Coarsely Quantized Decoding and Construction of Polar Codes Using the Information Bottleneck Method



{kind=link}
{kind=link}
{kind=link}
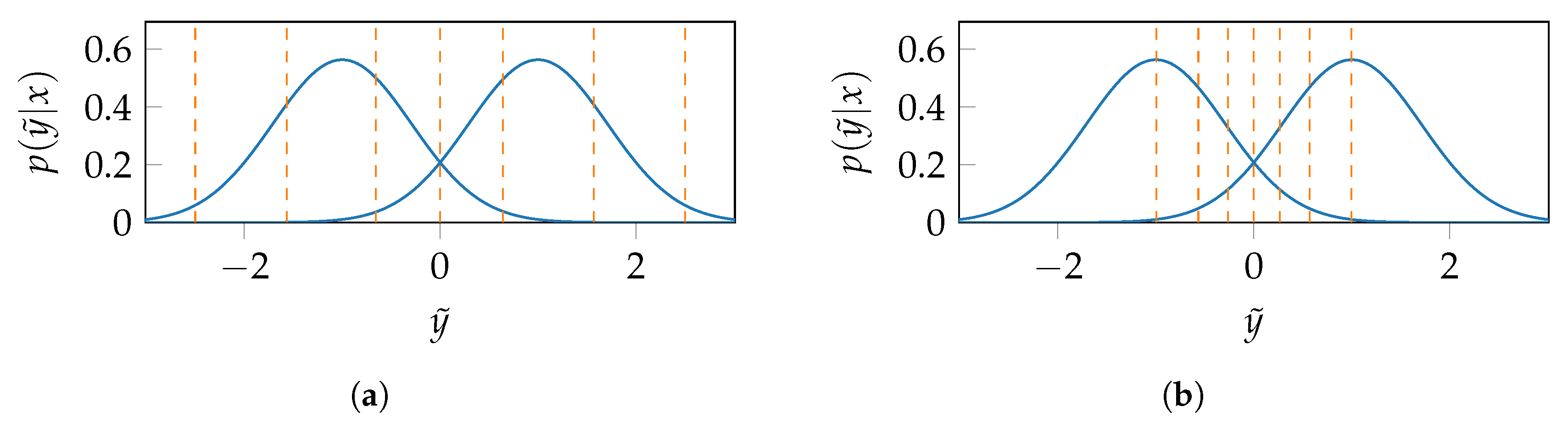{kind=link}
{kind=link}
{kind=link}
{kind=link}
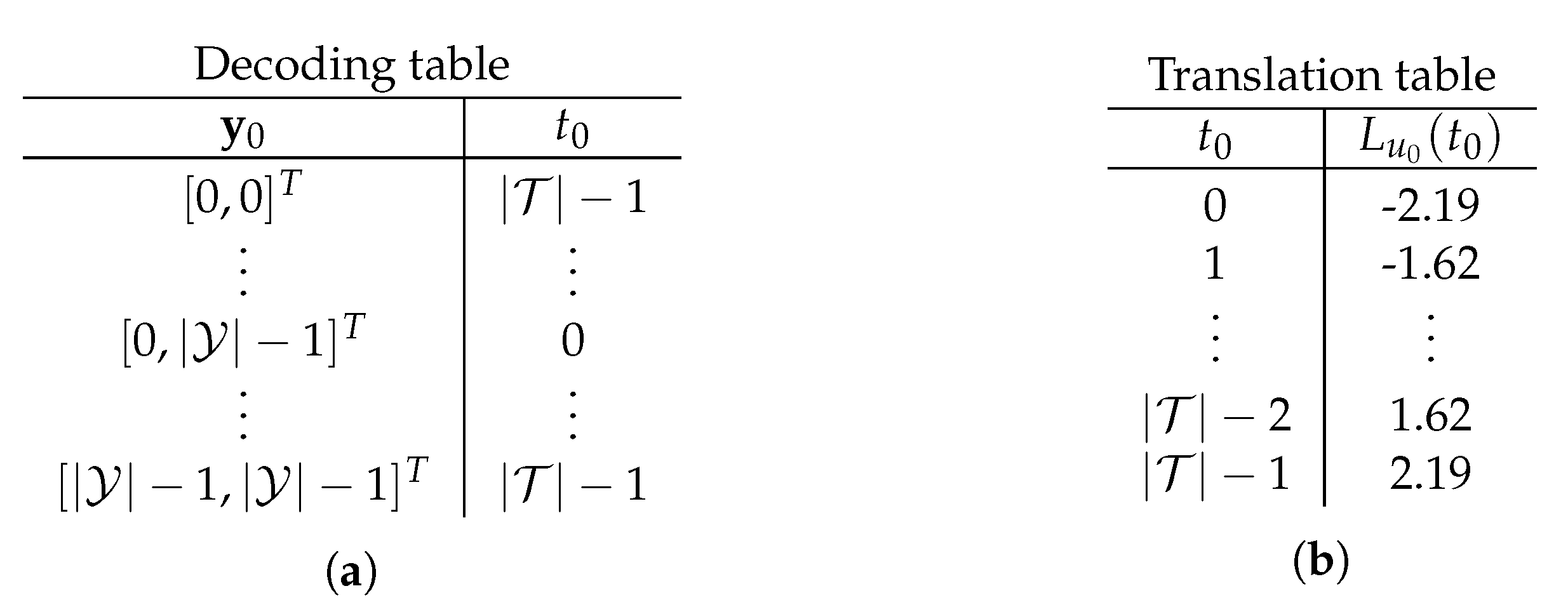{kind=link}
{kind=link}
{kind=link}
{kind=link}
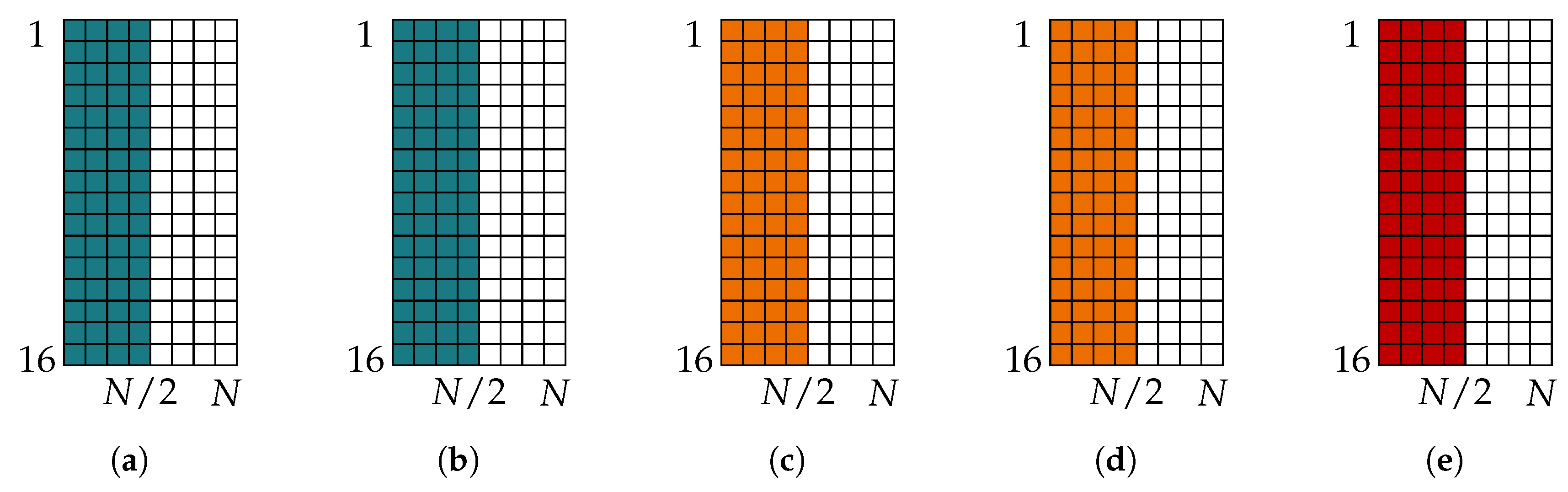{kind=link}
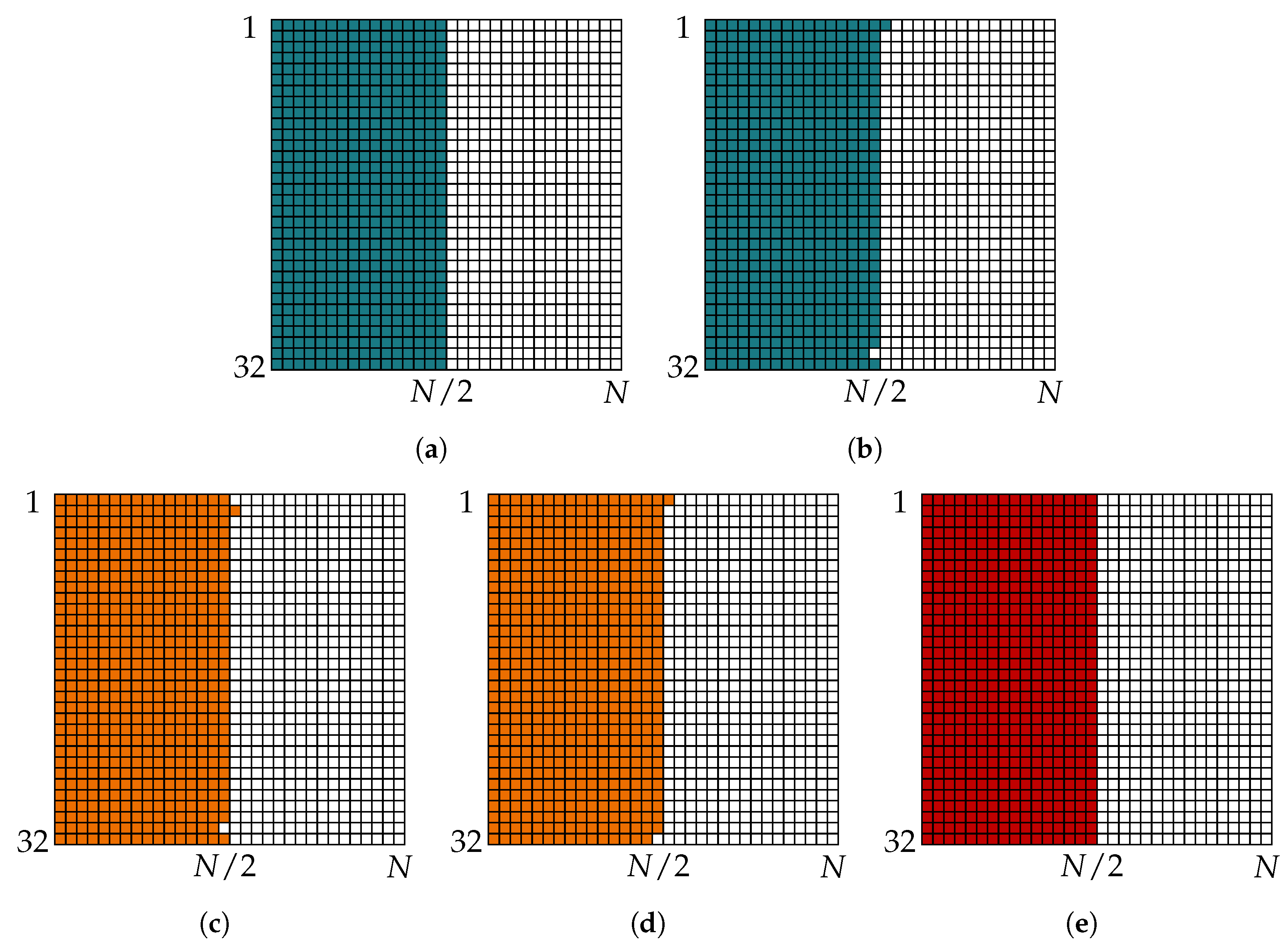{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
Notations
2. Prerequisites
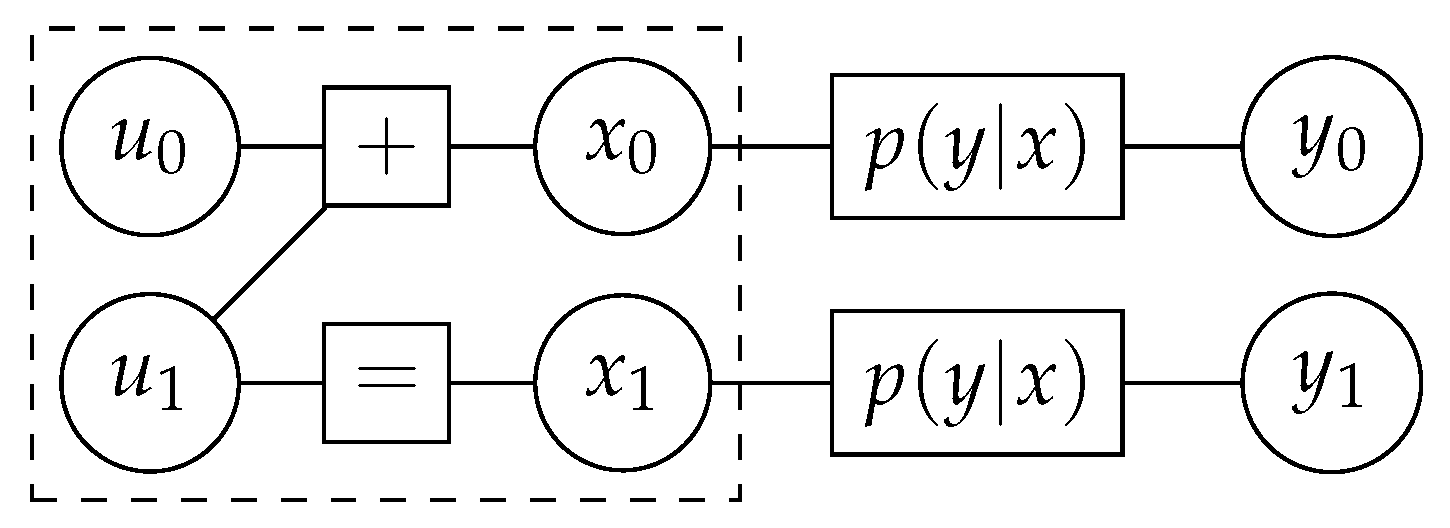
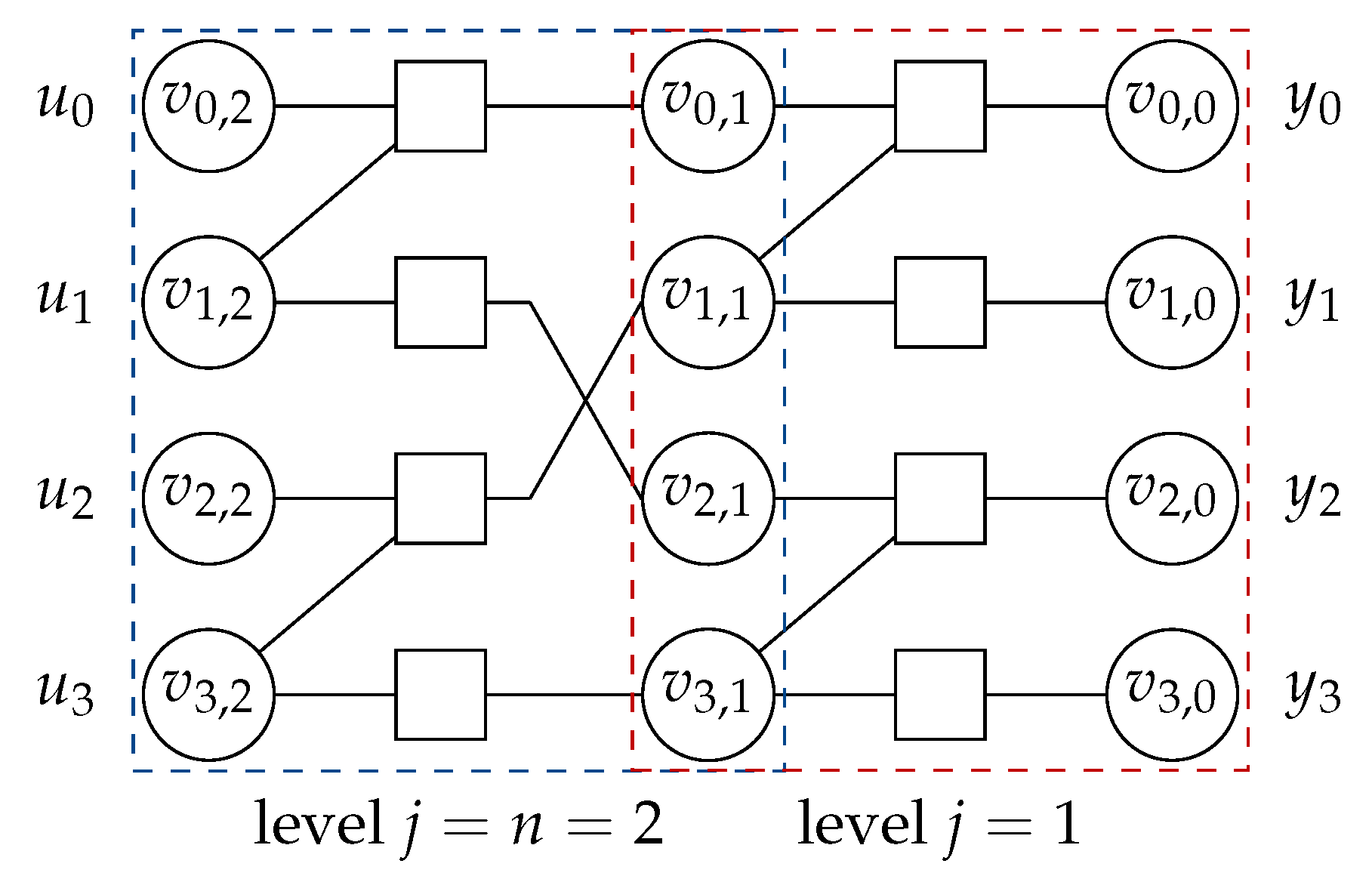
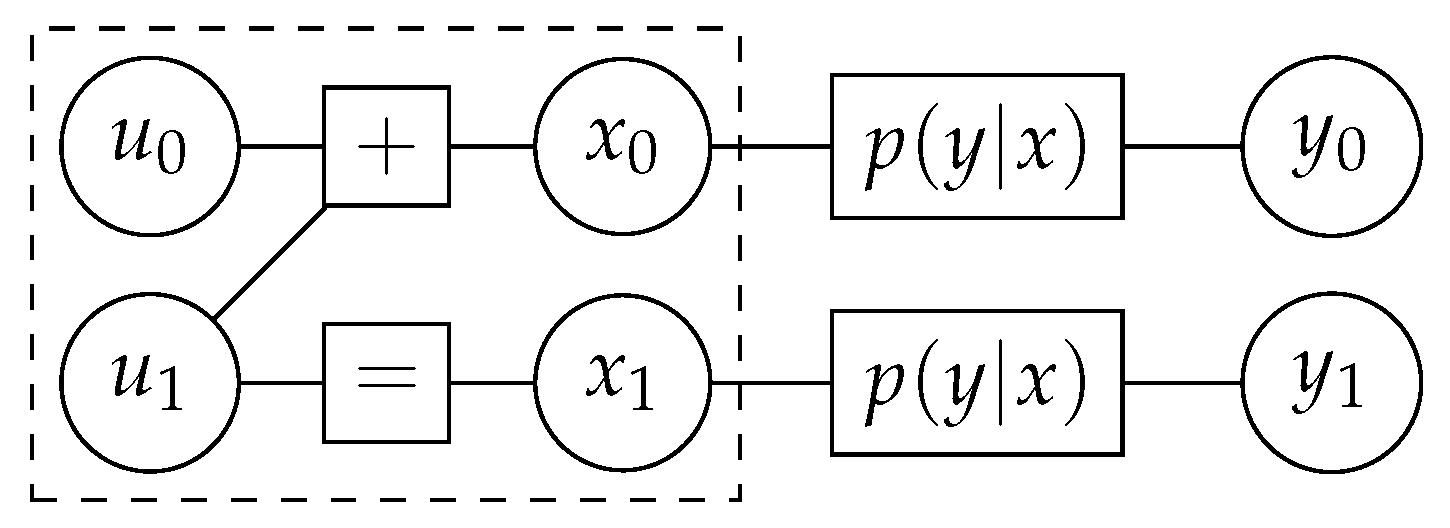
2.1. Polar Codes
2.2. Successive Cancellation List Decoder
2.3. Polar Code Construction
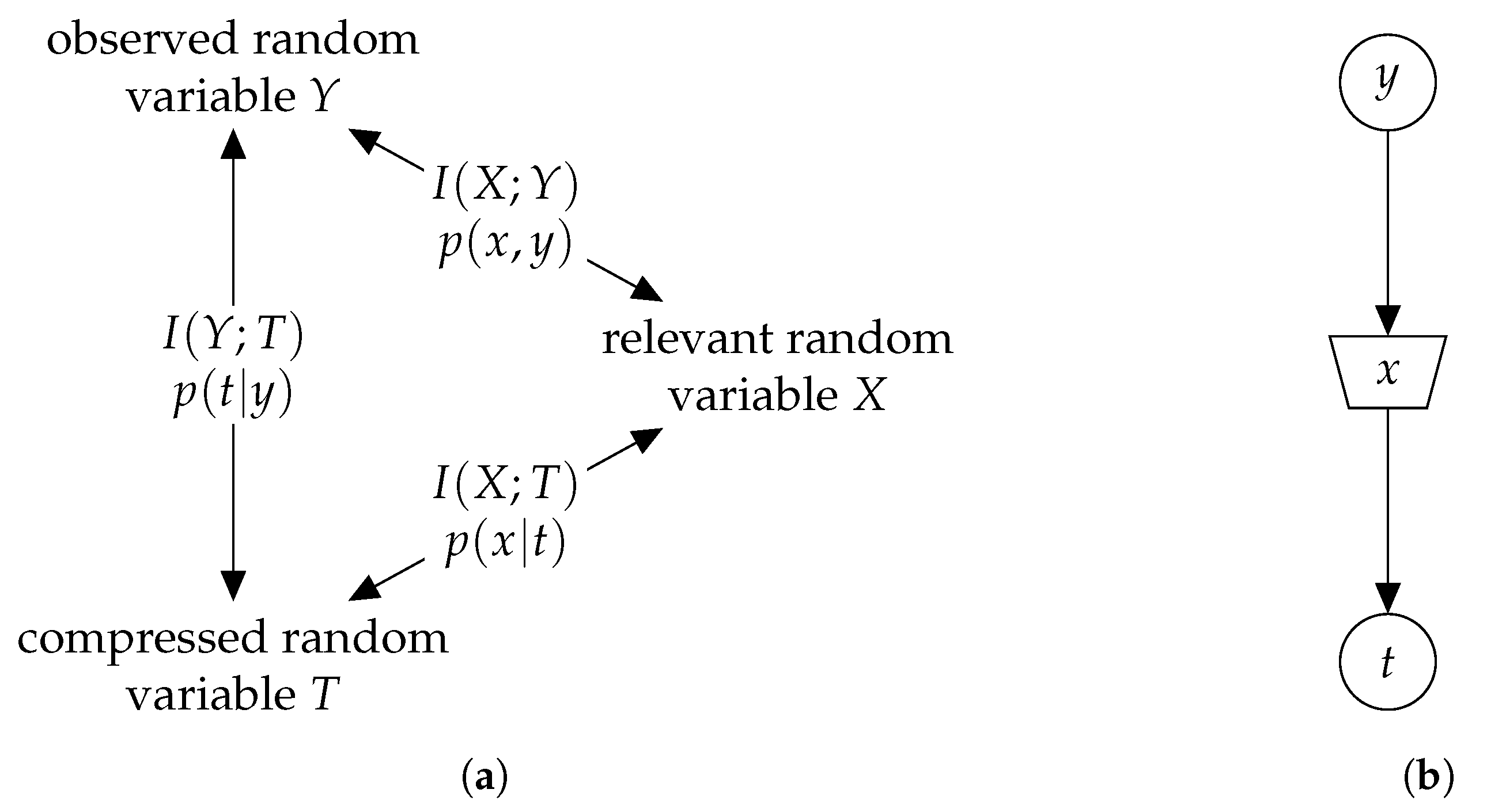
2.4. Information Bottleneck Method
3. Polar Code Construction Using the Information Bottleneck Method
3.1. Information Bottleneck Construction
3.2. Tal and Vardy’s Construction
3.3. Information Bottleneck vs. Tal and Vardy Construction
4. Information Bottleneck Polar Decoders
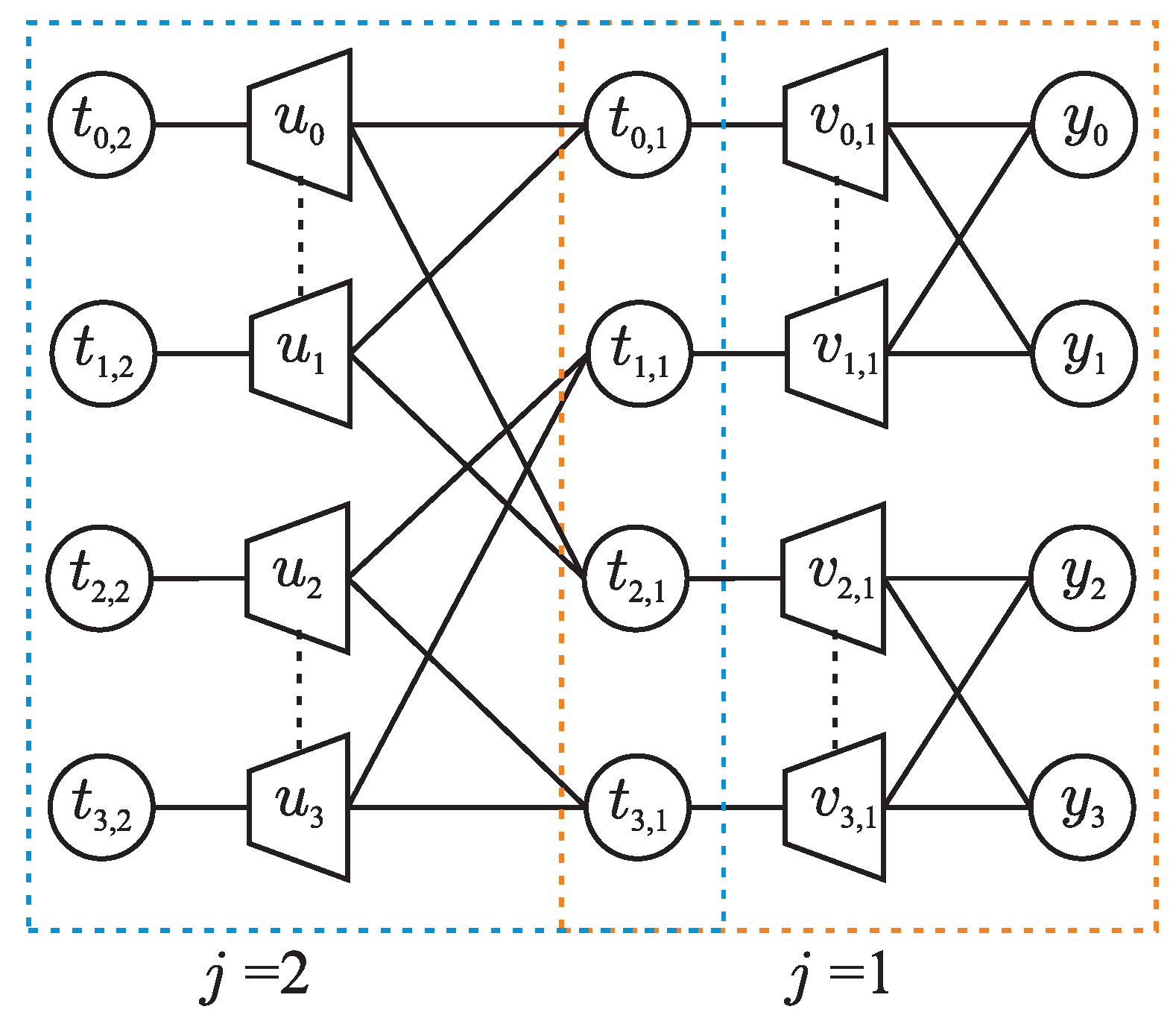
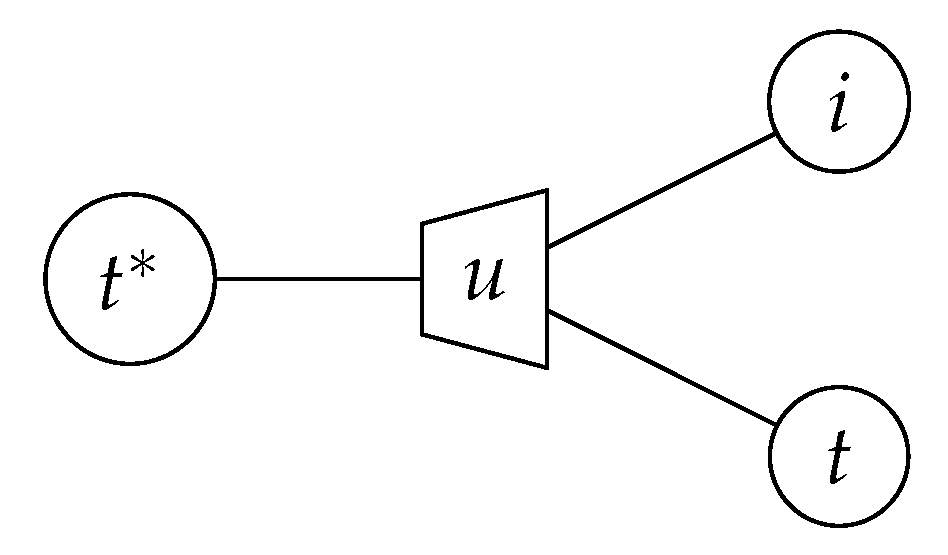
4.1. Lookup Tables for Decoding on a Building Block
4.2. Information Bottleneck Successive Cancellation List Decoder
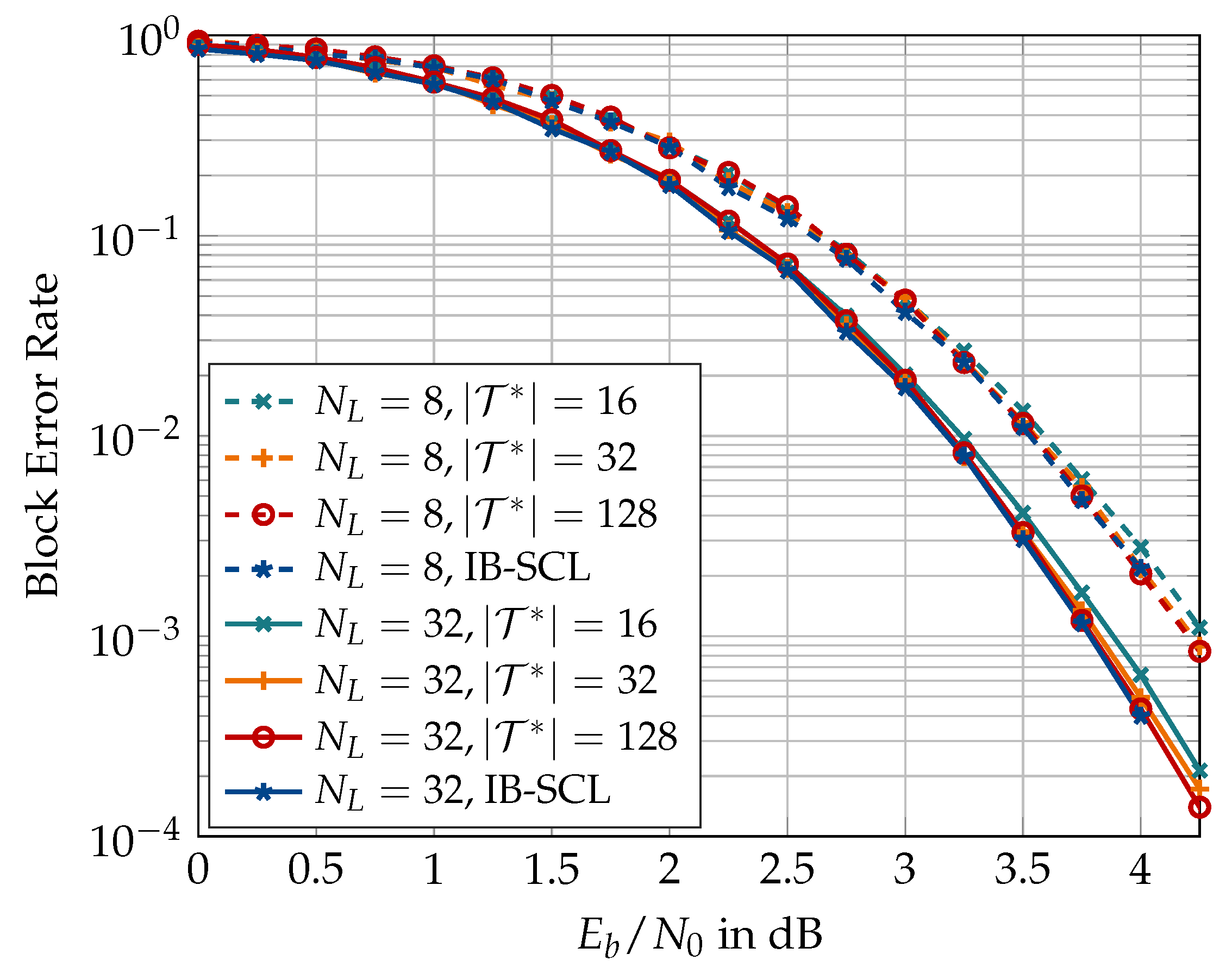
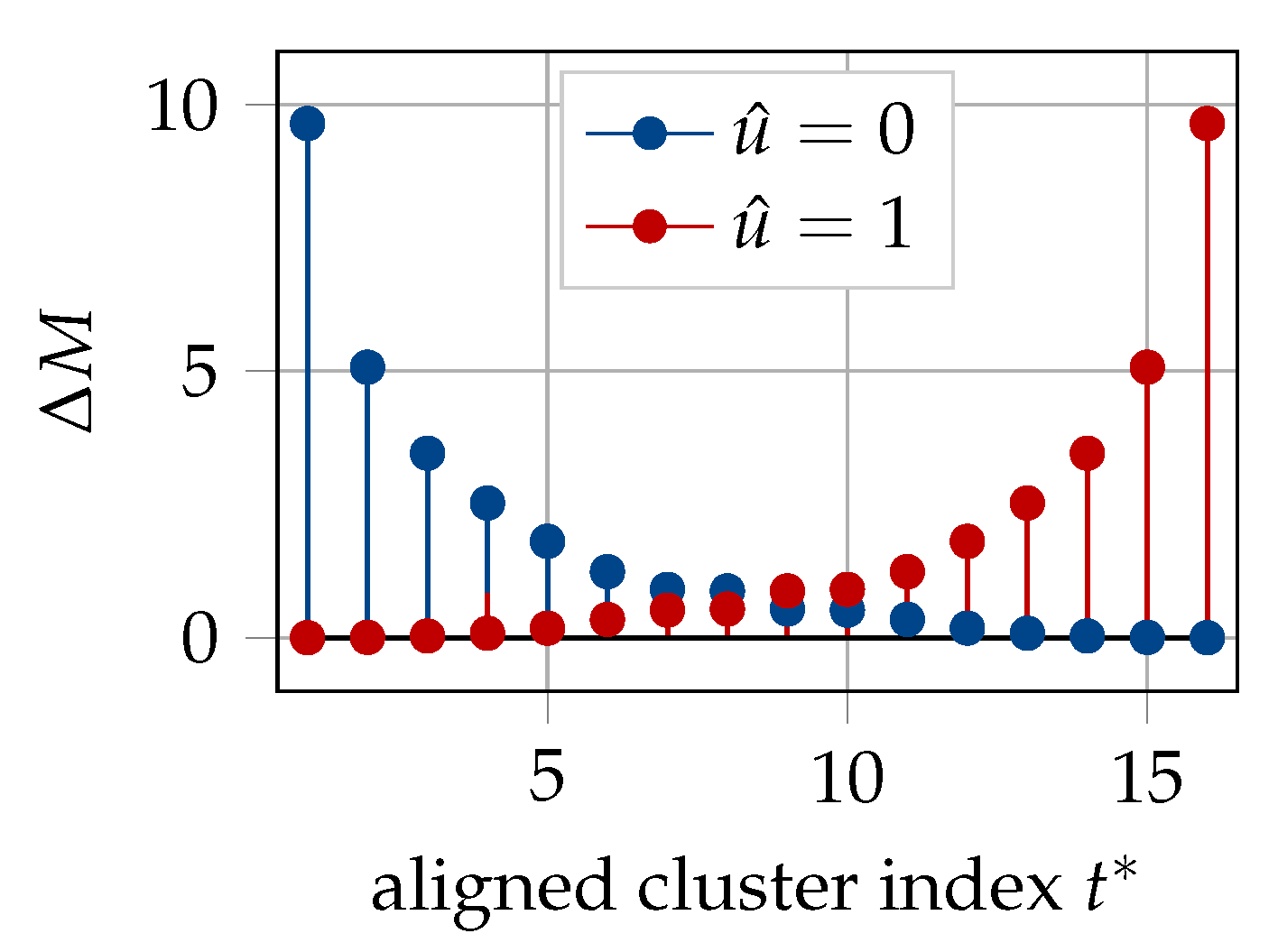
5. Space-Efficient Information Bottleneck Successive Cancellation List Decoder
5.1. The Role of Translation Tables
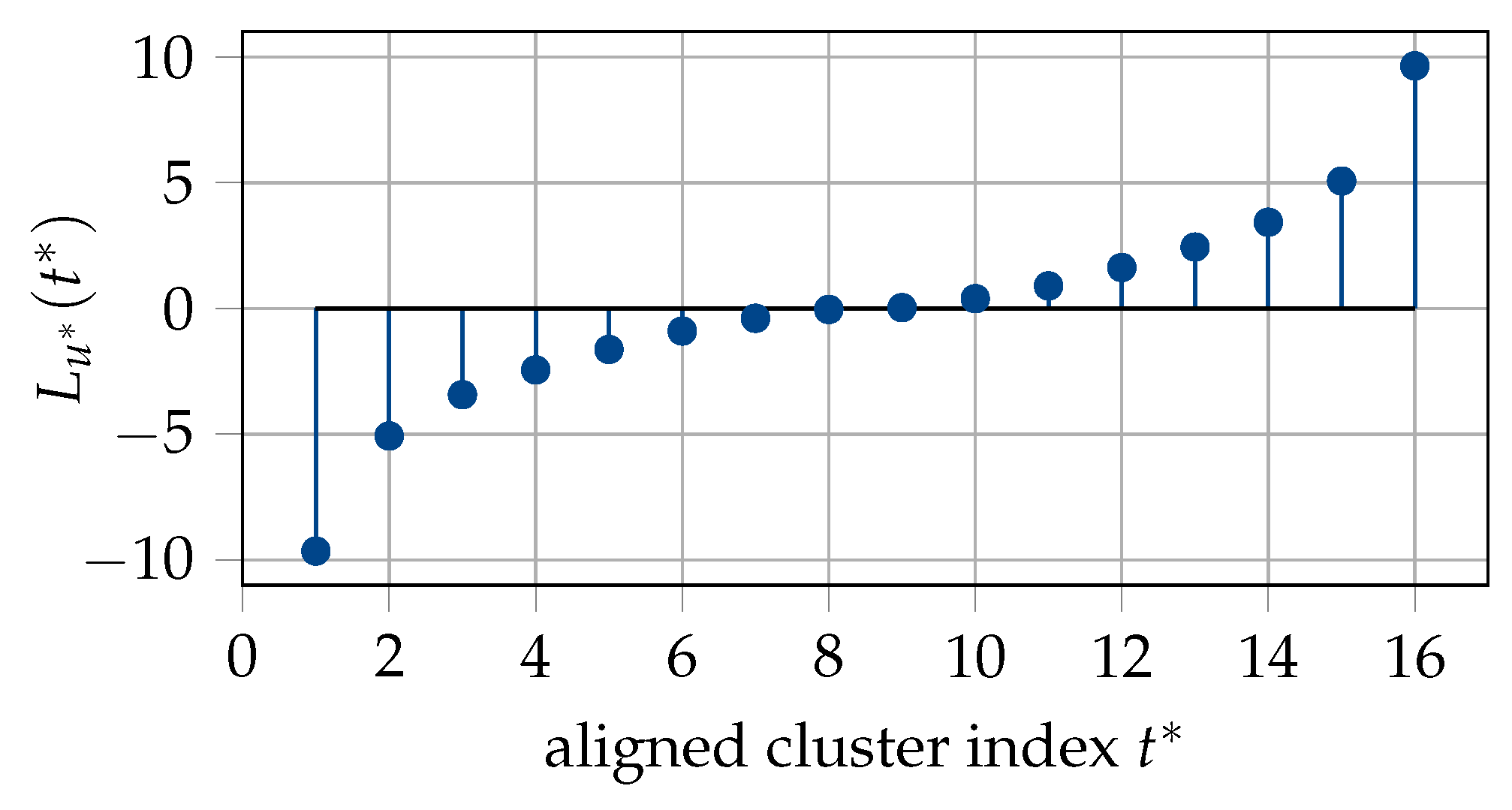
