Biogeography-Based Optimization of the Portfolio Optimization Problem with Second Order Stochastic Dominance Constraints

Abstract
:1. Introduction
2. The Model of Second Order Stochastic Dominance
2.1. The Expected Utility Theory and Mean-Variance Model
2.2. The Stochastic Dominance Theory
2.3. The Second Order Stochastic Dominance Model
2.4. Portfolio Optimization Model
3. The BBO Algorithm for SSD Model
3.1. The Fitness Function for SSD Model
3.2. Migration Operator for SSD Model
3.3. Mutation Operator for SSD Model
3.4. Adaptive BBO for SSD Model
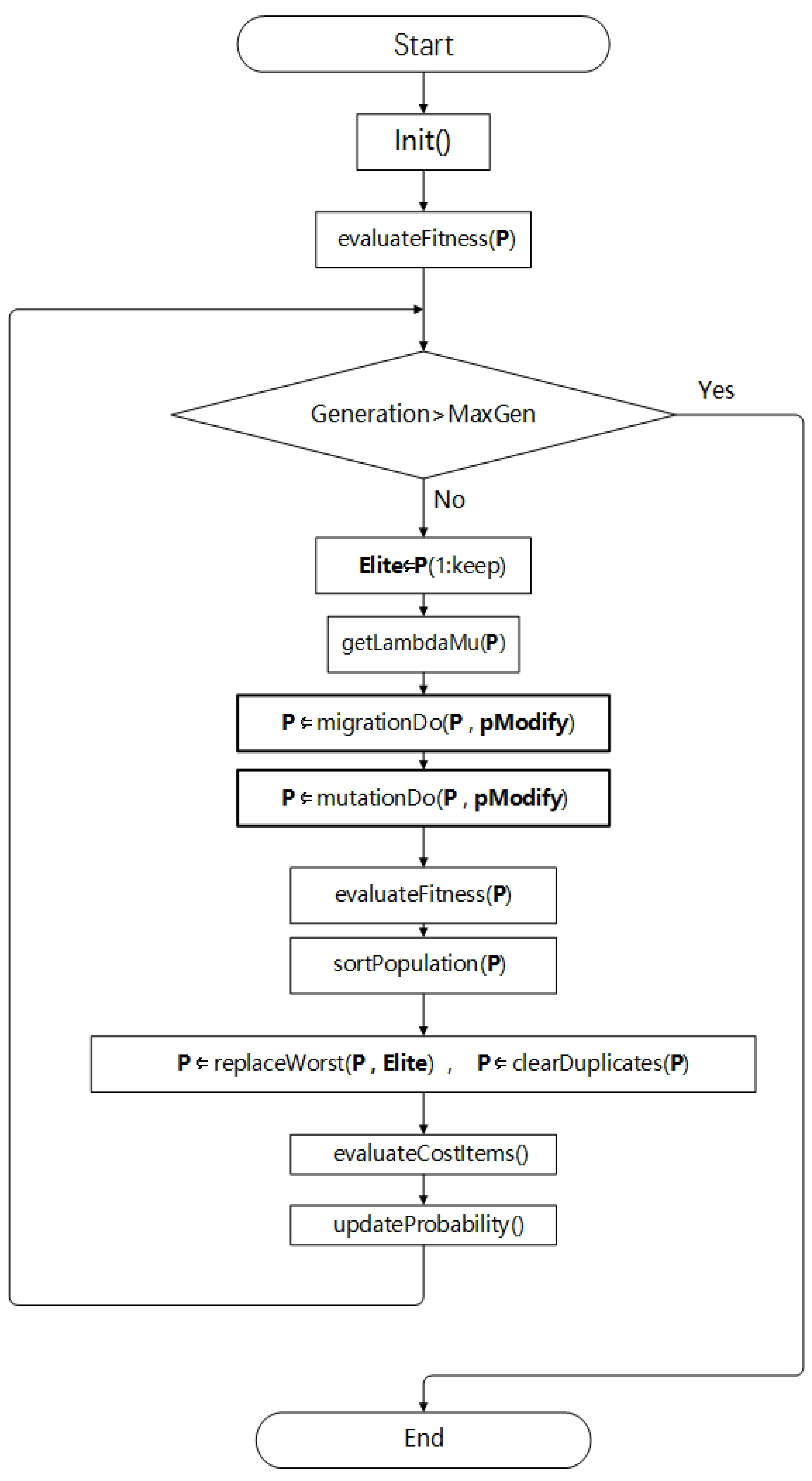
3.5. Main Procedure of BBO for SSD Model
| Algorithm 1 the main procedure of BBO for the SSD. |
|
| Algorithm 2 the main algorithm of sortPopulation (Population P). |
|
4. Numerical Experiments
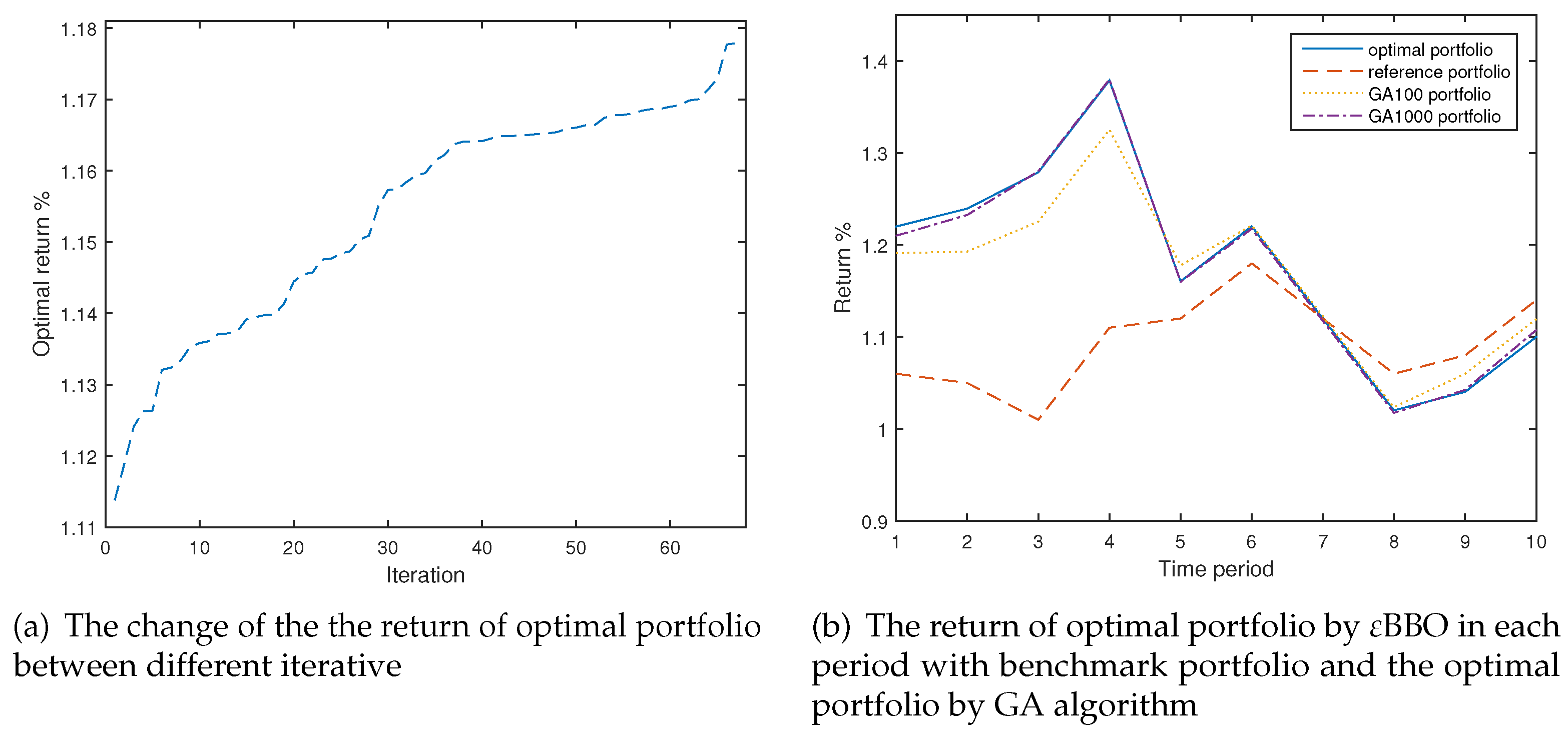
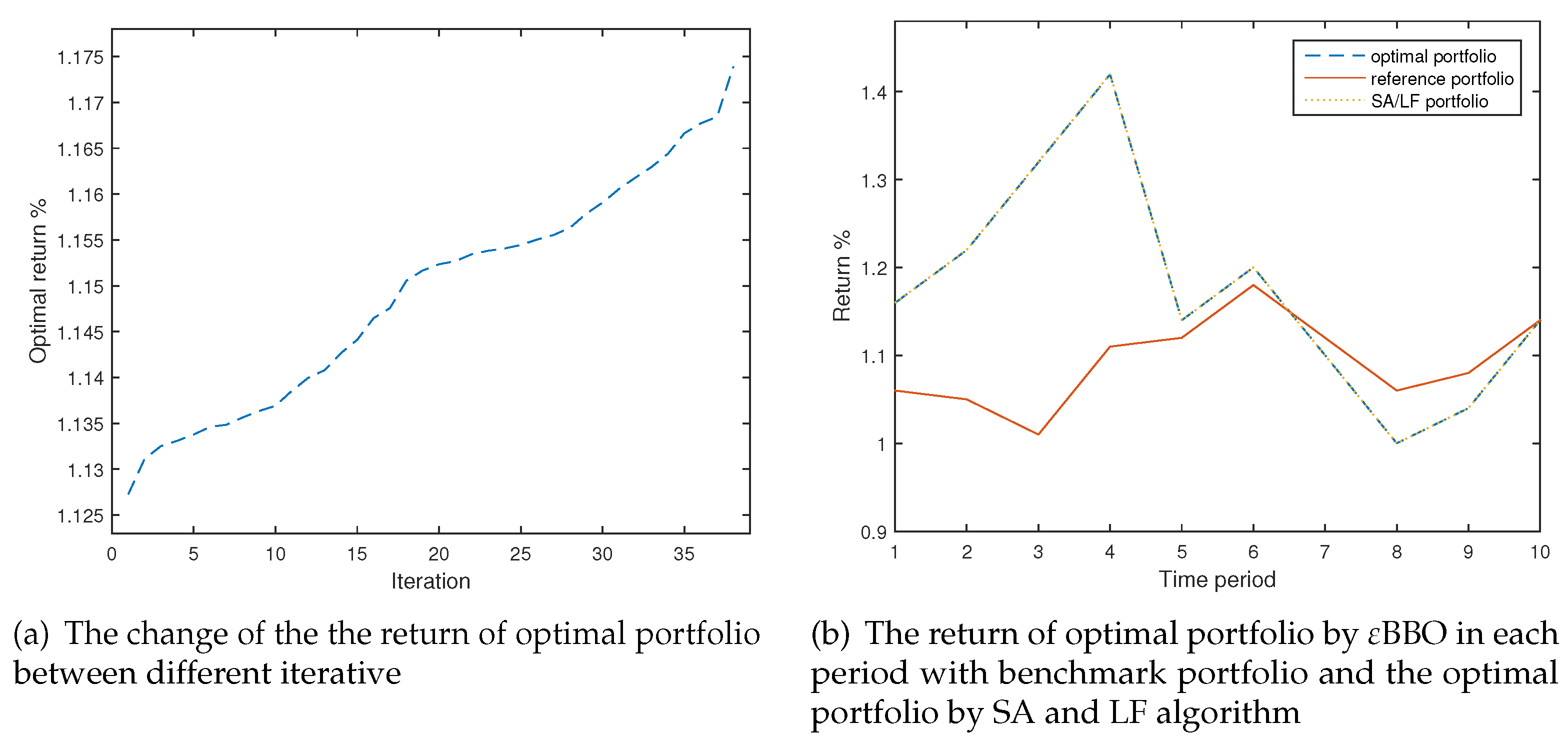
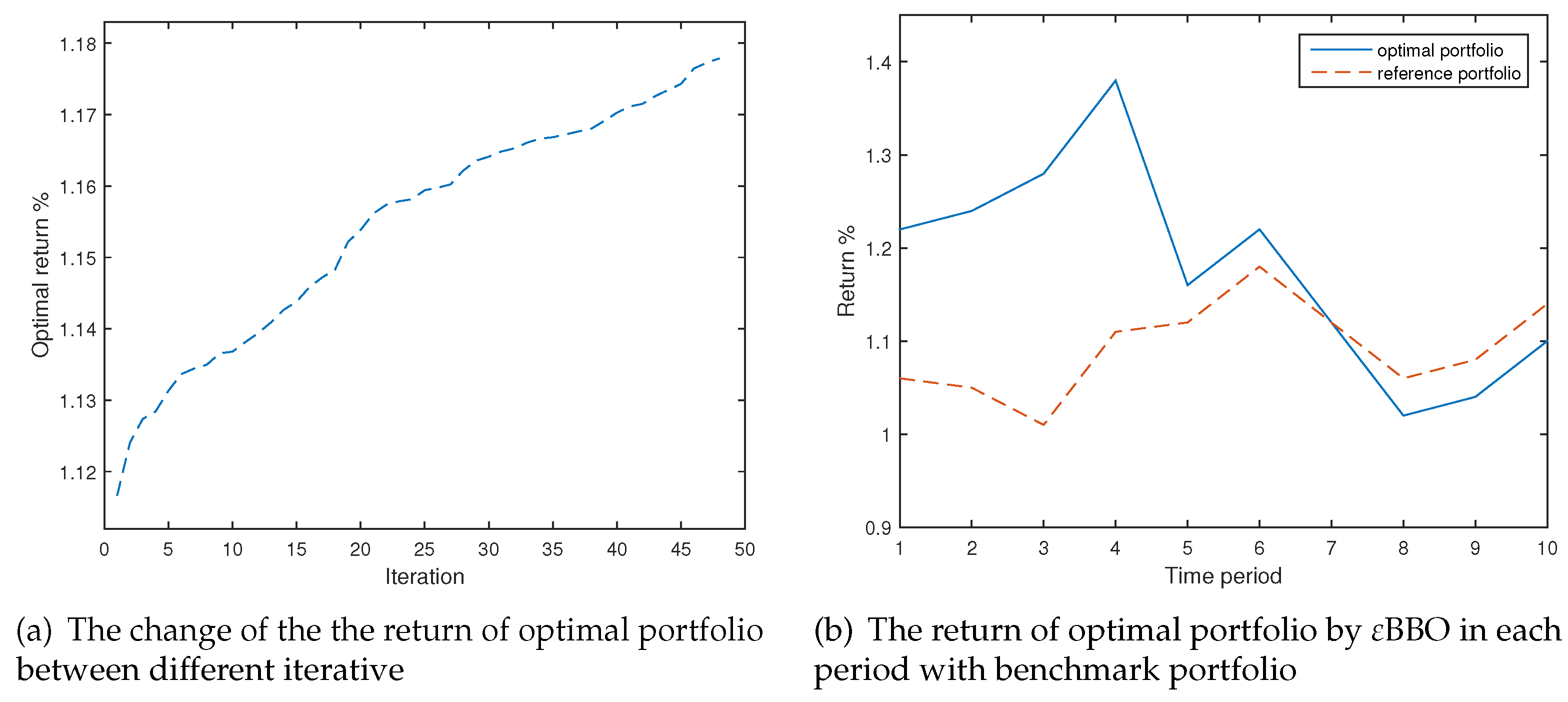
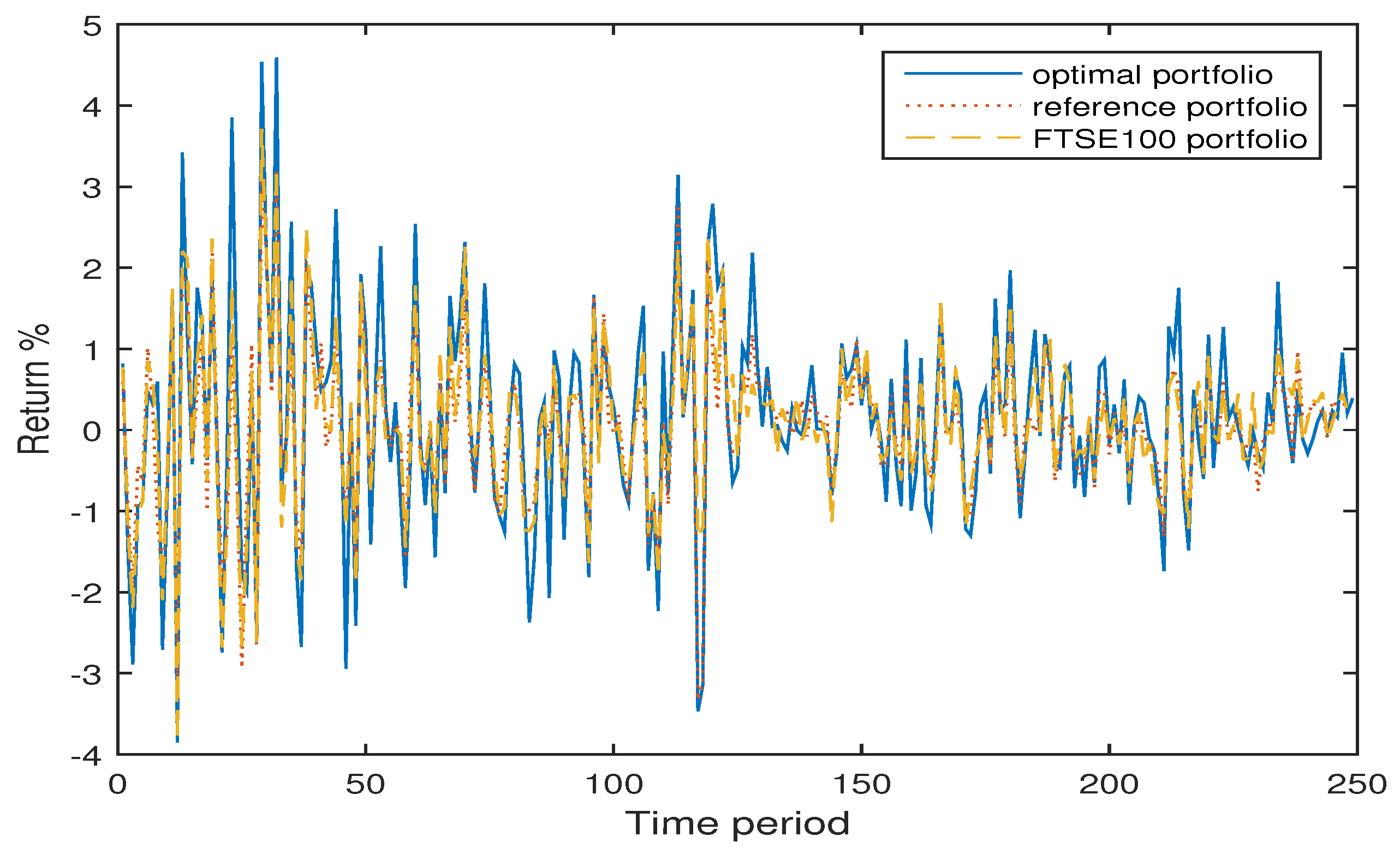
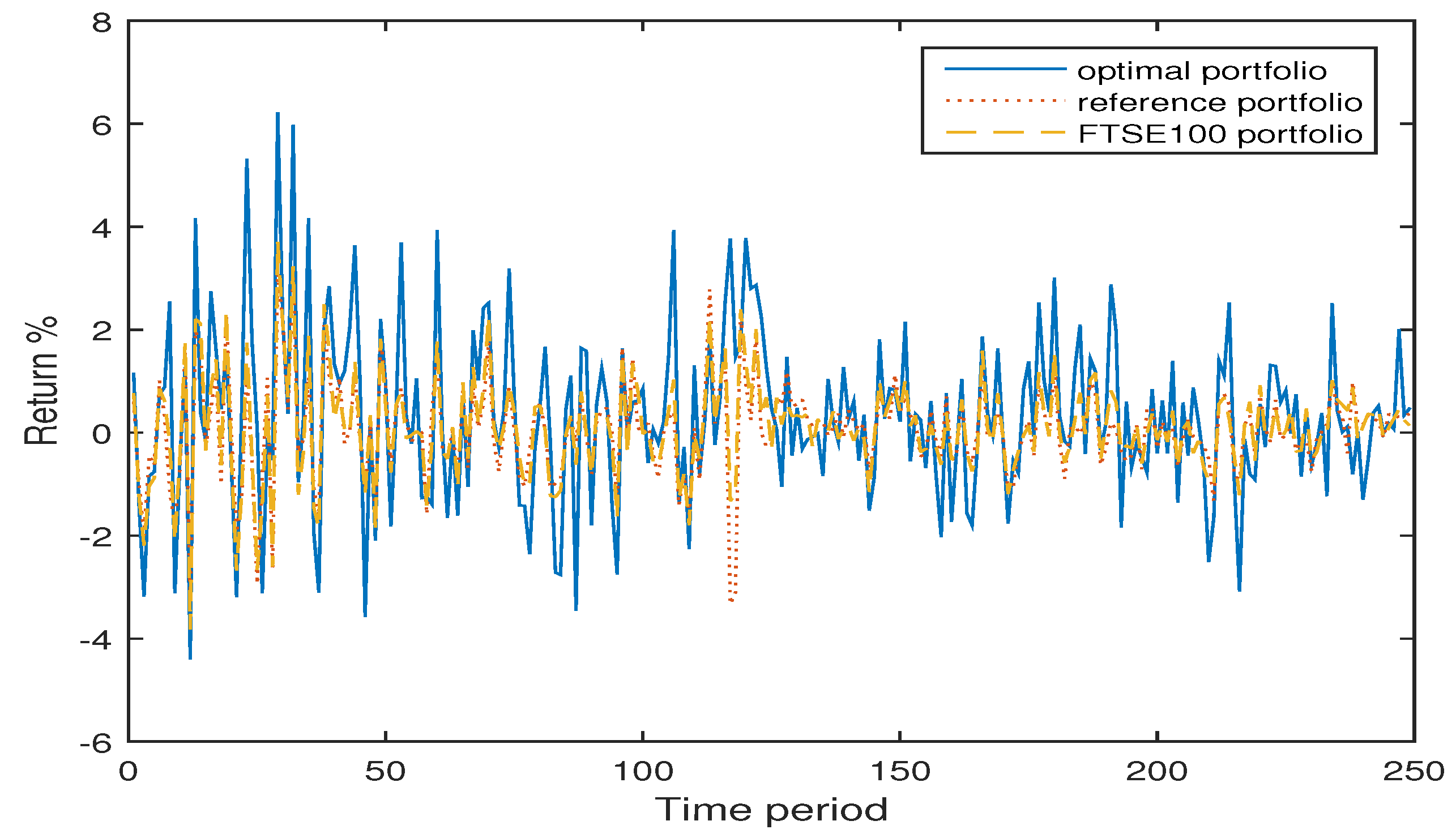
4.1. Example 1
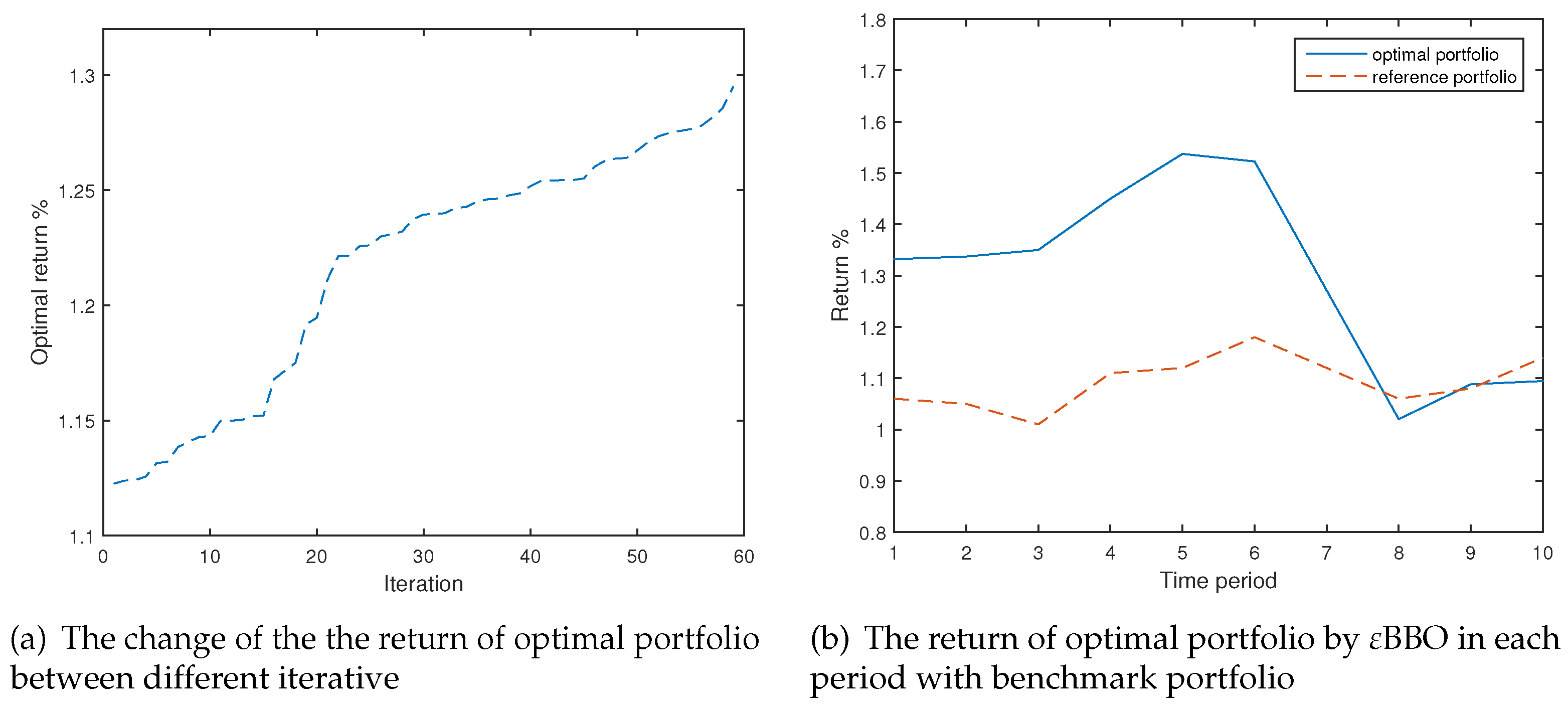
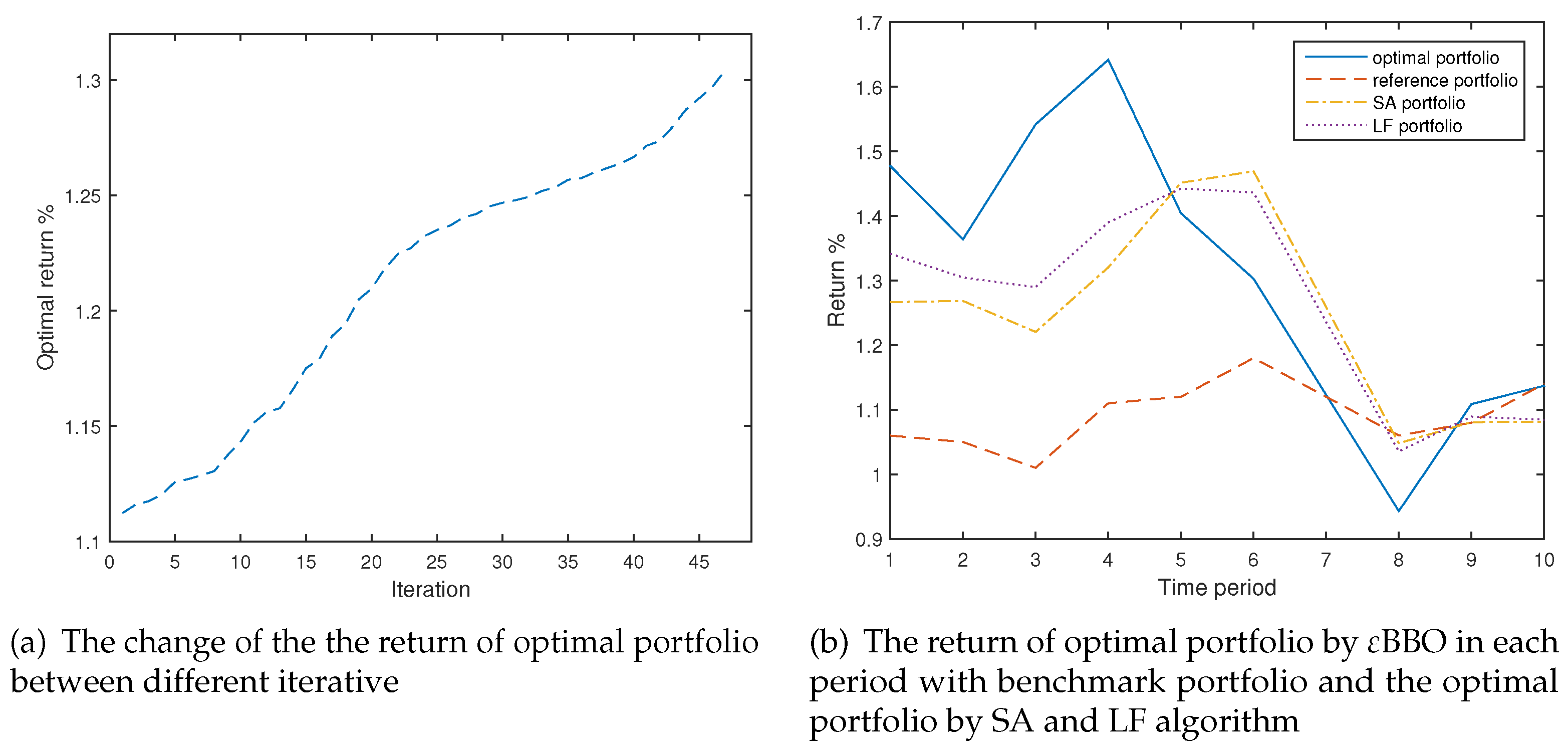
4.2. Example 2
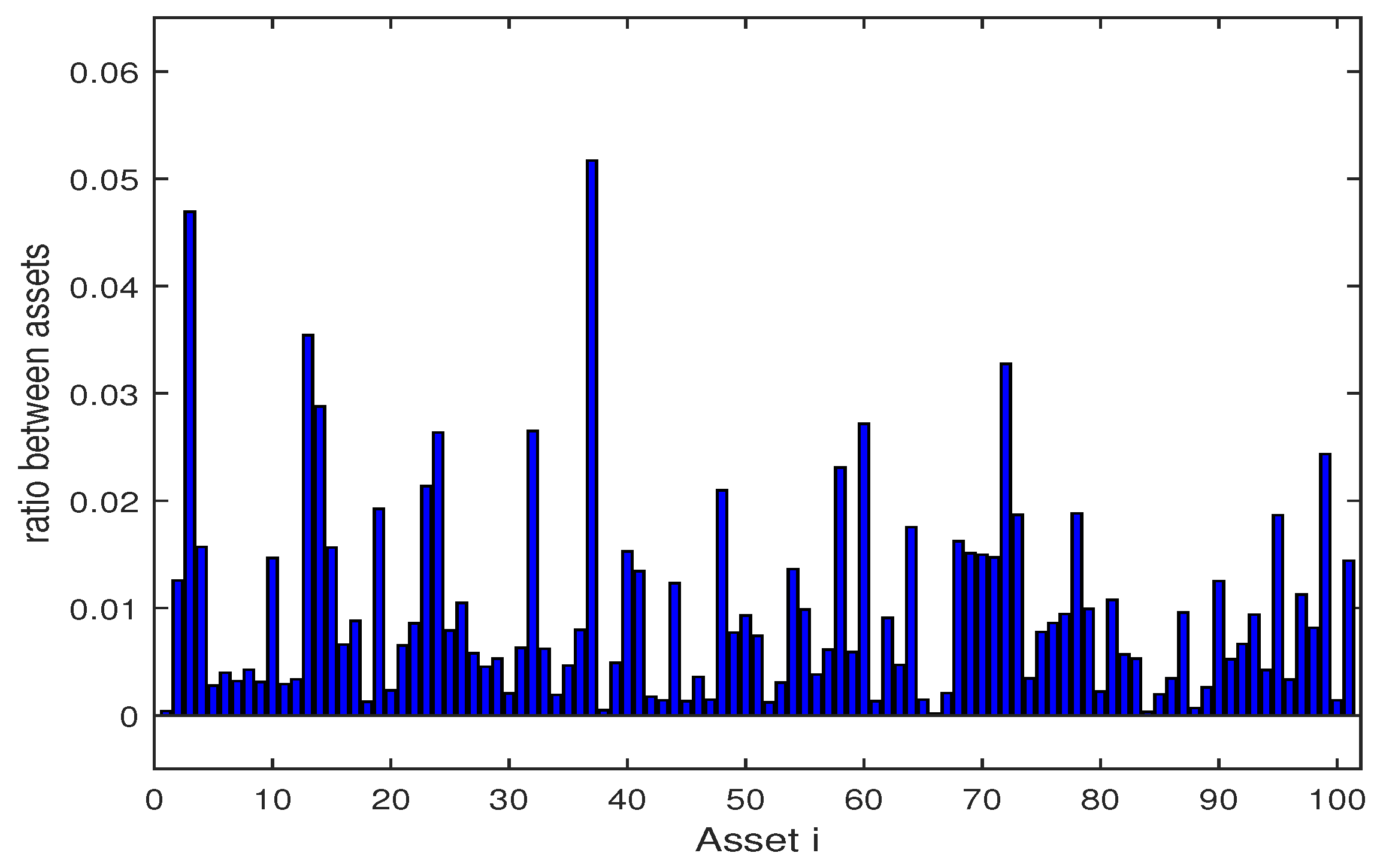
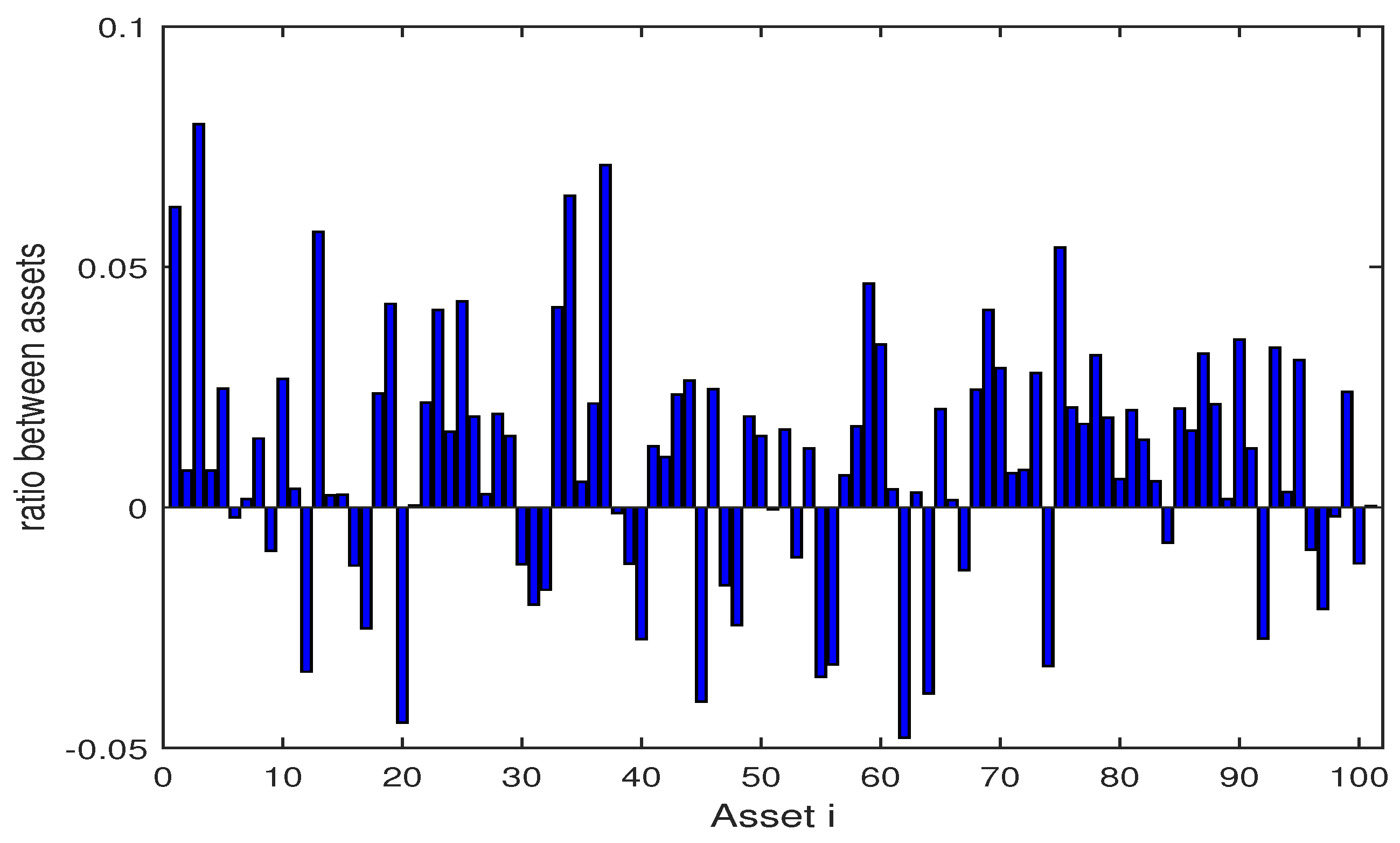
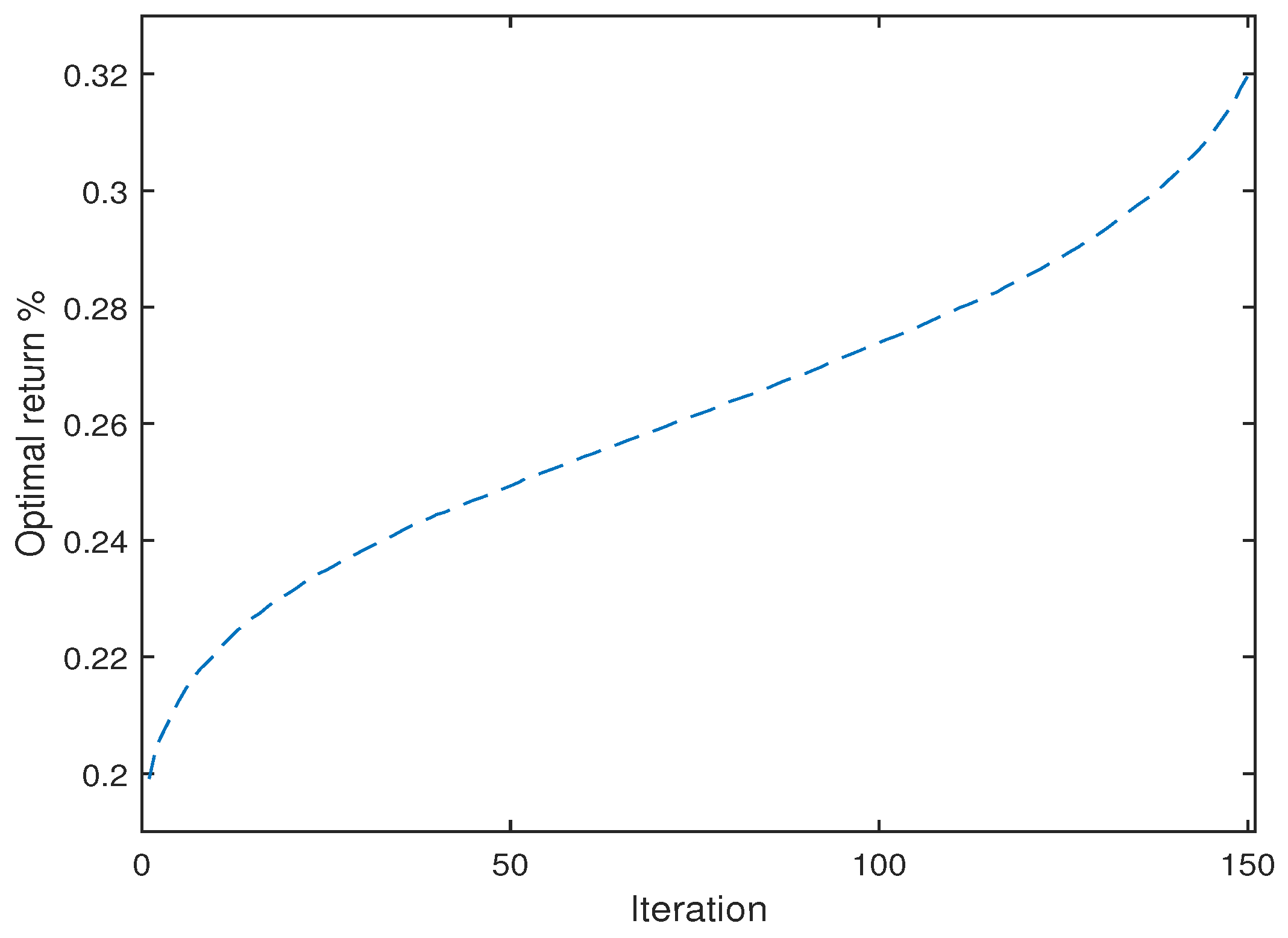
4.3. Numerical Analysis
5. Conclusions and Future Research
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| SSD | Second Order Stochastic Dominance |
| BBO | Biogeography-based Optimization |
| DE | Differential Evolution |
| HSI | Habitat Suitability Index |
| SIV | Suitability Index Variable |
| GA | Genetic Algorithm |
