Distributed Combinatorial Maps for Parallel Mesh Processing


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Preliminary Notions
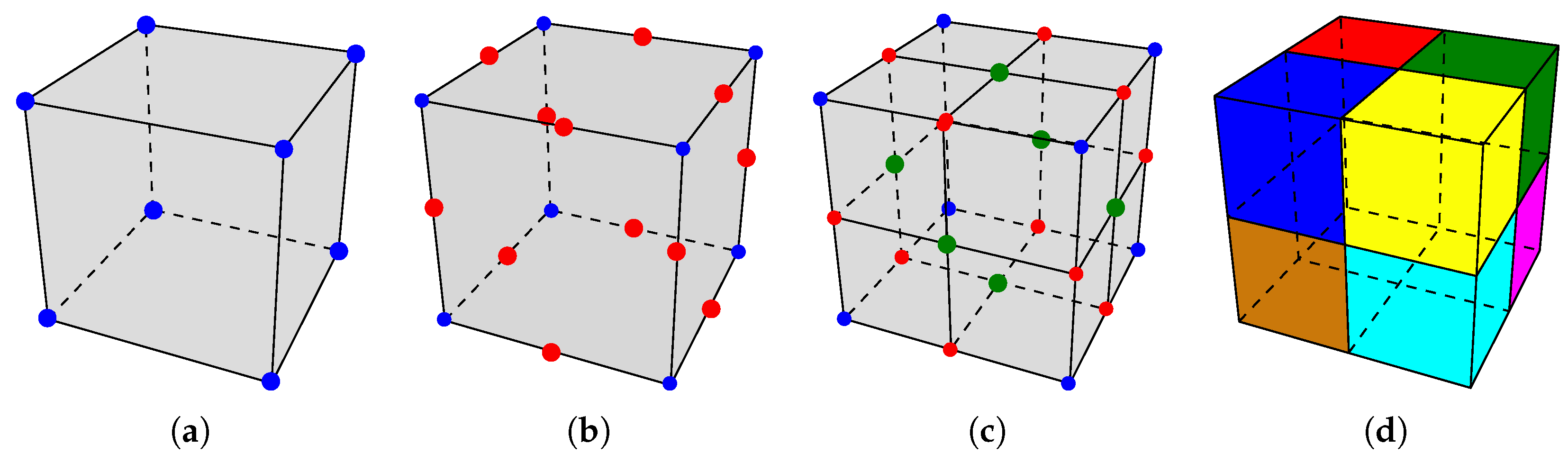
2.1. nD Combinatorial Map
- gives the dart after d that belongs to the same j-cells as the j-cells of d, for all ;
- , with , gives the dart different from d that belongs to the same j-cells as the j-cell of d, for all , .
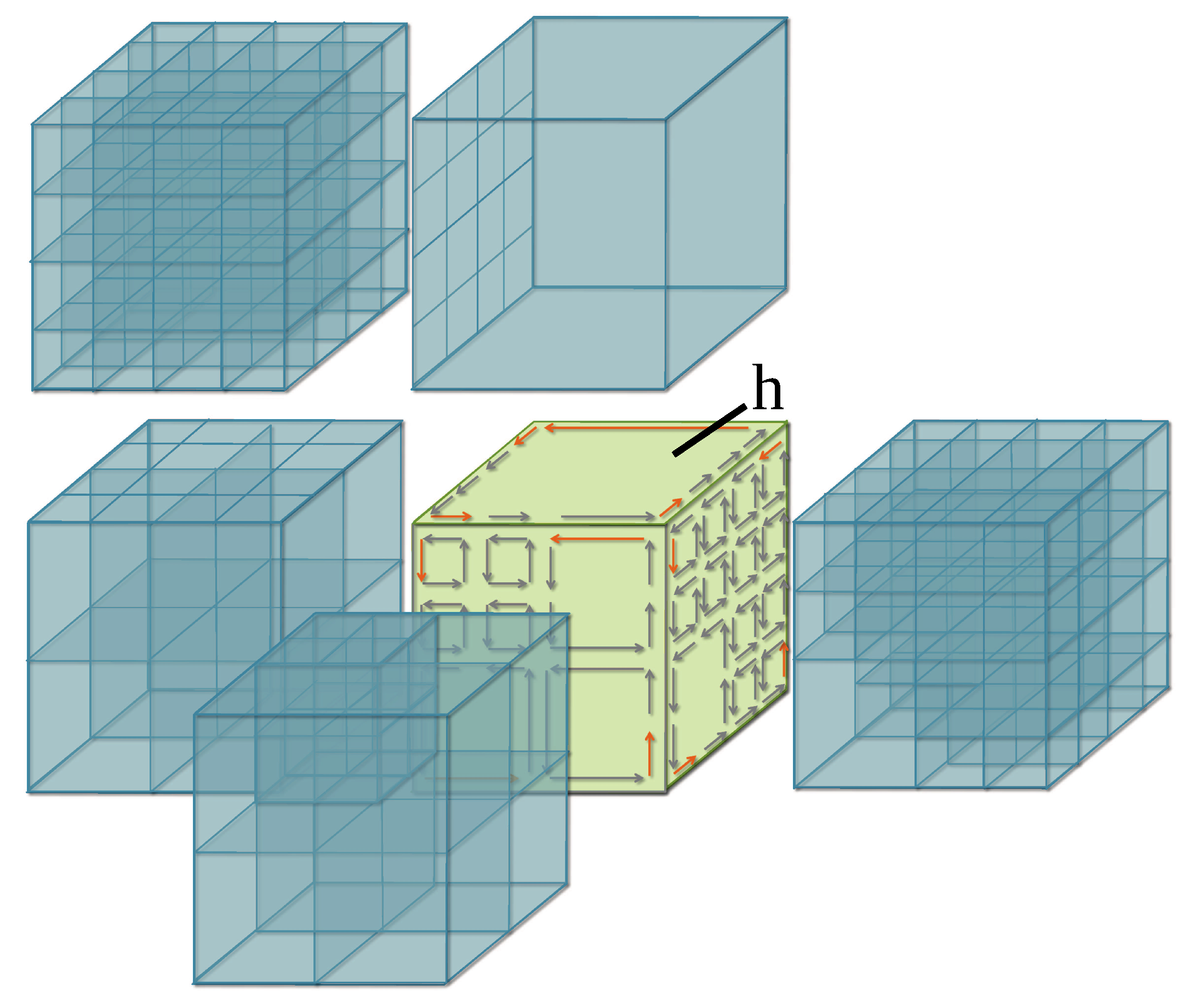
2.2. Adaptive Hexahedral Subdivision
3. nD Distributed Combinatorial Maps
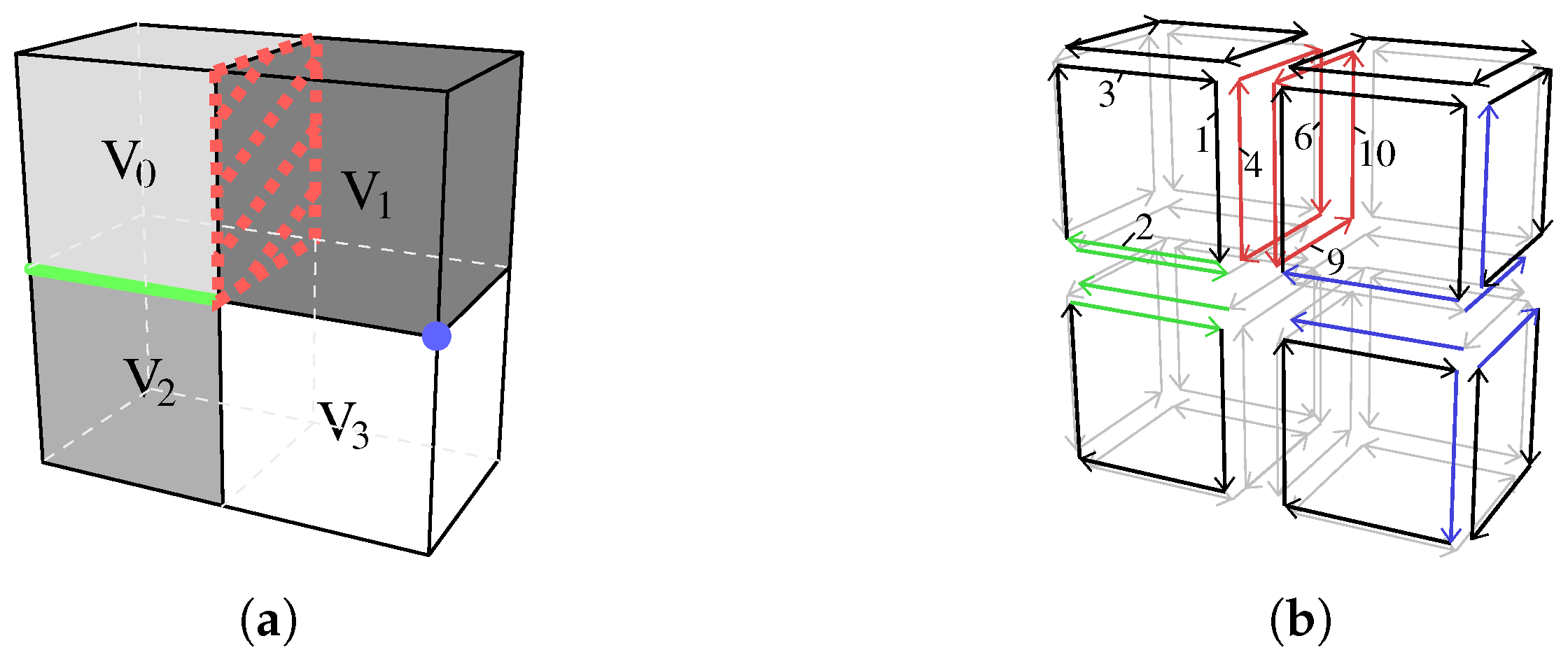
3.1. Definition of nD Distributed Combinatorial Maps
- 1.
- must be a set of complete -cells, i.e., , all the darts of the -cell containing d must belong to ;
- 2.
- each dart in belongs to the border of , i.e., , d isn-free;
- 3.
- for each critical dart d in , there is exactly one critical dart in , with , such that . For all other critical darts in any block z, ;
- 4.
- for each pair of critical darts in blocks and such that : , .
- Property (1) can be verified as all critical darts of form complete faces of their block.
- Property (2) can be verified as all critical darts of belong to the border of their block; each one corresponds to one face in M which is split in two in .
- Property (3) can be verified by checking that all critical darts that were linked by in M have the same label in , and we can verify that other pairs of critical darts have different labels.
