
XAS Data Preprocessing of Nanocatalysts for Machine Learning Applications




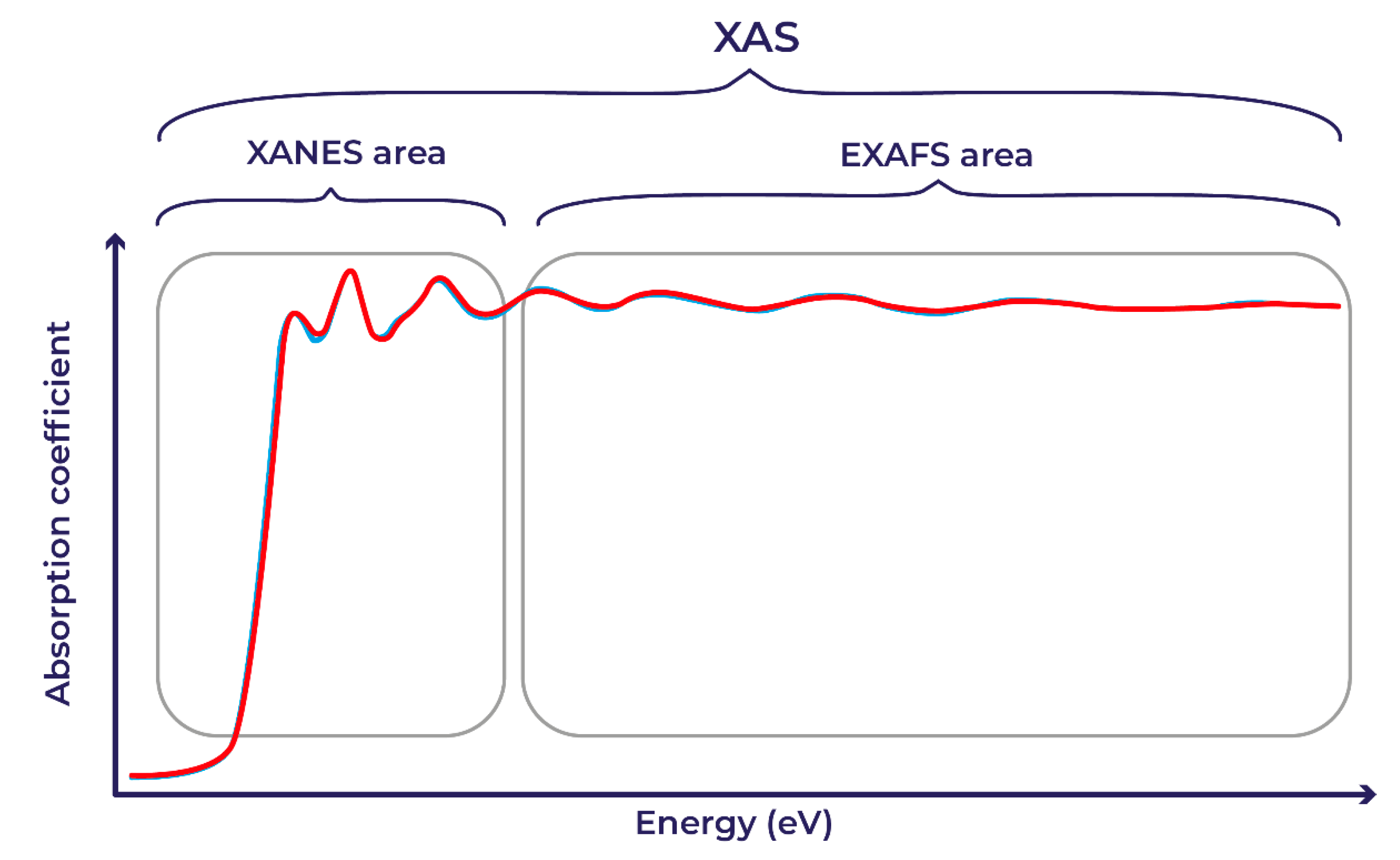{kind=link}
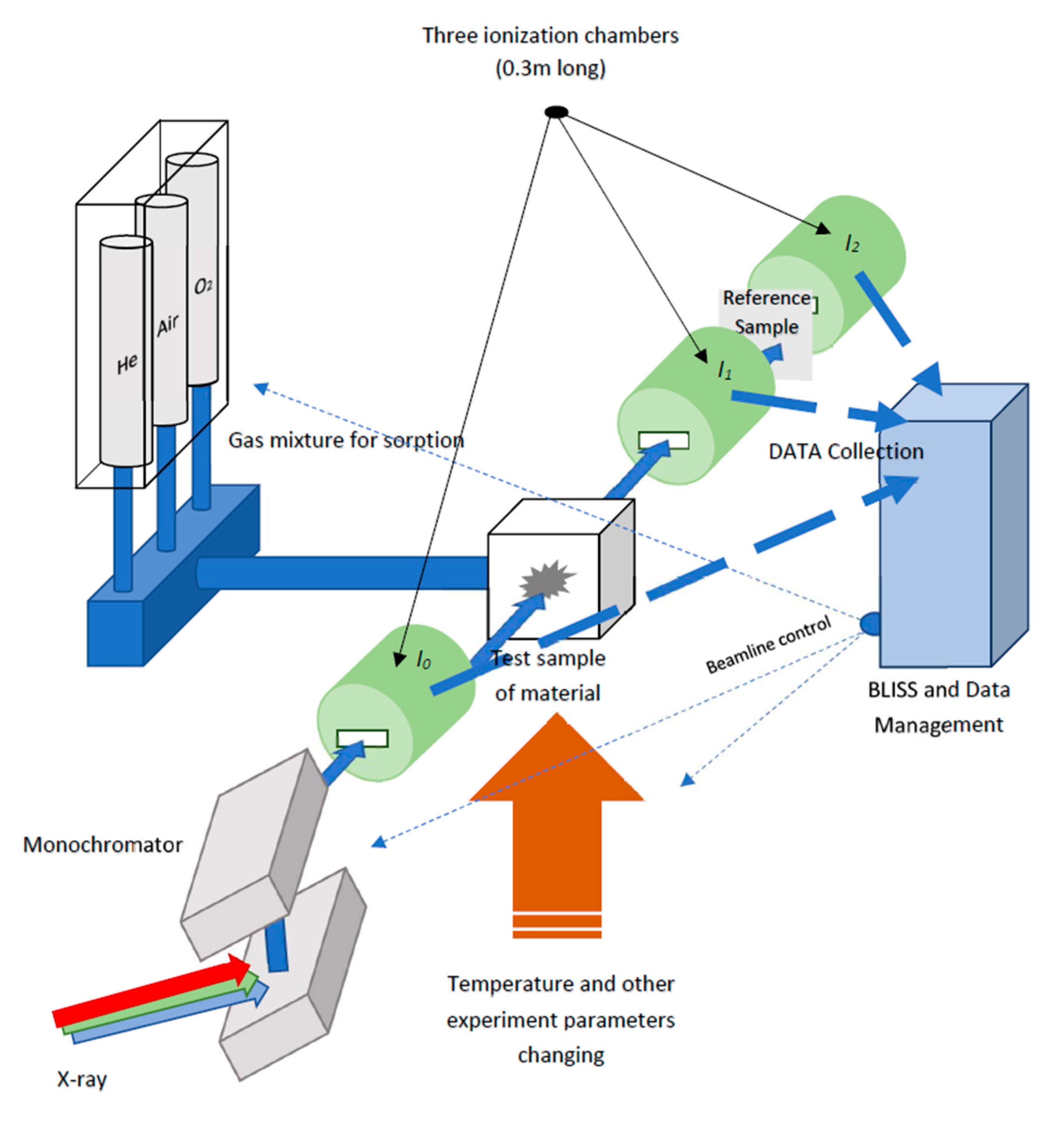{kind=link}
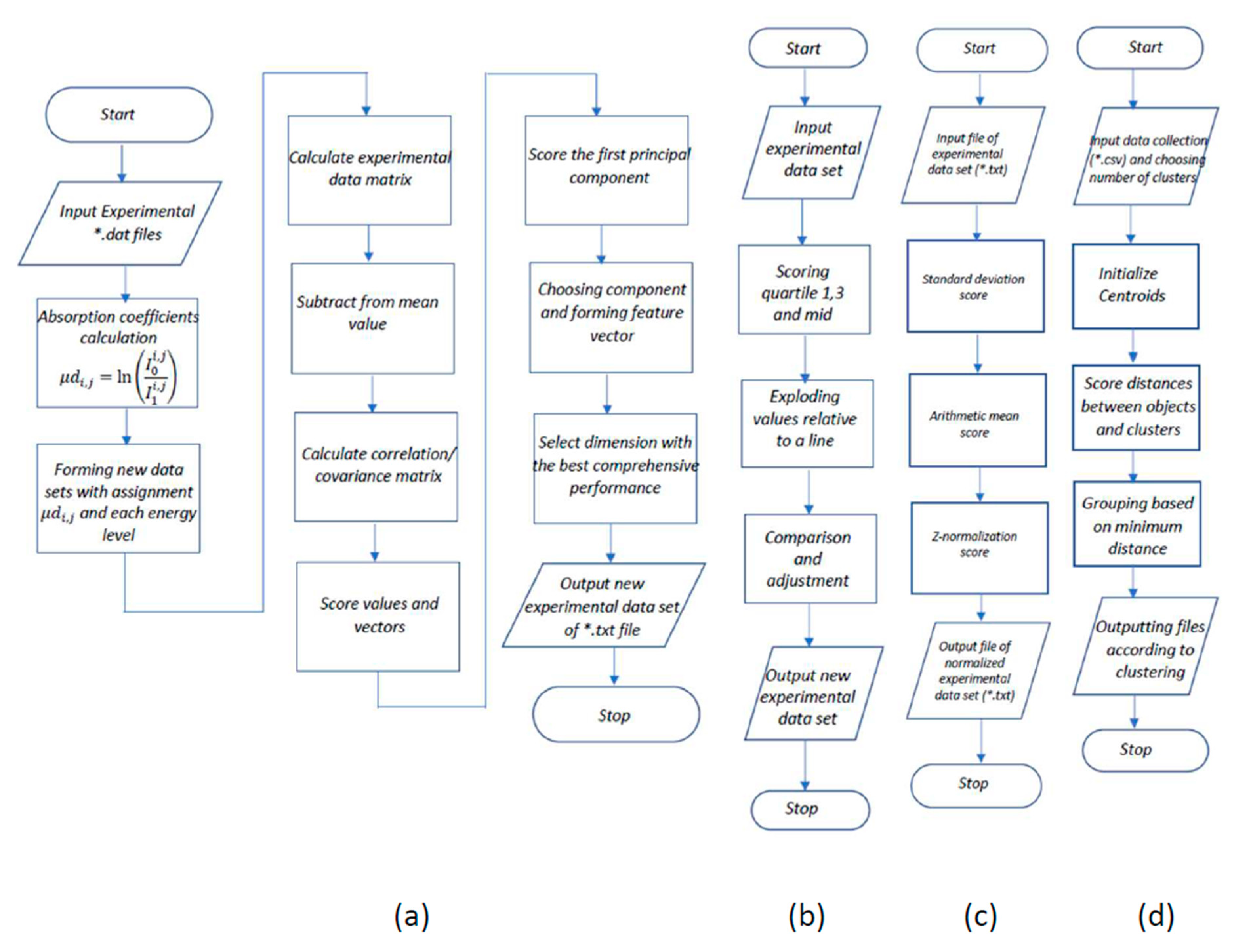{kind=link}
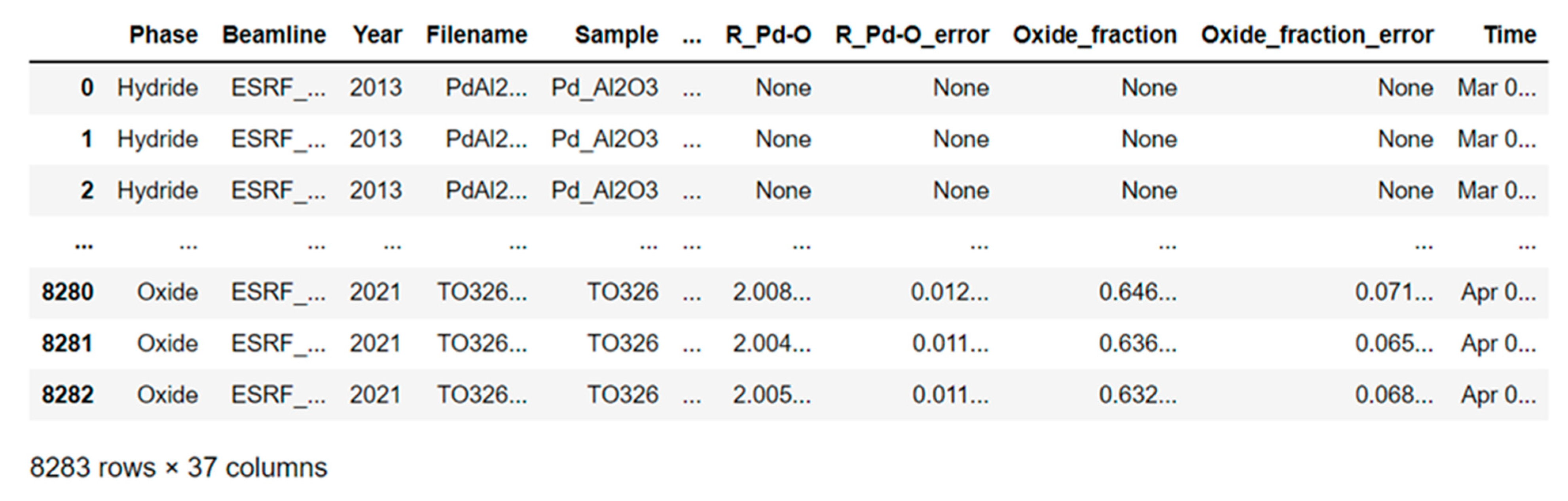{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
1.1. Problem Formulation
1.2. Mini Review of Existing Solutions
2. Materials and Methods
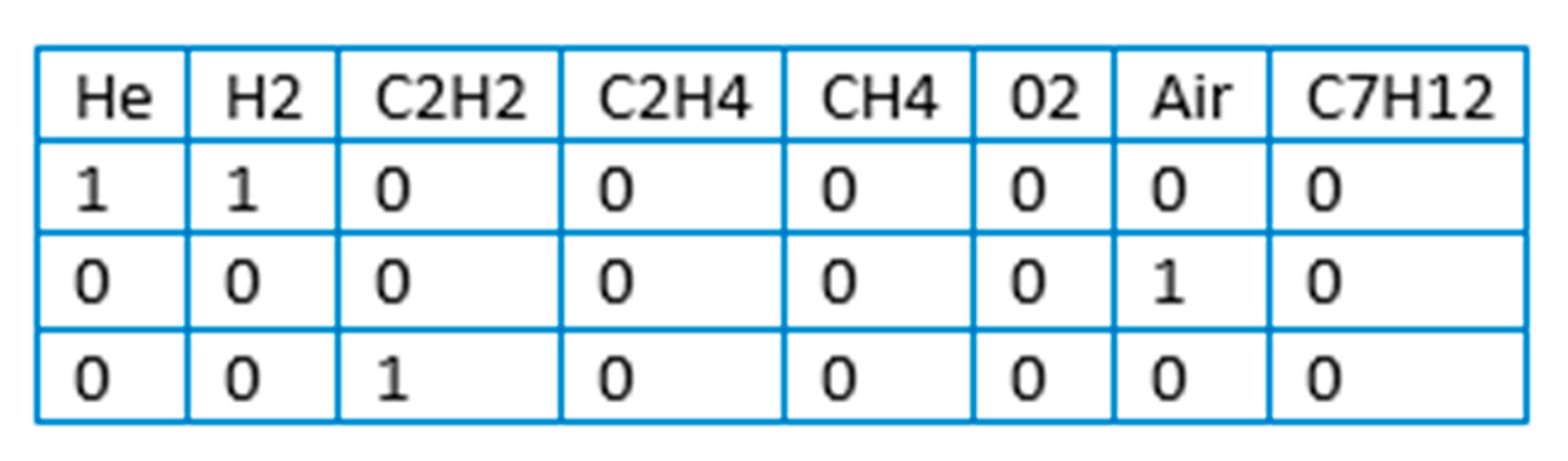
2.1. Retrieving Source Datasets
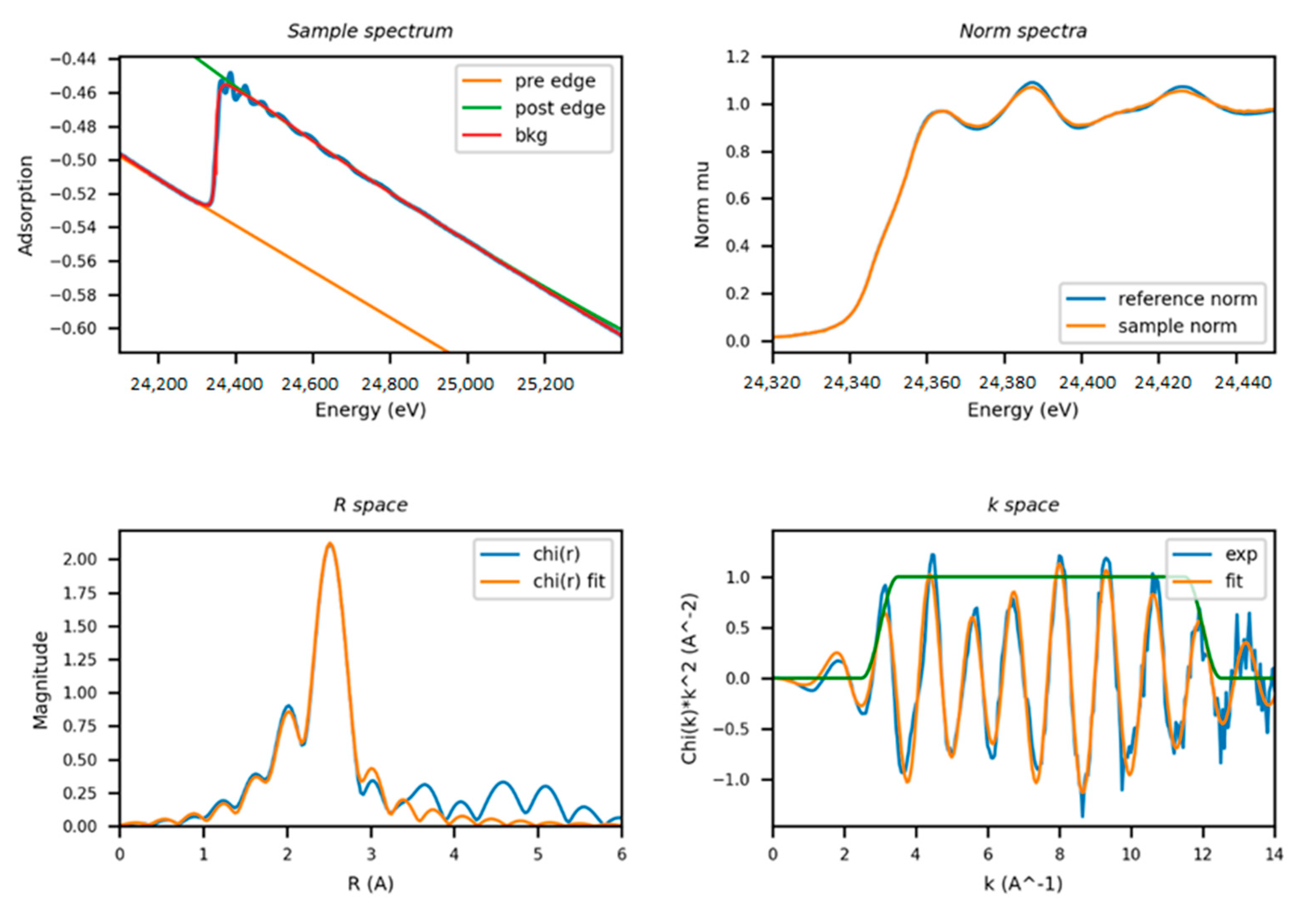
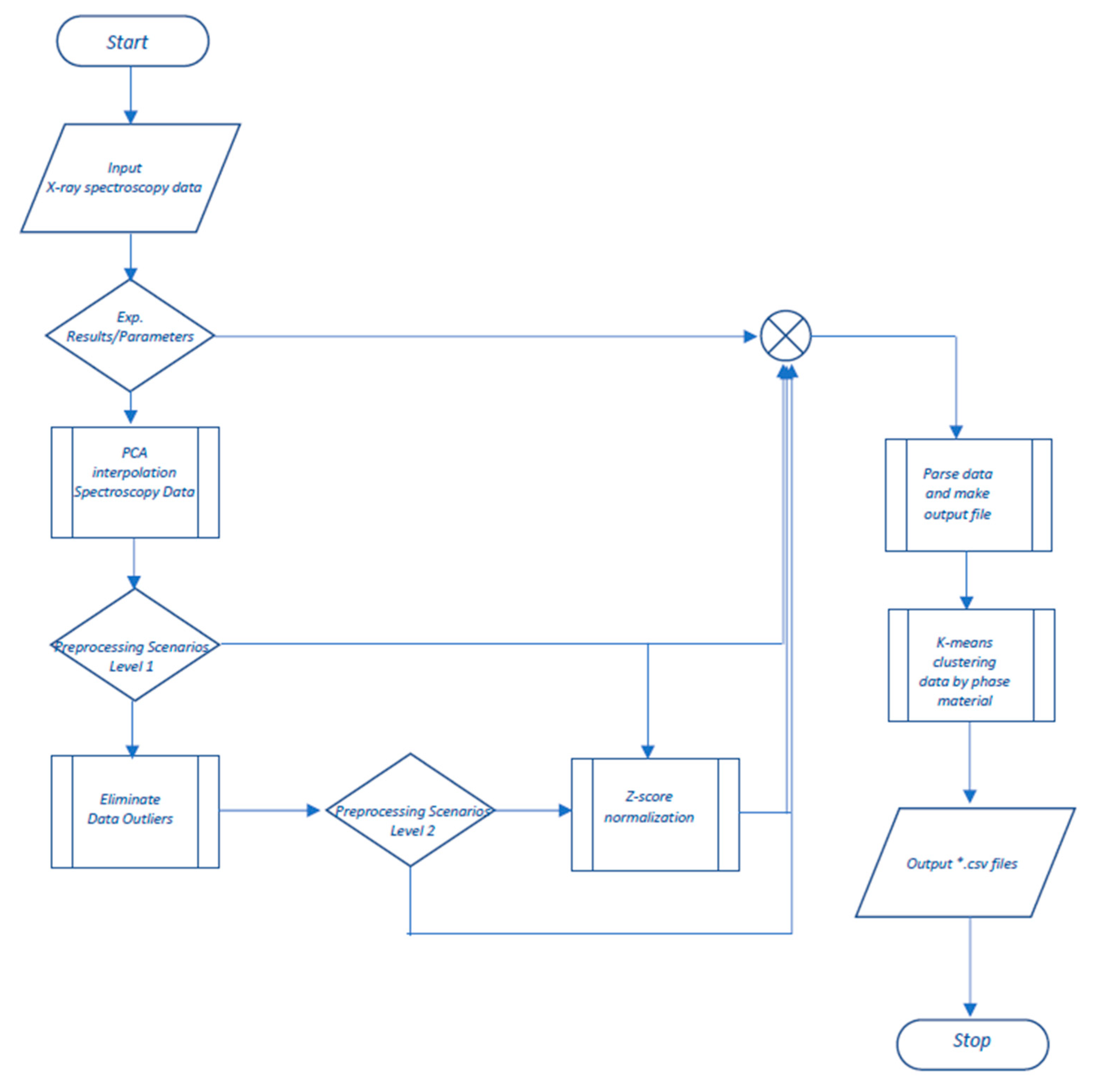
2.2. Suggested Methods and Algorithms
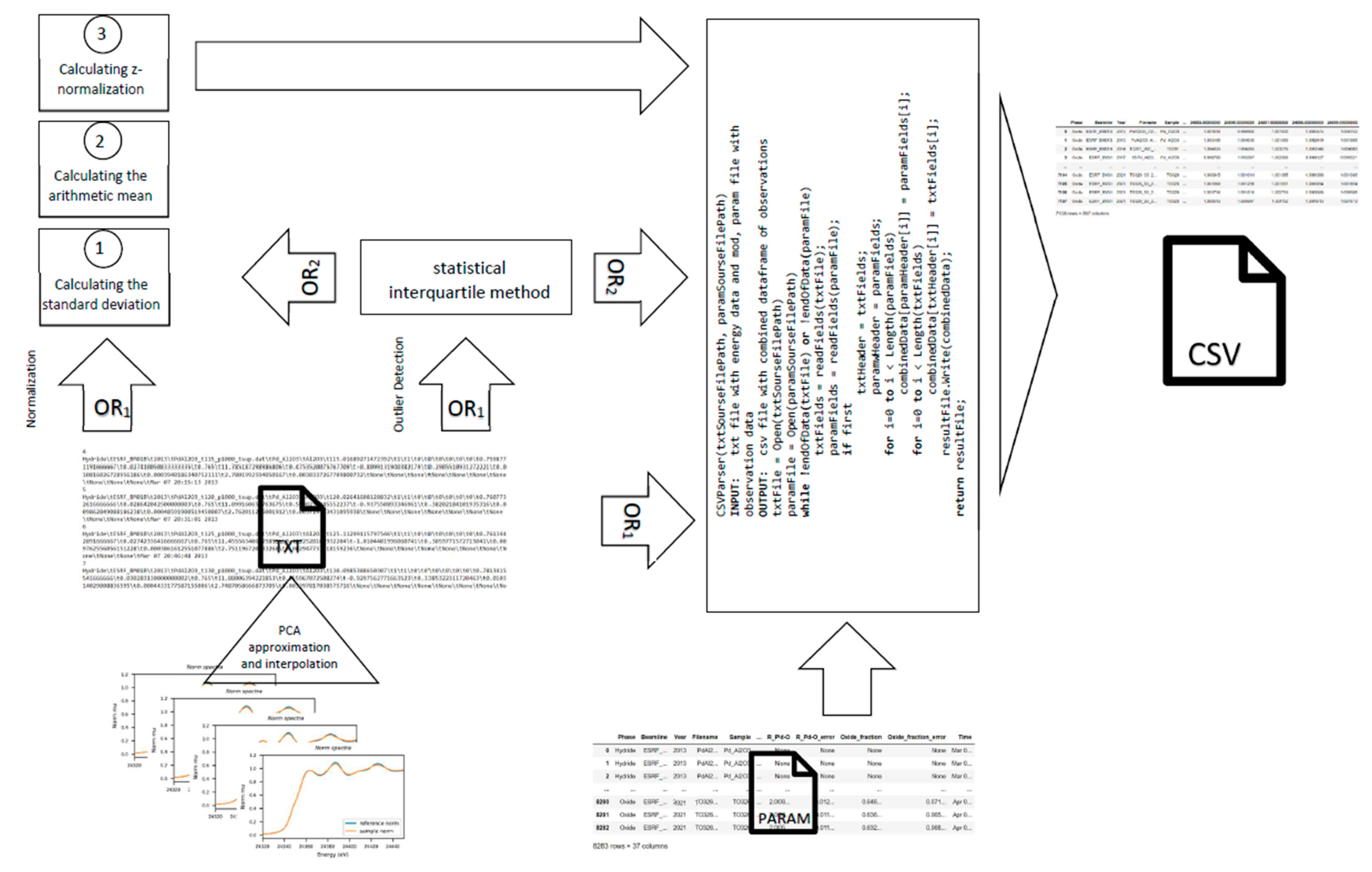
| Algorithm 1 Parse data and make output files [CSVParser(txtSourseFilePath, paramSourseFilePath)]. |
| INPUT: txt file with energy data and mod, param file with observation data |
| OUTPUT: csv file with combined dataframe of observations |
| txtFile = Open(txtSourseFilePath) |
| paramFile = Open(paramSourseFilePath) |
| while !endOfData(txtFile) or !endOfData(paramFile) |
| txtFields = readFields(txtFile); |
| paramFields = readFields(paramFile); |
| if first |
| txtHeader = txtFields; |
| paramwHeader = paramFields; |
