Abstract
High-dimensional system identification problems can be efficiently addressed based on tensor decompositions and modelling. In this paper, we design a recursive least-squares (RLS) algorithm tailored for the identification of trilinear forms, namely RLS-TF. In our framework, the trilinear form is related to the decomposition of a third-order tensor (of rank one). The proposed RLS-TF algorithm acts on the individual components of the global impulse response, thus being efficient in terms of both performance and complexity. Simulation results indicate that the proposed solution outperforms the conventional RLS algorithm (which handles only the global impulse response), but also the previously developed trilinear counterparts based on the least-mean- squares algorithm.
1. Introduction
Currently, there is an increasing interest in developing methods and algorithms that exploit tensor decompositions and modelling [1,2]. These techniques become of significant importance in many real-world scenarios, e.g., when dealing with large amounts of data, processing multidimensional signals, or solving high-dimensional system identification problems. Many important applications rely on such tensor-based techniques, which can be successfully used in the fields of big data [3], source separation [4], machine learning [5], multiple-input multiple-output (MIMO) communication systems [6], and beamforming [7].
Tensor decompositions and their related applications are frequently addressed based on multilinear signal processing techniques [8,9]. For example, in the context of system identification scenarios, the problems can be formulated in terms of identifying multilinear forms. As particular cases, we can mention the bilinear and trilinear forms, where the decomposition is performed using two and three components, respectively. Since the Wiener filter and adaptive algorithms represent popular methods to address system identification problems, their applicability was also extended to the multilinear framework. Among the recent related works, we can mention the iterative Wiener filter for bilinear forms [10] and the subsequent adaptive filtering methods [11,12,13], together with their extensions to trilinear forms [14,15,16,17].
In this context, the work in [17] provided a system identification framework based on tensor decomposition, which was suitable for the trilinear approach. This work presents the iterative Wiener filter and least-mean-squares (LMS) adaptive algorithms tailored for trilinear forms. Among those, the normalized LMS (NLMS) algorithm for trilinear forms, namely NLMS-TF, represents a practical solution in terms of both performance and complexity. Nevertheless, it is known that the recursive least-squares (RLS) algorithm [18] could provide improved performance as compared to the LMS-based algorithms, especially in terms of the convergence rate. This represents the motivation behind the solution proposed in this paper, which targets the development of the RLS algorithm for trilinear forms, namely RLS-TF. Therefore, the goal of this work is mainly twofold. First, we aim to design a faster converging algorithm as compared to the recently developed NLMS-TF. Second, we intend to outline the performance features of the RLS-TF algorithm as compared to the conventional RLS benchmark.
Besides the conventional adaptive algorithms (which usually act as supervised methods), we should also note that unsupervised algorithms can be used in conjunction with tensor-based approaches, e.g., [19,20]. In this context, we can mention the single-channel blind source separation problem, which targets the identification of individual source signals from a single mixture recording. Such an approach can be found in [19], where the parameters of a so-called “imitated-stereo” mixture model (i.e., one real and the other virtual microphones, which results in an artificial mixing system of dual channels) were found by applying tensor estimation and exploiting sparsity features. The method proposed in [20] also exploits sparsity (using the Gibbs distribution) for multichannel source separation, by solving the underdetermined convolutive mixture separation, while considering the reverberations of the surrounding environment. Another appealing field where such tensor-based techniques can be applied is video processing. For example, unsupervised algorithms can be used for detecting anomalies in a video sequence, e.g., detecting micro defects while employing a thermography imaging system [21].
Currently, in many real-world applications related to MIMO systems, speech processing, and image/video processing, the received signals are tensors or can be grouped in a tensorial form. Consequently, as outlined before, utilizing estimation techniques from tensor algebra is beneficial. Moreover, in most of these applications, the underlying parameters to be estimated are sparse, so that specific features could be exploited, thus bringing additional advantages, especially for systems of large dimensions. The tensor-based RLS algorithm proposed in this paper represents an improved solution (in terms of convergence rate) as compared to the existing solution based on the NLMS algorithm [17], but also an efficient version (in terms of computational complexity) as compared to the conventional RLS algorithm [18].
The rest of the paper is organized as follows. Section 2 provides a background on third-order tensors, which represents the framework of trilinear forms. The proposed RLS-TF algorithm is developed in Section 3. Simulation results are provided in Section 4, outlining the main performance features of the designed solution. Finally, Section 5 concludes this paper and discusses several perspectives for future works.
