Incremental Learning for Classification of Unstructured Data Using Extreme Learning Machine


Abstract
:1. Introduction
2. Related Works
3. Methodology
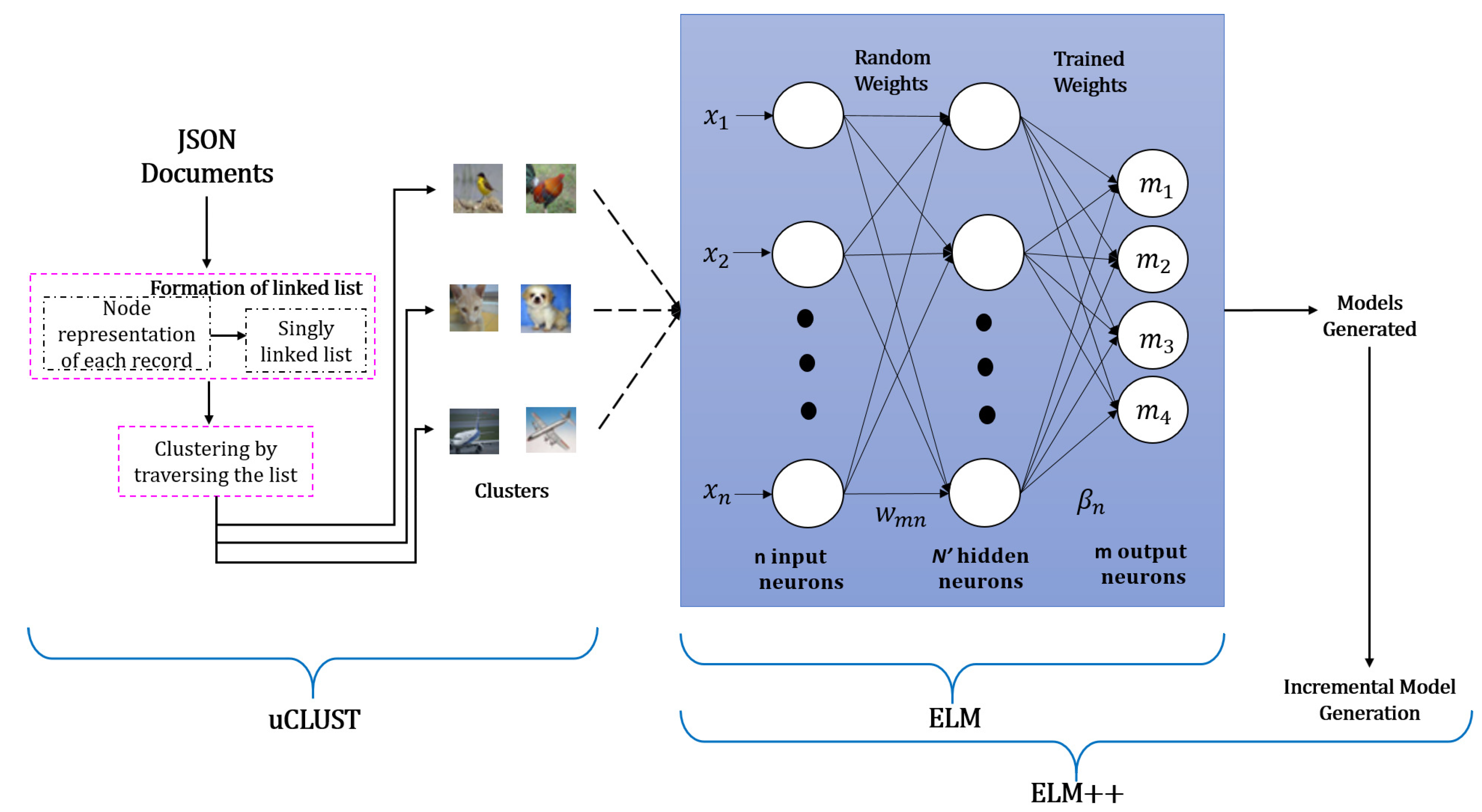
3.1. Architecture Description
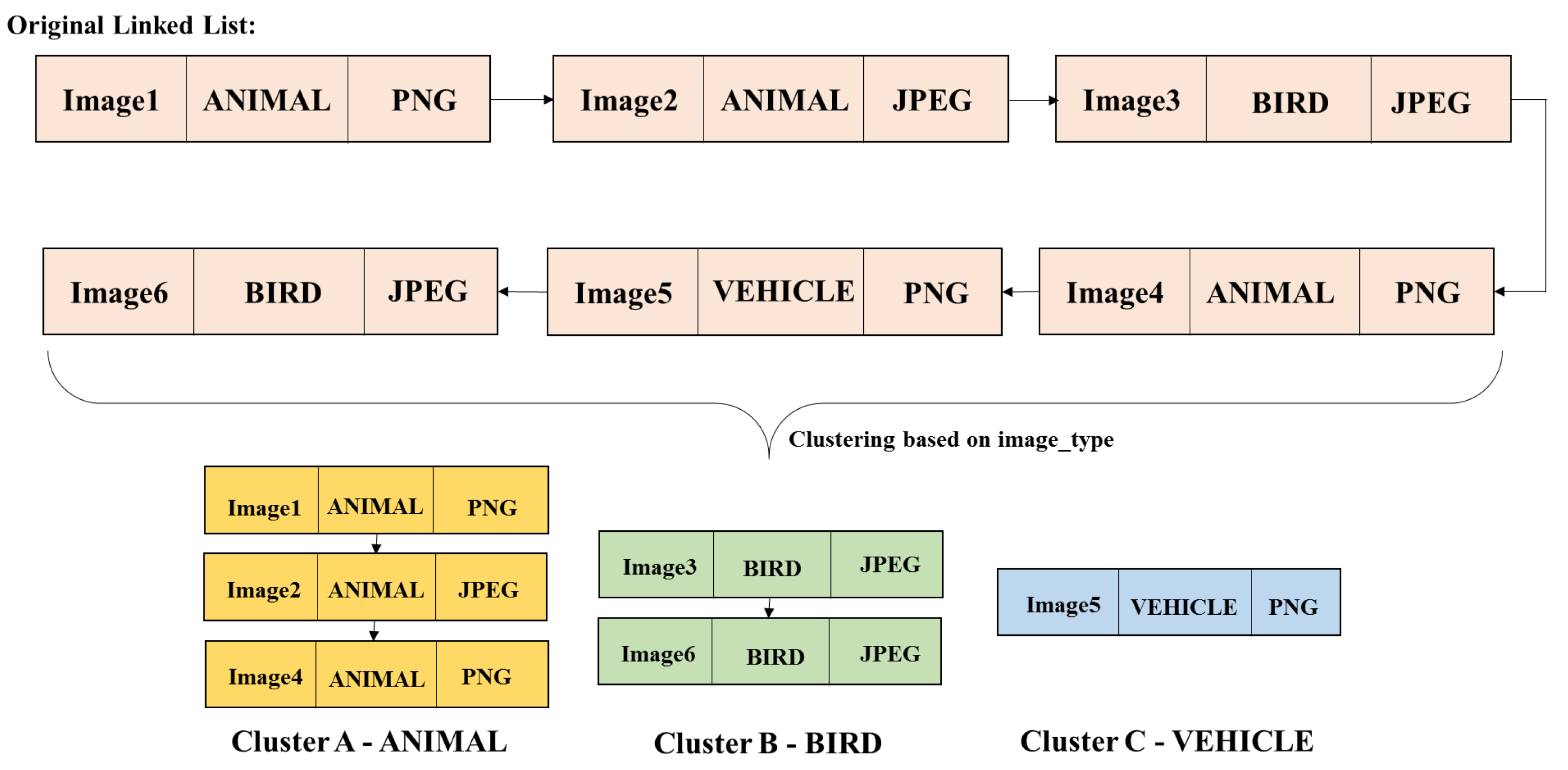
3.2. uCLUST
3.2.1. Algorithm of uCLUST
| Algorithm 1: Formation of the linked list. |
 |
| Algorithm 2: Clustering by traversing the linked list. |
 |
3.2.2. Illustrative Example
3.3. ELM++
| Algorithm 3: Extreme Learning Machine (ELM). |
| Input: Training set X with N images; n input neurons-image size: height x width; hidden neurons; m output neurons; Output: Model generated with parameters (output matrix (), weight matrix (W), bias (b)) 1. Input N distinct samples and an activation function , where are the input features (pixel intensities), and . 2. Generate random weights based on the number of hidden neurons used, which connects the input and hidden layer. 3. Calculate the output of the hidden layer using: 4. Calculate the output matrix for the output layer using the formula: |
| where |
| , |
| and |
3.3.1. Algorithm of ELM++
| Algorithm 4:ELM++: Incremental Model Generation. |
 |
| Algorithm 5:ELM++: Incremental testing. |
 |
3.3.2. Illustrative Example
| Algorithm 6:ELM++: Combining the classified results. |
 |
4. Results and Discussion
4.1. Dataset Description
4.2. Scenario 1
4.3. Scenario 2
4.4. Statistical Inference
4.5. Discussions
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Park, S.B.; Zhang, B.T. Co-trained support vector machines for large scale unstructured document classification using unlabeled data and syntactic information. Inf. Process. Manag. 2004, 40, 421–439. [Google Scholar] [CrossRef] [Green Version]
- Orru, G.; Pettersson-Yeo, W.; Marquand, A.F.; Sartori, G.; Mechelli, A. Using Support Vector Machine to identify imaging biomarkers of neurological and psychiatric disease: A critical review. Neurosci. Biobehav. Rev. 2012, 36, 1140–1152. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Rao, Y.; Jin, F.; Chen, H.; Xiang, X. Multi-label maximum entropy model for social emotion classification over short text. Neurocomputing 2016, 210, 247–256. [Google Scholar] [CrossRef]
- Xu, D.; Tian, Y. A comprehensive survey of clustering algorithms. Ann. Data Sci. 2015, 2, 165–193. [Google Scholar] [CrossRef]
- Bora, D.J.; Gupta, D.A.K. Effect of different distance measures on the performance of k-means algorithm: An experimental study in matlab. Int. J. Comput. Sci. Inf. Technol. 2014, 5, 2501–2506. [Google Scholar]