5.2. Message Alignment for Successive Cancellation List Decoder
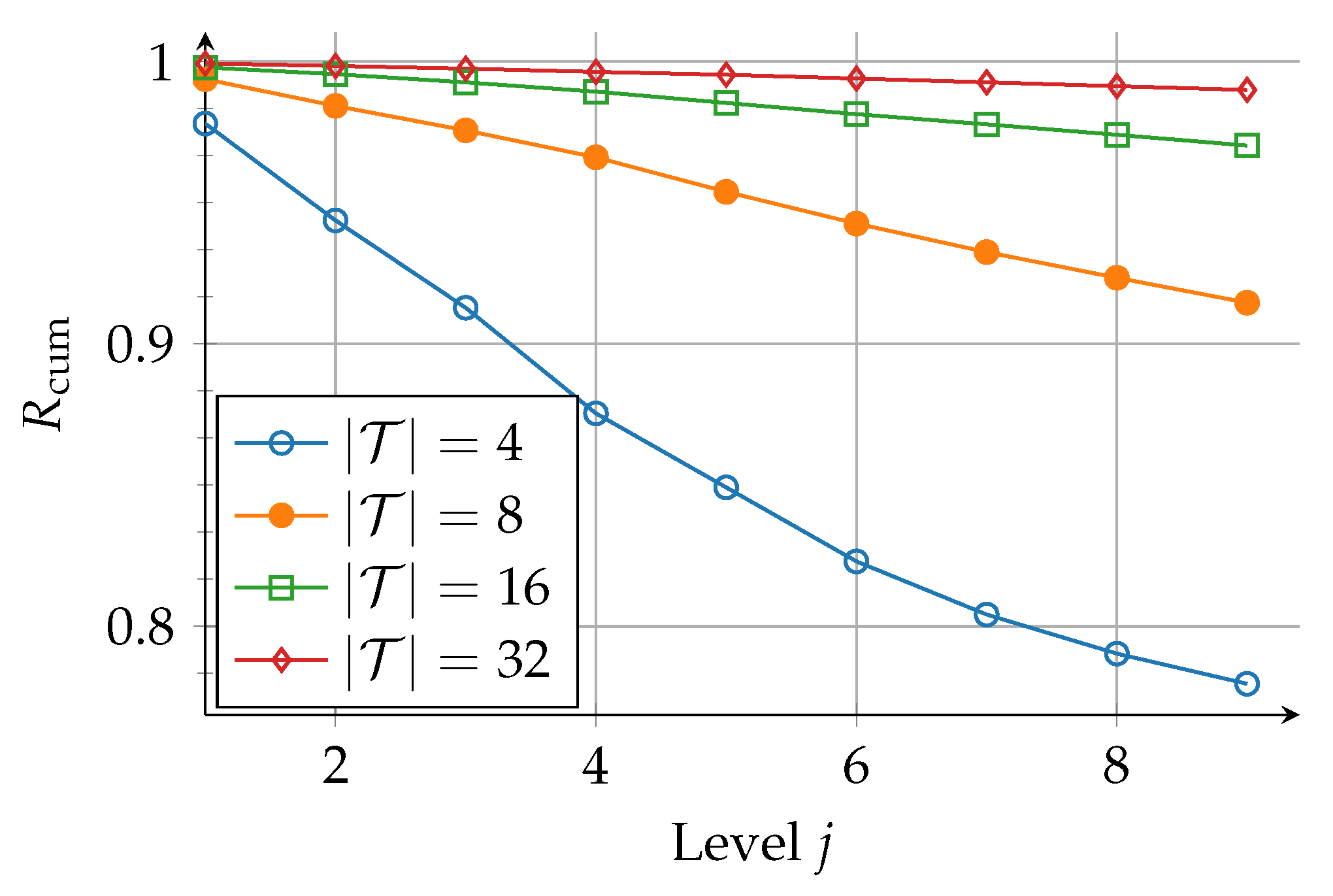
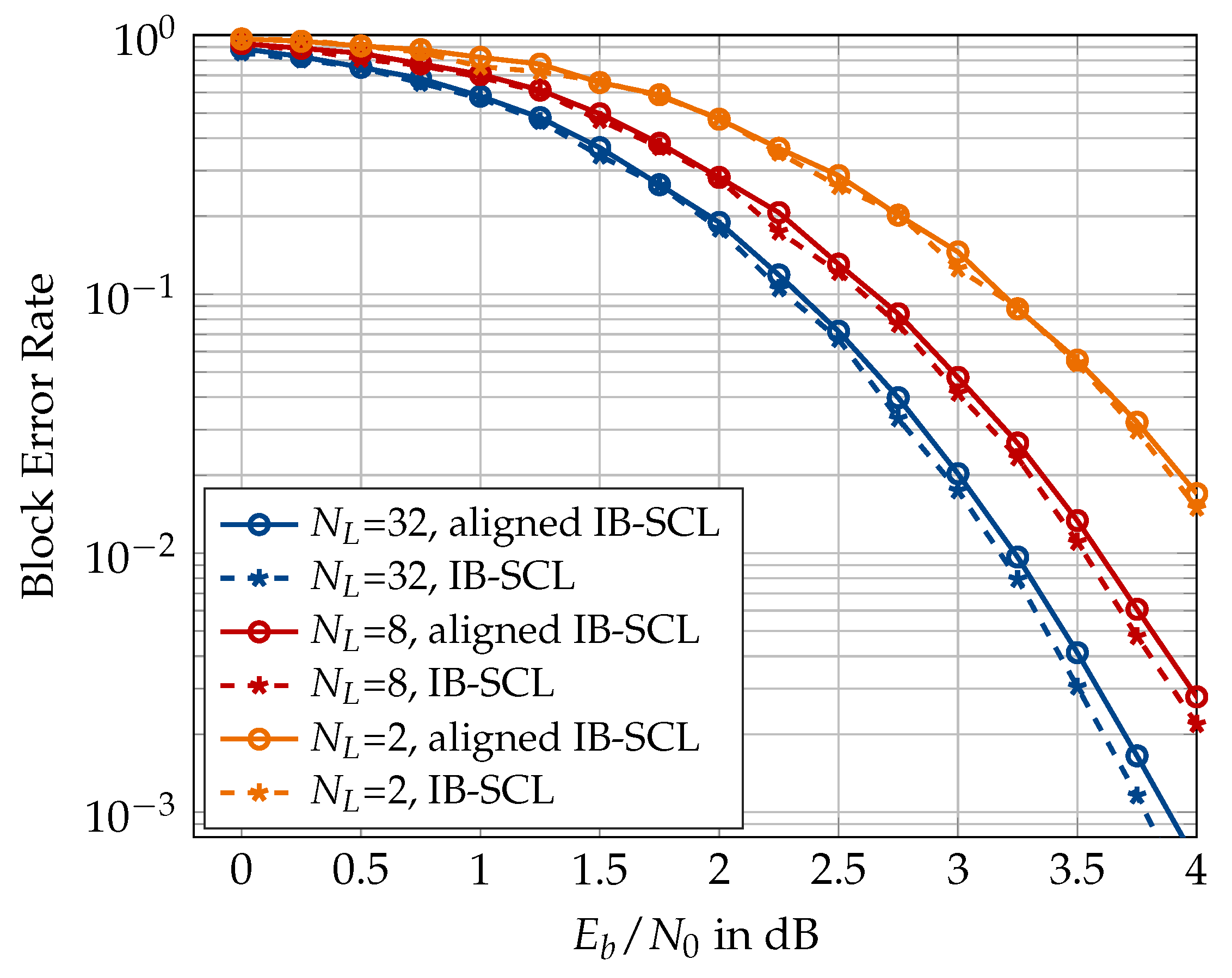
6. Numerical Results
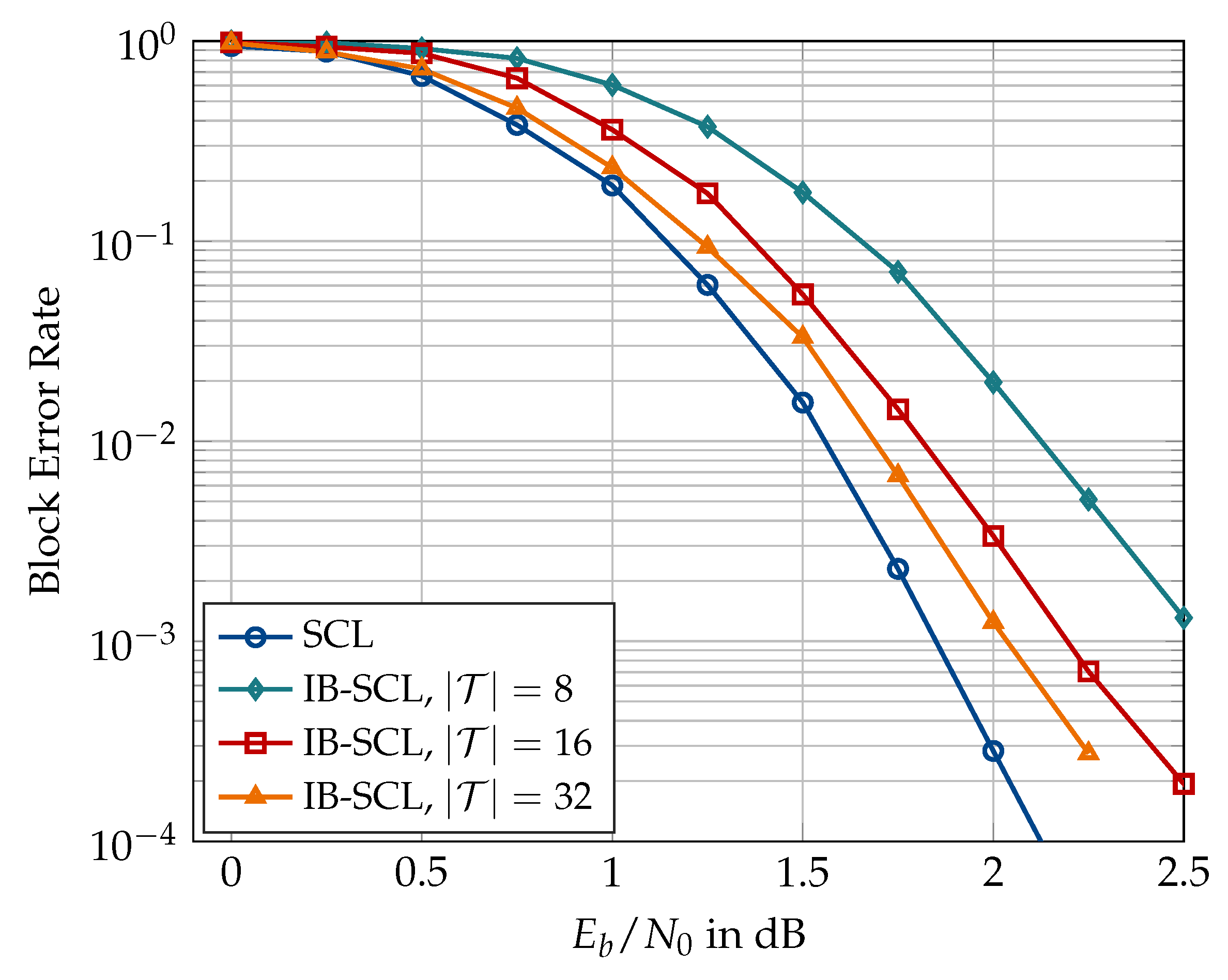
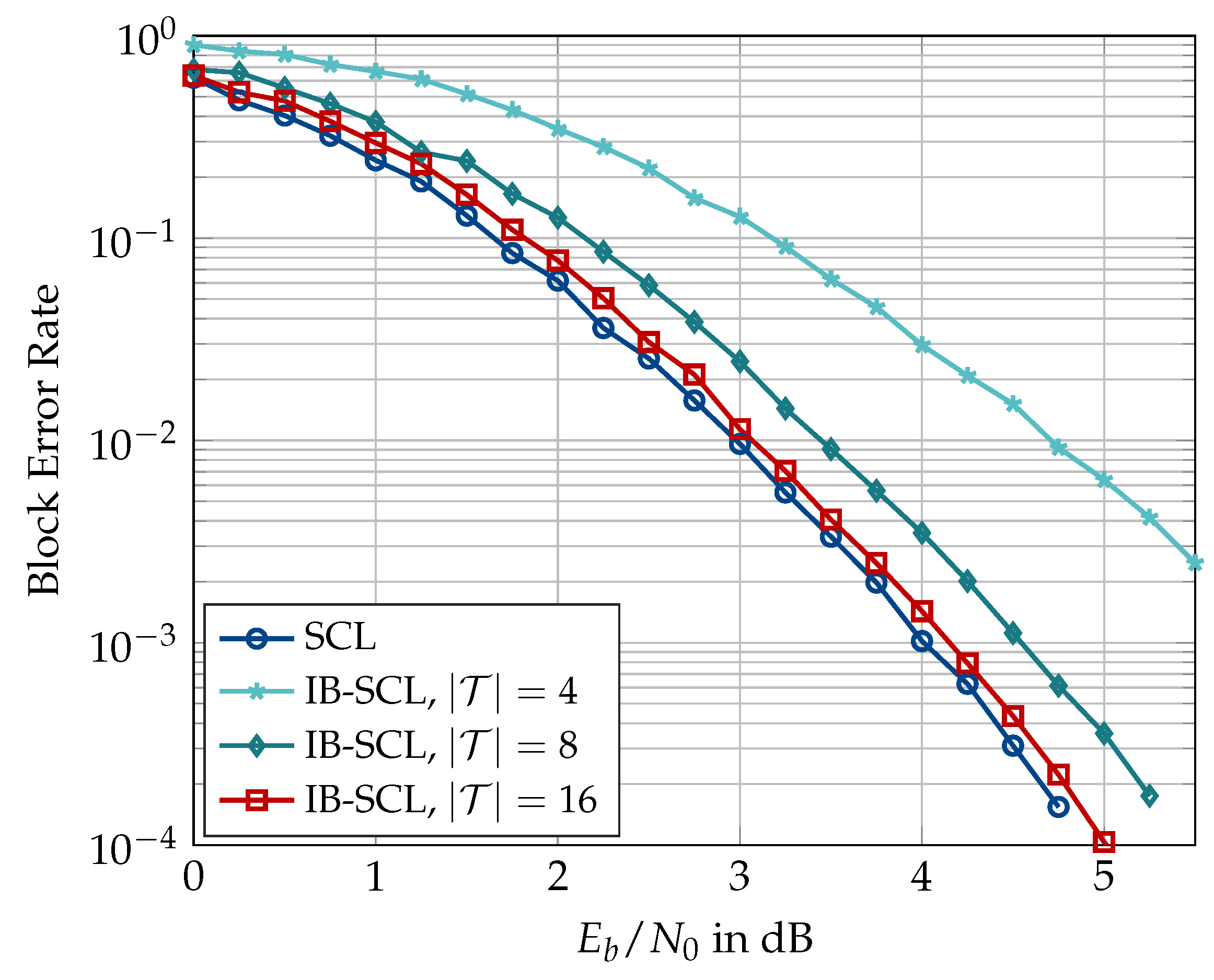
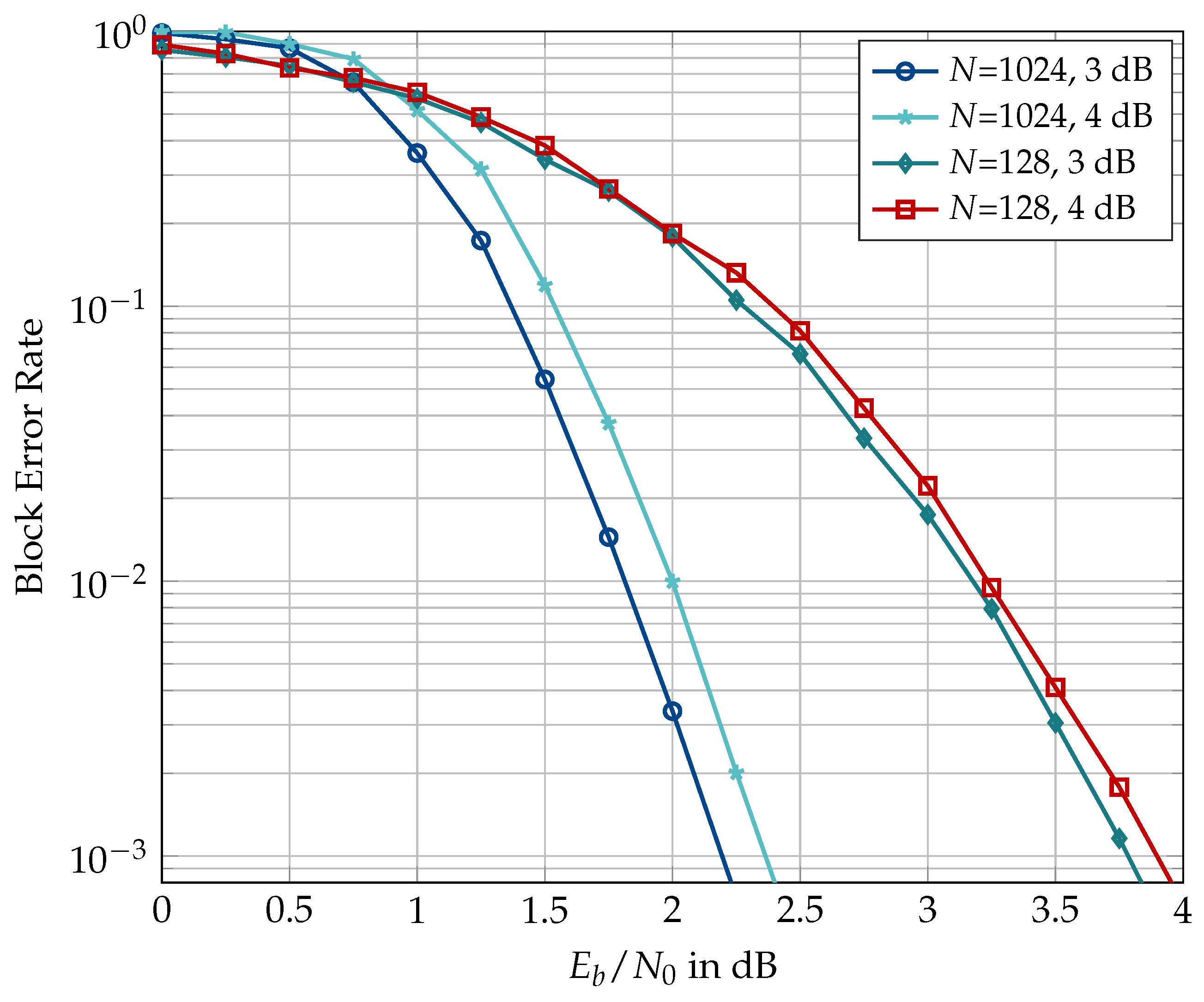
6.1. Code Construction
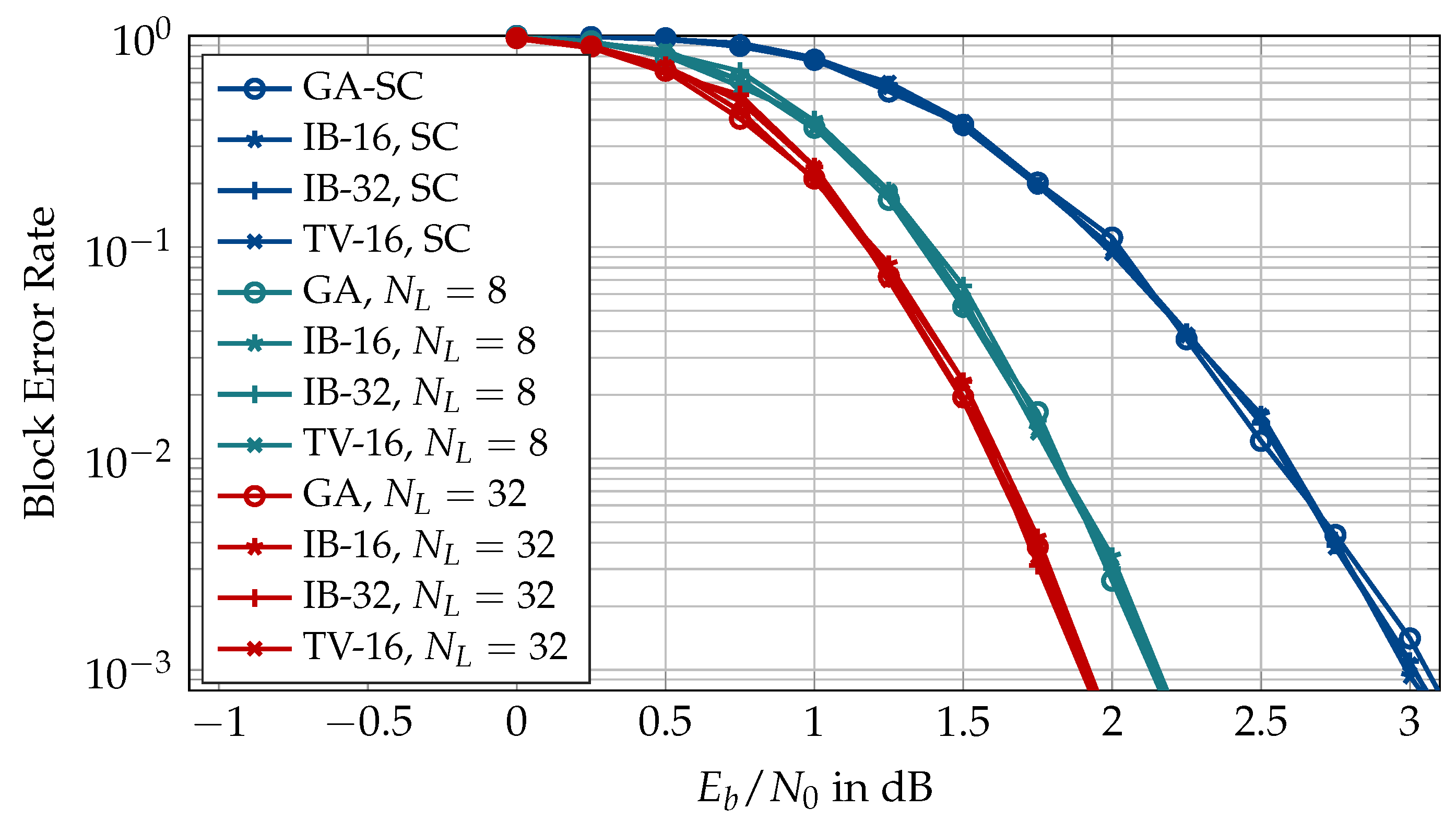
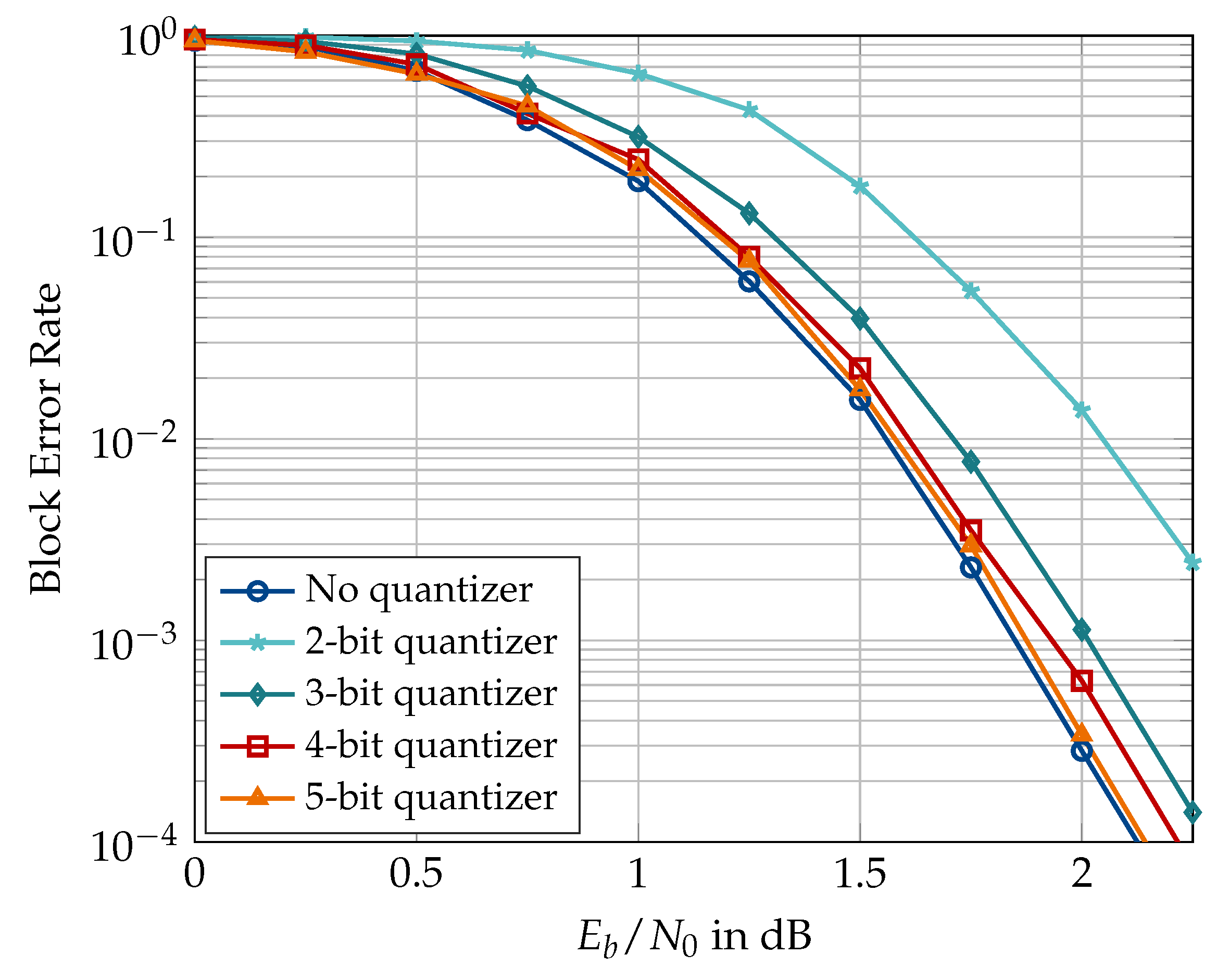
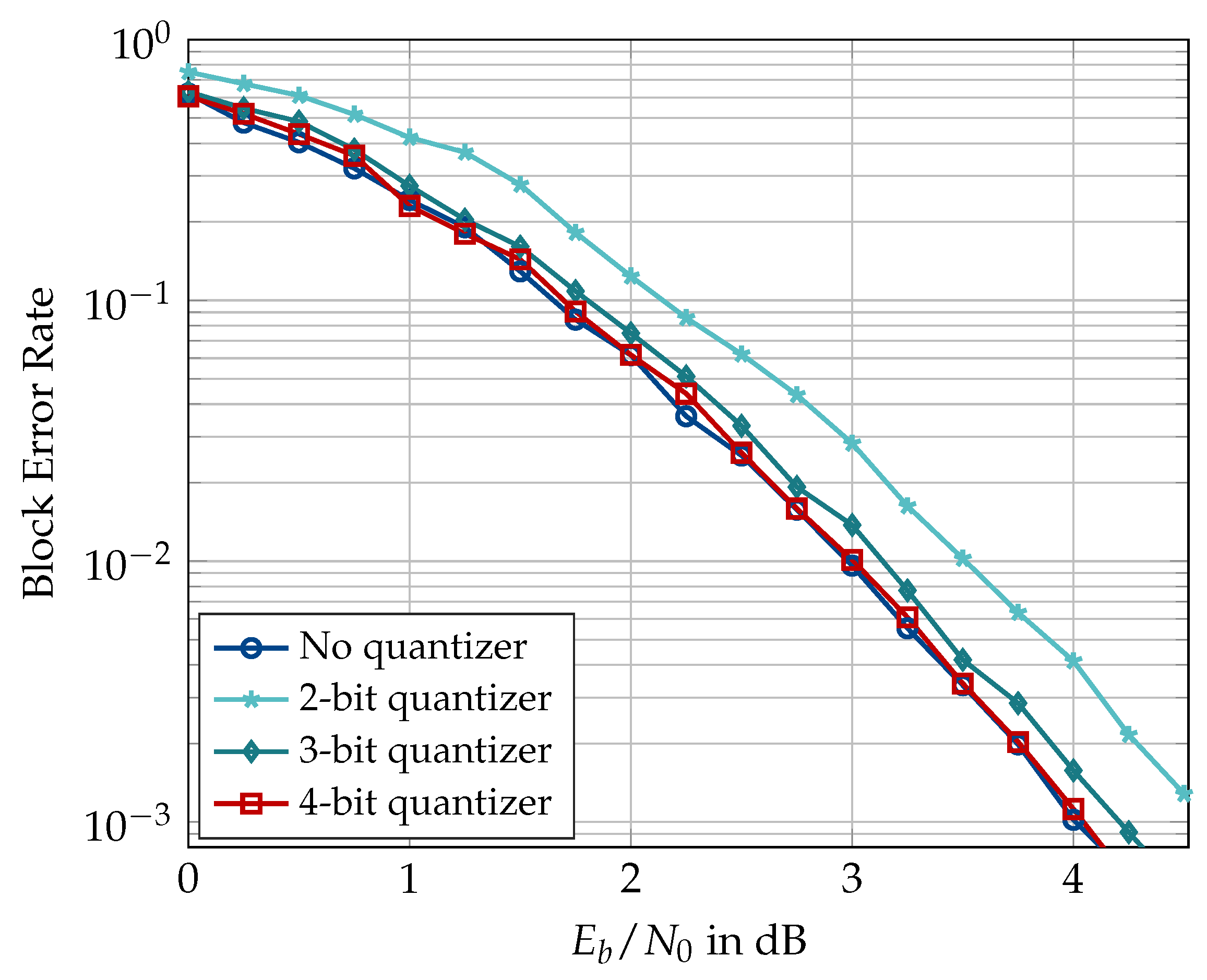
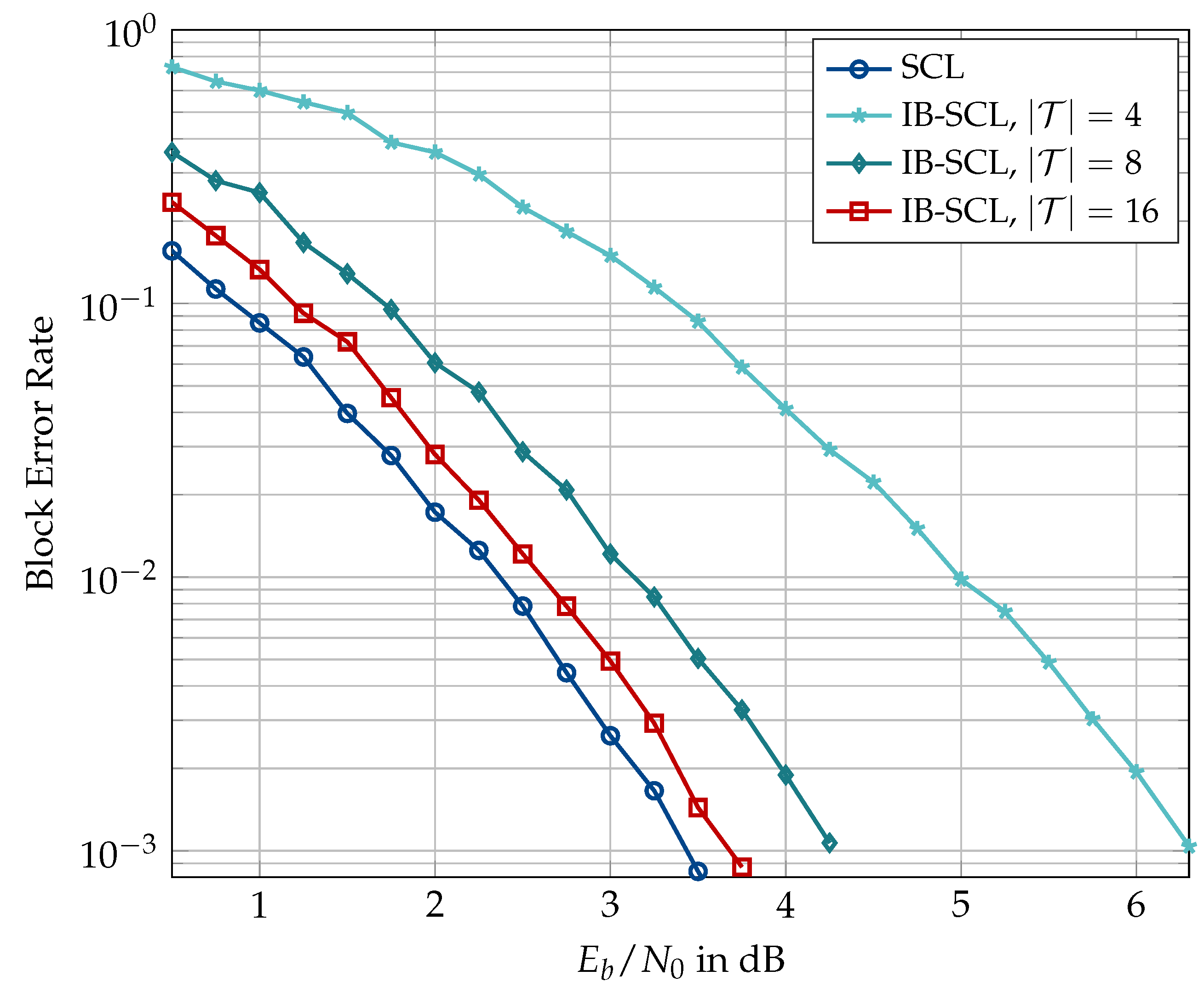
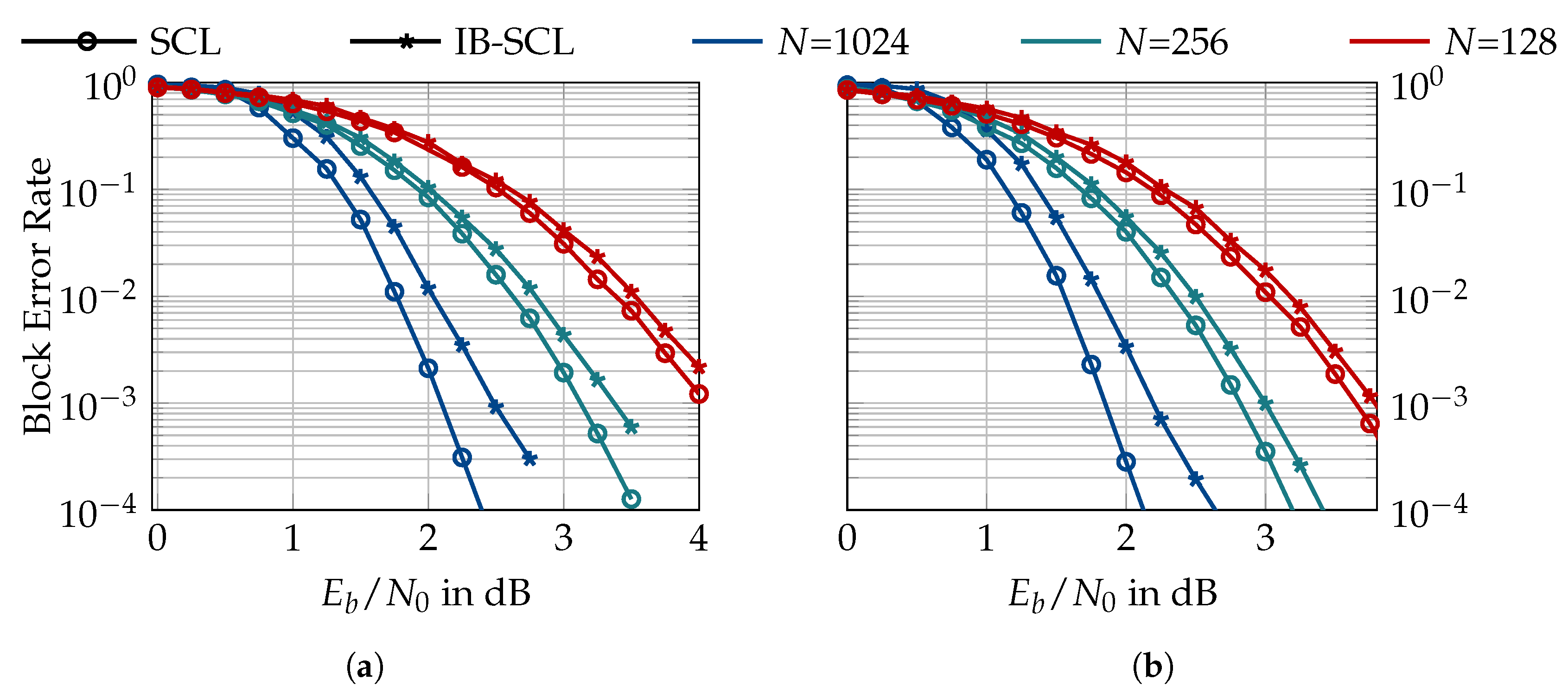
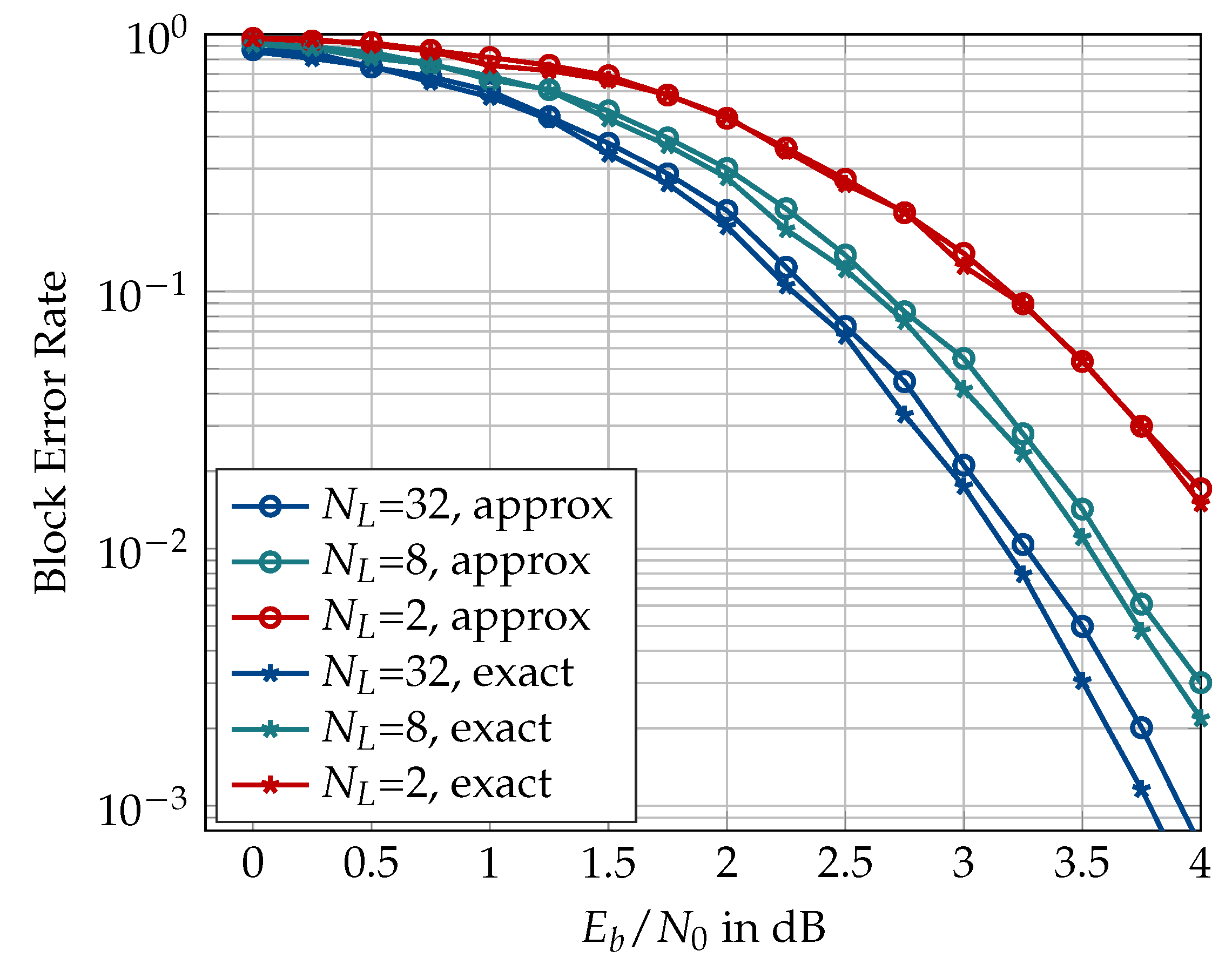
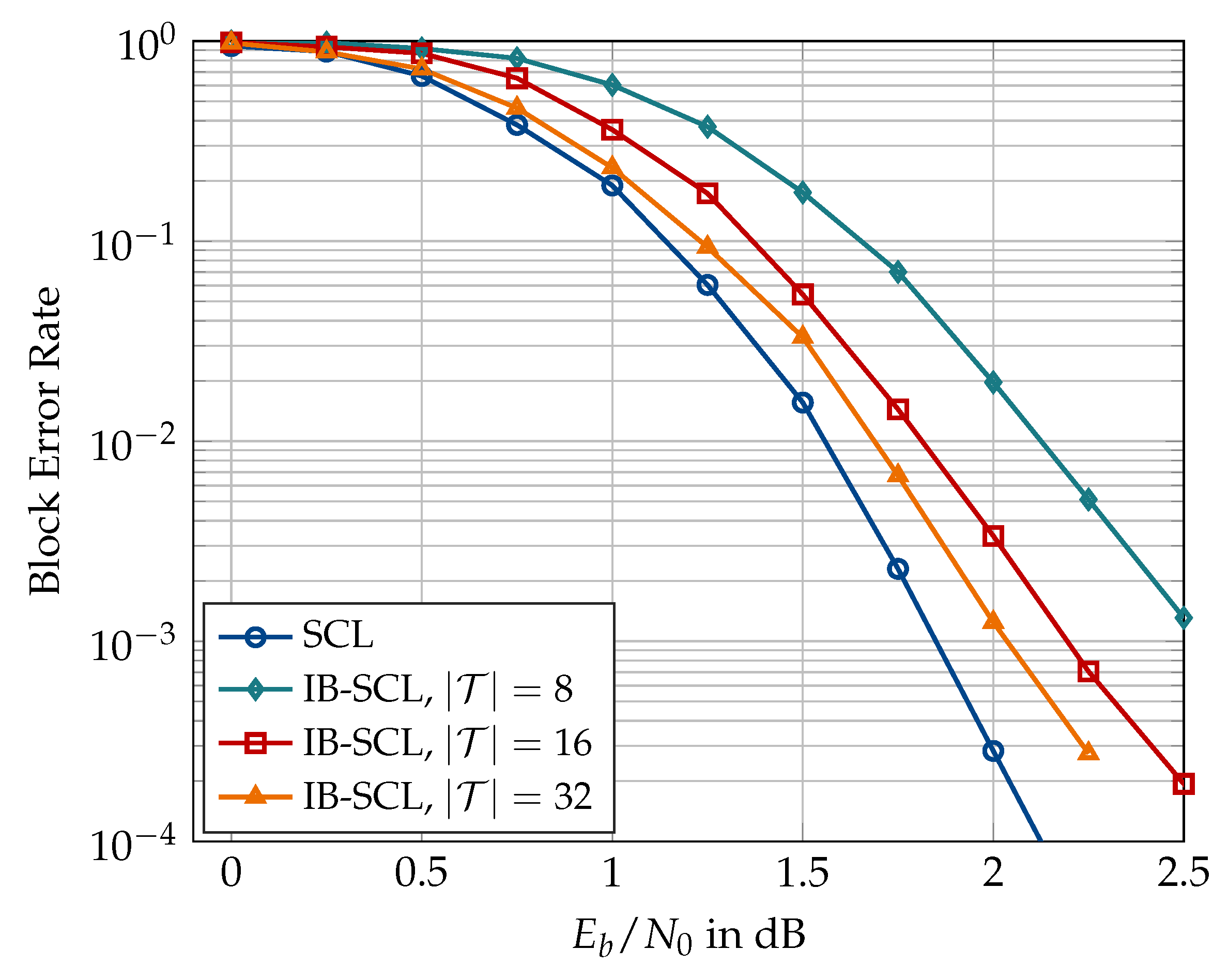
6.2. Information Bottleneck Decoders
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| SC | Successive cancellation |
| SCL | Successive cancellation list |
| CRC | Cyclic redundancy check |
| GA | Gaussian approximation |
| TV | Tal and Vardy |
References
- Lewandowsky, J.; Bauch, G. Trellis based node operations for LDPC decoders from the Information Bottleneck method. In Proceedings of the 9th International Conference on Signal Processing and Communication Systems (ICSPCS), Cairns, Australia, 14–16 December 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–10. [Google Scholar]
- Lewandowsky, J.; Bauch, G. Information-Optimum LDPC Decoders Based on the Information Bottleneck Method. IEEE Access 2018, 6, 4054–4071. [Google Scholar] [CrossRef]
