1. Introduction
Computer vision (CV) applications have recently witnessed a revolution, thanks to deep learning techniques which leverage hierarchical pattern learning techniques and vast amounts of data to solve several challenging tasks with high accuracy. Despite their high recognition performance, as a natural result of using a specific dataset, even the deep models are biased to the domain from which the data are collected; which causes the performance of these models to decrease dramatically when tested against datasets from different domains.
The primitive solution to this problem is to adapt the model to the new (or target) domain by re-training the model on the data from the target domain. However, the collection of new data and the re-training of the whole model can be difficult, expensive, and even impossible. Hence, a better approach is to store the knowledge learned in the primary domain and later transfer that knowledge to a target domain sharing the same tasks but potentially following a different distribution. This can help in reducing the cost of data re-collection and its labelling.
More formally, let
and
be the source and target domains, respectively. Domain adaptation (DA), which is a sub-field of transductive transfer learning (TTL), aims to solve a problem in
, where data are hard to collect, using data from
. Both domains, usually, share the same tasks (i.e.,
=
) but the marginal distributions of the inputs differ (i.e.,
), as shown in
Figure 1. DA is usually achieved by learning a shared feature space (i.e.,
=
) [
1].
There is a sizeable literature on DA. It can be categorized as either closed-set [
2] or open-set [
3,
4]. Closed-set DA is the case where the classes of
are the same as that of
. Our work belongs to closed-set DA. On the other hand, open-set DA handles the case where only a few classes are shared between the two domains, and the source or the target domain might contain more classes.
Similar to other machine learning tasks, DA can be split into supervised, unsupervised, and semi-supervised, depending on how much labeled data are available from
. For supervised domain adaptation (SDA) [
5] and semi-supervised domain adaptation (SSDA) [
6], the data are completely or partially labeled, but are not sufficient enough to train an accurate model for the target domain from scratch. In unsupervised domain adaptation (UDA) [
7,
8] the target domain samples are completely unlabeled, which is useful in situations where the data collection process is easy but the data labeling process is time consuming.
The extreme case of DA is when we don’t have any access to the target data, which is called domain generalization (DG). In DG, researchers have mainly used easy-to-collect datasets from different domains to make a model that can generalize well to unseen domains [
9].
The focus of this work is on UDA, which typically needs large amounts of target data, especially in the case of deep unsupervised domain adaptation (DUDA). Although the focus is on DUDA because of the wide variety of real-world applications that it can solve, we use SDA as an upper bound to aim for, because SDA typically outperforms UDA, and we will exploit this fact to make our model perform even better by using a concept called pseudo-labelling [
10]. Most of the previous DUDA approaches aimed at achieving two targets: (i) Produce (or learn) feature vectors from the data from
that can be used by a classifier to get highly accurate class labels, and (ii) make the features of both
and
indistinguishable. Both Z. Ren et al., in [
11], and Lanqing Hu et al., in [
12], used generative models in different manners to achieve those targets. The former used Generative Adversarial Networks (GAN) to reconstruct various property maps of the source images while keeping the features extracted of both domains similar by training a base encoder on the opposite loss of the discriminator. The latter work used a duplex GAN architecture that could reconstruct the input images in both flavours, source and target, using the features extracted from the encoder. Next, a duplex discriminator was trained to distinguish the reconstructed images into source and target.
Our model is motivated by the latter work, yet it is much simpler. More specifically, we show that the generative part is hard to train and is not necessary to obtain a domain adaptive model. By introducing novel loss functions, we show that our model produces comparable results to the state-of-the-art models in a computationally efficient way.
To conclude, in this work, we make the following contributions:
We implement a novel DUDA technique for image classification. Deep (D) because it consists of an auto-encoder, a discriminator, and a classifier—all of which are simple deep networks. Unsupervised (U) because we do not use the actual annotations of the target domain. Domain adaptation (DA) because, while learning the model using source data, we adapt it such that it performs well on the target domain, too.
