Time Series Clustering Model based on DTW for Classifying Car Parks

Abstract
:1. Introduction
2. Data and methodology
2.1. Dataset
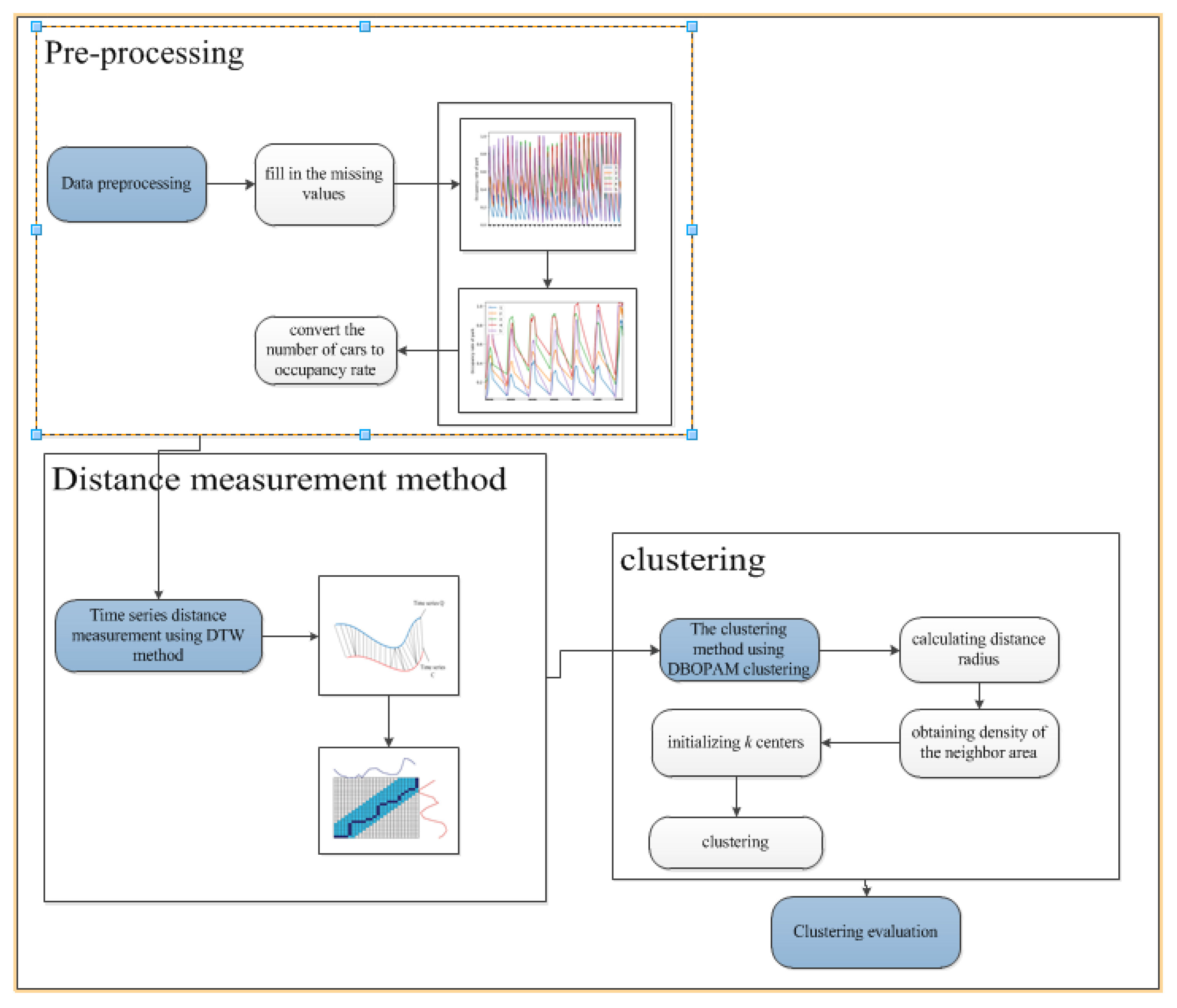
2.2. Framework for Classifying Car Parks
2.2.1. Data Preprocessing
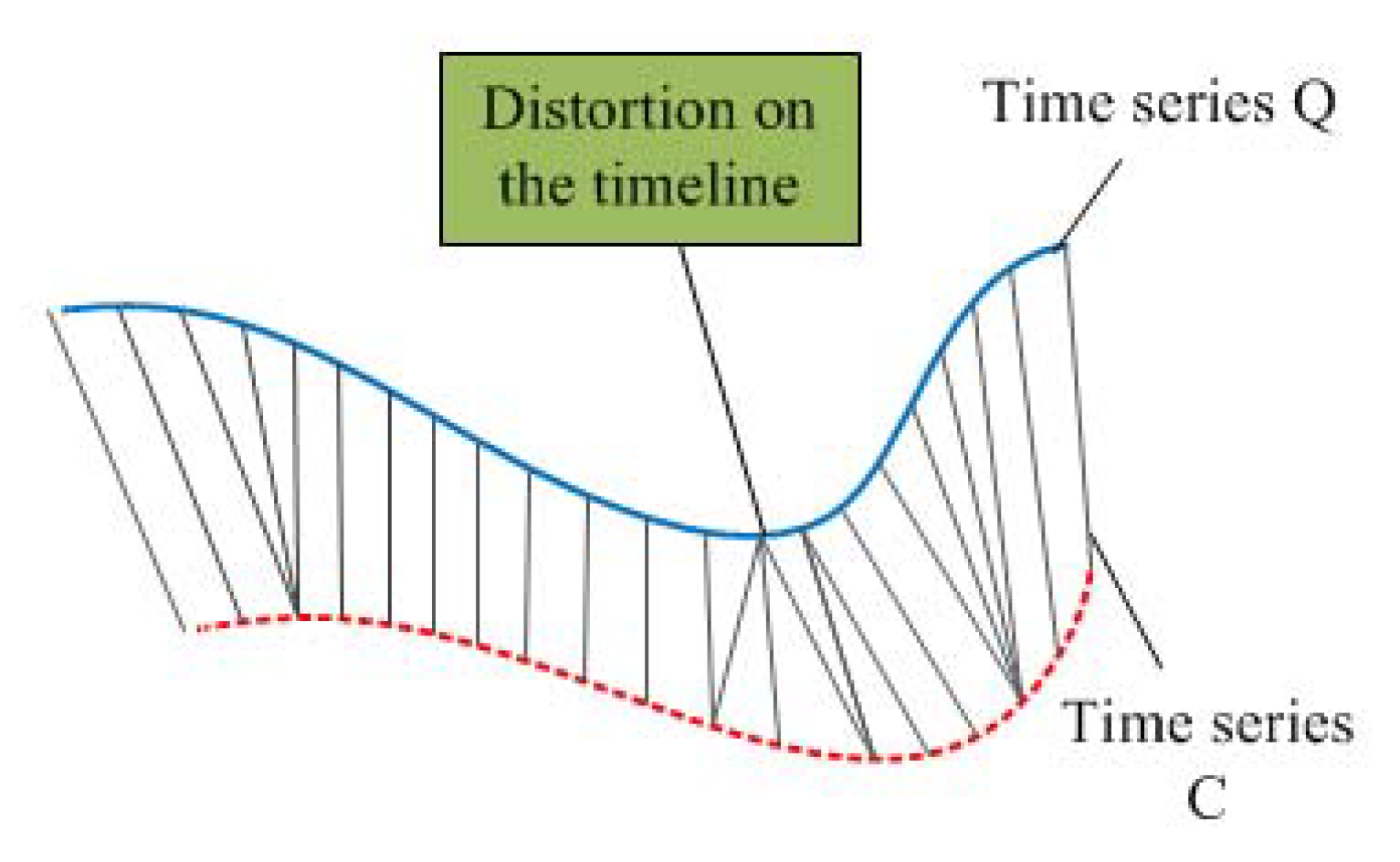
2.2.2. DTW
2.2.3. Clustering Algorithm
2.2.4. Performance Evaluation
2.3. Comparative Analysis of Experiments
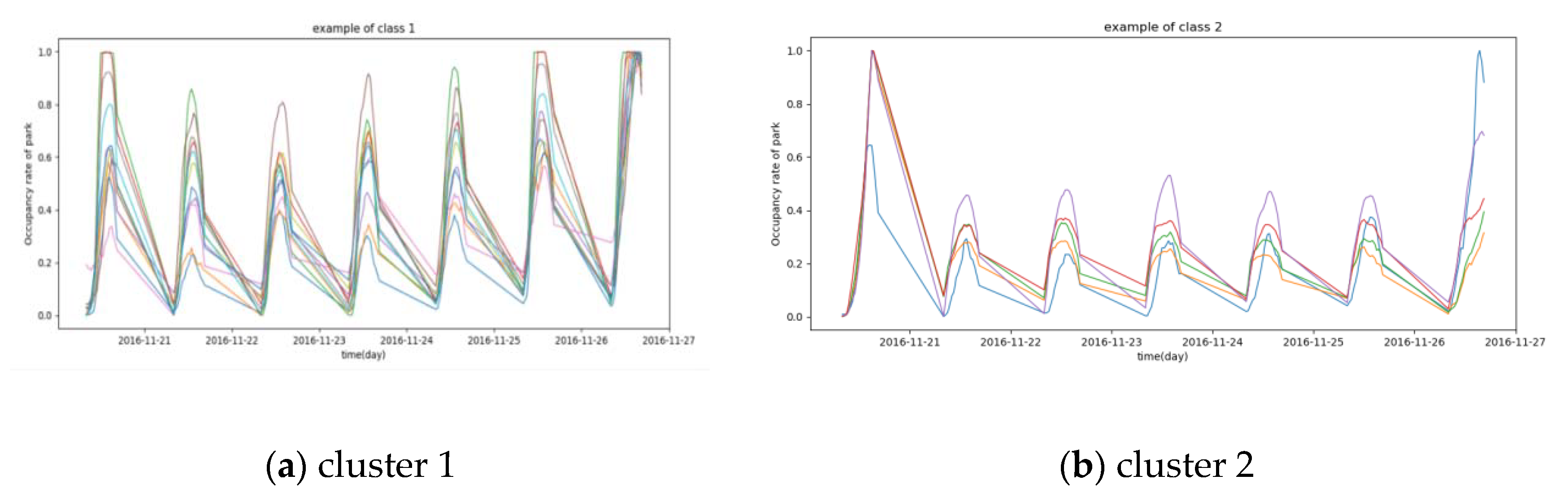
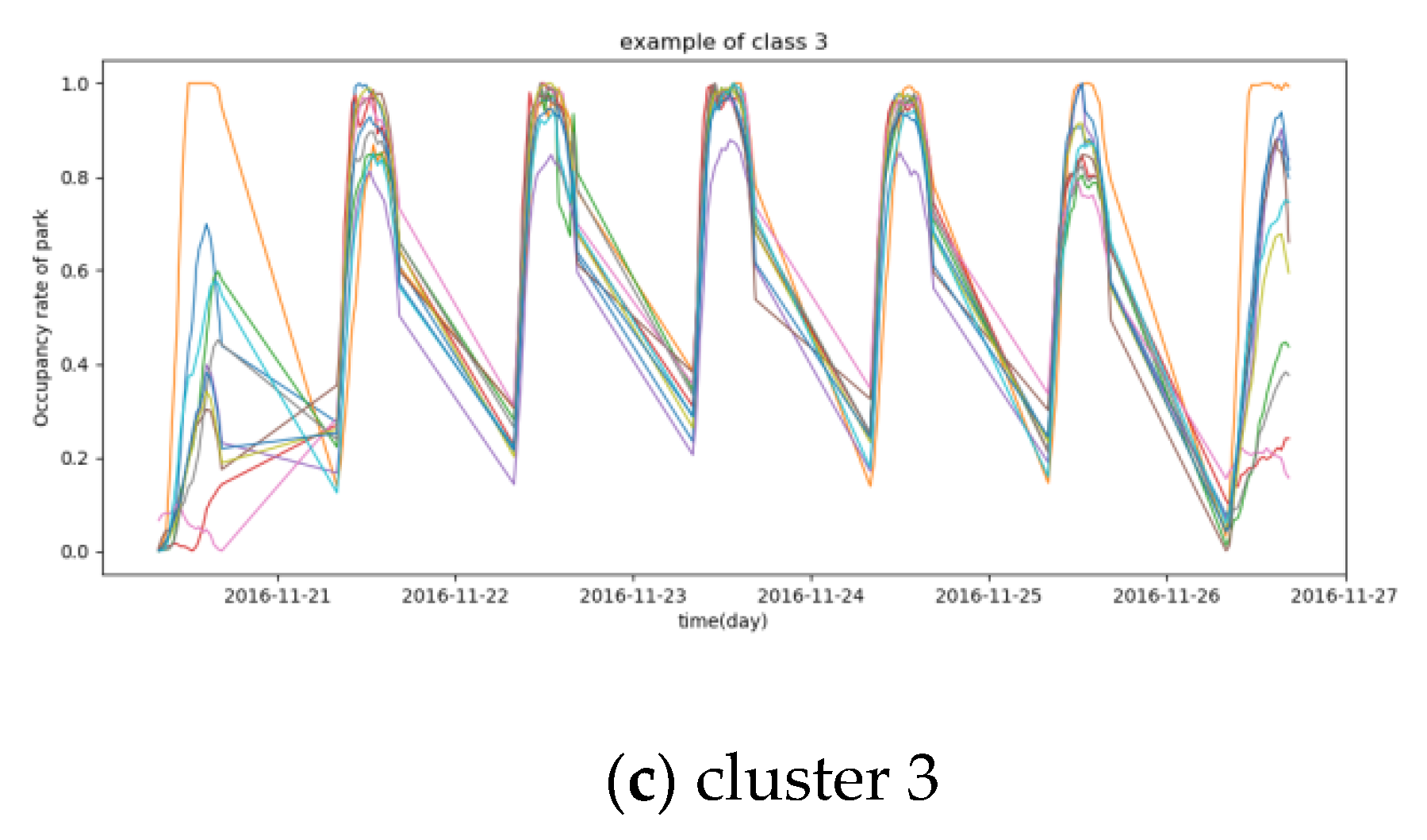
3. Results and Discussion of Car Parks Clustering
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Halsey III, A. DC tests new parking technology to help drivers find space, pay more easily. Wash. Post. 2010, 13, 479–486. [Google Scholar]
- Al-Turjman, F.; Malekloo, A. Smart parking in IoT-enabled cities: A survey. Sustain. Cities Soc. 2019, 49, 101608. [Google Scholar] [CrossRef]
- Kubota, T.; Hayashi, T.; Tarumi, T. Cluster analysis of car parking data, and development of their web applications. Commun. Stat. Appl. Methods 2011, 18, 549–557. [Google Scholar] [CrossRef] [Green Version]
- Klappenecker, A.; Lee, H.; Welch, J.L. Finding available parking spaces made easy. Ad Hoc Netw. 2014, 12, 243–249. [Google Scholar] [CrossRef]
- Caicedo, F.; Blazquez, C.; Miranda, P. Prediction of parking space availability in real time. Expert Syst. Appl. 2012, 39, 7281–7290. [Google Scholar] [CrossRef]
