3.1. Feature Space Reduction and Transfer Feature Space
As explained in
Section 2.2, the appropriate choice of the feature space is of decisive importance when learned model parameters shall be transferred for a new predictive task. Based on the available input features, we have evaluated the performance of six input features and the six combinations of five input features when one feature is removed. The difference of the
, i.e., the mean squared error (MSE) obtained during the training on the 121 data points, for the six-input feature scenario and the distinct five-input feature options is labelled as
, with
being the MSE for the six-input feature space. Therefore, the more positive the value of delta is, the more important the removed feature is.
While the reduction of the feature space is typically addressed via unsupervised or semi-supervised machine learning methods such as principle component analysis or manifold reconstruction, our rather manual approach provides a better intuitive understanding of the resulting performance differences. Since the transfer from the two-species-doped perovskites to the four-species-doped perovskites requires a redefinition of the input features, we stay with the manual approach. The input features of these 15 samples are calculated by weighted summation. The weights for the different features are chosen from a set of ad hoc estimates of suitable candidate weights. For example, for La
Sr
FeO
, suitable weights for estimating the ionic radius
are
For each of these six possibly removed features and the full feature set, the topology of the ANN is optimised, using the Tensorflow library [
37]. Some qualitative reasoning for the minimal set of neural layers for a given set of activation functions might be inspired by the phenomenological perspective on the problem. However, a precise, quantitative prediction of the optimal ANN topology based on arguments from the application domain is rarely possible. Taking into account that we aim at the regression of the non-linear, yet only mildly complex (considering the dimensionality of the feature space) functional dependence of the oxygen vacancy formation energy on the features introduced in
Section 2.1, we tackle this problem as follows: The input layer of the ANN has either five or six nodes, respectively. In both cases, we add nodes and layers sequentially as long as our performance metric of the prediction increases. Therefore, the initial topology on top of the input layer is a hidden layer with two neurons and an output layer with a single neuron. The number of edges ranges from 12 for a
ANN to 66 for a
+ 11 bias nodes ANN when using five input features. When six input features are used, the number of edges ranges from 14 for an
ANN up to 71 for an
+ 11 bias nodes ANN.
Taking into account the limited size of the data set and the generalisability of the learned models, the maximum number of neurons is reached quite fast. The size of 121 data points on the training data set leads to a substantial penalty in the bias-corrected performance metrics that we use for the largest topology with altogether 71 edges.
To determine the optimal ANN topology for each of the input feature combinations, a 10-fold cross-validation based on the MSE is used, with the results being listed in
Table 2. From these evaluations, the most suitable feature space for the task could be identified. Option 4 has the smallest values for MSE
(0.675), MSE
(0.064) and MAPE
(0.086). Here, MSE
and MAPE
are mean squared and mean absolute percentage error on the 15 data points in the test data set. It also has the highest benefit from reducing the feature space,
. This is the only model that provides an MAPE below 10% for the transferred prediction of four-species-doped perovskites from two-species-doped perovskites. For a better impression on the accuracy of the network forecast, we added selected predicted oxygen vacancy formation energy for Ba
Sr
Fe
Co
O
(BSCF) to
Table 1. We see that the energies and trends are predicted rather well despite the small size of the training data set, which contains only four compositions with this chemistry.
The application of the transfer model to generate a prospective data set is discussed in the next paragraph. From a chemical perspective, we find that the electronegativity, ionic radius and atomic mass of the A-site element are more important features than the corresponding B-site properties. In fact, the electronegativity of the A-site element is the most important feature variable, while the ionic radius of the B-site element is the least important feature variable. The importance of the electronegativity and mass of the B-site element are roughly comparable. Altogether, the feature importance in descending order is: electronegativity of the A-site element, ionic radius of the A-site element, atomic mass of the A-site element, electronegativity of the B-site element, mass of the B-site element and finally the ionic radius of the B-site element. For some parameters, such as the ionic radii or the electronegativity, an influence on the oxygen vacancy formation energy is plausible, as these parameters directly influence the lattice stability and the interatomic bonding. This is less obvious for the masses of the elements, which according to the obtained results do have an influence on , although the effect is not as pronounced as in particular that of and .