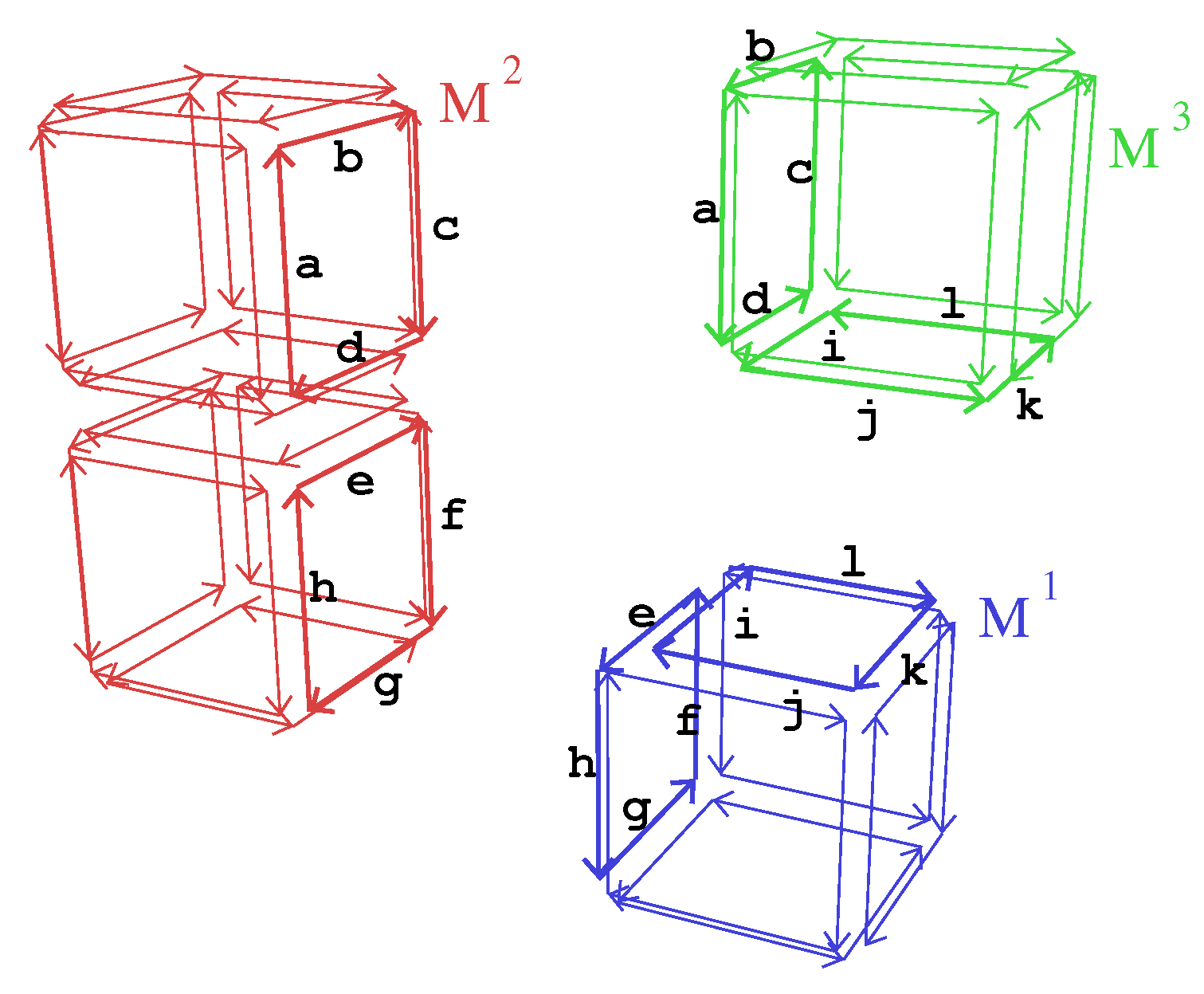
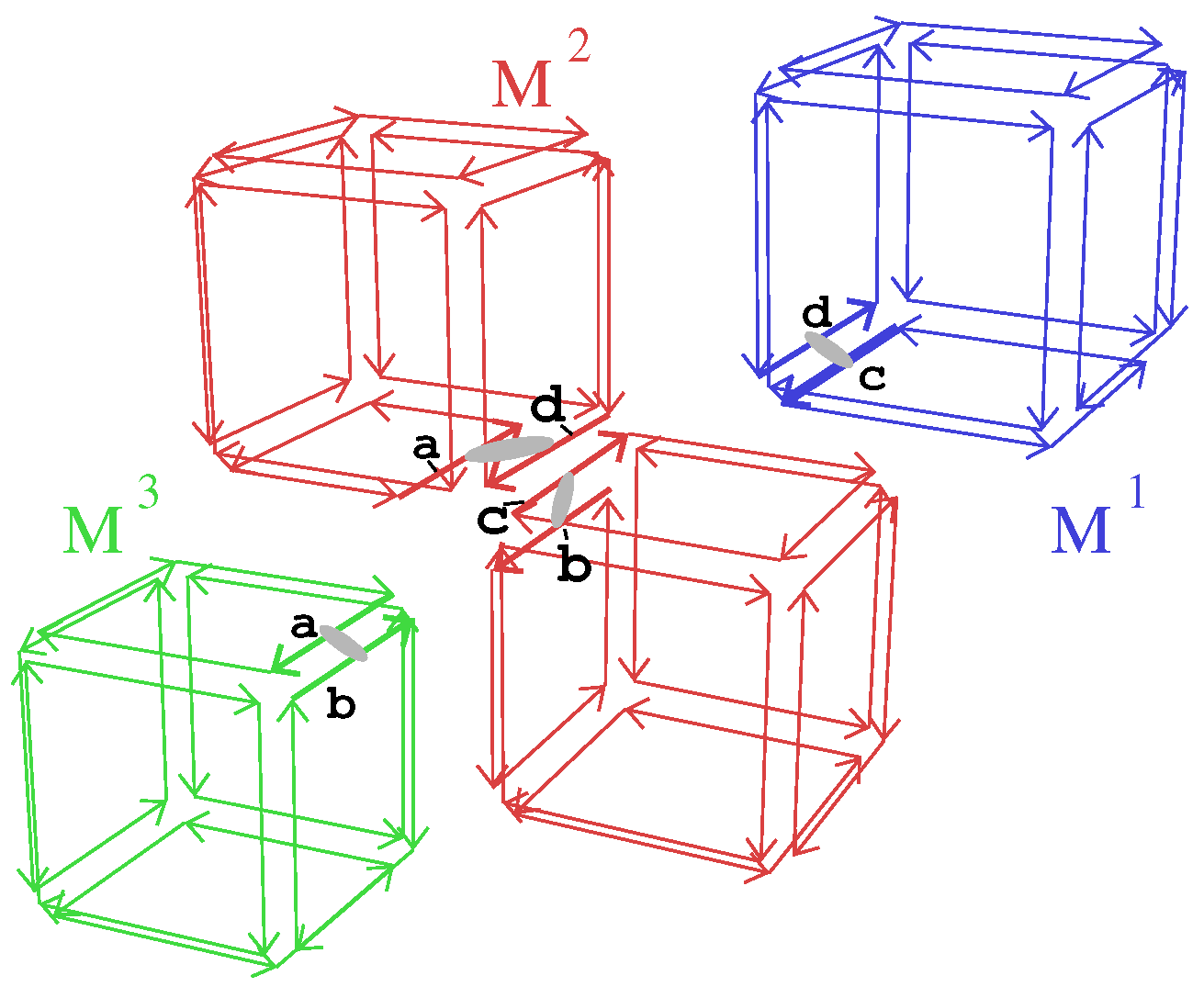
- Property (4) ensures that critical darts are labeled in a coherent way between the different blocks. In our example, critical darts of the top cube in block are labeled a, b, c, and d. Corresponding darts in block are also labeled a, b, c, and d. Starting from dart d labeled a in block and dart with the same label in block , we can check that darts and have the same label b. Step by step, this ensures the coherent labeling of all the darts of the two faces.
