4.1. DataSet
In order to verify the effectiveness of the DM-CPDP method, we validate the performance of the prediction model through experiments and compare it with other methods. In this paper, we selected 14 datasets in NASA and 3 datasets in SOFTLAB to experiment. The datasets of NASA and SOFTLAB are obtained from PROMISE repository. The PROMISE repository is constantly updating datasets. Compared to the datasets used in some of the previous papers [
8,
12], the current datasets have some variation in the number of samples, but its internal structure has not changed to some extent. Since this paper constructing cross-project software defect prediction model based on multi-source datasets, the impact of some change in the number of samples on the experimental results is limited. To facilitate comparison with previous studies, we used previous versions of datasets maintained by the PROMISE repository. These datasets are shown in
Table 1.
These datasets are derived from different projects, and the data distribution as well as feature attributes are different. We choose the common attributes of the target set and the source domain dataset to build the prediction models.
Table 2 shows the metrics of the software features used in the experiment. It mainly includes McCabe metric element, Line Countmetric element, Halstead basic metric element, and its extension DHalstead metric element.
To facilitate comparison, we performed two parts of the experiment on the data sets: NASA to NASA, NASA to SOFTLAB.
NASA to NASA: Only the NASA is used as the target set and the training set. Each dataset belonging to the NASA is chosen as the target set, and the remaining data sets are used as the training set.
NASA to SOFTLAB: All datasets belonging to NASA are used as source domain datasets, and datasets in SOFTLAB are used as the target sets.
4.2. Performance Index
In this paper, the prediction results are measured according to the indexes of F-measure, AUC (Area Under ROC Curve), and cost-effectiveness. The performance index is calculated based on the confusion matrix shown in
Table 3.
True Positive (TP): represents the number of positive samples predicted as positive classes.
False Positive (FP): represents the number of positive samples predicted as negative classes.
False Negative (FN): represents the number of negative samples predicted as positive clasess.
True Negative (TN): represents the number of negative samples predicted as negative classes.
F-measure is determined by both recall and precision, and its value is close to the smaller value of both. So that the larger F-measure means that both recall and precision are larger, the formula is shown in (13), where α is used to regulate the relative importance of precision and recall, and its value is usually at 1.
Recall is the ratio of correctly predicting the number of defective modules to the number of real defective modules, indicating how many positive samples are correctly predicted.
Precision is the ratio between correctly predicting the number of defective modules and the number of all predicted defective modules, indicating how many predictions are correct in positive samples.
AUC is defined as the area under the receiver operating characteristics (ROC) curve. This performance indicator is one of the criteria for judging the two-category model.
Cost-effectiveness refers to maximizing benefits by spending the same cost. Cost-effectiveness measures the percentage of defects that can be identified by the predictive model by examining the top 20 percent of the samples [
11,
25]. Zhang et al. consider that the cost of software includes not only the effort of inspecting the defective modules, but also the failure cost of classifying a defective sample as a non-defective sample [
26]. Incorrectly predicted defective samples will have a greater impact on software. Therefore, they propose a measurement method based on confusion matrix, and the cost-effectiveness is calculated according to the Equation (16). Compared with other methods, this method is more concise, and it is not affected by the order and the size of defect modules. The smaller the value means the lower the false negative of the prediction result of the model, and the more defective modules can be correctly predicted. So, the cost of failure caused by the software in the later stage is being lower.