Our approach obtains a domain adaptive model by introducing separability loss, discrimination loss, and classification loss, which works by generating a latent representation that is both domain-invariant and class informative, by pushing samples from the same classes and different domains to share similar distributions.
We compare the performance of our model against several existing state-of-the-art works in DA on different image classification tasks.
Through extensive experimentation, we show that our model, despite its simplicity, either surpasses or achieves similar performance to that of the state-of-the-art in DA.
The rest of the sections are organized as follows:
Section 2 provides a brief of the main contributions in DA.
Section 3 presents our model architecture and our novel loss function. Details of our experimental setup, datasets, and empirical results are shown in
Section 4. Finally,
Section 5 wraps up the paper.
4. Experiments and Results
We compared our model with several state of the art models, including DupGAN [
12], TarGan [
24], Maximum Classifier Discrepancy (MCD) [
29], Gen2Adpt [
25], SimNet [
13], Domain-Adversarial Training of Neural Networks (DANN) [
30,
31], T. Adversarial Discriminative Domain Adaptation (ADDA) [
32], Domain Separation Networks (DSN) [
33], Deep Reconstruction-Classification Networks (DRCN) [
34], Coupled Generative Adversarial Networks (CoGAN) [
35], Unsupervised Image-to-Image Translation Networks (UNIT) [
36], RevGrad [
30], PixelDA [
37], kNN-Ad [
20], Image2Image [
21], and Asymmetric Tri-training for Unsupervised Domain Adaptation (ATDA) [
27], for digit classification and object recognition. As we followed the same experimental set-up as the one that was employed for the compared networks, we evaluated our model based on the accuracy on the target test set, as this was the most-used metric within the previous works, which will enable us to compare it with the previously-mentioned papers using their reported results. The comparison will be made on three different tasks: (1) Digit classification, (2) object recognition, and (3) simulation-to-real object recognition. Then, we compare our model against DupGAN in terms of complexity (number of iterations).
We will also compare our model against itself, using just the encoder and the classifier trained on the source domain only (noted as training on source only) and the target domain only (noted as training on target labels) to give a lower bound and approximation of the upper bound. This comparison, shown in Table 4, shows the degradation of the accuracy of the target domain before domain adaptation in the EC-SourceOnly row. This demonstrates the effectiveness and the usefulness of the adaptation technique generally, and our model specifically.
4.1. Target Accuracy Comparison
4.1.1. Digit Classification
Our model was evaluated for UDA for the digit classification task, where the labels are 0 ∼ 9, using different datasets: MNIST of handwritten digits [
38], SVHN of street houses numbers [
39]; and the USPS [
40] of U.S. Postal Service Handwritten Digit Database. These datasets were chosen because they have different distributions and their labels are present for validation and evaluation. We used 60,000 images from MNIST from its training part and 10,000 images from its evaluation part. USPS is a relatively smaller dataset, from which we used 7291 images for training and 2007 images for testing. Finally, SVHN had 73,257 images for training, 26,032 images for testing, and SVHN
extra had 531,131 additional images for training. Our experiments were SVHN → MNIST, USPS ↔ MNIST, and SVHN
extra→ MNIST.
