1. Introduction
Multi-dwelling residential buildings are currently being constructed in areas with high population densities since these buildings can offer many houses within a limited urban space. This type of building allows residents access to workplaces and conveniences as well as economic benefits to society. Though multi-dwelling residential buildings have various advantages, they also have inherent problems due to their structural characteristics: shared floor, ceiling, and walls. In multi-dwelling residential buildings, any source of noise generated within a unit can be transmitted to adjacent units through those shared components. Specifically, the floor impact sound is generally more severe than others and can lead to troubles or even lawsuits between neighbors.
Many countries have established standards for quantifying floor impact sounds. The U.S. Department of Housing and Urban Development (HUD) [
1] has categorized five usages, and three steps for indoor rooms and floor impact sounds, respectively. European countries have similar standards to the United States regarding lightweight floor impact sounds. For example, Denmark, Norway, Finland, Estonia, and Poland stipulate the minimum standard of lightweight impact sound at 53 dB, while Sweden, Slovakia, and Latvia stipulate the standard at 58 dB [
2]. Japan has individual standards for lightweight, and heavyweight impact sounds [
3], and the performance of the dwelling is classified into five levels according to the sound insulation performance based on the evaluation criteria curve. The Republic of Korea has a standard to prevent noise using floor impact sound isolation structures [
4]; the structure has to limit lightweight and heavyweight impact sounds under 58 and 50 dB. The standard proposes three types of floor structures based on these decibel limits. The thickness of the concrete slab, resilient material, finishing, and mortar was considered to control the level of impact.
To mitigate the floor impact sounds, the use of resilient materials within floor slabs has recently become popular in research and construction practice [
5,
6]. These materials are typically defined to have characteristics such as impact sound-absorbing and vibration damping. Theoretically, increasing the floor slab thickness can alleviate the transmission of floor impact sound and vibration. However, this remedy will also unnecessarily increase the self-weights of the floor slabs, and result in increased structural demands for the entire structural system; eventually, the construction cost will inevitably go up. Therefore, resilient materials exhibiting superior soundproofing performance without sacrificing structural performance have been widely implemented in modern building construction. Various resilient materials such as expanded polystyrene (EPS), ethylene-vinyl acetate (EVA), and polyethylene (P.E.) have been developed and applied to numerous building construction. To maximize the effectiveness of such resilient materials, many standards, including ISO, have been developed to characterize the material properties of resilient materials such as density, dynamic stiffness, loss coefficient, residual strain, and heat conductivity [
7]. Many of these current standards are only based on short-term loading experimental results [
6,
8,
9]. For example, ISO 29770 [
10] and KS F 2873 [
11] limit the residual strains based on 11-min experimental results under different loading conditions. However, floor resilient materials are continuously exposed to loads for its service life. The material properties per the standards using a short-term loading history may not be adequate to predict the long-term performance of floor resilient materials [
12]. Also, the nonhomogeneity of the materials and the slab deflection caused by the service loading conditions could lead to cracking of the entire floor system, leading to a reduction in the sound insulation performance [
13]. Such a shortage makes the research on the long-term deflection of sound resilient structural material necessary.
Experiment-based studies are intrinsically data-driven. Classically, researchers gather the experimental data and extract an empirical formula or a model that can best describe the behavior of the material under question within the collected information. However, as the behavior of the material becomes highly nonlinear, the formula becomes more complex and harder to use. To ease the usage and eventually be free of a visible formula, we can utilize the emerging machine learning approach to estimate the material behavior. The data-driven property of material behavior study also makes it an excellent candidate to apply the machine learning strategy.