4.3. Analysis of Results
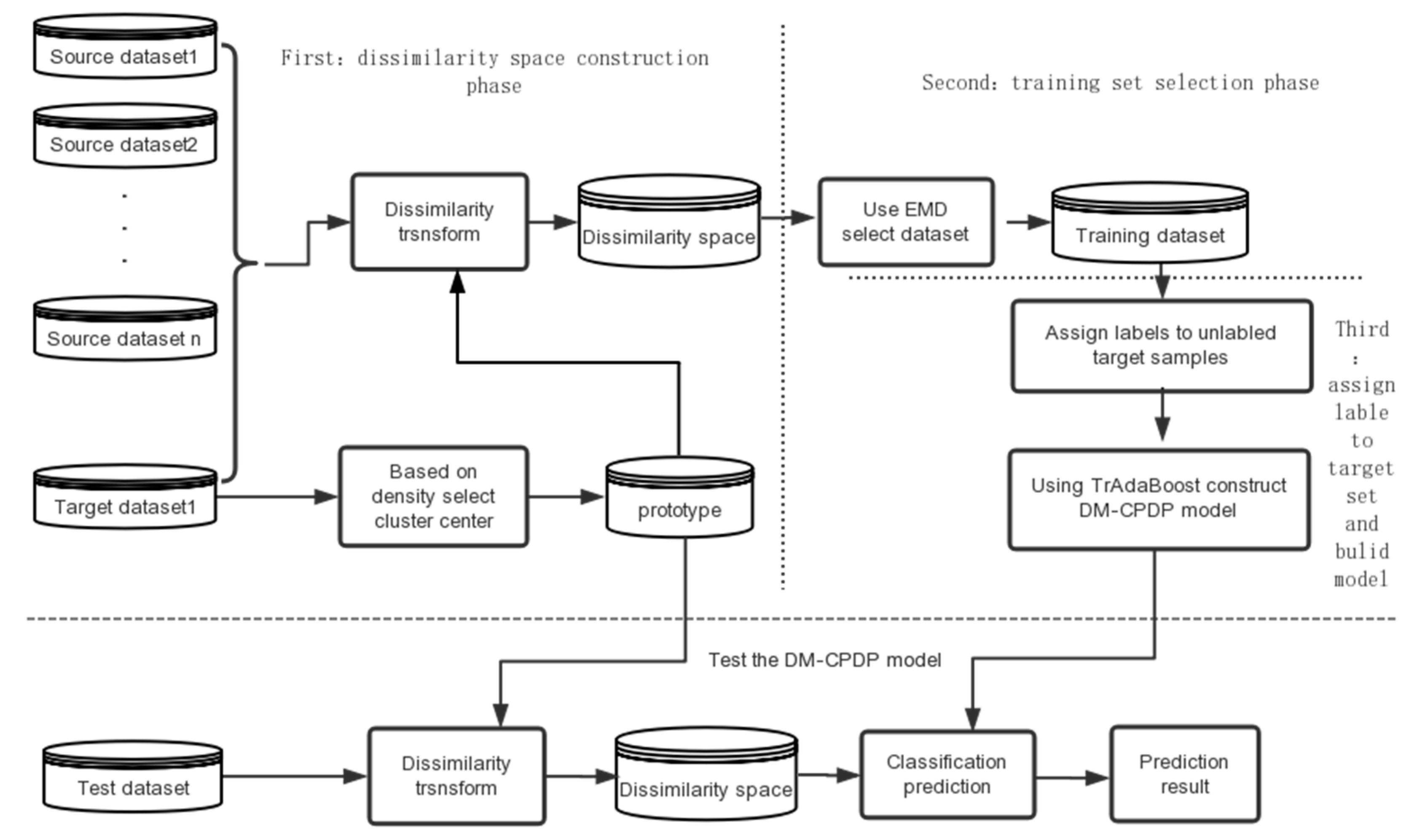
By comparing with traditional single-source and multi-source defect prediction methods, we prove that establishing prediction models in the dissimilarity space can improve the performance of the prediction model, and prove the superiority of the DM-CPDP method. The construction of classifier in the dissimilarity space is mainly influenced by two factors: dissimilarity metric and prototype selection. We compared the effects of different dissimilarity metric and prototype selection methods on the experimental results. In addition, the necessity of multi-source data in CPDP is also be verified.
4.3.1. Experiment on Different Methods
In order to verify the superiority of the DM-CPDP method, we compare it with traditional CPDP models.
In this part, we conduct experiments on NASA to NASA and NASA to SOFTLAB respectively. Among many traditional CPDP methods, this paper chooses three classical comparison methods, such as TNB, MSTrA, and HYDRA method. In each experiment, 90% of the source data set and target set are selected randomly as the training set, and the data of remaining target set are used as the test set. Each experiment was repeated 10 times, and the average values of these experiments are obtained from the results. The experimental details of each method are as follows:
TNB: randomly selects a dataset as the training set, and assigns weights to the training samples according to the target set using data gravity. Finally, the defect prediction model is built using the NB algorithm.
MSTrA: selects multiple data sets as training set and distributes weights for each training data according to the target set using data gravitation. In each iteration, each source domain data set is matched with the target set to train weak classifiers, and the weak classifier in the current iteration with the lowest error rate on the target set is selected.
