
Defect Classification for Additive Manufacturing with Machine Learning



Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Generation and Feature Extraction
2.2. Modeling and Testing
3. Results and Discussion
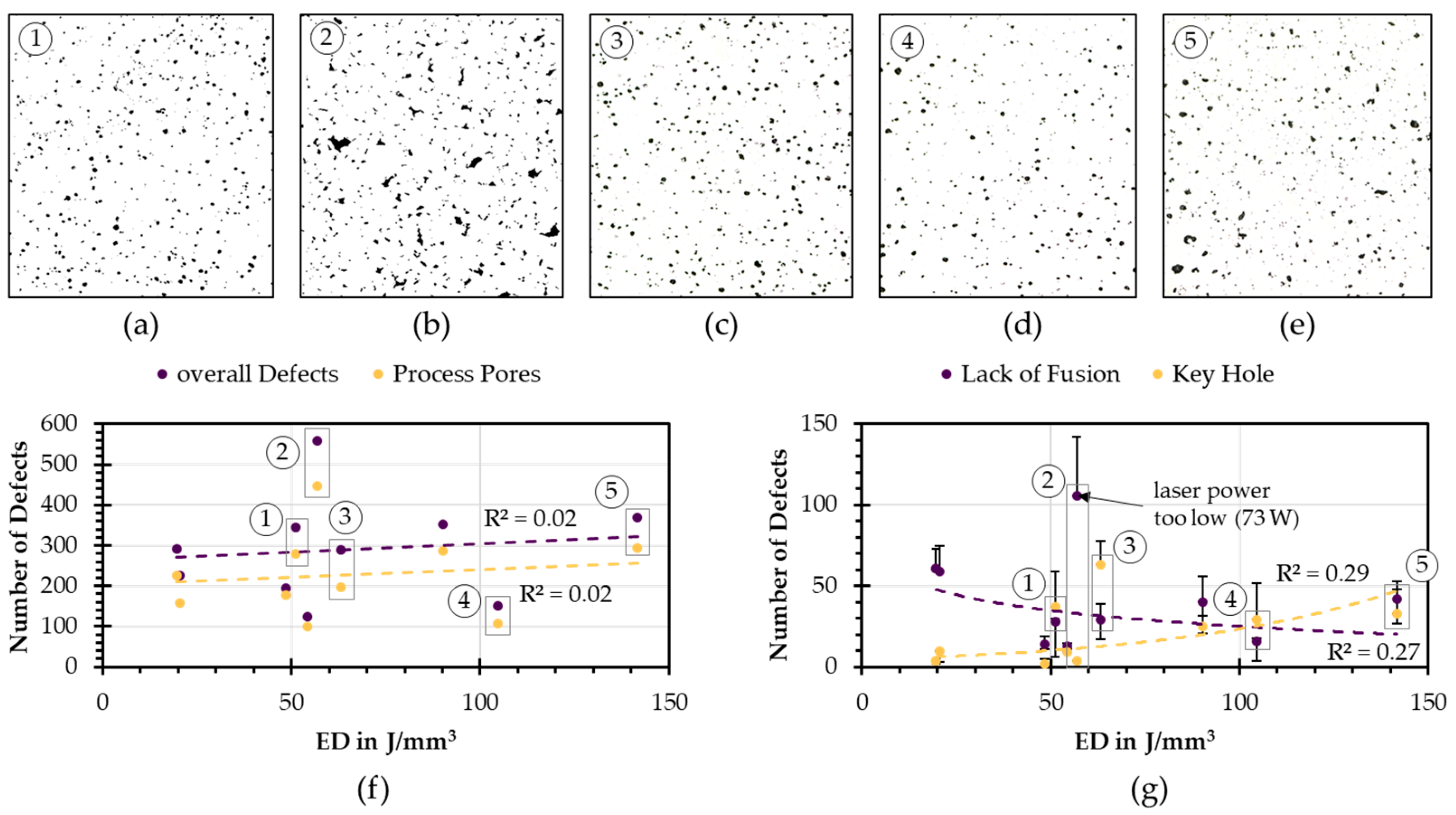
3.1. Unsupervised Defect Classification with Cluster Algorithms on Binary Images
3.2. Supervised Defect Classification with Random Forest Trees on Binary Images
3.3. Defect Classification with Random Forest Trees on Local Features
3.4. Comparison of the Models
3.5. Model Application on Unlabeled PBF-LB/M Fabricated Ti6Al4V Micrographs
4. Conclusions
- Unsupervised models like the kMeans and DBSCAN algorithm failed in classifying process pores, keyholes, and lacks of fusion defects. However, a supervised random forest tree classifier showed high accuracies, around 96%, for the classification. The staff-labeled data were needed, so the models could distinguish especially between the lacks of fusion and keyhole defects.
