MDAN-UNet: Multi-Scale and Dual Attention Enhanced Nested U-Net Architecture for Segmentation of Optical Coherence Tomography Images


Abstract
:1. Introduction
- We present an enhanced nested U-Net architecture named MDAN-UNet, taking advantages of re-designed skip pathways [21], multi-scale input, multi-scale side output and attention mechanism;
- We propose two versions of our method, which are MDAN-UNet-16 and MDAN-UNet-32 where 16 and 32 denote the number of convolutional kernels in the first encoder block. We validate the proposed methods on two OCT segmentation tasks (layer segmentation and fluid segmentation), and our methods outperform state-of-the-art networks, including Unet++ [21].
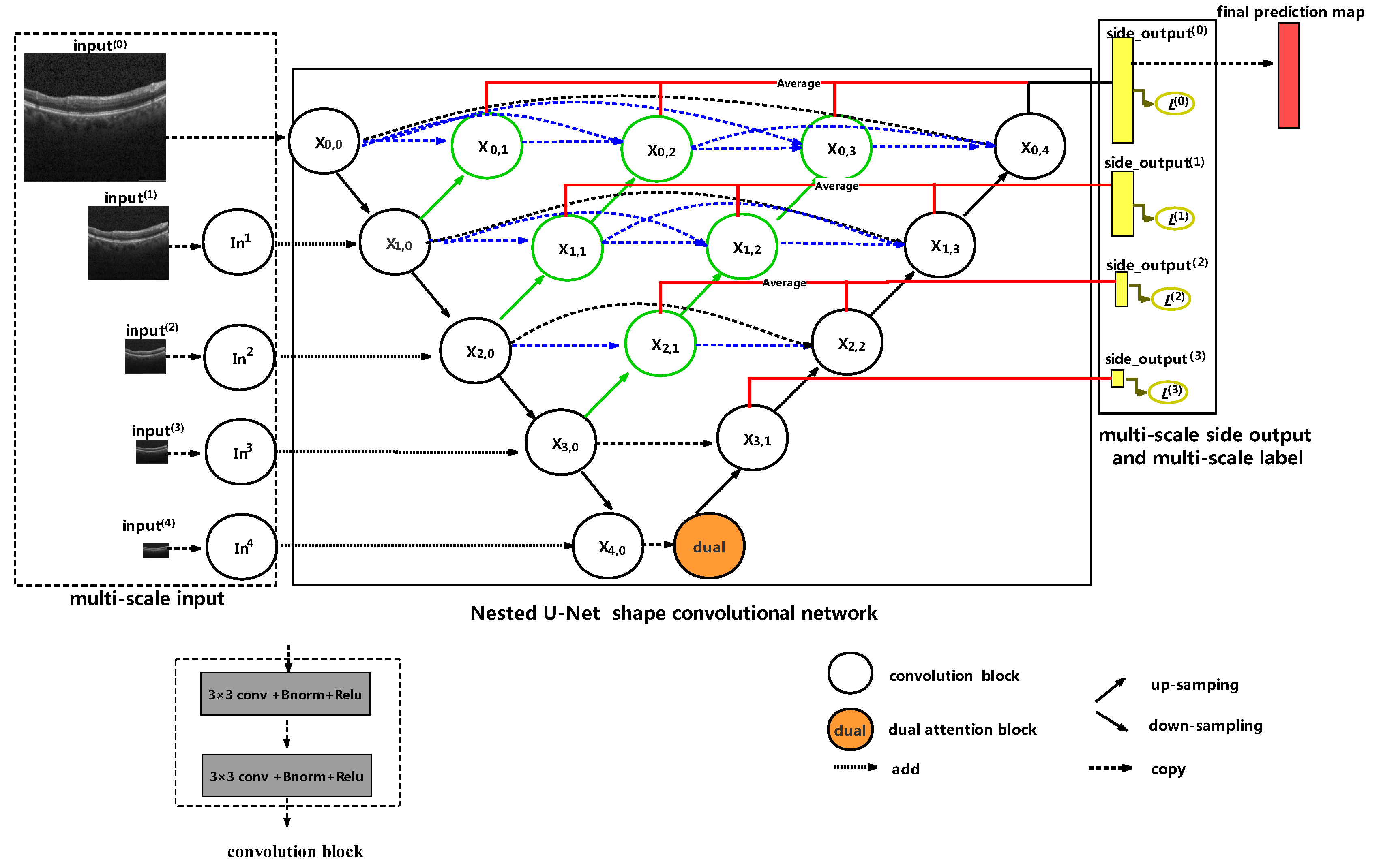
2. The Proposed Approach
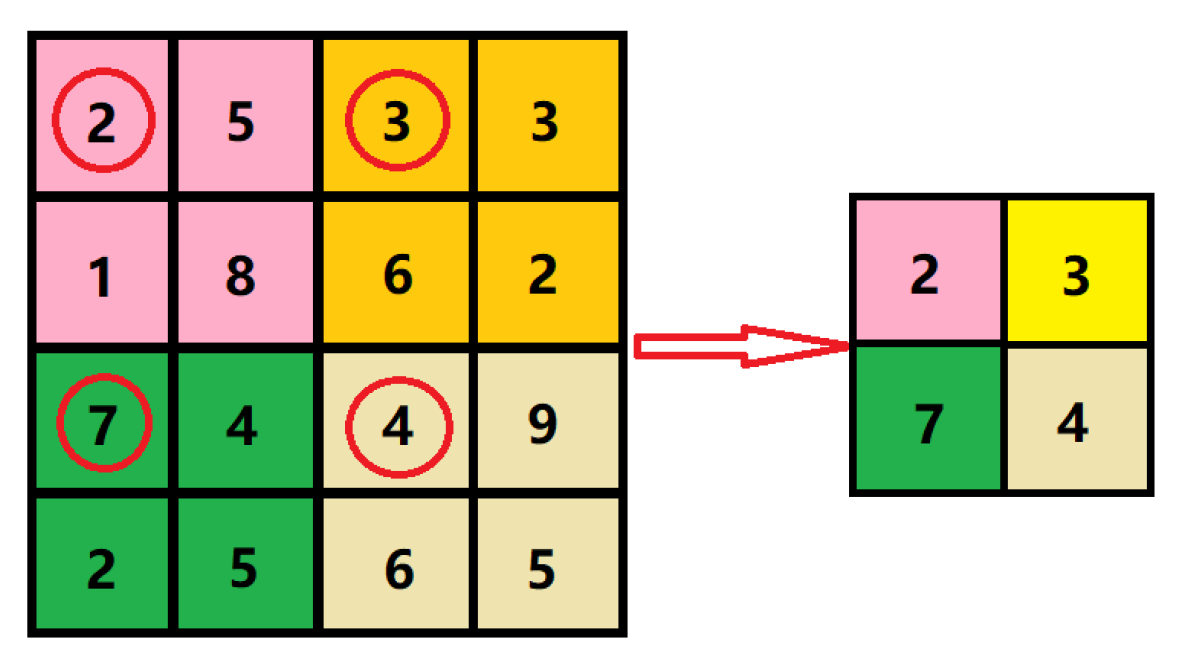
2.1. Multi-Scale Input
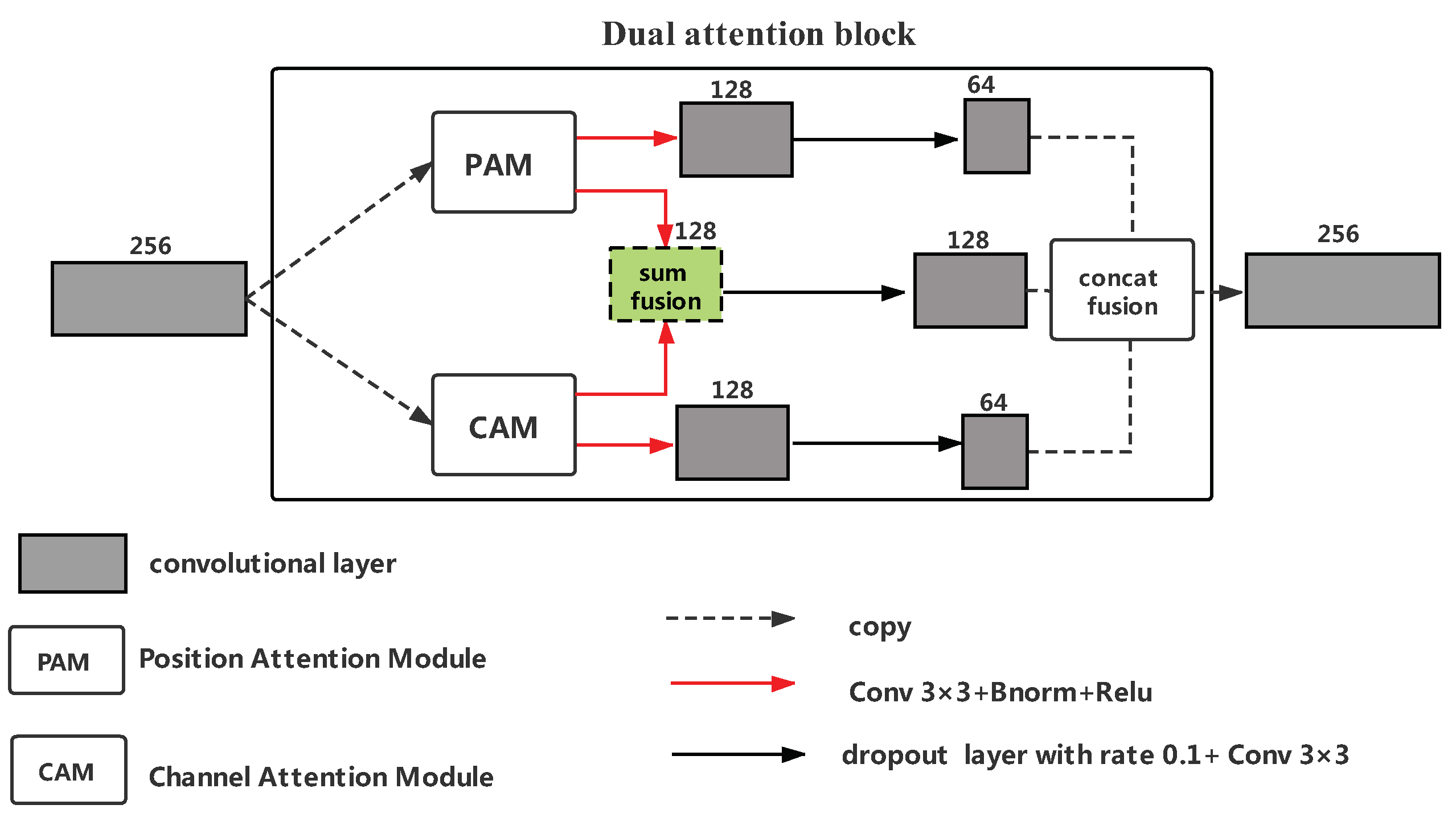
2.2. Nested U-Net shape convolutional network
2.3. Multi-Scale Side Output and Multi-Scale Label
3. Loss Function
- Weighted multi-class cross entropy, commonly used in semantic segmentation [9,10,17] to deal with the unbalance classes. Given a pixel i in the image , its formulation can be defined as follow:where denotes the weight associated with pixel i, and C is the number of classes. is the estimated probability of pixel i belonging to class c, and is one for the ground truth of pixel i belonging to class c and zero for others.Because most of the images are backgrounds, the classes are unbalance. What’s more, pixels near the boundary region are difficult to identify. So we apply larger weight for pixels belonging to foreground as well as pixels near the boundary region. Let a pixel i in the image , the formulation of is defined as follow:where is an indicator function, with one for is true and zero for others, and is value of pixel i in the ground map. L represents the values for foreground classes. ∇ denotes the gradient operator.