- Cheng, C.; Ji, Y.; Yin, Y.; Du, Y.; Sun, L. Designing a time limited-parking management plan for large-scale parking lots. J. Transp. Eng. Pt A Syst. 2018, 144, 04018027. [Google Scholar] [CrossRef]
- Fu, T. A review on time series data mining. Eng. Appl. Artif. Intell. 2011, 24, 164–181. [Google Scholar] [CrossRef]
- Esling, P.; Agon, C. Time-series data mining. ACM Comput. Surv. 2012, 45, 12. [Google Scholar] [CrossRef] [Green Version]
- Bokelmann, B.; Lessmann, S. Spurious patterns in google trends data-an analysis of the effects on tourism demand forecasting in Germany. Tour. Manag. 2019, 75, 1–12. [Google Scholar] [CrossRef]
- Karim, F.; Majumdar, S.; Darabi, H.; Chen, S. LSTM fully convolutional networks for time series classification. IEEE Access. 2017, 6, 1662–1669. [Google Scholar] [CrossRef]
- Sadi-Nezhad, S.; Damghani, K.K. Application of a fuzzy TOPSIS method base on modified preference ratio and fuzzy distance measurement in assessment of traffic police centers performance. Appl. Soft Comput. 2010, 10, 1028–1039. [Google Scholar] [CrossRef]
- Xu, R.; Wunsch, D. Survey of clustering algorithms. IEEE Trans. Neural Netw. 2005, 16, 645–678. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liao, T.W. Clustering of time series data—A survey. Pattern Recognit. 2005, 38, 1857–1874. [Google Scholar] [CrossRef]
- Hung, W.L.; Yang, M.S. Similarity measures of intuitionistic fuzzy sets based on Hausdorff distance. Pattern Recognit. Lett. 2004, 25, 1603–1611. [Google Scholar] [CrossRef]