| for i = 0 to i < Length(paramFields) |
| combinedData[paramHeader[i]] = paramFields[i]; |
| for i = 0 to i < Length(txtFields) |
| combinedData[txtHeader[i]] = txtFields[i]; |
| resultFile.Write(combinedData); |
| return resultFile; |
3. Results
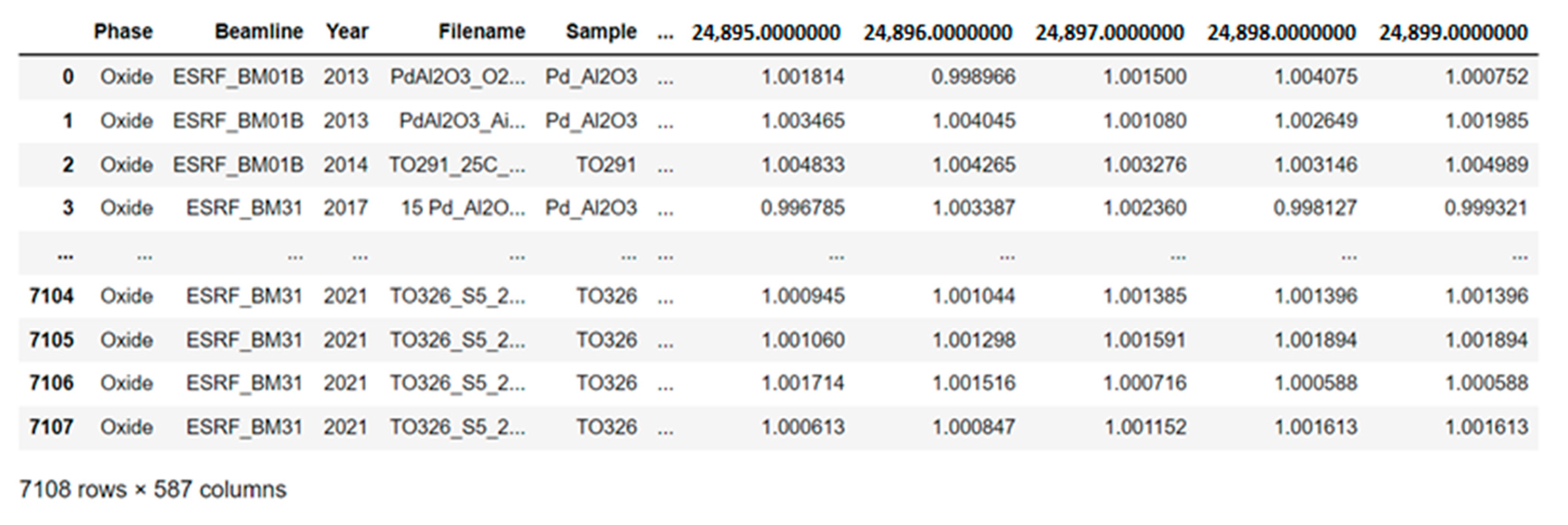
3.1. Structure of the Datasets under Study
3.2. Software Implementation
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shakil Hussain, S.M.; Kamal, M.S.; Hossain, M.K. Recent Developments in Nanostructured Palladium and Other Metal Catalysts for Organic Transformation. J. Nanomater. 2019, 2019, 1562130. [Google Scholar] [CrossRef]
- Bugaev, A.L.; Usoltsev, O.A.; Guda, A.A.; Lomachenko, K.A.; Brunelli, M.; Groppo, E.; Pellegrini, R.; Soldatov, A.V.; van Bokhoven, J.A. Hydrogenation of ethylene over palladium: Evolution of the catalyst structure by operando synchrotron-based techniques. Faraday Discuss. 2021, 229, 197–207. [Google Scholar] [CrossRef]
- Martini, A.; Borfecchia, E. Spectral Decomposition of X-ray Absorption Spectroscopy Datasets: Methods and Applications. Crystals 2020, 10, 664. [Google Scholar] [CrossRef]