HYDRA: merges each candidate source and target dataset as the training set to construct multiple base-classifiers, and then use the genetic algorithm to find the optimal combination of base-classifiers. After that, the process which is similar to the AdaBoost algorithm is used to obtain a linear combination of GA models.
The results are shown in
Table 4,
Table 5 and
Table 6, bold numbers indicate optimal results on a dataset.
It can be seen that the DM-CPDP method outperforms several existing algorithms on most data sets. In the NASA to SOFTLAB experiments, the performance of each algorithm on SOFTLAB data sets is stable. DM-CPDP method is better than the other algorithms. The average value of F-measure and AUC are 2.8%–27.3% and 1.7%–7.8% respectively, which is higher than other algorithm. In addition, the average value of the cost-effectiveness for the DM-CPDP method is 1%–4.9%, which is lower than other algorithms.
In the NASA to NASA experiment, the average value of DM-CPDP method on F-measure and AUC are higher than other methods: 4.4%–28.8%, 5.5%–13.0% respectively. The average value of DM-CPDP method on cost-effectiveness is lower than other methods 0.2%–1.8%. For the three metrics of F-measure, AUC, and cost-effectiveness, they are 9, 9, and 10 datasets respectively showing the best performance on the DM-CPDP method. For the HYDRA, there are 4, 4, and 3 datasets respectively showing the best performance. For the MSTrA method, only one dataset shows the best performance on the F-measure indicator. For the TNB method, there is one dataset performs optimally on AUC and cost-effectiveness respectively.
The reason for the above phenomenon is the influence of data distribution. Different machine learning methods behave different on the same data set, and the same machine learning method performs differently on different datasets. DM-CPDP is still superior to other algorithms in general. The reason is that this method uses multi-source datasets and dissimilarity representation method. By comparing with these three classic CPDP methods, it can be proved that DM-CPDP method performs well in the field of CPDP.
4.3.2. Experiments on Multi-Source Data Sets and Dissimilarity Space
In order to verify the impact of multi-source data and sample dissimilarity representation on the performance of predictive models, we compare the TrAdaBoost, Multi-source TrAdaBoost, dissimilarity space based single-source CPDP (DS-CPDP) method, and DM-CPDP method. All the comparisons base on F-measure, AUC, and cost-effectiveness to complete. Each experiment was repeated 10 times, and the average values of these experiments are obtained from the results. The experimental details of each method are as follows:
TrAdaBoost: randomly selects 90% of the source domain data set and target set as the training set, and the remaining target set as the test set. The prediction model was built using TrAdaBoost.
Multi-source TrAdaBoost: before using the TrAdaBoost algorithm to build a prediction model, the EMD method is used to select multiple data sets that are highly correlated with the target set, then these data sets are combined with the target set as a training set. Finally, the TrAdaBoost algorithm is used for modeling.
DS-CPDP: randomly selects a data set from the source domain for dissimilarity transformation as the training set, and then uses KNN method to assign labels to unlabeled target, after that use the TrAdaBoost method to build the model.
The experimental results are shown in
Table 7,
Table 8 and
Table 9, bold numbers indicate optimal results on a dataset.
In order to prove the importance of multi-source data, we verify it in the dissimilarity space and the feature space respectively. By comparing the results of DM-CPDP and DS-CPDP method, it can be found that DM-CPDP is superior to DS-CPDP in the three indexes of F-measure, AUC, and cost-effectiveness in the dissimilarity space. The average value of F-measure is higher than the DS-CPDP method by 6.4% and 3.2% in the two series of datasets respectively. The average value of AUC is higher than the DS-CPDP method by 7.0% and 5.4%. The average value of cost-effectiveness is lower than the DS-CPDP method by 1.1% and 0.4%. By comparing the results of TrAdaBoost and Multi-source TrAdaBoost, it can be found that the Multi-source TrAdaBoost method is better than the TrAdaBoost in the feature space, and the average value of F-measure is higher than the TrAdaBoost method by 2.1%, 8.9%. The average value of AUC is higher than the TrAdaBoost method by 2.3%, 7.6%. The average value of cost-effectiveness is lower than the TrAdaBoost method by 3.5%, 0.8%. These results prove that the CPDP method based on multi-source data can improve the performance of prediction models, whether in the dissimilarity space or in the feature space.
