
A Numerical Measurement Method for Dynamic Granular Materials Based on Computer Vision


Abstract
:1. Introduction
- We combine computer vision and the numerical measurement task to propose a numerical measurement method for dynamic granular materials. This method is mainly based on the VIS, which is able to realize end-to-end multi-task learning and simultaneously detect, segment and track dynamic granular materials;
- We analyze the properties of video data and granular materials to improve the VIS network. A temporal feature fusion module and tracking head with long-sequence external memory are introduced to make the VIS network more suitable for the numerical measurement of dynamic granular materials;
- A variety of effective post-processing steps such as the extraction of centroid and long axis, ellipse fitting, and pixel-actual distance calibration are used to obtain the amount of translation, the rotation angle, velocity and acceleration of dynamic granular materials;
- A set of experimental equipment is designed to collect dynamic granule videos and then the numerical results of dynamic granular materials are measured by the proposed method. The amount of translation, the rotation angle, and the velocity and acceleration of granular materials are compared with true results to verify the effectiveness of the proposed method.
2. Method
2.1. Method Framework
2.2. An Improved Video Instance Segmentation Network
2.2.1. Overall Network Architecture
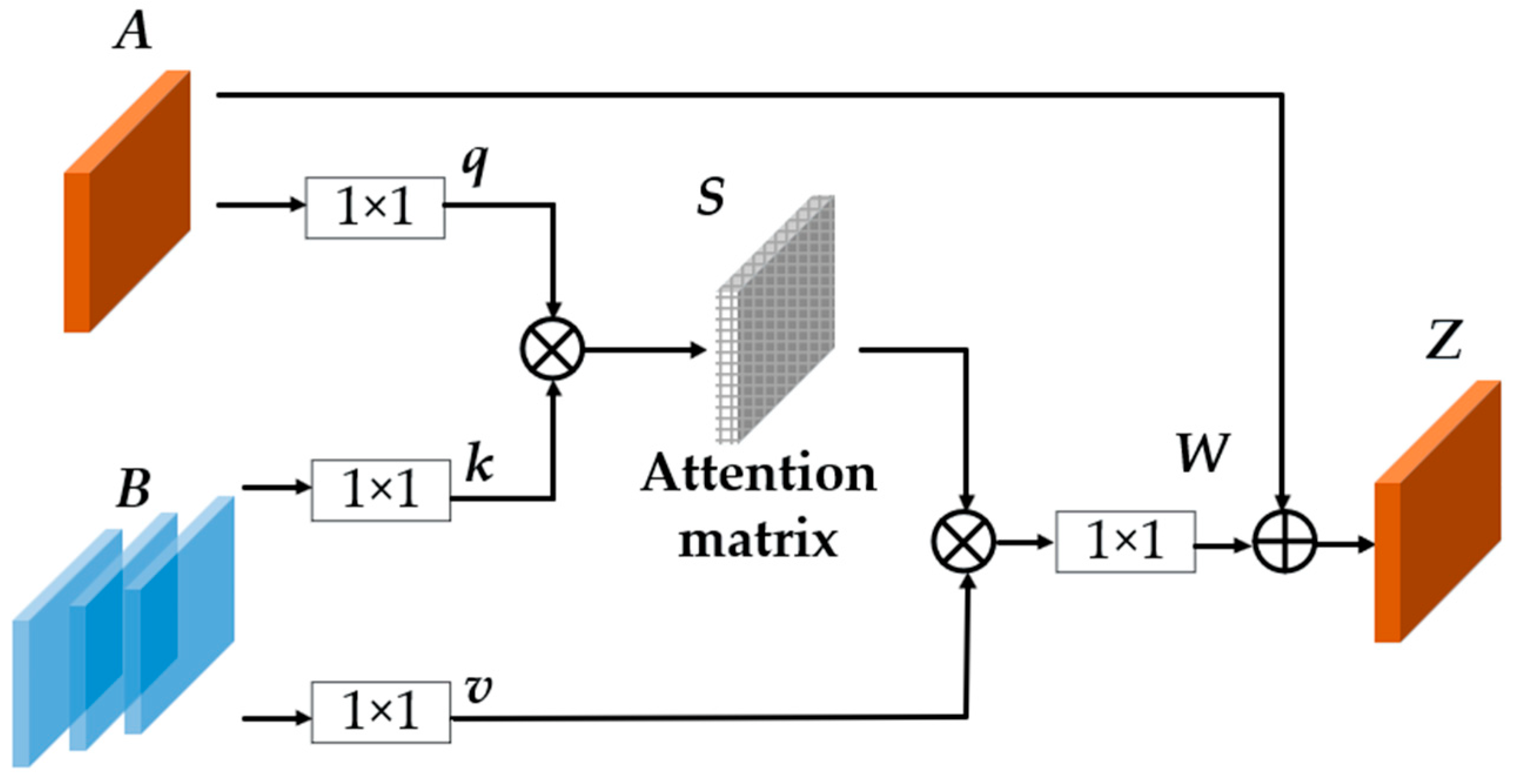
2.2.2. Temporal Feature Fusion Module
2.2.3. Tracking Head with Long-Sequence External Memory
2.2.4. Loss Function
2.3. Post-Processing Steps
3. Experiment and Analysis
3.1. Experimental Equipment and Parameter
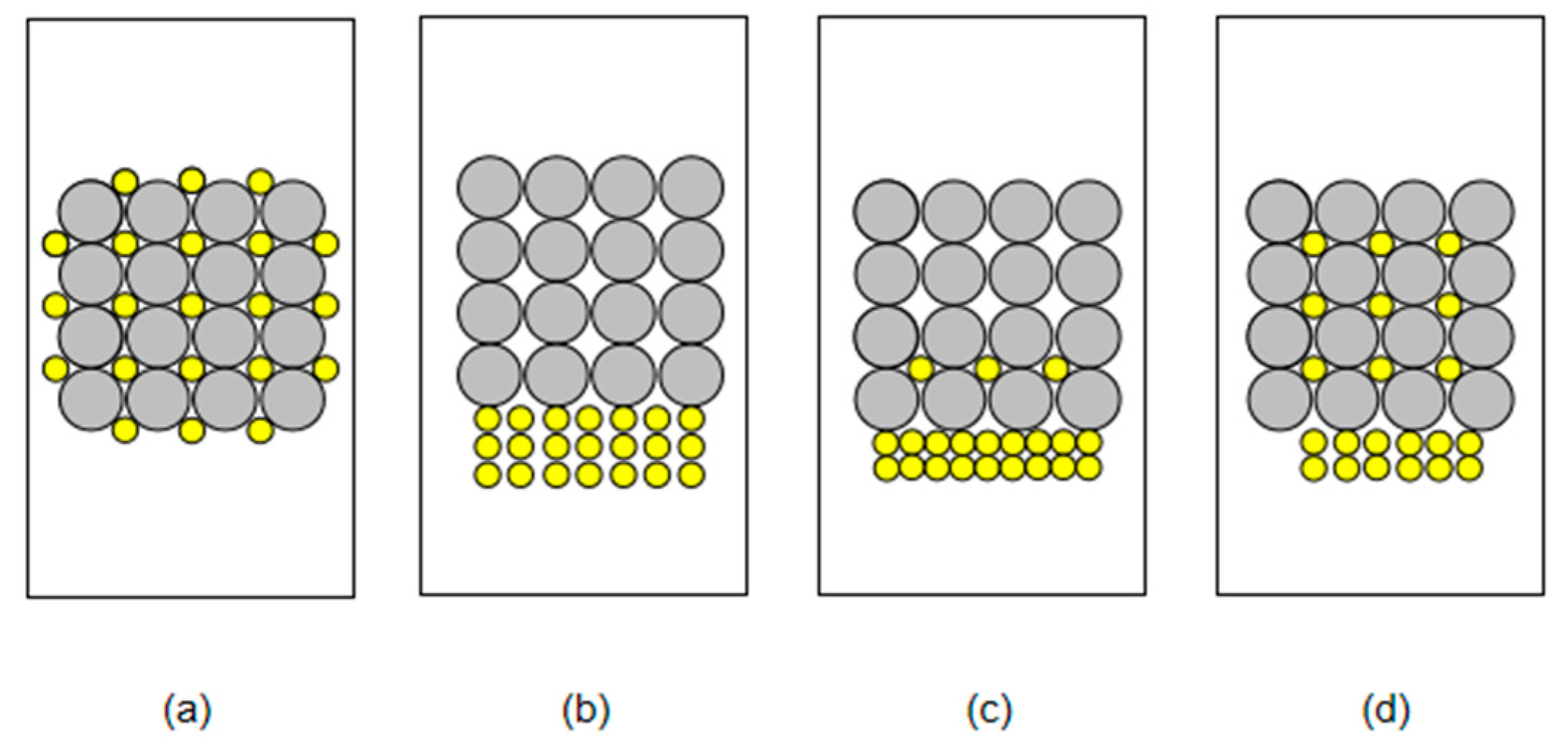
3.2. Dataset
3.3. Evaluation Indicators
3.4. Visual Processing Experiment
3.5. Numerical Measurement Experiment
4. Conclusions and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AP | Average precision at IoU = 0.50: 0.05: 0.95 |
| AP50 | Average precision at IoU = 0.50 |
| AP75 | Average precision at IoU = 0.75 |
| CompFeat | Comprehensive feature aggregation approach |
| Deep SORT | Deep simple online and real-time tracking |
| DEM | Discrete element method |
