |
| 6 RD = (Nroot -> right_child.weight) + 1 + (Ntarget ->right_child.weight); |
| 7 p = Ntarget -> parent; |
| 8 while (p! = Nroot) |
| 9 if ((p-> TS) > (Ntarget -> TS)) then |
| 10 RD + = (p->weight)-(p->left_child.weight); |
| 11 p = p-> parent; |
| 12 else |
| 13 p = p-> parent; |
| 14 end if |
| 15 end while |
| 16 RD = (RD < Ntarget ->RD)? RD: Ntarget ->RD; |
| //Set the smaller value of data reuse distance between target node |
| // and current to be inserted node as the current data reuse distance. |
| 17 return RD; |
| 18 else |
| //The target node is in the right subtree of root node. |
| 19 RD = Ntarget -> right_child.weight; |
| 20 p = p->parent; |
| 21 while (p! = T) |
| 22 if ((p->TS) > (Ntarget -> TS)) then |
| 23 RD+ = (p-> weight)-(p-> left_child.weight); |
| 24 p = p->parent; |
| 25 else |
| 26 p = p-> parent; |
| 27 end if |
| 28 end while |
| //Set the smaller value of data reuse distance between target node |
| //and current to be inserted node as the current data reuse distance. |
| 29 RD = (RD < Ntarget -> RD)? RD: Ntarget ->RD; |
| 30 return RD; |
| 31 end if |
| 32 End |
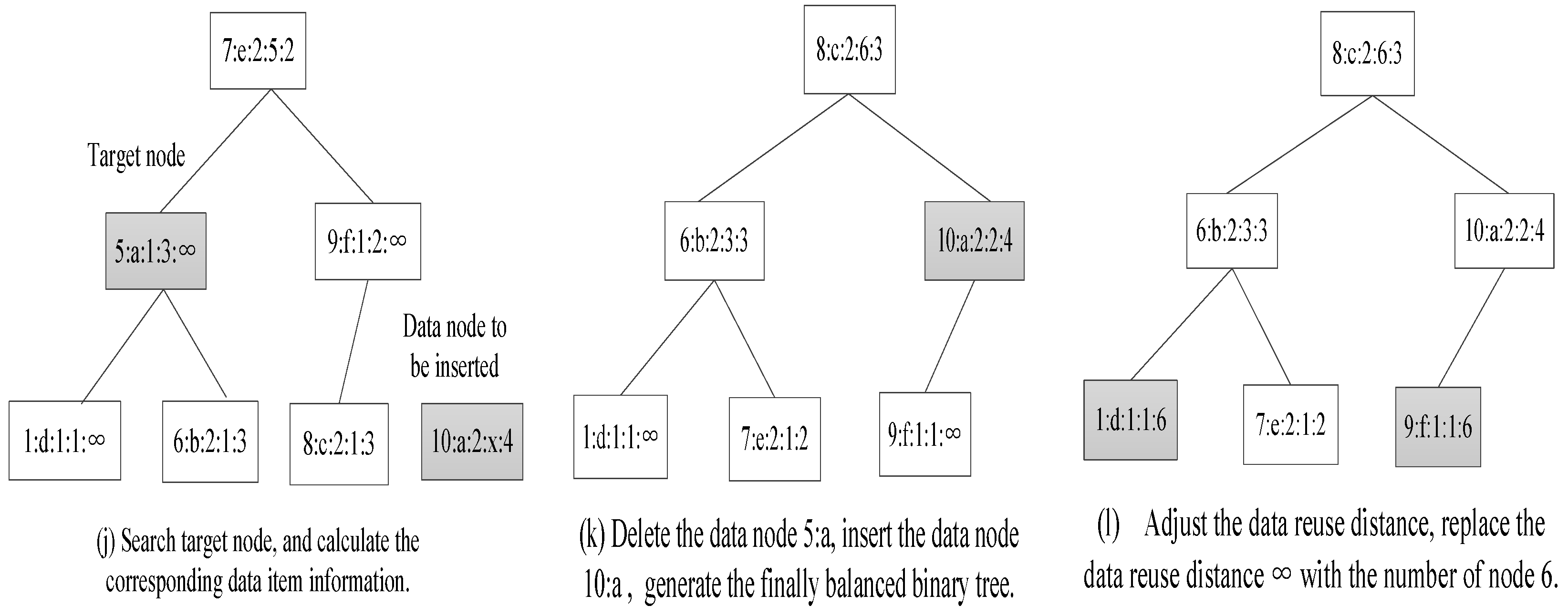
4.2. The Instance of Calculating Data Reuse Distance
4.3. The Average Data Reuse Distance of Thread
4.4. The Algorithm Complexity Analysis
5. Determining Data Affinity
5.1. Definition of Data Locality Pattern
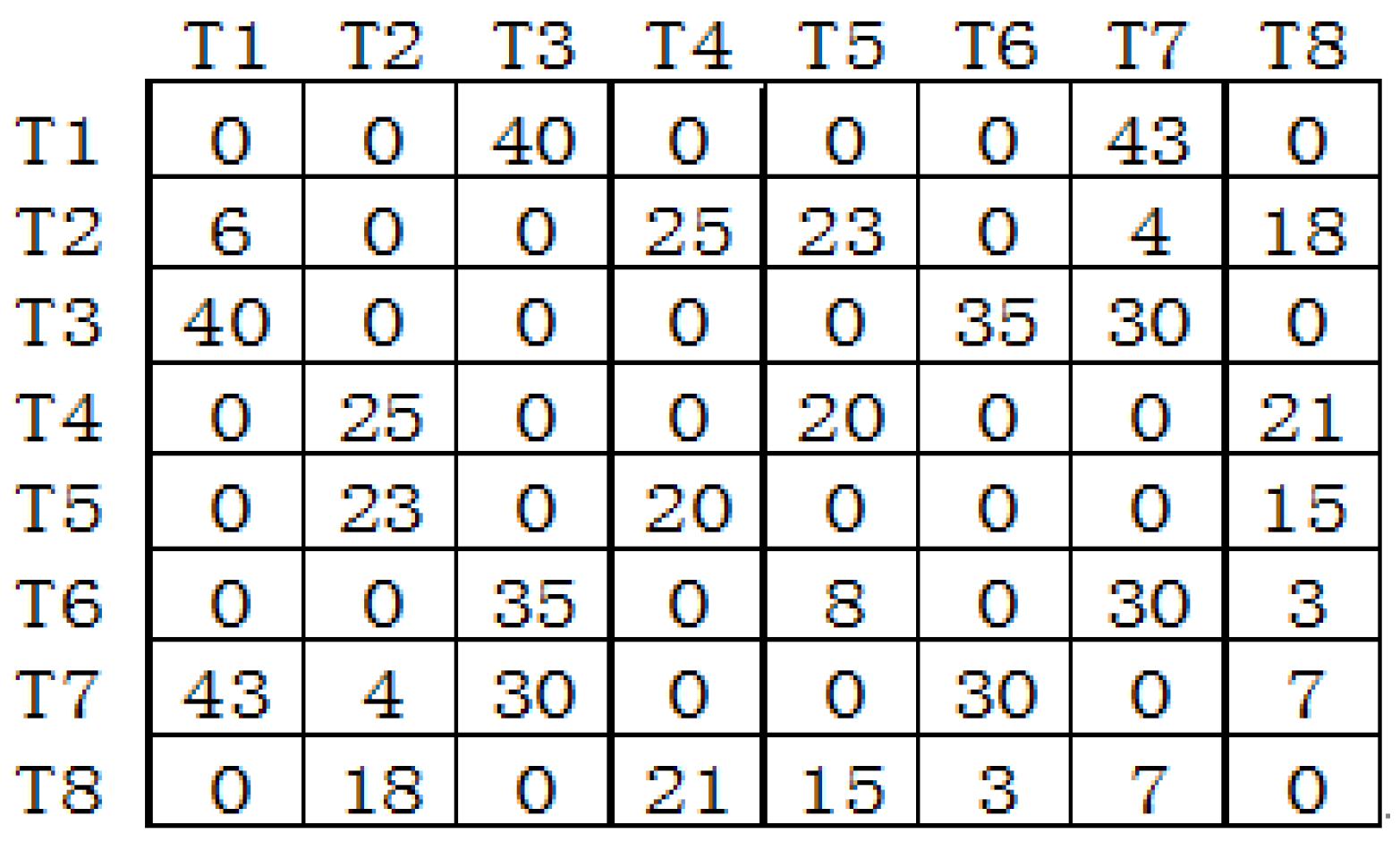
5.2. Quantifying Data Affinity among Threads
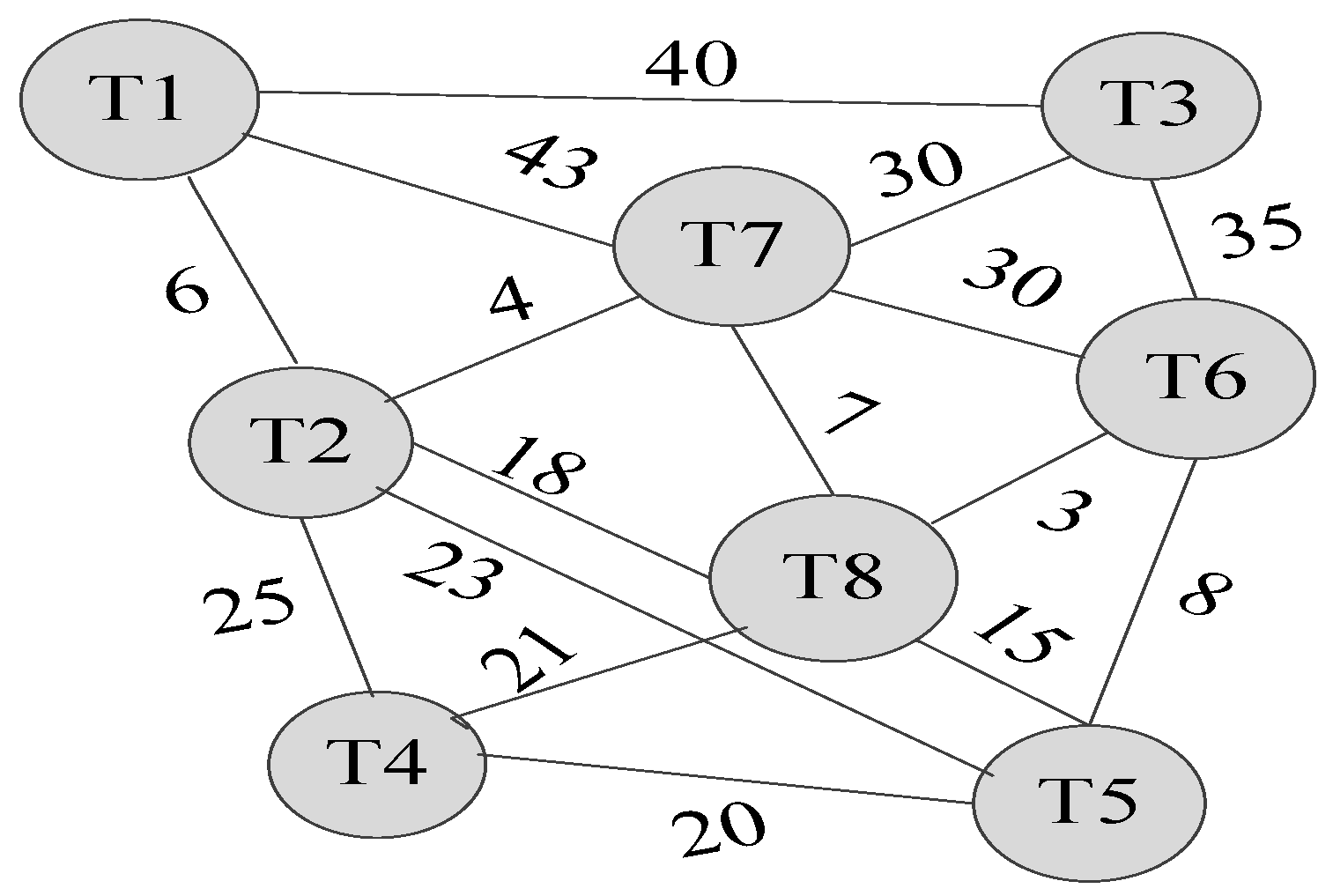
