1. Introduction
Data mining is a helpful and efficient process for analysis and implementation of data. Cluster analysis could be defined as uncensored data classification, it is a crucial topic in data mining [
1]. It aims at attempting to partition a collection of patterns into groups (clusters) of similar data points. Patterns within a cluster are more similar to each other than patterns belonging to other clusters. Clustering methods [
2] have been involved in many applications, including information retrieval, pattern classification, document extraction, image segmentation, etc.
Data clustering techniques can be broadly divided into two groups: hierarchical and partitional [
1,
3,
4]. Hierarchical clustering techniques is a tree showing a sequence of clustering. Hierarchical algorithms can be agglomerative (bottom-up) mode starting with each instance in its own cluster and merging the most similar pair of clusters successively to form a cluster hierarchy; or in divisive (top-down) mode starting with all the instances in one cluster and recursively splitting each cluster into smaller clusters. Partitional clustering methods find all the clusters simultaneously as a partition of the data without any other subpartition like hierarchical structures do and are often based on the combinatorial optimization task of the best configuration of partitions among all possible ones, according to a function that assesses the quality of partitions (objective function). In this paper we will consider partition clustering.
In the field of clustering, the
K-means algorithm [
5,
6,
7] is one of the most popular clustering techniques for finding structures in unlabeled datasets. It can be used to partition a number of data points into a given number of clusters, which is based on a simple iterative scheme for finding a local minimum solution. The
K-means algorithm is well known for its efficiency and its ability to cluster large datasets. However, a major bottleneck in the operation of
K-means is the requirement of predefinition of the clusters number [
8]. From another side, the high dependence of the final clustering on the initial identification of clusters elements represents another difficulty to the operation of
K-means [
8].
Some research studies have approached the clustering problem from a meta-heuristic perspective. Meta-heuristics have a major advantage over other methods, which is the ability to avoid becoming trapped at local minima. Such algorithms exploit guided random search. Therefore, much better results have been obtained with meta-heuristics approaches, such as simulated annealing [
9,
10,
11,
12,
13,
14], tabu search [
15,
16], and genetic algorithms [
17]. They combine techniques of local search and general strategies to escape from local optima leading to broadly searching the solution space. The objective of such combination is to obtain solutions that are closer to the global optima (centroids) of the clusters. Based on the tendency of the
K-means algorithm to obtain local optima [
18], this work investigates a new approach to solve clustering problem.
Data clustering is known to be NP hard in finding groups in heterogeneous data [
19]. It is the process of grouping similar data items together based on some measure of similarity (or dissimilarity) between items. A major difficulty that exists with
K-means clustering, as one of the most well-known unsupervised clustering methods, is the requirement of prior knowledge about the number of clusters. This piece of information could be difficult to know in advance for many applications. Moreover,
K-means has other well-known drawbacks, sensitivity to initial configuration and its convergence to local optima. These problems are raised in the literature, see [
7,
20,
21,
22,
23,
24,
25] and reference therein. Different treatments have been discussed to find better tuning mechanisms of the number
K including statistical tests, probabilistic models, incremental estimation process, or visualization schemes. In the following, we give a brief presents of some of those treatments.
In [
26], the authors built a powerful learning-based fuzzy
C-means structure, so it turns out to be free of the fuzziness index
m and initializations without parameter choice, and can likewise consequently locate the best number of clusters. They initially utilized entropy-type penalty terms for optimizing the fuzziness index, and afterward make a learning-based schema for finding the best number of clusters. That learning-based schema uses entropy terms contain the belonging probabilities of data points to clusters and the average of occurrence in those probabilities over fuzzy memberships to find the best number of clusters.
Kuo et al. [
27] proposed a new automatic clustering approach based on particle swarm optimization and genetic algorithm. Their algorithm can automatically find data clusters by examining the data without need to set a fixed number of clusters. Specifically, the number of clusters is treated as a variable to be optimized within the clustering method.
In [
28], the authors proposed an intelligent
K-means method, called
-means, that locates the number of clusters by extracting odd examples from the data one-by-one. They used the Gaussian distribution to generate cluster models. Therefore, the clustering process can be analyzed through the usage of Gaussians in the data generation and specifics
K-means clusters. Then, they could compare the performance of methods in terms of their capabilities in recovering cluster centroids as well as their abilities to recover of the number of clusters or clusters themselves. Their final version of
-means utilizes the cluster number tuning, the cluster recovery, and the centroid recovery.
Hamerly and Elkan [
29] proposed the
G-means algorithm, which is based on assuming a statistical test checking if a subset of data follows a Gaussian distribution or not.
G-means implements
K-means with increasing values of
K in a hierarchical structure until the hypothesis test is accepted.
The authors of [
30] presented a projected Gaussian method for data clustering called
-means. Their method tries to discover an appropriate number of Gaussian clusters, as well as their positions and orientations. Therefore, their clustering strategy inherits the features of the well-known Gaussian mixture model. The main contribution of that paper is to use projections and statistical tests to determine if a generated mixture model fits its data or not.
Tibshirani et al. [
31] introduced a new measurement to estimate the number of clusters based on comparing the change within-cluster dispersion through some statistical tests. That measure can be used to the output of any clustering method in order to adapt the number of clusters.
Kurihara and Welling [
32] presented a Bayesian
K-means based on the mixture model learning using the expectation-maximization method. Their method can be implement as a top-down approach “Bayesian k-means” or as a bottom-up one “agglomerative clustering”.
In [
33], Pelleg et al. introduced a new algorithm,
X-means, to find the best configuration of the cluster locations and the number of clusters to optimize the Bayesian or Akaike information criteria. In each
K-means run, the current centroids should be checked by the splitting conditions using Bayesian information criterion. A modified version of the
X-means algorithm is presented in [
34]. The main deviation is to apply a new cluster merging procedure to avoid unsuitable splitting caused by the cluster splitting order.
Pham et al. [
23] presented an extensive review of the existing methods for selecting the number of clusters in
K-means algorithms. In addition, the authors introduced a new measure to evaluate the selection of the number
K.
In [
35], the authors proposed a new clustering technique based on a modified version of
K-means and a union-split algorithm to find a better value of the number of clusters. Those clustering methods are applied to undirected graphs to cluster similar graph nodes into clusters with a minimum size constraint to the cluster number.
Other studies followed dynamic clustering strategies, e.g., in [
36], cluster combination is performed using an evidence accumulation approach. Also Guan et al. [
37] have developed
Y-means as an alternative clustering method of
K-means. In
Y-means, the number of clusters can be dynamically determined via assigning or removing data points to or from generated clusters depending on an Eacludian metric.
Masoud et al. [
38] proposed a dynamic data clustering method based on the combinatorial particle swarm optimization technique. Their method treats the data clustering problem as a single problem, including the sub-problem of finding the best number of clusters. Therefore, they tried to find the number of clusters and cluster centers simultaneously. In order to adapt the number of clusters, a similarity degree between the clusters is computed and the clusters with the highest similarity are merged.
