1. Introduction
Gaze tracking can help understand cognitive processes and emotional state, and has been applied in many fields, such as medicine, Human-Computer Interaction (HCI), and e-learning [
1,
2,
3]. The techniques of gaze tracking are classified into two methods, model-based and appearance-based [
4]. First, the model-based method mainly uses the near-infrared light device to track the pupil position and the designed algorithm to estimate the gaze points which usually require expensive hardware [
5]. A simple video-based eye tracking system was developed with one camera and one infrared light source to determine a person’s point of regard (PoR) [
6], assuming the location of features in the eye video is known. Zhu et al. [
7] used the dynamic head compensation model to solve the effect of head movement for estimating the gaze movement. Zhou et al. [
8] used the Kinect sensor to detect the three-dimensional coordinates of the head movement. Then the gaze is calculated by using the estimated eye model parameters acquired from gradients iris center localization method, geometric constraints-based and Kappa angle calculation method.
Second, the appearance-based method mainly uses the technology of machine learning to gain the features of a large number of input samples, such as eye, eyes or face, and then used the learning model to predict the gaze [
9]. Wu et al. [
10] proposed two procedures to estimate the gazing direction. First, the eye region is located by modifying the characteristics of the Active Appearance Model. Then the five gazing direction classes are predicted by employing the Support Vector Machine (SVM). Because deep learning (DL) and Convolution Neural Network (CNN) has a prominent performance in computer vision, there are some studies that are used to improve the accuracy of eye movement prediction considering as a regression task [
11,
12,
13,
14,
15] or a classification task [
11,
16]. The authors applied the convolutional neural network and trained a regression model in the output layer for gaze estimation [
11]. Krafka et al. developed the GazeCapture for gaze prediction, the first large-scale eye tracking dataset captured via crowdsourcing and iTracker, a convolutional neural network, is trained [
12]. Wang et al. [
13] proposed estimating the gaze angle by dividing the screen area into 41 points and random forest regression is used. In [
14], a convolutional neural network model was introduced as a regression problem with finding a gaze angle. This model has low computational requirements, and effective appearance-based gaze estimation was performed on it. Zhang et al. [
15] proposed a gaze estimation method in which a CNN utilizes the full face image as input with spatial weights on the feature maps. Based on a CNN classification task, the eye image is input to the multi-scale convolutional layer for depth feature extraction. The gaze direction classification is treated as a multi-class classification problem [
16]. The left and right eyes are trained separately by two convolutional neural networks to classify the gaze in seven directions. The scores from both the networks are used to obtain the class labels. Zhang et al. [
11] created the MPIIGaze dataset that contains 213,659 images collected from 15 participants. First, the head rotation angle and eye coordinates of the facial image are obtained through the head pose model and facial feature model. Then, the multimodal CNN is used to learn the mapping from the head poses and eye images to gaze directions in the camera coordinate system. Zhang et al. [
17] did not directly estimate the gaze angle, but introduced a method to divide human gaze into nine directions, and established a convolutional neural network model to estimate directions for a screen typing application.
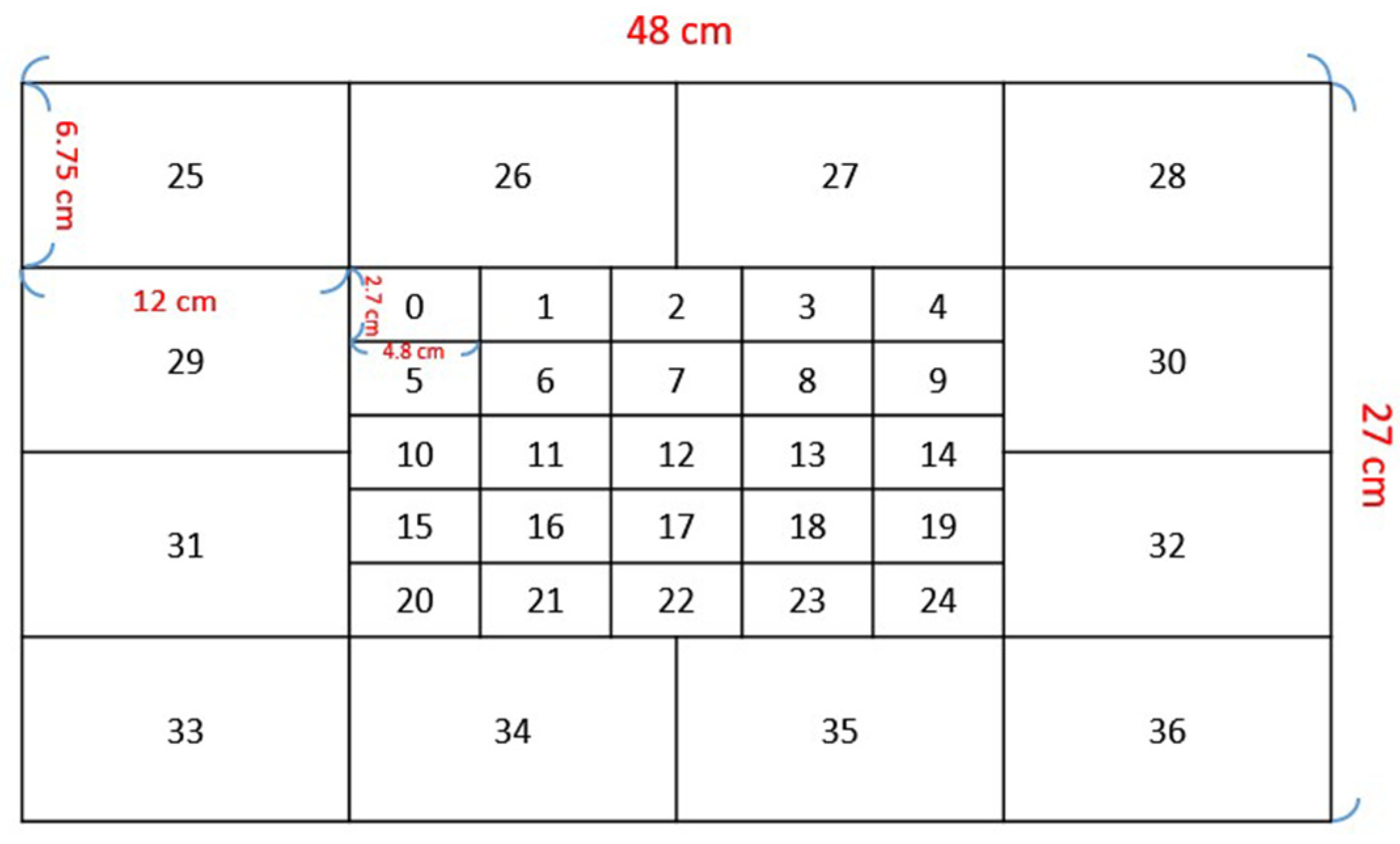
Many studies predicted the coordinates of the gaze point by the regression method. The accuracy of gaze estimation is expressed as the error of gaze direction or coordinate angle (degree). Although both methods are useful, we observed the incorrect predictions and found that the incorrect estimated class is usually near the correct class. Therefore, we infer that when the user views the edges in two adjacent blocks, it may cause the CNN model to make an incorrect estimation. In general, users watch videos or animations and are interested in objects. For establishing a relationship between an area-of-interest and an interesting object, according to our previous work [
18], the ratio of each area-of-interest is the probability of the interest in an object. Thus, when the amount of probability is calculated, one can estimate the amount of attention paid to the object of interest. Even if it is misidentified as a neighboring block, it may still correspond to the same object. Especially when the block area is relatively small, the misjudgment will be higher, and the influence will be reduced by using the classification method. Thus, this paper treats the eye gaze estimation task as a classification problem.