6. Threads Grouping Mapping
6.1. Threads Grouping
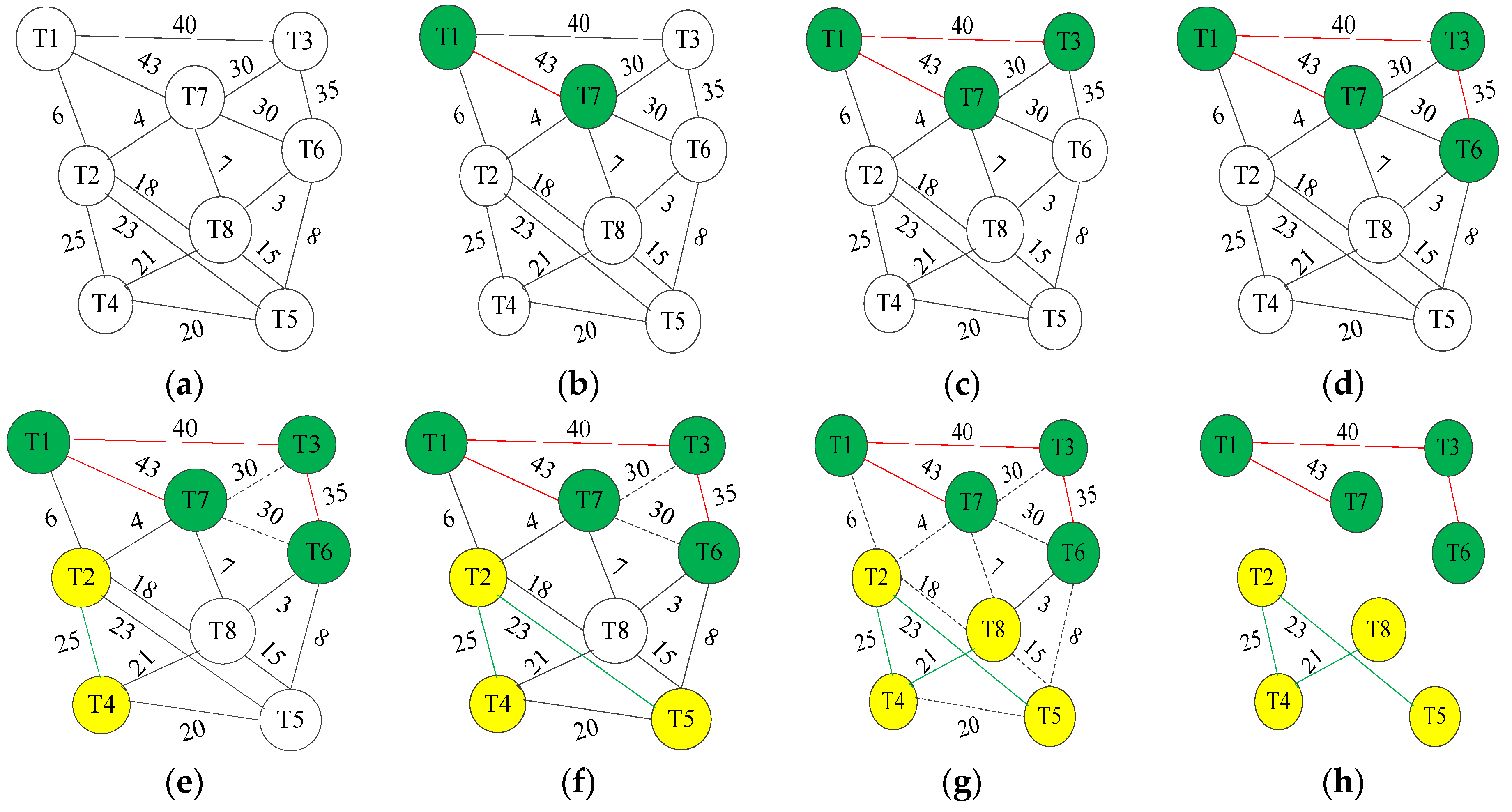
6.1.1. Affinity Subtree Spanning Algorithm
| Algorithm 2: Affinity Sub-tree Spanning Algorithm. |
| 1 Input: G = (V, E), Np. |
| 2 Output: STk (k = 1, 2, …, n). |
| 3 Begin |
| 4 K = 1; |
| 5 Search_max_weight_edge (G, E, STk); |
| //Searching the max weight values edge, and add it into the current subtree STk. |
| 6 while (V! = NULL) |
| 7 { |
| 8 do |
| 9 { |
| 10 Search_adjacent_max_weigh_edge (G, Ei, STk ); |
| //Searching the max weight edge connecting the current edge Ei, and add //it into the current subtree STk. |
| 11 } while (Vi < Np && V ! = NULL) |
| 12 end do |
| 13 Delete_adjacent_edge (G, STk ); |