- The supervised classification models performed better on binary image data of defects than on locally extracted features describing their morphologies. More local features are needed to achieve better classification results.
- Depending on the process parameters used in additive manufacturing, keyhole defects could become more irregular and unshaped even at relatively low energy densities. This resulted in major classification errors between lacks of fusion and keyhole defects. Considering the influences of the defects on mechanical properties, even keyhole defects could possibly significantly reduce the mechanical properties if they were more irregular and unshaped.
5. Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label | Rel. Density | |||||
|---|---|---|---|---|---|---|
| - | mm | W | mm/s | mm | J/mm3 | % |
| 1 | 0.19 | 134 | 283 | 0.05 | 51.2 | 98.12 |
| 2 | 0.12 | 73 | 225 | 0.05 | 56.89 | 96.76 |
| 3 | 0.11 | 188 | 565 | 0.05 | 63.18 | 97.24 |
| 4 | 0.07 | 250 | 690 | 0.05 | 104.60 | 98.36 |
| 5 | 0.12 | 254 | 306 | 0.05 | 141.70 | 97.65 |
| 6 | 0.18 | 317 | 668 | 0.05 | 54.35 | 99.45 |
| 7 | 0.12 | 104 | 367 | 0.05 | 48.43 | 98.75 |
| 8 | 0.14 | 278 | 452 | 0.05 | 90.24 | 97.92 |
| 9 | 0.20 | 195 | 958 | 0.05 | 20.55 | 96.30 |
| 10 | 0.19 | 319 | 1693 | 0.05 | 19.65 | 97.45 |
References
- Khorasani, A.; Gibson, I.; Veetil, J.K.; Ghasemi, A.H. A review of technological improvements in laser-based powder bed fusion of metal printers. Int. J. Adv. Manuf. Technol. 2020, 108, 191–209. [Google Scholar] [CrossRef]
- Ngo, T.D.; Kashani, A.; Imbalzano, G.; Nguyen, K.T.Q.; Hui, D. Additive Manufacturing (3D Printing): A Review of Materials, Methods, Applications and Challenges. Compos. Part B Eng. 2018, 143, 172–196. [Google Scholar] [CrossRef]
- Kruth, J.-P.; Van der Schueren, B.; Bonse, J.; Morren, B. Basic Powder Metallurgical Aspects in Selective Metal Powder Sintering. CIRP Ann. 1996, 45, 183–186. [Google Scholar] [CrossRef]
- Kruth, J.-P.; Mercelis, P.; Van Vaerenbergh, J.; Froyen, L.; Rombouts, M. Binding mechanisms in selective laser sintering and selective laser melting. Rapid Prototyp. J. 2005, 11, 26–36. [Google Scholar] [CrossRef]
- Bozic, D.; Cvijovic, I.; Vilotijevic, M.; Jovanovic, M. The influence of microstructural characteristics on the mechanical properties of Ti6Al4V alloy produced by the powder metallurgy technique. J. Serbian Chem. Soc. 2006, 71, 985–992. [Google Scholar] [CrossRef]
- Gong, H.; Rafi, K.; Gu, H.; Ram, G.D.J.; Starr, T.; Stucker, B. Influence of defects on mechanical properties of Ti–6Al–4V components produced by selective laser melting and electron beam melting. Mater. Des. 2015, 86, 545–554. [Google Scholar] [CrossRef]
- Zhang, B.; Li, Y.; Bai, Q. Defect Formation Mechanisms in Selective Laser Melting: A Review. Chin. J. Mech. Eng. 2017, 30, 515–527. [Google Scholar] [CrossRef]
- Keshavarzkermani, A.; Marzbanrad, E.; Esmaeilizadeh, R.; Mahmoodkhani, Y.; Ali, U.; Enrique, P.D.; Zhou, N.Y.; Bonakdar, A.; Toyserkani, E. An investigation into the effect of process parameters on melt pool geometry, cell spacing, and grain refinement during laser powder bed fusion. Opt. Laser Technol. 2019, 116, 83–91. [Google Scholar] [CrossRef]
- Han, J.; Yang, J.; Yu, H.; Yin, J.; Gao, M.; Wang, Z.; Zeng, X. Microstructure and mechanical property of selective laser melted Ti6Al4V dependence on laser energy density. Rapid Prototyp. J. 2017, 23, 217–226. [Google Scholar] [CrossRef]
- Cepeda-Jiménez, C.; Potenza, F.; Magalini, E.; Luchin, V.; Molinari, A.; Pérez-Prado, M. Effect of energy density on the microstructure and texture evolution of Ti-6Al-4V manufactured by laser powder bed fusion. Mater. Charact. 2020, 163, 110238. [Google Scholar] [CrossRef]
