1. Introduction
A collection of mobile nodes can make up mobile Ad hoc sensor networks, which are not intervened on by any centralized access point [
1,
2]. In order to assist other nodes in the network to build information links, nodes can be used as router or terminal or both of them [
3,
4]. Mobile Ad hoc sensor network can be utilized in these scenarios, such as military and habitat monitoring [
5,
6], target tracking network [
7,
8]. For example, in the animal tracking system, sensor nodes are loaded on the body of animals in order to observing animal behavior. Generally, the animals (such as zebras, elephants etc.) have the low group mobility. Additionally, the sensor nodes cannot be charged in this situation. Hence, the energy consumption is a vital problem for the limitation of the energy. Moreover, since the animals live in a relatively bad environment, the fault node will be a necessary part needed to be considered. Therefore, our proposed protocol is motivated by this kind of applications.
It has been proved that clustering in hierarchical structure is an effective scheme to improve the network survivability [
9,
10]. In [
9], it is introduced that the clustering method of fuzzy logic theory in the ECPF protocol. At the same time, in order to solve the problem of clustering non-uniformity, LEACH-C algorithm is proposed in [
10] and the residual energy and location of the cluster node are decided by the base station. However, how to elect the optimal cluster heads (CHs) and how can the optimal number of nodes be assigned become the bottleneck [
11,
12,
13]. The structure of cluster is especially more significant in large scale network. Instead of using gateways to exchange data packet, nodes in the network are distributed and confined within each cluster. The cluster members only need to collect data and transmit packet to CHs.
Though the process of clustering will consume a little of energy, the overhead of routing control can be reduced a lot. Apart from above, the measurement will cause some difficulties due to the high mobility of nodes. In this paper, a high density network is considered, so we adopt the specific group mobility model [
14,
15,
16]. In order to reduce the re-clustering times and save more energy, the novel mobility measurement is adopted. Nodes with similar motion pattern will form into a group or a cluster. The linear displacement of nodes is based on the record of history movement. The displacement index of each node will be calculated only when their displacement goes beyond the cluster range.
Consequently, robustness of network is becoming a hotspot because the network has characteristics of dynamic topology, limited energy and mobility. Currently, a number of researches on robustness have been done in the mobile Ad hoc network. Reasonable fault management framework can enhance work efficiency of nodes, which can improve the robustness [
17,
18]. A strong robust network will be utilized in different scenarios.
Currently, the proposed algorithms have taken fault tolerance and energy-efficiency into consideration and make some progress on fault detection and CH election. However, to some degree, only consideration of fault detection and energy-efficiency is unilateral to network, which neglected the mobility of nodes. Therefore, in order to render the energy consumption more homogenized, a robust and energy-efficient weighted clustering algorithm is adopted, which considers the group mobility and the residual energy. Meanwhile, for the purpose of enhancing the robustness of the network, a topology maintenance algorithm is proposed to control when the topology need be maintained. Our algorithm, A Robust, Energy-efficient Weighted Clustering Algorithm (RE2WCA), achieves the tradeoff of energy-efficiency and robustness and the following goals of our algorithm is demonstrated as below:
- (1)
For purpose of achieving load balance of cluster head, the clustering algorithm we proposed takes group mobility and residual energy into account to adapt to the change of network. Clustering times will be dramatically reduced due to the group mobility.
- (2)
Design a periodic fault detection protocol to exclude the fault node otherwise leading to paralysis of the network. The protocol is based on a clustering structure which integrates the advantages of centralized and distributed scheme.
- (3)
Combine topology protocol and clustering algorithm systematically to enhance lifespan and robustness of mobile Ad hoc network.
The structure of this paper is organized as followed: An overview of related work is given in
Section 2. A fault detection algorithm and RE
2WCA algorithm are described in detail in
Section 3. The topology maintenance process is demonstrated in
Section 4.1 and the inter-cluster and intra-cluster communication is demonstrated in
Section 4.2; Simulation results and discussion are provided in
Section 5;
Section 6 concludes the paper.
2. Related Work
There are various clustering algorithms for mobile Ad hoc network. Among them, lowest relative mobility clustering algorithm (MOBIC) based on mobility is proposed [
19]. The algorithm regards the relative mobility between nodes as the criterion of cluster header selection. WCA and DWCA are put forward in terms of weight clustering [
20,
21]. Although both of them take the mobility, the limited energy and the degree of nodes into consideration, it is also not involved in how to enhance the robustness and anti-attacks ability. Based on energy-efficiency of network, HEED forms clusters through a distributed scheme to render the energy consumption of network communication minimized [
22]. The algorithm elects the cluster heads based on the residual energy of nodes, which means that the nodes with high residual energy are more possible to be elected as cluster head than other nodes. Based on fuzzy c-means clustering, an energy efficient
CH selection is put forward [
22].
The cluster structure is optimized to consume less energy. However, in order to make a right decision, the fuzzy c-means protocol has to collect more information, which actually needs more energy and shortens the lifespan of network. So, the performance of the algorithm is not better due to the optimized structure. In [
23], based on residual energy and trust value, a cluster head selection is put forward. The trust value according to the interactive history and residual energy of each node are calculated to be used as the criterion of selecting cluster head.
In [
24], a distributed fault tolerant topology control scheme based on cooperative communication is proposed. In the literature, the author first defined the
k-connectivity and constructed a
t-spanner with
k-connectivity of an arbitrary communication network. The scheme enhances the fault tolerance ability and also takes the advantages of the cooperative communication to reduce the power consumption. Other algorithms also have their concentration on how to construct redundant backbone and
k-connected graph network [
25,
26,
27]. In addition, in order to overcome the malicious attack, trust model through the weighted method with direct trust and recommendation trust is proposed [
28]. In the literature, author builds a trust model to measure whether a node is a malicious node or not. However, since the multi-hop recommendation messages forwarding, each node consumed much energy although the security of the network and fault tolerance is enhanced. Especially when the route is long, the transmission delay and throughput of the whole network are seriously decreased.
In the literature [
29], the author adopts a voting scheme in sparse sensor network to obtain each statue of fault node. However, this scheme based on crowd-sourcing will increase the complexity of algorithm and decrease the network lifetime. Additionally, the algorithm is based on a flat structure and the routing overhead will be amplified. Besides many high complexity algorithms are presented to solve the problem of fault node with a flat structure instead of clustering [
30,
31,
32], however, it also results in energy depletion of the sensors nodes. In [
33], a full 2-connectivity restoration (F2CRA) algorithm and partial 3-connectivity restoration algorithm (P3CRA) algorithm for connectivity restoration are put forward. The topology quality and network coverage are taken into consideration when enhancing the fault tolerance and restoration. Unfortunately, the algorithm is executed in a flat structure so that when the network scale becomes large, the complexity of the calculation is increasing dramatically. Consequently, the P3CRA algorithm is not suitable for the large scale wireless sensor networks. In summary, these above algorithms sacrifice the validity for the sake of reliability. Therefore, a method and protocol which does not increase the connectivity of the network but enhances the fault tolerance ability with a hierarchical structure are motivated.
3. Description of RE2WCA Algorithm
3.1. Energy Consumption Model
The battery power of each nodes in network are assigned identically. Equations (1) is adopted to calculate the energy consumption of sending data and Equation (2) for receiving data [
15]:
In Equations (1) and (2),
Eelec is required energy for activating the electronic circuits; if the transmission distance is less than the threshold
d0, the consumption of energy amplification adopts the free space model. If the transmission range is greater than the threshold
d0, the energy amplification adopts the multipath attenuation model. ε
fs and ε
amp are required energy for amplification of transmitted signal to transmit one bit in open space and multipath models respectively;
l denotes the number of bits of data;
d is the distance between two nodes;
Et(
d,
l) is the energy consumption of the sending end;
Er(
l) is the energy consumption of the receiving end. The residual energy [
6] of each node is calculated by Equation (3):
In Equation (3), is the initial or max energy of each node i; demonstrates the residual energy of each node i after transmitting data.
When each node begins to send data packets, the summation of energy in each cluster can be calculated. In this paper, one of the significant threshold is topology maintenance energy threshold value. When the average of CHs’ energy lower than this value, the re-clustering process will be implemented.
Taking the difference of energy of each cluster into account, the average energy within cluster is implied as the inner cluster average energy. Only when the residual energy of cluster head is lower than the value, the process of new cluster head selection will start. Therefore, Equation (4) is adopted to calculate the inner cluster average energy. In Equation (4), Ck represents each cluster and if a node belongs to one of the clusters, then j ∈ Ck.
3.2. Mobility Measurement
MOBIC [
19] is a mobility-aware clustering scheme. Instead of using the node’s ID, MOBIC adopts the relative metric to measure the mobility of the nodes. However, if mobile nodes move in an arbitrary manner, the diversity with other nodes is dominant. Even if some nodes have similar motion but a few others move differently. It still results in dramatic increase in the variance. It shows the variance is greatly influenced by the diverse motion.
In the paper, a group mobility protocol is adopted to measure whether a node has possibility to be elected as cluster head. The higher group mobility of one node implies it has the similar mobility pattern with the majority of its neighbors [
14]. Thus, it suits to be elected as
CH.
