Abstract
Hardenability is one of the most basic criteria influencing the formulation of the heat treatment process and steel selection. Therefore, it is of great engineering value to calculate the hardenability curves rapidly and accurately without resorting to any laborious and costly experiments. However, generating a high-precision computational model for steels with different hardenability remains a challenge. In this study, a combined machine learning (CML) model including k-nearest neighbor and random forest is established to predict the hardenability curves of non-boron steels solely on the basis of chemical compositions: (i) random forest is first applied to classify steel into low- and high-hardenability steel; (ii) k-nearest neighbor and random forest models are then developed to predict the hardenability of low- and high-hardenability steel. Model validation is carried out by calculating and comparing the hardenability curves of five steels using different models. The results reveal that the CML model works well for its distinguished prediction performance with precise classification accuracy (100%), high correlation coefficient (≥0.981), and low mean absolute errors (≤3.6 HRC) and root-mean-square errors (≤3.9 HRC); it performs better than JMatPro and empirical formulas including the ideal critical diameter method and modified nonlinear equation. Therefore, this study demonstrates that the CML model combining material informatics and data-driven machine learning can rapidly and efficiently predict the hardenability curves of non-boron steel, with high prediction accuracy and a wide application range. It can guide process design and machine part selection, reducing the cost of trial and error and accelerating the development of new materials.
1. Introduction
Hardenability is the ability of steel to obtain martensite during quenching, depending on the austenization conditions and cooling rate [1]. Through the degree of hardenability, the most appropriate cooling medium is adopted to obtain the maximum depth of hardened layer under the condition of the minimum deformation of the workpiece. Steel has different applications depending on its hardenability. Low-hardenability steels have high surface hardness and good core toughness, and they are widely used in automobile gears, machine tool spindles, and industrial sectors [2]. High-hardenability steels normally have large quenchable section sizes of workpieces. Strong workpieces, i.e., springs, are usually made of high-hardenability steel to ensure that they can be quenched to a martensite structure [3]. Tools are also made of high-hardenability steels in order to obtain high strength, hardness, and wear resistance [4]. Therefore, hardenability can not only guide the design of the heat treatment process, but also serve as an important reference for the selection of machine parts [5].
The hardenability of steel is usually expressed as a hardenability curve. It is very laborious and costly to obtain hardenability curves through experiments, especially in a trial-and-error design. Therefore, calculation methods are used more often. As the hardenability mechanism of boron is different from other alloying elements, the calculation of hardenability of boron steel is complicated [6]. Trace amounts of boron (0.001–0.003 wt.%) can significantly improve the hardenability of steel. When the cooling rate is high, boron is adsorbed on the grain boundaries in an atomic state, which can inhibit and delay ferrite transformation and, thus, improve hardenability [7]. Upon decreasing the cooling rate, boron can be precipitated as boron phase, which leads to nonspontaneous nucleation and a sharp decrease in hardenability [8]. Therefore, only the calculation of hardenability curves of non-boron steels is discussed in this study. Empirical formulas based on experimental data and mathematical models based on phase transition dynamics were mainly used in the past to calculate hardenability curves. In recent years, machine learning models have been used to predict hardenability curves in order to ascertain the quenching behavior of steels. Grossman et al. [9] proposed the ideal critical diameter () method, which calculates on the basis of the chemical composition and grain size of steel, and then established the relationship between and the end-quenching curve. However, the calculation error was large, and it was only suitable for medium- and low-hardenability steel, hindering its application in practical production [10]. Just et al. [11] established regression equations to calculate the end-quenching curve on the basis of experimental data. However, their universality, accuracy, and rationality were also greatly limited, mainly because the linear mathematical model did not adapt to the actual shape and variation trend of the curve. Yu et al. [12] established nonlinear equations to predict the hardenability and mechanical properties. The modified nonlinear equation (MNE) was obtained through improvement, which further improved the prediction accuracy. Kirkaldy et al. [13] and Honeycombe et al. [14] calculated the hardenability of steel through the continuous cooling transformation (CCT) diagram of Jominy end-quenched bars on the basis of phase transformation kinetics and thermodynamics, and this method was integrated into the commercial software JMatPro. According to this model, the relationship between cooling rate temperatures and end-quenching distances can be expressed as
where η is the diffusivity at distance X (in cm) along the Jominy bar, T is the temperature, and Ta is the austenization temperature. Thus, the new phase volume fraction τ can be expressed as Equation (3) to calculate the TTT diagram; then, Scheil’s addition rule [15] can be used to convert the TTT diagram to a CCT diagram. Each cooling rate of the CCT diagram corresponds to a data point of the Jominy end-quenching bar.
where αj is the constant for each element, Cj is the concentration of the element, and Qeff is the effective activation energy for diffusion. The phase transformation reaction rate at any time is the derivative of the phase transformation volume fraction τ with time. Kirkaldy et al. believed that the inflection point of the phase transformation reaction rate is the same as that in TTT diagram and in proportion with the CCT diagram. Therefore, the points corresponding to the CCT diagram must correspond to the inflection point of the Jominy curve. Lastly, the corresponding Vickers pyramid number (VPN) is calculated as
where Y1 and Y2 are the calculated hardness values of martensite and pearlite, respectively, in the alloy, and X0 is the distance from the inflection point of the Jominy curve to the quenching end.