| FPN | Feature pyramid network |
| ID | Identity document |
| IoU | Intersection-over-union |
| IoUTracker | Intersection-over-union tracker |
| LM | Tracking head with long-sequence external memory |
| LSV | Laser speckle velocimetry |
| Mask R-CNN | Mask region-based convolutional neural network |
| MaskTrack R-CNN | Mask track region-based convolutional neural network |
| MSCOCO | Microsoft common objects in context |
| PIV | Particle imaging velocimetry |
| PTV | Particle tracking velocimetry |
| ResNet | Residual Network |
| RoIAlign | Region of interest align |
| RPN | Region proposal network |
| TF | Temporal feature fusion module |
| VIS | Video instance segmentation |
References
- Cao, Y.X.; Li, J.D.; Kou, B.Q.; Xia, C.J.; Li, Z.F.; Chen, R.C.; Xie, H.L.; Xiao, T.Q.; Kob, W.; Hong, L.; et al. Structural and topological nature of plasticity in sheared granular materials. Nat. Commun. 2018, 9, 2911. [Google Scholar] [CrossRef] [PubMed]
- Xie, Z.Z.; An, X.Z.; Wu, Y.L.; Wang, L.; Qian, Q.; Yang, X.H. Experimental study on the packing of cubic particles under three-dimensional vibration. Powder Technol. 2017, 317, 13–22. [Google Scholar] [CrossRef]
- Jia, M.C.; Yang, Y.; Liu, B.; Wu, S.H. PFC/FLAC coupled simulation of dynamic compaction in granular soils. Granul. Matter 2018, 20, 76. [Google Scholar] [CrossRef]
- Omidvar, M.; Chen, Z.; Iskander, M. Image-Based Lagrangian Analysis of Granular Kinematics. J. Comput. Civ. Eng. 2015, 29, 4014101. [Google Scholar] [CrossRef]
- Zhao, C.; Li, C.B.; Hu, L. Rolling and sliding between non-spherical particles. Phys. A-Stat. Mech. Its Appl. 2018, 492, 181–191. [Google Scholar] [CrossRef]
- Cundall, P.A.; Strack, O.D. A discrete numerical model for granular assemblies. Geotechnique 1979, 29, 47–65. [Google Scholar] [CrossRef]
- Lu, Y.; Tan, Y.; Li, X.; Liu, C.A. Methodology for Simulation of Irregularly Shaped Gravel Grains and Its Application to DEM Modeling. J. Comput. Civ. Eng. 2017, 31, 4017023. [Google Scholar] [CrossRef]
- Sarno, L.; Carravetta, A.; Tai, Y.C.; Martino, R.; Papa, M.N.; Kuo, C.Y. Measuring the velocity fields of granular flows—Employment of a multi-pass two-dimensional particle image velocimetry (2D-PIV) approach. Adv. Powder Technol. 2018, 29, 3107–3123. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, Y.; Jia, P. Improving the Delaunay tessellation particle tracking algorithm in the three-dimensional field. Measurement 2014, 49, 1–14. [Google Scholar] [CrossRef]