The target accuracy results are shown in
Table 1, where we can see first the decrease in performance when changing the domain (first two rows): For SVHN → MNIST, we see a decrease of 36.6%; on average, there was a 23% decrease across all experiments, proving the need for domain adaptation methods. Our novel model either exceeded the compared methods or approached the highest-achieved results. It is also noteworthy that our model was so close to the results of a model that was trained on the target only, and surpassed it in some cases. This is due to the use of the separation loss and the discriminator, which allowed our latent representations to be domain-invariant, as seen in
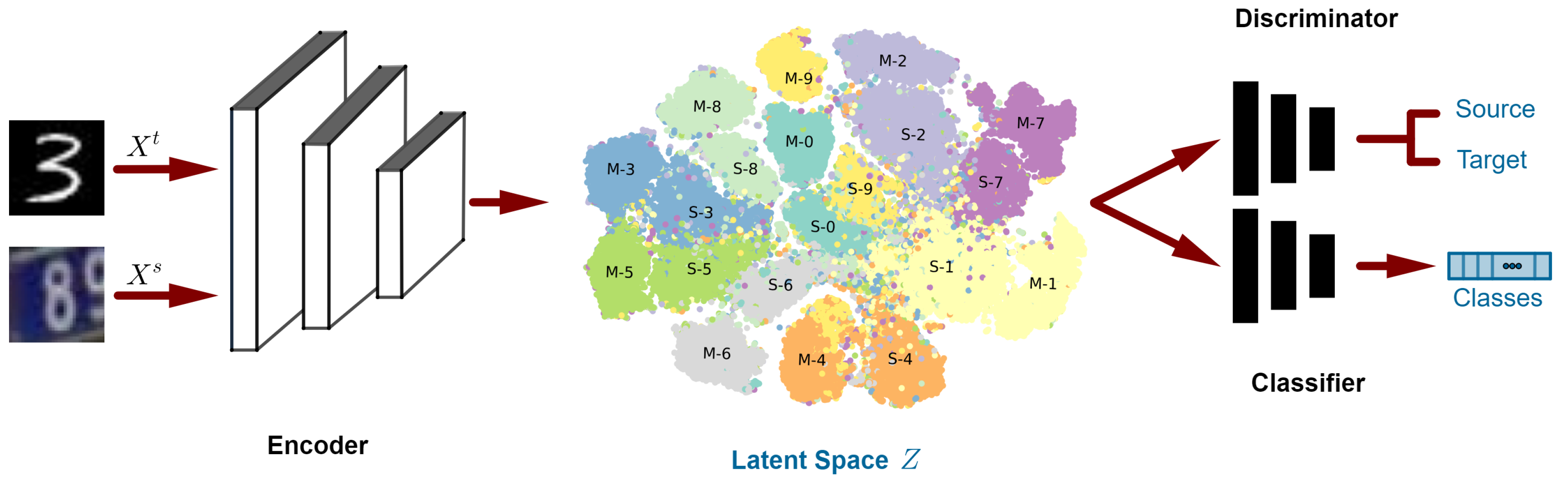
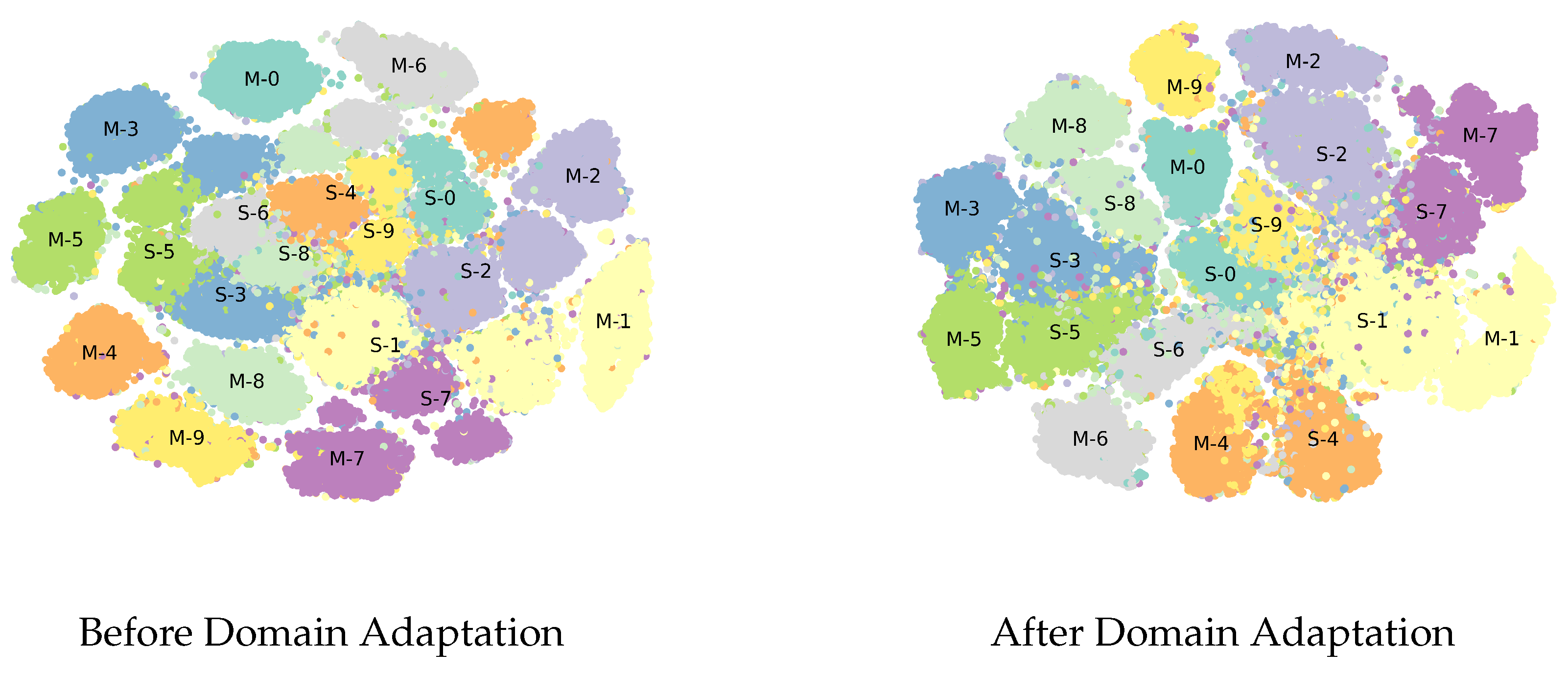
Figure 3, where all classes were clustered together, regardless of domain.
Figure 3 illustrates the projection of the latent representations of both domains in the first experiment, SVHN → MNIST. The projection for the visualization was produced using T-SNE [
41] by reducing the dimensions of the latent space from 512 into 2, for visualization purposes. In
Figure 3, it can be noticed that, after domain adaptation, the clusters for both domains that carry the same labels settled close to each other in the latent space, which demonstrates the competence of the presented model.
According to the results presented in
Table 1, there was no one specific model which outperformed the others in all cases. Those that exceeded our model (though, not by a significant margin) had more complex architectures and were difficult to train. We highlight this point later, in