3.2. Retrieve Information Inside nD Distributed Combinatorial Maps
- 1.
- 2.
- , , : ;
- 3.
- , : ;
- 4.
- , , let denote the dart in such that , , . Then, .
3.3. A Data Structure for Storing nD Distributed Combinatorial Maps
- each critical dart is marked with a Boolean mark, and stores its label;
- one associative array gives for each label used in this block the critical dart d of with this label.
3.4. Extensions and Discussion
4. A Parallel Algorithm of Mesh Processing Based on 3-dmaps
4.1. Generic Parallel Algorithm
| Algorithm 1: Hexahedral mesh refinement of a given block. |
 |
- split the four edges of f (line 5):
- -
- this splits the four critical darts labeled a, …, d;
- -
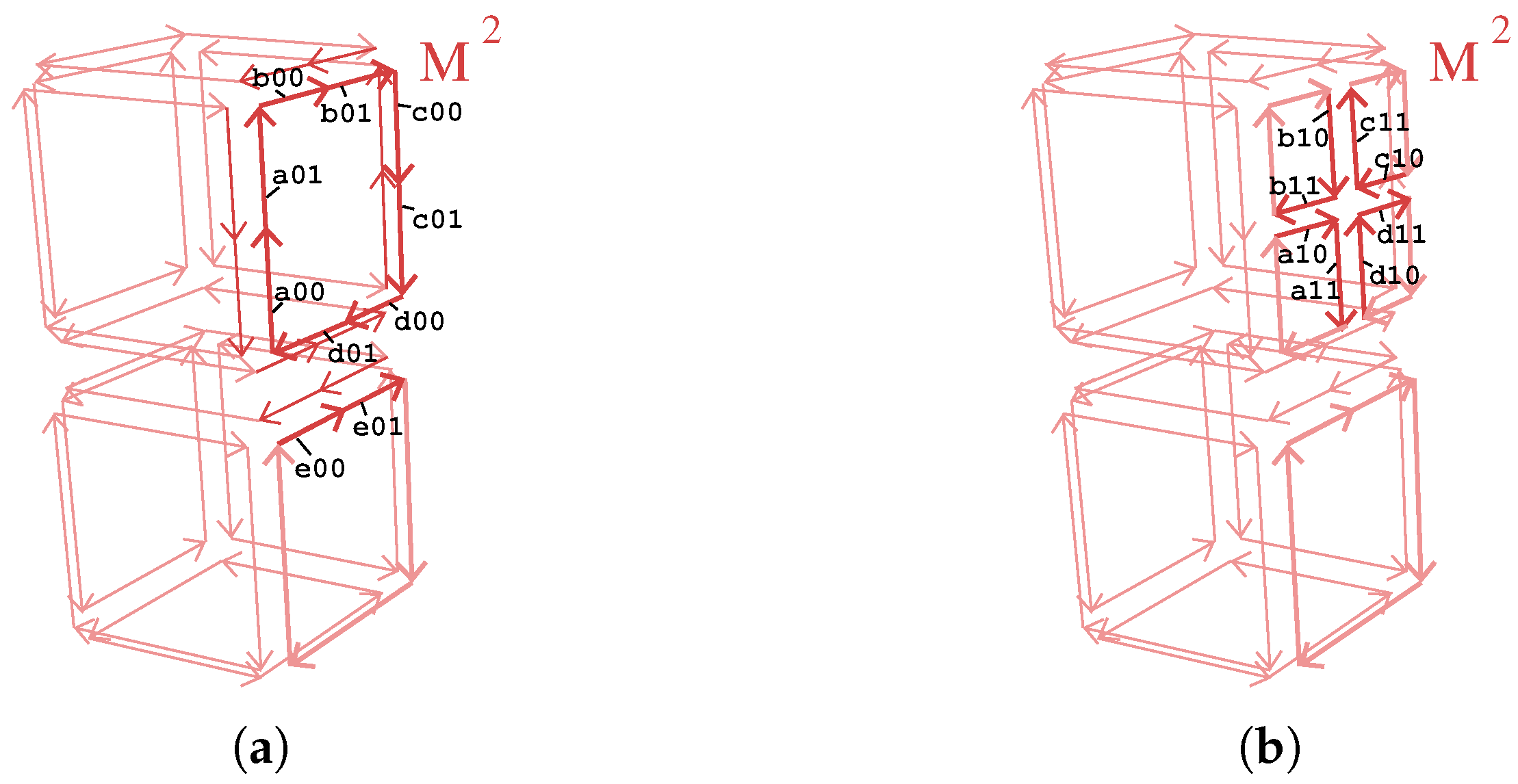
- the old darts are relabeled a00, …, d00 (line 9, cf. Figure 6a);
- -
- the new darts are labeled a01, …, d01 (line 10, cf. Figure 6a);
- -
- four messages are sent (line 8) in order to split also the corresponding edges in cluster (which is mandatory in order to preserve the global validity of the 3-dmap);
- split f in four (line 14):
- -
- the four corner darts of f are critical (by definition they are either all or none critical);
- -
- the message “split face” with the labels of the four corner darts as parameter is sent to , the other block containing the critical darts. This guarantees that each face matches in both blocks (line 16);
- -
- new darts created during the split of face f are all critical and are labeled in a unique way by using the label of the original darts of f (line 17, cf. Figure 6b to see how this labeling is done).
