Metric Embedding Learning on Multi-Directional Projections


Abstract
:1. Introduction
2. Related Work

3. Methodology
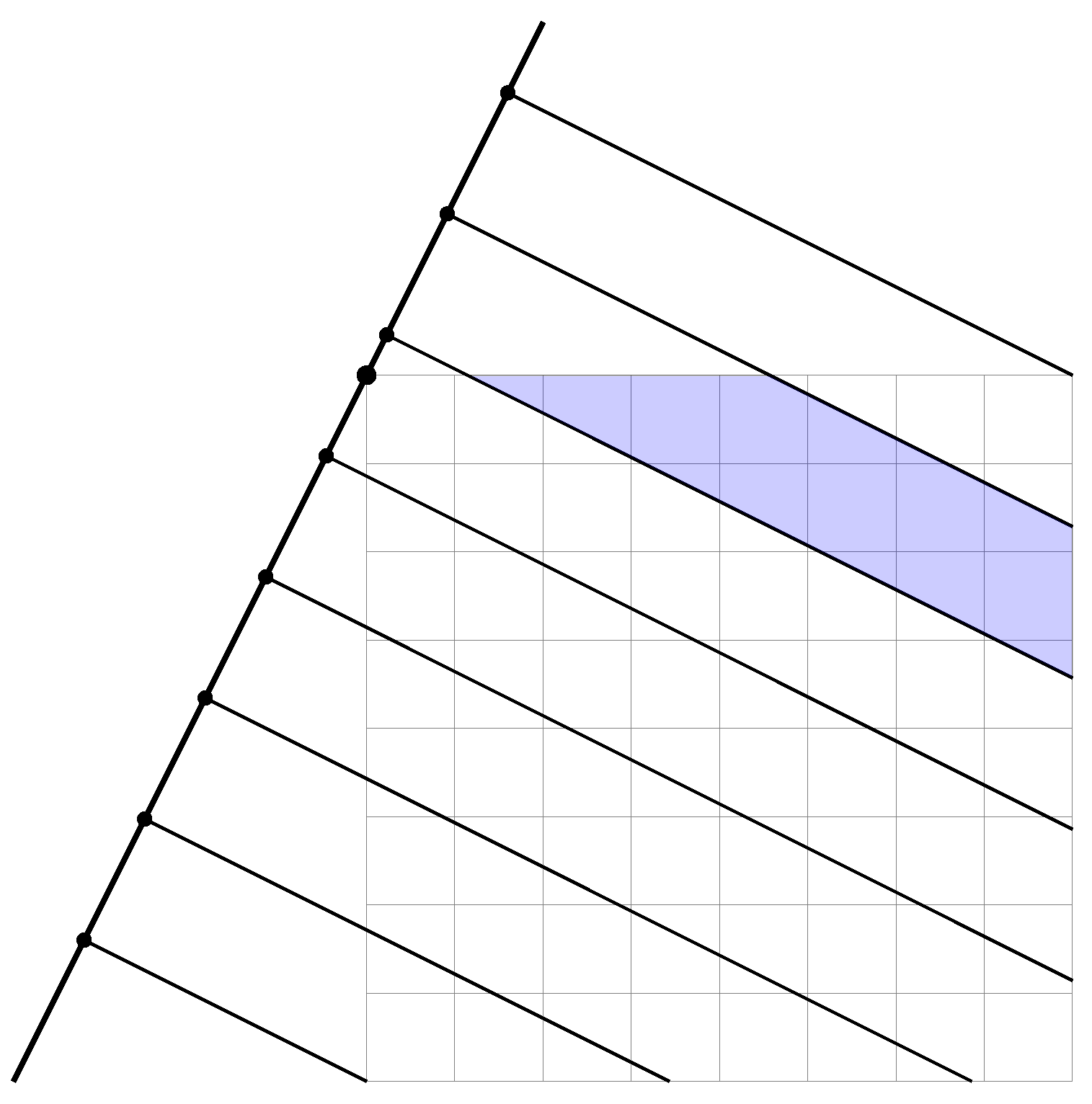
3.1. Multi-Directional Projections
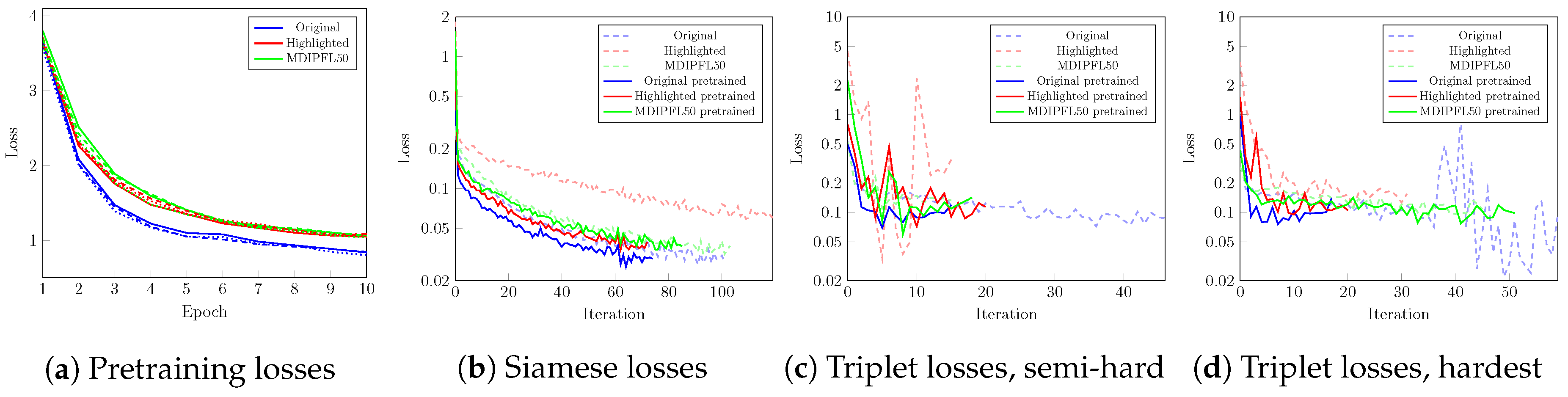
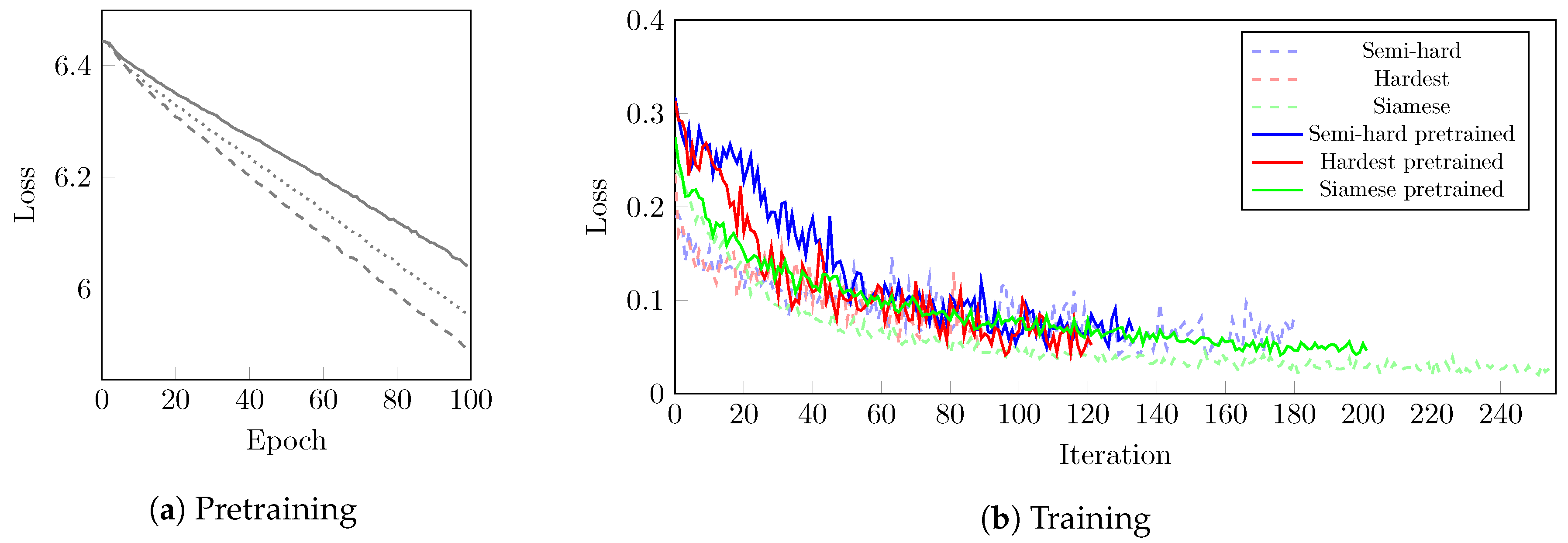