Section 4.2.
4.1.2. Object Recognition using OFFICE31
We also evaluated our method on the OFFICE dataset [
42] for object recognition. Office31 is a widely-used dataset in domain adaptation, containing images belonging to 31 different classes gathered from three different domains: Amazon (A), Webcam (W), and DSLR (D). One of the major challenges in this dataset is that it contains only 4110 images (A:2817, W:795, and D: 498), which is too small to build any deep classifier. Most DUDA methods tend to use a pre-trained model (like AlexNet [
43] or ResNet [
44]) and fine-tune it to this specific dataset. In our method, we chose to use a pre-trained AlexNet and replaced the final layer with a dense (4096,31) fully-connected layer, instead of the dense (4096,1000) layer. We followed the same protocol as for the digit classification task. We report our results in
Table 2. We can see that our model provided state-of-the-art performance on AlexNet-based models (rows above our model) and even beat the ResNet-based models on the D → W experiment, even though we used a much smaller network; as we aimed to design a simple model with good adaptation ability, ease to training, and, yet, which provides better performance as well. It is apparent, from our results, that indeed our model beat (or provided similar results to) most existing methods. It is also worth mentioning that the cited ResNet-based models did not show a significant increase in accuracy, ranging from 0.5% to a maximum of 11% of accuracy increase, when compared against the vanilla ResNet (last row in
Table 2).