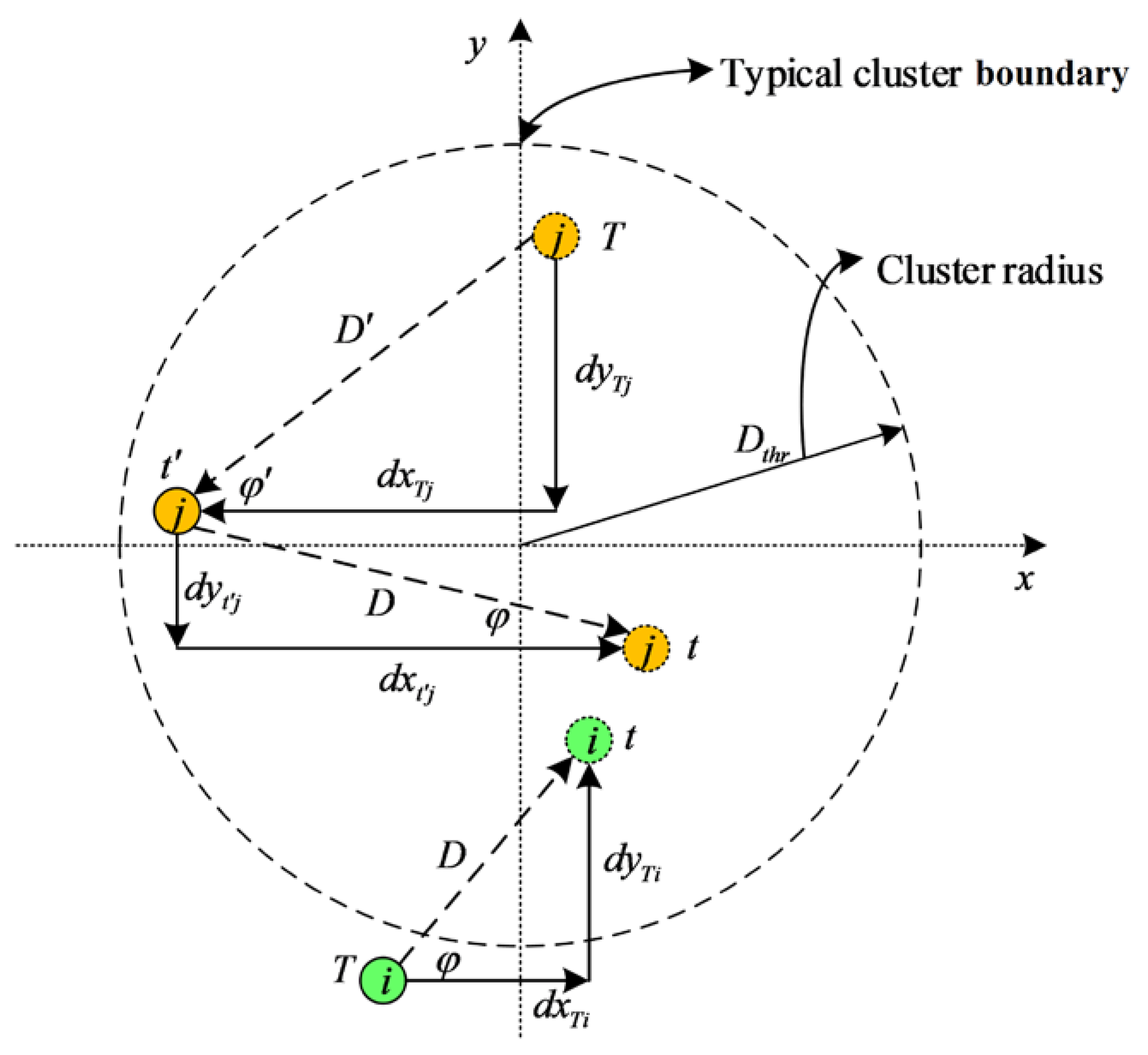
Figure 1 shows the derivation process and motion model of the nodes.
Based on record of last movement, the linear displacement of each node can be calculated in real time. The linear displacement of each node will be figured out as soon as nodes move in the network.
Then, the relative direction and speed ratio are considered to calculated the spatial dependency between nodes. In addition, the history cache can be updated.
As is shown in
Figure 1, the displacement of node
i is lower than
Dthr and consequently this record will not be updated into the history cache. From moment
T to
t’, the displacement
D’ of node
j is greater than
Dthr and consequently the history cache is updated. In addition, from moment
t’ to
t, movement of node
j D is still greater than the
Dthr, hence the record will be entered into the history cache.
Hence, only when node moves, the calculation process will be implement and not all nodes need to save their record into cache due to the cluster radius threshold. Nodes which have the frequent and great displacement will consume more energy for their mobility. Therefore, it is small probability of these nodes to be elected as CHs. Within a cluster or a group, the CH needs to be rotated for the homogenization of energy. Here, we define the spatial dependency with CH as CHSD which demonstrates that each round cluster members need to calculate the spatial dependency with current CH. In order to describe the spatial dependency with CH (CHSD), the following measurements will be demonstrated.
According to Algorithm 1, relative direction (RD) and speed radio (SR) at one moment t between one node i and cluster head are measured respectively as
| Algorithm 1 Group mobility computing process |
where t is the current time and are the coordinates of the node i from time T to t, respectively. Hence the displacement and angle can be calculated by:
If D ≥ Dthr, the most recent record of speed and direction that will be saved into the history cache are:
where T = be the moment when the last record was saved for node i and . The time , the speed , the direction and the present location of node i will be recorded into the history cache with . |
Hence, the
CHSD can be calculated by:
The range of CHSD is between [–1, 1]. If CHSD is very close to 1, it indicates the nearly same motion with CH otherwise the less similarity with CH. CH has the feature of maximum similarity and lower mobility and it is elected in the last round. However, in the current round, CH is a very ordinary node and it still needs to calculate the speed, the angle. But nodes now will not compare with each other, instead, with CH. It is the improvement compared with original measurement. It dramatically decreases the complexity of calculation and reduces great energy consumption. Additionally, the maximum of CHSD will be appropriate to be elected as CH. Therefore, in order to describe the stability of one cluster, it only needs to calculate the summation of CHSD.
3.3. Weight Model and Hybrid Clustering Algorithm
After the initialization of the network, one node within cluster announces the information of its cluster head. The cluster head needs to be rotated to prolong the survivability and lifespan of the network. Therefore, we put forward the weight probability average. The high weight value of node implies it has more possibility to be selected as cluster head. Hence, a weight model is proposed and its measurement is given by Equation (8):
where
a and
b are weighted coefficient index of residual energy and group mobility feature respectively;
CHSDmap(
i) is the spatial dependency with
CH at one moment after linear mapping from [–1, 1] to [0, 1];
weight(i) denotes one node probability to be
CH;
Cprob is an initial iteration probability.
It is obvious that the range of weight(i) value is limited with (0, 1). Additionally, the summation of a and b is set as 1. Generally, a > b is rendered. The adequate residual energy of the node implies that it can manage a cluster better than other nodes. In addition, the high group mobility of CHSD demonstrates that one of node within cluster has a high correlation with its cluster head. Hence, in order to make the times of re-clustering due to nodes’ mobility, the node with a high CHSD value is elected as the cluster head in the group. In addition, we use Cprob to limit the announcement of cluster head. Through calculating the weight value above, it is concluded that the nodes with high group mobility and residual energy is more suitable to be the cluster head.
Through limiting iteration of cluster head, a
CH selection protocol is put forward. In order to prolong the lifetime of the network, we regard
average minimum reachability power (
AMRP) as the cost of election. Compared with the other types of cost, such as
node degree or
1/
node degree, the
AMRP is a compromise between network density and load balancing. It has been proved that HEED has fewer iterations than General Cluster (GC) Scheme [
34]. In this paper, we consider a greater minimum iteration threshold
pthr. Due to the mobility, the radius of cluster or group will be greater. However, with the increase of the radius, the iterations of GC are dramatically increased but HEED has to stop iterating for the
pthr. Considering mobility of nodes, increasing
pthr appropriately will reduce the iterations so that save energy. Equation (9) demonstrates the calculation:
where
CHprob represents the probability of each node to be
CH. Through a limited iteration,
CH will be elected. In every iteration, the
CHprob will be doubled and until the cluster formation accomplished or finished beyond the threshold. The iteration times can be calculated:
Therefore,
Niter ≈
O(1). If
pthr sets to 10
−4, there is 15 iterations to end up. Actually, the greater number of iterations will consume much energy, thus it is necessary to select an appropriate iteration threshold. We define the ratio of residual energy of
CH and average energy of cluster is
ER (energy ratio) as Equation (11) described:
In addition, pmin = max {ER, pthr} is chosen. For Equation (11), if residual energy of cluster head is equal to the average energy of cluster approximately, ER is about 1. Therefore, the times of iteration is limited within 2. Considering an extreme case, if when the residual energy of CH is close to 10−3 J (a totally unsuitable residual energy) and cluster average energy is 1 J, then ER = 10−3. Thus, if we set initial pthr = 10−2, then the iteration times will be limited within 7 rather than 10. Therefore, if initial pthr is greater than ER, pthr will be chosen as the iteration threshold. Considering energy efficiency, if the residual energy of cluster head is enough, the iteration times of cluster head can be reduced. On the contrary, if the energy of cluster head is not adequate, the network will need more iteration times to update the perfect cluster head. In conclusion, according to Algorithm 2, the process of cluster head election is demonstrated as follows:
| Algorithm 2CH election algorithm (each round for all nodes within the network) |
Function: ; CHprob ← max(weight(i), pmin);
pmin ← max{ER, pthr};
Input: a, b ← weight(i) factors satisfy a > b and a + b = 1; Cprob ← assuming value;
d ← distance between sending end and receiving end;Begin The sending end radio energy consumption is Et if d < d0, the free space model is used, otherwise, multi-path attenuation model is used The receiving end radio energy consumption is Er(l) = lEelec Eresidual ← the difference between initial energy and the summation of sending and receiving energy ← group mobility process. ; CHSD(i,ch) ← RD(i,ch) × SD(i,ch) at one moment t; then a linear mapping from CHSD to CHSDmap. Start CH selection protocol to implement CH election. End.