By adding convolution and pooling layers compared to traditional neural networks [
19], the network can maintain the shape of the image information and reduce parameters. The convolution neural network for the research of gaze tracking can bring great results since convolutional neural networks capture subtler features through deep networks and make a robust model. Several papers have clearly helped improve CNN performance [
20,
21,
22,
23]. Ioffe et al. [
20] proposed the method of batch normalization (BN) to overcome the problem of hard to train models with saturating nonlinearities by making normalization a part of the model architecture and performing the normalization for each training mini-batch. The BN can improve the learning speed, reduce the dependence on initial parameters, and eliminate the need for Dropout layer in some cases. GoogleNet [
21] is proposed by Szegedy et al. who increased the depth and width of the network while keeping the computational budget constant, to perform multi-scale processing on images and greatly reduced the amount of model parameters. Simonyan et al. [
22] studied very deep convolutional networks by fixing other parameters and adding more convolutional layers. They used very small (3 × 3) convolution filters in all layers. This is beneficial for the classification accuracy, and good performance on the ImageNet challenge dataset can be achieved. Lin et al. [
23] proposed using the global average pooling (GAP) layer, over feature maps in the classification layer, instead of the fully connected layer. The results have shown that it is easier to interpret and less prone to overfitting.
The objective of most of the above research is concentrated on recognizing large sized images. In the case of gaze tracking, the input image usually is the eye or face, however, few studies focus on small sized image with relatively few features. The images (static stimuli) are used to construct the training dataset [
11,