- Gepperth, A.; Hammer, B. Incremental learning algorithms and applications. In Proceedings of the European Symposium on Artificial Neural Networks, Computational Intelligence, and Machine Learning, Bruges, Belgium, 27–29 April 2016. [Google Scholar]
- Joshi, P.; Kulkarni, P. Incremental learning: Areas and methods-a survey. Int. J. Data Min. Knowl. Manag. Process. 2012, 2, 43–51. [Google Scholar] [CrossRef]
- Losing, V.; Hammer, B.; Wersing, H. Incremental on-line learning: A review and comparison of state of the art algorithms. Neurocomputing 2018, 275, 1261–1274. [Google Scholar] [CrossRef] [Green Version]
- Sarwar, S.S.; Ankit, A.; Roy, K. Incremental learning in deep convolutional neural networks using partial network sharing. arXiv, 2017; arXiv:1712.02719. [Google Scholar]
- He, H.; Chen, S.; Li, K.; Xu, X. Incremental learning from stream data. IEEE Trans. Neural Netw. 2011, 22, 1901–1914. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y.; Park, C.H. An efficient concept drift detection method for streaming data under limited labeling. IEICE Trans. Inf. Syst. 2017, 100, 2537–2546. [Google Scholar] [CrossRef]
- Prasad, D.V.; Madhusudhanan, S.; Jaganathan, S. uCLUST—A new algorithm for clustering unstructured data. ARPN J. Eng. Appl. Sci. 2015, 10, 2108–2117. [Google Scholar]
- Fontenla-Romero, O.; Perez-Sanchez, B.; Guijarro-Berdinas, B. An incremental non-iterative learning method for one-layer feedforward neural networks. Appl. Soft Comput. 2017, 70, 951–958. [Google Scholar] [CrossRef]
- Ding, S.; Zhao, H.; Zhang, Y.; Xu, X.; Nie, R. Extreme machine learning: Algorithm, theory and applications. Artif. Intell. Rev. 2013, 44, 103–115. [Google Scholar] [CrossRef]
- Huang, G.; Liu, T.; Yang, Y.; Lin, Z.; Song, S.; Wu, C. Discriminative clustering via extreme learning machine. Neural Netw. 2015, 70, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Krawczyk, B.; Minku, L.L.; Gama, J.; Stefanowski, J.; Wozniak, M. Ensemble learning for data stream analysis: A survey. Inf. Fusion 2017, 37, 132–156. [Google Scholar] [CrossRef]
- Zang, W.; Zhang, P.; Zhou, C.; Guo, L. Comparative study between incremental and ensemble learning on data streams: Case study. J. Big Data 2014. [Google Scholar] [CrossRef]
- Haixiang, G.; Yijing, L.; Shang, J.; Mingyun, G.; Yuanyue, H.; Bing, G. Learning from class-imbalanced data: Review of methods and applications. Expert. Syst. Appl. 2017, 73, 220–239. [Google Scholar] [CrossRef]
- Jain, S.; Lange, S.; Zilles, S. Towards a better understanding of incremental learning. Algorithmic Learn. Theory 2006, 4264, 169–183. [Google Scholar]