|
3.4. The Process of Cluster Establishment
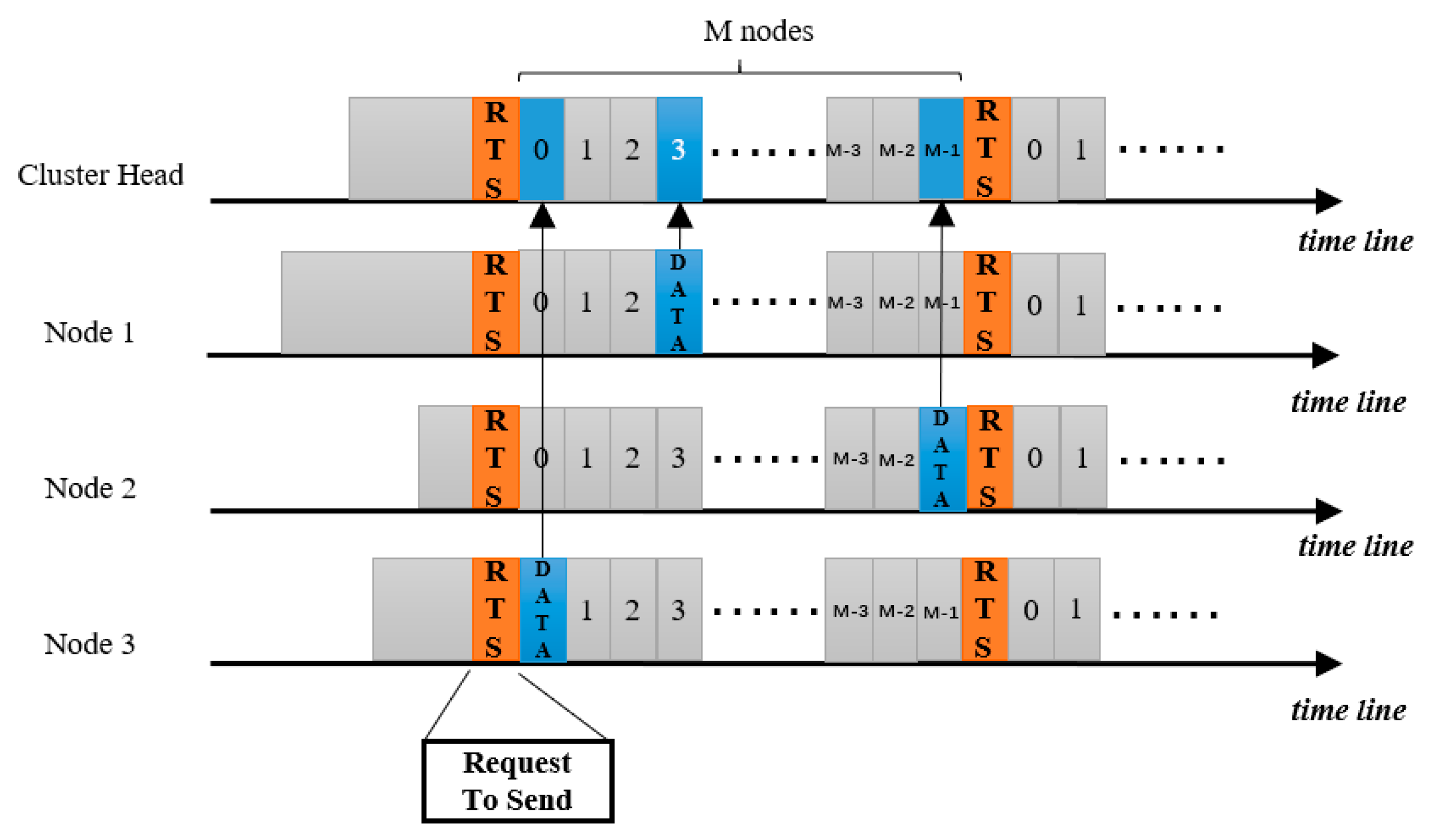
In mobile Ad hoc sensor network, this stage constitutes the final step of our novel weight algorithm and represents the construction of the cluster members’ set. Each cluster defines its neighbors at one hop maximum, which forms the member of the cluster. Firstly, all nodes are distributed in a network range and assigned with typically identical energy. In the network, each node broadcasts Hello messages packets which will consume a little of energy. Nodes will move towards different direction with different velocity, which will also cost various energy. When nodes are stable in first round, it is time to cluster through calculating the weight value of each node. Those nodes with large weight value will be elected as CH. Since the cluster is only restricted to manage its one hop neighbor, the process of cluster establishment will be accomplished quickly. Eventually, when all CHs connect with each other, the network is initialized. In order to display the process clearly, we give an explanatory example to clarify the clustering process.
Firstly, we give some relevant parameters. For example, we render a = 0.7, b = 0.3. It implies that the residual energy attaches more significance than mobility. Actually, the mobility will not very large in sensor network. It is only a small range of displacement; therefore, the history cache operations will not be very frequent. More clearly and directly, only those displacements of nodes beyond Dthr, the record will be entered into cache and is used to calculate the next moment displacement. Additionally, the CH is typically identical with cluster members. Hence, it also needs same computing with cluster members. Then, CHSD of one node will be calculated by Equations (5)–(7). This process actually need no data transmission except for the computing of CHSD. The data transmission needs only n times (if the number of cluster members is n). Of course, the weighted value can be adjusted according to different needs in application. For example, if the protocol is used in VANET, b can be adjusted larger since the energy is not a vital factor for sensor network. When the initialization of the network, the ratio of residual energy to average energy is equal and speed, directions are same, hence the weighted summation of CHSD and ratio of energy is 1. By Equation (8), we assume Cprob is an appropriate value that can reduce the iterations as much as possible. Then all nodes start to announce to form a cluster. Since we consider the cost of AMRP, therefore, each node need to broadcast a packet {ID, CHprob, cost (AMRP)}. According to the cost of broadcasting, the left nodes join in a cluster according to the minimum cost.