- Wang, M.; Feng, Z. Pitfalls in X-ray absorption spectroscopy analysis and interpretation: A practical guide for general users. Curr. Opin. Electrochem. 2021, 30, 100803. [Google Scholar] [CrossRef]
- Zheng, C.; Mathew, K.; Chen, C.; Chen, Y.; Tang, H.; Dozier, A.; Kas, J.J.; Vila, F.D.; Rehr, J.J.; Piper, L.F.J.; et al. Automated generation and ensemble-learned matching of X-ray absorption spectra. NPJ Comput. Mater. 2018, 4, 12. [Google Scholar] [CrossRef]
- Timoshenko, J.; Roldan Cuenya, B. In Situ/Operando Electrocatalyst Characterization by X-ray Absorption Spectroscopy. Chem. Rev. 2021, 121, 882–961. [Google Scholar] [CrossRef]
- Pollice, R.; Gomes, G.D.P.; Aldeghi, M.; Hickman, R.J.; Krenn, M.; Lavigne, C.; Lindner-D’Addario, M.; Nigam, A.; Ser, C.T.; Yao, Z.; et al. Data-Driven Strategies for Accelerated Materials Design. Acc. Chem. Res. 2021, 54, 849–860. [Google Scholar] [CrossRef]
- Jiang, W.-L.; Shen, J.-C.; Peng, Z.; Wu, G.-Y.; Yin, G.-Q.; Shi, X.; Yang, H.-B. Controllable synthesis of ultrasmall Pd nanocatalysts templated by supramolecular coordination cages for highly efficient reductive dehalogenation. J. Mater. Chem. A 2020, 8, 12097–12105. [Google Scholar] [CrossRef]