3.2. Pre-Training
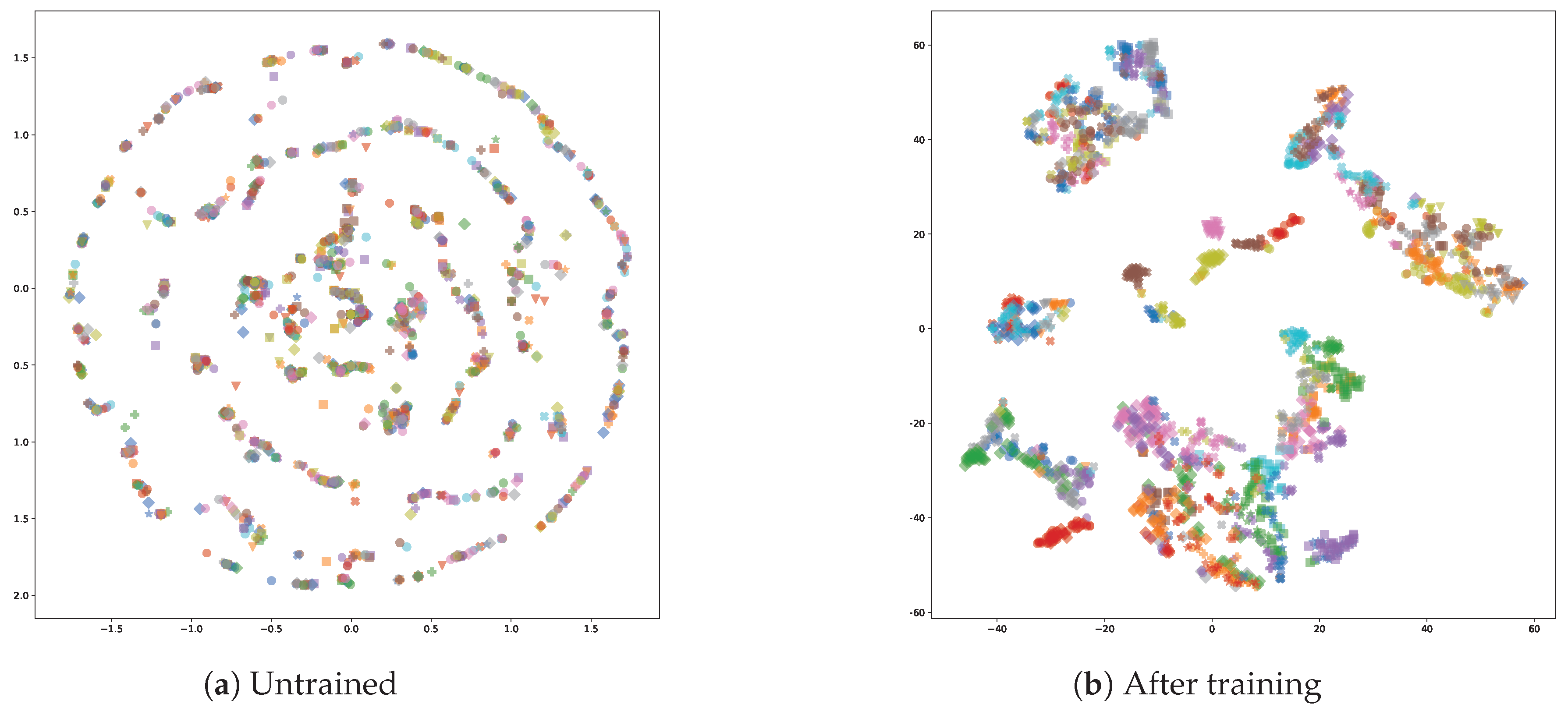
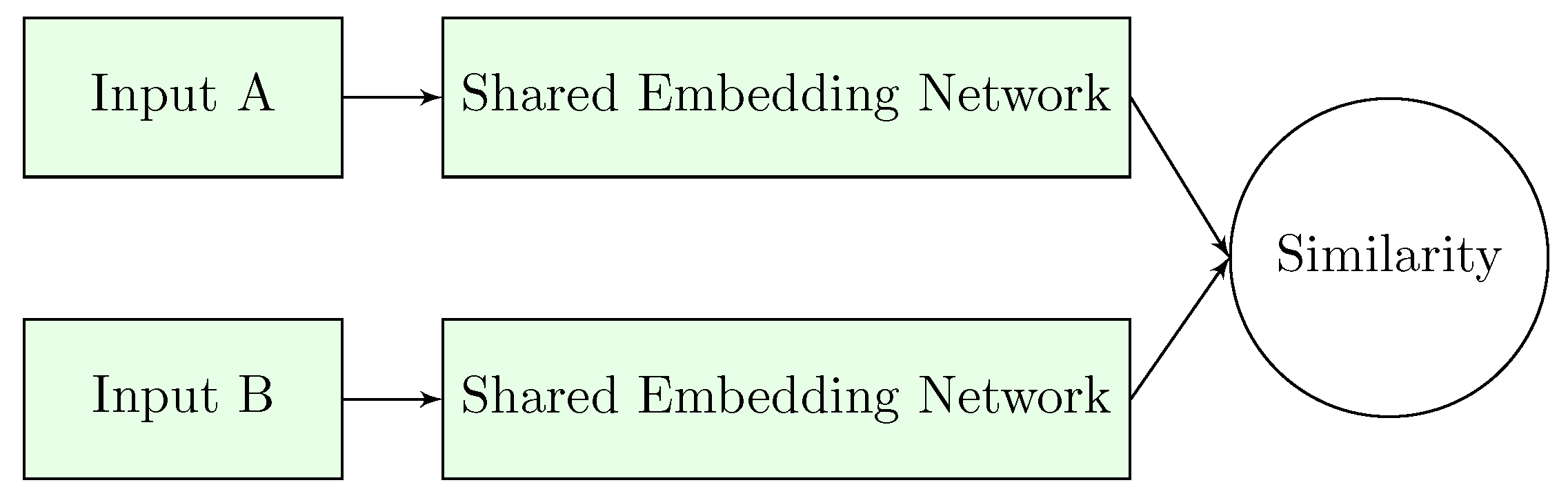
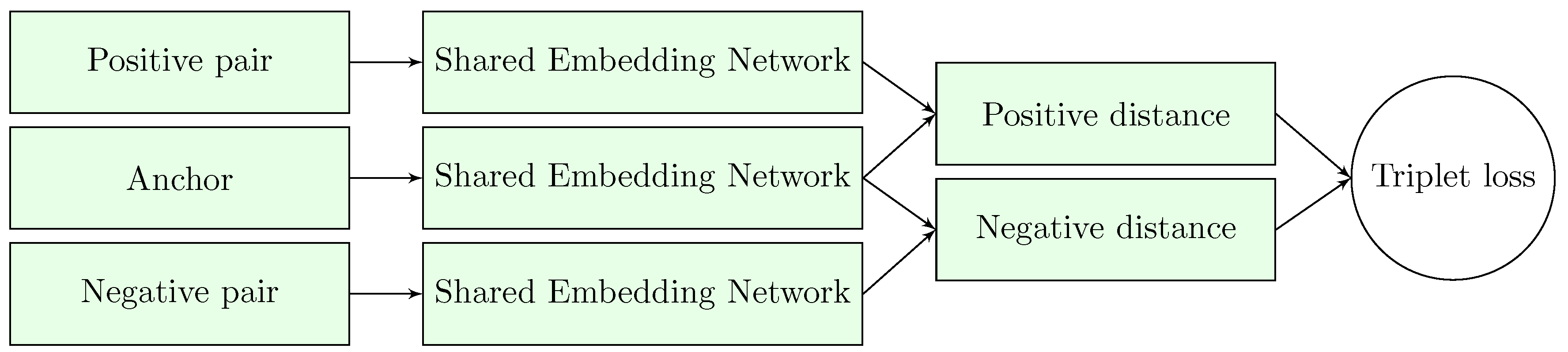
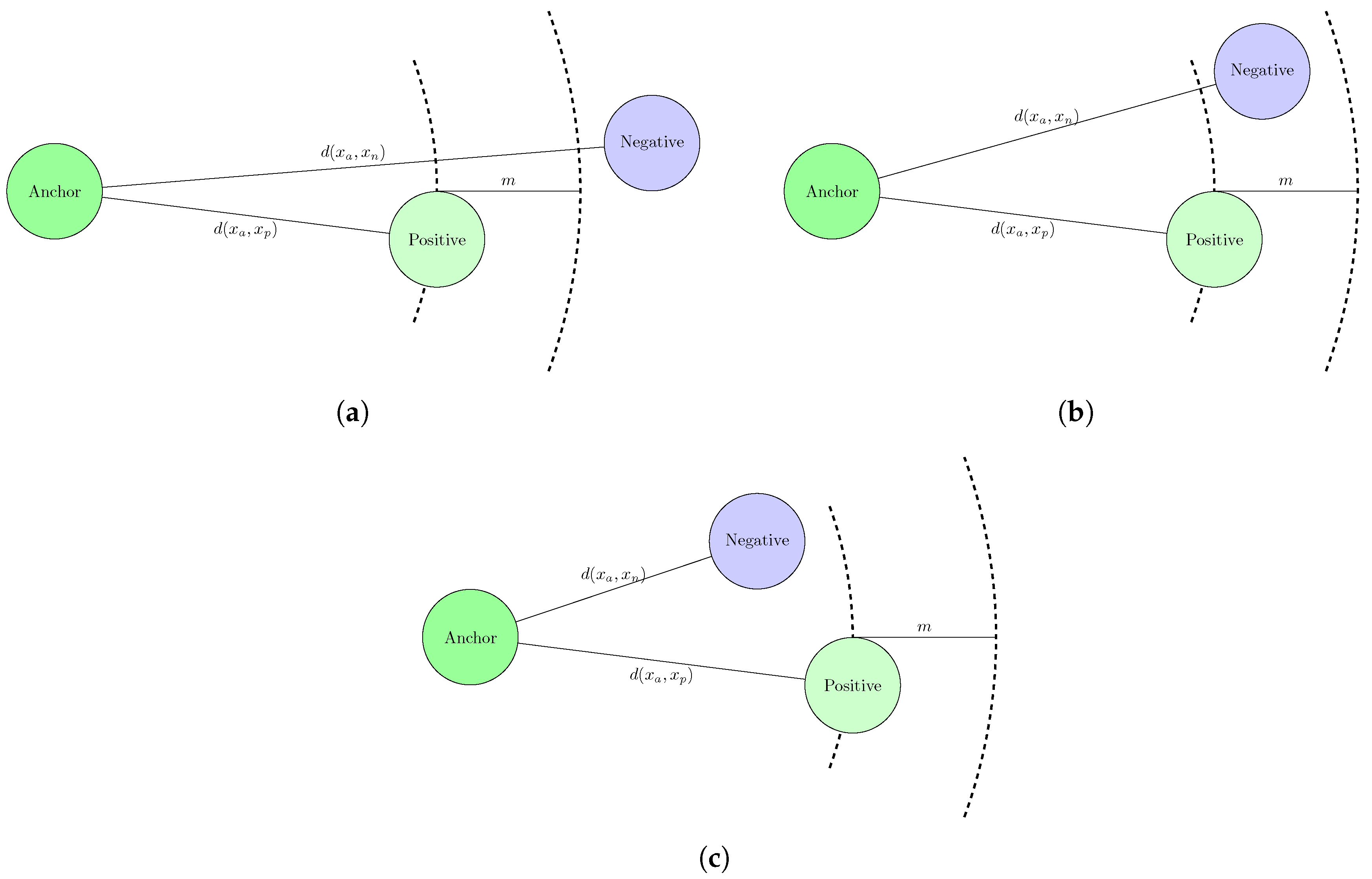
3.3. Embedding Learning
- random mining;
- semi-hard mining;
- hard mining.
3.4. Measuring Performance
- an anchor observation is randomly selected;
- a true pair is selected from the same category;
- false pair samples are selected from other categories;
- distances between the anchor and pairs are measured;
- classification is marked correct, if the distance between the anchor and the true pair is minimal amongst other anchor-based distances;
- steps 1–5 are repeated k-times, while correct classifications are counted;
- N-way one-shot classification accuracy is given as .