With the development of the Materials Genome Initiative (MGI) [16] and Integrated Computational Materials Engineering (ICME) [17], data-driven machine learning methods have been gradually introduced into material design and development, with great achievements in various fields [18,19,20,21]. These methods can make rapid predictions on the basis of existing experimental data and effectively deal with the complex multivariate nonlinear relationship between input and output variables. Churyumov et al. [22] constructed an artificial neural network model for predicting flow stress of high-alloyed, corrosion-resistant steel during hot deformation. Honysz et al. [23] used generalized regression neural networks (GRNNs) to more accurately predict the chemical concentration of carbon and nine of the other most common alloying elements in ferritic stainless steels on the basis of the mechanical properties with the best efficiency. Artificial neural network algorithms have also been used to predict the hardenability of steel [24,25,26]. Gao et al. [27] applied polynomial regression and artificial neural networks to predict the hardenability of gear steels. Dong et al. [28] built a chemical composition–hardenability model for wear-resistant steels using an artificial neural network. However, these studies were modeled for specific steel grades; hence, the applicability of the models is limited. The change trends of high- and low-hardenability steel are different. Therefore, it is very necessary to obtain a calculation model with high accuracy and a wide application range.
In this study, a combined machine learning (CML) model is developed to effectively predict the hardenability of non-boron steels. Through collecting data, modeling, and evaluating classification and regression models, the optimal CML model is established. Due to the complex influence of composition, the hardenability curves of steels vary greatly. In order to improve the prediction accuracy and application range of the model, random forest (RF) is firstly used to divide the steel into low- and high-hardenability steel. Then, k-nearest neighbor (k-NN) is used to predict the quenching curve of low-hardenability steel, while random forest is used as the optimal prediction model for high-hardenability steel. To further verify the accuracy of the CML model, the hardenability curves of five steels are predicted by this model and other methods. The results show that the hardenability curve calculated by CML model is in excellent agreement with the experimental ones, and the prediction accuracy of this model is better than that of JMatPro software, the ideal critical diameter method, and the modified nonlinear equation. Therefore, the CML model combining material informatics and data-driven machine learning can quickly and efficiently predict the hardenability curve of non-boron steel, with high prediction accuracy and a wide application range. It has certain guiding significance for heat treatment process design and mechanical part selection, which can accelerate new material research and development.
2. Methodology
2.1. Data Collection and Preprocessing
In this study, the hardenability curves of 126 different steels were obtained from published studies [2,29,30,31], of which 121 groups were used for training and five groups were used for testing. The ranges of composition, austenitizing temperature (AT), and Jominy equivalent cooling rate () are shown in Supplementary Table S1 (refer to electronic Supplementary Materials). Due to the complex influence of alloying elements, the hardness variation trends of low- and high-hardenability steels are different. The hardenability curves of low-hardenability steel (5SiMnMoV) and high-hardenability steel (40CrNiMoA) are shown in Figure 1. In the figure, the horizontal axis is the distance to the quenching end X (mm), while the vertical axis is the hardness (HRC). It can be seen that the hardness of low-hardenability steel decreases continuously from the water-cooled end until it approaches the horizontal line. Due to the low critical cooling rate of high-hardenability steel, martensite can be obtained in a range greater than the critical cooling rate. Therefore, its hardness does not change much within a certain distance from the water-cooled end, beyond which it begins to decline. The hardenability curves or hardenability bands collected in this study were obtained from end-quenched specimens using the Jominy method. For certain grades of steel, because their chemical composition fluctuates within a certain range, hardenability bands are obtained rather than a line. In order to obtain more statistically significant data, the average value of the upper and lower limits of the hardenability bands should be taken as the hardenability curve. These hardenability curves can be converted from graphical format to numerical format, i.e., distance versus hardness (X-HRC). All points were taken manually, and hardness values were obtained at 1.5 mm or 3 mm intervals along the horizontal axis, resulting in a training set and test set. Then, the training and test datasets were converted to CSV file format. Each dataset contained 11 input variables, whose attributes were numeric. The number of instances in the training datasets of low- and high-hardenability steels is shown in Supplementary Table S2.
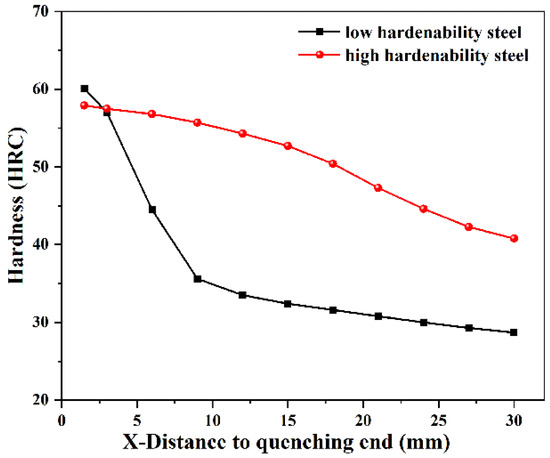
Figure 1.
Hardenability curves for low- and high-hardenability steels.