- Tishby, N.; Pereira, F.C.; Bialek, W. The Information Bottleneck Method. In Proceedings of the 37th Allerton Conference on Communication and Computation, Monticello, IL, USA, 22–24 September 1999. [Google Scholar]
- Slonim, N. The Information Bottleneck: Theory and Applications. Ph.D. Thesis, Hebrew University of Jerusalem, Jerusalem, Israel, 2002. [Google Scholar]
- Kurkoski, B.M.; Yamaguchi, K.; Kobayashi, K. Noise Thresholds for Discrete LDPC Decoding Mappings. In Proceedings of the IEEE GLOBECOM 2008–2008 IEEE Global Telecommunications Conference, New Orleans, LO, USA, 30 November–4 December 2008; pp. 1–5. [Google Scholar]
- Richardson, T.; Urbanke, R. Modern Coding Theory; Cambridge University Press: New York, NY, USA, 2008. [Google Scholar]
- Stark, M.; Lewandowsky, J.; Bauch, G. Information-Bottleneck Decoding of High-Rate Irregular LDPC Codes for Optical Communication Using Message Alignment. Appl. Sci. 2018, 8, 1884. [Google Scholar] [CrossRef]
- Stark, M.; Lewandowsky, J.; Bauch, G. Information-Optimum LDPC Decoders with Message Alignment for Irregular Codes. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, UAE, 9–13 December 2018; pp. 1–6. [Google Scholar]
- Balatsoukas-Stimming, A.; Meidlinger, M.; Ghanaatian, R.; Matz, G.; Burg, A. A fully-unrolled LDPC decoder based on quantized message passing. In Proceedings of the 2015 IEEE Workshop on Signal Processing Systems SiPS, Hangzhou, China, 14–16 October 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Meidlinger, M.; Balatsoukas-Stimming, A.; Burg, A.; Matz, G. Quantized message passing for LDPC codes. In Proceedings of the 49th Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 8–11 November 2015; pp. 1606–1610. [Google Scholar] [CrossRef]