- Dice loss, proposed by [34], is commonly used to minimize the overlap error between the predicted probability and the true label. It can deal with class imbalance problems. To make sure all pixel values in the predicted probability are positive and in range 0 to 1 when calculating dice loss, we apply soft-max to the predicted probability. The soft-max is defined as:where is the pixel value in feature channel c at the pixel position i. Given a pixel i in the image , the formulation of dice loss is defined as:where is the estimated probability of pixel i in feature channel c. is one for the ground truth of pixel i belonging to class c and zero for others.
4. Experiments
4.1. Experiments settings
4.2. Layer Segmentation
4.2.1. Dataset
4.2.2. Preprocessing
4.2.3. Comparative Methods and Metric
- Dice score, which has been commonly used to evaluate the overlap of OCT segmentation:where P and Y are predicted output and ground truth respectively.
- Estimated contour error calculates mean absolute difference between the predicted layer contour and the ground truth layer contour along the column. The estimated contour error for contour c can be formulated aswhere and denote the predicted row location of contour c in column i and the ground truth one respectively, and N is the number of pixels for one row.
- Estimated thickness error for each layer calculates absolute difference in layer thickness. The estimated thickness error for layer l can be formulated as:where and denote the number of pixels belonging to layer l in column i and the ground truth one respectively. N is the number of pixels for one row.
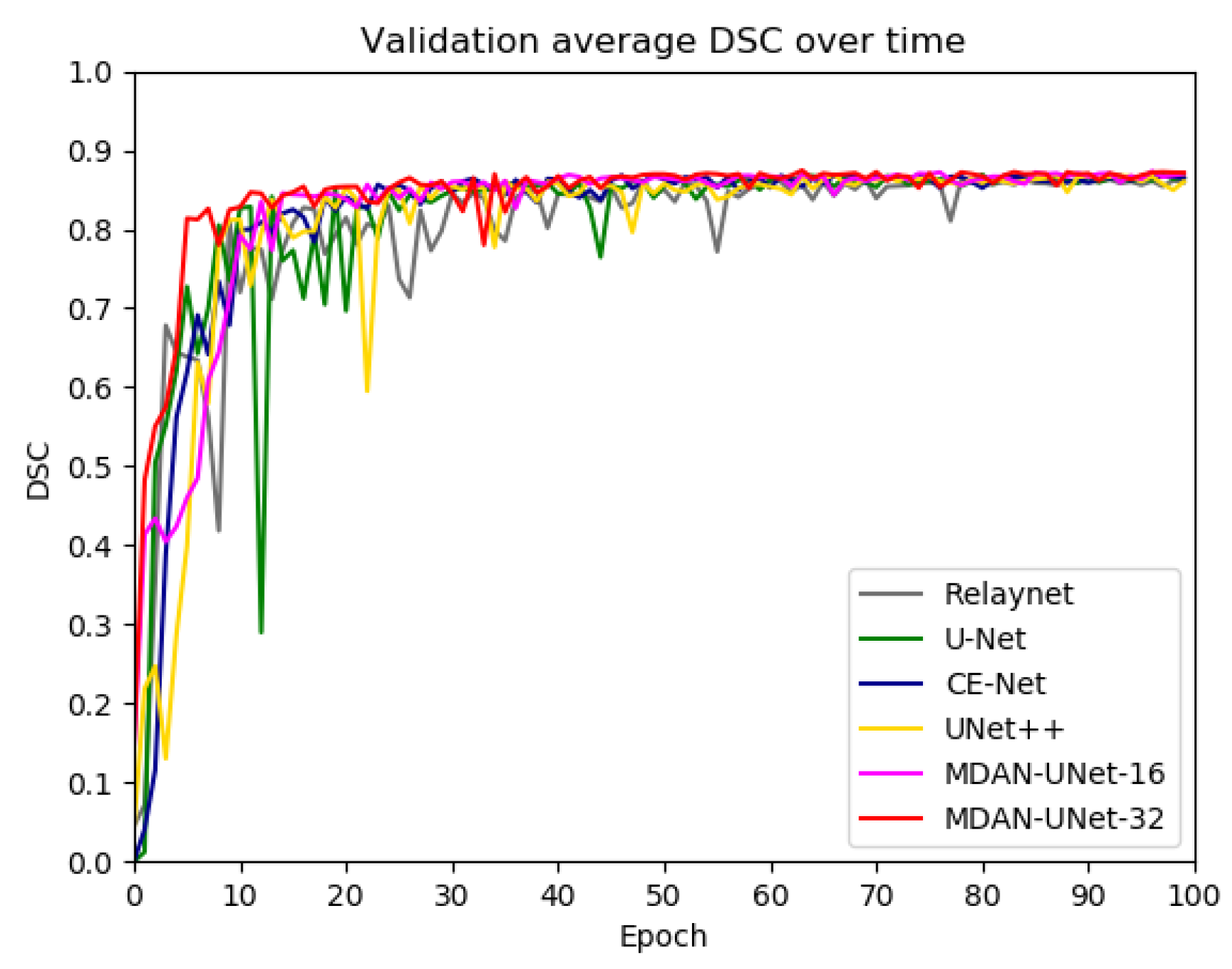
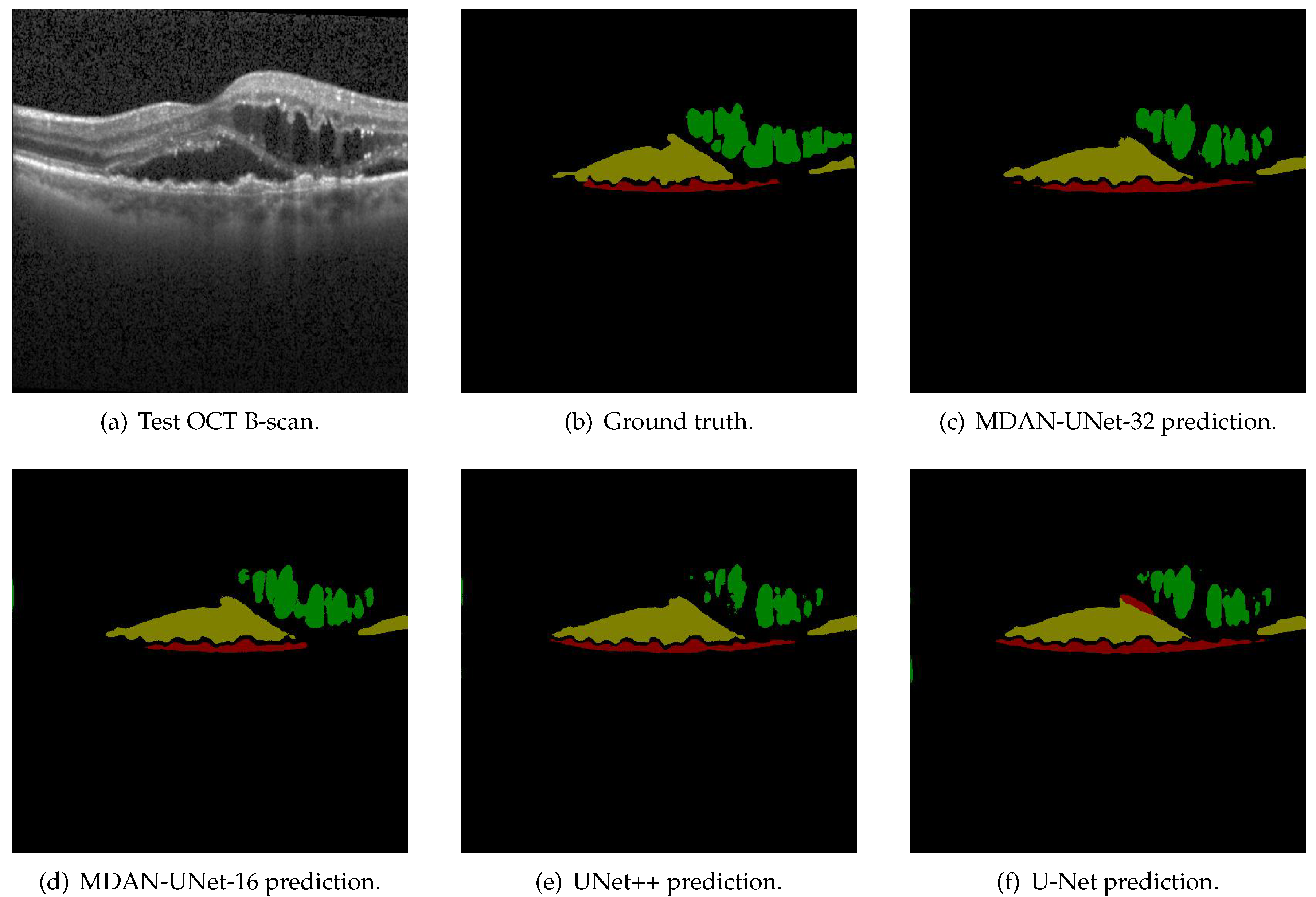
4.2.4. Results
4.3. Fluid Segmentation
4.3.1. Datasets
4.3.2. Preprocessing
4.3.3. Comparative Methods and Metric
- Absolute volume difference (AVD) :where P and Y are predicted output and ground truth respectively.