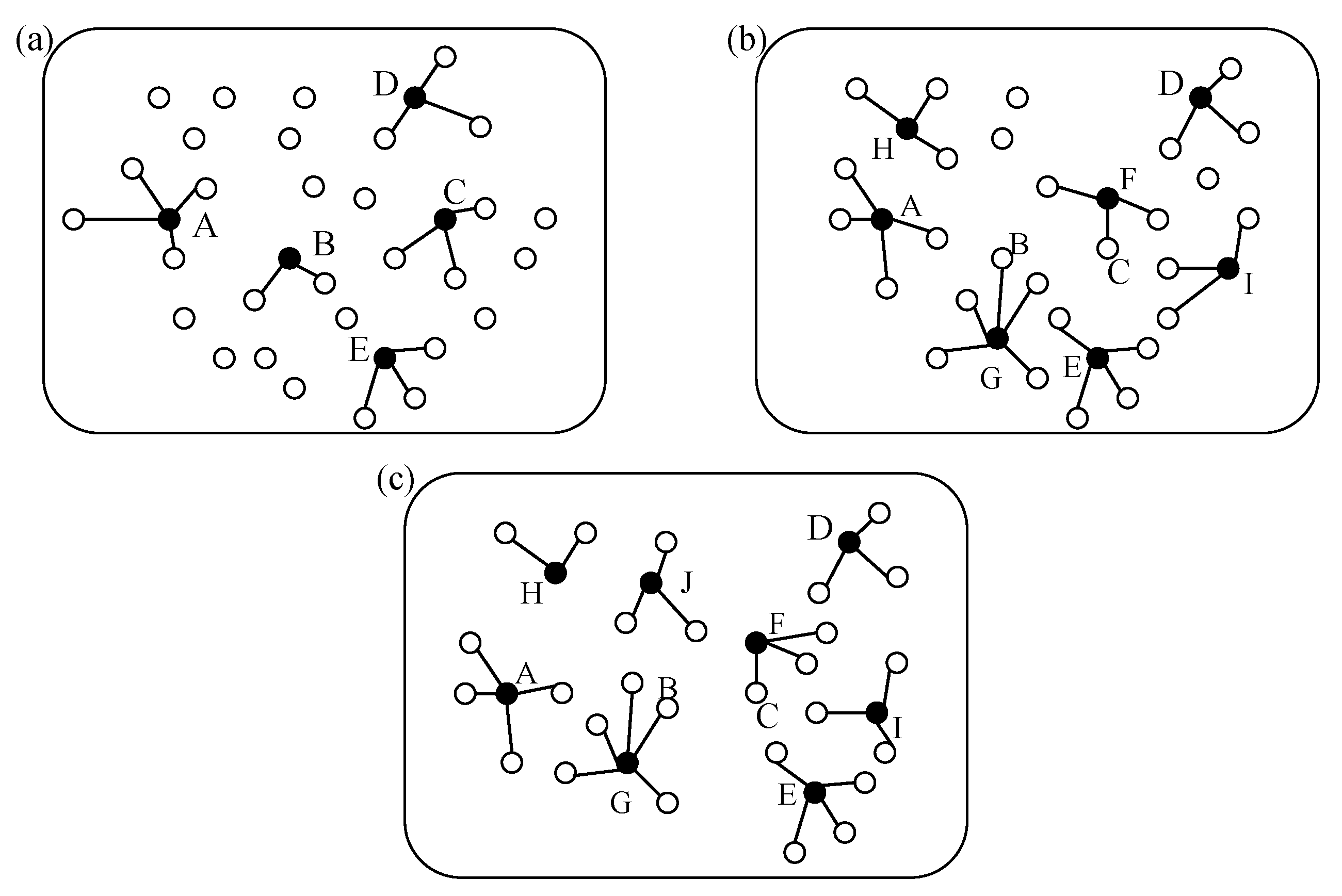
In
Figure 2a, nodes (A, B, C, D) announce their tentative
CH and display their connection with nodes in the first iteration. In
Figure 2b, tentative CHs (B, C) quit the job of
CH and join in cluster because the cost (AMRP) or
CHprob is not suitable. Tentative
CH (A, D) is still keeping their job for the group mobility feature (
CHSD) is relatively greater. In
Figure 2c, more tentative CHs are announced. Actually, AMRP will control the hops minimized in order to energy efficiency. After the first iteration, the
CHprob will double. Therefore, if
CHprob of one tentative
CH is greater than 1 or greater, this
CH will be the formal
CH and does not participate the iteration process but allows another node to join in. This example shows three iterations in
CH selection. Actually in the next round, the process will keep longer and will even trigger
pthr to finish the iteration forcibly.
3.5. Fault Detection Algorithm
Currently, mobile Ad hoc sensor network is widely utilized and obtains extensive applications for its rapid development, which results in the large quantities of problems emerged for the bad working condition [
35,
36,
37]. For example, nodes in the network are likely to suffer from battery out of charge for the increasing power consuming rate and the link failure in the network. In
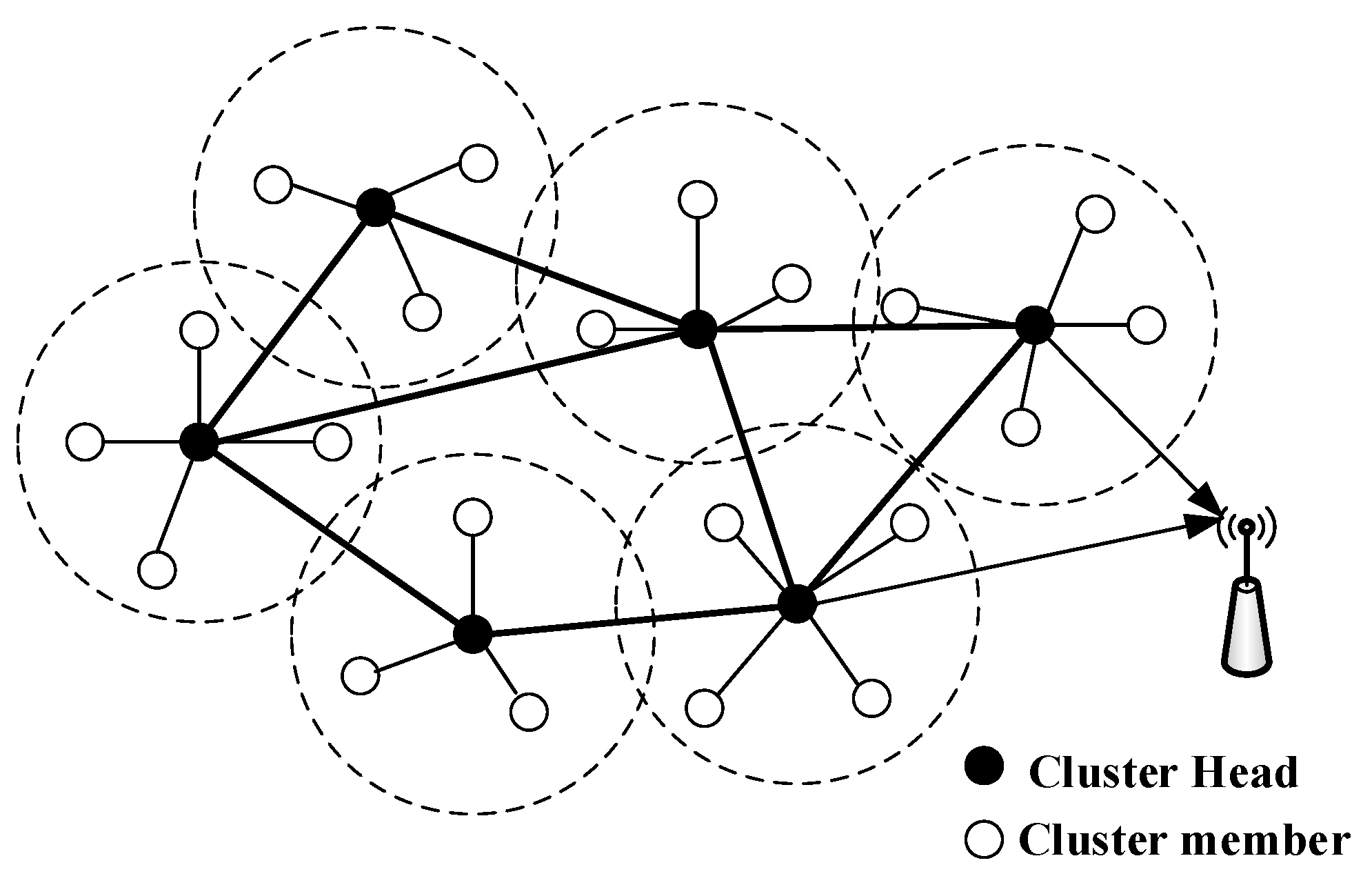
Figure 3, the network is stablished when the clustering algorithm finished. All nodes have its unique cluster and
CH.
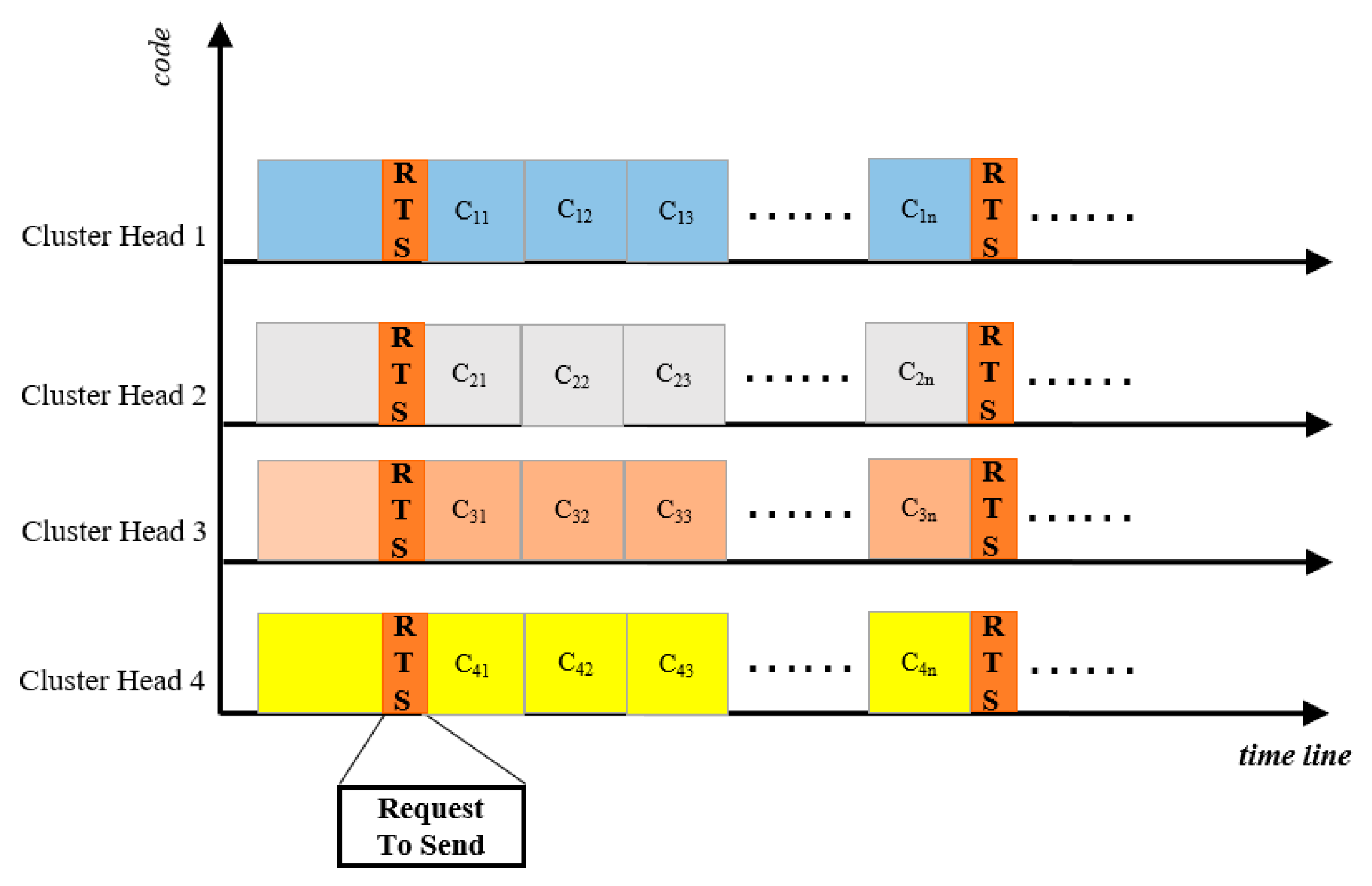
CH is responsible for the intra-cluster communication and inter-cluster packet transmission. Currently, there are mainly two kinds of methods in fault detection for wireless sensor network, which are centralized method and distributed method. In centralized fault detection approach, the central node, commonly sink node, is responsible for the faulty nodes in network. Apparently, these approaches are not suitable for large scale network because huge message forwarding will consume considerable energy and this will surely shorten the lifetime of the network. Therefore, distributed approach is proposed to overcome the problem of centralized approach. In distributed approach, faulty nodes are identified by local decision-making. In our network, the distributed fault detection managers are CHs and fault detection responsibility is subsequently distributed among each individual cluster. Further, if a failure is detected locally, the failure can be propagated to all other clusters. Hence, we propose a distributed approach to construct a fault detection framework to render the network more robust and fault tolerant.