12]. However, most visual behavior of many people involves watching dynamic stimuli such as movies from YouTube and Netflix. In this paper, we propose a gaze tracking method with feeding different types of images, including the single eye, double eyes and face based on CNN. Additionally, gaze prediction is considered a classification problem by dividing the screen into blocks to label the gaze. In order to obtain the fed images with gaze label for feature learning in a way that is close to the viewer’s visual behavior, the data collection involves participants watching the videos. Performing this way is closer to the actual visual behavior of the viewer rather than letting the participants watch specific screen blocks such as [
13]. The training images then are fed into the convolution neural network for training prediction model, performing several experiments by adjusting network parameters or architecture to explore the performance of the model. The highlights of the paper are shown below:
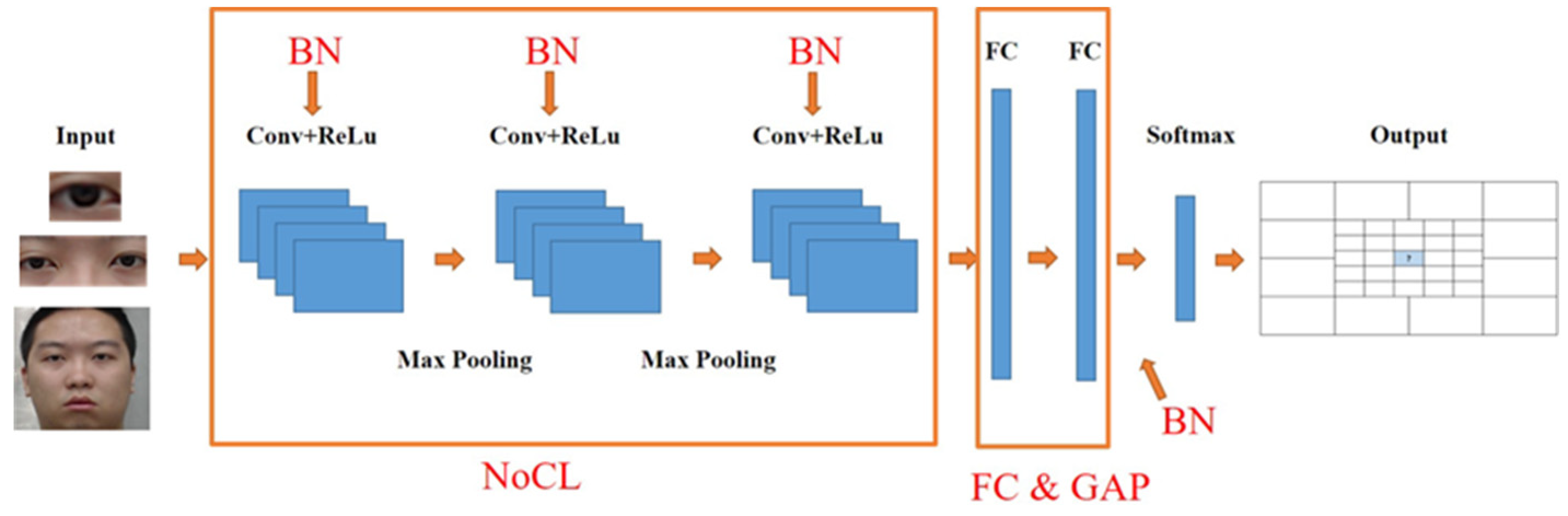
We propose a framework for eye gaze classification to explore the effect by using different convolutional layers, batch normalization and the global average pooling layer.