4.3.4. Results
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Huang, D.; Swanson, E.A.; Lin, C.P.; Schuman, J.S.; Stinson, W.G.; Chang, W.; Hee, M.R.; Flotte, T.; Gregory, K.; Puliafito, C.A.; et al. Optical coherence tomography. Science 1991, 254, 1178–1181. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schmidt-Erfurth, U.; Waldstein, S.M. A paradigm shift in imaging biomarkers in neovascular age-related macular degeneration. Prog. Retin. Eye Res. 2016, 50, 1–24. [Google Scholar] [CrossRef] [PubMed]
- Davidson, J.A.; Ciulla, T.A.; McGill, J.B.; Kles, K.A.; Anderson, P.W. How the diabetic eye loses vision. Endocrine 2007, 32, 107–116. [Google Scholar] [CrossRef] [PubMed]
- DeBuc, D.C. A review of algorithms for segmentation of retinal image data using optical coherence tomography. Image Segm. 2011, 1, 15–54. [Google Scholar]
- Schmidt-Erfurth, U.; Sadeghipour, A.; Gerendas, B.S.; Waldstein, S.M.; Bogunović, H. Artificial intelligence in retina. Prog. Retin. Eye Res. 2018, 67, 1–29. [Google Scholar] [CrossRef]
- Chiu, S.J.; Allingham, M.J.; Mettu, P.S.; Cousins, S.W.; Izatt, J.A.; Farsiu, S. Kernel regression based segmentation of optical coherence tomography images with diabetic macular edema. Biomed. Opt. Express 2015, 6, 1172–1194. [Google Scholar] [CrossRef] [Green Version]
- Karri, S.; Chakraborthi, D.; Chatterjee, J. Learning layer-specific edges for segmenting retinal layers with large deformations. Biomed. Opt. Express 2016, 7, 2888–2901. [Google Scholar] [CrossRef] [Green Version]
- Montuoro, A.; Waldstein, S.M.; Gerendas, B.S.; Schmidt-Erfurth, U.; Bogunović, H. Joint retinal layer and fluid segmentation in OCT scans of eyes with severe macular edema using unsupervised representation and auto-context. Biomed. Opt. Express 2017, 8, 1874–1888. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Devalla, S.K.; Renukanand, P.K.; Sreedhar, B.K.; Perera, S.; Mari, J.M.; Chin, K.S.; Tun, T.A.; Strouthidis, N.G.; Aung, T.; Thiéry, A.H.; et al. DRUNET: A dilated-residual u-net deep learning network to digitally stain optic nerve head tissues in optical coherence tomography images. arXiv 2018, arXiv:1803.00232. [Google Scholar] [CrossRef] [Green Version]
- Zadeh, S.G.; Wintergerst, M.W.; Wiens, V.; Thiele, S.; Holz, F.G.; Finger, R.P.; Schultz, T. CNNs enable accurate and fast segmentation of drusen in optical coherence tomography. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: New York, NY, USA, 2017; pp. 65–73. [Google Scholar]
- Venhuizen, F.G.; van Ginneken, B.; Liefers, B.; van Asten, F.; Schreur, V.; Fauser, S.; Hoyng, C.; Theelen, T.; Sánchez, C.I. Deep learning approach for the detection and quantification of intraretinal cystoid fluid in multivendor optical coherence tomography. Biomed. Opt. Express 2018, 9, 1545–1569. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.; Li, D.; Shen, H.; Mo, H.; Zeng, Z.; Wei, H. Automated segmentation of fluid regions in optical coherence tomography B-scan images of age-related macular degeneration. Opt. Laser Technol. 2020, 122, 105830. [Google Scholar] [CrossRef]
- Ben-Cohen, A.; Mark, D.; Kovler, I.; Zur, D.; Barak, A.; Iglicki, M.; Soferman, R. Retinal layers segmentation using fully convolutional network in OCT images. 2017. Available online: https://www.rsipvision.com/wp-content/uploads/2017/06/Retinal-Layers-Segmentation.pdf (accessed on 29 February 2020).
- Lu, D.; Heisler, M.; Lee, S.; Ding, G.W.; Navajas, E.; Sarunic, M.V.; Beg, M.F. Deep-learning based multiclass retinal fluid segmentation and detection in optical coherence tomography images using a fully convolutional neural network. Med Image Anal. 2019, 54, 100–110. [Google Scholar] [CrossRef] [PubMed]
- Roy, A.G.; Conjeti, S.; Karri, S.P.K.; Sheet, D.; Katouzian, A.; Wachinger, C.; Navab, N. ReLayNet: Retinal layer and fluid segmentation of macular optical coherence tomography using fully convolutional networks. Biomed. Opt. Express 2017, 8, 3627–3642. [Google Scholar] [CrossRef] [PubMed]
- Gu, Z.; Cheng, J.; Fu, H.; Zhou, K.; Hao, H.; Zhao, Y.; Zhang, T.; Gao, S.; Liu, J. CE-Net: Context encoder network for 2D medical image segmentation. IEEE Trans. Med Imaging 2019, 38, 2281–2292. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: New York, NY, USA, 2018; pp. 3–11. [Google Scholar]
- Lee, C.-Y.; Xie, S.; Gallagher, P.; Zhang, Z.; Tu, Z. Deeply-supervised nets. In Proceedings of the 18th International Conference on Artificial Intelligence and Statistics, San Diego, CA, USA, 9–12 May 2015; Volume 38, pp. 562–570. [Google Scholar]
- Fu, H.; Cheng, J.; Xu, Y.; Wong, D.W.K.; Liu, J.; Cao, X. Joint optic disc and cup segmentation based on multi-label deep network and polar transformation. IEEE Trans. Med Imaging 2018, 37, 1597–1605. [Google Scholar] [CrossRef] [Green Version]
- Abraham, N.; Khan, N.M. A novel focal tversky loss function with improved attention u-net for lesion segmentation. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 683–687. [Google Scholar]
- Xie, S.; Tu, Z. Holistically-nested edge detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1395–1403. [Google Scholar]
- Chu, X.; Yang, W.; Ouyang, W.; Ma, C.; Yuille, A.L.; Wang, X. Multi-context attention for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1831–1840. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid attention network for semantic segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Zhang, P.; Liu, W.; Wang, H.; Lei, Y.; Lu, H. Deep gated attention networks for large-scale street-level scene segmentation. Pattern Recognit. 2019, 88, 702–714. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3146–3154. [Google Scholar]
- Zeiler, M.D.; Krishnan, D.; Taylor, G.W.; Fergus, R. Deconvolutional networks. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2528–2535. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in pytorch. 2017. Available online: https://openreview.net/pdf?id=BJJsrmfCZ (accessed on 29 February 2020).