Through this hierarchical structure, the management framework is more efficient. CHs need to find a path to forward packets to the sink node. Thus, the optimal path is also vital for the sake of energy efficiency. Consequently, in order to reduce the cases of network paralysis caused by the nodes failures or
CH, we propose a fault-detection and
CH backup mechanism for the network. A periodic fault detection protocol is considered, which can detect the failures of nodes and CHs efficiently. Additionally, most topology control strategy is centralized [
38,
39,
40], which consumes amounts of energy and increases the overhead for broadcasting global messages. Therefore, we adopt a distributed fault tolerance control method to avoid the drawbacks of centralized strategy. When the process of cluster establishment is accomplished, the proposed fault detection algorithm is as followed:
The following example figures the process of this algorithm within each cluster under different cases. Among them,
Figure 4 gives the practical example of fault node detection. Meanwhile,
Figure 5 shows the practical process of Backup CH mechanism. We consider a low group mobility since actually most nodes have the similar movement characteristics.
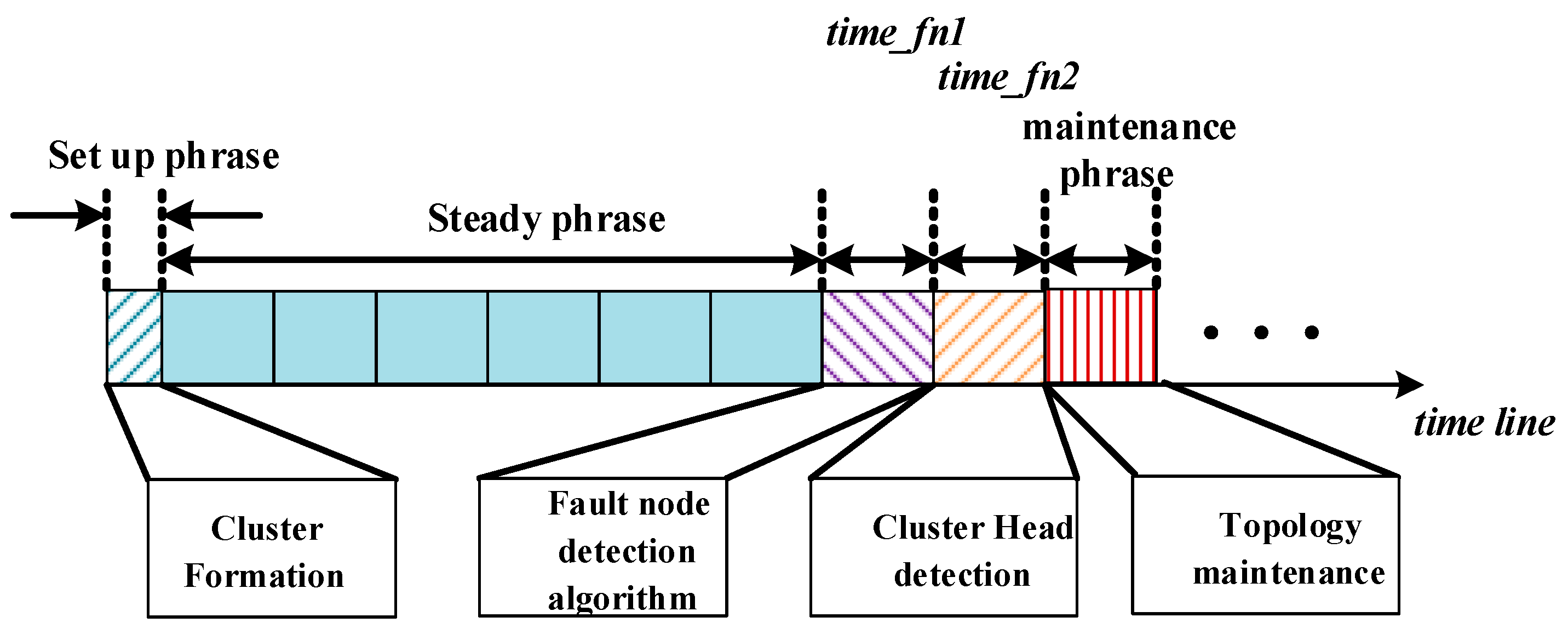
The above two processes are periodic. The period of detecting the fault node is time_fn1. Actually, the period is equal with the time when the last cluster member finish sending packets for the purpose of not influencing the normal communication of nodes. Thus, every time the last cluster member nodes finish sending packets, the network will run the fault detection algorithm. Similarly, the period of CH detection time_fn2 is equal with the time which consists of time_fn1 and the data processing time. Backup CH broadcasts sensing messages to cluster member and neighbor cluster nodes periodically. If finds CH cannot work, then execute the algorithm of Backup CH to make the network work. When the network cannot work normally, it needs to trigger the topology maintenance. In Algorithm 3, the detailed description of fault detection algorithm is shown.
| Algorithm 3 Fault detection algorithm description (run between inner-cluster and intra-cluster) |
After the packet transmission is finished, the fault detection begins.CH is elected and the degree (dvj) of each CH is ensured.
Initialization: ki = 0, ∑i = N, ∑j = H, Sfault = Φ, Sprob_fault = Φ, Sprob_fault(j) = Φ. |
#Round m (period time_fn1)- 1.
Initialization(ki, S); - 2.
whi(vi Clusterj and j <= H and i = N) - 3.
for i = 1 to dvj - 4.
bool flag = Send (vi → ID, vi) - 5.
if (flag = = false) - 6.
Append ((vi → ID),Sprob_fault(j)) - 7.
ki++; i++; - 8.
end; - 9.
end; - 10.
j++; - 11.
end; - 12.
if (ki >= 2) - 13.
Append ((vi → ID), Sfault) - 14.
else - 15.
Sprob_fault = ; - 16.
return ki, Sprob_fault and Sfault;
| #Round m (period time_fn2)- 1.
Input (Clusterj, weight); - 2.
Select_BackupCH (vi → weight < CH → weight) - 3.
while (viClusterj and j <= H and i = N) - 4.
for j = 1 to Clusterj - 5.
bool flag = Send (Clusterj → ID, vi) - 6.
if (flag == false) - 7.
mark (vi → ID) for each cluster - 8.
Append (Clusterj → ID, Sfault_prob) - 9.
end; - 10.
end; - 11.
for j = 1 to Clusterj - 12.
Send (vi ID, Clusterj and vi) - 13.
bool flag = Receive ((Clusterj and vi) → ID, vi) - 14.
if (flag == false) - 15.
Append ((Clusterj → ID), Sfault) - 16.
end; - 17.
end; - 18.
end;
|
3.6. Complexity
The time complexity of CH election algorithm is O(MN), in which M is the rounds number and N is the total number of nodes. When each round goes on, every node within the network will calculate its value of CHSD in order to compete with other nodes to be the next CH. So, when the times of rotation is M, the time complexity is O(MN). The most complex operation in the Fault detection algorithm is the rotation computation and it runs in O(Nlog(N)). This operation is performed for each cluster, which gives O(KNlog(N)), in which K is the number of clusters. Then, the time complexity of our proposed algorithm is O(MN) + O(KNlog(N)).