- Yang, L.J.; Fan, Y.C.; Xu, N. Video Instance Segmentation. In Proceedings of the 17th IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 5187–5196. [Google Scholar]
- Feng, Q.Y.; Yang, Z.X.; Li, P.K.; Wei, Y.C.; Yang, Y. Dual Embedding Learning for Video Instance Segmentation. In Proceedings of the 17th IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 717–720. [Google Scholar]
- Kim, D.; Woo, S.; Lee, J.-Y.; Kweon, I.S. Video panoptic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9859–9868. [Google Scholar]
- Lin, C.-C.; Hung, Y.; Feris, R.; He, L. Video instance segmentation tracking with a modified VAE architecture. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 13147–13157. [Google Scholar]
- Liu, X.; Ren, H.; Ye, T. Spatio-temporal Attention Network for Video Instance Segmentation. In Proceedings of the 17th IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 725–727. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.M.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Fu, Y.; Yang, L.J.; Liu, D.; Huang, T.S.; Shi, H. CompFeat: Comprehensive Feature Aggregation for Video Instance Segmentation. In Proceedings of the 35th AAAI Conference on Artificial Intelligence, online, 2–9 February 2021; pp. 1361–1369. [Google Scholar]
- Bertasius, G.; Torresani, L. Classifying, segmenting, and tracking object instances in video with mask propagation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9739–9748. [Google Scholar]
- Wang, Y.; Xu, Z.; Wang, X.; Shen, C.; Cheng, B.; Shen, H.; Xia, H. End-to-end video instance segmentation with transformers. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), online, 19–25 June 2021; pp. 8741–8750. [Google Scholar]
- Lin, H.; Wu, R.; Liu, S.; Lu, J.; Jia, J. Video instance segmentation with a propose-reduce paradigm. In Proceedings of the 18th IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 1739–1748. [Google Scholar]