| //Deleting adjacent edges are not to be included in the current subtree STk. |
| 14 Generate_subtree (STk); |
| //Generate the new subtree STk. |
| 15 K++; |
| 16 Search_max_weight_remain_edge (G, E-Ek-1, STk); |
| //Searching the max weight values edge in the remained graph G. |
| 17 } |
| 18 end while |
| 19 End. |
6.1.2. The Algorithm Complexity Analysis
6.1.3. Instance of Threads Grouping
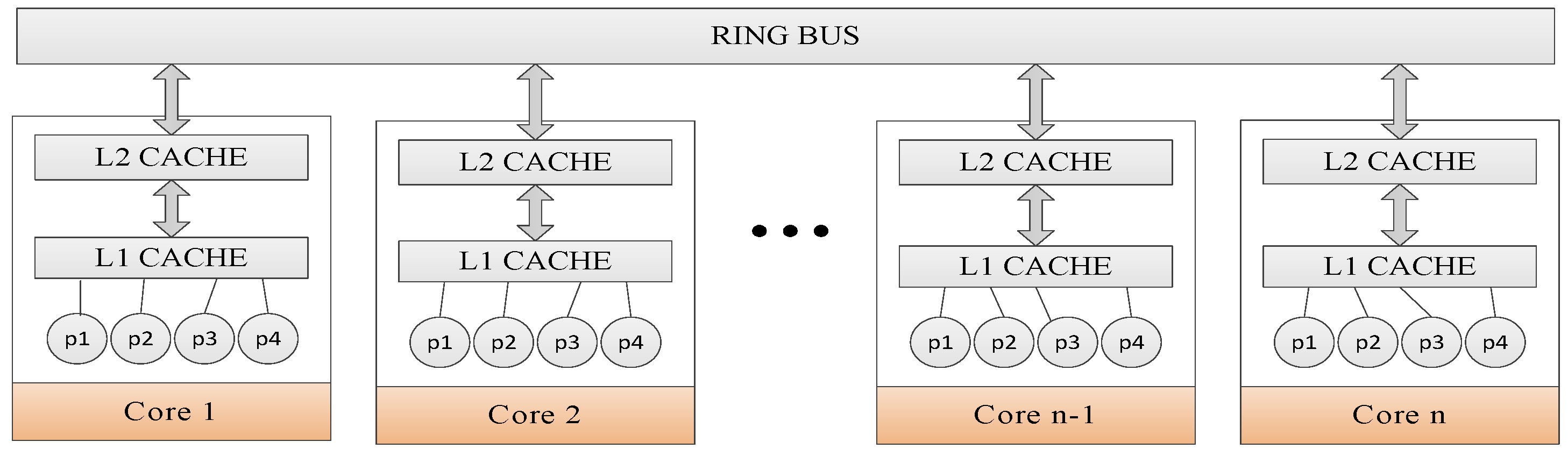
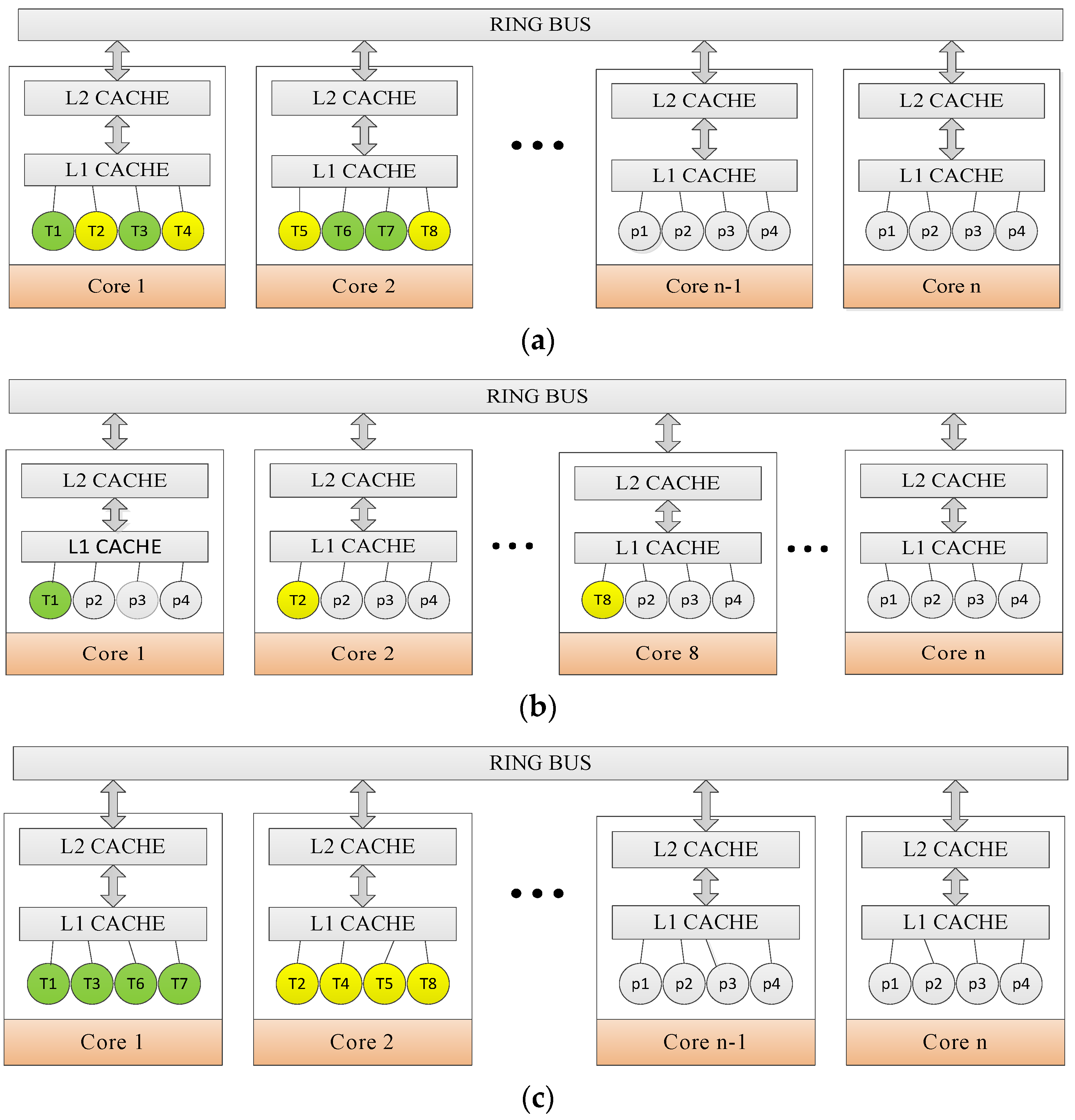
6.2. Mapping Rules
6.3. DagTM Implementation
7. Experimental Evaluation
7.1. Experimental Methodology
7.2. Experimental Results and Discussion
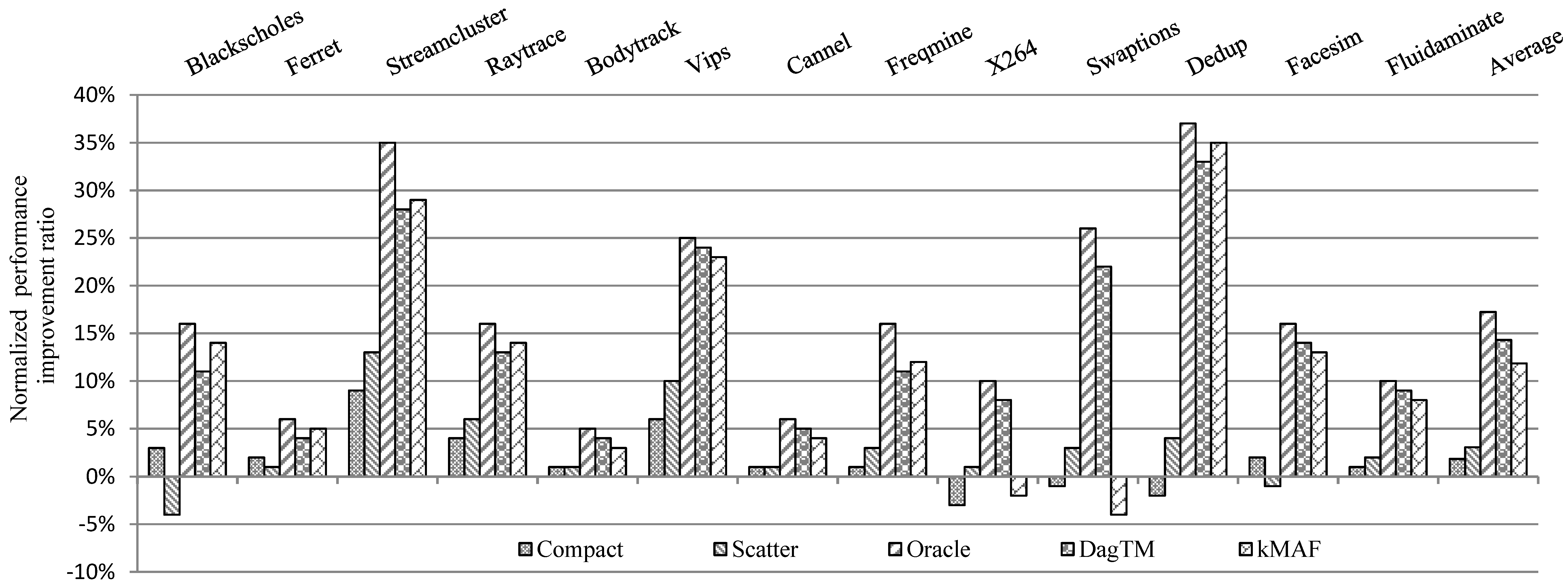
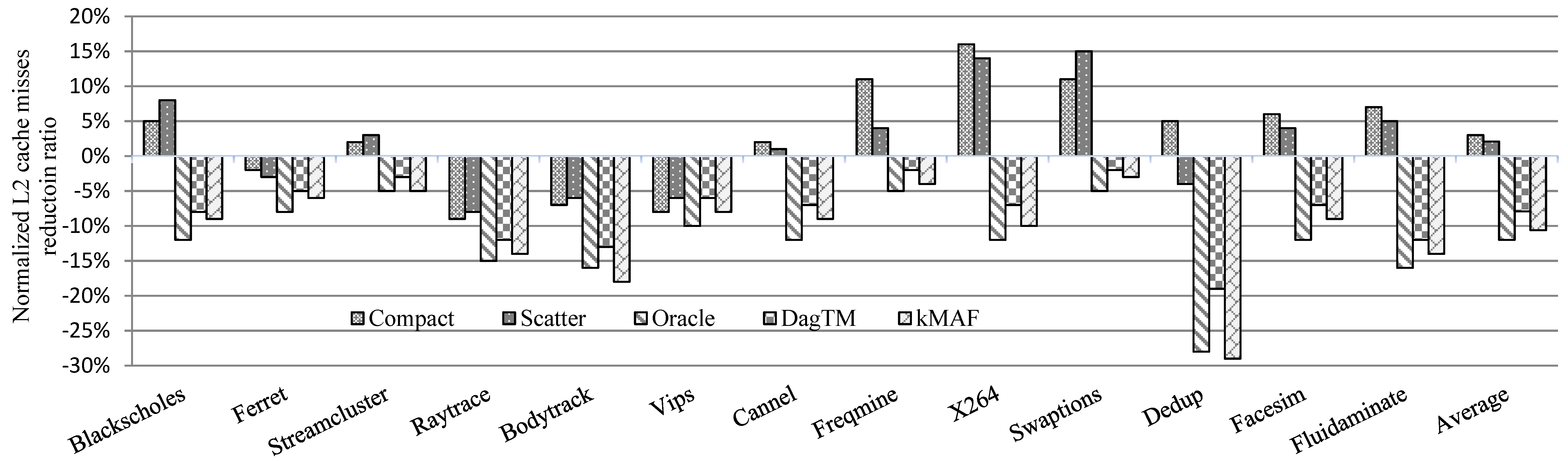
7.2.1. Computing Performance
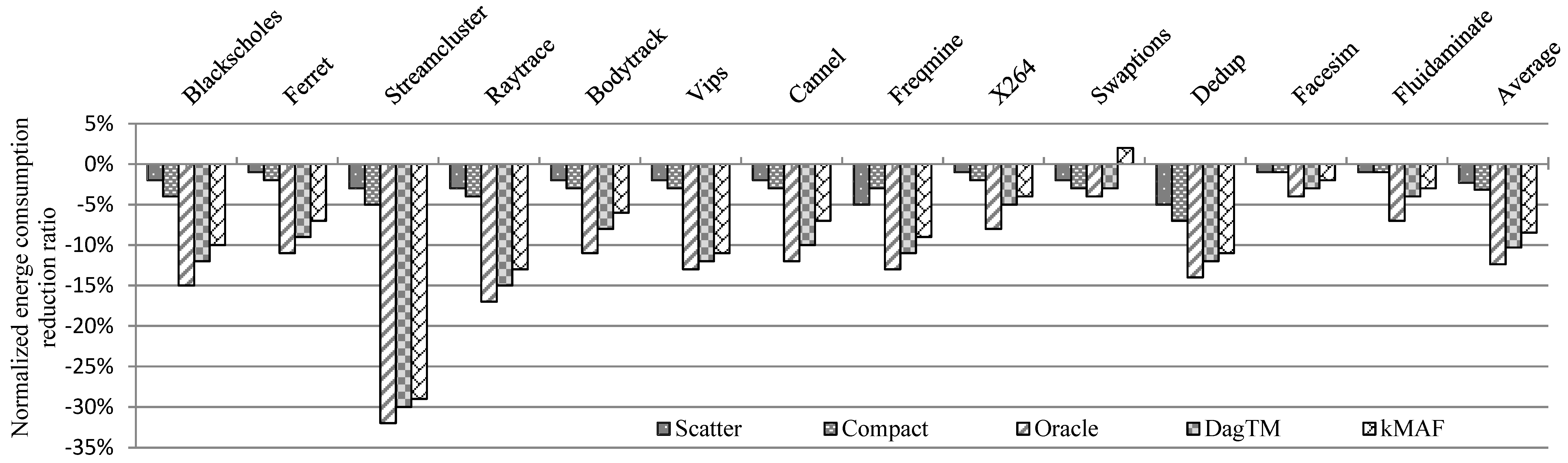