5. Simulation Results and Discussion
Firstly, the performance of RE
2WCA algorithm is evaluated. For purpose of generality, it is assumed that one thousand nodes are placed into a filed which ranges 2000 m × 2000 m. In addition, the iteration threshold is set to 0.0005 [
10,
11,
13]. Equation (10) implies that the max iteration times of RE
2WCA protocol is 12. In the process of initialization,
CHprob = Cprob = 5% is set for all nodes in the network, where only in sixth iteration, nodes with high energy will exit RE
2WCA protocol. It means that if the residual energy of nodes is higher, they will terminate RE
2WCA more earlier. The performance of DWCA and EDWCA are evaluated to demonstrate more straightforward and convincing. Therefore, from the aspects [
3,
10] listed as follows, RE
2WCA is compared with EMDWCA and DWCA protocols. (1) Ratio of the number of clusters to the number of all nodes; (2) Ratio of non-single node clusters to the number of clusters; (3) Standard deviation of the number of nodes in a cluster and maximum number of nodes in a cluster; (4) Average residual energy of CHs elected in each cluster.
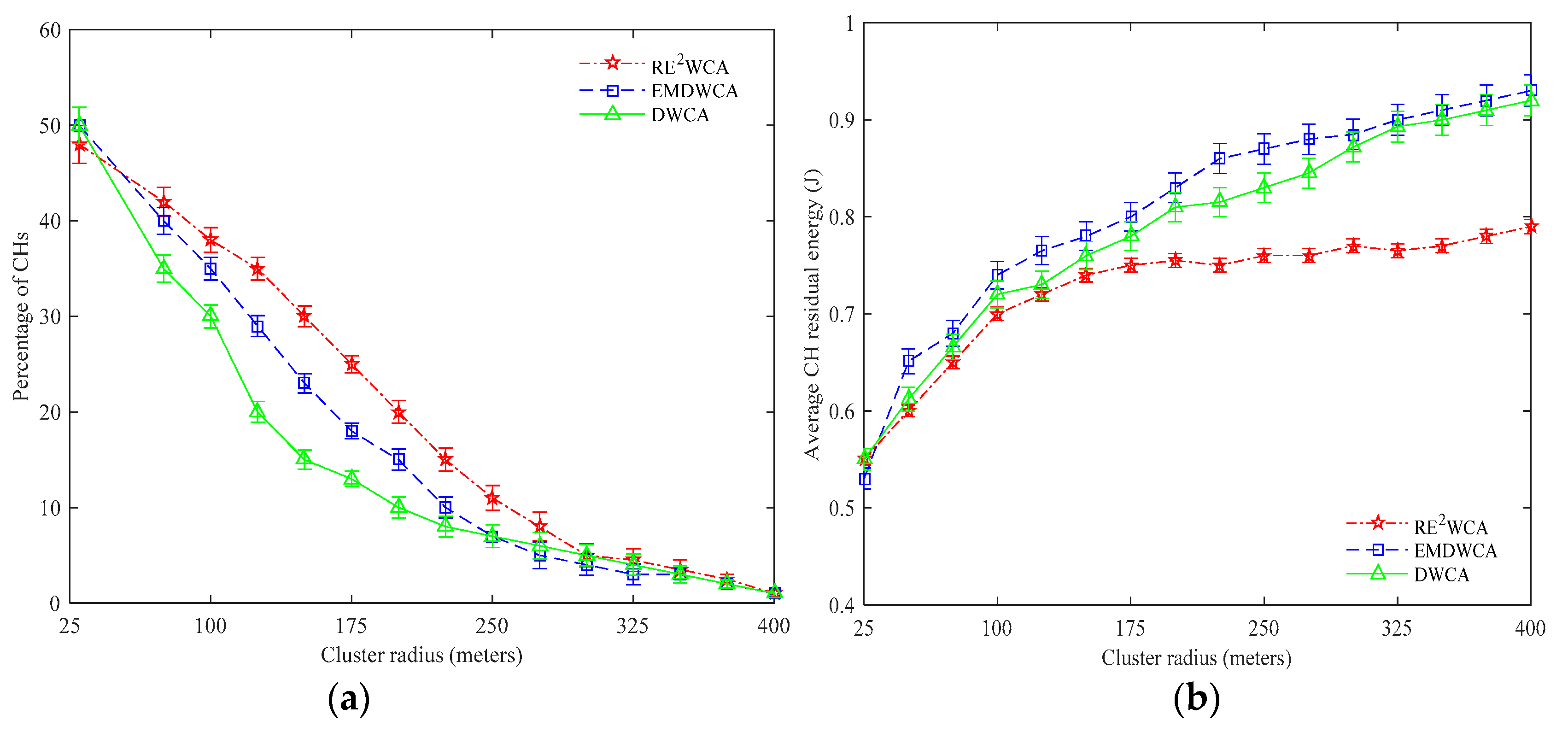
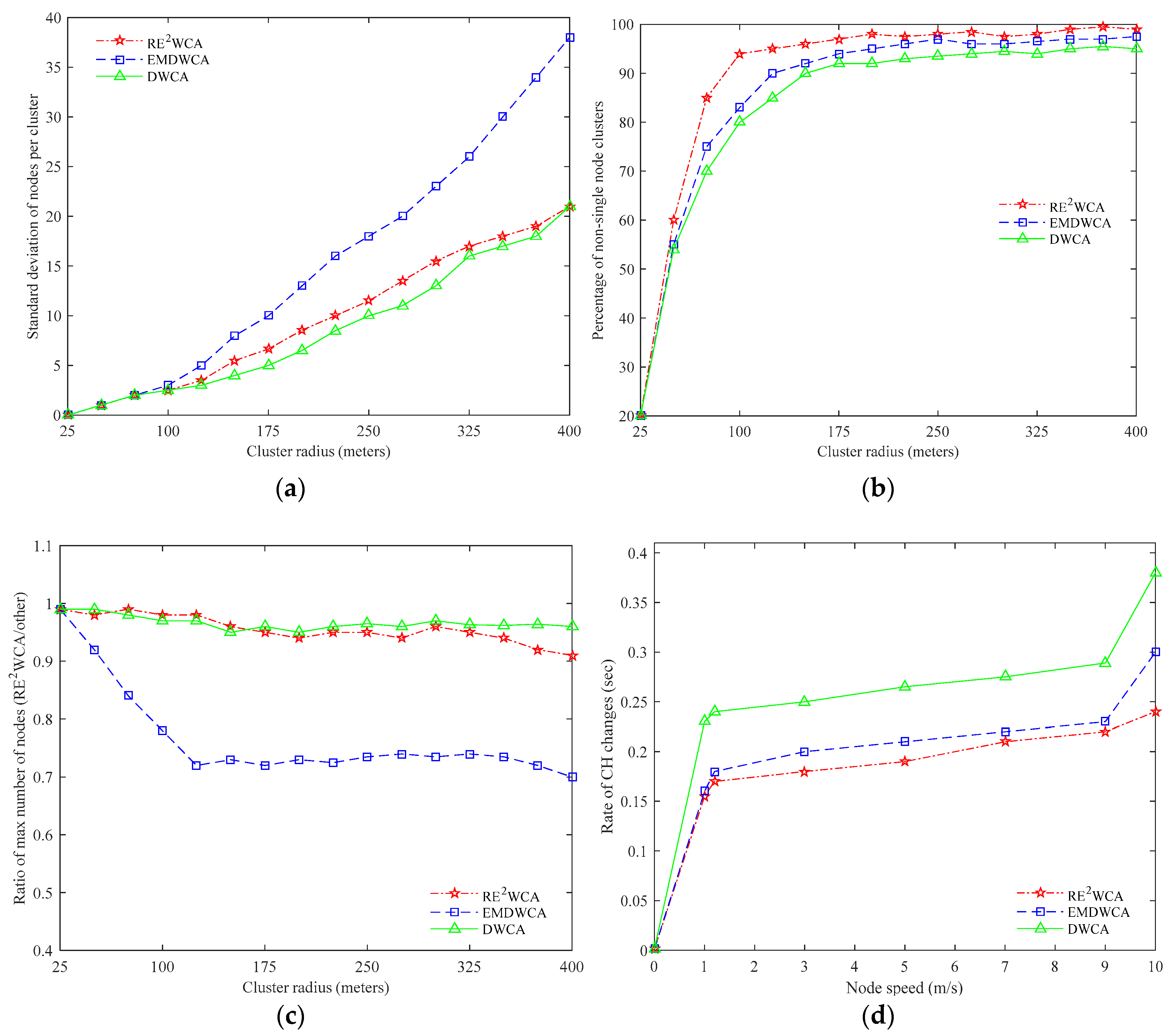
Figure 9a shows that both in three algorithms, when the radius of cluster increases, the percentage of cluster heads decrease respectively. When the radius of cluster reaches 400 m, it is not surprised that only one cluster head exists in the mobile network. With cluster radius increasing, the percentage of cluster heads of RE
2WCA is larger than DWCA and EDWCA algorithms. Because group mobility is considered where the nodes with similar motion pattern can maintain the original structure of cluster when the network topology changes. Thus, the number of cluster heads can be decreased a little slowly in RE
2WCA protocol. In
Figure 9b, RE
2WCA protocol does not perform very well compared with DWCA and EMDWCA. When the radius of cluster reaches 25 m, the average residual energy of three protocols are nearly same.