- Liu, Y. Incremental Learning in Deep Neural Networks. Master of Science Thesis, Tampere University of Technology, Tampere, Finland, 2015. [Google Scholar]
- Ade, R.R.; Deshmukh, P.R. Methods for incremental learning: A survey. Int. J. Data Min. Know. Manag. Process. 2013, 3, 119–125. [Google Scholar] [CrossRef]
- Rajbabu, K.; Srinivas, H.; Sudha, S. Industrial information extraction through multi-phase classification using ontology for unstructured documents. Comput. Ind. 2018, 100, 137–147. [Google Scholar]
- Ienco, D.; Pensa, R.G. Positive and unlabeled learning in categorical data. Neurocomputing 2016, 96, 113–124. [Google Scholar] [CrossRef] [Green Version]
- Raghuwanshi, B.S.; Shukla, S. Class-specific extreme learning machine for handling binary class imbalance problem. Neural Netw. 2018, 105, 206–217. [Google Scholar] [CrossRef] [PubMed]
- Mirza, B.; Lin, Z. Meta-cognitive online sequential extreme learning machine for imbalanced and concept-drifting data classification. Neural Netw. 2016, 80, 79–94. [Google Scholar] [CrossRef] [PubMed]
- Zhong, J.; Liu, Z.; Zeng, Y.; Cui, L.; Ji, Z. A survey on incremental learning. In Proceedings of the 5th International Conference on Computer, Automation and Power Electronics, Colombo, Sri Lanka, 25–27 Feburary 2017. [Google Scholar]
- Wang, J.H.; Wang, H.Y.; Chen, Y.L.; Liu, C.M. A constructive algorithm for unsupervised learning with incremental neural network. J. Appl. Res. Technol. 2015, 13, 188–196. [Google Scholar] [CrossRef]
- Huang, G.; Huang, G.B.; Song, S.; You, K. Trends in extreme learning machines: A review. Neural Netw. 2014, 61, 32–48. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Yang, L.; Du, J.; Sun, C.; Du, S.; Xi, H. An extreme learning machine architecture based on volterra filtering and pca. IEICE Trans. Inf. Syst. 2017, 100, 2690–2701. [Google Scholar] [CrossRef]
- Zhao, J.; Wang, Z.; Park, D.S. Online sequential extreme learning machine without forgetting mechanism. Neurocomputing 2012, 87, 79–89. [Google Scholar] [CrossRef]
- Polikar, R.; Udpa, L.; Udpa, S.S.; Honavar, V. Learn++: An incremental learning algorithm for supervised neural networks. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2001, 31, 497–508. [Google Scholar] [CrossRef]
- Jinyin, C.; Huihao, H.; Jungan, C.; Shanqing, Y.; Zhaoxia, S. Fast Density Clustering Algorithm for Numerical Data and Categorical Data. Math. Probl. Eng. 2017, 2017, 1–15. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S.No. | Title | Author | Year | Insights | Remarks |
|---|---|---|---|---|---|