2. Third-Order Tensors
In this section, we provide a brief summary on tensors, outlining the main definitions and operations, while also establishing the notation. A tensor can be defined as a multidimensional array of data [22,23]. For example, a matrix and a vector can be referred to as second- and first-order tensors, respectively. Tensors of order three or higher are called higher order tensors. In the following, the notation used for a tensor, a matrix, a vector, and a scalar is , , , and a, respectively. In this work, we are focusing only on real-valued third-order tensors, i.e., , so that the array dimension is .
The entries of a tensor can be referred to by using multiple indices. In our case, for a third-order tensor, the first and second indices (with ) and (with ) correspond to the row and column, respectively (like in a matrix); in addition, the third index (with ) corresponds to the tube and describes its depth. Consequently, these three indices describe the three different modes. In terms of notation, the entries of the different order tensors are denoted by , , and .
In the case of a matrix, the vectorization operation leads to a vector that contains the concatenated columns of the original matrix. In the case of a third-order tensor, the so-called matricization operation concatenates the “slices” of the tensor and produces a large matrix. Of course, the result depends on which index, all the elements of which are considered first. Thus, the matricization can be performed along three different modes [8,9]. For example, considering the mode row and then varying the columns and the tubes, we obtain:
where and the matrices with denote the frontal slices. Similarly, we can take the mode column and then vary the lines and the tubes, which results in , with . Finally, we can take the mode tube and then vary the rows and the columns, in order to obtain , where . The ranks of , , and represent the mode-1, mode-2, and mode-3 ranks of the tensor, respectively. Furthermore, the vectorization of a tensor (e.g., following mode-1) is
Nevertheless, there are some fundamental differences between the rank of a matrix and the rank of a tensor . For example, the rank of can never be larger than , while the rank of can be greater than . A rank-1 tensor (of dimension ) is defined as:
where , , and are vectors of lengths , , and , respectively, ∘ is the vector outer product, and the elements of are given by , where are the elements of the vector , with and . In this case, it can be easily verified that:
where ⊗ denotes the Kronecker product [24]. In this context, the rank of a tensor , denoted , is defined as the minimum number of rank-1 tensors that generate as their sum. For example, if:
where , , and are vectors of lengths , , and , respectively, then when R is minimal and (3) is called the canonical polyadic decomposition (CPD) of .
Another important operation is the multiplication of a tensor with a matrix [1,2], which can also be defined in different ways. For example, the mode-1 product between the tensor and the matrix gives the tensor:
whose entries are (for ) and . Similarly, the mode-2 product between the same tensor and the matrix leads to the tensor:
with the entries (for ) and . Finally, the mode-3 product between the tensor and the matrix results in the tensor:
having the entries (for ), while . Clearly, we can multiply the tensor with the three previously defined matrices , , and . In this case, we get the tensor:
where . As a consequence, considering , , and three vectors of lengths , , and , respectively, the multiplication of the tensor with the transposed vectors gives the scalar:
where is the transpose operator. It is easy to check that (8) is trilinear with respect to , , and .
At this point, we can also define the inner product between two tensors and of the same dimension (), which is:
Therefore, Expression (8) can also be written in a more convenient way, i.e.,
where (see (1)). Moreover, if is also a rank-1 tensor, i.e., , where the vectors have the lengths (with ), then:
Furthermore, it is easy to check that:
where the matrices , , and were previously defined (related to (4)–(6)).
The short background on tensors provided before and the main related operations (e.g., matricization, vectorization, rank, and different types of product) aim to facilitate the development that follows in Section 3. It is also important to outline that the trilinear forms result in the context of the decomposition of third-order tensors. Extension to higher order tensors and multilinear forms could be straightforward when dealing with rank-1 tensors. Otherwise, in the general case, decomposing higher rank higher order tensors (see (3)) raises additional difficulties, as will be briefly pointed out at the end of Section 5.
3. RLS Algorithm for Trilinear Forms
In the following, for the sake of consistency with the development of the NLMS-TF algorithm, we will keep the framework and notation from [17]. Therefore, let us consider the output of a multiple-input single-output (MISO) system (with real-valued data) at the discrete-time index n defined as:
where the tensorial form groups the input signals, with:
and the vectors (of lengths , , and , respectively) define the three impulse responses, i.e.,
As we can notice, represents a trilinear form (see (12) as compared to (8)), because it is a linear function of each of the vectors , if the other two are fixed.