| Algorithm 2: Receive and handle all the messages of a given block. |
 |
4.2. Message Passing
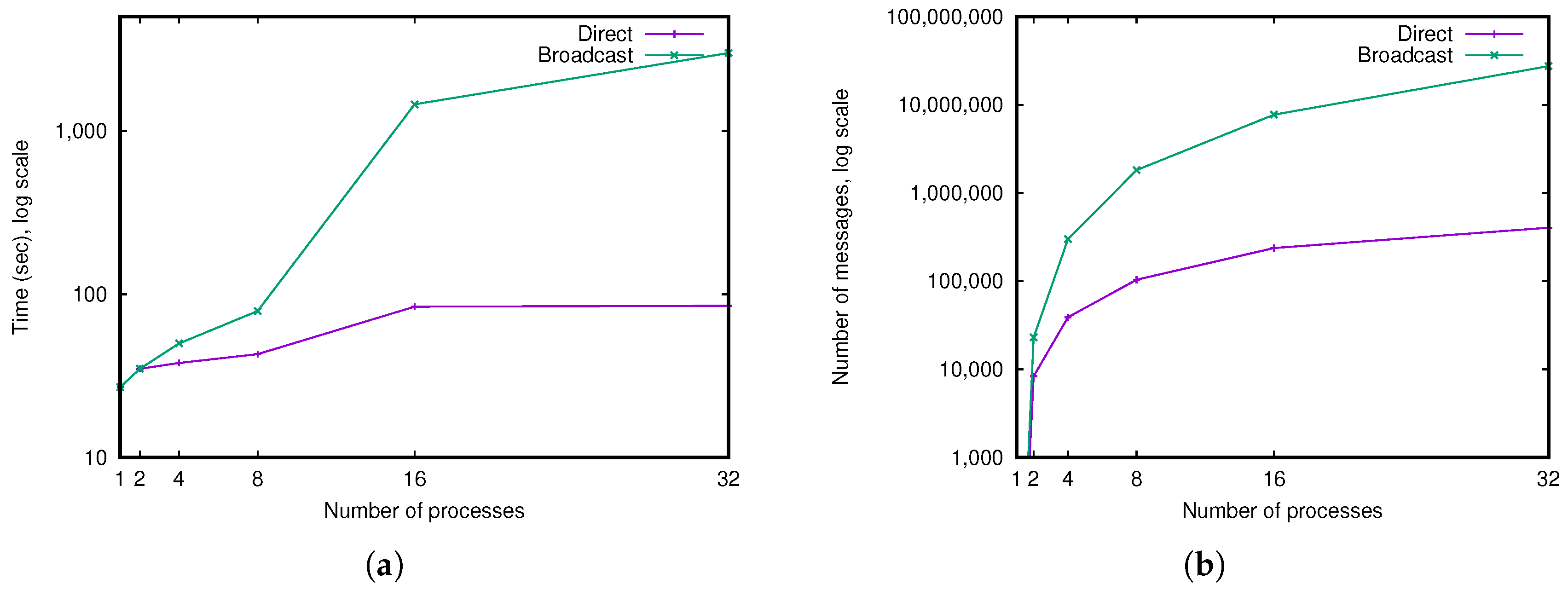
- If we broadcast messages, each message is sent to all tasks. When receiving a message, a task must first test if it is concerned by the message or not. This test is achieved by searching the critical dart in the associative array of critical darts. Since this test must be done anyway (to know if the cell was already subdivided or not, cf. lines 3 and 11 in Algorithm 2), there is no overhead in complexity. The only additional cost is due to the communication: many messages could be exchanged.
- If we do not broadcast messages, we use the possibility introduced in Section 3.3 where each critical dart stores the number of the other block containing this critical dart. With this number, it is then possible to directly send a message to the concerned block. In this case, the number of messages sent is smaller, but there is a small overhead in memory space to store these block numbers.
5. Experiments
5.1. Choice of the Communication Method
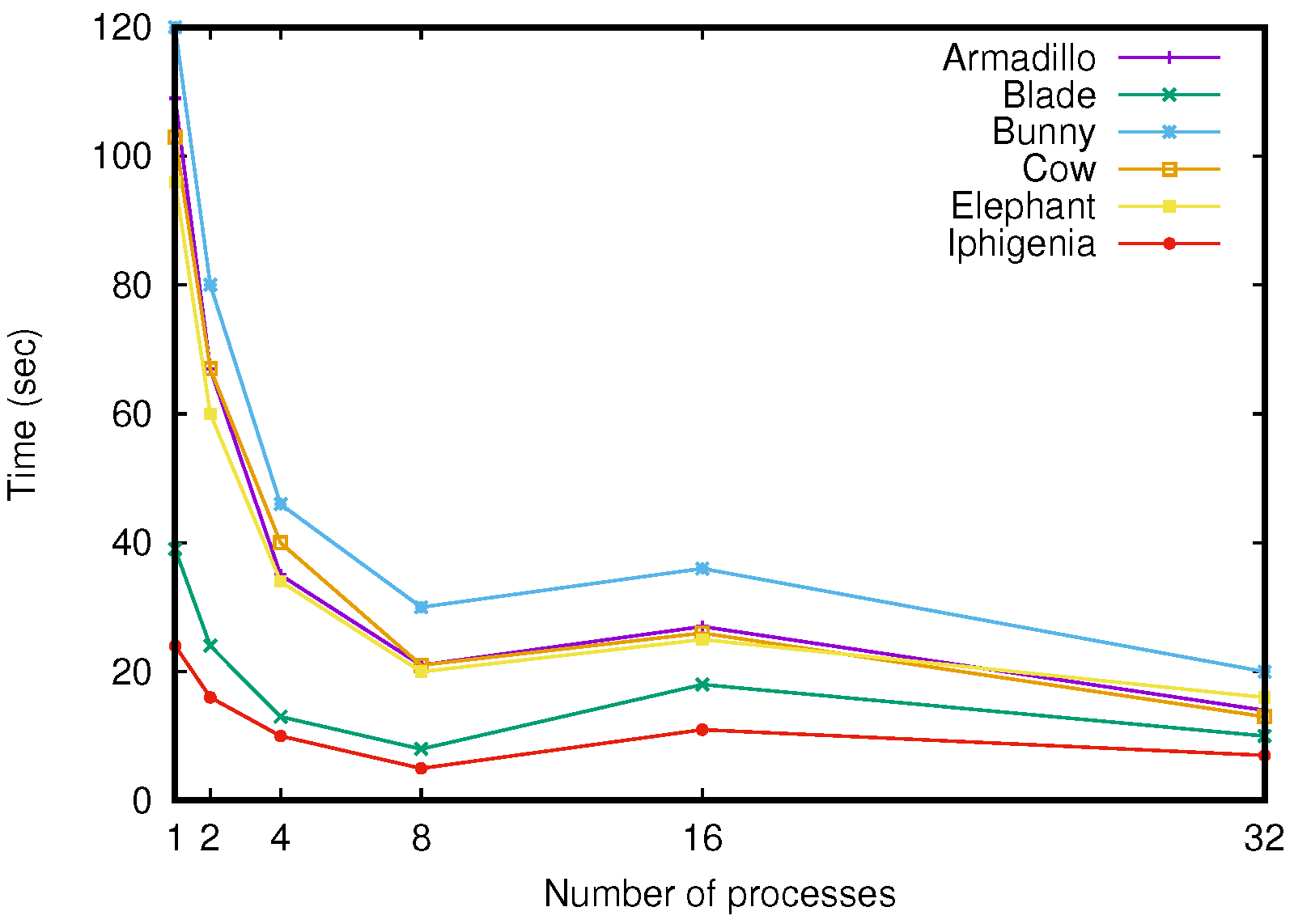
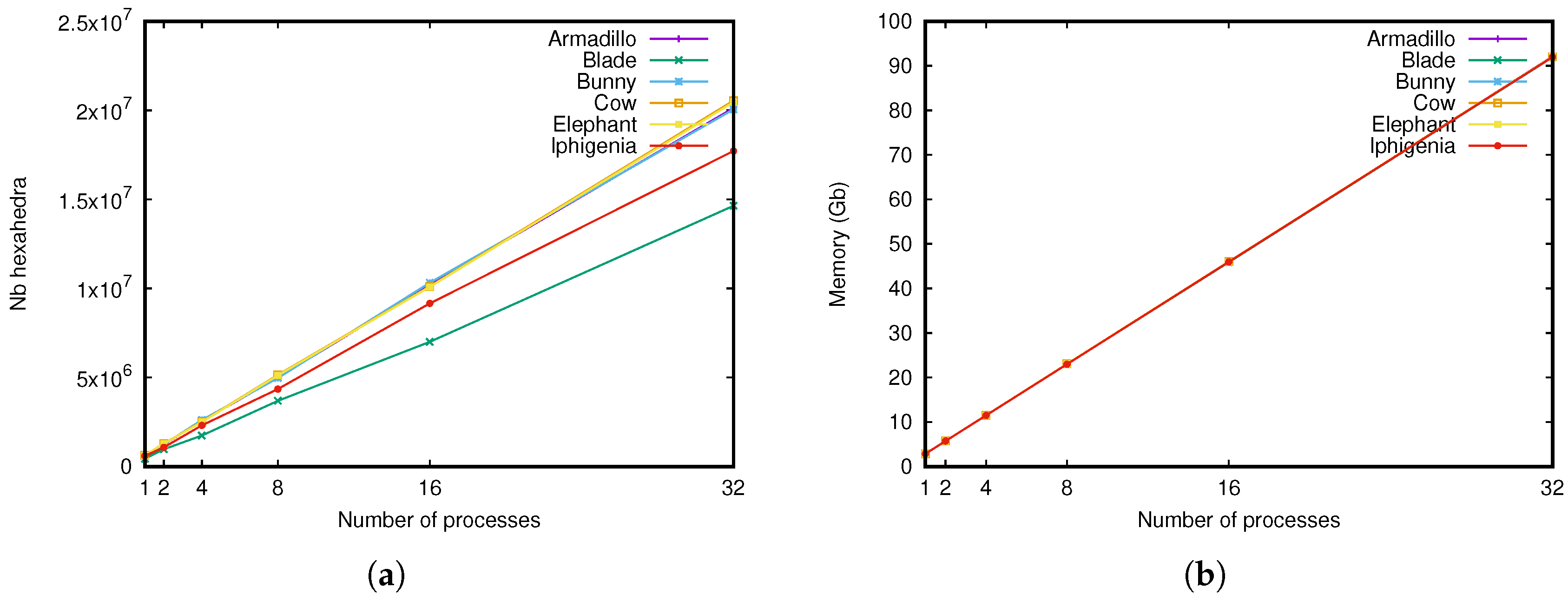
5.2. Comparison in Computation Time
5.3. Comparison in Memory Space
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Botsch, M.; Kobbelt, L.; Pauly, M.; Alliez, P.; Levy, B. Polygon Mesh Processing; AK Peters: Natick, MA, USA, 2010. [Google Scholar]
- Bajaj, C.L.; Schaefer, S.; Warren, J.D.; Xu, G. A subdivision scheme for hexahedral meshes. Vis. Comput. 2002, 18, 343–356. [Google Scholar] [CrossRef] [Green Version]
- Wu, J.; Westermann, R.; Dick, C. Physically-Based Simulation of Cuts in Deformable Bodies: A Survey; Eurographics (State of the Art Reports); Eurographics Association: Hoboken, NJ, USA, 2014; pp. 1–19. [Google Scholar]
- Döllner, J.; Buchholz, H. Continuous Level-of-detail Modeling of Buildings in 3D City Models. In Proceedings of the 13th GIS ’05 Annual ACM International Workshop on Geographic Information Systems, Bremen, Germany, 4–5 November 2005; ACM: New York, NY, USA, 2005; pp. 173–181. [Google Scholar]