The authors of [
39] developed a new method for automatically determination of the number of clusters based on some existing image and signal processing algorithms. Their algorithm generates an image representation of the data dissimilarity matrix and converts it to a Laplacian matrix. Then, visual assessment of cluster tendency techniques is applied in the latter matrix after normalizing its rows.
Metaheuristics are powerful and practical tools that have been applied to many different problems [
40,
41]. Many clustering methods have been designed as metaheuristic-based methods [
42,
43,
44]. Such methods try to find global optimal configurations of data clusters within reasonable processing times. Different types of metaheuristics have been used to solve different data clustering problems such as genetic algorithms [
45,
46,
47,
48,
49,
50,
51], simulated annealing [
18,
52,
53], tabu search [
54,
55], particle swarm optimization [
54,
56,
57,
58,
59], ant colony optimization [
60,
61,
62,
63], harmony search algorithm [
64,
65], and firefly algorithm [
66,
67].
Most of the above-mentioned papers mainly use statistical tests, probabilistic models, incremental estimation process, or visualization schemes. These procedures are usually deteriorated when applied to complex or big data sets. Therefore, we propose K-Means Cloning (KMC) algorithm as a dynamic clustering approach that generates continuously evolving clusters as new samples are added to the input dataset; the case which makes it very adequate to real-time fed data streams and for large datasets whose unpredictable number of clusters.
This paper describes KMC and its application to the automatic clustering of large unlabeled data sets. In contrast to most of the existing clustering techniques, the proposed algorithm requires no prior knowledge of the data to be classified. Rather, it determines the optimal number of partitions of the data with consistency of the results in every runs. KMC generates dynamic “colonies” of K-means clusters. As data samples are added to the dataset the initial number of clusters as well as the clusters structures are modified for the sake of achieving optimality constraints. The structure of the iteratively-generated clusters is changed using intensification and diversification of the K-means cluster. Superiority of the new method is demonstrated by comparing it with some state-of-the-arts clustering techniques.
The rest of this paper is organized as follows. In
Section 2, the outlines of the proposed
K-means cloning are described. Necessary overview of the used simulated annealing approach as well as the problem modeling are explained.
Section 3 shows how the procedure ingredients are used to build up the entire KMC algorithm. Experimental setup is detailed in
Section 4. A comprehensive discussion of the obtained evaluation results is presented in
Section 5. Finally, the paper is concluded in
Section 6.
2. K-Means Cluster Cloning
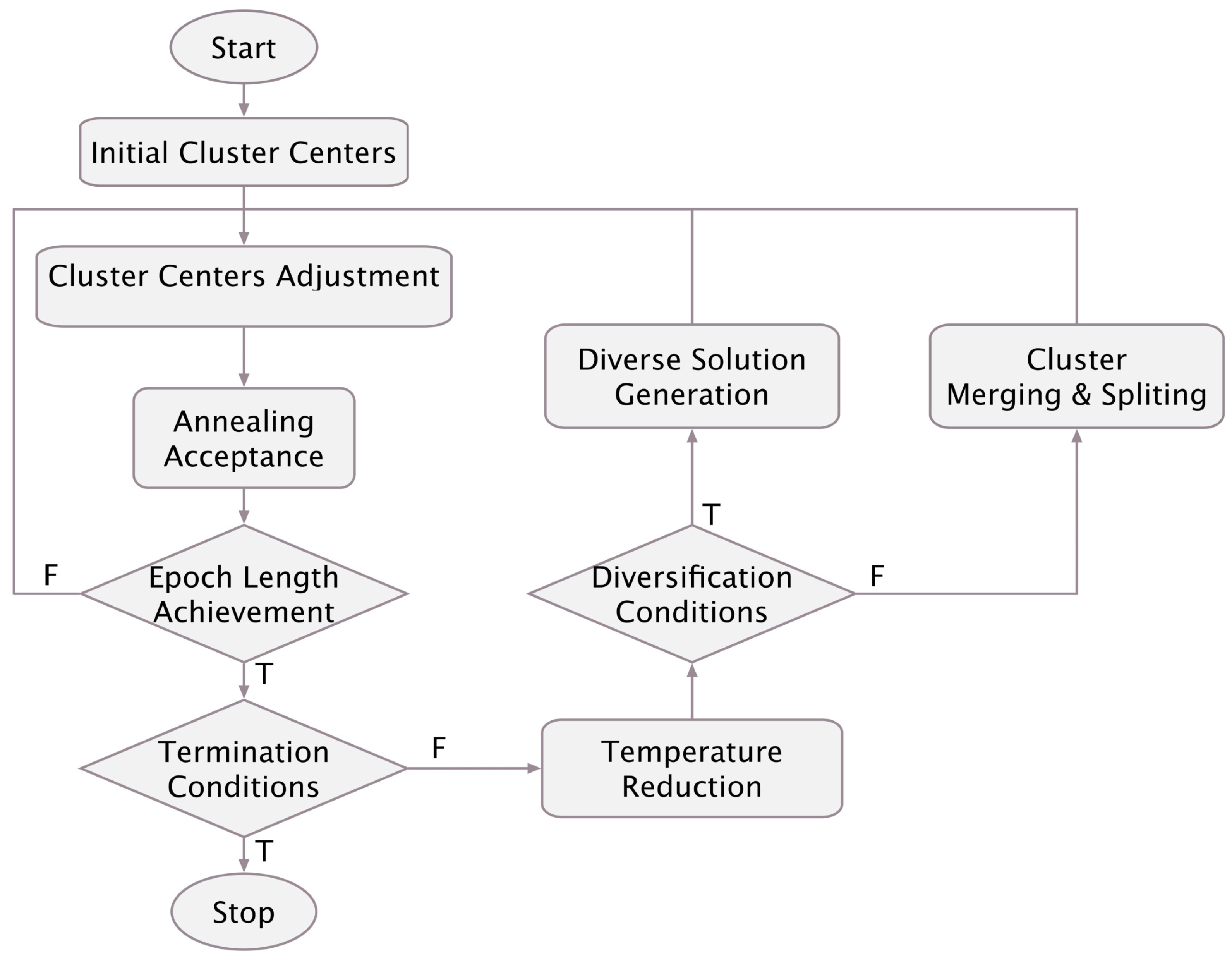
The proposed KMC data clustering procedure involves three main processes: the first one is measuring the similarity/dissimilarity between a data sample and the existing clusters in the data spaces. The second process is taking a decision of merging two existing clusters into a larger one, if they achieved a specific merging similarity constraint. The third is conducted if some degree of dissimilarity is reached within an existing cluster. In this case, the cluster is split into two or more smaller clusters. All of these three processes are performed in an integrated fashion in order for achieving global optimality conditions. Therefore, we look at this problem as a global search problem from an optimization perspective. Within this search, an optimum point in the search space, whose independent variables are the number of clusters and the data samples’ memberships to the constructed clusters, is to be found.