| SA | Stochastic Approximation |
| LF | Level Function |
| CVaR | conditional value at risk |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Constitution | Index Weight (%) | Constitution | Index Weight (%) |
|---|---|---|---|
| 3i Group | 0.38 | Admiral Group | 0.2 |
| Anglo American | 0.84 | Antofagasta | 0.13 |
| Ashtead Group | 0.44 | Associated British Foods | 0.53 |
| AstraZeneca | 3.1 | Aviva | 1.09 |
| Babcock International Group | 0.27 | BAE Systems | 1.04 |
| Barclays | 2.09 | Barratt Developments | 0.26 |
| BHP Billition | 1.53 | BP | 5.3 |
| British American Tobacco | 4.77 | British Land Co | 0.36 |
| BT Group | 1.7 | Bunzl | 0.39 |
| Burberry Group | 0.37 | Capita | 0.19 |
| Carnival | 0.42 | Centrica | 0.7 |
| Coca-Cola HBC AG | 0.19 | Compass Group | 1.37 |
| ConvaTec Group | 0.08 | CRH | 1.3 |
| Croda International | 0.23 | DCC | 0.3 |
| Diageo | 2.94 | Direct Line Insurance Group | 0.28 |
| Dixons Carphone | 0.2 | Easyjet | 0.14 |
| Experian | 0.84 | Fresnillo | 0.11 |
| GKN | 0.31 | GlaxoSmithKline | 4.21 |
| Glencore | 1.79 | Hammerson | 0.25 |
| Hargreaves Lansdown | 0.16 | Hikma Pharmaceuticals | 0.15 |
| HSBC HIdgs | 7.3 | Imperial Brands | 1.89 |
| Informa | 0.31 | InterContinental Hotels Group | 0.4 |
| International Consolidated Airlines Group | 0.41 | Intertek Group | 0.31 |
| Intu Properties | 0.14 | ITV | 0.43 |
| Johnson Matthey | 0.34 | Kingfisher | 0.44 |
| Land Securities Group | 0.46 | Legal & General Group | 0.81 |
| LIoyds Banking Group | 2.22 | London Stock Exchange Group | 0.51 |