- Sharir, M. Arrangements in higher dimensions: Voronoi diagrams, motion planning, and other applications. In Algorithms and Data Structures; Akl, S.G., Dehne, F., Sack, J.R., Santoro, N., Eds.; Springer: Berlin/Heidelberg, Germany, 1995; pp. 109–121. [Google Scholar]
- Arroyo Ohori, K.; Ledoux, H.; Stoter, J. Modelling and manipulating spacetime objects in a true 4D model. J. Spat. Inf. Sci. 2017, 14, 61–93. [Google Scholar]
- Liu, J.; Zhang, X.; Zhang, X.; Zhao, H.; Gao, Y.; Thomas, D.; Low, D.A.; Gao, H. 5D respiratory motion model based image reconstruction algorithm for 4D cone-beam computed tomography. Inverse Probl. 2015, 31, 115007. [Google Scholar] [CrossRef]
- Baumgart, B.G. A polyhedron representation for computer vision. In Proceedings of the American Federation of Information Processing Societies: 1975 National Computer Conference, Anaheim, CA, USA, 19–22 May 1975; pp. 589–596. [Google Scholar]
- Weiler, K. Edge-based data structures for solid modelling in curved-surface environments. Comput. Graph. Appl. 1985, 5, 21–40. [Google Scholar] [CrossRef]
- Mäntylä, M. An Introduction to Solid Modeling; Computer Science Press: New York, NY, USA, 1988. [Google Scholar]
- De Berg, M. Computational Geometry: Algorithms and Applications, 2nd ed.; Springer: Berlin, Germany, 2000. [Google Scholar]
- Guibas, L.J.; Stolfi, J. Primitives for the Manipulation of General Subdivisions and Computation of Voronoi Diagrams. ACM Trans. Graph. 1985, 4, 74–123. [Google Scholar] [CrossRef]
- Weiler, K. The radial edge structure: A topological representation for non-manifold geometric boundary modeling. In Geometric Modeling for CAD Applications; Elsevier Science: New York, NY, USA, 1988; pp. 217–254. [Google Scholar]
- Rossignac, J. 3D Compression Made Simple: Edgebreaker with Zip&Wrap on a Corner-Table. In Proceedings of the 2001 International Conference on Shape Modeling and Applications (SMI 2001), Genoa, Italy, 7–11 May 2001; p. 278. [Google Scholar]
- Edmonds, J. A Combinatorial Representation for Polyhedral Surfaces. Not. Am. Math. Soc. 1960, 7, 646. [Google Scholar]
- Tutte, W. A census of planar maps. Canad. J. Math. 1963, 15, 249–271. [Google Scholar] [CrossRef]
- Jacques, A. Constellations et graphes topologiques. Proc. Comb. Theory Appl. 1970, 2, 657–673. [Google Scholar]