The problem, as described in this context of the size and discontinuity of the search space, stimulates the usage of meta-heuristic search. We opted to use simulated annealing for this purpose. However, the problem can be remodeled to accommodate any other meta-heuristic approach.
In the next subsection, we give a brief review of the SA algorithm. Then, in the following subsections, we describe the proposed model incorporating the aforementioned three processes.
2.1. Simulated Annealing Heuristic
Simulated Annealing (SA) [
68] is a generic probabilistic meta-heuristic for the global optimization problem of locating a good approximation to the global optimum of a given function in a large search space. It is a random-search technique and often used when the search space is discrete. For certain problems, simulated annealing may be more efficient than exhaustive enumeration provided that the goal is merely to find an acceptably good solution in a fixed amount of time, rather than the best possible solution.
SA, as its name implies, exploits an analogy between the way in which a metal cools and freezes into a minimum energy crystalline structure, i.e., the annealing process. The SA algorithm successively generates a trial point in a neighborhood of the current solution and determines whether or not the current solution is replaced by this trial point based on a probability value. This value is related to the difference between their function values. Convergence to an optimal solution can theoretically be guaranteed only after an infinite number of iterations controlled by the procedure so-called cooling schedule. Algorithm 1 describes the main algorithmic steps of simulated annealing.
For global search purposes, it does not only accept changes that decrease the objective function
f (assuming a minimization problem), but also it makes some changes that increase it. The latter are accepted with a probability;
where
is the increase in
f and
T is a control parameter, which by analogy with the original application is known as the system “temperature” irrespective of the objective function involved.
| Algorithm 1 Simulated Annealing |
- 1:
Initialize , , and . - 2:
Set , , and . - 3:
while do - 4:
for to do - 5:
Generate y. - 6:
if then - 7:
then . - 8:
else - 9:
if then - 10:
Set . - 11:
end if - 12:
end if - 13:
end for - 14:
end while - 15:
Set . - 16:
Calculate epoch length . - 17:
Calculate control temperature T.
|
SA has been used on a wide range of combinatorial optimization problems and achieved good results. In data mining, SA has been used for feature selection, classification, and clustering [
69].
2.2. Clusters’ Fitness Function
To measure the quality of the proposed clustering, we exploit the silhouette as a fitness function [
70,
71,
72,
73]. In order to calculate the final silhouette fitness function, two inputs should be firstly computed for all data objects as shown in the following.
Inner Dissimilarity (): is the average dissimilarity between a data object
i and other objects in its cluster
, which can given by
where
is the classical Euclidean distance used in
K-means, and
is the number of objects in cluster
.
Outer Dissimilarity (): is the minimum distance between a data object
i to cluster centers except its cluster
, this can be computed in two steps as follows. First, we compute the average dissimilarity (
) between
i and other cluster
,
where
is the number of objects in cluster
. Then,
can be computed as,
For each data object
i in all clusters, the overall dissimilarity
is expressed by [
73]:
From Equation (
1), the cluster silhouette
is the average dissimilarity of its data objects.
Finally, the clusters fitness
function is the average of all cluster silhouettes.
It is worthwhile to mention that the object dissimilarity
satisfies the condition,
This condition is still valid for and since they are computed as averages of . Moreover, each different value of K generates a different . The higher value can achieve, the better clustering can be obtained.
2.3. K-Means Colony Growth
A major challenge in partitional clustering lies in determining the number of clusters that best characterize a set of observations. The question is: In starting with an initial number of clusters, what mechanism through which the search strategy can find the best solution, i.e., actual number clusters? To answer this question we define the cluster merging and splitting procedures which are discussed in this section.
For further explanation, we used two synthetic datasets described as follows:
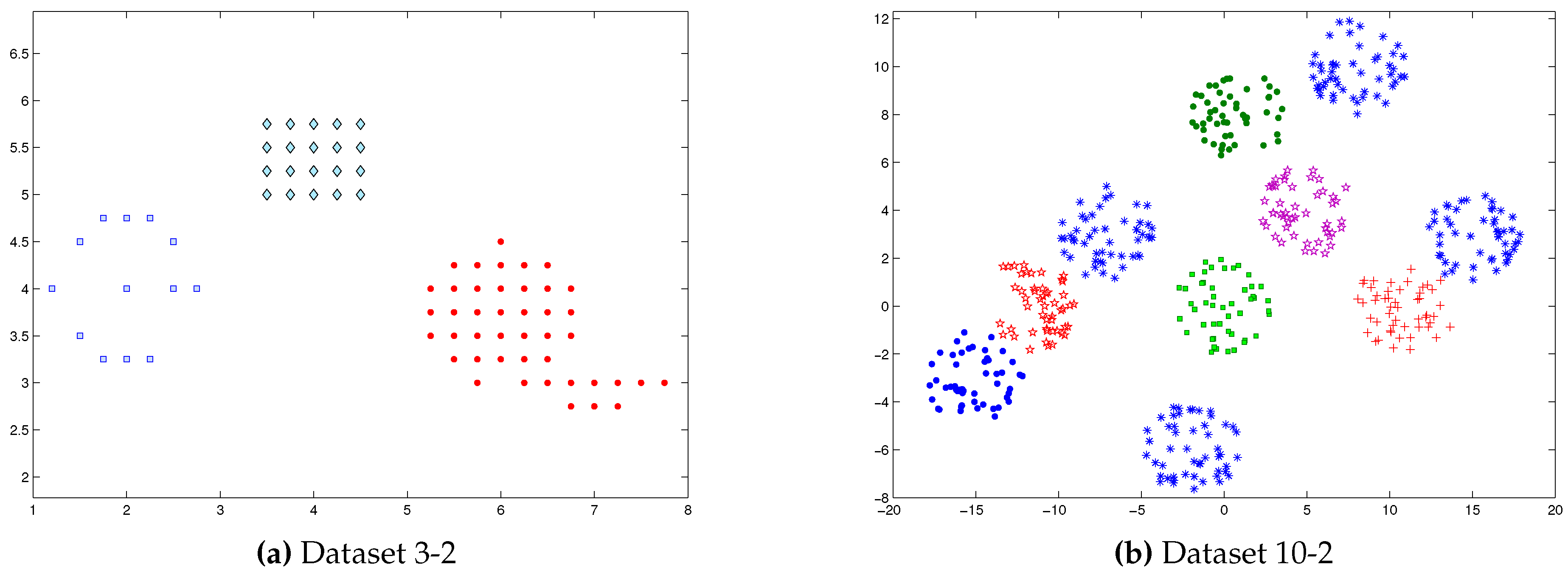
Dataset 3-2: This dataset used in [
74], consists of 76 data points distributed over three clusters. Some points of one cluster are symmetrical with respect to the other cluster center, see
Figure 1a.