| Marks & Spencer Group | 0.31 | Mediclinic International pIc | 0.17 |
| Merlin Entertainments | 0.18 | Micro Focus International | 0.27 |
| Mondi | 0.34 | Morrison (Wm) Supermarkets | 0.28 |
| National Grid | 1.99 | Next | 0.39 |
| Old Mutual | 0.56 | Paddy Power Betfair | 0.4 |
| Pearson | 0.37 | Persimmon | 0.3 |
| Provident Financial | 0.23 | Prudential | 2.33 |
| Randgold Resources | 0.33 | Reckitt Benckiser Group | 2.4 |
| RELX | 0.88 | Rio Tinto | 2.12 |
| Rolls-Royce Holdings | 0.61 | Royal Bank Of Scotland Group | 0.41 |
| Royal Dutch Shell A | 5.43 | Royal Dutch Shell B | 4.89 |
| Royal Mail | 0.23 | RSA Insurance Group | 0.33 |
| Sage Group | 0.39 | Sainsbury(J) | 0.23 |
| Schroders | 0.19 | Severn Trent | 0.29 |
| Shire | 2.34 | Sky | 0.58 |
| Smith & Nephew | 0.6 | Smiths Group | 0.31 |
| Smurfit Kappa Group | 0.24 | SSE | 0.87 |
| St. James’s Place | 0.29 | Standard Chartered | 0.99 |
| Standard Life | 0.41 | Taylor Wimpey | 0.28 |
| Tesco | 0.93 | TUI AG | 0.3 |
| Unilever | 2.2 | United Utilities Group | 0.34 |
| Vodafone Group | 2.94 | Whitbread | 0.38 |
| Wolseley | 0.69 | Worldpay Group | 0.25 |
| WPP | 1.29 |
References
- Markowitz, H.M. Portfolio Selection. J. Financ. 1952, 7, 77–91. [Google Scholar]
- Fishburn, P.C. Mean-Risk Analysis with Risk Associated with Below-Target Returns. Am. Econ. Rev. 1975, 67, 116–126. [Google Scholar]
- Dentcheva, D.; Ruszczyński, A. Optimization with stochastic dominance constraints. SIAM J. Optim. 2003, 14, 548–566. [Google Scholar] [CrossRef]