- Ringel, G. Map Color Theorem; Springer: Berlin, Germany, 1974. [Google Scholar]
- Dobkin, D.; Laszlo, M. Primitives for the Manipulation of Three-Dimensional Subdivisions. In Proceeding of the Symposium on Computational Geometry, Waterloo, ON, Canada, 8–10 June 1987; pp. 86–99. [Google Scholar]
- Lopes, H.; Tavares, G. Structural Operators for Modeling 3-manifolds. In Proceeding of the ACM Symposium on SMA ’97 Solid Modeling and Applications, Atlanta, GA, USA, 14–16 May 1997; ACM: New York, NY, USA, 1997; pp. 10–18. [Google Scholar]
- Kremer, M.; Bommes, D.; Kobbelt, L. OpenVolumeMesh - A Versatile Index-Based Data Structure for 3D Polytopal Complexes. In Proceeding of the of 21st International Meshing Roundtable; Jiao, X., Weill, J.C., Eds.; Springer: Berlin, Germany, 2012; pp. 531–548. [Google Scholar]
- Dyedov, V.; Ray, N.; Einstein, D.R.; Jiao, X.; Tautges, T.J. AHF: Array-based half-facet data structure for mixed-dimensional and non-manifold meshes. Eng. Comput. Lond. 2015, 31, 389–404. [Google Scholar] [CrossRef]
- Edelsbrunner, H. Algorithms in Combinatorial Geometry. In EATCS Monographs on Theoretical Computer Science; Brauer, W., Rozenberg, G., Salomaa, A., Eds.; Springer: Berlin, Germany, 1987. [Google Scholar]
- Rossignac, J.; O’Connor, M. SGC: A Dimension-Independant Model for Pointsets with Internal Structures and Incomplete boundaries. In Proceedings of the Geometric Modeling for Product Engineering: Selected and Expanded Papers from the IFIP WG 5.2/NSF Working Conference on Geometric Modeling, Rensselaerville, NY, USA, 18–22 September 1989; pp. 145–180. [Google Scholar]
- Lienhardt, P. N-Dimensional Generalized Combinatorial Maps and Cellular Quasi-Manifolds. Int. J. Comput. Geometry Appl. 1994, 4, 275–324. [Google Scholar] [CrossRef]
- Damiand, G.; Lienhardt, P. Combinatorial Maps: Efficient Data Structures for Computer Graphics and Image Processing; AK Peters: Natick, MA, USA; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Damiand, G. Combinatorial Maps. In CGAL User and Reference Manual, 3.9th ed.; CGAL Editorial Board, 2011; Available online: http://www.cgal.org/Pkg/CombinatorialMaps (accessed on 12 July 2018).