We propose three schemes, including the single eye image, double eyes image and facial image to evaluate the efficiency and computing complexity.
We propose a novel method to build a training dataset, namely watching videos, because this is closer to the viewer’s visual behavior.
The remainder of this paper is organized as follows.
Section 2 first gives the details of the proposed method, different convolutional layers, batch normalization and the global average pooling layer. The numerical analysis and performance comparison are given in
Section 3. Finally, we will draw conclusions in
Section 4.
4. Conclusions
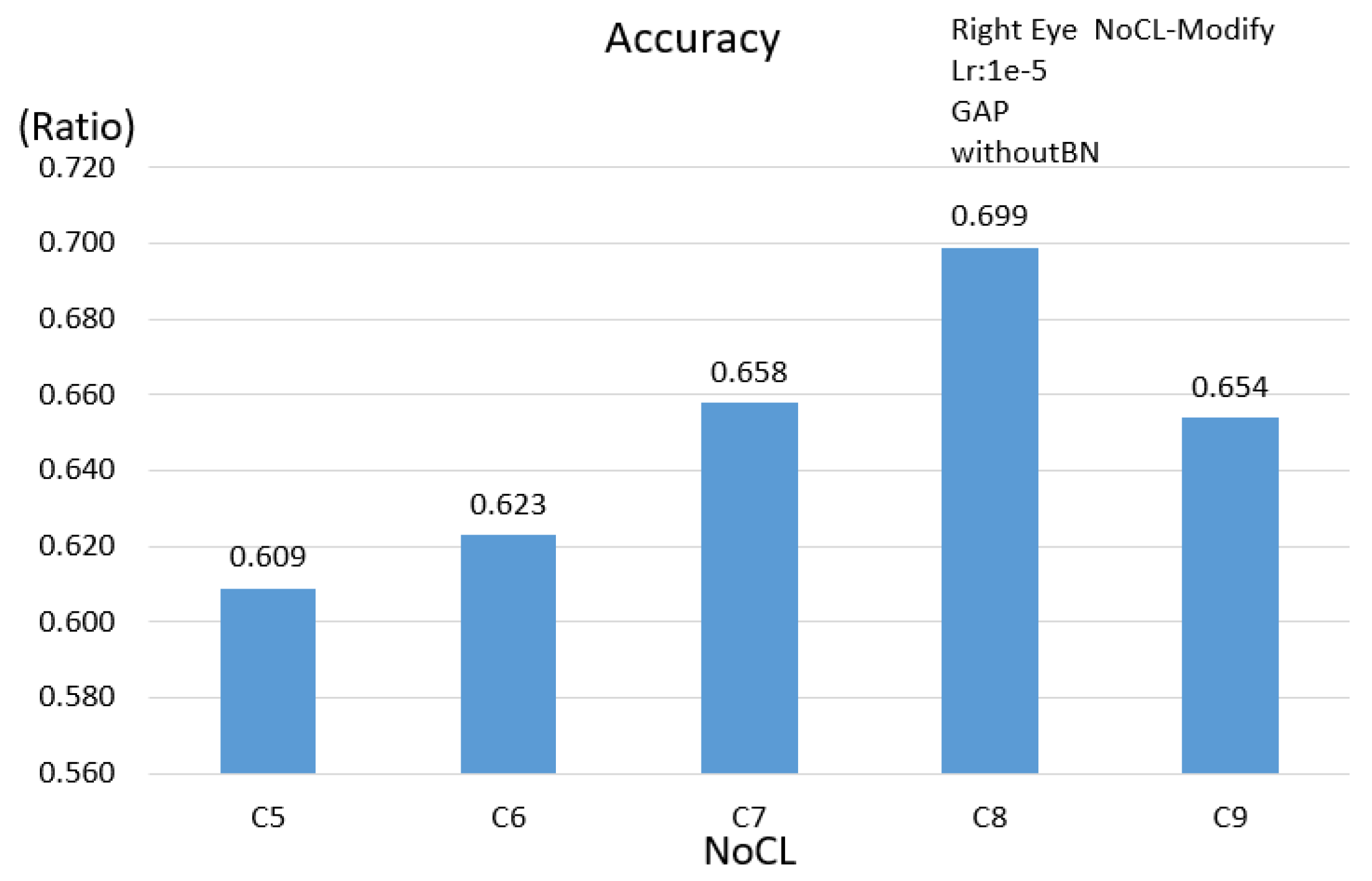
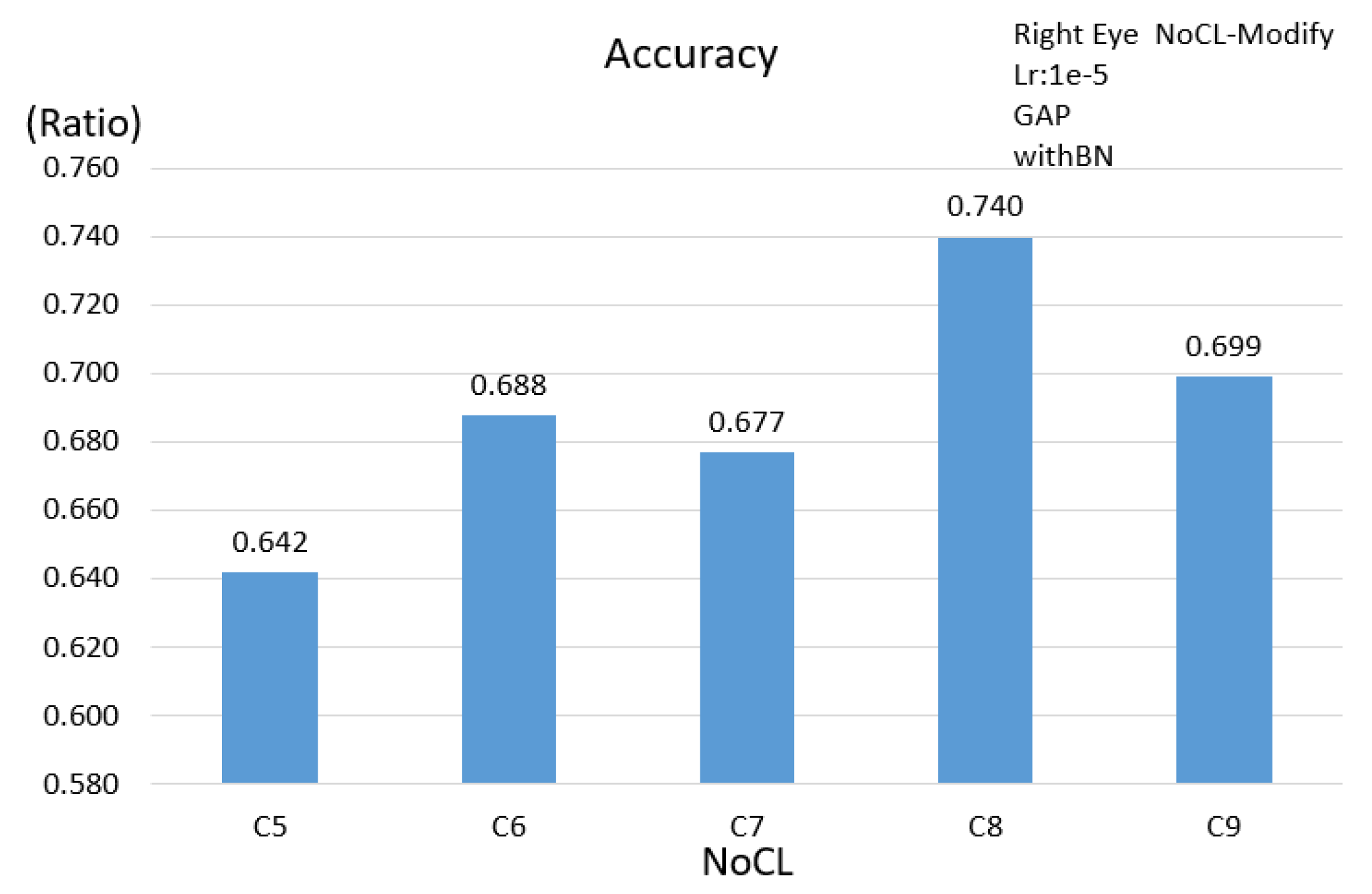
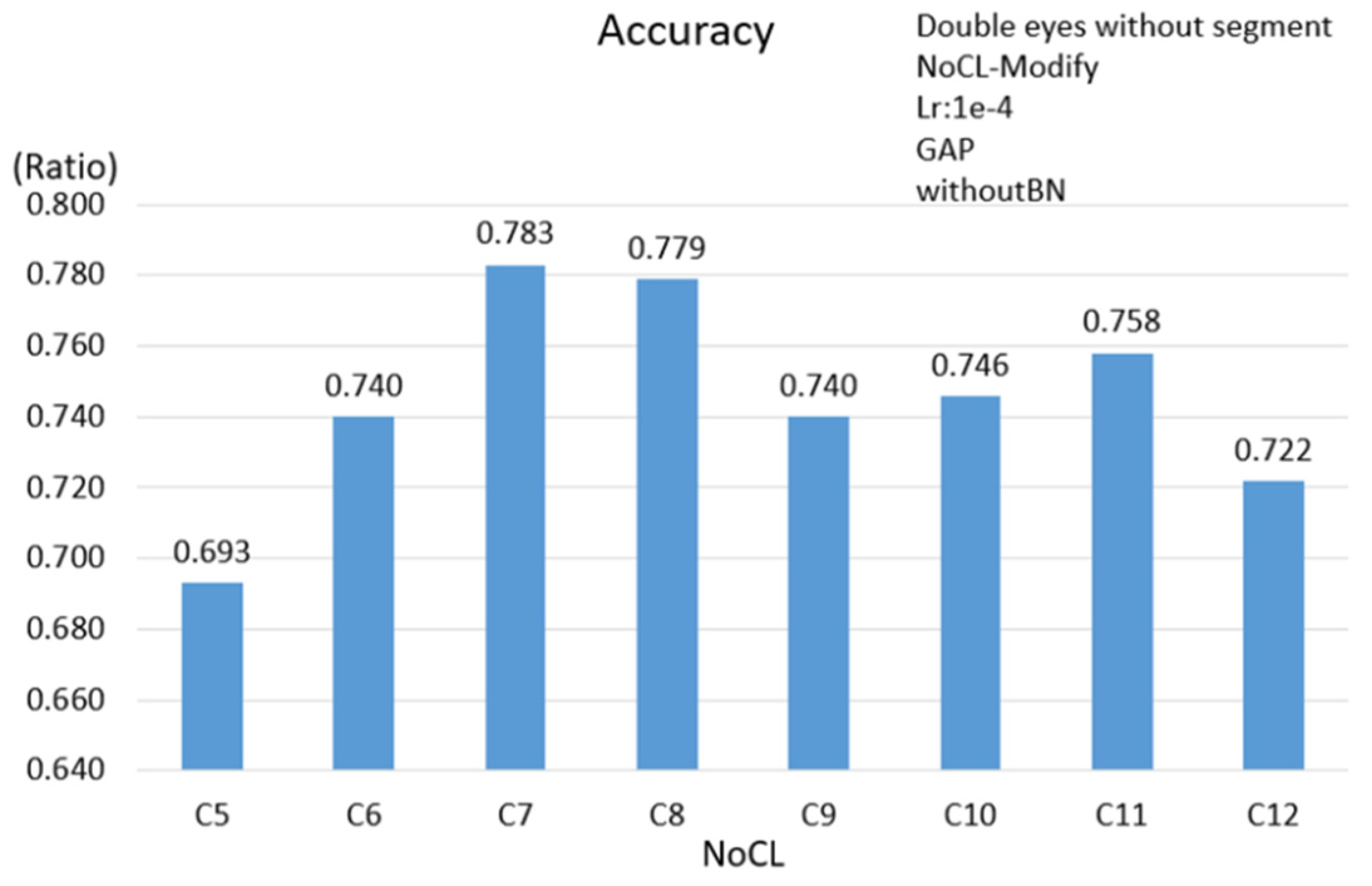
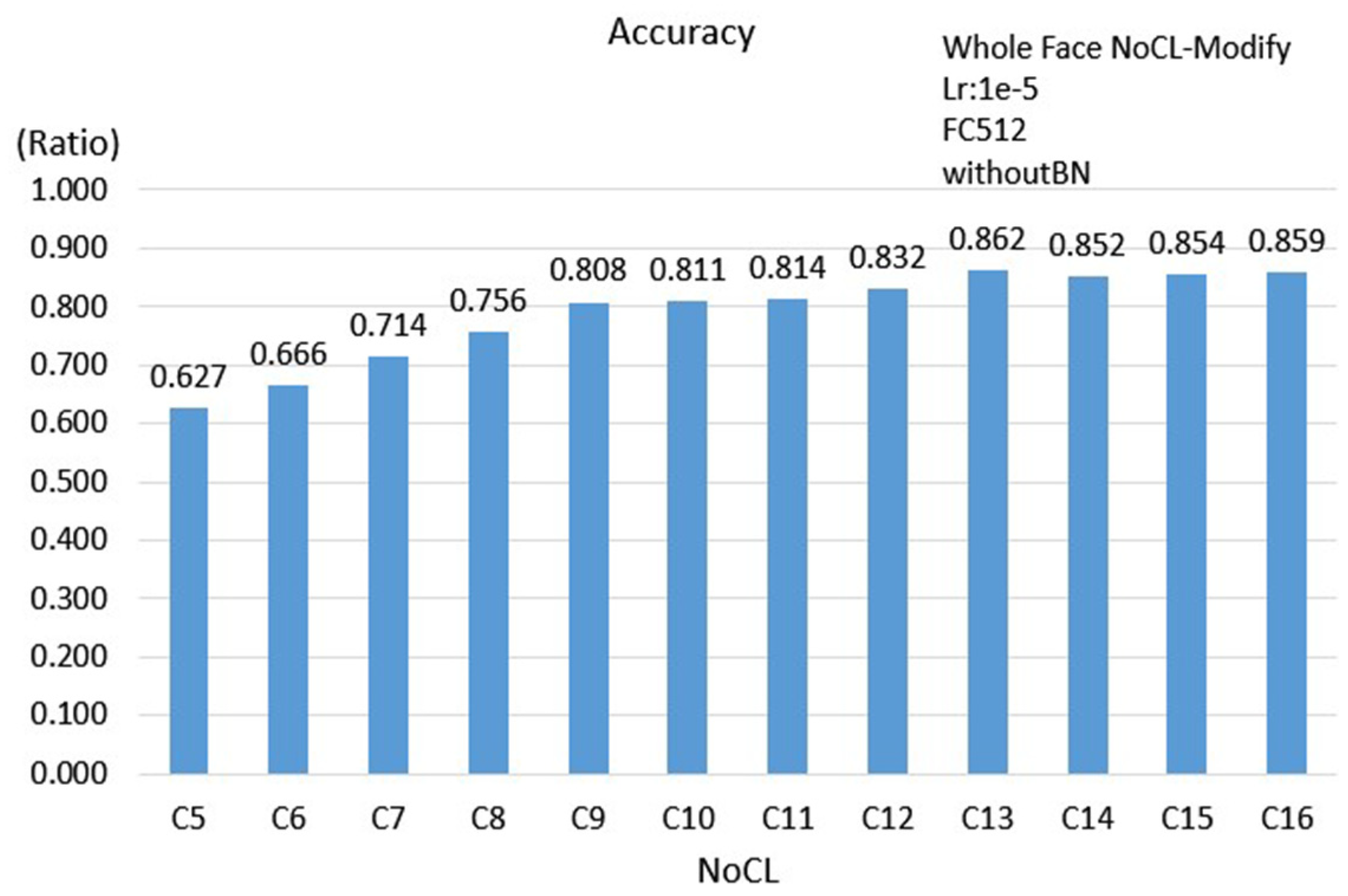
The evaluations for diversity parameters are performed by adjusting the numbers of NoCL and settings of BN as well as the GAP instead of the fully connected layer. A novel method is proposed to build a training dataset as the participant watches videos, because