A Modified Sufficient Descent Polak–Ribiére–Polyak Type Conjugate Gradient Method for Unconstrained Optimization Problems


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. The Modified PRP Method and Its Properties
| Algorithm 1 Modified PRP-type Conjugate Gradient Method |
|
3. Global Convergence of the ZPRP Method
- (i)
- The level set is bounded.
- (ii)
- In some neighborhood N of , f is continuously differentiable and its gradient is Lipschitz continuous, that is, there exists a constant such that .
4. Extension to the HS and LS Method
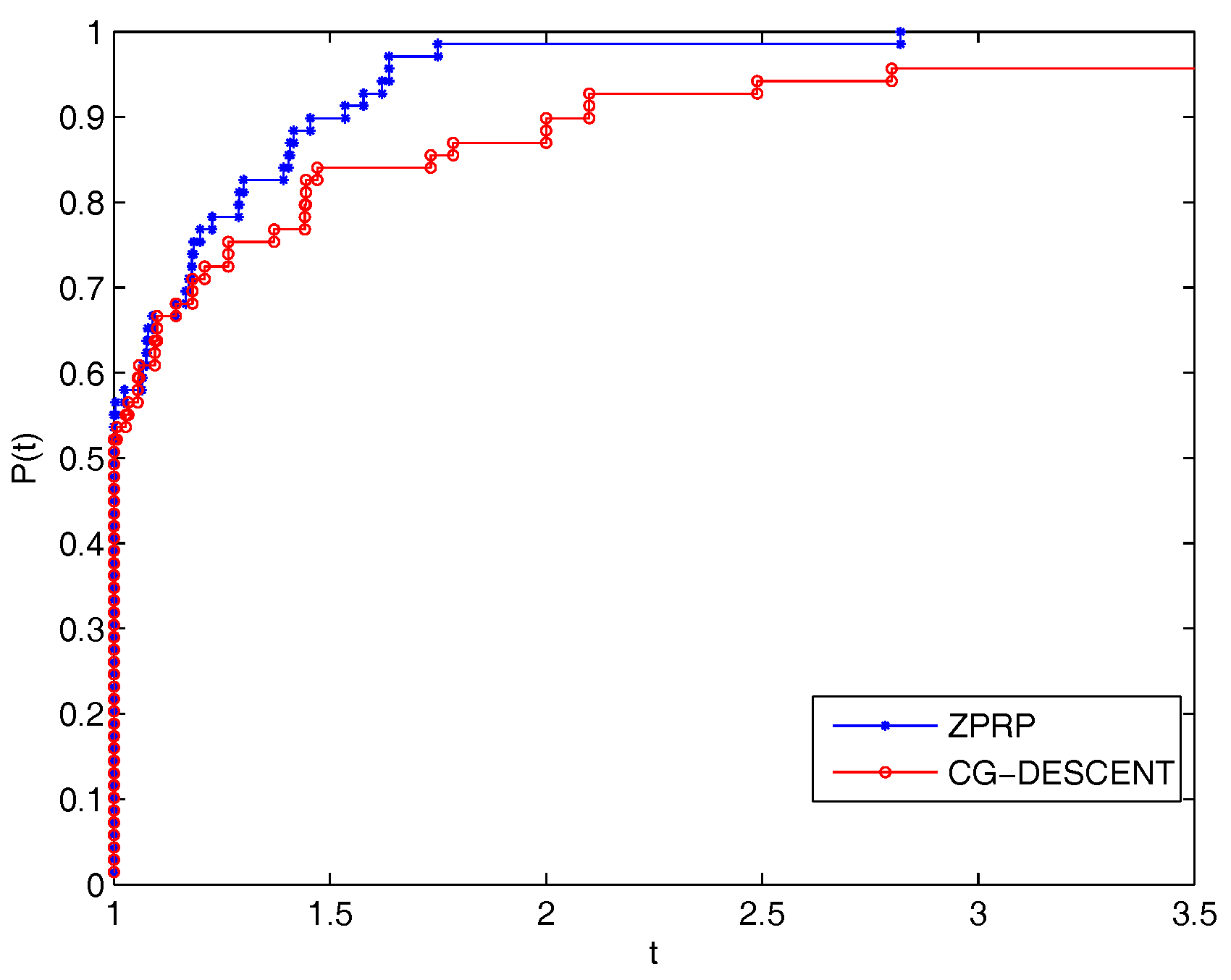
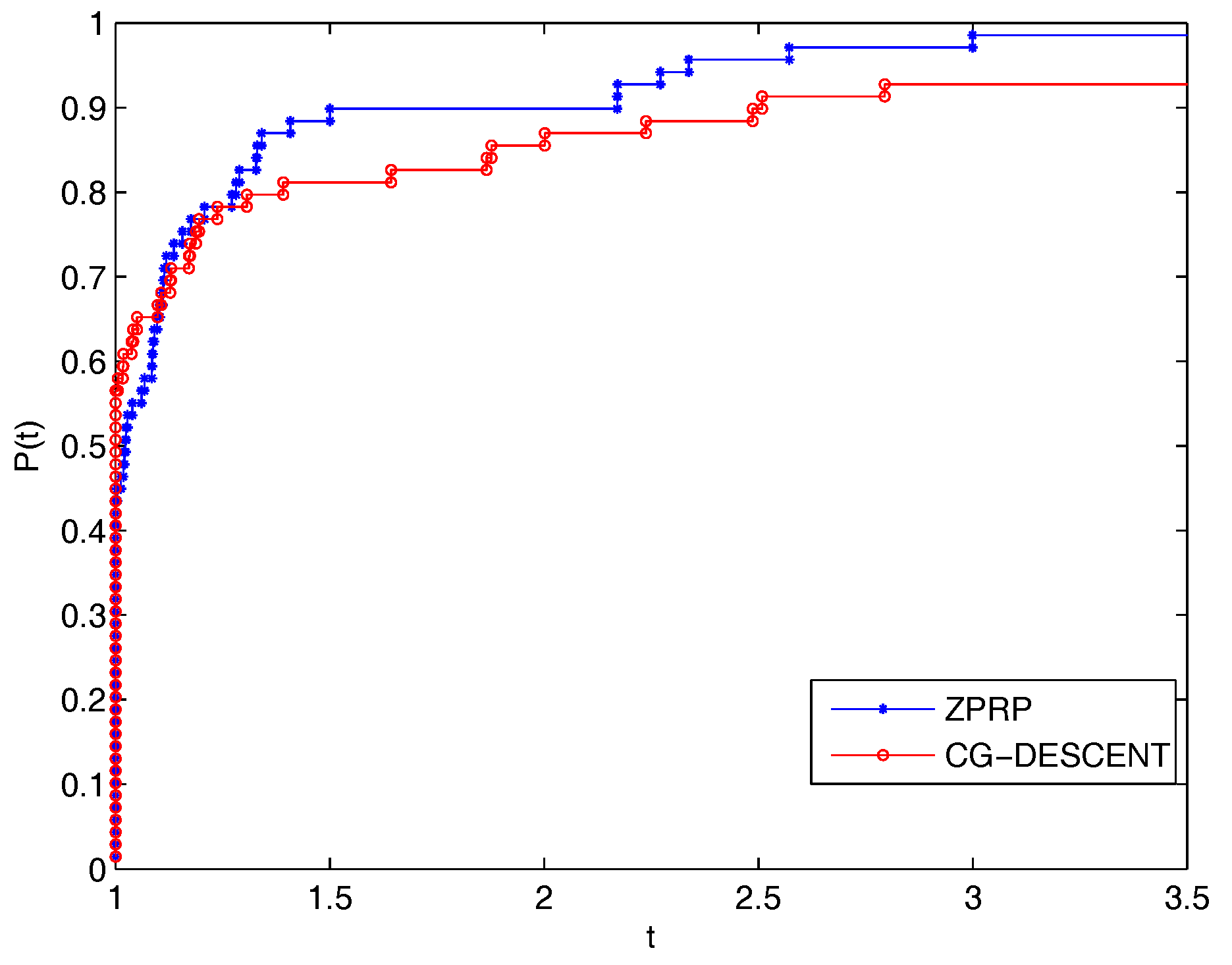
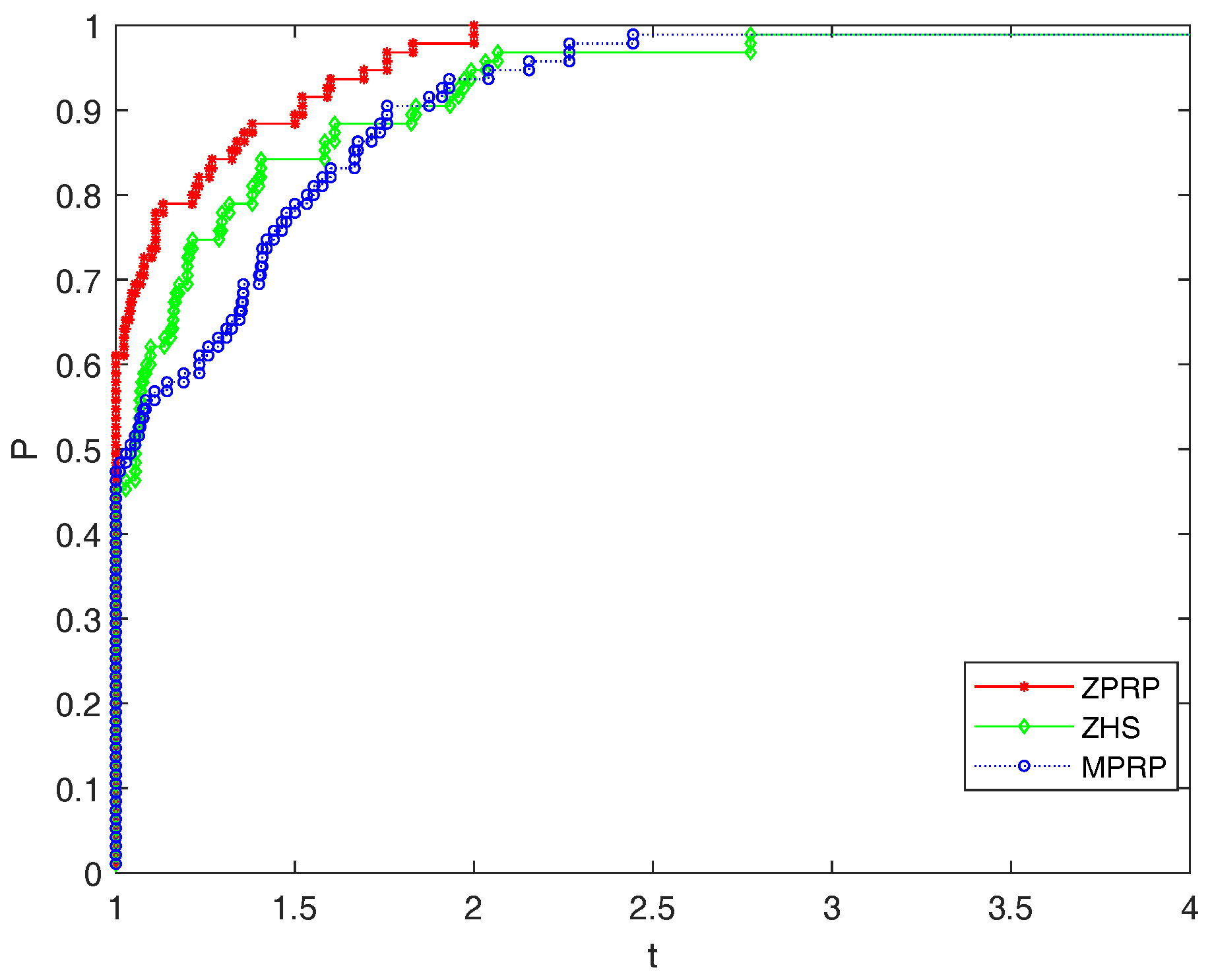
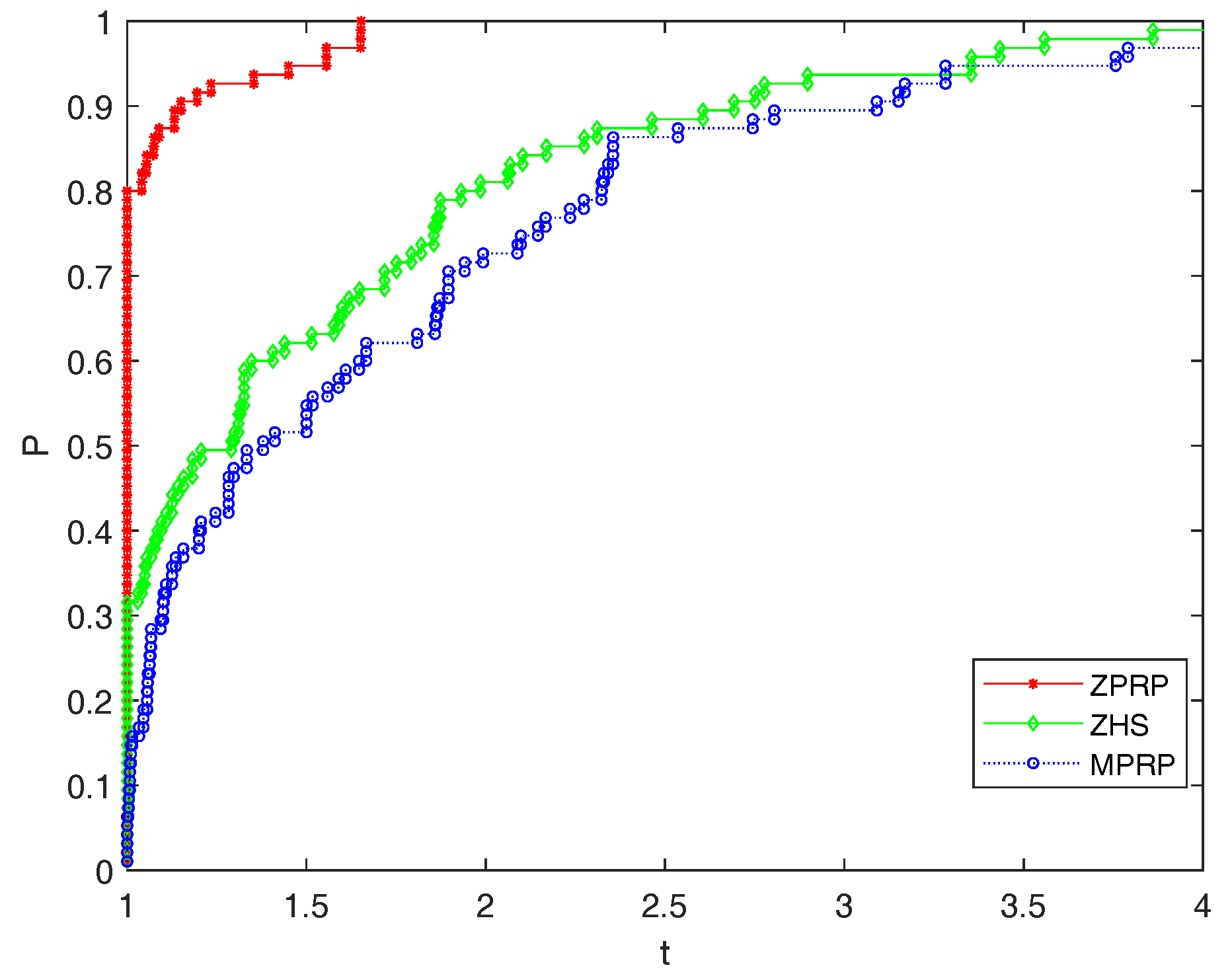
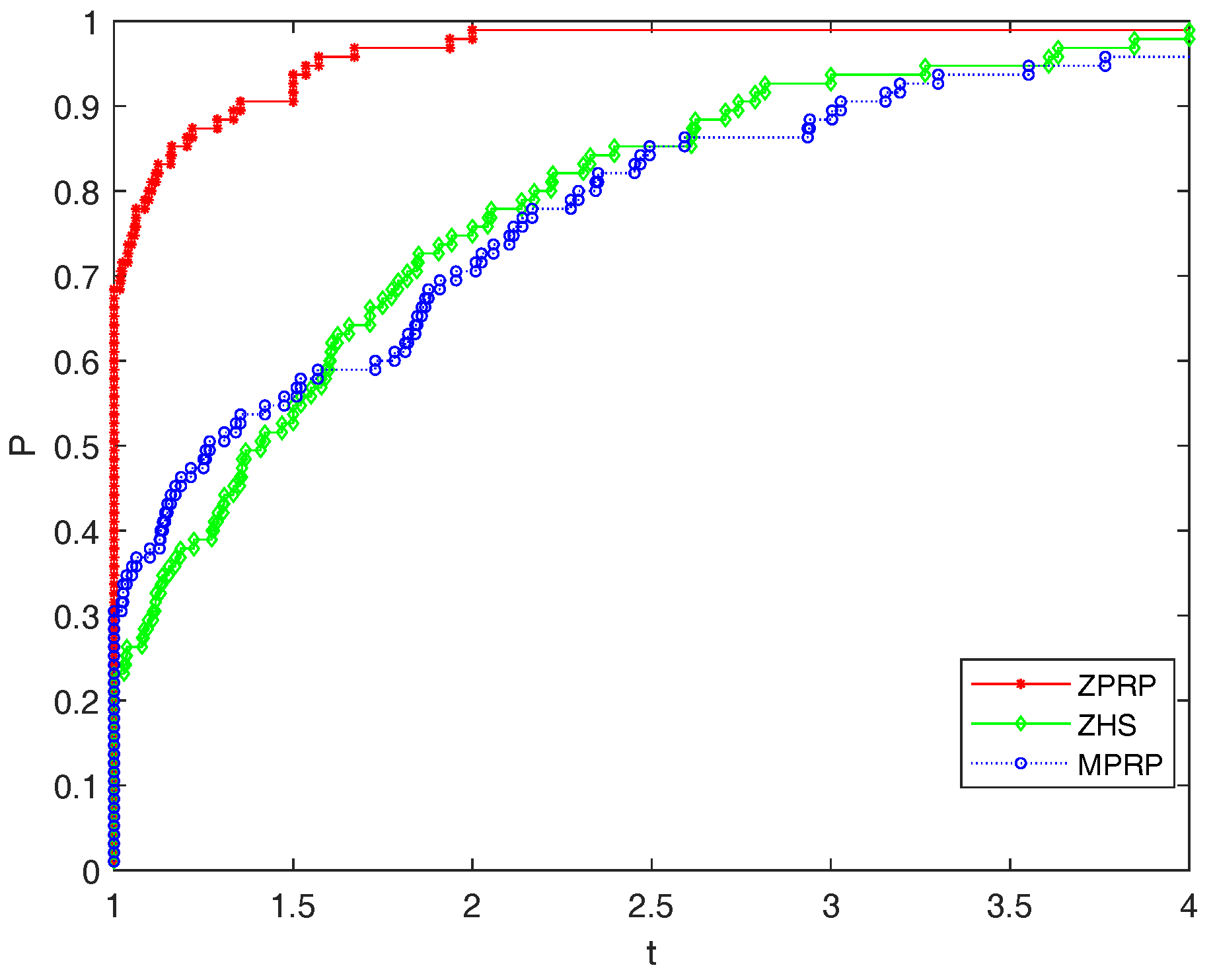
5. Numerical Experiments
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Dai, Y.; Yuan, Y. Nonlinear Conjugate Gradient Methods; Shanghai Scientific and Technical Publishers: Shanghai, China, 2000. [Google Scholar]