- Zimmermann, P.; Peredkov, S.; Abdala, P.; DeBeer, S.; Tromp, M.; Müller, C.; van Bokhoven, J.A. Modern X-ray spectroscopy: XAS and XES in the laboratory. Coordination. Chem. Rev. 2020, 423, 213466. [Google Scholar] [CrossRef]
- Mathew, K.; Zheng, C.; Winston, D.; Chen, C.; Dozier, A.; Rehr, J.J.; Ong, S.P.; Persson, K.A. High-throughput computational X-ray absorption spectroscopy. Sci. Data 2018, 5, 180151. [Google Scholar] [CrossRef] [PubMed]
- Imker, H.J.; Luong, H.; Mischo, W.H.; Schlembach, M.C.; Wiley, C. An examination of data reuse practices within highly cited articles of faculty at a research university. J. Acad. Librariansh. 2021, 47, 102369. [Google Scholar] [CrossRef]
- Delgado-Jaime, M.U.; Mewis, C.P.; Kennepohl, P. Blueprint XAS: A Matlab-Based Toolbox for the Fitting and Analysis of XAS Spectra. J. Synchrotron Rad. 2010, 17, 132–137. [Google Scholar] [CrossRef] [PubMed]
- Ravel, B.; Newville, M. ATHENA and ARTEMIS Interactive Graphical Data Analysisusing IFEFFIT. Phys. Scr. 2005, 2005, 1007. [Google Scholar] [CrossRef]
- Ravel, B.; Newville, M. ATHENA, ARTEMIS, HEPHAESTUS: Data Analysis for X-ray Absorption Spectroscopy Using IFEFFIT. J. Synchrotron Rad. 2005, 12, 537–541. [Google Scholar] [CrossRef]