Dataset 10-2: This dataset used in [
69], consists of 500 two dimensional data points distributed over 10 different clusters. Some clusters are overlapping in nature. Each cluster consists of 50 data points, see
Figure 1b.
The adaption process to fix the number of clusters depends on three sub-processes; how to evaluate the current number of cluster, which cluster(s) should be split or merged, and how we perform the cluster splitting or merging. These sub-processes are discussed in the following.
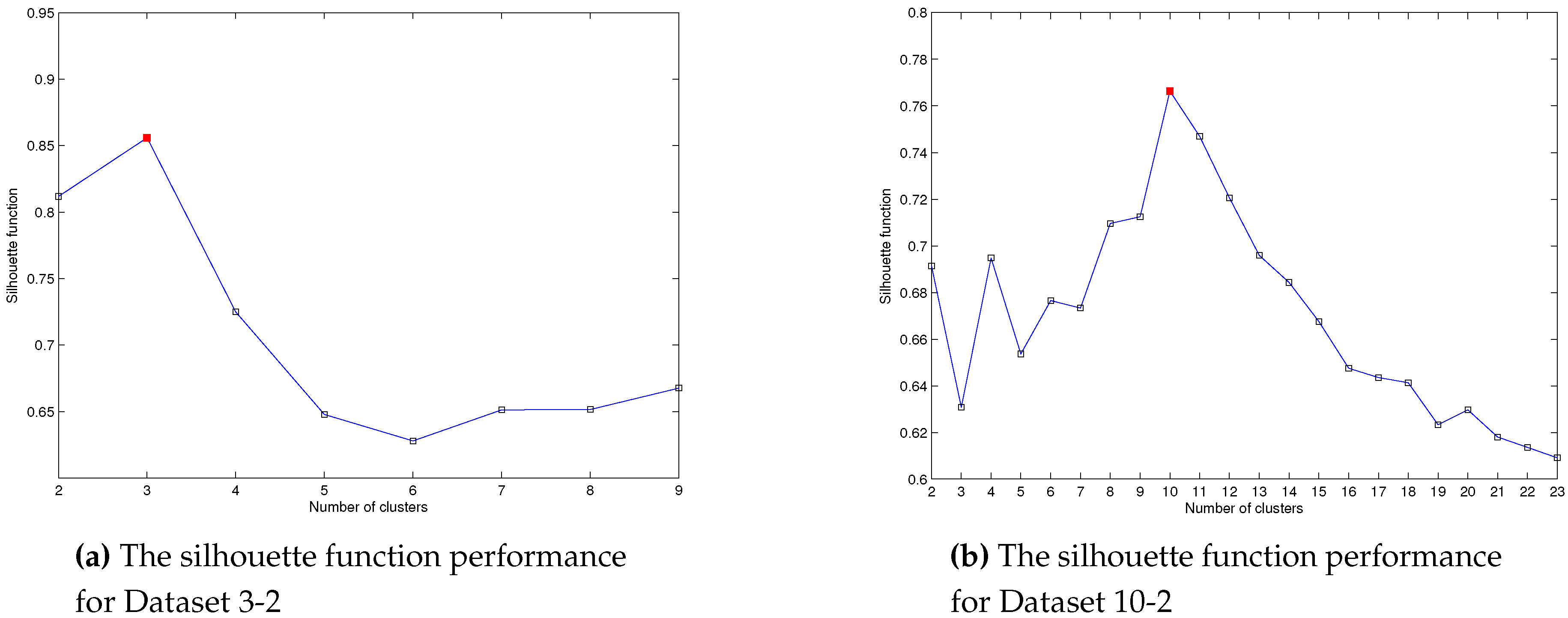
2.3.1. Evaluating the Number of Clusters
It is instructive to see how clustering objective function
changes with respect to the change of
K, the number of clusters. During our experiments, we discovered that the performance of
measure moves towards the best solution (optimum number of clusters) smoothly.
was sequentially applied to several dataset with the number of clusters ranging from 2 to
. SA was run many times starting with initial fixed number
, using Dataset 3-2 and Dataset 10-2. The best values obtained with maximum
measure were stored. The final outcome of these calculations and the performance of
are shown in
Figure 2.
In
Figure 2a the peak begin when
and minimum
, then starts increasing with the increase of the number of clusters and
together for Dataset 3-2.
continues to increase until it reaches the maximum value when the maximum peak is reached for
= 0.856. Then,
begin to decline with continued increase of the number of clusters. Similarly, the maximum peak for the Dataset 10-2 is reached when
= 0.7664, as shown in
Figure 2b.
These obtained values comply with the common sense evaluation of the data by visual inspection. Also the well-known Ruspini dataset [
72], has been widely used as a benchmark for clustering algorithms, the maximum peaks are achieved when
, see [
71]. We need two values for the number of clusters, the initial number
K and random
with two
values. By comparing the two
values for two values of number clusters, the next step whether of merging or splitting process is determined. The following procedure illustrates this process.
Procedure 1. K-Adaptation
- 1.
Input: two clustering outputs and with and clusters, respectively, with .
- 2.
If , then apply cluster merging (Procedure 2) or cluster splitting (Procedure 3) randomly in order to get different cluster numbers. Rename the obtained clusters to ensure that .
- 3.
Evaluation: compute and .
- 4.
Merging: if , then apply cluster merging (Procedure 2) on , to produce clusters. Set , and return.
- 5.
Splitting: if , then apply cluster splitting (Procedure 3) on , to produce clusters. Set , and return.
- 6.
Neutral: randomly apply the cluster merging or splitting procedure on or to produce new clusters, and return.
Accordingly, a decision is taken using SF by either merging two smaller clusters into a larger one or splitting a larger cluster into smaller ones.
2.3.2. Split/Merge Decision
A crucial step is how to select the next cluster(s) to split or merge. Our splitting and merging procedures issue criterion functions to select cluster(s) to be split or merged according to fitness assessments on the changing cluster structure. It is instructive to see how clustering objective functions change with respect to the change of the number of clusters K. The idea of performing split and merge procedures has been successfully applied to calculating the cluster silhouettes . If the decision was splitting, the cluster which has the minimum cluster silhouette is the one to be split into two sub-clusters. On the other hand, if the decision was merging, the two clusters with minimum cluster silhouettes are the two to be merged.