Applications of machine learning algorithms have shown reasonably good results in various engineering fields. Artificial neural networks (ANN) and linear regression have been used to predict the performance of a diesel engine [
14]. The use of ANN provided more accurate test results than the use of linear regression modeling. Machine learning algorithm approaches were reviewed to estimate concrete material properties such as flow, slump, strength, and serviceability [
15]. Backpropagation neural network and self-organization features were used to estimate concrete properties. This study reported that the repeated random subsampling method was recommended to reduce statistical bias. A multilayer feed-forward ANN creep behavior was developed to enhance asphalt mixtures creep compliance predictions [
16]. Hot mix asphalt (HMA) creep compliance behavior can be predicted using an ANN model in a short amount of time with a low error rate. A first-order multiple linear regression was developed to predict the permanent deformation behavior of the plant produced asphalt concrete mixtures [
17]. The produced linear regression model was compared to an existing model, and the results showed an improved performance of the developed model in the study. ANN and adaptive neuro-fuzzy inference system models were proposed to predict the shear strength of grouted reinforced concrete masonry walls [
18]. The ANN and neuro-fuzzy inference system models well predicted the test results and obtained improved performance as compared to the existing empirical models. ANN could well describe the behavior of the magnetorheological elastomer base isolator [
19]. Also, many ANN models have been considered and proposed to predict the compressive strength of concrete [
20,
21].
It must be noted here that the machine learning approach used for this purpose still falls into the regression analysis. Regression analysis is a statistical process to estimate the relationship between dependent variables and independent variables. The machine learning approach is doing the regression analysis that the conventional way—non-computer-based—does, except for the computational efficiency.
This paper presents a technique to predict the long-term compressive deformation of resilient materials using novel machine learning algorithms: K-nearest neighbors (KNN), regression tree (RT), and artificial neural networks (ANN). A compressive creep test results over 350 and 500 days were used to train and evaluate the machine learning algorithms. First, the above-mentioned machine learning algorithms were trained using the actual data set. Then, the predictions obtained from the trained algorithms were compared to the prediction by ISO 20392 procedure. ISO 20392 provides a means to evaluate the compressive creep of resilient material [
22]. This standard, however, allows us to measure the compressive deformation for the first 90 days. The long-term compressive responses of resilient materials after the first 90 days are estimated based on Findley’s equations [
23]. The accuracy and reliability of Findley’s equations are yet questionable in this situation because of two reasons. First, Findley’s equations are developed based on the test results of plastic laminates. Those equations do not account for the variable shape of resilient materials. Second, the predictions are typically based on relatively short-term loading tests (90-day compressive creep tests).
The two estimations are compared with the measured data points, and the long-term deformation prediction ability will be evaluated.
3. Learning Algorithms
In this section, the learning algorithms used in this article are briefly introduced. Three algorithms are considered, namely, distance-weighted k-nearest-neighbor regression (KNN), regression tree (RT), and artificial neural network (ANN).
3.1. Distance Weighted KNN Regression
The k-nearest neighbor (KNN) algorithm is intrinsically suitable for such increasing relationships because it involves neighboring data points and, therefore, sensitive to the local slope. For a given set of data
, where vector
denotes a collection of
i-th input features and scalar
denotes the corresponding output label, distance weighted KNN regression predicts the label
for a query
as the distance weighted average of
k nearest neighbors of
, where
k is a preselected parameter. In other words,
where,
KNN is a type of instance-based learning algorithm. The learning in this algorithm is done by simply storing the provided training set
S in the computer’s memory space. Then, in the later querying step, the algorithm loads the
k number of nearest neighbors of the query point
and returns the predicted label
by the predefined mechanism. This method does not construct any model that spans the entire instance space but instead finds a local approximation in the neighborhood of the query point, which, in turn, has a significant advantage when the model is expected to be very complicated. However, the query time may be very long, since the algorithm must investigate every data point in
S to find the nearest
k neighbors in the worst case, and may have large memory costs since the prediction must inquire of
S. Additional regression details such as equations for KNN can be found in Kim et al. [
19].