2.2. Feature Selection
Feature selection is the key step in the data analysis process, which greatly affects the results of machine learning. Chemical composition and austenite grain size are some of most important factors affecting hardenability [32]. However, austenite grain size was not used as a feature parameter due to a lack of relevant data. Therefore, the input feature parameters of the present model included the chemical composition (C, Si, Mn, Cr, Ni, Mo, W, V, Ti, Cu) and the distance X along the Jominy bar (1.5, 3, 6, 9, 12, 15, 18, 21, 24, 27, and 30 mm). The output feature parameter was the hardness value (in HRC). The relationship between the hardness value and the selected features can be described by Equation (6).
In order to further verify the relationship between alloying elements and hardenability, a Pearson correlation map was calculated using the training data with blue and red colors indicating positive and negative correlations, respectively. A lighter tone indicates a less significant corresponding correlation. The filled fraction of each pie chart in the graph corresponds to the absolute value of the associated Pearson correlation coefficient. Here, the hardness 15 mm away from the cold quenching end was taken as the hardenability index, marked as J15. The Pearson correlation map for J15 and chemical elements is shown in Figure 2. It can be seen that C had the greatest influence on hardenability of steels, while hardenability increased with increasing C content. Alloying elements Cr, Ni, Mo, W, and Si had positive correlations with hardenability, indicating that they could improve hardenability to varying degrees. Micro-alloy elements V and Ti were negatively correlated with hardenability, indicating that their addition reduced hardenability. For example, V can consume C in the solution to form carbonitride, thus reducing hardenability [33]. Ti probably reduces hardenability for the same reasons. The correlation of Mn and Cu with hardenability was not obvious, indicating that Mn and Cu were not linearly correlated with hardenability. In summary, the influence of alloying elements on hardenability was basically consistent with the common knowledge of materials.
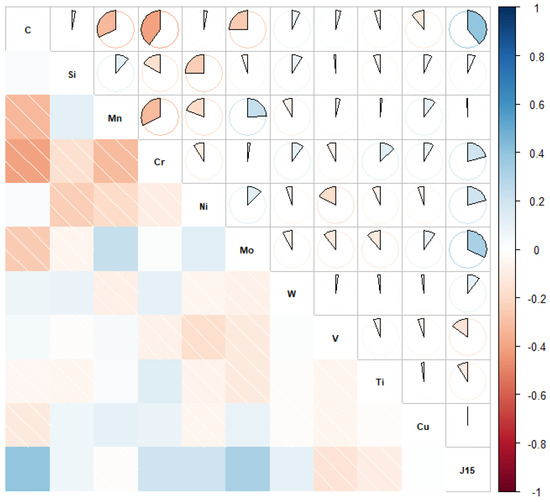
Figure 2.
Pearson correlation map of hardenability and chemical elements.
2.3. Machine Learning Models
A variety of machine learning algorithms were applied to build prediction models of hardenability curves using Weka 3.9. K-NN is a nonparametric method used for classification and regression [34]. The mean of top k labels is used for the regression task, while the mode of top k labels is used in the case of classification. Multilayer perceptron is a feedforward artificial neural network model that is trained on a set of input–output pairs and learns to model the correlation between those inputs and outputs. Training involves adjusting the parameters or weights and biases of the model in order to minimize error. Backpropagation is used to make these weight and bias adjustments relative to the error. Multilayer perceptron classifier (MLP-C) and multilayer perceptron regression (MLP-R) can handle classification and regression problems, respectively, and MLP-R was mostly used to predict the hardenability curves in previous studies [24,25,26]. SVC is a classifier that is used for predicting discrete categorical labels, while SVR is a regression algorithm that supports both linear and nonlinear regressions, used for predicting continuous ordered variables [35]. Radial basis function (RBF) networks were trained in a fully supervised manner using WEKA’s optimization class by minimizing the squared error according to the BFGS method [36]. Bagging (bootstrap aggregating) is a simple and effective integration method to obtain training subsets on the basis of uniform random sampling with replacement [37]. RF is an ensemble learning method for classification, regression, and other tasks that operates by constructing a multitude of decision trees at training time, which can handle complex multivariable nonlinear problems with good generalization ability and resistance to overfitting [38].
2.4. Model Evaluation
In order to reduce the influence of unfitting and overfitting problems on calculations, appropriate evaluation methods and indicators need to be chosen for established models. In this paper, 10-fold cross-validation was adopted, whereby the original sample set was randomly divided into 10 equal-sized subsample sets, among which nine subsample sets were used as training data and the remaining subsample set was used as validation data [39]. By repeating the above process 10 times, each subsample set was used as validation data only once. For the classification model, the evaluation parameters were the values of accuracy [40], F1-score [41], and area under curve (AUC) [42]. Accuracy can reflect the ability of a classification model to judge the whole sample, as shown in Equation (7), where TP is true positive, FP is false positive, FN is false negative, and TN is true negative. The F1-score can be regarded as the weighted average of accuracy and recall rate, as shown in Equation (8). Higher values of accuracy and F1-score indicate better discriminability of the model. AUC is the area under the receiver operating characteristic (ROC) curve, which enables a reasonable evaluation of the classifier in the case of unbalanced samples. The classifier performs better if the AUC value is closer to 1.
One of the evaluation indicators of a regression model is the correlation coefficient (CC, Equation (9)) [43], where , are the experimental values and predicted values, and , are the corresponding average values, respectively. CC is a real number between −1 and 1, and a greater absolute value represents a higher correlation between input and output features. Generally, an absolute value of CC greater than 0.8 is considered as highly correlated. In this study, the minimum CC standard was set to be 0.95 to ensure reliable prediction results.