4.1.3. SYN-SIGNS to GTSRB
Our last comparison will be on the German traffic signs recognition benchmark (GTSRB) datasets and Synthetic Signs (SYN-SIGNS) dataset. The goal of this evaluation is to evaluate the use of DA in generalizing to real-world images using synthetic data. Both datasets were split into 43 different traffic signs. We used 10,000 labeled SYN-SIGNS images as the source domain, and 31,367 GTSRB images as training data; while 3000 GTSRB images were used for validation and the rest of the images were used as a test set for evaluating the final performance. We used the same experimental setup as the one in the digits experiment, with the same model and network architecture.
We can definitely see an improvement, from 56.4–88.7% (
Table 3). Although our model was behind the state-of-the-art in this experiment, it is important to note that consumed less computational resources and converged much faster.
4.2. Comparison of TripNet and DupGAN
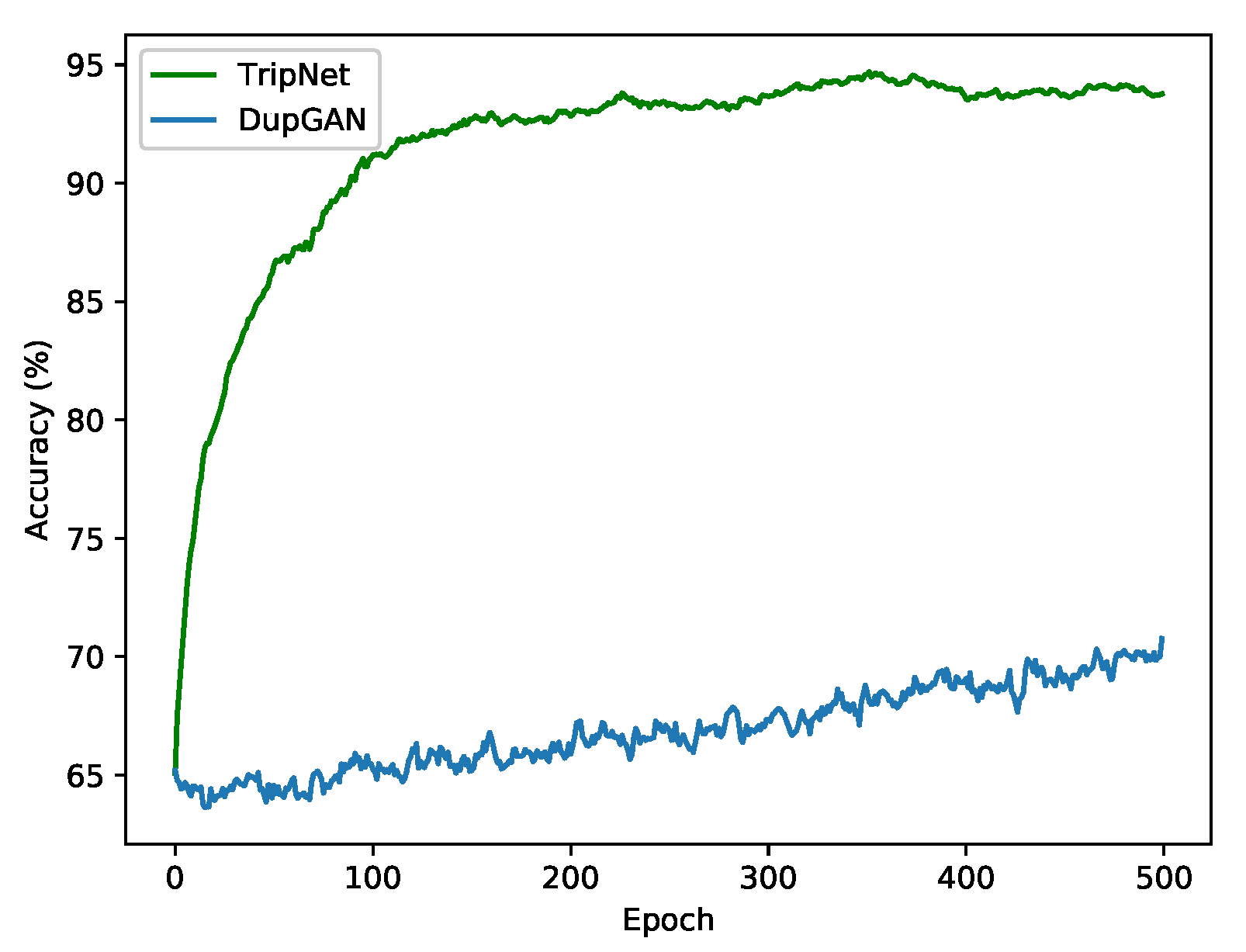
We conducted a comparison between the convergence of TripNet and DupGAN for the experiment SVHN → MNIST, as shown in
Figure 4, within the same experimental setup. It is clear that our model converged significantly faster—after just the first 120 iterations—whereas DupGAN didn’t even approach its maximum accuracy after 500 iterations. Based on our experiments, we found that the generative model DupGAN needs roughly 100 times the number of iterations that TripNet needed to reach its maximum accuracy.
