Low-Resource Cross-Domain Product Review Sentiment Classification Based on a CNN with an Auxiliary Large-Scale Corpus


Abstract
:1. Introduction
2. Problem Setting
- Domain: A domain D consists of the following two components: a feature space, , and a marginal probability distribution, P(X). is the space that includes all the term vectors, and X is an individual learning sample. In general, different domains have different feature spaces or different marginal probability distributions.
- Source domain: refers to a set of labeled reviews from a certain domain. is the i-th labeled review, denoting one product review in the source domain. is the sentiment label of , , where the sentiment labels +1 and -1 denote positive and negative sentiments, respectively. is the number of labeled instances in the source domain and denotes the total number of product reviews in the source domain.
- Target domain: refers to a set of unlabeled reviews from a domain different from but related to the source domain. Here, is the i-th unlabeled review corresponding to one product review in the target domain, and is the number of unlabeled reviews in the target domain.
- Cross-domain sentiment classification: Cross-domain sentiment classification is defined as the task of training a binary classifier using labeled to predict the sentiment label of a review in the target domain.
3. Data Collection
4. Neural Network Architecture
5. Experimental Evaluation
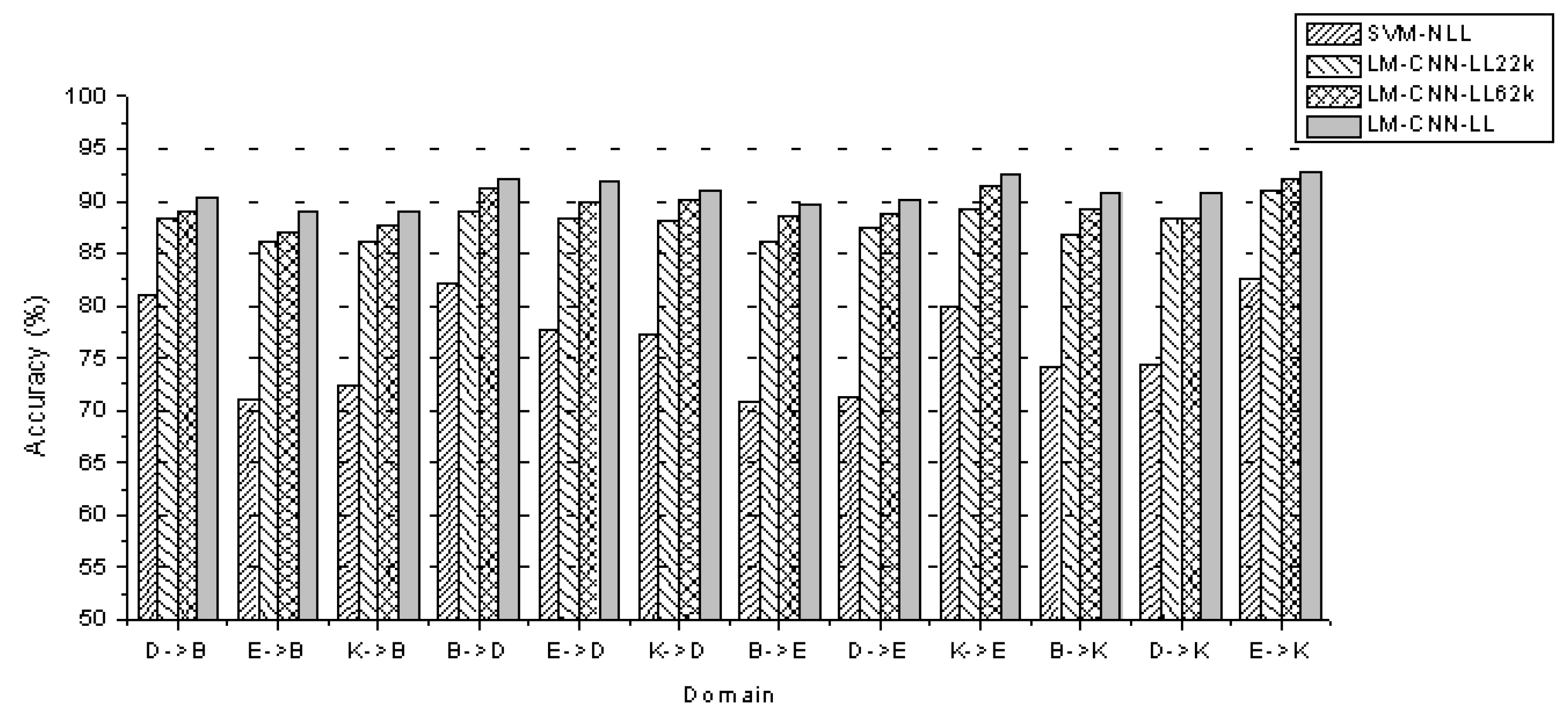
5.1. Benchmark Experiments
- SVM-NBB: A model trained on the source domain was directly applied to predict the target domain without any transfer learning method. The classifier was an SVM using the bag-of-words (BOW) schema and a linear kernel; the source domain and target domain were all from . For example, the source domain was and the target domain was ; the cross-domain classification task was →.