| 1 | Ensemble learning for data stream analysis: A survey | Krawczyk B, et al. | 2017 | Provides a survey on different types of ensemble learning for the analysis of data streams. | Survey Paper in which some research problems like gradual drifts, handling delayed information and big data not addressed. |
| 2 | Learning from class-imbalanced data: Review of methods and applications | Haixiang G., et al. | 2017 | Survey paper about class-imbalanced methods. | Survey Paper |
| 3 | Towards a better understanding of incremental learning | Jain S, et al. | 2006 | Provides insights on requirements like consistency and conservativeness for incremental learning. | Survey Paper |
| 4 | Industrial information extraction through multi-phase classification using ontology for unstructured documents | Rajbabu K, et al. | 2018 |
| Some issues to be addressed are the precision loss and improvement in execution time. |
| 5 | Positive and unlabeled learning in categorical data | Ienco D., et al. | 2016 |
| Multi-class classification problems is yet to be addressed by Pulce. |
| 6 | Class-specific extreme learning machine for handling binary class imbalance problem | Raghuwanshi B S, et al. | 2018 |
| Multi-class classification problems is yet to be addressed. |
| 7 | Meta-cognitive online sequential extreme learning machine for imbalanced and concept-drifting data classification | Mirza B, et al. | 2016 | Algorithm proposed for learning muti-class imbalance and concept drift problems by using an adaptive window scheme. | Class imbalance problems in data streams is yet to be addressed by MOS-ELM when minority and majority classes gets added over time. |
| Title | Method | Datasets Used | Supports Concept Drift | Parameters Considered | Issues (Future Work) |
|---|---|---|---|---|---|
| Industrial information extraction through multi-phase classification using ontology for unstructured documents | Decision Trees, Naive Bayes, SVM | Unstructured documents | NO | accuracy | precision loss, performance time |
| Positive and unlabeled learning in categorical data | k-NN | Categorical dataset (UCI Machine Learning Repository) | NO | accuracy | Multi-class |
| Class-specific extreme learning machine for handling binary class imbalance problem | ELM | Binary dataset (KEEL dataset) | NO | accuracy | Multi-class |
| Meta-cognitive online sequential extreme learning machine for imbalanced and concept-drifting data classification | ELM | Binary and multi-class datasets | YES | accuracy | Class imbalance over time. |
| Proposed work (CUIL) | ELM | Binary and multi-class datasets | NO | accuracy, performance time | Concept drift |