this is closer to the viewer’s visual behavior. The most real and natural data of users can be obtained; the participants can swing their head freely without too many restrictions in the data collecting procedure. We propose three schemes, namely, the single eye image, double eyes image and facial image to evaluate the efficiency and computing complexity under different network architectures. Generally, the input image of an eye tracking system mostly is the eye or face of the small size image with relatively few features. Regarding the efficiency of BN and GAP, this paper completed the evaluation of the 3 schemes. Based on
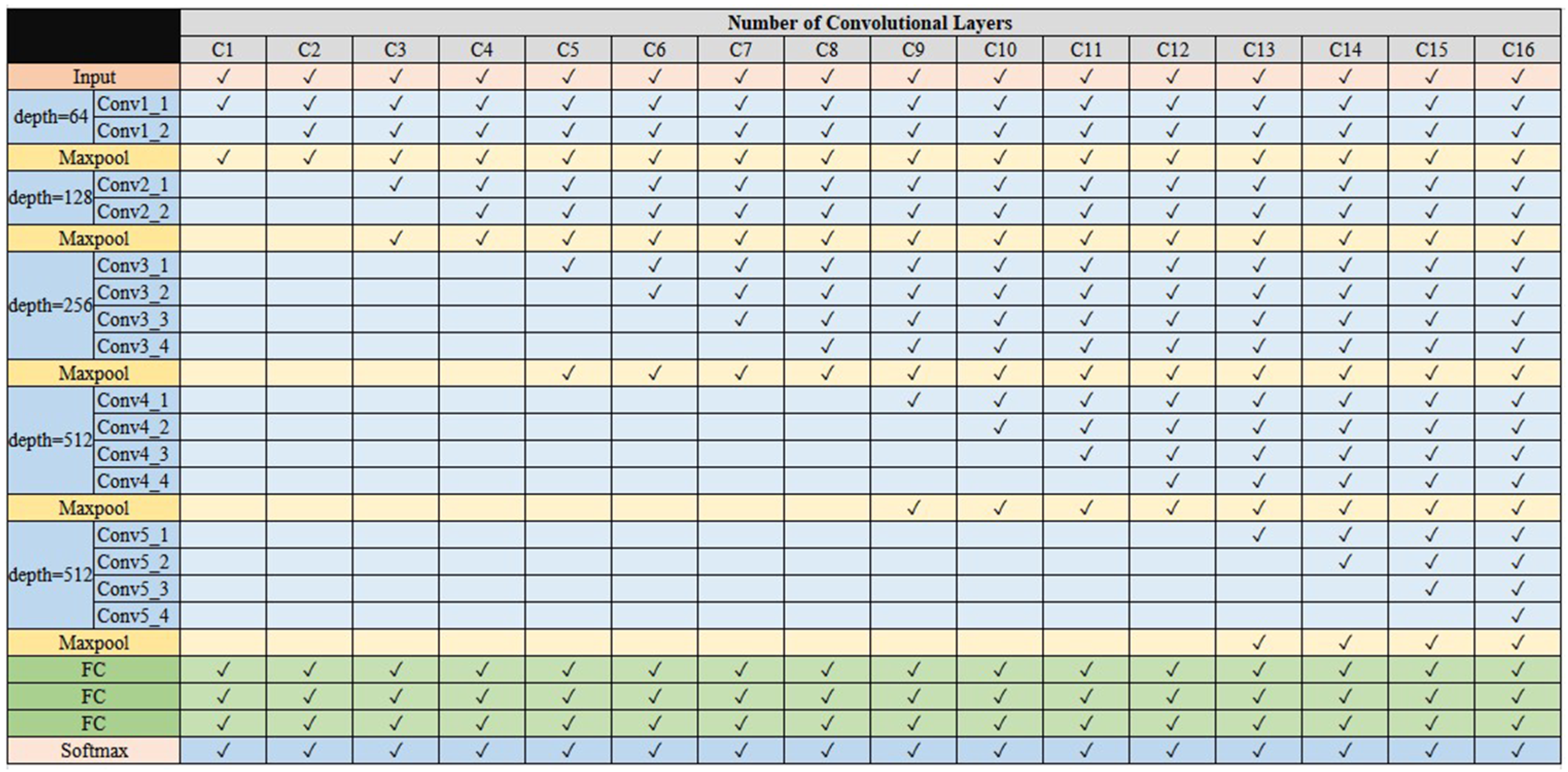
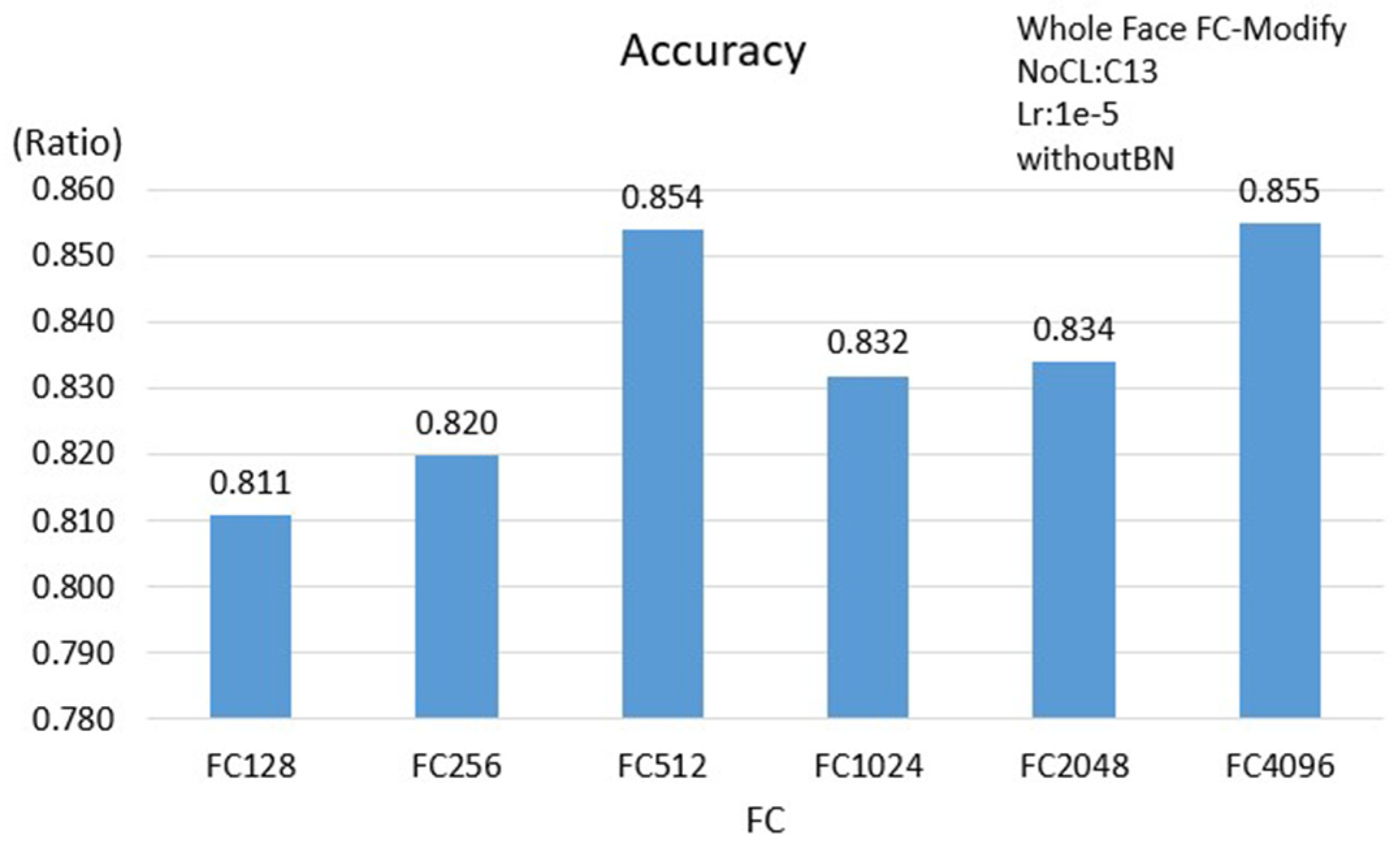
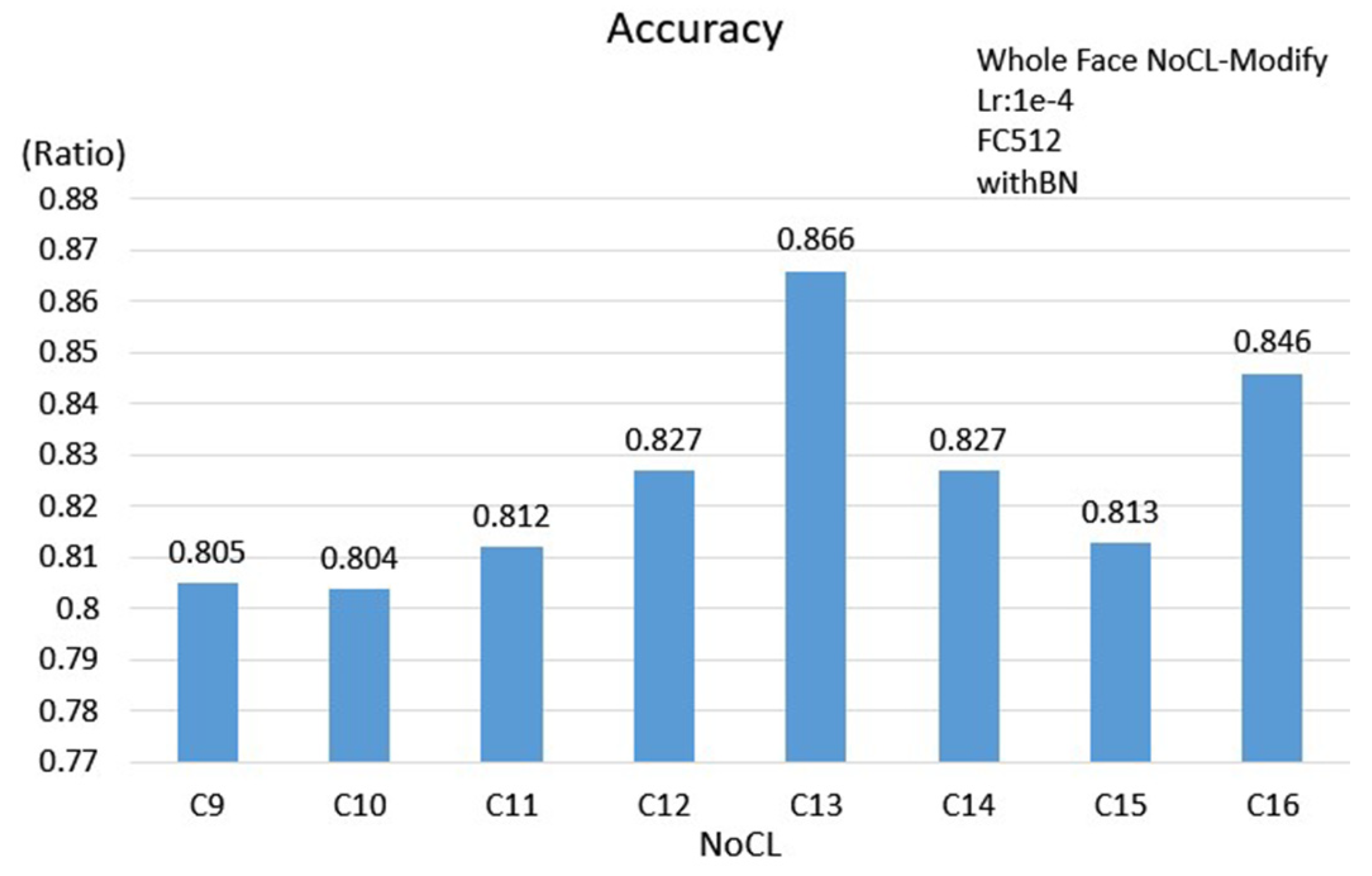
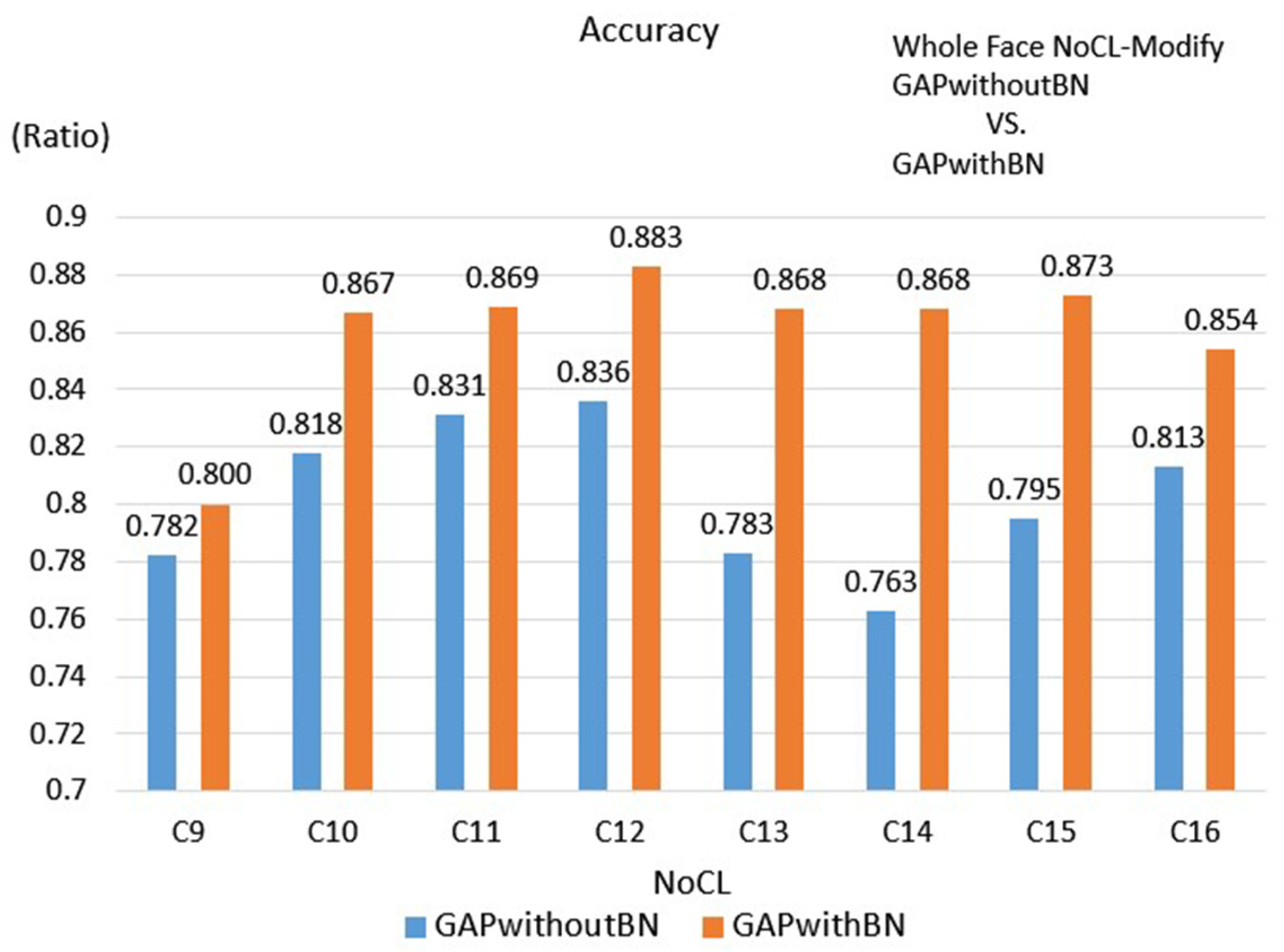
Table 4, the results show that BN and GAP are helpful in overcoming the problem to train models and in reducing the network complexity; however, the accuracy does not necessarily show a significant improvement. It is shown that the accuracy is significantly improved