7.2.2. Energy Consumption
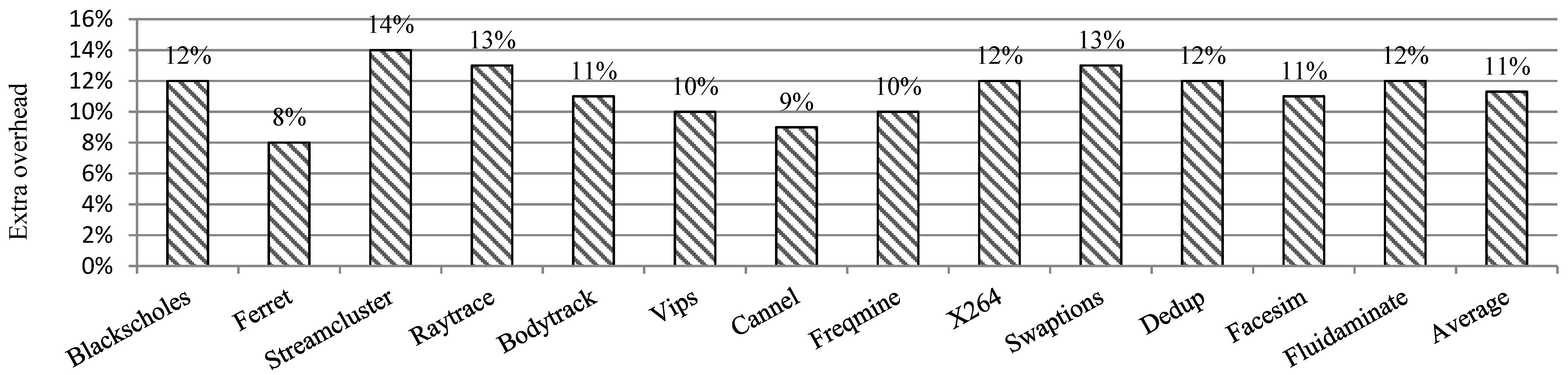
7.2.3. Overhead
8. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Brodtkorb, A.R.; Dyken, C.; Hagen, T.R.; Hjelmervik, J.M.; Storaasli, O.O. State-of-the-art in heterogeneous computing. Sci. Programm. 2011, 18, 1–33. [Google Scholar] [CrossRef]
- Liu, X.; Smelyanskiy, M.; Chow, E.; Dubey, P. Efficient sparse matrix-vector multiplication on x86-based many-core processors. In Proceedings of the 27th International ACM Conference on International Conference on Supercomputing, Eugene, OR, USA, 27 March 2013; pp. 273–282.
- Zhong, Y.; Shen, X.; Ding, C. Program Locality Analysis Using Reuse Distance. ACM Trans. Programm. Lang. Syst. 2009, 31, 341–351. [Google Scholar] [CrossRef]