The mean absolute error (MAE, Equation (10)) and root-mean-square error (RMSE, Equation (11)) are used to evaluate the difference between experimental and predicted values [43], where is the experimental value, is the predicted value, and n is the number of samples. Lower values of MAE and RMSE denote better consistency between measured and predicted hardness, as well as a more accurate learning model. According to the evaluation thresholds of CC > 0.95 and MAE/RMSE < 3 HRC, an optimal model was obtained to predict hardenability.
3. Results and Discussion
3.1. Classification Model
The mutual interaction of various alloying elements in steel is undoubtedly complex, which leads to a significant difference in the hardenability curves of steels. Therefore, the preliminary classification of steels based on the calculated was the first stage of the hardenability modeling method. The calculation formula of is shown in Equation (12).
where is the calculation factor of the grain size grade, and , , , , , , , and are the calculation factors of alloying elements, which can be obtained from the American Society for Testing Materials A255-20a (ASTM A255-20a). In this study, was 1.0, corresponding to the calculated factor value for a granularity of 7. When the calculated of steel was greater than 80, it was regarded as a high-hardenability steel. Otherwise, it was considered as a low-hardenability steel.
Classification models were established using bagging, k-NN, MLP-C, SVC, and RF. Figure 3 shows the training results. As can be seen, the accuracy rate and F1-score value of RF were the highest, both reaching 92.1%. The AUC of RF was also the maximum, being 0.953. The accuracy and F1-score of k-NN and MLP-C were 91.3%. However, the AUC of k-NN was 0.917, lower than that of RF. MLP-C had a similar AUC value to RF, but RF had higher accuracy and stronger generalization ability than MLP-C. Therefore, RF was taken as the optimal classification model.
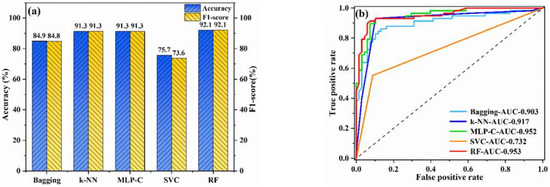
Figure 3.
The performance of classification models on the training set: (a) accuracy and F1-score; (b) ROC curves.
3.2. Regression Model
Regression models included the bagging, k-NN, MLP-R, SVR, RBF, and RF models. In order to make a more intuitive comparison, scatter diagrams were adopted to show the training results of these models, as shown in Figure 4 and Figure 5. In these scatter plots, darker colors represent smaller absolute values in error. For absolute values of error greater than 18 HRC, the point was colored gray. More points concentrated on the line y = x indicated better performance of the model.
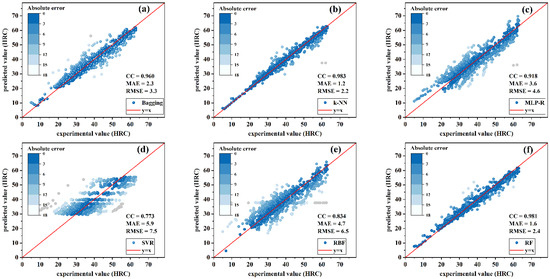
Figure 4.
Training results of regression models for low-hardenability steels: (a) bagging; (b) k-NN; (c) MLP-R; (d) SVR; (e) RBF; (f) RF.
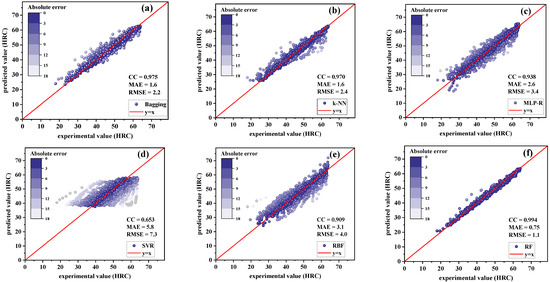
Figure 5.
Training results of regression models for high-hardenability steels: (a) bagging; (b) k-NN; (c) MLP-R; (d) SVR; (e) RBF; (f) RF.
For low-hardenability steels, as shown in Figure 4, the predicted values of k-NN were more concentrated on the oblique 45° line compared with other algorithms; k-NN had the highest trained CC value of 0.983 and the smallest MAE and RMSE, 1.2 HRC and 2.2 HRC, respectively. On the other hand, SVR had the worst prediction performance with CC equal to 0.773, and MAE and RMSE equal to 5.9 and 7.5 HRC, respectively. It can also be seen that the prediction values of k-NN had the strongest correlation with the experimental data.
Figure 5 shows the results of the training model for high-hardenability steels. It can be seen that the calculated data points were more concentrated in the vicinity of oblique 45° reading line for RF, with the largest CC value (0.994) and the smallest error values, with MAE being 0.75 HRC and RMSE being 1.1 HRC. The training results of SVR were also the worst, with the lowest CC value and the largest error values, indicating that SVR is not suitable for the regression prediction of the hardenability of steels. Since the RF algorithm performed very well for both high-hardenability steels and low-hardenability steels, it was further used to establish the optimal prediction model of the hardenability of steels.