4. Results
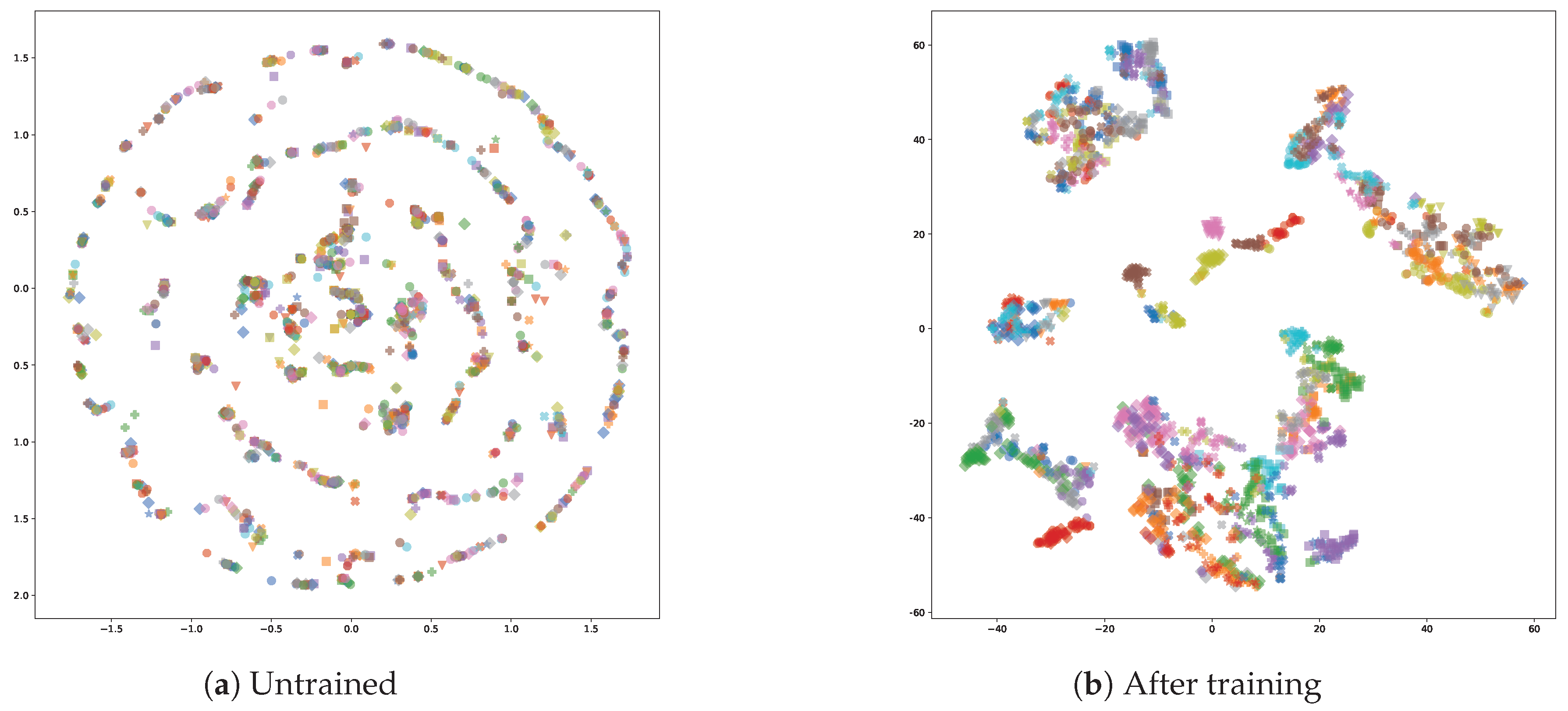
4.1. Discriminative Ability
4.2. Object Re-Identification
5. Discussion
6. Conclusions
Supplementary Materials
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| Adam | Adaptive Moment Estimation |
| CNN | Convolutional Neural Network |
| EMNIST | Extended MNIST |
| GPU | Graphics Processing Unit |
| ILSVRC | ImageNet Large Scale Visual Recognition Challenge |
| k-NN | k-nearest neighbors |
| MNIST | Modified NIST |
| MDIPFL | Multi-Directional Image Projections with Fixed Length |
| NIST | National Institute of Standards and Technology |
| PCA | Principal Component Analysis |
| RAdam | Rectified Adam |
| ResNet | Residual Network |
| SNN | Siamese Neural Network |
| t-SNE | T-distributed Stochastic Neighbor Embedding |
| VGG | Visual Geometry Group |
References
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Bromley, J.; Guyon, I.; LeCun, Y.; Säckinger, E.; Shah, R. Signature verification using a “siamese” time delay neural network. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 28 November–1 December 1994; pp. 737–744. [Google Scholar]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. In Proceedings of the ICML Deep Learning Workshop, Lille, France, 10–11 July 2015; Volume 2. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Li, Y.; Huang, H.; Xie, Q.; Yao, L.; Chen, Q. Research on a surface defect detection algorithm based on MobileNet-SSD. Appl. Sci. 2018, 8, 1678. [Google Scholar] [CrossRef] [Green Version]
- Ribeiro, M.; Grolinger, K.; Capretz, M.A. Mlaas: Machine learning as a service. In Proceedings of the 2015 IEEE 14th International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 9–11 December 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 896–902. [Google Scholar]
- Li, H.; Ota, K.; Dong, M. Learning IoT in edge: Deep learning for the Internet of Things with edge computing. IEEE Netw. 2018, 32, 96–101. [Google Scholar]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Gaidhane, V.; Singh, V.; Kumar, M. Image compression using PCA and improved technique with MLP neural network. In Proceedings of the 2010 International Conference on Advances in Recent Technologies in Communication and Computing, Bradford, UK, 29 June–1 July 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 106–110. [Google Scholar]
- Dev, S.; Wen, B.; Lee, Y.H.; Winkler, S. Machine learning techniques and applications for ground-based image analysis. arXiv 2016, arXiv:1606.02811. [Google Scholar] [CrossRef]
- Kramer, M.A. Nonlinear principal component analysis using autoassociative neural networks. AIChE J. 1991, 37, 233–243. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar]
- Cui, W.; Zhou, Q.; Zheng, Z. Application of a hybrid model based on a convolutional auto-encoder and convolutional neural network in object-oriented remote sensing classification. Algorithms 2018, 11, 9. [Google Scholar] [CrossRef] [Green Version]
- Deng, C.; Lin, W.; Lee, B.s.; Lau, C.T. Robust image compression based on compressive sensing. In Proceedings of the 2010 IEEE International Conference on Multimedia and Expo, Singapore, 19–23 July 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 462–467. [Google Scholar]
- Kertész, G.; Szénási, S.; Vamossy, Z. A novel method for robust multi-directional image projection computation. In Proceedings of the 2016 IEEE 20th Jubilee International Conference on Intelligent Engineering Systems (INES), Budapest, Hungary, 30 June–2 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 239–244. [Google Scholar]
- Ammah, P.N.T.; Owusu, E. Robust medical image compression based on wavelet transform and vector quantization. Inform. Med. Unlocked 2019, 15, 100183. [Google Scholar]
- Kertész, G.; Szénási, S.; Vámossy, Z. Multi-Directional Image Projections with Fixed Resolution for Object Matching. Acta Polytech. Hung. 2018, 15, 211–229. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NA, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Bengio, Y. Practical recommendations for gradient-based training of deep architectures. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 437–478. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional siamese networks for object tracking. In Computer Vision—ECCV 2016 Workshops; Hua, G., Jégou, H., Eds.; Springer: Cham, Switzerland, 2016; pp. 850–865. [Google Scholar]