- Bertoli, U.S.; Wolfer, A.J.; Matthews, M.J.; Delplanque, J.-P.R.; Schoenung, J.M. On the limitations of Volumetric Energy Density as a design parameter for Selective Laser Melting. Mater. Des. 2017, 113, 331–340. [Google Scholar] [CrossRef]
- Kruth, J.P.; Froyen, L.; Van Vaerenbergh, J.; Mercelis, P.; Rombouts, M.; Lauwers, B. Selective Laser Melting of iron-based powder. Mater. Process. Technol. 2004, 149, 616–622. [Google Scholar] [CrossRef]
- Wang, W.; Ning, J.; Liang, S.Y. Prediction of lack-of-fusion porosity in laser powder-bed fusion considering boundary conditions and sensitivity to laser power absorption. Int. J. Adv. Manuf. Technol. 2021, 112, 61–70. [Google Scholar] [CrossRef]
- Shrestha, S.; Starr, T.; Chou, K. A Study of Keyhole Porosity in Selective Laser Melting: Single-Track Scanning with Mi-cro-CT Analysis. J. Manuf. Sci. Eng. 2019, 141, 071004. [Google Scholar] [CrossRef]
- Möbus, M.; Woizeschke, P. Keyhole-in-keyhole formation by adding a coaxially superimposed single-mode laser beam in disk laser deep penetration welding. Weld. World 2023, 67, 1467–1478. [Google Scholar] [CrossRef]
- King, W.E.; Barth, H.D.; Castillo, V.M.; Gallegos, G.F.; Gibbs, J.W.; Hahn, D.E.; Kamath, C.; Rubenchik, A.M. Obervation of keyhole-mode laser melting in laser powder-bed fusion additive manufacturing. J. Mater. Process. Technol. 2014, 214, 2915. [Google Scholar] [CrossRef]
- Wang, T.; Dai, S.; Liao, H.; Zhu, H. Pores and the formation mechanisms of SLMed AlSi10Mg. Rapid Prototyp. J. 2020, 26, 1657–1664. [Google Scholar] [CrossRef]
- Martin, A.A.; Calta, N.P.; Khairallah, S.A.; Wang, J.; Depond, P.J.; Fong, A.Y.; Thampy, V.; Guss, G.M.; Kiss, A.M.; Stone, K.H.; et al. Dynamics of pore formation during laser powder bed fusion additive manufacturing. Nat. Commun. 2019, 10, 1987. [Google Scholar] [CrossRef]
- Cao, M.; Liu, Y.; Dunne, F.P. A crystal plasticity approach to understand fatigue response with respect to pores in additive manufactured aluminium alloys. Int. J. Fatigue 2022, 161, 106917. [Google Scholar] [CrossRef]
- Ellendt, N.; Fabricius, F.; Toenjes, A. PoreAnalyzer-An Open-Source Framework for the Analysis and Classification of Defects in Additive Manufacturing. Appl. Sci. 2021, 11, 6086. [Google Scholar] [CrossRef]
- El-Sonbaty, Y.; Ismail, M.A.; Farouk, M. An efficient density based clustering algorithm for large databases. ICTAI 2004, 16, 1082. [Google Scholar]
- Rehman, S.U.; Asghar, S.; Fong, S.; Sarasvady, S. DBSCAN: Past, present and future. ICADIWT 2014, 5, 232. [Google Scholar]
- Mohri, M.; Rostamizadeh, A.; Talwalkar, A. Foundations of Machine Learning; The MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Bishop, C.M. Neural Networks for Pattern Recognition; Oxford Univ. Press: Oxford, UK, 1999. [Google Scholar]
- Feng, S.; Chen, Z.; Bircher, B.; Ji, Z.; Nyborg, L.; Bigot, S. Predicting laser powder bed fusion defects through in-process mon-itoring data and machine learning. Mater. Des. 2022, 222, 111115. [Google Scholar] [CrossRef]
- Baumgartl, H.; Tomas, J.; Buettner, R.; Merkel, M. A deep learning-based model for defect detection in laser-powder bed fusion using in-situ thermographic monitoring. Prog. Addit. Manuf. 2020, 5, 277–285. [Google Scholar] [CrossRef]
- Estalaki, S.M.; Lough, C.S.; Landers, R.G.; Kinzel, E.C.; Luo, T. Predicting Defects in Laser Powder Bed Fusion using in-situ Thermal Imaging Data and Machine Learning. Addit. Manuf. 2022, 58, 103008. [Google Scholar] [CrossRef]
- Du, Y.; Mukherjee, T.; DebRoy, T. Physics-informed machine learning and mechanistic modeling of additive manufacturing to reduce defects. Appl. Mater. Today 2021, 24, 101123. [Google Scholar] [CrossRef]
- Meluhn, L.A.; Mueller, S.; Altmann, M.L.; Benthien, T.; Toenjes, A. PBF-LB/M Ti6Al4V Micrographs and Labeled Manufacturing Defects, Zenodo. 2023. Available online: https://doi.org/10.5281/zenodo.8303011 (accessed on 8 September 2023).