- Meidlinger, M.; Matz, G. On irregular LDPC codes with quantized message passing decoding. In Proceedings of the 2017 IEEE 18th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Sapporo, Japan, 3–6 July 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Ghanaatian, R.; Balatsoukas-Stimming, A.; Müller, T.C.; Meidlinger, M.; Matz, G.; Teman, A.; Burg, A. A 588-Gb/s LDPC Decoder Based on Finite-Alphabet Message Passing. IEEE Trans. Very Large Scale Integr. Syst. 2018, 26, 329–340. [Google Scholar] [CrossRef]
- Arikan, E. Channel Polarization: A Method for Constructing Capacity-Achieving Codes for Symmetric Binary-Input Memoryless Channels. IEEE Trans. Inf. Theory 2009, 55, 3051–3073. [Google Scholar] [CrossRef]
- Hussami, N.; Korada, S.B.; Urbanke, R. Performance of polar codes for channel and source coding. In Proceedings of the 2009 IEEE International Symposium on Information Theory, Seoul, Korea, 28 June–3 July 2009; pp. 1488–1492. [Google Scholar] [CrossRef]
- Bakshi, M.; Jaggi, S.; Effros, M. Concatenated Polar codes. In Proceedings of the 2010 IEEE International Symposium on Information Theory, Austin, TX, USA, 13–18 June 2010; pp. 918–922. [Google Scholar] [CrossRef]
- Tal, I.; Vardy, A. List Decoding of Polar Codes. IEEE Trans. Inf. Theory 2015, 61, 2213–2226. [Google Scholar] [CrossRef]