when using GAP and BN at the mean time. Overall, the face scheme has the highest accuracy of 0.883 when BN and GAP are used at the mean time. Additionally, comparing to the FC512 case, the number of parameters is reduced less than 50% and the accuracy is improved by about 2%.
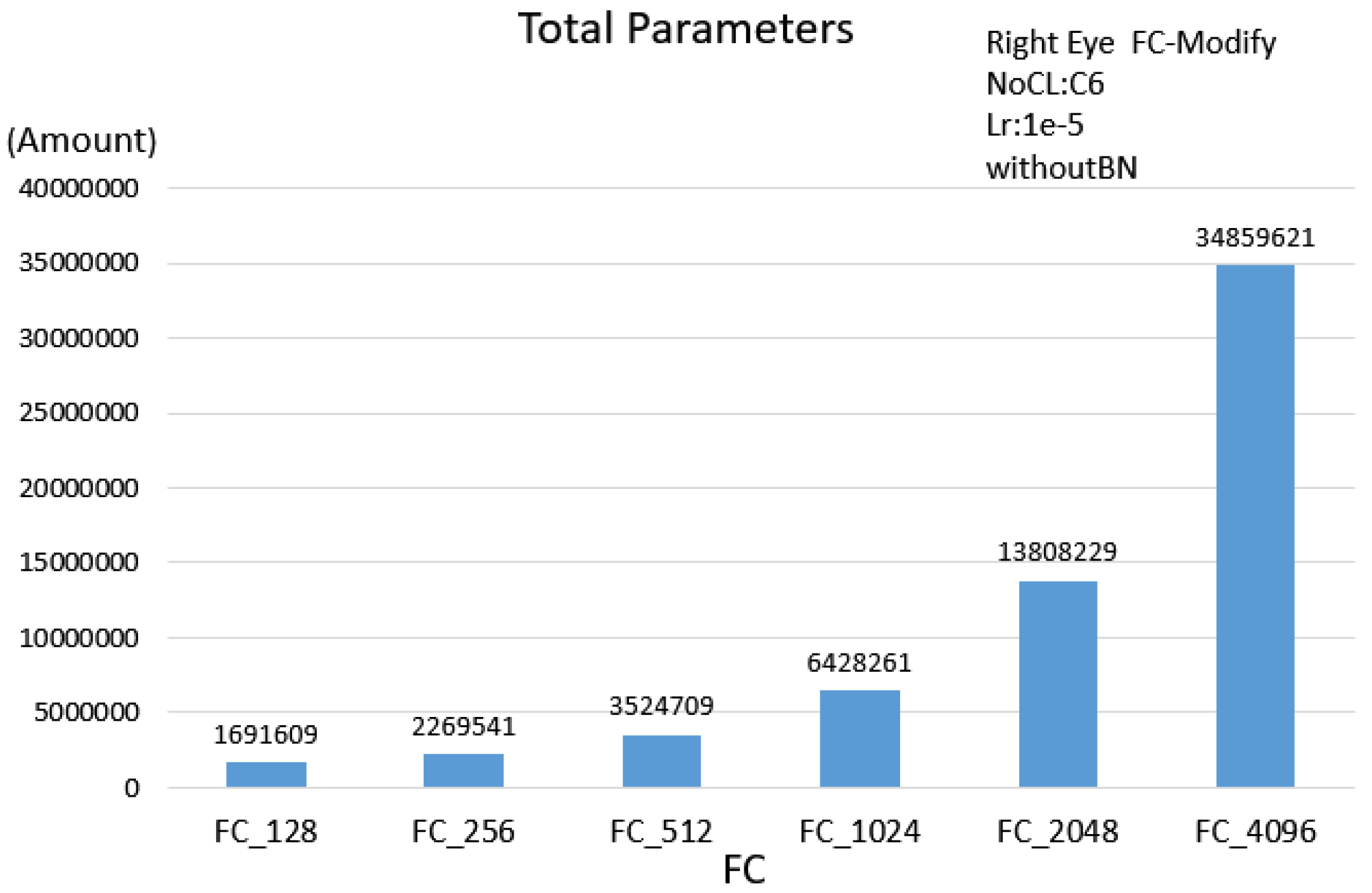
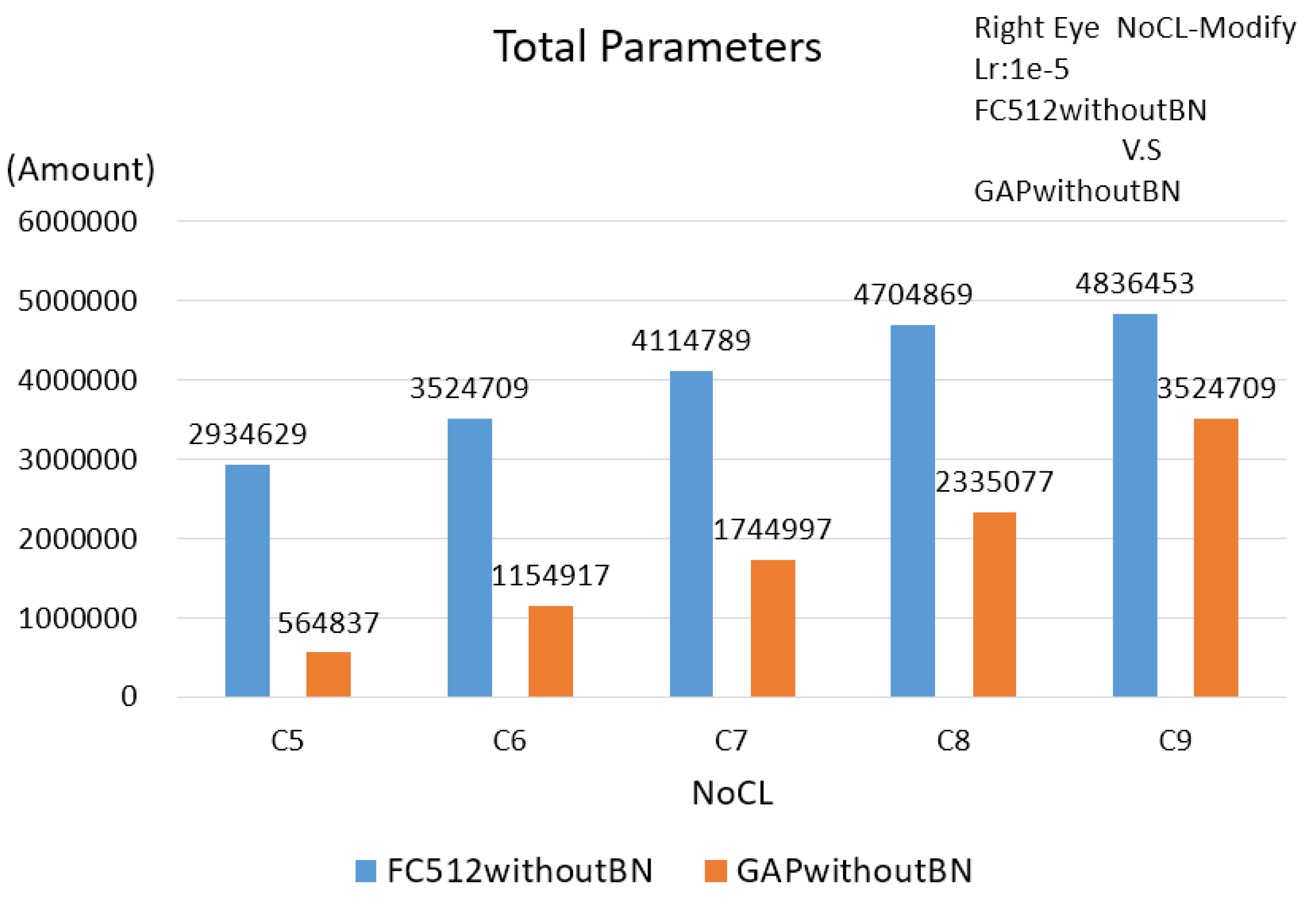
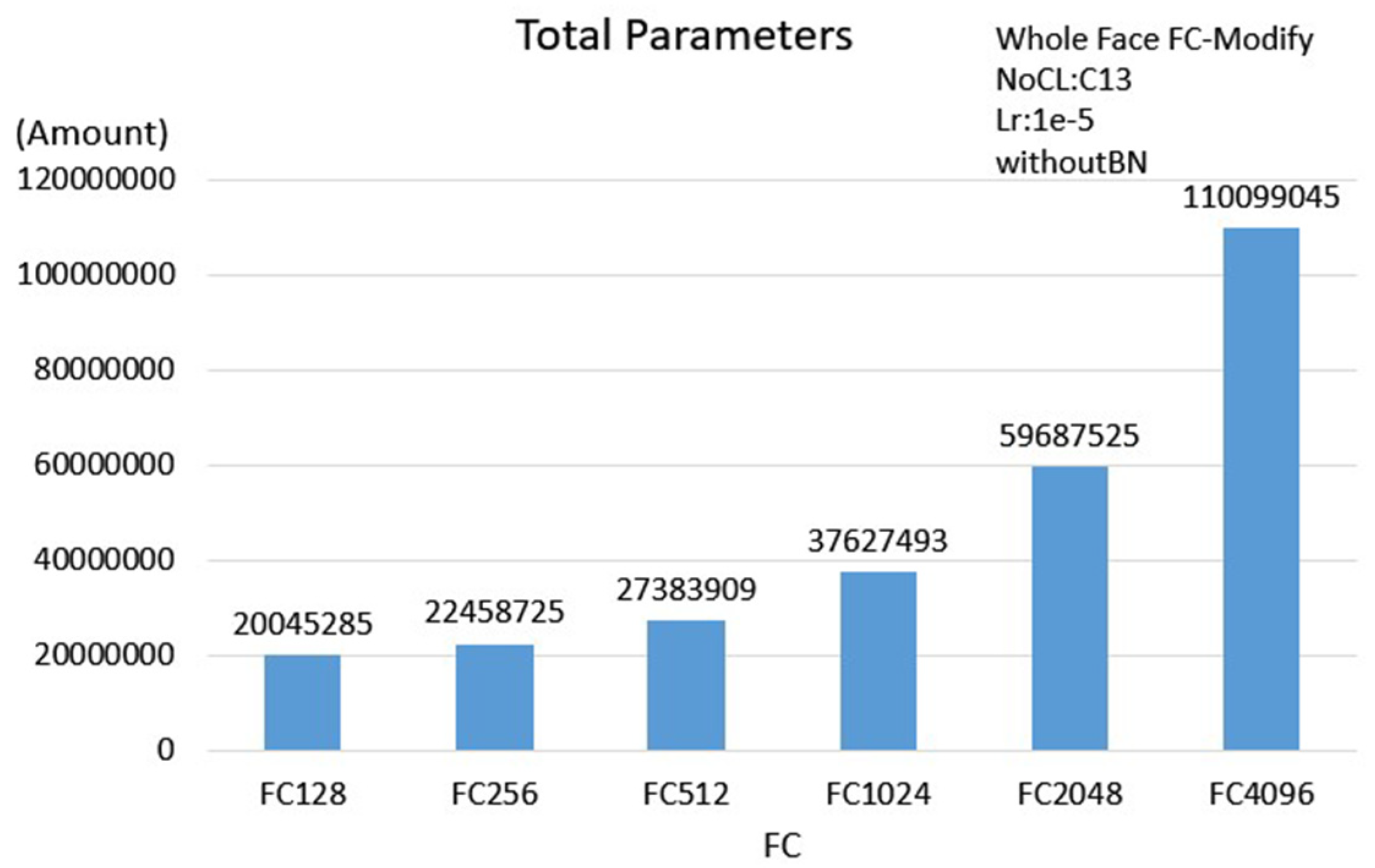
Since the numbers of input features are different and the corresponding NoCL at the best performance is different for the 3 proposed schemes, the number of parameters will be different. Based on
Table 5, presenting the numbers of the parameters of the 3 proposed schemes, the face scheme obtains the maximum number of parameters and the single eye scheme obtains the minimum number of parameters. Meanwhile, using GAP, the parameters were significantly reduced. Therefore, the execution time for applying GAP can be reduced; in our case, there are 4.466 ms, 5.071 ms and 10.776 ms respectively for the single eye scheme, double eyes scheme and face scheme.