3.2. Regression Tree
The regression tree (RT) algorithm if the ranges are adequately divided since the local slopes will be better expressed. RT builds a binary decision tree with the given training set S. Starting from the root node, the algorithm tracks down the branches of the upside-down tree with the given query point until reaching the terminal node, also known as the leaf node. Depending on the split value that determines which branch to track down, there are subcategories of trees. The most commonly used norm is the correlation coefficient between each feature in and the corresponding label ; however, one can also randomly select any feature in to decide which branch to follow. The leaf size is a user tunable parameter that must be carefully selected. Smaller leaf size leads to overfitting and degrades the prediction accuracy. Bigger leaf size, on the other hand, tends to average all the data in S and ultimately gives no meaningful information. It is recommended to either sweep through every leaf size to seek an optimal leaf size or implement some strategy such as bagging or boosting to introduce regularity. Learning in RT is implemented as building the tree with given S, and S can be forgotten after the learning is finished since the querying is done with the RT, not with S. Such implementation expedites the query time compare to KNN; however, the whole tree must be rebuilt if one wants to add additional data points.
In this article, RT with the highest correlation coefficient is implemented, and the algorithm is as follows:
Step 1 Let , be the length d vectors where , indicates the j-th feature of i-th instance among N instances in S. The corresponding label is a scalar value . Then, for every feature j in , , calculate the correlation coefficient with the labels , , and select the feature j that has the highest correlation coefficient.
Step 2 Let j be the highest correlated feature to . Take the median among as the value to binary split the node and form two children nodes. Denote the split value as c.
Step 3 Training set S has now been split into two subsets with respect to c, namely and where and is an empty set. Repeat Steps 1 and 2 for subsets and until the number of elements in all of the subsets becomes less than or equal to the predefined leaf size.
Once the tree is built, for a given query point
, the algorithm tracks down the tree from the root node and returns the prediction
when it reaches the leaf node.
can be taken as the mean of
’s in the destination leaf node, since there can be multiple
’s in a leaf. The value other than the mean of
’s can also be considered, whatever is appropriate. Additional regression details such as equations for RT can be found in Kim et al. [
19].
3.3. Artificial Neural Network
The artificial neural network (ANN) algorithm is robust when the data points have random change over the entire range, such as abrupt jumps. The ANN algorithm possesses a mechanism to include all patterns appearing in the whole range. Thus, the ANN is presumed to be less suitable for the present application than the other two methods. ANN superficially mimics the biological nerve system, although many details are neglected in implementation. When there is an input and output , many computational units called neurons are arranged in layers between inputs and outputs. Each neuron in a layer is linked to other neurons in other layers, and ultimately to the inputs and outputs with some weights. These layers and weights are usually out of consideration after the training is completed since the one we find useful is the trained model, not the optimum layer configuration and weights; therefore, we say that these layers are hidden. The number of neurons in the hidden layers and the number of layers in a model is typically determined through trial and error, which is a significant shortcoming of this algorithm. However, once an optimum configuration is found, the querying is implemented relatively swiftly.
The training in this algorithm is the process of finding an optimal set of weights that connect the neurons in layers. Depending on the method of optimizing the weights to fit the given dataset
S at best, the direction of the data flow, and other detailed implementation specifics, ANN can be categorized into several different types. In this article, we relied on by far the most popular method, called the feed-forward, backpropagation method, where the data moves in one-way from the input to the output through hidden layers, and the error terms at the end of each trial, also known as an epoch, propagate back to the lower layer, and the weights are iteratively adjusted in every epoch until they converge. A schematic of this is shown in
Figure 3.
For this particular application, the model landed at two hidden layers, where each layer consists of 50 neurons. Sigmoid activation function was used that gave the highest fidelity compared to the others, which were also chosen by trial and error. The dataset was divided into ten subsets, where nine were used for training, and one was used for validation. There are ten possible combinations to group the training set and validation set in this approach, and all ten combinations were used for training the ANN model. (
Figure 4.) Additional regression details such as equations for ANN can be found in Kim et al. [
19].
4. Results and Analysis
In this section, the predictions of long-term compressive deformation responses using three machine learning algorithms are presented. Those algorithms were trained using the experimental test results presented in
Section 2. The accuracy of the predictions made by the trained models is evaluated by comparing them with the experimental observations and predictions based on ISO 20392. Specifically, the authors focused on the capabilities of the trained algorithms regarding the long-term deformation predictions compared to the estimations per ISO 20392. Lastly, the feasibility of each machine learning algorithm for application in the long-term compressive deformation prediction was discussed.