The reason why multi-source data is superior to single-source data is that multi-source method in CPDP can not only increase the useful information by providing sufficient data, but also effectively avoid the problem of negative transferring. Besides, in the process of modeling, we also filter the multi-source datasets and select the data highly correlated with the target set as the training set. So that the data distribution of the training set and the target set is as similar as possible. Thus, multi-source data can improve the predictive performance of classifiers.
In order to verify that the construction of dissimilarity space can improve the performance of the classifier, these two sets of experiments are compared: TrAdaBoost and DS-CPDP, Multi-source TrAdaBoost and DM-CPDP. From the experimental results in
Table 7,
Table 8 and
Table 9, the average value of F-measure on DS-CPDP is 13.2% and 11.4% respectively, which is higher than the TrAdaBoost algorithm. The average value on AUC is higher than the latter by 8.2%, 10.6%. The average value on cost-effectiveness is lower than the latter by 5.7%, 1.3%. By comparing DM-CPDP with Multi-source TrAdaBoost, we can find that the former is better than the latter in the average value of the two performance indicators. The average value of F-measure in the former is higher than that in the latter 17.5% and 5.7% respectively. In terms of AUC, the former is better than the latter 12.9% and 8.4% respectively. The average value on cost-effectiveness is lower than the latter by 3.3%, 0.9%. Therefore, it can be proved that the model established in the dissimilarity space is better than that built in the feature space.
There are three reasons why constructing dissimilarity space can improve the performance of prediction models.
Firstly, the classification algorithm essentially establishes the classifier by analyzing the intrinsic relationship between the feature attributes and the class labels in the datasets. If the feature attributes of samples have the weak discriminant ability to class labels, the performance of the prediction model will be affected, but building a dissimilarity space can solve this problem. When constructing the space, we use the dissimilarity between samples instead of the original feature attribute, so that the intrinsic structure information of the dataset can be obtained. Thus, the discriminant ability of sample attributes to class labels is enhanced.
Secondly, the DM-CPDP method uses the data from the target set as the prototype set when constructing the dissimilarity space. Therefore, when mapping the samples belonging to the source domain to the dissimilarity space, it essentially carries out comprehensive transferring learning. So, the training set with the same data distribution as the target set can be obtained, which better meets the requirements of the hypothesis of the same data distribution.