- Varior, R.R.; Haloi, M.; Wang, G. Gated siamese convolutional neural network architecture for human re-identification. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; Volume 9912, pp. 791–808. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. Deepface: Closing the gap to human-level performance in face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Hadsell, R.; Chopra, S.; LeCun, Y. Dimensionality reduction by learning an invariant mapping. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 1735–1742. [Google Scholar]
- Wang, J.; Song, Y.; Leung, T.; Rosenberg, C.; Wang, J.; Philbin, J.; Chen, B.; Wu, Y. Learning fine-grained image similarity with deep ranking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1386–1393. [Google Scholar]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training region-based object detectors with online hard example mining. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 761–769. [Google Scholar]
- Wu, C.Y.; Manmatha, R.; Smola, A.J.; Krahenbuhl, P. Sampling matters in deep embedding learning. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2840–2848. [Google Scholar]
- Zhu, X.; Jing, X.Y.; You, X.; Zuo, W.; Shan, S.; Zheng, W.S. Image to video person re-identification by learning heterogeneous dictionary pair with feature projection matrix. IEEE Trans. Inf. Forensics Secur. 2017, 13, 717–732. [Google Scholar] [CrossRef]
- Amos, B.; Ludwiczuk, B.; Satyanarayanan, M. Openface: A general-purpose face recognition library with mobile applications. CMU Sch. Comput. Sci. 2016, 6, 2. [Google Scholar]
- Hermans, A.; Beyer, L.; Leibe, B. In defense of the triplet loss for person re-identification. arXiv 2017, arXiv:1703.07737. [Google Scholar]
- Xuan, H.; Stylianou, A.; Pless, R. Improved embeddings with easy positive triplet mining. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 2474–2482. [Google Scholar]
- Radon, J. Uber die Bestimmung von Funktionen durch ihre Integralwerte längs gewissez Mannigfaltigheiten. Available online: https://www.bibsonomy.org/bibtex/1fdcf4d741dfedba3c56a3a942ecc463b/haggis79 (accessed on 14 May 2020).
- Radon, J. On the determination of functions from their integral values along certain manifolds. IEEE Trans. Med Imaging 1986, 5, 170–176. [Google Scholar] [CrossRef]
- Hough, P.V. Method and Means for Recognizing Complex Patterns. US Patent 3,069,654, 18 December 1962. [Google Scholar]
- Duda, R.O.; Hart, P.E. Use of the Hough transformation to detect lines and curves in pictures. Commun. ACM 1972, 15, 11–15. [Google Scholar]
- Ramlau, R.; Scherzer, O. The Radon Transform: The First 100 Years and Beyond; Walter de Gruyter GmbH & Co KG: Berlin, Germany, 2019; Volume 22. [Google Scholar]
- Deans, S. The Radon Transform and Some of Its Applications; John Wiley and Sons: New York, NY, USA, 1983. [Google Scholar]
- Betke, M.; Haritaoglu, E.; Davis, L.S. Real-time multiple vehicle detection and tracking from a moving vehicle. Mach. Vis. Appl. 2000, 12, 69–83. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Collins, R.; Tsin, Y. Gait sequence analysis using frieze patterns. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2002; Springer: Berlin/Heidelberg, Germany, 2002; pp. 657–671. [Google Scholar]
- Jelača, V.; Pižurica, A.; Niño-Castañeda, J.O.; Frías-Velázquez, A.; Philips, W. Vehicle matching in smart camera networks using image projection profiles at multiple instances. Image Vis. Comput. 2013, 31, 673–685. [Google Scholar] [CrossRef]
- Rinner, B.; Wolf, W. An introduction to distributed smart cameras. Proc. IEEE 2008, 96, 1565–1575. [Google Scholar] [CrossRef]
- Kawamura, A.; Yoshimitsu, Y.; Kajitani, K.; Naito, T.; Fujimura, K.; Kamijo, S. Smart camera network system for use in railway stations. In Proceedings of the 2011 IEEE International Conference on Systems, Man, and Cybernetics, Anchorage, AK, USA, 9–12 October 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 85–90. [Google Scholar]
- Alessandrelli, D.; Azzarà, A.; Petracca, M.; Nastasi, C.; Pagano, P. ScanTraffic: Smart camera network for traffic information collection. In Proceedings of the European Conference on Wireless Sensor Networks, Trento, Italy, 13–15 February 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 196–211. [Google Scholar]
- Grother, P.; Hanaoka, K. NIST Special Database 19 Handprinted Forms and Characters, 2nd ed.; Tech. Report; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2016. [Google Scholar]
- Kertész, G.; Szénási, S.; Vámossy, Z. Application and properties of the Radon transform for object image matching. In Proceedings of the SAMI 2017, Herl’any, Slovakia, 26–28 January 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 353–358. [Google Scholar]