4.1. Test Results
The long-term compressive deformation tests on six soundproofing resilient materials were conducted. Their deformations were monitored for periods of 350 days (for the specimens loaded at both 40 and 80 N) and 500 days (for the specimens loaded at 250 and 500 N).
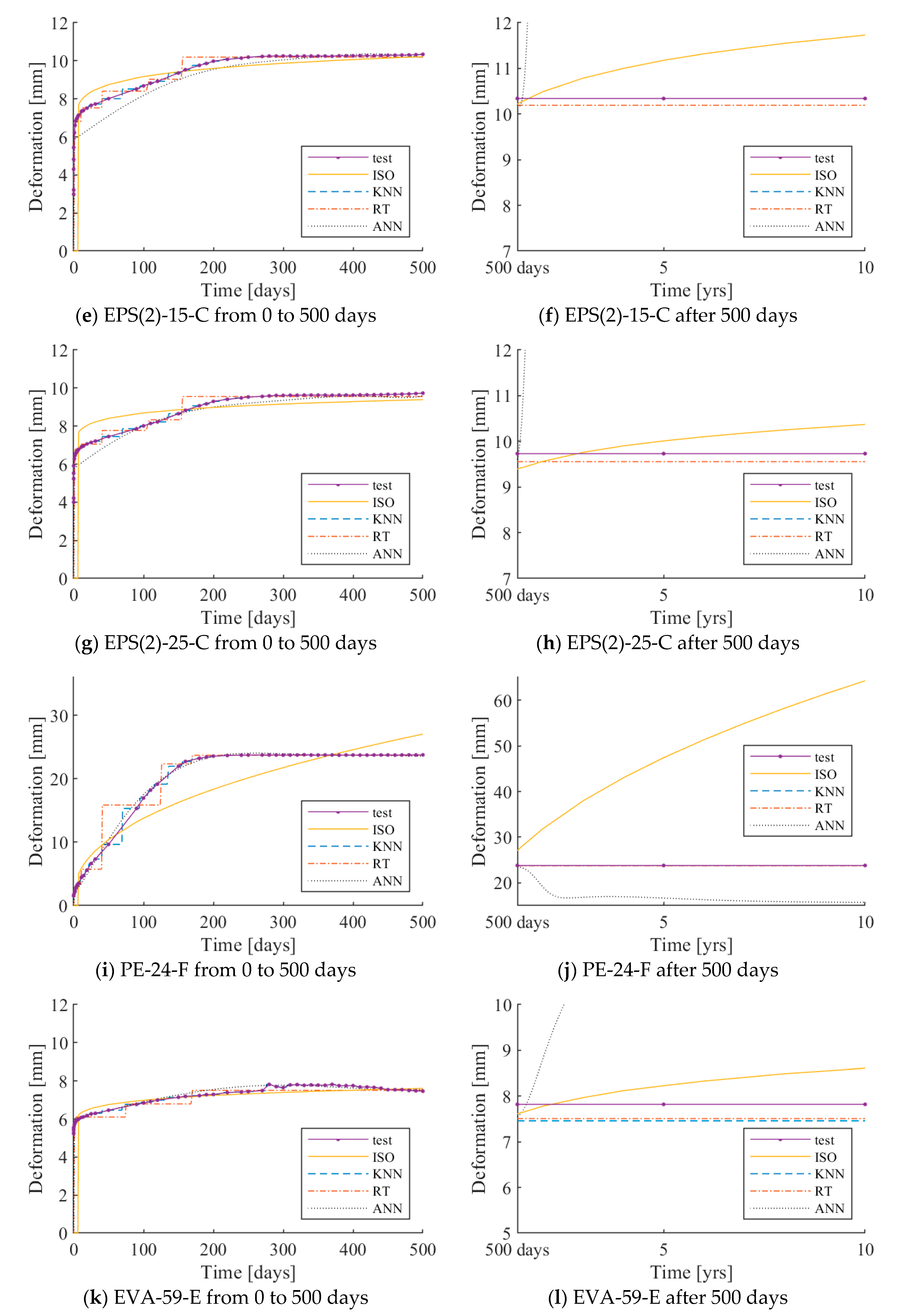
Figure 5 shows the deformations of each specimen under various loading conditions over time. It can be seen that the long-term deformations of the models asymptotically approach their horizontal asymptotes.