- Fléchon, E.; Zara, F.; Damiand, G.; Jaillet, F. A Unified Topological-Physical Model for Adaptive Refinement. In Proceedings of the 11th Workshop on Virtual Reality Interaction and Physical Simulation (VRIPHYS), Bremen, Germany, 24–25 September 2014; The Eurographics Association: Bremen, Germany, 2014; pp. 39–48. [Google Scholar]
- Kraemer, P.; Untereiner, L.; Jund, T.; Thery, S.; Cazier, D. CGoGN: n-dimensional Meshes with Combinatorial Maps. In Proceedings of the 22nd IMR 2013, International Meshing Roundtable, Orlando, FL, USA, 13–16 October 2013; pp. 485–503. [Google Scholar]
- Damiand, G.; Teillaud, M. A Generic Implementation of dD Combinatorial Maps in CGAL. In Proceedings of the 23rd International Meshing Roundtable (IMR), London, UK, 12–15 October 2014; Elsevier: London, UK, 2014; Volume 82, pp. 46–58. [Google Scholar]
- De Cougny, H.; Shephard, M. Parallel volume meshing using face removals and hierarchical repartitioning. Comput. Methods Appl. Mech. Eng. 1999, 174, 275–298. [Google Scholar] [CrossRef]
- Coupez, T.; Digonnet, H.; Ducloux, R. Parallel meshing and remeshing. Appl. Math. Model. 2000, 25, 153–175. [Google Scholar] [CrossRef]
- Chrisochoides, N. Parallel Mesh Generation. In Numerical Solution of Partial Differential Equations on Parallel Computers; Bruaset, A.M., Tveito, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 237–264. [Google Scholar]
- Freitas, M.O.; Wawrzynek, P.A.; Neto, J.B.C.; Vidal, C.A.; Martha, L.F.; Ingraffea, A.R. A distributed-memory parallel technique for two-dimensional mesh generation for arbitrary domains. Adv. Eng. Softw. 2013, 59, 38–52. [Google Scholar] [CrossRef]
- Löhner, R. Recent Advances in Parallel Advancing Front Grid Generation. Arch. Comput. Methods Eng. 2014, 21, 127–140. [Google Scholar] [CrossRef]
- Ghisi, I.T.; Camata, J.J.; Coutinho, A.L.G.A. Impact of tetrahedralization on parallel conforming octree mesh generation. Int. J. Numer. Methods Fluids 2014, 75, 800–814. [Google Scholar] [CrossRef]
- Zhao, D.; Chen, J.; Zheng, Y.; Huang, Z.; Zheng, J. Fine-grained parallel algorithm for unstructured surface mesh generation. Comput. Struct. 2015, 154, 177–191. [Google Scholar] [CrossRef]
- Diachin, L.F.; Hornung, R.; Plassmann, P.; Wissink, A. Parallel Adaptive Mesh Refinement. In Parallel Processing for Scientific Computing; Heroux, M.A., Raghavan, P., Simon, H.D., Eds.; SIAM: Portland, OR, USA, 2006; Chapter 8; pp. 143–162. [Google Scholar]
- Freitas, M.O.; Wawrzynek, P.A.; Neto, J.B.C.; Vidal, C.A.; Carter, B.J.; Martha, L.F.; Ingraffea, A.R. Parallel generation of meshes with cracks using binary spatial decomposition. Eng. Comput. (Lond.) 2016, 32, 655–674. [Google Scholar] [CrossRef]
- Tautges, T.J.; Kraftcheck, J.; Bertram, N.; Sachdeva, V.; Magerlein, J. Mesh Interface Resolution and Ghost Exchange in a Parallel Mesh Representation. In Proceedings of the 26th IEEE International Parallel and Distributed Processing Symposium Workshops & PhD Forum, IPDPS 2012, Shanghai, China, 21–25 May 2012; pp. 1670–1679. [Google Scholar]
- Langer, A.; Lifflander, J.; Miller, P.; Pan, K.; Kalé, L.V.; Ricker, P.M. Scalable Algorithms for Distributed-Memory Adaptive Mesh Refinement. In Proceedings of the IEEE 24th International Symposium on Computer Architecture and High Performance Computing, SBAC-PAD 2012, New York, NY, USA, 24–26 October 2012; pp. 100–107. [Google Scholar]
- Ray, N.; Grindeanu, I.; Zhao, X.; Mahadevan, V.; Jiao, X. Array-based, parallel hierarchical mesh refinement algorithms for unstructured meshes. Comput. Aided Des. 2017, 85, 68–82. [Google Scholar] [CrossRef]
- Kirk, B.S.; Peterson, J.W.; Stogner, R.H.; Carey, G.F. libMesh: A C++ library for parallel adaptive mesh refinement/coarsening simulations. Eng. Comput. (Lond.) 2006, 22, 237–254. [Google Scholar] [CrossRef]
- Ibanez, D.A.; Seol, E.S.; Smith, C.W.; Shephard, M.S. PUMI: Parallel Unstructured Mesh Infrastructure. ACM Trans. Math. Softw. 2016, 42, 17:1–17:28. [Google Scholar] [CrossRef]
- Damiand, G.; Lienhardt, P. Removal and Contraction for N-Dimensional Generalized Maps. In Proceedings of the 11th International Conference on Discrete Geometry for Computer Imagery (DGCI), Naples, Italy, 19–21 November 2003; Lecture Notes in Computer Science. Springer: Berlin, Germany, 2003; Volume 2886, pp. 408–419. [Google Scholar]
- The CGAL Project. CGAL User and Reference Manual; CGAL Editorial Board: Boston, MA, USA, 2009; Available online: http://www.cgal.org/ (accessed on 12 July 2018).
- Alliez, P.; Tayeb, S.; Wormser, C. 3D Fast Intersection and Distance Computation. In CGAL User and Reference Manual, 3.5th ed.; CGAL Editorial Board: Boston, MA, USA, 2009; Available online: http://www.cgal.org/Pkg/AABB_tree (accessed on 12 July 2018).
- Gabriel, E.; Fagg, G.E.; Bosilca, G.; Angskun, T.; Dongarra, J.J.; Squyres, J.M.; Sahay, V.; Kambadur, P.; Barrett, B.; Lumsdaine, A.; et al. Open MPI: Goals, Concept, and Design of a Next Generation MPI Implementation. In Proceedings of the 11th European PVM/MPI Users’ Group Meeting, Budapest, Hungary, 19–22 September 2004; pp. 97–104. [Google Scholar]
- Untereiner, L.; Kraemer, P.; Cazier, D.; Bechmann, D. CPH: A Compact Representation for Hierarchical Meshes Generated by Primal Refinement. Comput. Graph. Forum 2015, 34, 155–166. [Google Scholar] [CrossRef] [Green Version]









| Mesh | Armadillo | Blade | Bunny | Cow | Elephant | Iphigenia |
| # faces | 52000 | 1765388 | 52000 | 5804 | 5558 | 703512 |
| # init. hexa |



© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Damiand, G.; Gonzalez-Lorenzo, A.; Zara, F.; Dupont, F. Distributed Combinatorial Maps for Parallel Mesh Processing. Algorithms 2018, 11, 105. https://doi.org/10.3390/a11070105
Damiand G, Gonzalez-Lorenzo A, Zara F, Dupont F. Distributed Combinatorial Maps for Parallel Mesh Processing. Algorithms. 2018; 11(7):105. https://doi.org/10.3390/a11070105
Chicago/Turabian StyleDamiand, Guillaume, Aldo Gonzalez-Lorenzo, Florence Zara, and Florent Dupont. 2018. "Distributed Combinatorial Maps for Parallel Mesh Processing" Algorithms 11, no. 7: 105. https://doi.org/10.3390/a11070105
APA StyleDamiand, G., Gonzalez-Lorenzo, A., Zara, F., & Dupont, F. (2018). Distributed Combinatorial Maps for Parallel Mesh Processing. Algorithms, 11(7), 105. https://doi.org/10.3390/a11070105