- He, K.M.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the 16th IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Hamzeloo, E.; Massinaei, M.; Mehrshad, N. Estimation of particle size distribution on an industrial conveyor belt using image analysis and neural networks. Powder Technol. 2014, 261, 185–190. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the 13th European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Bochinski, E.; Eiselein, V.; Sikora, T. High-Speed Tracking-by-Detection Without Using Image Information. In Proceedings of the 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 24th IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Video Type | Degree of Mixing | 0% | 0–50% | 50–100% | 100% | Total |
|---|---|---|---|---|---|---|
| Vibrating | Number of videos | 8 | 9 | 11 | 9 | 37 |
| Number of frames | 3072 | 3755 | 4733 | 3987 | 15,547 | |
| Number of marked frames | 51 | 62 | 78 | 66 | 257 | |
| Rotating | Number of videos | 9 | 8 | 9 | 8 | 34 |
| Number of frames | 2930 | 3058 | 3855 | 3702 | 13,545 | |
| Number of marked frames | 97 | 101 | 128 | 123 | 449 |
| Method | AP | AP50 | AP75 |
|---|---|---|---|
| IoUTracker+ [25] | 66.4 | 75.4 | 67.5 |
| Deep SORT [26] | 69.7 | 78.0 | 70.6 |
| MaskTrack R-CNN [10] | 74.5 | 85.2 | 75.8 |
| Ours | 76.6 | 88.3 | 78.1 |
| TF | LM | AP | AP50 | AP75 |
|---|---|---|---|---|
| 74.5 | 85.2 | 75.8 | ||
| √ | 76.3 (+1.8) | 87.7 (+2.5) | 77.6 (+1.8) | |
| √ | 75.1 (+0.6) | 86.3 (+1.1) | 76.7 (+0.9) | |
| √ | √ | 76.6 (+2.1) | 88.3 (+3.1) | 78.1 (+2.3) |
| Video Type | ||||
|---|---|---|---|---|
| Vibrating | 8.95 | 16.43 | 0.47 | 3.41 |
| Rotating | 5.67 | 9.51 | 0.26 | 1.92 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, H.; Nie, Y.; Chen, M.; Liu, S.; Mohammed, A. A Numerical Measurement Method for Dynamic Granular Materials Based on Computer Vision. Materials 2022, 15, 3554. https://doi.org/10.3390/ma15103554
Liu H, Nie Y, Chen M, Liu S, Mohammed A. A Numerical Measurement Method for Dynamic Granular Materials Based on Computer Vision. Materials. 2022; 15(10):3554. https://doi.org/10.3390/ma15103554
Chicago/Turabian StyleLiu, Hao, Yuxing Nie, Man Chen, Shunkai Liu, and Ashiru Mohammed. 2022. "A Numerical Measurement Method for Dynamic Granular Materials Based on Computer Vision" Materials 15, no. 10: 3554. https://doi.org/10.3390/ma15103554