3.2. Prospective Studies
As the model transfer from two-species doping to four-species doping has been tested with an acceptable accuracy for the prediction of the oxygen vacancy formation energies, we apply the model next to provide prospective studies for a larger variety of dopings. The first application focuses on A
A
Co
Fe
O
dopings. In the training data set, A
and A
are two arbitrary elements from 68 options for the A site. The electronegativity for B (dimensionless Pauling scale) and the mass (in atomic mass units) for B are fixed to 1.855 and 57.3891, respectively, which corresponds to the equal mixing of Fe and Co on this site. Using the trained model, we vary independently the (mean) atomic radius, the electronegativity and the mass of the A site element. Here, we note that only the averaged quantities of the A site elements are needed, which are calculated in analogy to Equation (
2) using the values for A
and A
and the composition variable
x, e.g.,
. The varied parameters are discretized over 30 steps, with
being in the range of 0.27 to 1.73 Ångstrom,
in the interval
of the dimensionless Pauling scale, and
in the range of 6.941 to 238.0289 atomic mass units, which corresponds to the parameter regimes of typical elements for the A site. The resulting prediction for the oxygen vacancy formation energy
of A
A
Co
Fe
O
for given
,
and
is plotted in the heat map shown in
Figure 2.
Obviously, there is some clustering of low and high oxygen vacancy formation energies, but the dependencies are rather nontrivial. For example, low values of
can be found in regions of low and high A site radii as well as for low atomic masses
, as can also been seen in two-dimensional slices of the heat map for fixed average A site mass
in
Figure 3.
We note that negative values of the oxygen vacancy formation energies are contained in the ab initio training data and shall typically indicate the instability of the given structure. This aspect will also be discussed below. In the following, we focus on the optimisation of , irrespective of the sign.
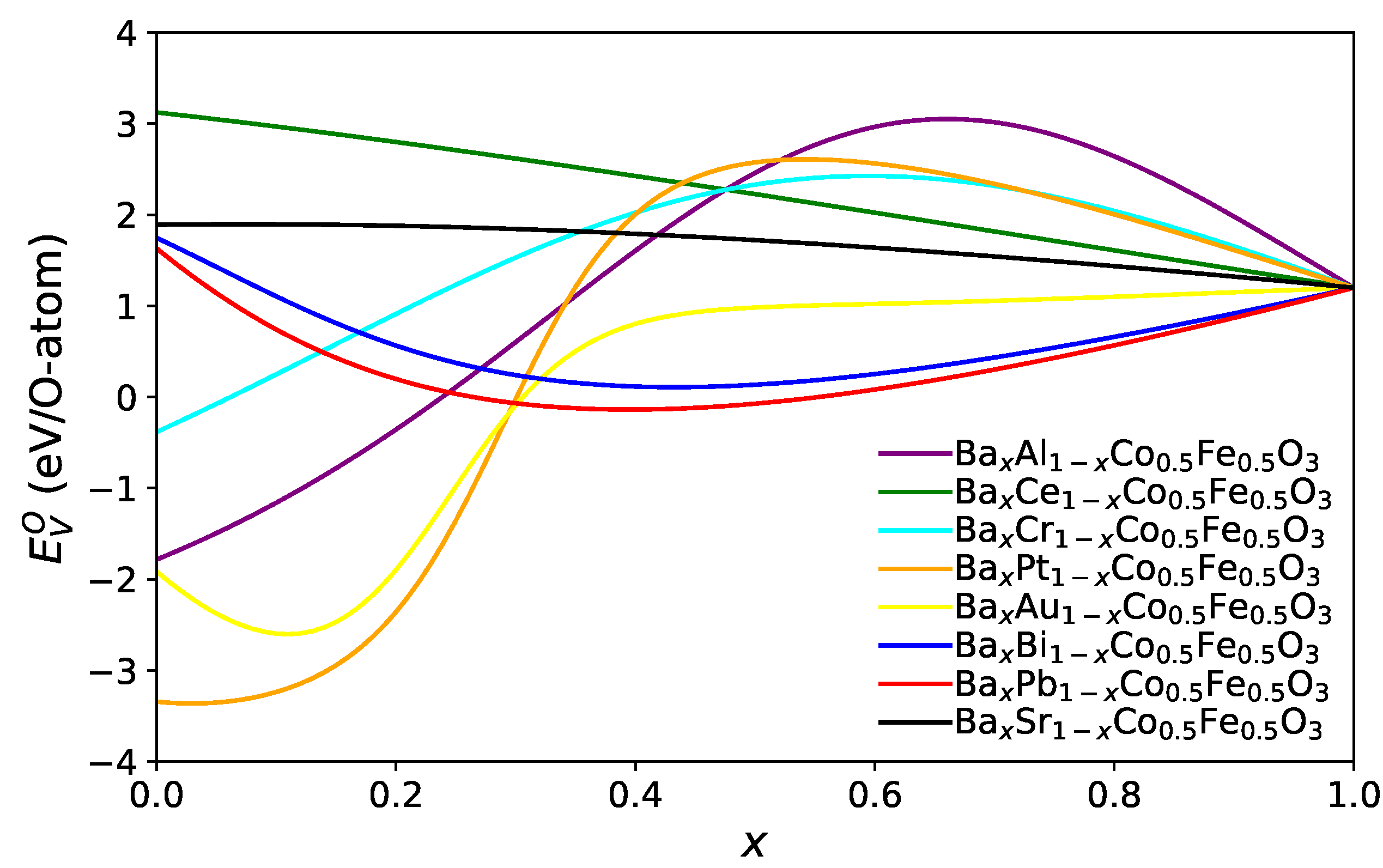
To link the systematic scan of A site parameters to chemical element, we use the model to predict the oxygen vacancy formation energy for a composition A
A
Co
Fe
O
for all possible pairs A
and A
. The dependence on the concentration
x is shown for selected cases of Ba containing compounds in
Figure 4.
For many combinations, the minimum oxygen vacancy formation energy
is found at the limiting values either
or
(this is the case, e.g., for combinations of alkaline and alkaline earth elements), but sometimes, the functional form is very non-monotonic and exhibits one or several extrema. We have determined for each combination the minimum value of
and visualised it in
Figure 5 for combinations of selected elements, which lead to particularly low oxygen vacancy formation energies.