- Bradski, G. The openCV library. Dr. Dobb’s J. 2000, 120, 122–125. [Google Scholar]
- Zdilla, M.J.; Hatfield, S.A.; McLean, K.A.; Cyrus, L.M.; Laslo, J.M.; Lambert, H.W. Circularity, Solidity, Axes of Best Fit Ellipse, Aspect Ratio, and Roundness of the Foramen Ovale: A Morphometric Analysis with Neurosurgical Considerations. J. Craniofac. Surg. 2016, 27, 222. [Google Scholar] [CrossRef]
- Lai, W.; Zhou, M.; Hu, F.; Bian, K.; Song, Q. A New DBSCAN Parameters Determination Method Based on Improved MVO. IEEE Access 2019, 7, 104085–104095. [Google Scholar] [CrossRef]
- Ahmed, M.; Seraj, R.; Islam, S.M.S. The k-means Algorithm: A Comprehensive Survey and Performance Evaluation. Electronics 2020, 9, 1295. [Google Scholar] [CrossRef]
- Wu, X.; Kumar, V.; Quinlan, J.R.; Ghosh, J.; Yang, Q.; Motoda, H.; McLachlan, G.J.; Ng, A.; Liu, B.; Yu, P.S.; et al. Top 10 algorithms in data mining. Knowl. Inf. Syst. 2008, 14, 1–37. [Google Scholar] [CrossRef]
- Halkidi, M.; Batistakis, Y.; Vazirgiannis, M. On Clustering Validation Techniques. J. Intell. Inf. Syst. 2001, 17, 107. [Google Scholar] [CrossRef]
- Sinaga, K.P.; Yang, M.-S. Unsupervised K-Means Clustering Algorithm. IEEE Access 2020, 8, 80716–80727. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In KDD-96; University of Munich: Munich, Germany, 1996. [Google Scholar]
- Hou, J.; Gao, H.; Li, X. DSets-DBSCAN: A Parameter-Free Clustering Algorithm. IEEE Trans. Image Process. 2016, 25, 3182–3193. [Google Scholar] [CrossRef] [PubMed]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825. [Google Scholar]
- Oshiro, T.M.; Perez, P.S.; Baranauskas, J.A. How Many Trees in a Random Forest? In Machine Learning and Data Mining in Pattern Recognition: 8th International Conference, MLDM 2012, Berlin, Germany, 13–20 July 2012. Proceedings 8; Springer: Berlin/Heidelberg, Germany, 2012; p. 154. [Google Scholar]
- Sirikulviriya, N.; Sinthupinyo, S. Integration of Rules from a Random Forest; IPCSIT: Singapore, 2011; Volume 6. [Google Scholar]
- Bicego, M. K-Random Forests: A K-means style algorithm for Random Forest clustering. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]











| Laser Power PL in W | Layer Thickness DL in µm | Scan Speed vS in mm/s | Hatch Distance dH in mm | |
|---|---|---|---|---|
| Min | 51 | 0.025 | 201 | 0.05 |
| Max | 350 | 0.1 | 1700 | 0.2 |
| Count | 290 | 4 | 628 | 794 |
| Model | Accuracy in % | |||
|---|---|---|---|---|
| Overall | Process Pores | Lack of Fusion | Key Hole | |
| kMeans | 60 | 100 | 57.75 | 22.5 |
| RFT images | 95.28 | 100 | 90.08 | 95.93 |
| RFT local features | 55.28 | 49.18 | 62.28 | 54.84 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Altmann, M.L.; Benthien, T.; Ellendt, N.; Toenjes, A. Defect Classification for Additive Manufacturing with Machine Learning. Materials 2023, 16, 6242. https://doi.org/10.3390/ma16186242
Altmann ML, Benthien T, Ellendt N, Toenjes A. Defect Classification for Additive Manufacturing with Machine Learning. Materials. 2023; 16(18):6242. https://doi.org/10.3390/ma16186242
Chicago/Turabian StyleAltmann, Mika León, Thiemo Benthien, Nils Ellendt, and Anastasiya Toenjes. 2023. "Defect Classification for Additive Manufacturing with Machine Learning" Materials 16, no. 18: 6242. https://doi.org/10.3390/ma16186242