3.3. Model Validation
In order to verify the accuracy of the classification model and further determine the optimal regression model, the hardenability curves of five randomly selected steels with different compositions were chosen as test samples. The chemical compositions of these test samples are shown in Supplementary Table S4. The number of instances in the test datasets is shown in Supplementary Table S5. Among these steels, #1 and #2 steels were low-hardenability steels, while #3, #4, and #5 steels were high-hardenability steels. The hardenability curves of these five steels were used as the verification set; thus, data of these five steels were not included in the training set. RF could accurately classify steels, playing a very important role in the subsequent calculation of the regression model. These five steels were classified by RF, and an accuracy of classification of 100% was obtained, indicating that RF could accurately classify steels, enabling the hardenability curve to be accurately calculated by the regression model.
Six regression models were then used to predict the hardenability curves of steels. The correlation coefficients and error values are shown in Figure 6. For #1 steel, the CC value of k-NN was relatively higher than others; the MAE and RMSE of k-NN were the smallest, 2.2 HRC and 3.0 HRC respectively. RF was better than k-NN in predicting the hardenability curve of #2 steel. However, the performance of RF was worse than that of k-NN in the training set. Therefore, k-NN was chosen as the optimal prediction model for low-hardenability steels. For high-hardenability steels, it can be seen that the CC values of all algorithms were all higher than 0.95. For #4 and #5 steels, the error values of RF were the smallest, with MAE being 0.3 and 0.4 HRC and RMSE being 0.8 and 0.8 HRC, respectively. As for #3 steel, the data distribution led to SVR having the smallest MAE and RMSE in the test set. However, the MAE and RMSE of SVR for #4 and #5 steel were higher than those of RF, and the performance of SVR in the training set was the worst. Therefore, SVR was not considered as the optimal model. RF was, thus, selected as the prediction model for high-hardenability steel.
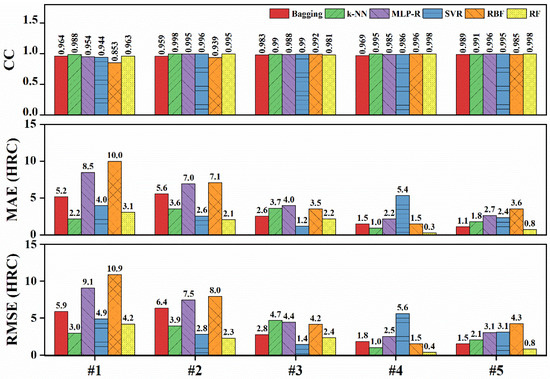
Figure 6.
Correlation coefficients and error values of the prediction result on the test sets.
Finally, these classification and regression models were combined to form a CML model to calculate the hardenability curves of non-boron steels, and the flow chart is shown in Figure 7. In the CML model, non-boron steels were divided into high-hardenability steels and low-hardenability steels by RF. Then, the k-NN model was established to predict the hardenability curves of low-hardenability steels, and the RF model was used for the calculation of the hardenability curves of high-hardenability steels. The optimized parameters and package version of the models are shown in Supplementary Table S3. The applicability of the CML model depends largely on the training dataset and the generalization ability of the arithmetic. Therefore, it can be considered that the present CML model has relatively high prediction accuracy for steel in the range of compositions listed in Supplementary Table S1.
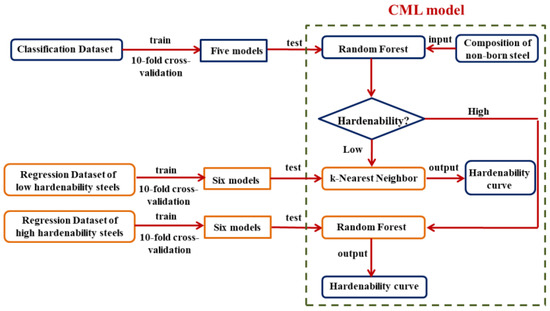
Figure 7.
Flow chart of the CML model for predicting hardenability curves of non-boron steels.
3.4. Comparison of CML Model with Others
In order to further verify the accuracy of the present CML model, the prediction results of CML were compared with the method, the MNE model, and the commercial software JMatPro. In the empirical formula and JMatPro, the grain size was also set to 7. The comparison of errors calculated by different methods is shown in Figure 8, and the comparison results of calculated hardenability curves are shown in Figure 9, where the black line indicates the experimental results, while the red, blue, orange, and green lines represent the prediction results of the CML, JMatPro, , and MNE models, respectively. It can be seen that the present CML model could accurately predict the hardenability curve of steels and was superior to the method, the MNE model, and JMatPro. The present CML model had the smallest calculation errors, and the predicted hardenability curves of CML were more consistent with the experimental ones than the curves of others, especially for the #1, #4, and #5 steels. For example, the MAE and RMSE of CML were both smaller than 3 HRC, except for #2 steel, but the errors of #2 steel were still much smaller than those of other models. For #1 and #2 steels, the overall change trends predicted by JMatPro were away from experimental ones. The calculation error of JMatPro started to increase when X was greater than 10 mm for #3 and #4 steels. Although the MAE and RMSE of JMatPro for #5 steel were small, 1.4 HRC and 1.6 HRC, respectively, the hardenability curve predicted by the CML model was closer to the experimental one than that of JMatPro. Therefore, the accuracy of JMatPro for the overall prediction of the steel hardenability curve was not high enough. Compared with CML model, the errors of MNE and were quite large for both low-hardenability steels and high-hardenability steels.