Finally, when using the source domain and target domain data to construct dissimilarity space, each sample is represented as the dissimilarity between the sample and the prototype set. If the dissimilarity between the samples is small, a larger attribute value can be obtained. So that these samples with high similarity to the target set will gain higher attention during the modeling process, and the performance of the classifier will be improved.
By analyzing the above reasons, we can conclude that using multi-source datasets and dissimilarity space can improve the performance of the classifier, and the experimental results also prove this conclusion very.
4.3.3. Different Dissimilarity Metric Method
In this part, we compare the effects of several different dissimilarity metric methods on the experimental results and verify which measurement is efficient in CPDP.
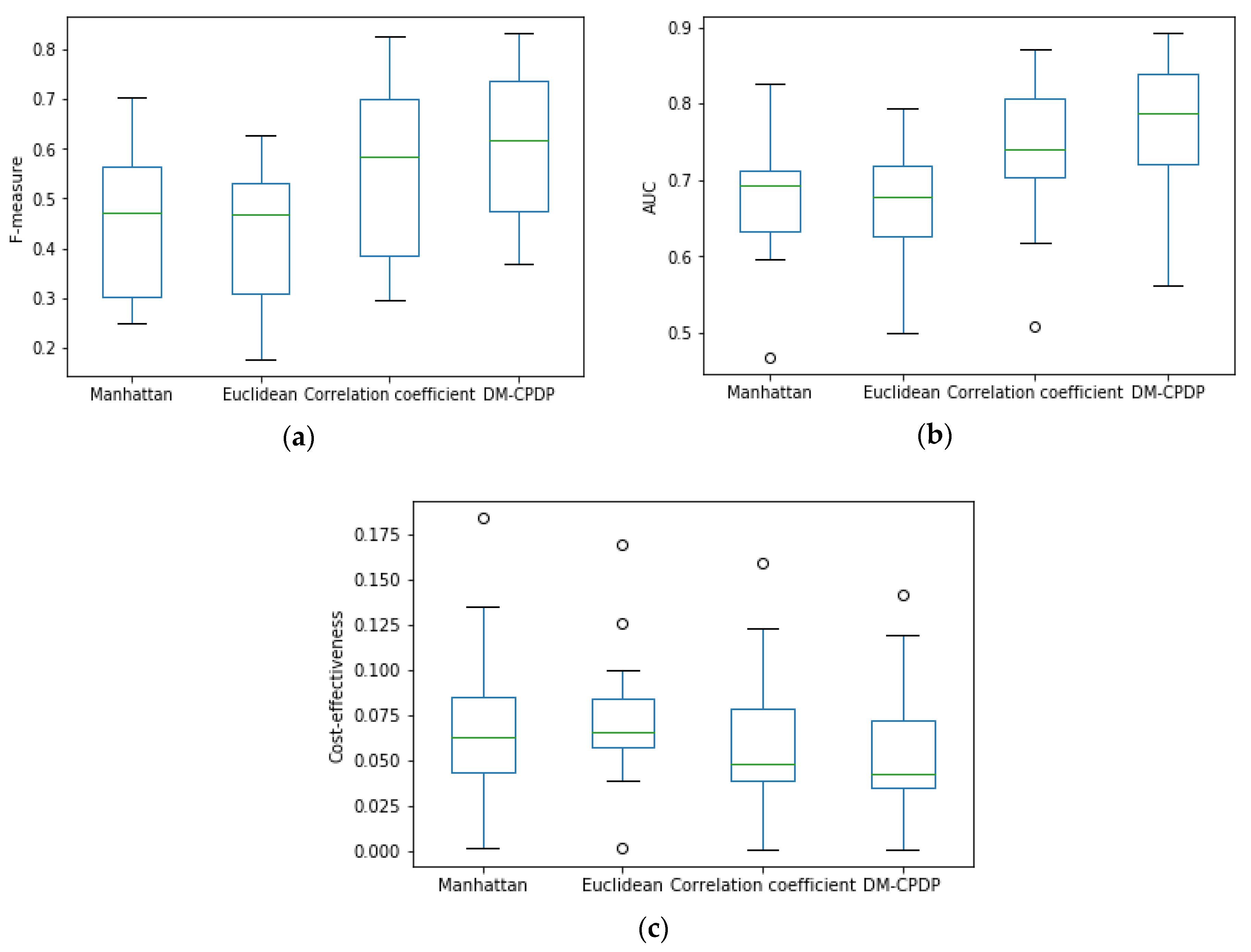
Figure 4 is the box plot of performance indicators, which compare the values of several different dissimilarity metric methods on F-measure, AUC, and cost-effectiveness. Euclidean distance, Manhattan distance, and correlation coefficient are chosen as the measurement of dissimilarity.
The experimental results show that the prediction model using Manhattan distance and Euclidean distance as the measurements of dissimilarity are poor. The value of median, quartile, maximum, and minimum on F-measure and AUC are lower than the arc-cosine kernel. These values on cost-effectiveness are higher than the arc-cosine kernel. During the course of the experiment, we found that the average values of the arc-cosine kernel method on F-measure and AUC are still higher than those three methods, and cost-effectiveness index of arc-cosine kernel method is lower than other methods. In addition, it can be seen from the box plot that when the correlation coefficient is used as the measuring method, the value of median, quartile, maximum, and minimum on F-measure, AUC, and cost-effectiveness are still inferior to the arc-cosine kernel, but superior to the Manhattan and Euclidean distances.
The reasons for these results are as follows. When the relationship between samples is measured by Euclidean distance and Manhattan distance, if the sample and the prototype data are highly correlated, the attribute value of the sample in the dissimilarity space is lower. So that the samples with the same distribution to the target set receive less attention in the process of modeling. Correlation coefficient as the measurement is opposite to the above two methods. This method makes the same distribution samples get higher attention when building the classifier. The arc-cosine kernel function is superior to other methods because the kernel function can better represent the intrinsic relationship between samples, and more attention can be paid to the data that is highly correlated with the target sample in the process of modeling. So it can be concluded that using the arc-cosine kernel function as the measuring method of dissimilarity between samples works better.