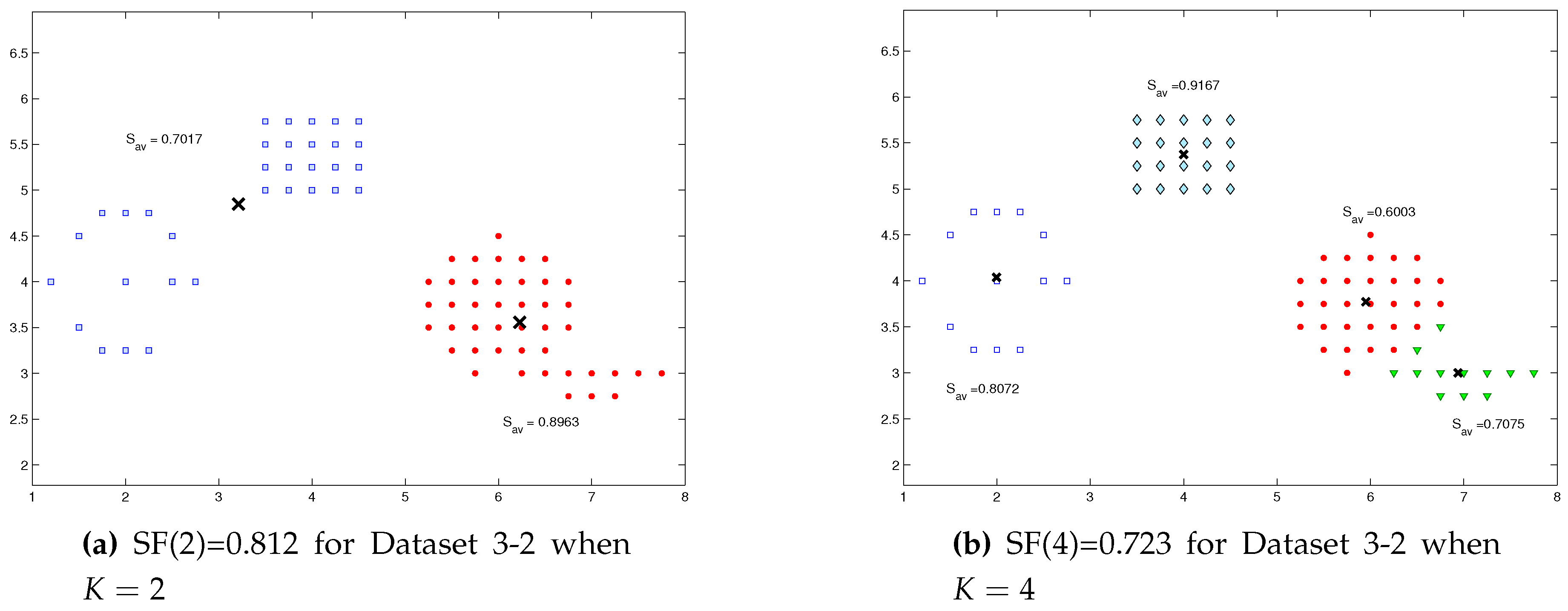
As an illustrative example, Dataset 3-2 in
Figure 1a has the largest value of
, with the optimal number of cluster
, as also shown in
Figure 2a. We computed two appropriate clusters for Dataset 3-2, which
and
, as shown in
Figure 3a. Similarly, four appropriate clusters for the same Dataset 3-2, which are
,
,
and
, see
Figure 3b. According to the
K-Adaptation Procedure, if the comparison was between
and
and
, then splitting procedure must be applied to the cluster which have the minimum dissimilarity
, as shown in
Figure 3a. In the case of which the comparison was between
and
and
, merging procedure must be applied to the two clusters whose the minimum dissimilarities
, as shown in
Figure 3b.
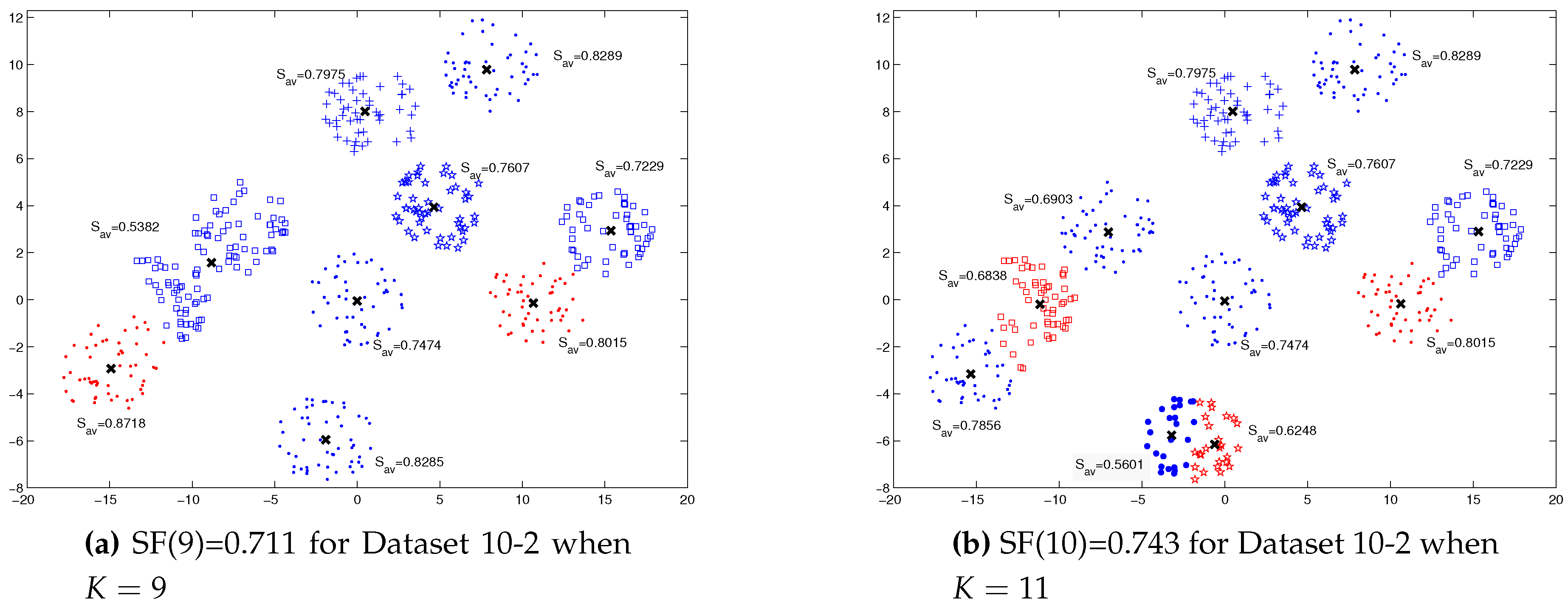
For Dataset 10-2,
Figure 4 describes how the split/merge decision is taken for the clusters that need to be split are determined, as in
Figure 4a, or merged, as in
Figure 4b.
Many attempts were performed on other datasets and proved the veracity of this method and adoption of it as a cluster merging and splitting method to detection an appropriate clusters.
2.3.3. How to Split or Merge
K-means cloning is a continuous evolving process that is represented by split and merge of K-means clusters. Merging and Splitting Procedures 2, 3 show the cloning mechanism of merging two clusters into a larger one, and how a single cluster is split into two new clusters with new centers. When a cluster is split into two sub-clusters, new-alternative centers are generated.