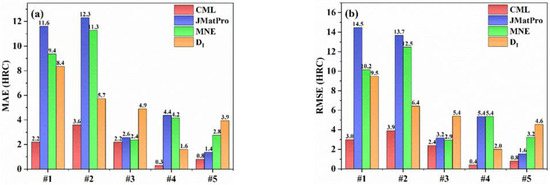
Figure 8.
Comparison of the error values calculated by different calculation methods on the test set: (a) MAE; (b) RMSE.
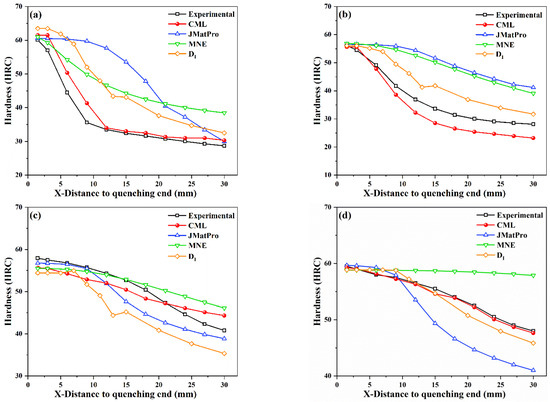
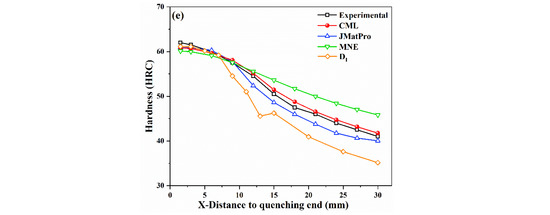
Figure 9.
Comparison of experimental and predicted hardenability curves of steels by CML, JMatPro, MNE, and ; (a) #1-5SiMnMoV; (b) #2-42SiMn; (c) #3-40CrNiMoA; (d) #4-45CrMnMo; (e) #5-50CrMnVA.
In summary, an effective CML model to predict hardenability curves of steels was established only on the basis of chemical compositions and distance along the Jominy bar, making the prediction of hardenability curves more convenient and accurate during alloy design.
4. Conclusions
A combined machine learning (CML) model including classification and regression was developed to predict the hardenability curves of non-boron steels using chemical composition and distance along the Jominy bar. Bagging, k-NN, MLP-C, MLP-R, SVC, SVR, RBF, and RF algorithms were applied on experimental datasets, and an optimal model was selected by comparing the results of 10-fold cross-validation, in terms of correlation coefficients and error values. In the present CML model, steels are first classified into low-hardenability or high-hardenability steel by RF. For low-hardenability steels, k-NN had the best prediction performance and was, thus, selected as the optimal model. For high permeability steels, RF was adopted as the optimal model for hardenability curves.
The accuracy of the present CML model was verified by comparing the predicted results with experimental ones and prediction results of JMatPro, the ideal critical diameter method, and modified nonlinear equations. A superior predictive performance was obtained by the present CML model with a classification accuracy of 100%, high correlation coefficients, and low error values.
The findings of this work can realize the potential of big data mining. By using existing experimental data and machine learning algorithms to calculate the process curves and mechanical properties of steels, the experimental cost can be reduced, and the development of new materials can be accelerated.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/ma15093127/s1, Supplementary Table S1: Range of composition (wt.%), austenitizing temperature (AT, °C) and Jominy equivalent cooling rate (, °C/s) of the steels; Supplementary Table S2: Number of instances in the training datasets; Supplementary Table S3: Optimized parameters and package; Supplementary Table S4: Chemical composition of test set (wt.%); Supplementary Table S5: Number of instances in the test set; Supplementary Note S1: The basic principles of machine learning algorithms [44,45,46,47,48,49,50,51].
Author Contributions
Conceptualization, H.W.; methodology, X.G.; software, S.W.; validation, X.G.; investigation, G.W.; resources, S.W.; data curation, H.W.; writing—original draft preparation, X.G.; writing—review and editing, A.U. and G.W.; visualization, G.W. All authors have read and agreed to the published version of the manuscript.
Funding
The authors greatly acknowledge the financial support from the National Key Research and Development Program of China (No. 2021YFB3702400) and the National Natural Science Foundation of China (NSFC, No. 52071038).
Institutional Review Board Statement
Ethical approval is not required for the study.