- Li, B.; Shen, H.; Tse, D. An Adaptive Successive Cancellation List Decoder for Polar Codes with Cyclic Redundancy Check. IEEE Commun. Lett. 2012, 16, 2044–2047. [Google Scholar] [CrossRef]
- Wang, T.; Qu, D.; Jiang, T. Parity-Check-Concatenated Polar Codes. IEEE Commun. Lett. 2016, 20, 2342–2345. [Google Scholar] [CrossRef]
- Nokia. Chairman’s notes of AI 7.1.5 on channel coding and modulation for NR. In Proceedings of the Meeting 87, 3GPP TSG RAN WG1, Reno, NV, USA, 14–19 November 2016. [Google Scholar]
- Arikan, E. A performance comparison of polar codes and Reed-Muller codes. IEEE Commun. Lett. 2008, 12, 447–449. [Google Scholar] [CrossRef]
- ETSI. 5G; NR; Multiplexing and Channel Coding (Release 15); Version 15.6.0; Technical Specification (TS) 38.212, 3rd Generation Partnership Project (3GPP); ETSI: Sophia Antipolis, France, 2019. [Google Scholar]
- Mori, R.; Tanaka, T. Performance of Polar Codes with the Construction using Density Evolution. IEEE Commun. Lett. 2009, 13, 519–521. [Google Scholar] [CrossRef]
- Tal, I.; Vardy, A. How to Construct Polar Codes. IEEE Trans. Inf. Theory 2013, 59, 6562–6582. [Google Scholar] [CrossRef] [Green Version]
- Trifonov, P. Efficient Design and Decoding of Polar Codes. IEEE Trans. Commun. 2012, 60, 3221–3227. [Google Scholar] [CrossRef] [Green Version]