- Silversmit, G.; Poelman, H.; Balcaen, V.; Heynderickx, P.M.; Olea, M.; Nikitenko, S.; Bras, W.; Smet, P.F.; Poelman, D.; De Gryse, R.; et al. In-Situ XAS Study on the Cu and Ce Local Structural Changes in a CuO–CeO2/Al2O3 Catalyst under Propane Reduction and Re-Oxidation. J. Phys. Chem. Solids 2009, 70, 1274–1284. [Google Scholar] [CrossRef]
- Sarangi, R. A Biological Perspective towards a Standard for Information Exchange and Reporting in XAS. J. Synchrotron Rad. 2018, 25, 944–952. [Google Scholar] [CrossRef]
- Ressler, T. WinXAS: A New Software Package Not Only for the Analysis of Energy-Dispersive XAS Data. J. Phys. IV Fr. 1997, 7, C2-269–C2-270. [Google Scholar] [CrossRef]
- Kuzmin, A. EDA: EXAFS Data-Analysis Software Package. Int. Tables Crystallogr. 2020, 1. [Google Scholar] [CrossRef]
- Asakura, H.; Yamazoe, S.; Misumi, T.; Fujita, A.; Tsukuda, T.; Tanaka, T. XTunes: A New XAS Processing Tool for Detailed and on-the-Fly Analysis. Radiat. Phys. Chem. 2020, 175, 108270. [Google Scholar] [CrossRef]