Informed Consent Statement
This study did not involve humans.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Canale, L.C.F.; Albano, L.; Totten, G.E.; Meekisho, L. Hardenability of Steel. In Comprehensive Materials Processing; Hashmi, S., Ed.; Elsevier: Amsterdam, The Netherlands, 2014; pp. 39–97. [Google Scholar]
- Ohmori, A.; Torizuka, S.; Nagai, K. Strain-hardening due to Dispersed Cementite for Low Carbon Ultrafine-grained Steels. ISIJ Int. 2004, 44, 1063–1071. [Google Scholar] [CrossRef]
- Fedin, V.M.; Borts, A.I. Volume-surface hardening of freight bogie springs from steels with reduced and controlled hardenability. Met. Sci. Heat Treat. 2009, 51, 544–552. [Google Scholar] [CrossRef]
- Anggraini, L. Hardenability of ASSAB 760 Steel during Tempering for Punch Holder Applications. Solid State Phenom. 2017, 266, 13–18. [Google Scholar] [CrossRef]
- Santa-aho, S.; Sorsa, A.; Honkanen, M.; Vippola, M. Detailed Barkhausen noise and microscopy characterization of Jominy end-quench test sample of CF53 steel. J. Mater. Sci. 2020, 55, 4896–4909. [Google Scholar] [CrossRef]
- Geng, X.; Cheng, Z.; Wang, S.; Peng, C.; Ullah, A.; Wang, H.; Wu, G. A data-driven machine learning approach to predict the hardenability curve of boron steels and assist alloy design. J. Mater. Sci. 2022, 1–14. [Google Scholar] [CrossRef]
- Kamada, Y.; Kurayasu, H.; Watanabe, S. Relation between hardenability and segregation to austenite grain boundaries of boron atom on direct quenching process. Tetsu-to-Hagane 2010, 74, 2153–2160. [Google Scholar] [CrossRef][Green Version]
- Biaobrzeska, B. Effect of alloying additives and microadditives on hardenability increase caused by action of boron. Metals 2021, 11, 589. [Google Scholar] [CrossRef]
- Grossman, M.A. Hardenability calculated from chemical compositions. Trans. AIME 1942, 150, 227–259. [Google Scholar]
- Umemoto, M.; Nishioka, N.; Tamura, I. Prediction of Hardenability from Isothermal Transformation Diagrams. J. Heat Treat. 1981, 2, 130–138. [Google Scholar] [CrossRef]
- Just, E. New formulas for calculating hardenability curves. Met. Prog. 1969, 96, 87–88. [Google Scholar]
- Yu, B.H. Nonlinear equations for calculating hardenability and mechanical property. Iron Steel 1985, 3, 40–49. [Google Scholar]
- Kirkaldy, J.S.; Venugopolan, D. Phase Transformations in Ferrous Alloys; AIME: Englewood, CO, USA, 1983. [Google Scholar]
- Honeycombe, R.W.K. Steels: Microstructure and Properties; Edward Arnmold: London, UK, 1980. [Google Scholar]
- Kang, S.-H.; Im, Y.-T. Finite element investigation of multi-phase transformation within carburized carbon steel. J. Mater. Process. Technol. 2007, 183, 241–248. [Google Scholar] [CrossRef]
- Breneman, C.M.; Brinson, C.L.; Schadler, L.S.; Natarajan, B.; Krein, M.; Wu, K.; Morkowchuk, L.; Li, Y.; Deng, H.; Xu, H.Y. Stalking the materials genome: A data-driven approach to the virtual design of nanostructured polymers. Adv. Funct. Mater. 2013, 23, 5746–5752. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.Y.; Li, J.; Liu, W.; Liu, Z.-K. Integrated computational materials engineering for advanced materials: A brief review. Comput. Mater. Sci. 2019, 158, 42–48. [Google Scholar] [CrossRef]
- Geng, X.; Wang, H.; Xue, W.; Xiang, S.; Huang, H.; Meng, L.; Ma, G. Modeling of CCT diagrams for tool steels using different machine learning techniques. Comput. Mater. Sci. 2020, 171, 109235. [Google Scholar] [CrossRef]
- Wang, J.; Fa, Y.; Tian, Y.; Yu, X. A machine-learning approach to predict creep properties of Cr–Mo steel with time-temperature parameters. J. Mater. Res. Technol. 2021, 13, 635–650. [Google Scholar] [CrossRef]
- Geng, X.; Wang, H.; Ullah, A.; Xue, W.; Xiang, S.; Meng, L.; Ma, G. Prediction of Continuous Cooling Transformation Diagrams for Ni-Cr-Mo Welding Steels via Machine Learning Approaches. JOM 2021, 72, 3926–3934. [Google Scholar] [CrossRef]
- Zhang, L.; Qian, K.; Huang, J.; Liu, M.; Shibuta, Y. Molecular dynamics simulation and machine learning of mechanical response in non-equiatomic FeCrNiCoMn high-entropy alloy. J. Mater. Res. Technol. 2021, 13, 2043–2054. [Google Scholar] [CrossRef]
- Churyumov, A.; Kazakova, A.; Churyumova, T. Modelling of the steel high-temperature deformation behaviour using artificial neural network. Metals 2022, 12, 447. [Google Scholar] [CrossRef]
- Honysz, R. Modeling the chemical composition of ferritic stainless steels with the use of artificial neural networks. Metals 2021, 11, 724. [Google Scholar] [CrossRef]
- Gao, X.-H.; Qi, K.-M.; Deng, T.-Y.; Qiu, C.-L.; Zhou, P.; Du, X.-B. Application of artificial neural network to predicting hardenability of gear steel. J. Iron Steel Res. Int. 2006, 13, 71–73. [Google Scholar] [CrossRef]