Procedure 2. Merging
- 1.
Input: clustering outputs with clusters , and for each cluster is the number of objects in this cluster, and his center is .
- 2.
Evaluate the cluster silhouettes .
- 3.
Sort the cluster silhouettes to determine the two clusters with the minimum cluster silhouettes and .
- 4.
Set a new center as, - 5.
Replace the centers and by , set .
- 6.
Adjust the new generated centers based on K-means, and return with the adjusted clusters.
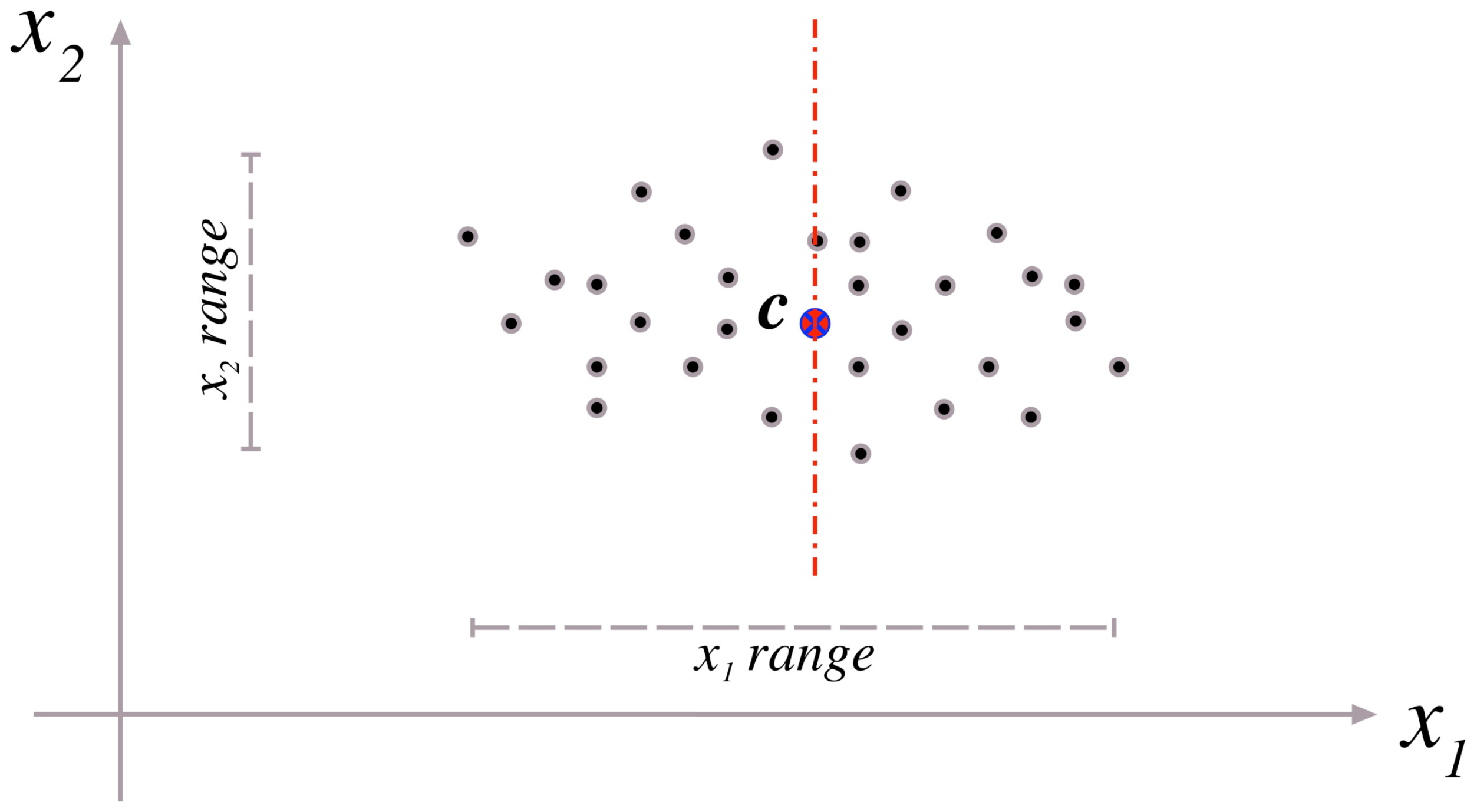
The splitting process is applied to the cluster with the minimum cluster silhouette value among all clusters. A hyperplane is generated to split this cluster objects in order to generate two new clusters. Coordinate-wise variances are computed over the data objects of the chosen cluster. Then, the separation hyperplane is generated passing through the cluster center and orthogonal to the coordinate axis corresponding to the highest variance component of the data objects.
Figure 5 shows an example of cluster splitting in two dimensions. In this figure, it is clear that the data variance over
-axis is higher than that over
-axis. Therefore, the dashed hyperplane is generated passing through center
c and orthogonal to
-axis in order to separate the data objects into two clusters along the both sides of the hyperplane. Data objects which are located on the hyperplane can be added to any of the two clusters since new centers will be computed and all data objects will be adjusted as in the case of
K-means.
Procedure 3. Splitting
- 1.
Input: clustering outputs with clusters , and for each cluster is the number of objects in this cluster, and his center is .
- 2.
Evaluate the cluster silhouettes .
- 3.
Sort the cluster silhouettes to determine the cluster with the minimum cluster silhouette.
- 4.
Divide cluster into two sub-clusters with objects and by splitting the data objects in using a separation hyperplane passing through its center and orthogonal to the coordinate axis corresponding to the highest variance component of the data objects.
- 5.
Compute the centers and of the new clusters and , respectively.
- 6.
Replace with and , set .
- 7.
Adjust the new generated centers based on K-means, and return with the adjusted clusters.
2.4. Diversification
In the proposed KMC method, we use a diversification generation method to generate a diverse solution. This diverse solution can help the search process to scape from local minima. The search space of the parameter K, which is the interval , is divided into equal sub-intervals. When a predefined consecutive number of iterations is reached without hitting any of these sub-intervals, a new diverse solution should be generated from the unvisited sub-intervals. In order to generate a new diverse solution, a new value of is randomly chosen from the unvisited sub-intervals and the K-means clustering process is implemented to compute new clusters , . Procedure 4 formally explains the steps of the diversification process.
Procedure 4. Diversification
- 1.
Input: the lower and upper bounds and of the number of clusters, respectively, the number of cluster number sub-intervals, and numbers of visiting each sub-interval.
- 2.
Select an η from with a probability inversely proportional to its corresponding visiting number .
- 3.
Choose a randomly from the selected sub-interval η.
- 4.
Generate new centers.
- 5.
Adjust the generated centers based on K-means, and return with the adjusted clusters.