Figure 9b implies that with the radius of cluster increasing, the average residual energy increases. However, the residual energy of DWCA and EDWCA protocols is higher than RE
2WCA. The difference between RE
2WCA and EMDWCA is about 13%. Compared with DWCA is approximately 10%. It demonstrates that the
CH residual energy selected by RE
2WCA is high and is not far lower than the EMDWCA and DWCA.
Application requirement meets different types of cost function when selecting CH. If the protocol needs to be utilized in high node density network, the standard deviation will larger. If considering load balance, the standard deviation will be much smaller. In EMDWCA, the protocol considers the 1/node degree. Clearly, the maximum degree cost will increase the standard deviation. However, DWCA considers the minimum degree cost, that is, node degree, which demonstrates the standard deviation is relatively smaller. In RE2WCA, we consider a compromise between two extremes which is load balancing and cluster density respectively.
Another vital property of cluster is percentage of non-single node clusters. It demonstrates the feature of minimize the node into a cluster. In
Figure 10b, the percentage of non-single nodes of three protocols increase with the radius of cluster becomes larger. Theoretically, if the radius of cluster is large enough, the percentage of non-single nodes nearly reaches to 100% with all nodes forming into one cluster. It also implies that the percentage non-single nodes of RE
2WCA is much higher compared with two other protocols. From
Figure 1c, we can see the ratio of maximum number of nodes RE
2WCA to EMDWCA is lower than other two types of cost. The number of nodes will surely larger than minimum node degree and AMRP. In fact, this figure shows similar facts with
Figure 10a. They all demonstrates the different types of cost will form into various clusters. More requirements need considering in the actual application.
Figure 10d illustrates that when the node speed increases, the rate of
CH change goes high since the topology of network changes dramatically. Considering group mobility of network, the performance of RE
2WCA is better than DWCA and EDWCA protocols. The rate of
CH changes in RE
2WCA is nearly lower 7.5% than DWCA, 2.5% than EDWCA.
In addition, our protocol can be used into a cluster structure routing protocols, in which higher tier nodes should have more residual energy. Our approach can also be effective for sensor applications requiring efficient data aggregation and prolonged network lifetime. In the simulations, most of parameters are similar to those in [
2,
19,
20,
34]. Additionally, the mobility speed of nodes is 10m/s which is also similar with Ref [
14,
42,
43]. The parameters are listed in
Table 2. The energy consumption computing of sensor nodes is on the basis of Equations (1)–(3). Except for the above parameters, without loss of generality, the application parameters are as followed: data packet size of 100 bytes, broadcast packet size of 25 bytes and packet header size of 25 bytes [
3,
10,
34]. Additionally, we assume a = 0.7, b = 0.3 as the weighted average index. The reasonability has been discussed before. Firstly, all network has to solve the problem of throughput. For the purpose of increasing the throughput of the network, clustering method for nodes is adopted.
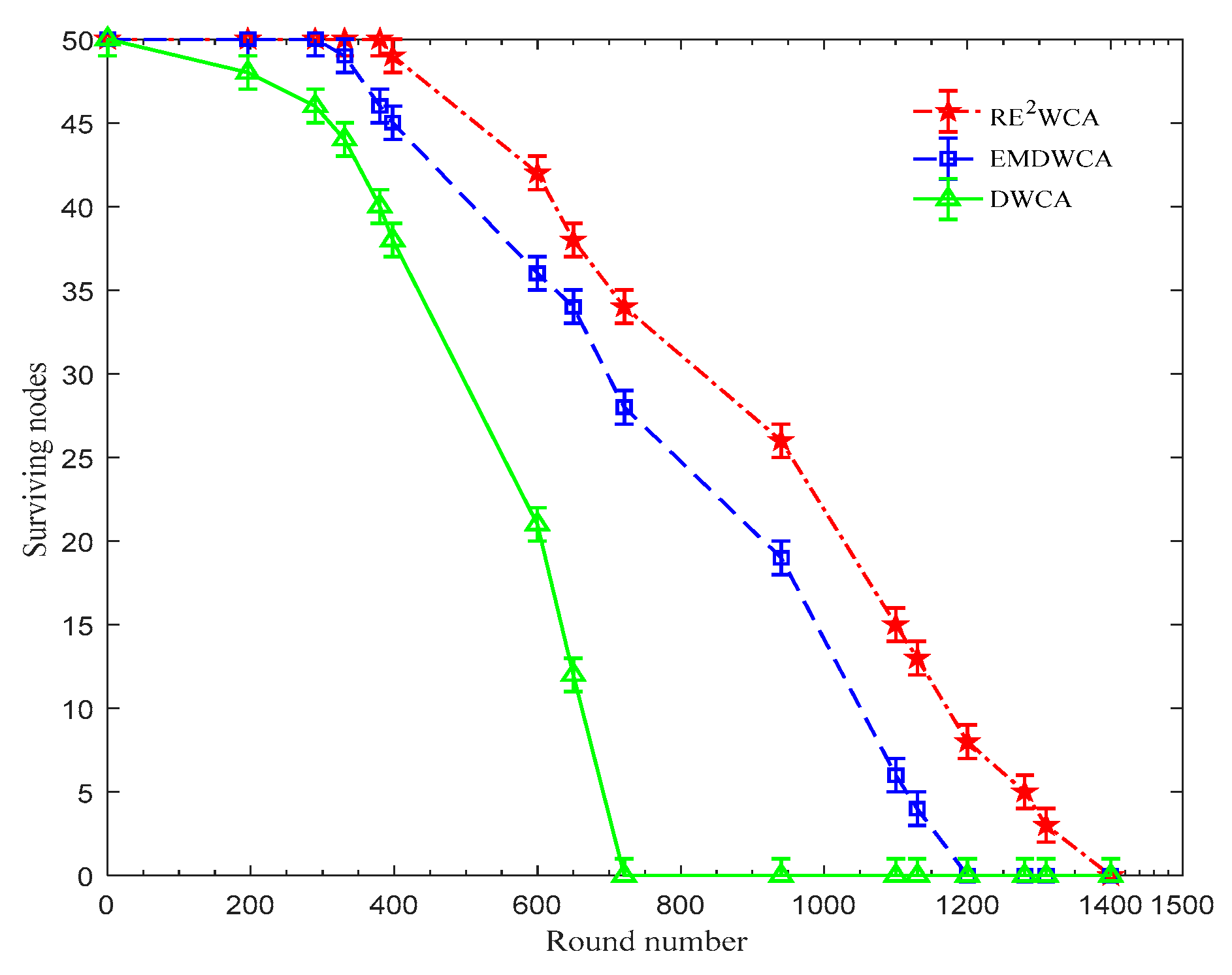
In
Figure 11, the first node of the DWCA algorithm failed at 196 rounds and the first node of the EMDWCA algorithm failed at 331 rounds, while the first node of the RE
2WCA algorithm failed at 398 rounds; the nodes that survive with the RE
2WCA algorithm is 103% higher than that of the DWCA algorithm and 20% higher than that of the EMDWCA algorithm. We also know that, when using the DWCA algorithm, all nodes are dead after 721 rounds of cluster head election. By applying the EMDWCA algorithm the life cycle of the node is 1270 rounds, however, by using RE
2WCA algorithm the surviving nodes remain to exist after 1410 rounds. This is because the algorithm proposed in this paper not only considers the residual energy and the mobility of the node but also takes the maximal capability of cluster head handling into account, which makes the nodes’ energy consumption more homogeneous and protects the cluster heads from excessive consumption. So, the RE
2WCA algorithm improves the stability of the network topology and the survivability of the overall network.
Figure 12 demonstrates the average network throughput varies with the distance of nodes. Within a short distance, the RE
2WCA is similar to the DWCA and EMDWCA, however, in the long distance, the throughput of RE
2WCA is obviously greater than the DWCA and EMDWCA since the proposed algorithm can elect the optimal
CH, which can accelerate the message forwarding. The throughput is nearly 10% greater than the EMDWCA and nearly 15% greater than DWCA respectively.
In
Figure 12, with the number of fault nodes increasing, the throughput of DWCA is decreased rapidly. On the meanwhile, the throughput of EMDWCA and RE
2WCA decreased slowly since in order to increase robustness of network, both of them introduce fault nodes detection algorithm. In RE
2WCA, the redundancy of the network is not increased but a mechanism of fault detection is introduced. The EMDWCA increases the redundant links of the nodes, which increases the routing overhead and consume more energy to construct links. Therefore, the throughput will be degraded. When the proportion of fault nodes reaches to 16%, the throughput of three types protocols decreased dramatically since many clusters cannot work normally. Actually, the proportion of fault node cannot reach so highly, thus, RE
2WCA remains to maintain a better throughput than DWCA and EDWCA protocols.