- Alain, M.; Jacques, M.; Diane, M.-B.; Karine, P. MAX: Multiplatform Applications for XAFS. J. Phys. Conf. Ser. 2009, 190, 012034. [Google Scholar] [CrossRef]
- Noronha, F.B. EXAFS as a Tool for Catalyst Characterization: A Review of the Data Analysis Methods. Braz. J. Chem. Eng. 1999, 16, 309–317. [Google Scholar] [CrossRef]
- Carey, C.; Dyar, D.; Boucher, T.; Giguere, S. Web-Based Software for Preprocessing, Matching, Fitting, Prediction, and Visualization of Spectroscopic Data: The Data Exploration, Visualization, and Analysis of Spectra (Devas) Website. In Proceedings of the 48th Lunar and Planetary Science XLVIII, The Woodland, TX, USA, 20–24 March 2017; Available online: https://www.hou.usra.edu/meetings/lpsc2017/pdf/1097.pdf (accessed on 14 December 2021).
- Martini, A.; Guda, S.A.; Guda, A.A.; Smolentsev, G.; Algasov, A.; Usoltsev, O.; Soldatov, M.A.; Bugaev, A.; Rusalev, Y.; Lamberti, C.; et al. PyFitit: The Software for Quantitative Analysis of XANES Spectra Using Machine-Learning Algorithms. Comput. Phys. Commun. 2020, 250, 107064. [Google Scholar] [CrossRef]
- Sharkov, M.D.; Pogrebitsky, K.Y.; Boiko, M.E. New Technique for EXAFS Data Processing and Its Application. Tech. Phys. 2011, 56, 1353–1358. [Google Scholar] [CrossRef]