- SVM-NLB: The model trained on the source domain was directly applied to predict the target domain without any transfer learning method. The classifier was SVM, using BOW and a linear kernel. The source domain was from , and the target domain was from . For example, when the source domain was , the target domain was , and the cross-domain classification task was →.
- SFA: Spectral feature alignment was proposed by Pan et al. This approach bridged the gap between different source and target domains via word alignments [3]. The source domain and target domain were both from .
- SS-FE: The SS-PE approach was used to conduct both labeling adaptation and instance adaptation for domain adaptation as in [5]. The source domain and target domain were each from .
- CSC: The authors of [8] proposed a common subspace construction method for cross-domain sentiment classification called CSC. The source domain and target domain were each from .
- PJNMF: This method links heterogeneous input features via pivots via joint non-negative matrix factorization [6]. The source domain and target domain were each from .
- LM-CNN-NLB: LM-CNN-LB was applied to the source domain using to train the . Then, the was directly applied to predict the target domain from .
- LM-CNN-BB: Like LM-CNN-LB but the was trained on the source domain from . The training set size was 1600 and the validation set size was 400. Then, the was also trained on the target domain from . The training set size was 400, the validation set size was 200, and the remaining 1400 data points comprised the test set.
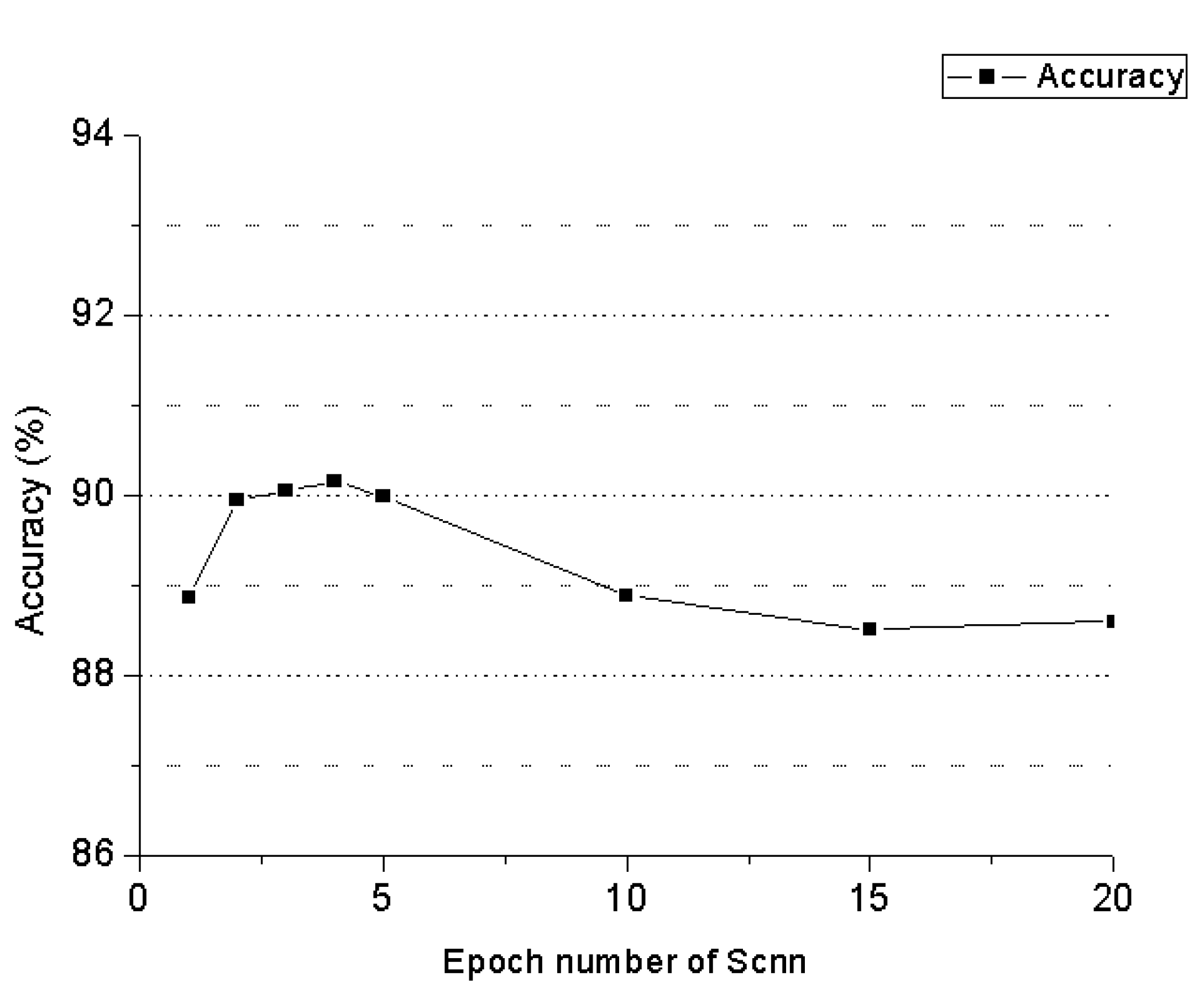
5.2. Experimental Configuration
5.3. Large-Scale Corpus Experiments
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| CNN | Convolutional neural network |
| NLP | Natural language processing |
References
- Recupero, D.R.; Presutti, V.; Consoli, S.; Gangemi, A.; Nuzzolese, A.G. Sentilo: Frame-based sentiment analysis. Cognit. Comput. 2015, 7, 211–225. [Google Scholar]
- Blitzer, J.; McDonald, R.; Pereira, F. Domain adaptation with structural correspondence learning. In Proceedings of the Empirical Methods in Natural Language Processing (EMNLP), Sydney, Australia, 22–23 July 2006; pp. 120–128. [Google Scholar]
- Pan, S.J.; Ni, X.; Sun, J.T.; Yang, Q.; Chen, Z. Cross-domain sentiment classification via spectral feature alignment. In Proceedings of theWorldWideWeb (WWW), Raleigh, NC, USA, 26–30 April 2010; pp. 751–760. [Google Scholar]
- Bollegala, D.; Weir, D.; Carroll, J. Cross-domain sentiment classification using a sentiment sensitive thesaurus. IEEE Trans. Knowl. Data Eng. 2013, 25, 1719–1731. [Google Scholar] [CrossRef]