| S. No. | Dataset | Number of Classes | Number of Images Per Class | Total Number |
|---|---|---|---|---|
| 1 | MNIST | 10 | 2000 | 20000 |
| 2 | STL-10 | 10 | 1300 | 13000 |
| 3 | CIFAR-10 | 10 | 6000 | 60000 |
| 4 | Caltech101 | 101 | 40 | 4040 |
| 5 | Caltech256 | 256 | 119 | 30607 |
| Set | Training | Incre. Testing | ||
|---|---|---|---|---|
| Accuracy (%) | ||||
| Learn++ | ELM++ | Learn++ | ELM++ | |
| S1 (0–9) | 94.2 | 92 | 82 | 72 |
| S2 (0–9) | 93.5 | 90 | 84.7 | 78.2 |
| S3 (0–9) | 95 | 90 | 89.7 | 85.3 |
| S4 (0–9) | 93.5 | 92 | 91.7 | 88 |
| S5 (0–9) | 95 | 96 | 92.2 | 90.8 |
| S6 (0–9) | 95 | 96 | 92.7 | 94 |
| Attribute | No. of | Model No. | Test | Accuracy (%) | |
|---|---|---|---|---|---|
| Used for Clustering | Clusters Formed | (No. of Clusters) | Set | Training | Incre. Test |
| format | 2 | M1(1) | 1, 2 | 99 | 97.75 |
| M2(1) | 96.5 | ||||
| image_type | 4 | M1(2) | 1, 2, 3, 4 | 97 | 93.3 |
| M2(1) | 93 | ||||
| M3(1) | 90.75 | ||||
| image_type, format | 8 | M1(4) | 1, 2, 3, 4, 5, 6, 7, 8 | 95.75 | 94.2 |
| M2(2) | 98 | ||||
| M3(2) | 90.75 | ||||
| Attribute Used for Clustering | No. of Clusters Formed | Model No. (No. of Clusters) | Test Set | uCLUST— Clustering Time(secs) | Time Taken(secs) | |
|---|---|---|---|---|---|---|
| Training (ELM++) | Incre. Test | |||||
| format | 2 | M1(1) | 1,2 | 9 | 16.45 | 8.86 |
| M2(1) | 15.9 | |||||
| image_type | 4 | M1(2) | 1,2,3,4 | 13 | 12.78 | 6.35 |
| M2(1) | 11.89 | |||||
| M3(1) | 12.05 | |||||
| image_type, format | 8 | M1(4) | 1, 2, 3, 4, 5, 6, 7, 8 | 22 | 12.35 | 6.11 |
| M2(2) | 11.34 | |||||
| M3(2) | 11.96 | |||||
| Set No. | S1 | S2 | S3 | S4 | S5 | S6 |
|---|---|---|---|---|---|---|
| d | 8 | 2.75 | 0.1 | 2.07 | 3.4 | 0.7 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Madhusudhanan, S.; Jaganathan, S.; L S, J. Incremental Learning for Classification of Unstructured Data Using Extreme Learning Machine. Algorithms 2018, 11, 158. https://doi.org/10.3390/a11100158
Madhusudhanan S, Jaganathan S, L S J. Incremental Learning for Classification of Unstructured Data Using Extreme Learning Machine. Algorithms. 2018; 11(10):158. https://doi.org/10.3390/a11100158
Chicago/Turabian StyleMadhusudhanan, Sathya, Suresh Jaganathan, and Jayashree L S. 2018. "Incremental Learning for Classification of Unstructured Data Using Extreme Learning Machine" Algorithms 11, no. 10: 158. https://doi.org/10.3390/a11100158
APA StyleMadhusudhanan, S., Jaganathan, S., & L S, J. (2018). Incremental Learning for Classification of Unstructured Data Using Extreme Learning Machine. Algorithms, 11(10), 158. https://doi.org/10.3390/a11100158