- Torrisi, S.B.; Carbone, M.R.; Rohr, B.A.; Montoya, J.H.; Ha, Y.; Yano, J.; Suram, S.K.; Hung, L. Random Forest Machine Learning Models for Interpretable X-ray Absorption near-Edge Structure Spectrum-Property Relationships. NPJ Comput. Mater. 2020, 6, 109. [Google Scholar] [CrossRef]
- Laclare, J.L. Target Specifications and Performance of the ESRF Source. J. Synchrotron Rad. 1994, 1, 12–18. [Google Scholar] [CrossRef]
- Bauters, S.; Tack, P.; Rudloff-Grund, J.H.; Banerjee, D.; Longo, A.; Vekemans, B.; Bras, W.; E Brenker, F.; van Silfhout, R.; Vincze, L. Polycapillary Optics Based Confocal Micro X-ray Fluorescence and X-ray Absorption Spectroscopy Setup at The European Synchrotron Radiation Facility Collaborative Research Group Dutch–Belgian Beamline, BM26A. Anal. Chem. 2018, 90, 2389–2394. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q. The Experimental and Theoretical Investigation of Single-Crystal Diamond Compound Refractive Lenses (CRLs). Ph.D. Thesis, University of Stavanger, Stavanger, Norway, 2020. UiS No. 527. Available online: https://hdl.handle.net/11250/2657862 (accessed on 14 December 2021).