- Stark, M.; Shah, S.A.A.; Bauch, G. Polar code construction using the information bottleneck method. In Proceedings of the 2018 IEEE Wireless Communications and Networking Conference Workshops, Barcelona, Spain, 15–18 April 2018; pp. 7–12. [Google Scholar] [CrossRef]
- Shah, S.A.A.; Stark, M.; Bauch, G. Design of Quantized Decoders for Polar Codes using the Information Bottleneck Method. In Proceedings of the 12th International ITG Conference on Systems, Communications and Coding (SCC 2019), Rostock, Germany, 11–14 February 2019. [Google Scholar]
- Balatsoukas-Stimming, A.; Parizi, M.B.; Burg, A. LLR-based successive cancellation list decoding of polar codes. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 3903–3907. [Google Scholar] [CrossRef]
- Hassani, S.H.; Urbanke, R. Polar codes: Robustness of the successive cancellation decoder with respect to quantization. In Proceedings of the 2012 IEEE International Symposium on Information Theory Proceedings, Cambridge, MA, USA, 1–6 July 2012; pp. 1962–1966. [Google Scholar] [CrossRef]
- Shi, Z.; Chen, K.; Niu, K. On Optimized Uniform Quantization for SC Decoder of Polar Codes. In Proceedings of the 2014 IEEE 80th Vehicular Technology Conference (VTC2014-Fall), Vancouver, BC, Canada, 14–17 September 2014; pp. 1–5. [Google Scholar] [CrossRef]
- Giard, P.; Sarkis, G.; Balatsoukas-Stimming, A.; Fan, Y.; Tsui, C.; Burg, A.; Thibeault, C.; Gross, W.J. Hardware decoders for polar codes: An overview. In Proceedings of the 2016 IEEE International Symposium on Circuits and Systems (ISCAS), Montreal, QC, Canada, 22–25 May 2016; pp. 149–152. [Google Scholar] [CrossRef]