- Dentcheva, D.; Ruszczyński, A. Portfolio optimization with stochastic dominance constraints. J. Bank. Financ. 2006, 30, 433–451. [Google Scholar] [CrossRef]
- Rudolf, G.; Ruszczyński, A. Optimization Problems with Second Order Stochastic Dominance Constraints: Duality, Compact Formulations, and Cut Generation Methods. SIAM J. Optim. 2008, 19, 1326–1343. [Google Scholar] [CrossRef]
- Homem-De-Mello, T.; Mehrotra, S. A Cutting-Surface Method for Uncertain Linear Programs with Polyhedral Stochastic Dominance Constraints. SIAM J. Optim. 2014, 20, 1250–1273. [Google Scholar] [CrossRef]
- Fábián, C.I.; Mitra, G.; Roman, D. Processing second-order stochastic dominance models using cutting-plane representations. Math. Program. 2011, 130, 33–57. [Google Scholar] [CrossRef]
- Dentcheva, D.; Ruszczyński, A. Inverse cutting plane methods for optimization problems with second-order stochastic dominance constraints. Optimization 2010, 59, 323–338. [Google Scholar] [CrossRef]
- Meskarian, R.; Xu, H.; Fliege, J. Numerical methods for stochastic programs with second order dominance constraints with applications to portfolio optimization. Eur. J. Oper. Res. 2012, 216, 376–385. [Google Scholar] [CrossRef]
- Hu, J. Sample average approximation of stochastic dominance constrained programs. Math. Program. 2012, 133, 171–201. [Google Scholar] [CrossRef]
- Roman, D.; Mitra, G.; Zverovich, V. Enhanced indexation based on second-order stochastic dominance. Eur. J. Oper. Res. 2013, 228, 273–281. [Google Scholar] [CrossRef]