- Bienia, C.; Kumar, S.; Singh, J.P.; Li, K. The PARSEC Benchmark Suite: Characterization and Architectural Implications. In Proceedings of the 17th International Conference on Parallel Architectures and Compilation Techniques, Toronto, ON, Canada, 25–29 October 2008; pp. 72–81.
- Jiang, Y.; Zhang, E.Z.; Tian, K.; Shen, X. Is Reuse Distance Applicable to Data Locality Analysis on Chip Multiprocessors? In Proceedings of the International Conference on Compiler Construction, Paphos, Cyprus, 20–28 March 2010; pp. 264–282.
- Zhang, Y.; Kandemir, M.; Yemliha, T. Studying inter-core data reuse in multicores. ACM Sigmetrics Perform. Eval. Rev. 2011, 39, 25–36. [Google Scholar]
- Drebes, A.; Heydemann, K.; Drach, N.; Pop, A.; Cohen, A. Topology-Aware and Dependence-Aware Scheduling and Memory Allocation for Task-Parallel Languages. ACM Trans. Arch. Code Optim. (TACO) 2014, 11, 1–25. [Google Scholar] [CrossRef]
- Lu, Q.; Lin, J.; Ding, X.; Zhang, Z.; Zhang, X.; Sadayappan, P. Soft-olp: Improving Hardware Cache Performance through Software-Controlled Object-Level Partitioning. In Proceedings of the 18th International Conference on Parallel Architectures and Compilation Techniques (PACT), Raleigh, NC, USA, 12–16 September 2009; pp. 246–257.
- Muralidhara, S.P.; Kandemir, M.; Kislal, O. Reuse Distance Based Performance Modeling and Workload Mapping. In Proceedings of the 9th Conference on Computing Frontiers, Caligari, Italy, 15–17 May 2012; pp. 193–202.