- Szénási, S.; Felde, I. Using multiple graphics accelerators to solve the two-dimensional inverse heat conduction problem. Comput. Methods Appl. Mech. Eng. 2018, 336, 286–303. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, X.; Lan, X. How to train triplet networks with 100k identities? In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 1907–1915. [Google Scholar]
- Li, C.; Ma, X.; Jiang, B.; Li, X.; Zhang, X.; Liu, X.; Cao, Y.; Kannan, A.; Zhu, Z. Deep speaker: An end-to-end neural speaker embedding system. arXiv 2017, arXiv:1705.02304. [Google Scholar]
- Yagfarov, R.; Ostankovich, V.; Akhmetzyanov, A. Traffic Sign Classification Using Embedding Learning Approach for Self-driving Cars. Human Interaction, Emerging Technologies and Future Applications II. In Proceedings of the 2nd International Conference on Human Interaction and Emerging Technologies: Future Applications (IHIET–AI 2020), Lausanne, Switzerland, 23–25 April 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 180–184. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Altman, N.S. An introduction to kernel and nearest-neighbor nonparametric regression. Am. Stat. 1992, 46, 175–185. [Google Scholar]
- Lake, B.M.; Salakhutdinov, R.R.; Tenenbaum, J. One-shot learning by inverting a compositional causal process. In Advances in Neural Information Processing Systems 26; Burges, C.J.C., Bottou, L., Welling, M., Ghahramani, Z., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2013; pp. 2526–2534. [Google Scholar]
- LeCun, Y.; Cortes, C.; Burges, C.J. The MNIST database of handwritten digits, 1998. J. Intel. Learn. Syst. Appl. 1998, 10, 34. [Google Scholar]
- Cohen, G.; Afshar, S.; Tapson, J.; Van Schaik, A. EMNIST: Extending MNIST to handwritten letters. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2921–2926. [Google Scholar]
- Liu, L.; Jiang, H.; He, P.; Chen, W.; Liu, X.; Gao, J.; Han, J. On the variance of the adaptive learning rate and beyond. arXiv 2019, arXiv:1908.03265. [Google Scholar]
- Chollet, F. Keras: The Python Deep Learning Library; Astrophysics Source Code Library: College Park, MD, USA, 2018. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation, Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Chopra, S.; Hadsell, R.; LeCun, Y. Learning a similarity metric discriminatively, with application to face verification. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 1, pp. 539–546. [Google Scholar]
- Almazan, J.; Gajic, B.; Murray, N.; Larlus, D. Re-id done right: Towards good practices for person re-identification. arXiv 2018, arXiv:1801.05339. [Google Scholar]
- Kuma, R.; Weill, E.; Aghdasi, F.; Sriram, P. Vehicle re-identification: An efficient baseline using triplet embedding. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–9. [Google Scholar]
- Zapletal, D.; Herout, A. Vehicle Re-Identification for Automatic Video Traffic Surveillance. In Proceedings of the the IEEE Conference on Computer Vision and Pattern Recognition Workshops 2016, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1–7. [Google Scholar]
- Maaten, L.v.d.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8697–8710. [Google Scholar]
- Real, E.; Aggarwal, A.; Huang, Y.; Le, Q.V. Regularized evolution for image classifier architecture search. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 4780–4789. [Google Scholar]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q.V. Mnasnet: Platform-aware neural architecture search for mobile. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 2820–2828. [Google Scholar]
- Mateen, M.; Wen, J.; Song, S.; Huang, Z. Fundus image classification using VGG-19 architecture with PCA and SVD. Symmetry 2019, 11, 1. [Google Scholar] [CrossRef] [Green Version]
- Lin, Y.; Zhu, X.; Zheng, Z.; Dou, Z.; Zhou, R. The individual identification method of wireless device based on dimensionality reduction and machine learning. J. Supercomput. 2019, 75, 3010–3027. [Google Scholar] [CrossRef]
- Maeda, E. Dimensionality reduction. In Computer Vision: A Reference Guide; Springer: Berlin/Heidelberg, Germany, 2020; pp. 1–4. [Google Scholar]
- Szénási, S.; Vámossy, Z.; Kozlovszky, M. Preparing initial population of genetic algorithm for region growing parameter optimization. In Proceedings of the 2012 4th IEEE International Symposium on Logistics and Industrial Informatics, Smolenice, Slovakia, 5 September 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 47–54. [Google Scholar]