Obviously, this matrix is symmetric concerning (the colour coding), as by construction, this predicted value only depends on the weighted average of the ionic radius, electronegativity and mass of the A site elements. Diagonal elements correspond to pure A site occupation, and off-diagonal elements have the antisymmetry property when A and A are exchanged. A striking observation is that for many A site pairs, the energy is minimised indeed for pure elements ( or ), and only for specific elements such as Re, Os, Pt, and Ir, a substantial decrease of can be obtained compared to pure elements by forming binaries on the A site, i.e., .
The second group of prospective calculations focuses on A
A
Co
Fe
O
systems, with A
being a lanthanide element and A
representing a candidate element from the alkaline earth metals, specifically Mg, Ca, Sr and Ba. The resulting predictions are shown in
Figure 6.
Generally, when A belongs to the group of the first six lanthanide elements, counted from La to Sm, doping with 50% Mg or Ca or Sr or Ba at the A site leads to a reduction of . Here, we should mention that PmSrCoFeO is an exception. If A corresponds to one of the last eight lanthanide elements, counting from Gd to Lu, doping with 50% Ca or Sr or Ba at the A site increases the oxygen vacancy formation energy .
Apart from the influence of the doping for varying chemical composition, also the dependence of
on the ionic radius difference between host element A
and doping element A
has been investigated. As shown in
Figure 7, with an exception for Mg as a dopant, there is a robust trend for the dependence of the oxygen vacancy formation energy difference on the ionic radius difference. The oxygen vacancy formation energy difference is calculated as:
For Ca, Sr and Ba as dopants, the difference in the vacancy formation energy shifts from the positive to the negative regime with increasing difference of the ionic radii of host and dopant. For Mg, no clear trend is visible. Altogether, these observations support the role of the ionic radius as a relevant feature variable for the oxygen vacancy formation energy.
Altogether, preferable air electrode materials for SOCs exhibit low values of , as they correspond to a higher concentration of oxygen vacancies. This promotes rapid oxygen adsorption and dissociation at the electrode.
However, to be a potential air electrode material, there are other conditions that should be also considered, such as the stability of the perovskite structure, a considerable electronic conductivity, and the chemical and mechanical compatibilities with other components in SOCs. The stability of the structure is also related to the sign of , and it is obvious that a comprehensive investigation requires also the consideration of such criteria, which is beyond the scope of the present work.