- Diener, M.; Cruz, E.; Navaux, P.; Busse, A.; Heiβ, H. kMAF: Automatic Kernel-Level Management of Thread and Data Affinity. In Proceedings of the 23rd International Conference on Parallel Architectures and Compilation Techniques (PACT), Edmonton, AB, Canada, 23–27 August 2014; pp. 277–288.
- Ding, W.; Zhang, Y.; Kandemir, M.; Srinivas, J.; Yedlapalli, P. Locality-Aware Mapping and Scheduling for Multicores. In Proceedings of the IEEE/ACM International Symposium on Code Generation and Optimization (CGO), Shenzhen, China, 23–27 February 2013; pp. 1–12.
- Cruz, E.; Diener, M.; Alves, M.; Navaux, P.O.A. Dynamic Thread Mapping of Shared Memory Applications by Exploiting Cache Coherence Protocols. J. Parallel Distrib. Comput. 2014, 74, 2215–2228. [Google Scholar] [CrossRef]
- Tousimojarad, A.; Vanderbauwhede, W. An efficient thread mapping strategy for multiprogramming on manycore processors. Parallel Comput. 2013, 25, 63–71. [Google Scholar]
- Marongiu, A.; Burgio, P.; Benini, L. Supporting OpenMP on a multi-cluster embedded MPSoC. Microprocess. Microsyst. 2011, 35, 668–682. [Google Scholar] [CrossRef]
- Poovey, J.A.; Rosier, M.C.; Conte, T.M. Pattern-Aware Dynamic Thread Mapping Mechanisms for Asymmetric Manycore Architectures; Technical Report; Georgia Institute of Technology: Atlanta, GA, USA, 2011. [Google Scholar]
- Weaver, V.; Johnson, M.; Kasichayanula, K.; Ralph, J. Measuring Energy and Power with PAPI. In Proceedings of the IEEE International Conference on Parallel Processing Workshops, Pittsburgh, PA, USA, 2012; pp. 262–268.
- Terpstra, D.; Jagode, H.; You, H.; Dongarra, J. Collecting performance data with PAPI-C. In Tools for High Performance Computing; Springer: Berlin/Heidelberg, Germany, 2010; pp. 157–173. [Google Scholar]
- Niu, Q.; Dinan, J.; Lu, Q.; Sadayappan, P. PARDA: A Fast Parallel Reuse Distance Analysis Algorithm. In Proceedings of the IEEE 26th International Parallel and Distributed Processing Symposium (IPDPS), Shanghai, China, 21–25 May 2012; pp. 1284–1294.
- Ju, T.; Zhu, Z.; Wang, Y.; Dong, X. Thread Mapping and Parallel Optimization for MIC Heterogeneous Parallel Systems. In Proceedings of the 14th International Conference on Algorithms and Architectures for Parallel Processing, Dalian, China, 24–27 August 2014; pp. 300–311.
- Xiang, X.; Ding, C.; Luo, H.; Bao, B. HOTL: A Higher Order Theory of Locality. In Proceedings of the 18th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), Houston, TX, USA, 16–20 March 2013; pp. 343–356.
- Bach, M.M.; Charney, M.; Cohn, R.; Demikhovsky, E.; Devor, T. Analyzing parallel programs with pin. IEEE Comput. 2010, 43, 34–41. [Google Scholar] [CrossRef]
- Schuff, D.L.; Kulkarni, M.; Pai, V.S. Accelerating Multicore Reuse Distance Analysis with Sampling and Parallelization. In Proceedings of the 19th International conference on Parallel Architectures and Compilation Techniques (PACT), New York, NY, USA, 11–15 September 2010; pp. 53–64.
- Cochran, R.; Hankendi, C.; Coskun, A.; Reda, S. Pack & Cap: Adaptive DVFS and Thread Packing under Power Caps. In Proceedings of the 44th Annual International Symposium on Microarchitecture, MICRO, Porto Alegre, RS, Brazil, 4–7 December 2011; pp. 175–185.
- Rodrigues, R.; Koren, I.; Kundu, S. Does the Sharing of Execution Units Improve Performance/Power of Multicores? ACM Trans. Embed. Comput. Syst. 2015, 14, 17. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time Stamp | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| data element | d | b | c | e | a | b | e | c | f | a |
| frequency | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 1 | 2 |
| reuse distance | ∞ | ∞ | ∞ | ∞ | ∞ | 3 | 2 | 3 | ∞ | 4 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ju, T.; Dong, X.; Chen, H.; Zhang, X. DagTM: An Energy-Efficient Threads Grouping Mapping for Many-Core Systems Based on Data Affinity. Energies 2016, 9, 754. https://doi.org/10.3390/en9090754
Ju T, Dong X, Chen H, Zhang X. DagTM: An Energy-Efficient Threads Grouping Mapping for Many-Core Systems Based on Data Affinity. Energies. 2016; 9(9):754. https://doi.org/10.3390/en9090754
Chicago/Turabian StyleJu, Tao, Xiaoshe Dong, Heng Chen, and Xingjun Zhang. 2016. "DagTM: An Energy-Efficient Threads Grouping Mapping for Many-Core Systems Based on Data Affinity" Energies 9, no. 9: 754. https://doi.org/10.3390/en9090754