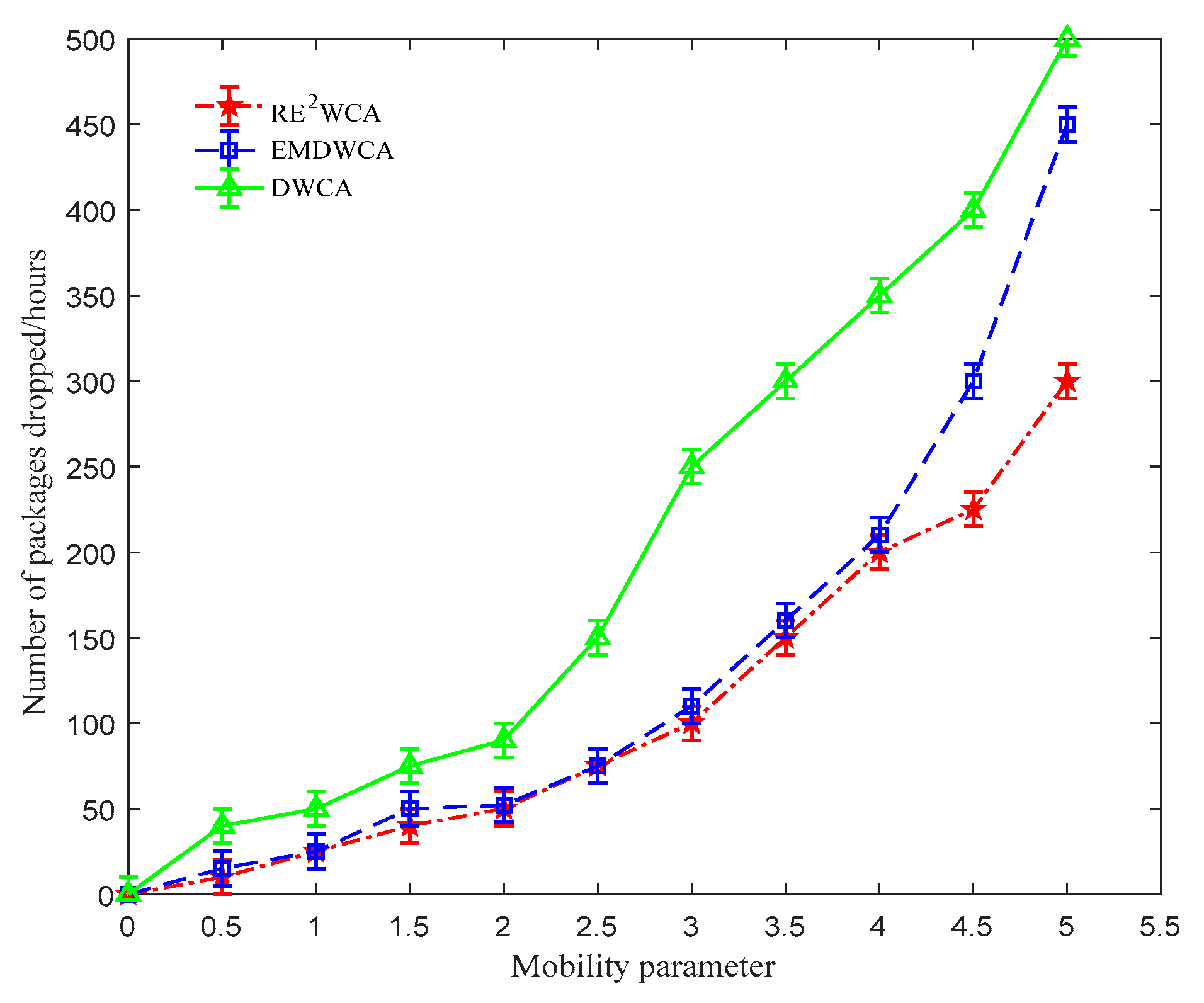
Figure 13 displays the effect of mobility on the packet drop rate. With increasing in the mobility of nodes, link failures occur causing more packets to be dropped on way. This decrease is less in RE
2WCA algorithm because of the use of mobility thresholds as well as group mobility.
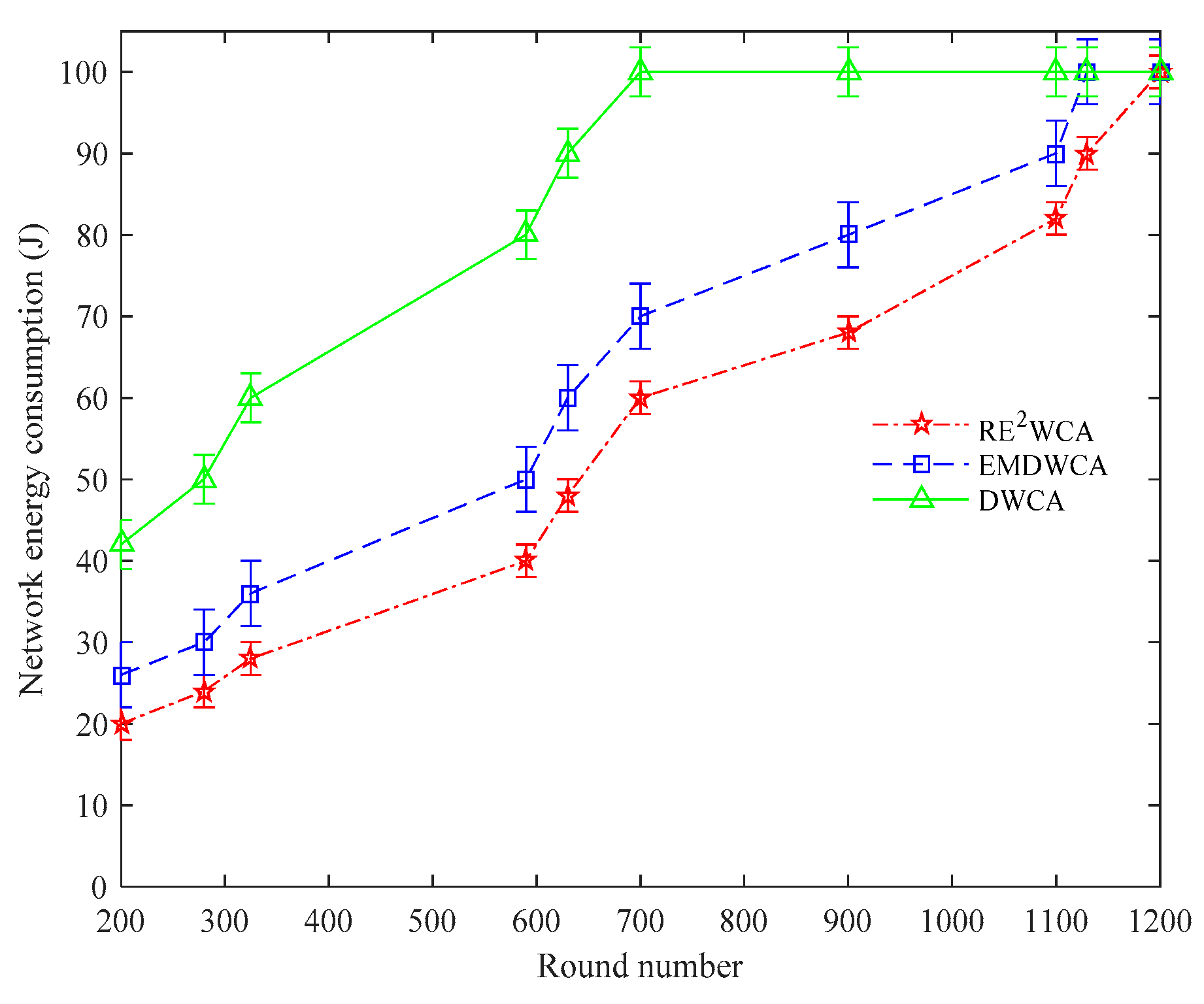
Figure 14 shows the energy consumption of the whole network. We can conclude that DWCA consumes energy fastest, EMDWCA second and RE
2WCA slowest. The energy consumption is vital in sensor network, however, DWCA fails to control the energy consumption reasonably, therefore when the round number is nearly 700 rounds, the network is paralyzed. In EMDWCA, the lifetime of the network is relatively longer because the
CH election considers the residual energy. Unfortunately, since the increased routing overhead and constructed redundancy link, the energy still consumes fast, therefore when the round number is nearly 1100 rounds, the network is paralyzed. However, the proposed algorithm can reach 1220 rounds, because we not only consider the residual energy but also exclude the fault nodes so that network can proceed the topology maintenance which can save amount of energy caused by the times of failed routing. The energy consumption of network which is conducted in RE
2WCA protocol is 50% less than DWCA and 15% for EMDWCA respectively. In conclusion, we discuss the cluster application from different aspects which are throughput and network energy consumption. The throughput actually reflects the lifespan of the network and data transmission ability. Network energy consumption however, demonstrates the energy-efficiency, which indirectly implies the lifetime of network. From the simulations results, we can conclude that our protocol, RE
2WCA, is superior to original two protocols, EMDWCA and DWCA respectively
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}