3.3. Statistical Analysis: Validity of the Applied Transfer Learning Approach
As discussed in
Section 2.2 on artificial neural networks, performing regression via ANNs is in general a non-linear regression. Therefore, the standard approach to estimate the quality of a fit and significance of a regression in terms of
and a
p-value is not generally applicable. Furthermore, we use very asymmetrically sized training and test data sets while assuming we may transfer the model learned on the training data to apply it to the test data based on the formal similarity of the feature spaces for both data sets. The most crucial point that must be addressed concerns the transferability of the trained model to the testing data set. In the ABO
training data set with binary doping, the B site is either Fe or Co, and the determined characteristic is the set
. In the testing A
A
B
B
O
data set, the same characteristic is used, but the radius, electronegativities and masses are obtained as linear superposition in accordance with the stochiometry of the sample. While the format of the features remains unchanged, it is not clear if the choice of linear superposition for the complex doped configurations in the test sample is suitable for the prediction of the oxygen vacancy formation energy. Usually, in applications of transfer learning, the transferred model parameters are used as initialisation of another training of the transferred model, or additional layers are added to adapt the learned model to the new data set. However, due to the limited size of our testing data set, we aim at a direct transfer of the model, which was trained on the 121 ABO
data points to the test data set, which consists of 15 A
A
B
B
O
data points. Consequently, it is required to investigate the feasibility of this approach from a statistical perspective. In addition to the performance of the model on the individual data sets, we therefore also evaluate the discrepancy of the residual distributions in both data sets with respect to the trained model. The evaluation is performed both from a classical null hypothesis testing (NHT) and a Bayesian perspective.
3.3.1. Classical Null Hypothesis Testing
The error in both data sets needs to be normally distributed with zero mean and homoscedastic. Satisfaction of these two criteria tells us—independent of the accuracy of the learned models—how reasonable it is to approach the prediction of the oxygen vacancy formation energies via a machine-learned model. In addition to visual inspection, we conduct the Shapiro–Wilk (SW) [
38] test for normalcy of the residual distribution, a Breush–Pagan (BP) test for heteroscedasticity and the Kolmogorov–Smirnov test for the difference between the two univariate distributions. We briefly recall the idea and evaluation of these three tests before we present the results.
The Shapiro–Wilk test is a test for the null hypothesis that a data set is normally distributed. The sample should not include more than 5000 data points, and the Shapiro–Wilk test is reported to provide a higher power than other normalcy tests based on analysis of variance (ANOVA) in the regime of small data sets with up to 50 data points [
39]. Therefore, it is the test of choice, as we want to use the same test with the same implementation (scikit.stats package) on both data sets for easy comparability. The Shapiro–Wilk test statistic W measures the correlation between the transformed and standardised empirical distribution and the normal distribution and thus has an upper limit of unity. The
p value of the W statistic has to be larger than the desired alpha level of the test, i.e., the probability of false rejection of the null hypothesis.
Concerning the homoscedasticity assumption, the Breush–Pagan test detects linear deviations from a homogeneous variance distribution. The test statistic is defined as scaled by the sample size n, . If it has a p value below 0.05, the null assumption of homoscedasticity is rejected. Due to the smallness of the test data set, we prefer it instead of the White test, which is more sensitive as it covers more types of heteroscedasticity but requires a large sample size as it is an asymptotic test.
The third test we apply is the Kolmogorov–Smirnov (KS) two-sample test. It considers the difference in the empirical distribution functions (i.e., probability that the empirical sample from the assumed distribution takes values up to x)
, with sample sizes
n and
m for training and test data. The test statistic is:
The null hypothesis is the equality of the underlying distribution functions, and for a given alpha level, it is rejected for:
We note that the Kolmogorov–Smirnov test is robust to small sample sizes and is non-parametric; i.e., while the small data set with 15 data points only allows for a check of normality with less power, the Kolmogorov–Smirnov test would not suffer from deviations from normality. However, as pointed out in [
40], the sample sizes for the two-sample KS test should be chosen equally if possible, as increasing asymmetry of the sample sizes leads to higher probability of not rejecting a false null. Therefore, we restrict the training data set to the subset defined by all values which are in the range of the predicted values of the test data set. The resulting restricted training data set contains 38 data points. Consequently, with a confidence level of
, the critical value of the KS test statistic, D, is
. Using the scipy implementation of the two-sample KS test, the value for the KS statistic is
with a
p-value of
. The KS test does not reject the hypothesis of equal distribution functions as
, and the
p-value above the anticipated significance level indicates equality.