- Neu, J. Quantized Polar Code Decoders: Analysis and Design. arXiv 2019, arXiv:1902.10395. [Google Scholar]
- Hagenauer, J.; Offer, E.; Papke, L. Iterative decoding of binary block and convolutional codes. IEEE Trans. Inf. Theory 1996, 42, 429–445. [Google Scholar] [CrossRef]
- Lewandowsky, J.; Stark, M.; Bauch, G. Information Bottleneck Graphs for receiver design. In Proceedings of the 2016 IEEE International Symposium on Information Theory (ISIT), Barcelona, Spain, 10–15 July 2016; pp. 2888–2892. [Google Scholar] [CrossRef]
- Stark, M.; Lewandowsky, J. Information Bottleneck Algorithms in Python. Available online: https://goo.gl/QjBTZf (accessed on 25 August 2019).
- Lewandowsky, J.; Stark, M.; Bauch, G. A Discrete Information Bottleneck Receiver with Iterative Decision Feedback Channel Estimation. In Proceedings of the 2018 IEEE 10th International Symposium on Turbo Codes Iterative Information Processing (ISTC), Hong Kong, China, 3–7 December 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Hassanpour, S.; Wuebben, D.; Dekorsy, A. Overview and Investigation of Algorithms for the Information Bottleneck Method. In Proceedings of the 11th International ITG Conference on Systems, Communications and Coding (SCC 2017), Hamburg, Germany, 6–9 February 2017; pp. 1–6. [Google Scholar]