- Fletcher, R.; Reeves, C. Function minimization by conjugate gradients. Comput. J. 1964, 7, 149–154. [Google Scholar] [CrossRef] [Green Version]
- Hestenes, M.; Stiefel, E. Methods of conjugate gradient for solving linear systems. J. Res. Natl. Bur. Stand. 1952, 49, 409–436. [Google Scholar] [CrossRef]
- Polak, B.; Ribière, G. Note surla convergence des mèthodes de directions conjuguèes. Rev. Fr. Inform. Rech. Oper. 1969, 3, 35–43. [Google Scholar]
- Polyak, B. The conjugate gradient method in extreme problems. USSR Comput. Math. Math. Phys. 1969, 9, 94–112. [Google Scholar] [CrossRef]
- Liu, Y.; Sorey, C. Efficient generalized conjugate gradient algorithms. Part 1 Theory. J. Optim. Theory Appl. 1991, 69, 177–182. [Google Scholar] [CrossRef]
- Hager, W.W.; Zhang, H. A survey of nonlinear conjugate gradient methods. Pac. J. Optim. 2006, 2, 35–58. [Google Scholar]
- Gibert, J.; Nocedal, J. Global convergence properties of conjugate gradient methods for optimization. SIAM J. Optim. 1992, 2, 21–42. [Google Scholar] [CrossRef]
- Yuan, Y. Analysis on the conjugate gradient method. Optim. Method Softw. 1993, 2, 19–29. [Google Scholar] [CrossRef]
- Powell, M. Nonconvex minimization calculations and the conjugate gradient method. Numer. Anal. Lect. Notes Math. 1984, 1066, 122–141. [Google Scholar] [CrossRef]
- Hager, W.W.; Zhang, H. A new conjugate gradient method with guaranteed descent and an efficient line search. SIAM J. Optim. 2005, 16, 170–192. [Google Scholar] [CrossRef]
- Cheng, W. A Two-Term PRP-Based Descent Method. Numer. Func. Anal. Opt. 2007, 28, 1217–1230. [Google Scholar] [CrossRef]
- Yu, G.; Guan, L.; Li, G. Global convergence of modified Polak-Ribiére-Polyak conjugate gradient methods with sufficient descent property. J. Ind. Manag. Optim. 2008, 4, 565–579. [Google Scholar] [CrossRef]