We summarize the null hypothesis test-based inspection of the statistical aspects of the training and test data set in
Table 3.
The model trained on the training data set satisfies the normalcy of the residual distribution on both data sets as indicated by the Shapiro–Wilk test results. The Breush–Pagan Test tests the systematic linear deviation from a normal distribution of the residuals. It shows a p value of 3.83% for the training data set and 2.29% for the test data set, indicating that homoscedasticity is not fulfilled. However, while the scaled indicated by the value of the Lagrange parameter is about ≈0.08 for the training data set, it is of order 1 for the test data set. For a standard confidence level of , the assumption of homoscedasticity thus would be rejected, although we see a small value for the squared coefficient of determination for the training data set.
The Kolmogorov–Smirnov two-sample test shows no rejection of the hypothesis of equal underlying distribution of training and test data. While we reduced the difference in sample sizes to take into account the weakness of the KS two-sample test with respect to sample size differences, this is a qualitative approach that would require extensive simulation efforts to be developed as a quantitative scheme. Such simulation efforts are beyond the scope of this article. We note that the KS test statistics are determined for an alpha level of 0.01 to provide a higher requirement on the probability of a false rejection here.
Whereas Breush–Pagan and Kolmogorov–Smirnov testing support the transfer learning approach, the Breush–Pagan test indicates heteroscedasticity especially in the test data set. Therefore, to further investigate the similarity of predictions for training and test data set, the next paragraph provides the results from a Bayesian analysis of the discrepancy of the residual distributions in both data sets. Combining these results and the results from the next section provides a better basis to judge whether the introduced pragmatic transfer learning approach is suitable.
3.3.2. Bayesian Analysis
The formal basis for the comparison of training and test data set is the residual distribution. If the residual distributions in both data sets are not significantly different, it is assumed that the transfer of the learned parameter values from the training to the testing data set is appropriate. To estimate the distributional discrepancies in both data sets via Bayesian analysis, a sampling distribution has to be chosen. Based on the results presented below in
Figure 8, we choose the t-distribution as we see potential finite size effects due to the limited sample size. Therefore, the probabilistic character of the model specification includes not only the mean and standard deviation, as it would in the case of a Gaussian distribution, but also the normality parameter
. The normality parameter controls the strength of the finite size effects in terms of the tail mass in the t-distribution. When
, the t-distribution becomes identical to a Gaussian distribution.
The first part of the Bayesian analysis of the transferability of trained parameters from the training to the testing data set includes a probabilistic modelling of both data sets. Therefore, we perform a Bayesian analysis using the library pymc3 for the characteristics of the t-distributions that we use to model the residual distribution. The random variables for the sampling thus include the mean, standard deviation and normality parameter. Generator distributions are a Gaussian for the mean, a half (positive) Gaussian for the standard deviation and an exponential distribution for the normality parameter. To reflect potential finite size effects in the testing data set, we assign one common normality parameter distribution to the generator samples from both the training and testing data set. The results from this first step of the analysis are visualised in
Figure 8.
In this figure, the distributions approximating the residuals are also evaluated with respect to the highest posterior density (HPD) regions. It is defined as a credible interval in Bayesian analysis, i.e., the interval into which an unobserved parameter will fall with a certain probability. It is the shortest possible interval on the posterior density for the given probability, in our case 0.94 (for further details, we refer to [
41]). As shown in
Figure 8, both residual distributions have a comparably small deviation from zero mean, and the HPDs have a large overlap, indicating a high probability that any residual mean obtained from modelling the training sample could also be obtained from modelling the testing sample. In contrast to that, the means and HPDs of the standard deviation modelling of the residuals show a relevant discrepancy, which requires attention in the following step.
Finally, for the quantitative part of the Bayesian analysis of transferability, the metric for effect size of our choice is Cohen’s d; i.e., it is the ratio of the mean shift to the pooled (symmetrically weighted) standard deviation. Therefore, we consider the distribution of the mean shift between the training and testing data set residual distribution, the distribution of the standard deviation shift between the training and testing data set residual distribution, and the effect size, which is Cohen’s d. With a value of only 0.1, the effect is weak, which suggests that transferability of the trained model from the training to the testing data set is indeed appropriate. The results are shown in
Figure 9.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}