- Xia, R.; Zong, C.; Hu, X.; Cambria, E. Feature ensemble plus sample selection: Domain adaptation for sentiment classification. IEEE Intell. Syst. 2013, 28, 10–18. [Google Scholar] [CrossRef]
- Zhou, G.; He, T.; Wu, W.; Hu, X.T. Linking heterogeneous input features with pivots for domain adaptation. In Proceedings of the International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 1419–1425. [Google Scholar]
- Li, S.; Xue, Y.; Wang, Z.; Zhou, G. Active learning for cross-domain sentiment classification. In Proceedings of the International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013; pp. 2127–2133. [Google Scholar]
- Zhang, Y.; Xu, X.; Hu, X. A common subspace construction method in cross-domain sentiment classification. In Proceedings of the Conference on Electronic Science and Automation Control, Zhengzhou, China, 15–16 August 2015; pp. 48–52. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y. Convolutional neural networks for sentence classification. In Proceedings of the Empirical Methods on Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 5–8 December 2013; pp. 3111–3119. [Google Scholar]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A convolutional neural network for modelling sentences. In Proceedings of the Association for Computational Linguistics (ACL), Baltimore, MD, USA, 22–27 June 2014; pp. 655–665. [Google Scholar]
- Lu, J.; Behbood, V.; Hao, P.; Xue, S.; Zhang, G. Transfer learning using computational intelligence: A survey. Knowl.-Based Syst. 2015, 80, 14–23. [Google Scholar] [CrossRef]
- Kandaswamy, C.; Silva, L.M.; Alexandre, L.A.; Santos, J.M.; de Sá, J.M. Improving deep neural network performance by reusing features trained with transductive transference. In Proceedings of the International Conference on Artificial Neural Networks (ICANN), Hamburg, Germany, 15–19 September 2014; pp. 265–272. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? In Proceedings of the Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014; pp. 3320–3328. [Google Scholar]
- Pan, J.; Hu, X.; Li, P.; Li, H.; Li, W.; He, Y.; Zhang, Y.; Lin, Y. Domain adaptation via multi-layer transfer learning. Neurocomputing 2016, 190, 10–24. [Google Scholar] [CrossRef]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Ding, X.; Liu, T.; Duan, J.; Nie, J.Y. Mining user consumption intention from social media using domain adaptive convolutional neural network. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 2389–2395. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Domain adaptation for large-scale sentiment classification: A deep learning approach. Proceedings of ICML Workshop on Unsupervised and Transfer Learning, Bellevue, WA, USA, 28 June–2 July 2011; pp. 513–520. [Google Scholar]