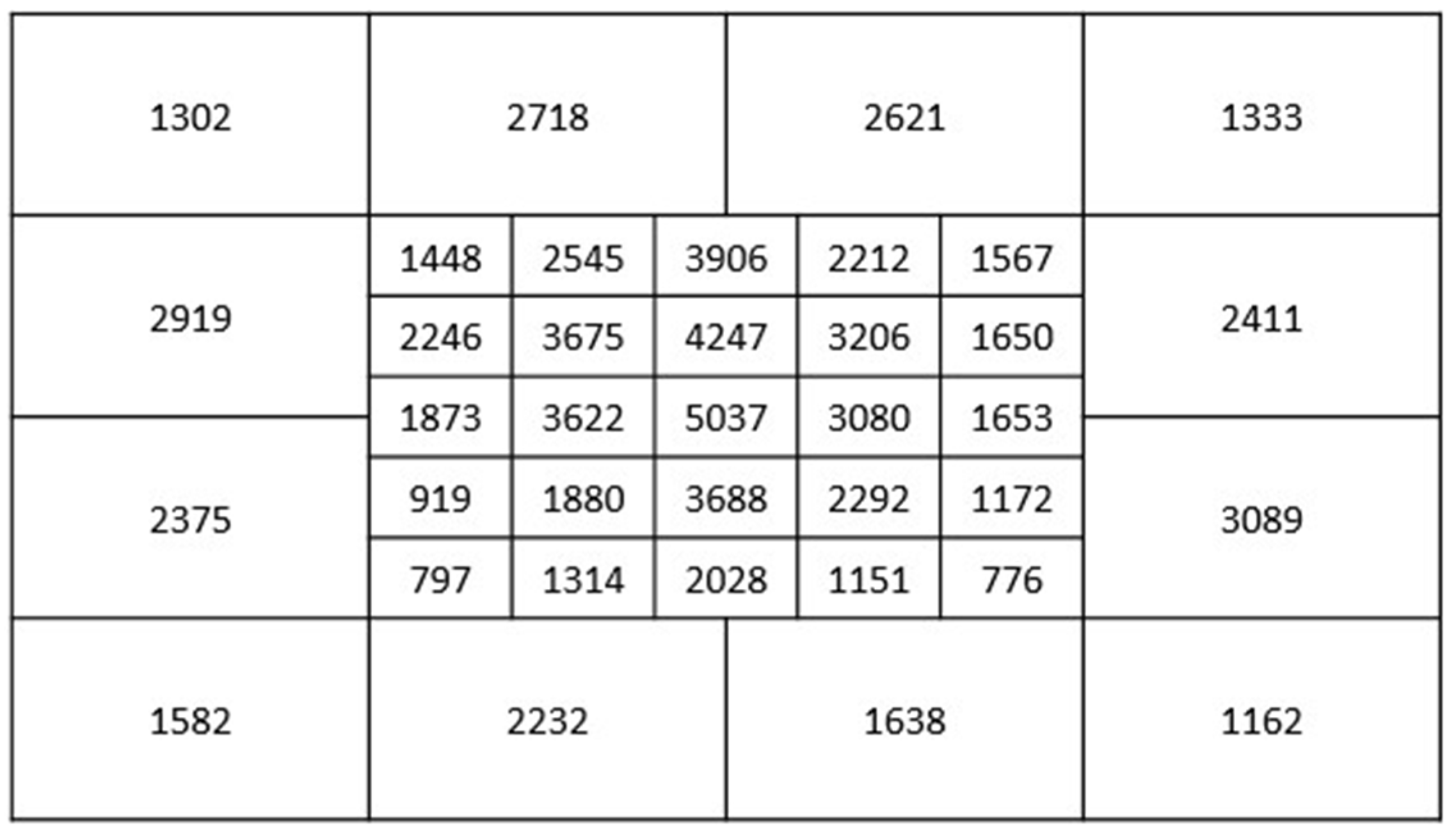
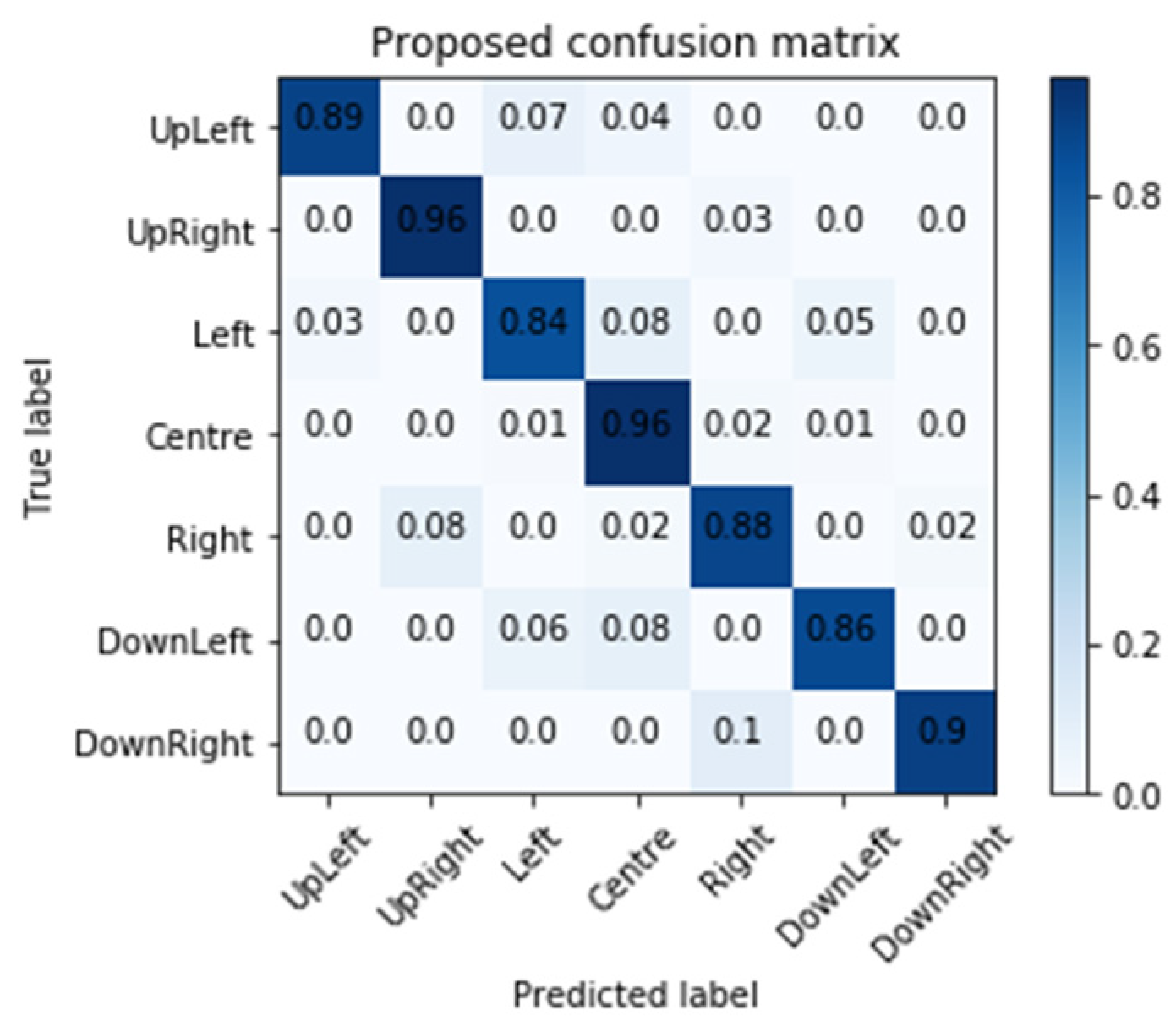
According to
Figure 28, we observed and found that the incorrect estimated class is usually near the correct class. When the gaze estimation is applied to discover the object of interest, based on our previous work [
18], the influence caused by incorrect prediction will be reduced by using the classification method. In the future, we plan to work on adaptively adjusting the block size based on the content and gaze distribution to reduce incorrect prediction.
































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}