- Yuan, G. Modified nonlinear conjugate gradient methods with sufficient descent property for large-scale optimization problems. Optim. Lett. 2009, 3, 11–21. [Google Scholar] [CrossRef]
- Livieris, I.; Pintelas, P. A new class of spectral conjugate gradient methods based on a modified secant equation for unconstrained optimization. J. Comput. Appl. Math. 2013, 239, 396–405. [Google Scholar] [CrossRef]
- Wei, Z.; Yao, S.; Liu, L. The convergence properties of some new conjugate gradient methods. Appl. Math. Comput. 2006, 183, 1341–1350. [Google Scholar] [CrossRef]
- Zhang, L. An improved Wei-Yao-Liu nonlinear conjugate gradient method for optimization computation. Appl. Math. Comput. 2009, 215, 2269–2274. [Google Scholar] [CrossRef]
- Zhang, L.; Zhou, W.; Li, D. A descent modified Polak-Ribière-Polyak conjugate gradient method and its global convergence. IMA J. Numer. Anal. 2006, 26, 629–640. [Google Scholar] [CrossRef]
- Dong, X.; Liu, H.; He, Y.; Babaie-Kafaki, S.; Ghanbari, R. A New Three-Term Conjugate Gradient Method with Descent Direction for Unconstrained Optimization. Math. Model. Anal. 2016, 21, 399–411. [Google Scholar] [CrossRef]
- Zoutendijk, G. Nonlinear Programming, Computational Methods. In Ineger and Nonlinear Programming; Abadie, J., Ed.; North-Holland: Amsterdam, The Netherlands, 1970; pp. 37–86. [Google Scholar]
- Bongartz, K.; Conn, A.; Gould, N.; Toint, P. CUTE: Constrained and unconstrained testing environments. ACM T. Math. Softw. 1995, 21, 123–160. [Google Scholar] [CrossRef]
- Dolan, E.; Morè, J. Benchmarking optimization software with performance profiles. Math. Program. 2002, 91, 201–213. [Google Scholar] [CrossRef] [Green Version]






© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, X.; Shi, J. A Modified Sufficient Descent Polak–Ribiére–Polyak Type Conjugate Gradient Method for Unconstrained Optimization Problems. Algorithms 2018, 11, 133. https://doi.org/10.3390/a11090133
Zheng X, Shi J. A Modified Sufficient Descent Polak–Ribiére–Polyak Type Conjugate Gradient Method for Unconstrained Optimization Problems. Algorithms. 2018; 11(9):133. https://doi.org/10.3390/a11090133
Chicago/Turabian StyleZheng, Xiuyun, and Jiarong Shi. 2018. "A Modified Sufficient Descent Polak–Ribiére–Polyak Type Conjugate Gradient Method for Unconstrained Optimization Problems" Algorithms 11, no. 9: 133. https://doi.org/10.3390/a11090133
APA StyleZheng, X., & Shi, J. (2018). A Modified Sufficient Descent Polak–Ribiére–Polyak Type Conjugate Gradient Method for Unconstrained Optimization Problems. Algorithms, 11(9), 133. https://doi.org/10.3390/a11090133