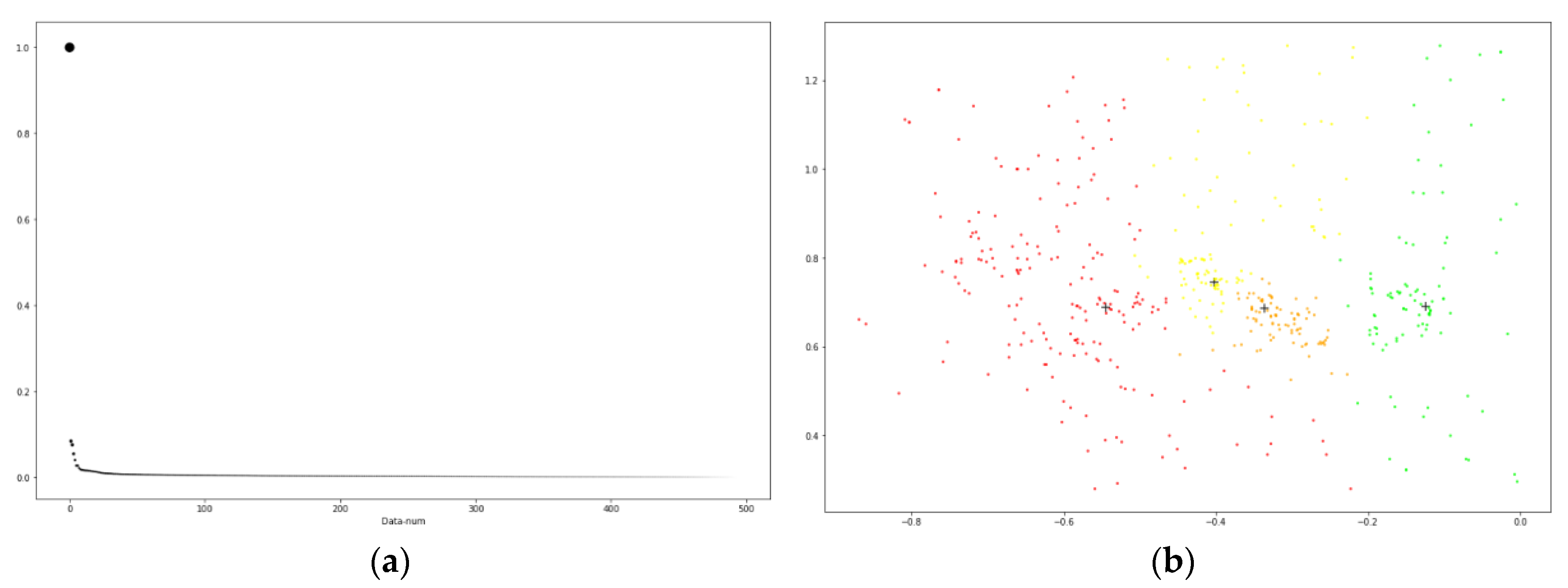
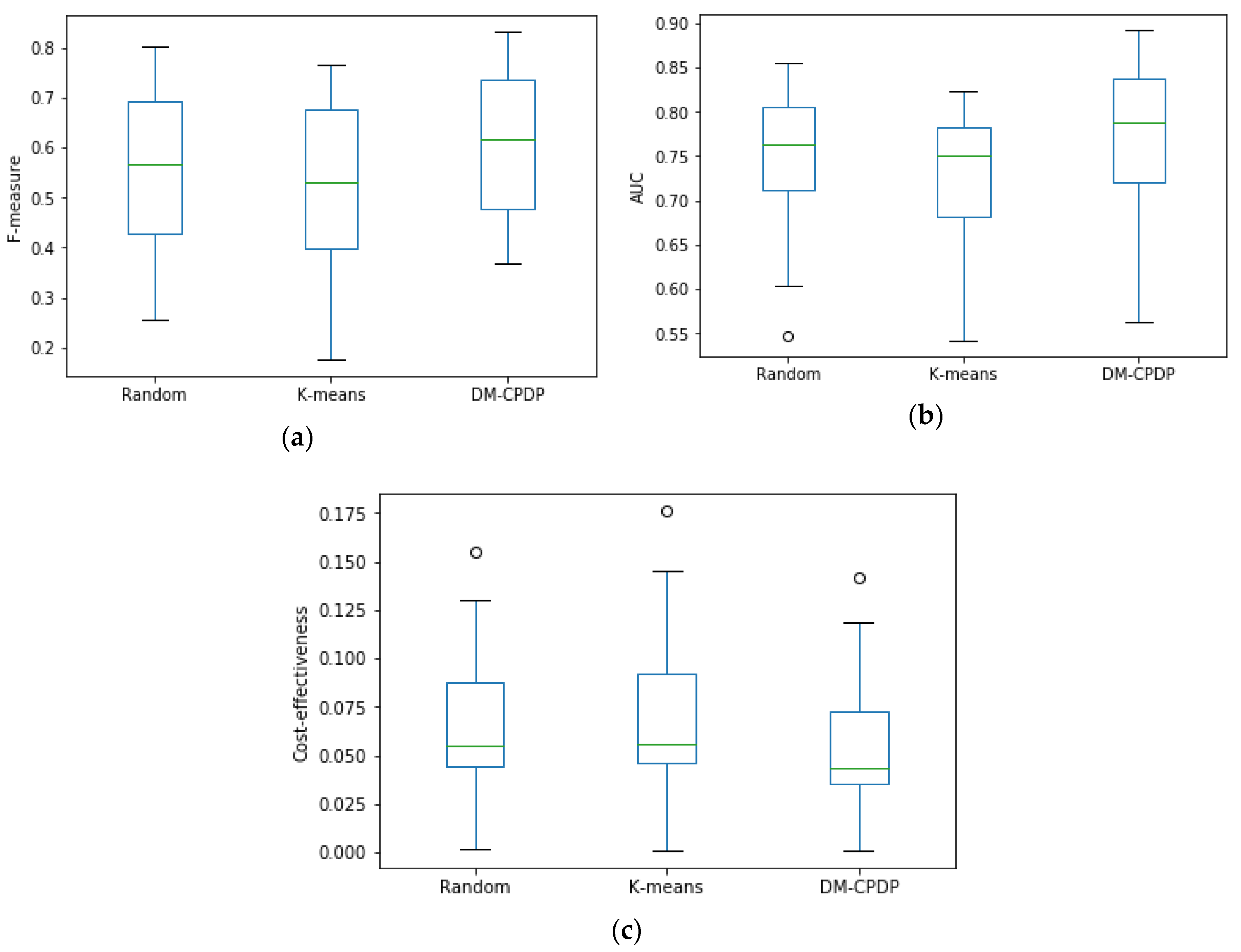
4.3.4. Different Prototype Set Selection Methods
In this part, we compare the effects of several different prototype set selection methods on the experimental results.
Figure 5 compares three different methods of prototype set selection, namely random algorithm, the K-means algorithm, and the DPC method for DM-CPDP. For the random method, researchers generally select 3%–10% of the dataset [
27]. When using the random method to select the prototype set, we select
r samples as the prototype set,
(
I is the number of the instance), and repeat the results 10 times to take the mean. When using the K-means method, we also select
r samples as the initial cluster center for clustering and select the output cluster center as the prototype set.
It can be seen from the box plot that the density-based prototype selection method used in this paper is better than the random selection method and the K-means clustering method. In
Figure 5, the density-based prototype selection method used by the DM-CPDP has higher value of median, quartile, maximum, and minimum on the F-measure and AUC than the other two methods. These cost-effectiveness values for density-based prototype selection method are lower than other methods. However, the K-means clustering method performs the worst, so this method is not suitable for prototype selection.
The reason for this problem is that the K-means algorithm is not suitable for solving non-spherical clusters and is greatly affected by outliers. Although the average effect of random selection is ideal, the prediction results are unstable due to the randomness of the instance selection. Therefore, it is reasonable to use the DPC method for prototype selection.
4.3.5. Experiment on Different Dataset Selection Methods
In this part of the experiment, we compare the effects of different dataset selection methods on the experimental results, bold numbers indicate optimal results on a dataset.
Since the samples have been mapped into the dissimilarity space, the dataset selection method based on extracting the feature vectors is no longer applicable. Thus, we compare the EMD with another method. In each dissimilarity subspace, we select the value of the smallest attribute in each sample and take the mean value to measure the similarity between the source domain data set and the prototype set. Then, the values are sorted in descending order and the first α datasets are selected as the training data. This approach is named as Method 1 [
7]. The calculation is as follows:
The experimental results are shown in
Table 10. The results show that the performance of dataset selection method based on EMD is superior to Method1 in F-measure, AUC, and cost-effectiveness. The reason for this phenomenon is that when comparing the similarity between datasets, Method 1 has lost more information by selecting the minimum attribute and averaging these attribute values, which leads to inaccurate measurement results. However, the EMD method takes into account each attribute of the sample, so the performance of the prediction model is better.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}