5. Results and Discussions
The clustering results of the KMC algorithm are shown in
Table 3 and
Table 4. Two major indicators of performance can be found in these tables: the average computed number of clusters and the average classification error, accompanied by the corresponding standard deviations.
In
Table 3, we took twenty independent runs and provided the mean value and standard deviation evaluated over final clustering results for each algorithm. The number of classes evaluated and the number of misclassified items with respect to the known partitions and classification objects are reported. We can see from the results that are presented in this table, on synthetic and real datasets, all computed clusters that were obtained from the KMC algorithm exactly equals the ground truth classes without any deviation at all runs. Furthermore, KMC obtains misclassification error rates zero in two of datasets.
In
Table 4, the results are averaged over 50 runs on each of the evaluation datasets. Specifically, we used ten instances of each of these datasets in our evaluation and multiple runs were distributed evenly across the instances.
Table 4 shows the comparison results of KMC with CCEA and VGA using Overlap 3, 5 and Separate 3, 6 synthetic datasets, as well as the Iris real datasets. The class distribution is presented in
Table 5. As it is seen from the table, the exact real number of classes have been obtained by KMC algorithm without any deviation. Both CCEA and VGA have deviations in the number of classes with or more datasets.
In most real datasets the number of clusters is not priori known. So, to illustrate the potential of KMC in accurate estimation of the number of clusters in non-obvious datasets, KMC was applied to ten well-known real datasets [
75].
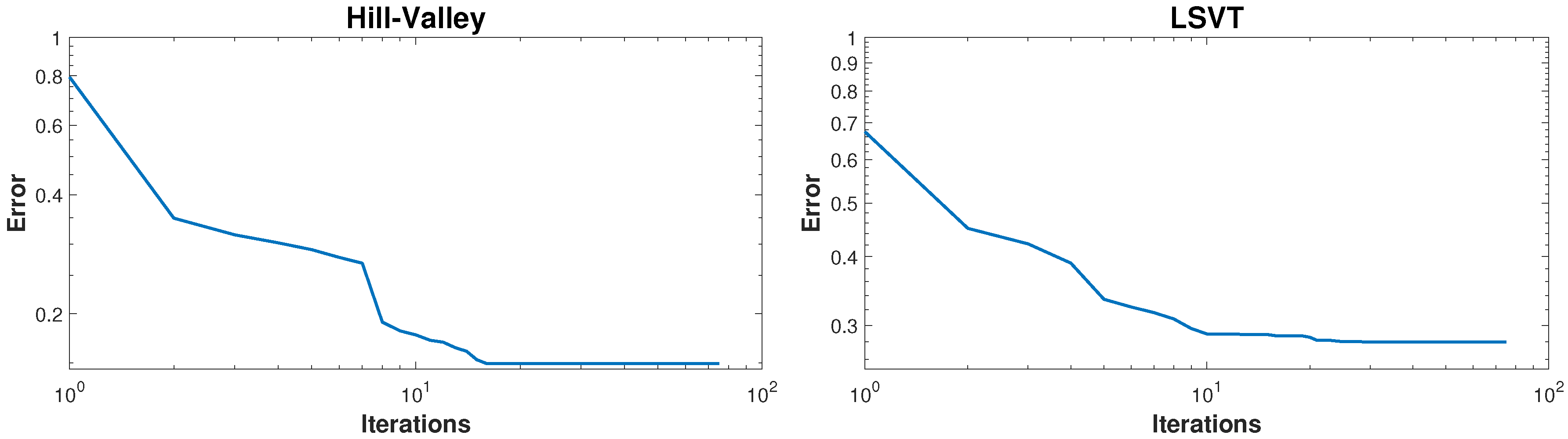
In order to test the performance of the proposed method in higher dimensional datasets, two datasets called “Hill-Valley” and “LSVT” are used [
75]. The details of these datasets are given in
Table 6. The KMC method could obtained the exact number of cluster for both datasets as stated in
Table 6.
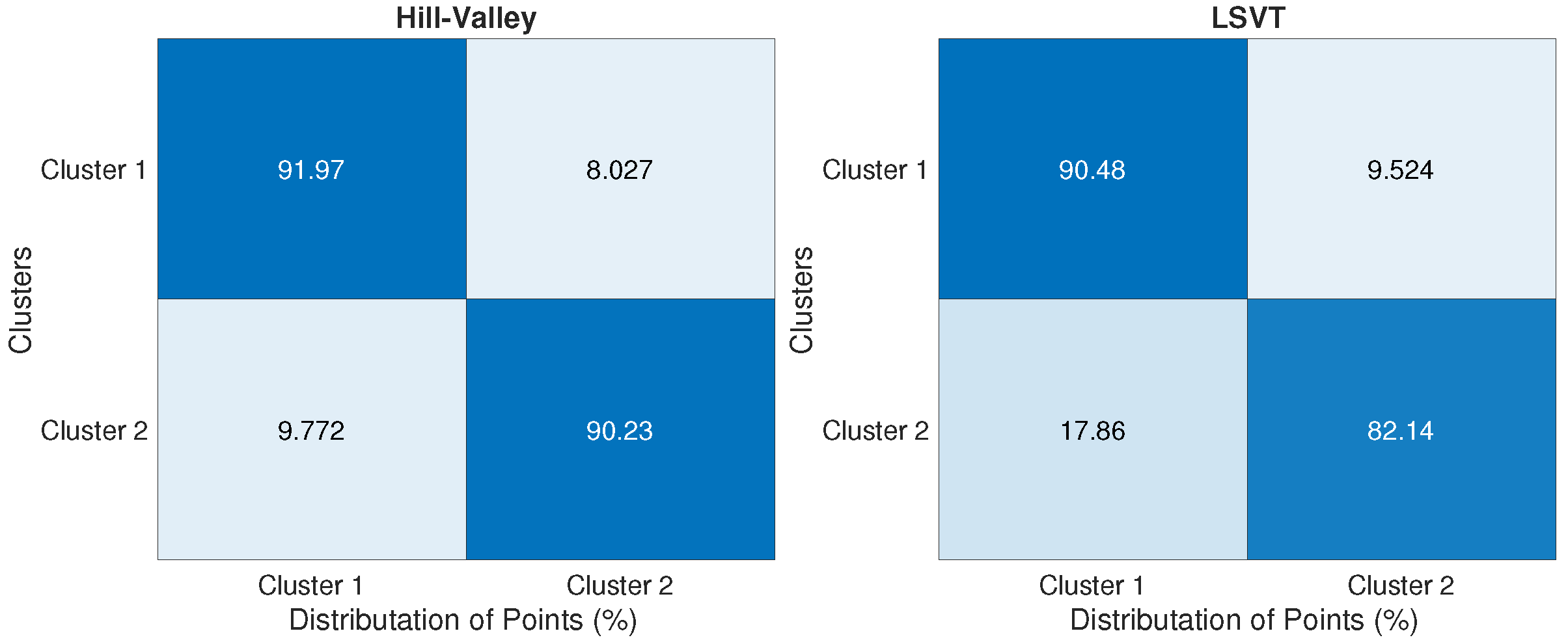
Figure 8 shows the performance of the KMC method in improving the misclassification errors for these datasets. The average misclassification errors for Hill-Valley and LSVT datasets are 14.95% and 27.98%, respectively.