- Wallace, A.R. The Geographical Distribution of Animals: With a Study of the Relations of Living and Extinct Faunas as Elucidating the Past Changes of the Earth’s Surface; Cambridge University Press: New York, NY, USA, 2011. [Google Scholar]
- Dan, S. Biogeography-based optimization. IEEE Trans. Evolut. Comput. 2008, 12, 702–713. [Google Scholar]
- Wang, S.; Li, P.; Chen, P.; Phillips, P.; Liu, G.; Du, S.; Zhang, Y. Pathological Brain Detection via Wavelet Packet Tsallis Entropy and Real-Coded Biogeography-Based Optimization. Fundament. Inf. 2017, 151, 275–291. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, X.; Lu, S.; Wang, H.; Phillips, P.; Wang, S. Smart detection on abnormal breasts in digital mammography based on contrast-limited adaptive histogram equalization and chaotic adaptive real-coded biogeography-based optimization. Simulation 2016, 92, 873–885. [Google Scholar] [CrossRef]
- Ghaffarzadeh, N.; Sadeghi, H. A new efficient BBO based method for simultaneous placement of inverter-based DG units and capacitors considering harmonic limits. Int. J. Electr. Power Energy Syst. 2016, 80, 37–45. [Google Scholar] [CrossRef]
- Yogesh, C.K.; Hariharan, M.; Ngadiran, R.; Adom, A.H.; Yaacob, S.; Berkai., C.; Polat, K. A New Hybrid PSO Assisted Biogeography-Based Optimization for Emotion and Stress Recognition from Speech Signal. Expert Syst. Appl. 2017, 69, 149–158. [Google Scholar]
- Wang, S.; Zhang, Y.; Ji, G.; Yang, J.; Wu, J.; Wei, L. Fruit Classification by Wavelet-Entropy and Feedforward Neural Network Trained by Fitness-Scaled Chaotic ABC and Biogeography-Based Optimization. Entropy 2015, 17, 5711–5728. [Google Scholar] [CrossRef]