- Sun, Q.; Liu, Y.; Chua, T.S.; Schiele, B. Meta-transfer learning for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 403–412. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pretraining | Architeture | Mining | N-Way | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ||||
| Original 128 × 128 | Yes | Siamese | 100.0 | 98.3 | 96.4 | 95.6 | 93.7 | 92.2 | 90.9 | 90.4 | 88.8 | 89.9 | |
| Yes | Triplet | Semi-hard | 100.0 | 94.8 | 87.7 | 86.0 | 83.9 | 80.5 | 82.0 | 75.6 | 77.5 | 74.2 | |
| Yes | Triplet | Hardest | 100.0 | 95.7 | 92.5 | 91.1 | 86.7 | 82.4 | 81.0 | 80.2 | 76.9 | 75.3 | |
| No | Siamese | 100.0 | 98.2 | 97.5 | 94.9 | 94.7 | 92.3 | 93.6 | 90.1 | 87.8 | 89.5 | ||
| No | Triplet | Semi-hard | 100.0 | 94.7 | 93.4 | 88.0 | 86.7 | 83.5 | 83.3 | 79.8 | 80.1 | 76.7 | |
| No | Triplet | Hardest | 100.0 | 95.8 | 91.0 | 87.1 | 87.7 | 84.5 | 80.4 | 80.6 | 78.3 | 76.1 | |
| Highlighted 96 × 96 | Yes | Siamese | 100.0 | 97.5 | 94.7 | 94.0 | 94.5 | 90.5 | 91.6 | 89.7 | 88.0 | 86.5 | |
| Yes | Triplet | Semi-hard | 100.0 | 90.3 | 83.8 | 81.3 | 77.3 | 72.4 | 68.2 | 68.2 | 65.1 | 60.4 | |
| Yes | Triplet | Hardest | 100.0 | 94.1 | 86.3 | 85.9 | 81.2 | 78.1 | 77.6 | 71.7 | 68.1 | 69.8 | |
| No | Siamese | 100.0 | 94.9 | 92.8 | 91.1 | 88.8 | 84.9 | 83.3 | 84.4 | 82.1 | 79.8 | ||
| No | Triplet | Semi-hard | 100.0 | 81.9 | 70.3 | 65.7 | 61.4 | 57.2 | 52.1 | 49.1 | 45.0 | 46.3 | |
| No | Triplet | Hardest | 100.0 | 90.4 | 83.0 | 80.5 | 76.4 | 68.9 | 70.6 | 66.1 | 64.2 | 64.2 | |
| MDIPFL50 50 × 37 | Yes | Siamese | 100.0 | 97.3 | 95.2 | 94.0 | 90.4 | 88.8 | 87.1 | 88.3 | 87.2 | 86.2 | |
| Yes | Triplet | Semi-hard | 100.0 | 92.4 | 87.3 | 86.2 | 81.5 | 77.6 | 75.0 | 76.0 | 69.6 | 70.6 | |
| Yes | Triplet | Hardest | 100.0 | 96.2 | 93.2 | 88.3 | 87.1 | 82.9 | 79.9 | 81.1 | 79.5 | 75.1 | |
| No | Siamese | 100.0 | 97.7 | 95.1 | 93.9 | 92.7 | 92.2 | 88.0 | 88.1 | 85.9 | 87.3 | ||
| No | Triplet | Semi-hard | 100.0 | 80.8 | 72.4 | 66.4 | 61.0 | 54.7 | 54.8 | 50.6 | 45.6 | 42.2 | |
| No | Triplet | Hardest | 100.0 | 94.3 | 91.8 | 87.3 | 83.4 | 80.8 | 79.3 | 77.3 | 77.2 | 75.5 | |
| Pretraining | Architeture | Mining | Training Time (Seconds) | Iterations | Time per Iteration (Seconds) | |
|---|---|---|---|---|---|---|
| Original 128 × 128 | Yes | Siamese | 7488.01 | 75 | 99.84 | |
| Yes | Triplet | Semi-hard | 2528.65 | 16 | 158.04 | |
| Yes | Triplet | Hardest | 2907.28 | 18 | 161.52 | |
| No | Siamese | 10,263.05 | 102 | 100.62 | ||
| No | Triplet | Semi-hard | 9047.23 | 47 | 192.49 | |
| No | Triplet | Hardest | 9720.34 | 60 | 162.01 | |
| Highlighted 96 × 96 | Yes | Siamese | 2976.65 | 73 | 40.78 | |
| Yes | Triplet | Semi-hard | 1399.09 | 21 | 66.62 | |
| Yes | Triplet | Hardest | 1454.04 | 21 | 69.24 | |
| No | Siamese | 1984.10 | 120 | 16.53 | ||
| No | Triplet | Semi-hard | 518.04 | 16 | 32.38 | |
| No | Triplet | Hardest | 1212.54 | 32 | 37.89 | |
| MDIPFL50 50 × 37 | Yes | Siamese | 2430.68 | 86 | 28.26 | |
| Yes | Triplet | Semi-hard | 890.85 | 16 | 55.68 | |
| Yes | Triplet | Hardest | 2500.35 | 52 | 48.08 | |
| No | Siamese | 3017.49 | 104 | 29.01 | ||
| No | Triplet | Semi-hard | 888.62 | 19 | 46.77 | |
| No | Triplet | Hardest | 2425.68 | 46 | 52.73 |
| Architeture | Pretraining | Mining | N-Way | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |||
| Siamese | Yes | 100.0 | 91.8 | 83.5 | 79.4 | 76.1 | 74.0 | 71.3 | 65.8 | 66.5 | 65.6 | |
| Triplet | Yes | Semi-hard | 100.0 | 94.3 | 88.2 | 84.5 | 82.9 | 78.7 | 76.1 | 74.1 | 70.0 | 71.1 |
| Triplet | Yes | Hardest | 100.0 | 93.2 | 89.3 | 83.0 | 81.2 | 78.7 | 72.7 | 72.0 | 73.2 | 70.7 |
| Siamese | No | 100.0 | 82.9 | 76.0 | 70.3 | 67.7 | 66.0 | 62.0 | 58.1 | 56.7 | 55.1 | |
| Triplet | No | Semi-hard | 100.0 | 94.8 | 90.2 | 88.6 | 82.9 | 81.0 | 81.5 | 74.9 | 74.8 | 75.7 |
| Triplet | No | Hardest | 100.0 | 92.8 | 87.4 | 82.4 | 80.2 | 73.4 | 70.4 | 69.3 | 65.9 | 61.7 |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kertész, G. Metric Embedding Learning on Multi-Directional Projections. Algorithms 2020, 13, 133. https://doi.org/10.3390/a13060133
Kertész G. Metric Embedding Learning on Multi-Directional Projections. Algorithms. 2020; 13(6):133. https://doi.org/10.3390/a13060133
Chicago/Turabian StyleKertész, Gábor. 2020. "Metric Embedding Learning on Multi-Directional Projections" Algorithms 13, no. 6: 133. https://doi.org/10.3390/a13060133
APA StyleKertész, G. (2020). Metric Embedding Learning on Multi-Directional Projections. Algorithms, 13(6), 133. https://doi.org/10.3390/a13060133