- Kingma, D.P. Adam: A method for stochastic optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Simard, P.Y.; Steinkraus, D.; Platt, J.C. Best practices for convolutional neural networks applied to visual document analysis. In Proceedings of the 7th International Conference on Document Analysis and Recognition, Edinburgh, UK, 6 August 2003. [Google Scholar]
- Bogunović, H.; Venhuizen, F.; Klimscha, S.; Apostolopoulos, S.; Bab-Hadiashar, A.; Bagci, U.; Beg, M.F.; Bekalo, L.; Chen, Q.; Ciller, C.; et al. RETOUCH: The Retinal OCT Fluid Detection and Segmentation Benchmark and Challenge. IEEE Trans. Med Imaging 2019, 38, 1858–1874. [Google Scholar] [CrossRef] [PubMed]
- Tennakoon, R.; Gostar, A.K.; Hoseinnezhad, R.; Bab-Hadiashar, A. Retinal fluid segmentation and classification in OCT images using adversarial loss based CNN. In Proceedings of the MICCAI Retinal OCT Fluid Challenge (RETOUCH), Quebec, QC, Canada, 10–14 September 2017; pp. 30–37. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Architecture | Params | |||||
|---|---|---|---|---|---|---|
| U-Net [10] | 13.39M | 64 | 128 | 256 | 512 | 1024 |
| ReLayNet [17] | 7.74M | 64 | 64 | 64 | 64 | 64 |
| CE-Net [18] | 29M | - | - | - | - | - |
| UNet++ [21] | 9.16M | 32 | 64 | 128 | 256 | 512 |
| MDAN-UNet-16 | 3.77M | 16 | 32 | 64 | 128 | 256 |
| MDAN-UNet-32 | 15.02M | 32 | 64 | 128 | 256 | 512 |
| ILM | NFL-IPL | INL | OPL | ONL-ISM | ISE | OSE-RPE | Average | ||
|---|---|---|---|---|---|---|---|---|---|
| Expert 1 | LSE [7] | 0.874 | 0.909 | 0.807 | 0.770 | 0.944 | 0.889 | 0.868 | 0.866 |
| U-Net [10] | 0.884 | 0.917 | 0.818 | 0.793 | 0.947 | * 0.901 | 0.871 | 0.876 | |
| ReLayNet [17] | 0.884 | 0.914 | 0.811 | 0.795 | 0.945 | 0.895 | 0.870 | 0.874 | |
| CE-Net [18] | 0.885 | 0.917 | * 0.823 | 0.795 | 0.947 | 0.892 | 0.871 | 0.876 | |
| UNet++ [21] | 0.887 | 0.920 | 0.815 | 0.794 | * 0.948 | 0.902 | 0.880 | 0.878 | |
| MDAN-UNet-16 | 0.890 | * 0.923 | * 0.823 | * 0.800 | 0.950 | 0.900 | 0.874 | * 0.880 | |
| MDAN-UNet-32 | * 0.889 | 0.924 | 0.830 | 0.806 | 0.957 | 0.902 | * 0.876 | 0.883 | |
| Expert 2 | LSE [7] | 0.868 | 0.900 | 0.802 | 0.756 | 0.944 | 0.878 | 0.845 | 0.856 |
| U-Net [10] | 0.873 | 0.904 | 0.810 | 0.772 | 0.943 | 0.880 | 0.838 | 0.860 | |
| ReLayNet [17] | 0.870 | 0.898 | 0.805 | 0.768 | 0.945 | * 0.886 | 0.844 | 0.860 | |
| CE-Net [18] | * 0.874 | 0.903 | * 0.814 | 0.775 | 0.948 | 0.882 | 0.841 | 0.862 | |
| UNet++ [21] | 0.870 | 0.905 | 0.803 | 0.770 | * 0.947 | 0.888 | * 0.850 | 0.862 | |
| MDAN-UNet-16 | 0.877 | * 0.908 | 0.810 | * 0.777 | * 0.947 | 0.885 | 0.847 | * 0.865 | |
| MDAN-UNet-32 | * 0.874 | 0.909 | 0.818 | 0.783 | 0.948 | 0.883 | 0.848 | 0.866 |
| ILM | NFL-IPL | INL | OPL | ONL-ISM | ISE | OSE-RPE | Average | ||
|---|---|---|---|---|---|---|---|---|---|
| Expert 1 | LSE [7] | 1.764 | 2.25 | 2.195 | 2.315 | 2.314 | 1.268 | 1.231 | 1.905 |
| U-Net [10] | 1.542 | 1.763 | 1.936 | 1.732 | 2.126 | 1.149 | * 1.037 | 1.612 | |