- Zhang, Y.; Phillips, P.; Wang, S.; Ji, G.; Yang, J.; Wu, J. Fruit classification by biogeography-based optimization and feedforward neural network. Expert Syst. 2016, 33, 239–253. [Google Scholar] [CrossRef]
- Neumann, J.L.V.; Morgenstern, O.V. The Theory of Games and Economic Behavior; Princeton University Press: Princeton, NJ, USA, 1944. [Google Scholar]
- Laciana, C.E.; Weber, E.U. Correcting expected utility for comparisons between alternative outcomes: A unified parameterization of regret and disappointment. J. Risk Uncertain. 2008, 36, 1–17. [Google Scholar] [CrossRef]
- Ogryczak, W.; Ruszczyński, A. From stochastic dominance to mean-risk models: Semideviations as risk measures. Eur. J. Oper. Res. 1999, 116, 33–50. [Google Scholar] [CrossRef]
- Ma, H.; Simon, D. Blended biogeography-based optimization for constrained optimization. Eng. Appl. Artif. Intell. 2011, 24, 517–525. [Google Scholar] [CrossRef]
- Trivedi, A.; Srinivasan, D.; Biswas, S.; Reindl, T. Hybridizing genetic algorithm with differential evolution for solving the unit commitment scheduling problem. Swarm Evolut. Comput. 2015, 23, 50–64. [Google Scholar] [CrossRef]
- Jiang, W.; Shi, Y.; Zhao, W.; Wang, X. Parameters Identification of Fluxgate Magnetic Core Adopting the Biogeography-Based Optimization Algorithm. Sensors 2016, 16, 979. [Google Scholar] [CrossRef] [PubMed]