The long-term deformation varied depending on the mechanical properties, specimen dimensions, and loading situations of resilient materials. The larger the applied load, the greater the increment in long-term deformation was observed; however, they were not proportional to the applied loads.
PE-24-F deflected the most in all loading cases, while EPS 2 deflected more than EPS 1. In particular, the PE-24-F specimen showed deformations of 23.9 and 27.2 mm under 250 and 500 N loads, respectively, which is more than 80% deformation as compared to the initial thickness (30 mm). The deformation in the specimens with the corrugated bottom shape was larger than that of flat bottom shape. In the resilient materials with identical materials and bottom shape, the deformation was larger for the specimen with lower density. Across all specimens, deformations were observed when the applied load was 80, 250, and 500 N; however, no deformation could be recognized as long-term deformation when they were lightly loaded (40 N).
The deformation trend in all loading cases was similar across all specimens. The increment in deformations was large at the initial stage of loading and gradually decreased until they sufficiently reached their asymptotes. This trend was more apparent when the specimens were subject to heavier loads: 250 and 500 N.
4.2. ISO 20392 and Trained Models’ Predictions
Here, the long-term deformations of resilient materials estimated by ISO 20392 and by our trained learning algorithms are compared to the actual measured data, and their estimation quality and accuracy are discussed.
ISO 20392 calculates the long-term compressive deformation using Equation (1). The input parameters required for the calculation are brought from the experiment settings. The equation uses information on a period up to the first 90 days only.
where,
In this equation, Xt indicates the deformation at time t, X0 is the initial deformation, xm and ym are averages of xt and yt, respectively, xt is time (logt), and yt = creep (logXct, Xct = Xt − X0).
Various k values for KNN, tree depth, and leaf size for RT, and hidden layer configuration and choice of activation functions were considered to identify the best-trained models with the minimum root mean squared error (RMSE). KNN utilized three different distance weighting: No distance weighting, weighting by 1/distance, and weight by 1-distance. The minimum total weight of the instances in a leaf of RT was two. In the case of KNN, the value of the weighted KNN was four, with one over distance weighting. The tree depth of RT was limited to 10, and two hidden layers where each layer consists of 50 neurons were used for ANN and iterated for 1000 epochs.
The correlation coefficients and various errors between the test data and trained models plus ISO 20392 are tabulated in
Table 3 for comparison. The average of the correlation coefficients of KNN, RT, and ANN was 0.9973 in the in-sample test, which implies that the trained models reflect the test results very well. However, when the data are extrapolated beyond 350 or 500 days, the prediction by ANN deviates very far from the rational region, and so must be rejected.
KNN returned the most accurate result among the trained models, including ISO 20392; the correlation coefficient increased by 6.1%, and the RMSE decreased by 43.4% with respect to ISO 20392. The evaluation of ISO 20392 was also done with a full range of test data, while the equation takes only the first 90 days of observation for the calculation. Thus, the rest of the data by ISO 20392 up to 350 or 500 days is extrapolated, and the assessment is not strictly an in-sample test. Taking note of this fact, the accuracy assessment of ISO 20392 in terms of correlation coefficient and other error measurements gives a good sense of the long-term deformation prediction ability of ISO 20392. It turns out that ISO 20392 is the worst compared to the trained models, which indicates that ISO 20392 does not accurately predict the long-term behavior of the resilient materials, and the use of a learning algorithm is justified.
The test results under 250 and 500 N loadings are plotted with the ISO 20392 equation, and the predictions by each of the three learning algorithms are presented in
Figure 6 and
Figure 7, respectively. The same graphs for 40 and 80 N loadings can be found in the
Appendix A. The x- and y-axes indicate the load application time and deformation of the resilient material, respectively. The solid curve with markers and dotted curve indicates the test results of the resilient materials and the ISO 20392 equation, respectively. The three different types of curves represent the deformation – time responses as predicted by the three learning algorithms.