| ReLayNet [17] | 1.558 | 1.894 | 1.802 | 1.699 | 2.165 | 1.178 | 1.032 | 1.618 | |
| CE-Net [18] | 1.567 | 1.852 | 1.638 | 1.745 | 2.039 | 1.234 | 1.104 | 1.597 | |
| UNet++ [21] | 1.533 | 1.887 | 1.733 | 1.743 | * 1.952 | 1.060 | 1.111 | 1.574 | |
| MDAN-UNet-16 | 1.466 | * 1.728 | 1.661 | * 1.701 | 2.006 | 1.112 | 1.092 | * 1.538 | |
| MDAN-UNet-32 | * 1.480 | 1.686 | * 1.640 | 1.710 | 1.928 | * 1.099 | 1.055 | 1.514 | |
| Expert 2 | LSE [7] | 2.055 | 2.533 | 2.264 | 2.25 | 2.303 | 1.327 | 1.429 | 2.023 |
| U-Net [10] | * 1.891 | * 2.117 | 2.010 | 1.860 | 2.129 | 1.318 | 1.347 | 1.810 | |
| ReLayNet [17] | 2.028 | 2.273 | 1.900 | 1.732 | 2.160 | 1.374 | 1.319 | 1.827 | |
| CE-Net [18] | 1.920 | 2.192. | 1.835 | 1.833 | * 1.978 | 1.393 | 1.349 | 1.786 | |
| U-Net++ [21] | 1.931 | 2.126 | 1.932 | 1.803 | 2.030 | 1.286 | 1.284 | 1.767 | |
| MDAN-UNet-16 | 1.881 | 2.128 | 1.905 | * 1.778 | 2.054 | * 1.277 | * 1.298 | * 1.760 | |
| MDAN-UNet-32 | * 1.891 | 2.110 | * 1.869 | 1.816 | 1.959 | 1.257 | 1.311 | 1.745 |
| Contour1 | Contour2 | Contour3 | Contour4 | Contour5 | Contour6 | Contour7 | Contour8 | Average | ||
|---|---|---|---|---|---|---|---|---|---|---|
| Expert 1 | LSE [7] | 0.969 | 1.625 | 1.698 | 1.704 | 2.146 | 0.863 | 1.086 | 0.863 | 1.369 |
| U-Net [10] | 1.046 | 1.455 | 1.450 | 1.788 | 1.997 | 0.796 | 1.490 | 0.936 | 1.369 | |
| ReLayNet [17] | 1.024 | 1.523 | 1.530 | 1.811 | 1.886 | 0.906 | * 0.902 | 0.796 | 1.297 | |
| CE-Net [18] | 0.996 | 1.448 | 1.445 | * 1.547 | 1.764 | 0.963 | 0.971 | 0.943 | 1.260 | |
| UNet++ [21] | * 0.981 | 1.377 | 1.495 | 1.595 | 1.840 | 0.833 | 0.896 | 0.931 | 1.244 | |
| MDAN-UNet-16 | 0.995 | 1.334 | * 1.357 | 1.603 | * 1.802 | * 0.779 | 0.950 | 0.872 | * 1.212 | |
| MDAN-UNet-32 | 1.040 | * 1.336 | 1.323 | 1.493 | 1.825 | 0.777 | 0.919 | * 0.832 | 1.193 | |
| Expert 2 | LSE [7] | * 0.906 | 1.826 | 1.853 | 1.753 | 2.125 | 0.901 | 1.229 | 1.112 | 1.463 |
| U-Net [10] | 1.026 | 1.721 | 1.623 | 1.887 | 2.089 | 0.865 | 1.782 | 1.170 | 1.521 | |
| ReLayNet [17] | 0.965 | 1.865 | 1.739 | 1.892 | 1.930 | 0.842 | 1.157 | * 1.070 | 1.432 | |
| CE-Net [18] | 0.966 | 1.740 | 1.605 | * 1.678 | 1.810 | 0.911 | 1.203 | 1.186 | 1.387 | |
| UNet++ [21] | 0.968 | 1.733 | 1.634 | 1.812 | * 1.884 | 0.824 | 1.110 | 1.187 | 1.394 | |
| MDAN-UNet-16 | 0.926 | 1.671 | * 1.534 | 1.769 | 1.887 | * 0.839 | 1.152 | 1.102 | * 1.364 | |
| MDAN-UNet-32 | 1.043 | * 1.690 | 1.514 | 1.641 | 1.928 | 0.867 | * 1.148 | 1.064 | 1.362 |
| Expert 1 | Expert 2 | |||||
|---|---|---|---|---|---|---|
| DSC | TE | CE | DSC | TE | CE | |
| UNet++ [21] | 0.878 | 1.574 | 1.244 | 0.862 | 1.767 | 1.394 |
| Backbone | 0.879 | 1.561 | 1.241 | 0.863 | 1.766 | 1.392 |
| Backbone+Attention Block | 0.881 | 1.557 | 1.225 | 0.864 | 1.788 | 1.379 |
| Backbone+Attention Block+Multi-input | 0.883 | 1.542 | 1.202 | 0.865 | 1.766 | 1.371 |
| MDAN-UNet-32 | 0.883 | 1.514 | 1.193 | 0.866 | 1.745 | 1.362 |
| IRF | SRF | PED | ALL | ||
|---|---|---|---|---|---|