- Xu, H.; Zeng, W.; Zeng, X.; Yen, G.G. An evolutionary algorithm based on Minkowski distance for many-objective optimization. IEEE Trans. Cybern. 2018, 49, 3968–3979. [Google Scholar] [CrossRef] [PubMed]
- Ioannidou, Z.S.; Theodoropoulou, M.C.; Papandreou, N.C.; Willis, J.H.; Hamodrakas, S.J. CutProtFam-Pred: Detection and classification of putative structural cuticular proteins from sequence alone, based on profile hidden Markov models. Insect Biochem. Mol. Biol. 2014, 52, 51–59. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.C.; Liu, L.; Li, P. Failure mode and effects analysis using intuitionistic fuzzy hybrid weighted Euclidean distance operator. Int. J. Syst. Sci. 2014, 45, 2012–2030. [Google Scholar] [CrossRef]
- Guan, X.; Huang, C.; Liu, G.; Meng, X.; Liu, Q. Mapping rice cropping systems in Vietnam using an NDVI-based time-series similarity measurement based on DTW distance. Remote Sens. 2016, 8, 19. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Wu, J.; Ni, J.; Chen, J.; Xi, C. Relationship Between Urban Road Traffic Characteristics and Road Grade Based on a Time Series Clustering Model: A Case Study in Nanjing, China. Chin. Geogra. Sci. 2018, 28, 144–156. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Mueen, A.; Ding, H.; Trajcevski, G.; Scheuermann, P.; Keogh, E. Experimental comparison of representation methods and distance measures for time series data. Data Min. Knowl. Discov. 2013, 26, 275–309. [Google Scholar] [CrossRef] [Green Version]