- Jain, P.; Bhakar, R.; Singh, S.N. Influence of Bidding Mechanism and Spot Market Characteristics on Market Power of a Large Genco Using Hybrid DE/BBO. J. Energy Eng. 2015, 141, 04014028. [Google Scholar] [CrossRef] [Green Version]
- Feng, S.L.; Yang, Z.Q.; Huang, M.X. Hybridizing Adaptive Biogeography-Based Optimization with Differential Evolution for Multi-Objective Optimization Problems. Information 2017, 8, 83. [Google Scholar] [CrossRef]
- Zhang, H. Solution to constrained optimization problem of second-order stochastic dominance by genetic algorithm. J. Dalian Univ Technol. 2016, 3, 299–303. [Google Scholar]













| Returns % for Period | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| Asset 1 | 1.2 | 1.3 | 1.4 | 1.5 | 1.1 | 1.2 | 1.1 | 1.0 | 1.0 | 1.1 |
| Asset 2 | 1.3 | 1.0 | 0.8 | 0.9 | 1.4 | 1.3 | 1.2 | 1.1 | 1.2 | 1.1 |
| Asset 3 | 0.9 | 1.1 | 1.0 | 1.1 | 1.1 | 1.3 | 1.2 | 1.1 | 1.0 | 1.1 |
| Asset 4 | 1.1 | 1.1 | 1.2 | 1.3 | 1.2 | 1.2 | 1.1 | 1.0 | 1.1 | 1.2 |
| Asset 5 | 0.80 | 0.75 | 0.65 | 0.75 | 0.80 | 0.90 | 1.00 | 1.10 | 1.10 | 1.20 |
| X Constraint | Algorithm | Iteration | Time | x | E[g(x,)] |
|---|---|---|---|---|---|
| BBO | 92 | 0.2833 | (0.595,0.005,0,0.4,0) | 1.1736 | |
| SA | 115 | 5 | (0.325,0.231,0.177,0.266,0) | 1.147 | |
| LF | 5 | 0.6355 | (0.325,0.231,0.177,0.266,0) | 1.148 | |
| BBO | 67 | 0.217 | (0.799,0.201,0,0,0) | 1.1779 | |
| GA(100) | 4 | 0.1322 | (0.576,0.203,0.027,0.188,0.006) | 1.165 | |
| GA(1000) | 3 | 0.6536 | (0.75,0.175,0,0.075,0) | 1.177 | |
| BBO | 59 | 0.25 | (0.097,0.468,0.49,0.701,-0.756) | 1.300 |
| X constraint | Algorithm | Iteration | Time | x | E[g(x,)] |