- Bengio, Y. Deep learning of representations for unsupervised and transfer learning. In Proceedings of the International Conference on Unsupervised and Transfer Learning Workshop, Edinburgh, UK, 26 June–1 July 2012; pp. 17–36. [Google Scholar]
- Mesnil, G.; Dauphin, Y.; Glorot, X.; Rifai, S.; Bengio, Y.; Goodfellow, I.J.; Lavoie, E.; Muller, X.; Desjardins, G.; Warde-Farley, D. Unsupervised and Transfer Learning Challenge: a Deep Learning Approach. Proceedings of ICML Workshop on Unsupervised and Transfer Learning, Bellevue, WA, USA, 27 June–1 July 2012; pp. 97–110. [Google Scholar]
- Liu, B.; Huang, M.; Sun, J.; Zhu, X. Incorporating domain and sentiment supervision in representation learning for domain adaptation. In Proceedings of the International Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 1277–1283. [Google Scholar]
- Gani, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-Adversarial Training of Neural Networks. J. Mach. Learn. Res. 2015, 17, 1–35. [Google Scholar]
- Mou, L.; Meng, Z.; Yan, R.; Li, G.; Xu, Y.; Zhang, L.; Jin, Z. How Transferable are Neural Networks in NLP Applications? In Proceedings of the EMNLP, Austin, TX, USA, 1–4 November 2016; pp. 479–489. [Google Scholar]
- Seera, M.; Lim, C.P. Transfer learning using the online fuzzy min-max neural network. Comput. Appl. 2014, 25, 469–480. [Google Scholar] [CrossRef]
- Zeng, D.; Liu, K.; Lai, S.; Zhou, G.; Zhao, J. Relation classification via convolutional deep neural network. In Proceedings of the International Conference on Computational Linguistic (COLING), Dublin, Ireland, 23–29 August 2014; pp. 2335–2344. [Google Scholar]
- Nguyen, T.H.; Grishman, R. Relation extraction: Perspective from con-volutional neural networks. In Proceedings of the VS@HLT-NAACL, Denver, CO, USA, 31 May–5 June 2015; pp. 39–48. [Google Scholar]
- Meng, F.; Lu, Z.; Wang, M.; Li, H.; Jiang, W.; Liu, Q. Encoding source language with convolutional neural network for machine translation. In Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), Beijing, China, 26–31 July 2015; pp. 20–30. [Google Scholar]
- Dos Santos, C.N.; Gatti, M. Deep convolutional neural networks for sentiment analysis of short texts. In Proceedings of the International Conference on Computational Linguistics (COLING), Dublin, Ireland, 23–29 August 2014; pp. 69–78. [Google Scholar]
- McAuley, J.; Pandey, R.; Leskovec, J. Inferring networks of substitutable and complementary products. In Proceedings of the International Conference on Knowledge Discovery and Data Mining (KDD’15), Sydney, Australia, 10–13 August 2015; pp. 785–794. [Google Scholar]