In the case of the prediction curve using ISO 20392, the predicted curve before 90 days was nearly the same as the test results, except for PE-24-F. Since the ISO 20392 equation depends on the test results of 90 days, large deformations occurring after 90 days are not reflected. The step-wise shape of the predictions observed in KNN and RT is due to the sparsely distributed test data, as the gradient of the deformation in time is very steep in the early stage of loadings. Increasing the parameter k in KNN can alleviate this trend; however, doing so increases RMSE. Therefore, the value of N.N. is set to one in this study. In the case of the ANN algorithm (multilayer perceptron), the algorithm predicts the test results well within the range of the actual test data. However, the prediction deviated sharply after 500 days.
Table 4 and
Table 5 show the measured and predicted long-term deformations of the resilient materials under 250 and 500 N loadings, respectively. Since the KNN algorithm showed the smallest RMSE, the results of the deformation prediction of the KNN algorithm are shown in the table.
The long-term deformation after 500 days, as calculated using ISO 20392, tends to increase gradually. In PE-24-F, the deformation estimated to occur after ten years was more than the initial thickness. Therefore, it is difficult to predict the long-term deformation of all of the resilient materials by the ISO equation. The long-term deformation using the KNN model did not increase after a certain point and converged. The tendency of the long-term deformation was nearly the same as the actual test results. This observation implies that the deformation prediction of the resilient materials using the KNN model is valid.
5. Conclusions
Whenever a new building material is considered in the design, it is important to understand their mechanical properties, structural performances, and long-term behaviors to ensure the safety of the structure during its service life. This article measured the long-term deformation of acoustically resilient material over 500 days. It then adopted a machine learning technique to build models that can accurately predict the resilient material’s asymptotic behavior over more extended periods.
Four loading conditions were considered, and six resilient material specimens were prepared to test the long-term deformations of the new materials. The measured data were then fed into three different machine learning algorithms, KNN, RT, and ANN, to train the models. Then, the predictions from each of the trained models were compared to the ISO 20392 prediction and the experimental test data to see how closely the trained models could estimate the long-term behaviors of resilient materials, and in turn, their potential for supplementing the shortcoming inherent in ISO 20392.
The main scope of this experimental study was the comparative analysis of the regression algorithms that could be applied to resilient materials among construction materials. Among the three different algorithms, the KNN algorithm was determined to predict the long-term behavior of the resilient materials usefully.
The conclusions of this study are summarized as follows:
- (1)
The compressive deformation of resilient materials varied depending on the material type, base shape, and density. Under the same long-term loading conditions and bottom patterns, both EPS 1 and EPS 2 deformed more than the others. The specimens with a corrugated or embossed bottom shape experienced more long-term compressive deformation. Also, the results of resilient materials with a higher density show that the amount of compressive deformation was less in denser resilient material.
- (2)
The predicted deformation responses using all three algorithms – KNN, RT, and ANN –could reasonably predict the actual experimental data, regardless of material properties. However, the predicted long-term responses using ANN showed significant deviations. Meanwhile, KNN and RT showed reasonable predictions for long-term deformation, which could supplement ISO 20392.
- (3)
The ISO 20392 model underestimates the long-term deformation response of PE-24-F. Such underestimation is because Findley’s equations (i.e., ISO 20392 model) were developed based on compressive creep tests on plastic laminates. As such, the ISO 20392 model is inappropriate for resilient materials which have variable shapes and nonhomogeneous material properties. However, machine learning techniques trained using an appropriate set of experimental test data are capable of accurately predicting long-term compressive deformation.
Extending the result of this literature can lead us to approach other novel constructional material’s behavior estimation using machine learning. We can also assess the results of structural analyses in two different paths: one with the structural member’s behavior calculated by the classical approach and the other with machine learning algorithms. Such comparison can provide us the confidence on the answers given by the machine learning approach, and ultimately provide the grounds for it to be used in practice.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}