- Trzaska, J.; Sitek, W.; Dobrzański, L.A. Application of neural networks for selection of steel grade with required hardenability. Int. J. Comput. Mater. Sci. Surf. Eng. 2007, 1, 366–382. [Google Scholar] [CrossRef]
- Knap, M.; Falkus, J.; Rozman, A.; Konopka, K.; Lamut, J. The prediction of hardenability using neural networks. Arch. Metall. Mater. 2014, 59, 133–136. [Google Scholar] [CrossRef]
- Gao, X.H.; Deng, T.Y.; Wang, H.R.; Qiu, C.L.; Qi, K.M.; Zhou, P. Prediction of Hardenability of Gear Steel Using Stepwise Polynomial Regression and Artificial Neural Network. Adv. Mater. Res. 2010, 118–120, 332–335. [Google Scholar] [CrossRef]
- Dong, G.; Li, X.; Zhao, J.; Su, S.; Misra, R.; Xiao, R.; Shang, C. Machine learning guided methods in building chemical composition-hardenability model for wear-resistant steel. Mater. Today Commun. 2020, 24, 101332. [Google Scholar] [CrossRef]
- Liu, X.Q. Hardenability Hand-Book of Steels; Chemical Industry Press: Beijing, China, 2011. [Google Scholar]
- Hu, Z.Z. Handbook of Steel and Heat Treatment Curves; National Defense Industry Press: Beijing, China, 2011. [Google Scholar]
- Sun, Z.B.; Zhu, P.F.; Lin, H.G.; Yu, T.S. Handbook of Alloy Steel; Metallurgical Industry Press: Beijing, China, 1992. [Google Scholar]
- Kirkaldy, J.S. Quantitative Prediction of Transformation Hardening in Steels; ASM International: Novelty, OH, USA, 1991; Volume 4, pp. 20–32. [Google Scholar]
- Adrian, H. A mechanism for effect of vanadium on hardenability of medium carbon manganese steel. Mater. Sci. Technol. 1999, 15, 366–378. [Google Scholar] [CrossRef]
- Pan, Z.B.; Wang, Y.K.; Pan, Y.W. A new locally adaptive k-nearest neighbor algorithm based on discrimination class. Knowl.-Based Syst. 2020, 204, 106185. [Google Scholar] [CrossRef]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. 1998, 13, 18–28. [Google Scholar] [CrossRef]
- Chen, S.; Cowan, C.F.N.; Grant, P.M. Orthogonal least squares learning algorithm for radial basis function networks. IEEE Trans. Neural Netw. 1991, 2, 302–309. [Google Scholar] [CrossRef]
- Xue, L.; Liu, Y.; Xiong, Y.; Liu, Y.; Cui, X.; Lei, G. A data-driven shale gas production forecasting method based on the multi-objective random forest regression. J. Pet. Sci. Eng. 2021, 196, 107801. [Google Scholar] [CrossRef]
- Chelgani, S.C.; Matin, S.S.; Makaremi, S. Modeling of free swelling index based on variable importance measurements of parent coal properties by random forest method. Measurement 2016, 94, 416–422. [Google Scholar] [CrossRef]
- Xiong, Z.; Cui, Y.; Liu, Z.; Zhao, Y.; Hu, M.; Hu, J. Evaluating explorative prediction power of machine learning algorithms for materials discovery using k-fold forward cross-validation. Comput. Mater. Sci. 2020, 171, 109203. [Google Scholar] [CrossRef]
- Baldi, P.; Brunak, S.; Chauvin, Y.; Andersen, C.A.F.; Nielsen, H. Assessing the accuracy of prediction algorithms for classification: An overview. Bioinformatics 2000, 16, 412–424. [Google Scholar] [CrossRef] [PubMed]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Sonego, P.; Kocsor, A.; Pongor, S. ROC analysis: Applications to the classification of biological sequences and 3D structures. Brief. Bioinform. 2008, 9, 198–209. [Google Scholar] [CrossRef] [PubMed]
- Geng, X.; Mao, X.; Wu, H.-H.; Wang, S.; Xue, W.; Zhang, G.; Ullah, A.; Wang, H. A hybrid machine learning model for predicting continuous cooling transformation diagrams in welding heat-affected zone of low alloy steels. J. Mater. Sci. Technol. 2022, 107, 207–215. [Google Scholar] [CrossRef]
- Kam, H.T. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; pp. 278–282. [Google Scholar]
- Ho, T.K. The Random Subspace Method for Constructing Decision Forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 8, 832–844. [Google Scholar]
- Berk, R.A. Statistical Learning from a Regression Perspective; Springer: New York, NY, USA, 2008. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: New York, NY, USA, 2013; Volume 6, pp. 316–321. [Google Scholar]
- Altman, N.S. An introduction to kernel and nearest-neighbor nonparametric regression. Am. Stat. 1992, 46, 175–185. [Google Scholar]
- Hsu, B. Generalized linear interpolation of language models. In Proceedings of the 2007 IEEE Workshop on Automatic Speech Recognition & Understanding (ASRU), Kyoto, Japan, 9–13 December 2007; pp. 136–140. [Google Scholar]
- Vries, A.P.D.; Mamoulis, N.; Nes, N.; Kersten, M. Efficient k-NN search on vertically decomposed Data. In Proceedings of the 2002 ACM SIGMOD International Conference on Management of Data, Madison, WI, USA, 3–5 June 2002; pp. 322–333. [Google Scholar]










Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).