- Blitzer, J.; Dredze, M.; Pereira, F. Biographies, bollywood, boom-boxes and blenders: Domain adaptation for sentiment classification. In Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), Prague, Czech Republic, 23–30 June 2007; pp. 440–447. [Google Scholar]
- Chollet, F. Keras. Available online: http://github.com/fchollet/keras (accessed on 19 July 2017).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| KL Divergence | ||
|---|---|---|
| 0.1005126 | ||
| 0.0956735 | ||
| 0.0661170 | ||
| 0.0397648 |
| Domain | → | ||
|---|---|---|---|
| D→B | 0.2643 | 0.2052 | 0.3017 |
| E→B | 0.6069 | 0.4864 | 0.5113 |
| K→B | 0.6048 | 0.5064 | 0.5126 |
| B→D | 0.2294 | 0.1925 | 0.2439 |
| E→D | 0.5225 | 0.4587 | 0.4734 |
| K→D | 0.5677 | 0.5043 | 0.4938 |
| B→E | 0.6153 | 0.3171 | 0.4014 |
| D→E | 0.5363 | 0.3025 | 0.3610 |
| K→E | 0.3010 | 0.2379 | 0.2189 |
| B→K | 0.6280 | 0.3029 | 0.3746 |
| D→K | 0.6211 | 0.2642 | 0.3425 |
| E→K | 0.3033 | 0.1936 | 0.1800 |
| Domain | + | Positive | Negative |
|---|---|---|---|
| + | 50,000 + 1000 | 50,000 + 1000 | |
| + | 50,000 + 1000 | 50,000 + 1000 | |
| + | 50,000 + 1000 | 50,000 + 1000 | |
| + | 50,000 + 1000 | 50,000 + 1000 |
| Method | Training () | Validation () | Training () | Validation () |
|---|---|---|---|---|
| LM-CNN-LB22k | 18,000 | 4000 | 700 | 300k |
| LM-CNN-LB62k | 54,000 | 8000 | 2000 | 1000 |
| LM-CNN-LB | 90,000 | 12,000 | 4000 | 1000 |
| Multi-source domain | 54,000 | 12,000 | 700 | 300 |
| Frozen Layer/s | Accuracy |
|---|---|
| 0,1,2,3 | 88.12 |
| 0,1,2 | 88.13 |
| 0,1 | 88.66 |
| 0 | 89.42 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, X.; Lin, H.; Yu, Y.; Yang, L. Low-Resource Cross-Domain Product Review Sentiment Classification Based on a CNN with an Auxiliary Large-Scale Corpus. Algorithms 2017, 10, 81. https://doi.org/10.3390/a10030081
Wei X, Lin H, Yu Y, Yang L. Low-Resource Cross-Domain Product Review Sentiment Classification Based on a CNN with an Auxiliary Large-Scale Corpus. Algorithms. 2017; 10(3):81. https://doi.org/10.3390/a10030081
Chicago/Turabian StyleWei, Xiaocong, Hongfei Lin, Yuhai Yu, and Liang Yang. 2017. "Low-Resource Cross-Domain Product Review Sentiment Classification Based on a CNN with an Auxiliary Large-Scale Corpus" Algorithms 10, no. 3: 81. https://doi.org/10.3390/a10030081
APA StyleWei, X., Lin, H., Yu, Y., & Yang, L. (2017). Low-Resource Cross-Domain Product Review Sentiment Classification Based on a CNN with an Auxiliary Large-Scale Corpus. Algorithms, 10(3), 81. https://doi.org/10.3390/a10030081