- Van Beek, W.; Emerich, H.; Chernyshov, D.; Dmitriev, V. MS42-P04|SNBL’S BM31 AT ESRF BEYOND 2020—COMBINED XRD-PDF-XAS. Found. Crystallogr. 2019, 75, e677. [Google Scholar] [CrossRef]
- Michel, V.; Beteva, A.; Coutinho, T.; Dominguez, M.-C.; Guijarro, M.; Guilloud, C.; Homs, A.; Meyer, J.; Papillon, E.; Perez, M.; et al. BLISS—Experiments Control for ESRF Beamline. In Proceedings of the 12th International Workshop on Emerging Technologies and Scientific Facilities Controls, PCaPAC2018, Taiwan, China, 16–18 October 2018; pp. 26–29. [Google Scholar] [CrossRef]
- Singh, V.; Asari, V.K.; Kumar, S.; Patel, R.B. (Eds.) Computational Methods and Data Engineering. In Proceedings of the ICMDE 2020, Bangkok, Thailand, 26–28 February 2020; Advances in intelligent systems and computing; Springer: Singapore, 2021; Volume 1, ISBN 9789811568763. [Google Scholar]
- Hayman, M.; Stillwell, R.A.; Spuler, S.M. Fast computation of absorption spectra for lidar data processing using principal component analysis. Opt. Lett. 2019, 44, 1900. [Google Scholar] [CrossRef] [PubMed]
- Oliveira, P.; Gomes, L. Interpolation of signals with missing data using Principal Component Analysis. Multidim. Syst. Sign. Process 2010, 21, 25–43. [Google Scholar] [CrossRef]
- Wasserman, S.R.; Allen, P.G.; Shuh, D.K.; Bucher, J.J.; Edelstein, N.M. EXAFS and principal component analysis: A new shell game. J. Synchrotron Rad. 1999, 6, 284–286. [Google Scholar] [CrossRef]
- Jolliffe, I.T.; Cadima, J. Principal Component Analysis: A Review and Recent Developments. Phil. Trans. R. Soc. A 2016, 374, 20150202. [Google Scholar] [CrossRef] [PubMed]
- Wold, S. Cross-Validatory Estimation of the Number of Components in Factor and Principal Components Models. Technometrics 1978, 20, 397–405. [Google Scholar] [CrossRef]
- Gebrekidan, M.T.; Knipfer, C.; Stelzle, F.; Popp, J.; Will, S.; Braeuer, A. A shifted-excitation Raman difference spectroscopy (SERDS) evaluation strategy for the efficient isolation of Raman spectra from extreme fluorescence interference. J. Raman Spectrosc. 2016, 47, 198–209. [Google Scholar] [CrossRef]
- Frenkel, A.I. Applications of extended X-ray absorption fine-structure spectroscopy to studies of bimetallic nanoparticle catalysts. Chem. Soc. Rev. 2012, 41, 8163. [Google Scholar] [CrossRef] [PubMed]
- Gayathri, A.; Mohanavalli, S.; Clustering, K. Enhanced Customer Relationship Management Using Fuzzy Clustering. Int. J. Comput. Sci. Eng. Technol. 2011, 1, 163–167. [Google Scholar]
- Reddy, K.P.N. Comparison of Programming Languages: Review. Int. J. Comput. Sci. Commun. 2018, 9, 113–122. [Google Scholar]
- Berretti, E.; Giaccherini, A.; Montegrossi, G.; D’Acapito, F.; Di Benedetto, F.; Zafferoni, C.; Puri, A.; Lepore, G.O.; Miller, H.; Giurlani, W.; et al. In-situ Quantification of Nanoparticles Oxidation: A Fixed Energy X-ray Absorption Approach. Catalysts 2019, 9, 659. [Google Scholar] [CrossRef]
- Cho, H.; Eo, S.-H. Outlier Detection for Mass Spectrometric Data. In Statistical Analysis in Proteomics; Jung, K., Ed.; Springer: New York, NY, USA, 2016; Volume 1362, pp. 91–102. [Google Scholar]
- Ahmed, S.; Usman, M.; Ferzund, J.; Atif, M.; Rehman, A.; Mehmood, A. Modern Data Formats for Big Bioinformatics Data Analytics. IJACSA 2017, 8, 366–377. [Google Scholar] [CrossRef]









Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kartashov, O.O.; Chernov, A.V.; Polyanichenko, D.S.; Butakova, M.A. XAS Data Preprocessing of Nanocatalysts for Machine Learning Applications. Materials 2021, 14, 7884. https://doi.org/10.3390/ma14247884
Kartashov OO, Chernov AV, Polyanichenko DS, Butakova MA. XAS Data Preprocessing of Nanocatalysts for Machine Learning Applications. Materials. 2021; 14(24):7884. https://doi.org/10.3390/ma14247884
Chicago/Turabian StyleKartashov, Oleg O., Andrey V. Chernov, Dmitry S. Polyanichenko, and Maria A. Butakova. 2021. "XAS Data Preprocessing of Nanocatalysts for Machine Learning Applications" Materials 14, no. 24: 7884. https://doi.org/10.3390/ma14247884
APA StyleKartashov, O. O., Chernov, A. V., Polyanichenko, D. S., & Butakova, M. A. (2021). XAS Data Preprocessing of Nanocatalysts for Machine Learning Applications. Materials, 14(24), 7884. https://doi.org/10.3390/ma14247884