- Cánovas, J.S.; Guillamón, A.; Ruiz-Abellón, M.C. Using permutations for hierarchical clustering of time series. Entropy 2019, 21, 306. [Google Scholar] [CrossRef] [Green Version]
- Yao, Y.; Zhao, X.; Wu, Y.; Zhang, Y.; Rong, J. Clustering driver behavior using dynamic time warping and hidden Markov model. J. Intell. Transport. Syst. 2019, 1–14. [Google Scholar] [CrossRef]
- Petitjean, F.; Ketterlin, A.; Gançarski, P. A global averaging method for dynamic time warping, with applications to clustering. Pattern Recognit. 2011, 44, 678–693. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, X.; Li, X.; Liu, X.; Yao, Y.; Hu, G.; Xu, X.; Pei, F. Delineating urban functional areas with building-level social media data: A dynamic time warping (DTW) distance based k-medoids method. Landsc. Urban Plan 2017, 160, 48–60. [Google Scholar] [CrossRef]
- Izakian, H.; Pedrycz, W.; Jamal, I. Fuzzy clustering of time series data using dynamic time warping distance. Eng. Appl. Artif. Intell. 2015, 39, 235–244. [Google Scholar] [CrossRef]
- Huang, X.; Ye, Y.; Xiong, L.; Lau, R.Y.; Jiang, N.; Wang, S. Time series k-means: A new k-means type smooth subspace clustering for time series data. Inf. Sci. 2016, 367, 1–13. [Google Scholar] [CrossRef]
- Johnson, M.G.; Pokorny, L.; Dodsworth, S.; Botigue, L.R.; Cowan, R.S.; Devault, A.; Eiserhardt, W.L.; Epitawalage, N.; Forest, F.; Kim, J.T.; et al. A universal probe set for targeted sequencing of 353 nuclear genes from any flowering plant designed using k-medoids clustering. Syst. Biol. 2018, 68, 594–606. [Google Scholar] [CrossRef] [Green Version]