Next, we can also introduce a rank-1 tensor of dimension , using the three impulse responses of the MISO system:
whose elements are:
Consequently, the output signal results in:
where:
with and () being the frontal slices of and , respectively. At this point, we can introduce the notation:
where and are two long vectors, each of them having elements. Thus, the output signal can also be expressed as:
The main goal is to estimate the output of the MISO system, which is usually corrupted by an additive noise. Hence, the reference signal results in:
where is a zero-mean additive noise, which is uncorrelated with the input signals. Alternatively, we could estimate the global impulse response , using an adaptive filter (of length ). At this point, we may also define the error signal:
which represents the difference between the reference signal and the estimated signal, .
Based on (17), we can notice that the global impulse response (of length ) results based on a combination of the shorter impulse responses , of lengths , , and , respectively. Consequently, the estimated impulse response can also be decomposed as:
where are three adaptive filters (with , , and coefficients, respectively), which aim to model the individual impulse responses . Nevertheless, we should notice that there is no unique solution related to the decomposition in (22). It is obvious that, for any constants , and , with , we have:
Hence, also represent a set of solutions. However, the global impulse response is identified with no scaling ambiguity.
Following the decomposition from (22), we can easily verify that:
where:
and are the identity matrices of sizes , , and , respectively. Moreover, introducing the notation:
the error signal from (21) can be expressed in three equivalent ways as:
Based on the least-squares error criterion [18] applied in the context of (20) and (21), the conventional RLS algorithm is derived from:
where is a positive constant known as the forgetting factor. On the other hand, based on (24)–(26), the cost function from (36) can be expressed in three different ways, targeting the optimization of the individual components, i.e.,
where , , and are the individual forgetting factors. The previous cost functions suggest a “trilinear” optimization strategy [25], where we assume that two components are fixed during the optimization of the third one. Consequently, based on the minimization of (37)–(39) with respect to , , and , respectively, the following set of normal equations are obtained:
where:
Solving (40)–(42), the updates of the individual filters result in:
where , , and are the Kalman gain vectors, while the error signal can be computed based on (33). At this point, the main task is to update the inverse of the matrices , , and efficiently. The solution relies on the matrix inversion lemma [18], which leads to the following updates:
Therefore, the Kalman gain vectors are evaluated as:
For initialization, we can choose:
where and are two vectors of length N, all elements of which are equal to zero and one, respectively.
The proposed RLS algorithm for trilinear forms, namely RLS-TF, is summarized in Table 1. It could also be interpreted as an extension of the RLS-based algorithm tailored for bilinear forms, which was presented in [12]. However, if the MISO system identification problem results based on (12), it is natural to use the RLS-TF algorithm, which is designed for the identification of third-order (rank-1) tensors.

Table 1.
RLS algorithm for trilinear forms (RLS-TF).
In terms of computational complexity, it can be noticed that the proposed RLS-TF algorithm combines the solutions provided by three RLS-based filters, i.e., (of length ), (of length ), and (of length ). Since the complexity of a regular RLS-based algorithm is proportional to the square of the filter length, the overall complexity of the RLS-TF algorithm roughly results in . On the other hand, the system identification problem can also be handled based on the conventional RLS algorithm, which results following (20) and (21), together with the cost function from (36). However, in this case, there is a single adaptive filter , of length , so that the computational complexity is of the order of . This could be much more computationally expensive as compared to the proposed RLS-TF algorithm.
Basically, the RLS-TF algorithm “transforms” a large system identification problem of length into three “smaller” problems of lengths , , and , respectively, with advantages in terms of both performance (as will be shown in simulations) and complexity. As outlined before, the proposed RLS-TF algorithm combines the solutions provided by three adaptive filters of lengths , , and , respectively, while the conventional RLS algorithm deals with a single filter of length , which is usually much longer. Since the length of the filter highly influences the main performance criteria, i.e., convergence rate and misadjustment [18], the proposed algorithm is able to outperform the conventional one in terms of both criteria. In other words, the shorter the length, the faster the convergence and the lower the misadjustment. This expected behaviour will be supported by the simulation results provided in the next section.
Finally, we should observe that there are some extra operations specific to the RLS-TF algorithm. For example, the “input” signals , , and result based on (30)–(32), which rely on (27)–(29). Furthermore, the global impulse response (if required within the application) can be evaluated based on (22). These operations require Kronecker products, but the related computational complexity is moderate, i.e., of the order of .
The detailed computational complexities of the proposed RLS-TF algorithm and other benchmark algorithms (i.e., the conventional RLS and NLMS algorithms) are summarized in Table 2. For a better visualization, the computational complexities are also illustrated in Figure 1, in terms of the number of multiplications and additions (per iteration), for different values of ; the other lengths are fixed to and (similar to the experimental setup from Section 4). As we can notice, the computational complexity of the conventional RLS algorithm was significantly greater, while the computational amount of the proposed RLS-TF algorithm was closer to the conventional NLMS algorithm, especially for higher lengths.