| Cirrus | U-Net [10] | 0.676(0.16) | * 0.739(0.09) | 0.485(0.21) | 0.627(0.20) |
| UNet++ [21] | 0.646(0.23) | 0.665(0.17) | 0.500(0.14) | 0.604(0.21) | |
| MDAN-UNet-16 | * 0.724(0.11) | 0.708(0.12) | 0.530(0.19) | * 0.662(0.17) | |
| MDAN-UNet-32 | 0.753(0.11) | 0.743(0.11) | * 0.512(0.14) | 0.677(0.16) | |
| Spectralis | U-Net [10] | 0.524(0.26) | 0.600(0.38) | 0.709(0.24) | 0.592(0.31) |
| UNet++ [21] | 0.563(0.20) | 0.745(0.27) | * 0.714(0.24) | 0.651(0.25) | |
| MDAN-UNet-16 | 0.627(0.17) | * 0.736(0.26) | * 0.714(0.26) | * 0.679(0.23) | |
| MDAN-UNet-32 | * 0.621(0.17) | 0.731(0.30) | 0.754(0.22) | 0.685(0.23) | |
| Topcon | U-Net [10] | 0.652(0.14) | 0.494(0.36) | * 0.600(0.07) | 0.594(0.23) |
| UNet++ [21] | 0.668(0.11) | 0.493(0.36) | 0.598(0.10) | 0.602(0.23) | |
| MDAN-UNet-16 | * 0.675(0.11) | * 0.516(0.26) | 0.586(0.26) | * 0.609(0.23) | |
| MDAN-UNet-32 | 0.706(0.10) | 0.530(0.38) | 0.677(0.02) | 0.648(0.23) | |
| average | 0.652(0.16) | 0.641(0.26) | 0.614(0.17) | 0.635(0.22) |
| IRF | SRF | PED | ALL | ||
|---|---|---|---|---|---|
| Cirrus | U-Net [10] | 0.193(0.25) | 0.132(0.12) | 0.120(0.15) | * 0.161(0.21) |
| UNet++ [21] | 0.203(0.26) | * 0.097(0.10) | * 0.128(0.11) | 0.164(0.20) | |
| MDAN-UNet-16 | * 0.153(0.20) | 0.098(0.10) | 0.241(0.18) | 0.171(0.19) | |
| MDAN-UNet-32 | 0.144(0.20) | 0.085(0.07) | 0.141(0.11) | 0.134 (0.16) | |
| Spectralis | U-Net [10] | 0.080(0.09) | 0.098(0.11) | 0.096(0.06) | 0.089(0.09) |
| UNet+ [21] | 0.104(0.12) | * 0.072(0.08) | * 0.089(0.05) | 0.092(0.09) | |
| MDAN-UNet-16 | * 0.063(0.08) | 0.091(0.10) | 0.095(0.08) | * 0.079(0.09) | |
| MDAN-UNet-32 | 0.056(0.12) | 0.047(0.05) | 0.067(0.06) | 0.056(0.09) | |
| Topcon | U-Net [10] | * 0.036(0.03) | * 0.061(0.07) | 0.051(0.04) | 0.048(0.05) |
| UNet++ [21] | * 0.036(0.03) | 0.073(0.08) | * 0.039(0.04) | 0.048(0.05) | |
| MDAN-UNet-16 | 0.048(0.03) | 0.040(0.04) | 0.054(0.02) | * 0.047(0.03) | |
| MDAN-UNet-32 | 0.034(0.03) | 0.064(0.09) | 0.026(0.004) | 0.041(0.07) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, W.; Sun, Y.; Ji, Q. MDAN-UNet: Multi-Scale and Dual Attention Enhanced Nested U-Net Architecture for Segmentation of Optical Coherence Tomography Images. Algorithms 2020, 13, 60. https://doi.org/10.3390/a13030060
Liu W, Sun Y, Ji Q. MDAN-UNet: Multi-Scale and Dual Attention Enhanced Nested U-Net Architecture for Segmentation of Optical Coherence Tomography Images. Algorithms. 2020; 13(3):60. https://doi.org/10.3390/a13030060
Chicago/Turabian StyleLiu, Wen, Yankui Sun, and Qingge Ji. 2020. "MDAN-UNet: Multi-Scale and Dual Attention Enhanced Nested U-Net Architecture for Segmentation of Optical Coherence Tomography Images" Algorithms 13, no. 3: 60. https://doi.org/10.3390/a13030060
APA StyleLiu, W., Sun, Y., & Ji, Q. (2020). MDAN-UNet: Multi-Scale and Dual Attention Enhanced Nested U-Net Architecture for Segmentation of Optical Coherence Tomography Images. Algorithms, 13(3), 60. https://doi.org/10.3390/a13030060