4.3. Ablation Study
For the purpose of seeing the usefulness of each component of TripNet, we performed an ablation study on the MNIST → USPS and SVHNextra→ MNIST cases by running the experiments each time without a specific component and comparing it with our final (full-model) results. We also compared the performance against two extreme cases: (i) tTraining and testing on target domain, and (ii) training on the source domain and testing on the target domain. Our experiments also covered training without the balancing factor for separation loss (referred to as TripNet-WBF), training without the separation loss (referred to as TripNet-WSL), training without pseudo-labeling (referred to as TripNet-WPL), and training without the discriminator (referred to as TripNet-WD).
As shown in
Table 4, the accuracy degrades if we exclude any component, which shows the necessity of each in the presented model to build an efficient architecture for domain adaptation. It is also worth noticing that our model (TripNet) obtained better results than EC-TargetOnly on MNIST → USPS, even though EC-TargetOnly was trained directly on the USPS data; this is mainly due to the fact that USPS and MNIST are very similar, and as USPS has a small training set.
4.4. Implementation Details
In the digit recognition and synthetic-to-real experiments, our input images from all domains were reshaped into
images, or into
for the OFFICE31 object recognition task, and each pixel was re-scaled to
. Given that the latent representation vectors
are high-dimensional (512 in digit classification and SYS-SIGNS to GTSRB, and 9216 for OFFICE31), we used the cosine similarity as our measure of distance
in the separability loss in Equation (
8).
For digit classification and synthetic-to-real task, the encoder part of our model has four convolutional layers using
filters with 64, 128, 256, and 512 filters per layer, respectively. The classifier and the discriminator are four-layer fully-connected networks with 256, 128, and 50 neurons per each of their first three layers, respectively, and with an output layer of 10 neurons for the classifier and one neuron for the discriminator. The model weights were initialized using Xavier weight initialization [
45]. The rest of the hyper-parameters are reported below, in
Table 5, as they were tuned empirically for each experiment in
Table 1. For the object recognition task, we used a pre-trained AlexNet [
43] as the base for our encoder and classifier. For detailed information about our code, see the
supplementary data/materials.
5. Conclusions
Domain Adaptation proves its benefit in increasing the accuracy for unlabeled datasets into other domains, which is a significant breakthrough in the field of machine learning. The current models that approach the unsupervised domain adaptation problem using generative models (or very deep models, like ResNet) as their baseline are highly expensive to train, in terms of time and space. Therefore, in this work, we present our model, TripNet, which has a simple model that allows for fast convergence, yet which can achieve good performance on domain adaptation in different image classification problems. TripNet consists of an encoder, a classifier, and a discriminator. Both the classifier and the discriminator are stacked on the encoder. For each of the three components, we define a specific loss: Classification, discrimination, and separability losses. These losses are used to train the components in a weighted manner. When tested on three image classification problems, TripNet achieved the best results in some cases and a fair performance (given its simplicity, in terms of training) in other cases. As further work on TripNet, we will explore the problem of semi-supervised domain adaptation, as we believe that TripNet will perform better in this field compared to the existing models.

 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}