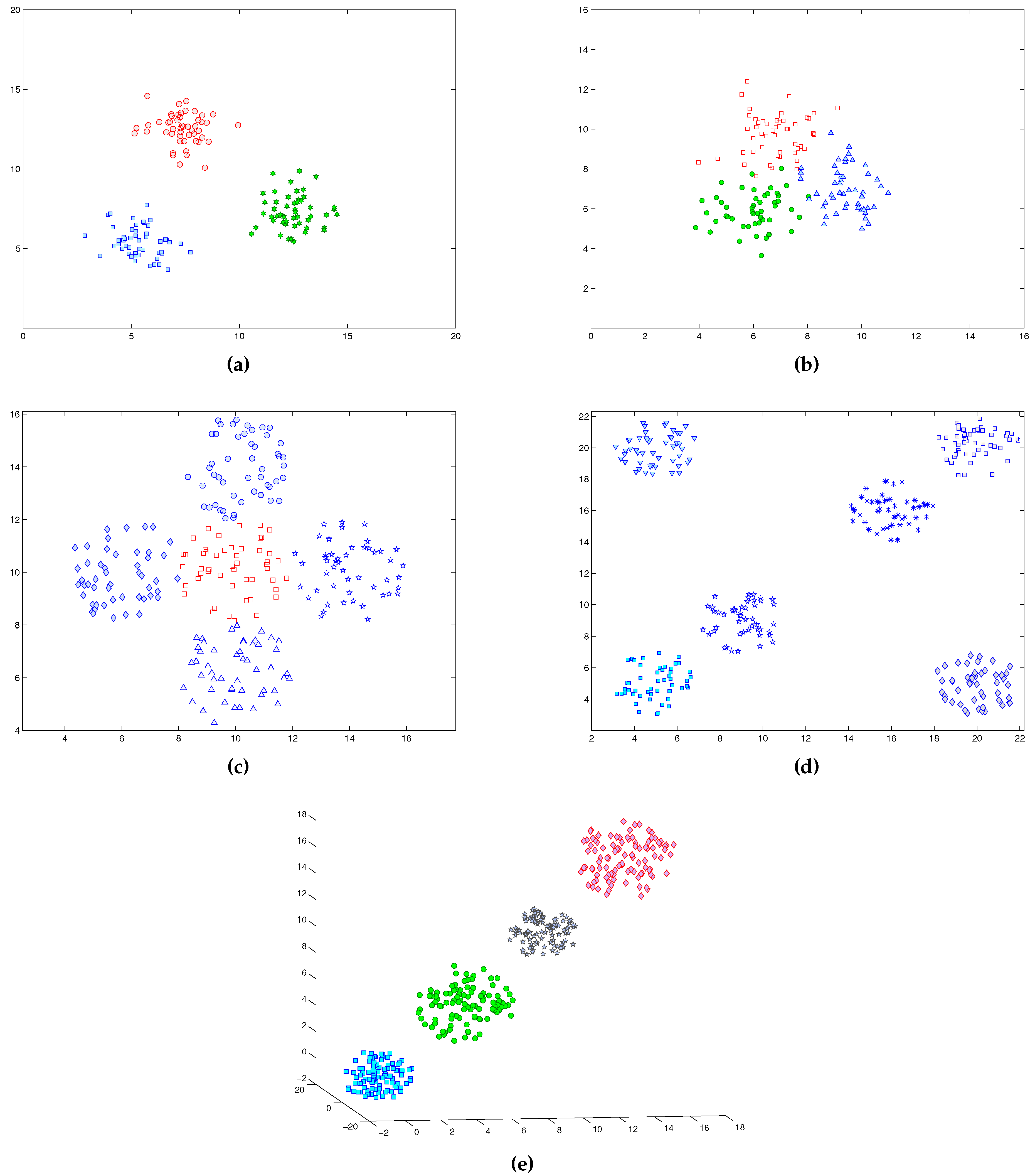
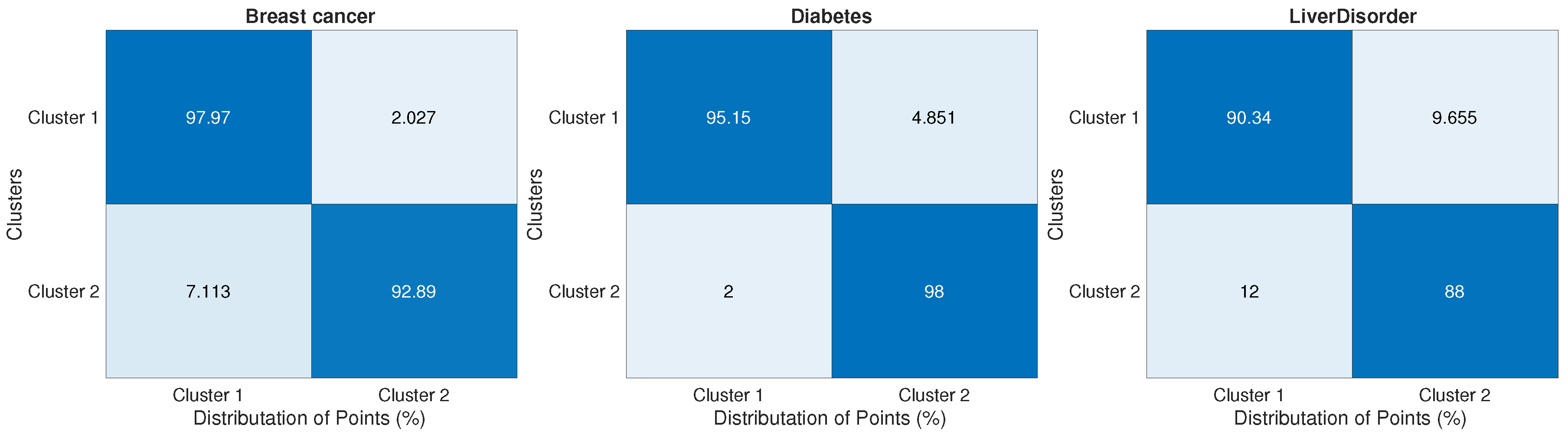
Finally, we present the cluster analysis figures to show how the proposed algorithm could distribute points over clusters.
Figure 9 and
Figure 10 show that for low dimensional datasets, while
Figure 11 illustrates the point distributions for big datasets. Those figures show the efficiency of the proposed method in assigning the right clusters for the majority of points in different datasets.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}