|---|---|---|---|---|---|
| BBO | 38 | 0.367 | (0.599,0,0.001,0.4,0) | 1.1739 | |
| SA | 226 | 9 | (0.6,0,0,0.4,0) | 1.174 | |
| LF | 4 | 0.577 | (0.6,0,0,0.4,0) | 1.174 | |
| BBO | 48 | 0.65 | (0.799,0.2,0,0.001,0) | 1.1779 | |
| BBO | 47 | 0.5 | (0.8,0.359,-0.529,0.769,-0.399) | 1.3043 | |
| SA | 684 | 16 | (0.127,0.495,0.550,0.380,-0.553) | 1.23 | |
| LF | 4 | 0.649 | (0.39,0.527,0.287,0.3,-0.5) | 1.26 |
| X constraint | Portfolio | Iteration | Time | NO.Assets | E[g(x,)] |
|---|---|---|---|---|---|
| BBO | 92 | 1.6 | 101 | 0.1325 | |
| BBO | 150 | 2.64 | 101 | 0.3197 | |
| / | FTSE100 | / | / | 101 | 0.0937 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, T.; Yang, Z.; Feng, S. Biogeography-Based Optimization of the Portfolio Optimization Problem with Second Order Stochastic Dominance Constraints. Algorithms 2017, 10, 100. https://doi.org/10.3390/a10030100
Ye T, Yang Z, Feng S. Biogeography-Based Optimization of the Portfolio Optimization Problem with Second Order Stochastic Dominance Constraints. Algorithms. 2017; 10(3):100. https://doi.org/10.3390/a10030100
Chicago/Turabian StyleYe, Tao, Ziqiang Yang, and Siling Feng. 2017. "Biogeography-Based Optimization of the Portfolio Optimization Problem with Second Order Stochastic Dominance Constraints" Algorithms 10, no. 3: 100. https://doi.org/10.3390/a10030100
APA StyleYe, T., Yang, Z., & Feng, S. (2017). Biogeography-Based Optimization of the Portfolio Optimization Problem with Second Order Stochastic Dominance Constraints. Algorithms, 10(3), 100. https://doi.org/10.3390/a10030100