




Algorithms 2025, 18(11), 706; https://doi.org/10.3390/a18110706 - 5 Nov 2025
Abstract
►
Show Figures
Integrating recommendation systems with dynamic pricing strategies is essential for enhancing product sales and optimizing revenue in modern business. This study proposes a novel product recommendation model that uses Reinforcement Learning to tailor pricing strategies to customer purchase intentions. While traditional recommendation systems
[...] Read more.
Integrating recommendation systems with dynamic pricing strategies is essential for enhancing product sales and optimizing revenue in modern business. This study proposes a novel product recommendation model that uses Reinforcement Learning to tailor pricing strategies to customer purchase intentions. While traditional recommendation systems focus on identifying products customers prefer, they often neglect the critical factor of pricing. To improve effectiveness and increase conversion, it is crucial to personalize product prices according to the customer’s willingness to pay (WTP). Businesses often use fixed-budget promotions to boost sales, emphasizing the importance of strategic pricing. Designing intelligent promotions requires recommending products aligned with customer preferences and setting prices reflecting their WTP, thus increasing the likelihood of purchase. This research advances existing recommendation systems by integrating dynamic pricing into the system’s output, offering a significant innovation in business practice. However, this integration introduces technical complexities, which are addressed through a Markov Decision Process (MDP) framework and solved using Reinforcement Learning. Empirical evaluation using the Dunnhumby dataset shows promising results. Due to the lack of direct comparisons between combined product recommendation and pricing models, the outputs were simplified into two categories: purchase and non-purchase. This approach revealed significant improvements over comparable methods, demonstrating the model’s efficacy.
Full article
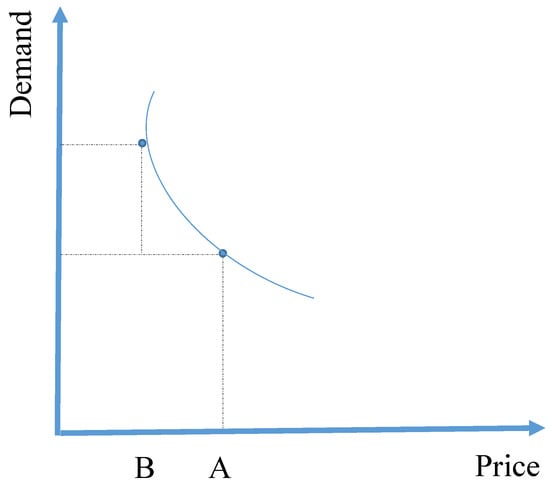
Figure 1
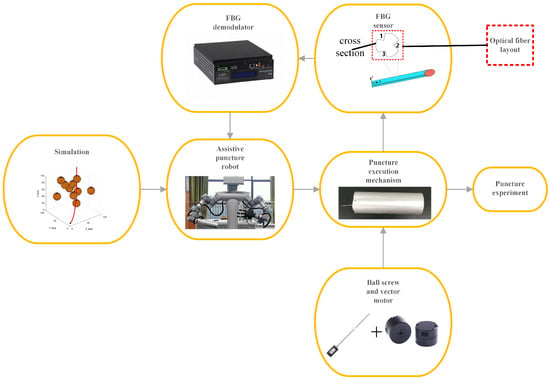
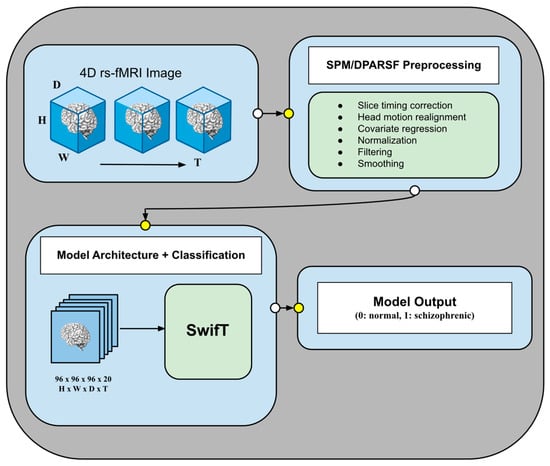
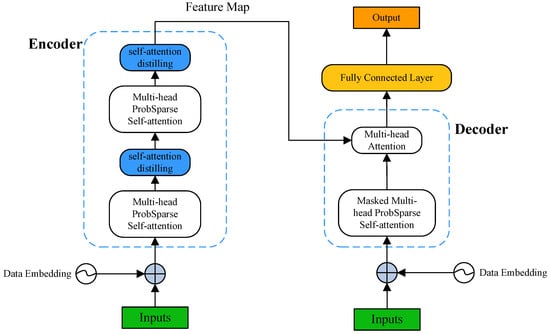


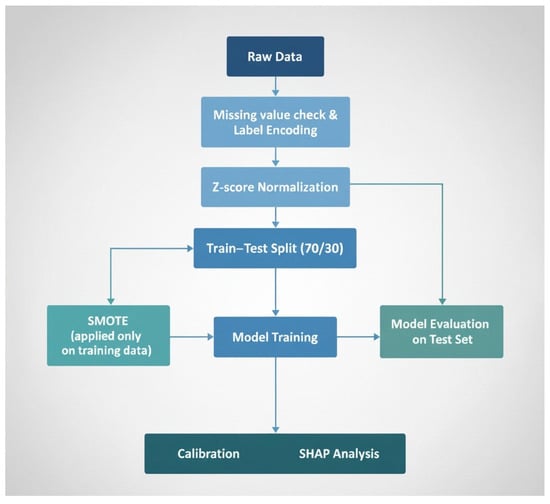












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}