- Lewandowsky, J.; Stark, M.; Bauch, G. Message alignment for discrete LDPC decoders with quadrature amplitude modulation. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 2925–2929. [Google Scholar] [CrossRef]
- Elkelesh, A.; Ebada, M.; Cammerer, S.; ten Brink, S. Decoder-Tailored Polar Code Design Using the Genetic Algorithm. IEEE Trans. Commun. 2019, 67, 4521–4534. [Google Scholar] [CrossRef] [Green Version]
- Wu, D.; Li, Y.; Sun, Y. Construction and Block Error Rate Analysis of Polar Codes Over AWGN Channel Based on Gaussian Approximation. IEEE Commun. Lett. 2014, 18, 1099–1102. [Google Scholar] [CrossRef]























© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shah, S.A.A.; Stark, M.; Bauch, G. Coarsely Quantized Decoding and Construction of Polar Codes Using the Information Bottleneck Method. Algorithms 2019, 12, 192. https://doi.org/10.3390/a12090192
Shah SAA, Stark M, Bauch G. Coarsely Quantized Decoding and Construction of Polar Codes Using the Information Bottleneck Method. Algorithms. 2019; 12(9):192. https://doi.org/10.3390/a12090192
Chicago/Turabian StyleShah, Syed Aizaz Ali, Maximilian Stark, and Gerhard Bauch. 2019. "Coarsely Quantized Decoding and Construction of Polar Codes Using the Information Bottleneck Method" Algorithms 12, no. 9: 192. https://doi.org/10.3390/a12090192
APA StyleShah, S. A. A., Stark, M., & Bauch, G. (2019). Coarsely Quantized Decoding and Construction of Polar Codes Using the Information Bottleneck Method. Algorithms, 12(9), 192. https://doi.org/10.3390/a12090192