- Garain, J.; Kumar, R.K.; Kisku, D.R.; Sanyal, G. Addressing facial dynamics using k-medoids cohort selection algorithm for face recognition. Multimed. Tools Appl. 2019, 78, 18443–18474. [Google Scholar] [CrossRef]
- Li, Z.; Wang, G.; He, G. Milling tool wear state recognition based on partitioning around medoids (PAM) clustering. Int. J. Adv. Manuf. Technol. 2017, 88, 1203–1213. [Google Scholar] [CrossRef]
- Kou, G.; Peng, Y.; Wang, G. Evaluation of clustering algorithms for financial risk analysis using MCDM methods. Inf. Sci. 2014, 275, 1–12. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | k | train | test | total |
|---|---|---|---|---|
| EthanolLevel | 4 | 804 | 200 | 1004 |
| SyntheticControl | 6 | 480 | 120 | 600 |
| Strawbeerry | 2 | 787 | 196 | 983 |
| CBF | 3 | 744 | 186 | 930 |
| Beef | 5 | 48 | 12 | 60 |
| Coffee | 2 | 45 | 11 | 56 |
| SmoothSubspace | 3 | 240 | 60 | 300 |
| MoteStrain | 2 | 1018 | 254 | 1272 |
| SonyAIBORobotsurface1 | 2 | 497 | 124 | 621 |
| DataSet | Purity | |||||||
|---|---|---|---|---|---|---|---|---|
| ED+PAM | ED+DBPAM | DTW +PAM | DTW +DBPAM | |||||
| Train | Test | Train | Test | Train | Test | Train | Test | |
| EthanolLevel | 0.3188 | 0.38555 | 0.3562 | 0.408 | 0.35495 | 0.3532 | 0.3935 | 0.4726 |
| SyntheticControl | 0.67875 | 0.723333 | 0.7213 | 0.7867 | 0.71375 | 0.745 | 0.76875 | 0.791667 |
| Strawbeerry | 0.76132 | 0.75938 | 0.8066 | 0.7767 | 0.671749 | 0.6802 | 0.820611 | 0.8223 |
| CBF | 0.597043 | 0.627957 | 0.6022 | 0.64 | 0.709409 | 0.683871 | 0.553763 | 0.575269 |
| Beef | 0.53334 | 0.68334 | 0.5236 | 0.7225 | 0.54584 | 0.7 | 0.4792 | 0.75 |
| Coffee | 0.87112 | 0.89092 | 0.9115 | 0.9461 | 0.8667 | 0.94546 | 0.9556 | 0.9091 |
| SmoothSubspace | 0.63832 | 0.63998 | 0.6017 | 0.6549 | 0.70334 | 0.77998 | 0.6125 | 0.6833 |
| MoteStrain | 0.83558 | 0.8173 | 0.8722 | 0.8934 | 0.83538 | 0.82124 | 0.9855 | 0.9843 |
| SonyAIBORobotsurface1 | 0.8012 | 0.78388 | 0.83148 | 0.86844 | 0.73118 | 0.76844 | 0.992 | 1 |
| 0 | 0 | 0 | 1 | 3 | 2 | 6 | 6 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, T.; Wu, X.; Zhang, J. Time Series Clustering Model based on DTW for Classifying Car Parks. Algorithms 2020, 13, 57. https://doi.org/10.3390/a13030057
Li T, Wu X, Zhang J. Time Series Clustering Model based on DTW for Classifying Car Parks. Algorithms. 2020; 13(3):57. https://doi.org/10.3390/a13030057
Chicago/Turabian StyleLi, Taoying, Xu Wu, and Junhe Zhang. 2020. "Time Series Clustering Model based on DTW for Classifying Car Parks" Algorithms 13, no. 3: 57. https://doi.org/10.3390/a13030057
APA StyleLi, T., Wu, X., & Zhang, J. (2020). Time Series Clustering Model based on DTW for Classifying Car Parks. Algorithms, 13(3), 57. https://doi.org/10.3390/a13030057