Table 2.
Computational complexity of the RLS-TF algorithm, as compared to the conventional RLS and NLMS algorithms.
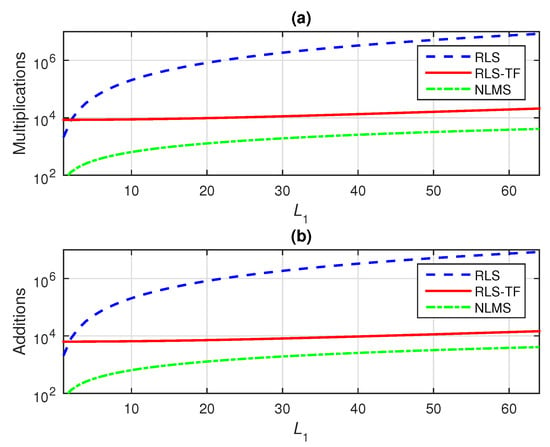
Figure 1.
Computational complexity of the proposed RLS-TF algorithm, as compared to the conventional RLS and NLMS algorithms, as a function of ; the other dimensions are set to and : (a) number of multiplications per iteration and (b) number of additions per iteration.
4. Simulation Results
Simulations were performed in the framework of a tensor-based system identification problem, which resulted following the MISO model defined by (12) and (20) and was similar to the setup used in [17]. The input signals that form the third-order tensor are AR(1) processes; they are generated by filtering white Gaussian noises through a first-order system . The additive noise is white and Gaussian; its variance was set to .
The third-order system used in the simulations and its components (, , and ) are depicted in Figure 2. First, the component is an impulse response from the G168 Recommendation [26], of length ; it is provided in Figure 2a. Second, in Figure 2b, the component is a random impulse response (with Gaussian distribution) of length . Third, the coefficients of the last component, i.e., the impulse response , are depicted in Figure 2c; those were evaluated as , using the length . Therefore, the global impulse response from Figure 2d resulted as , and its length was . This global impulse response resembled a channel with echoes, e.g., like an acoustic echo path [27]. Finally, the third-order (rank-1) tensor of dimension could be formed according to (13). In order to test the tracking capabilities of the algorithms, an abrupt change of the system was introduced in the middle of each experiment, by changing the sign of the coefficients of each impulse response.
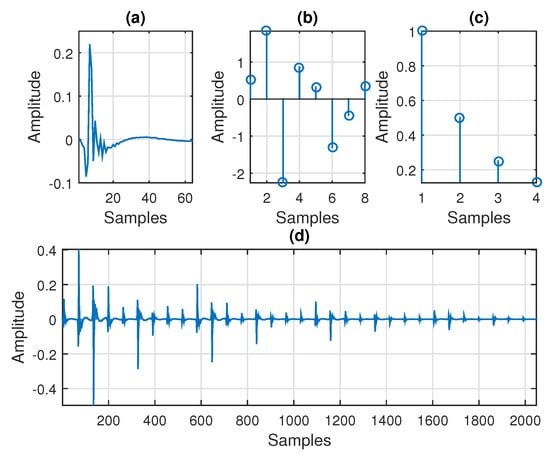
Figure 2.
The components of the third-order system used in simulations: (a) is the first impulse response (of length ) from the G168 Recommendation [26]; (b) is a randomly generated impulse response (of length ), with Gaussian distribution; (c) the impulse response (of length ), with the coefficients computed as , with ; and (d) the global impulse response (of length ) results based on (17), .
As shown in Section 3, the proposed RLS-TF algorithm was designed to estimate the individual components of the global system. However, we could identify , , and up to some scaling factors, as explained using (23). Therefore, to evaluate the identification of these individual impulse responses, a proper performance measure is the normalized projection misalignment (NPM) [28]:
where denotes the Euclidean norm. On the other hand, the global impulse response results without any scaling ambiguity. Consequently, we can use a performance measure based on the regular normalized misalignment (NM):
which is also equivalent to , where and denotes the Frobenius norm (the Frobenius norm of a third-order tensor is defined as ).
The simulation results should provide answers to several important questions, as follows. (i) What is the influence of the forgetting factors on the performance of the proposed RLS-TF algorithm? (ii) What are the advantages of the RLS-TF algorithm over the previously developed NLMS-TF counterpart [17]? (iii) What are the advantages of the RLS-TF algorithm over the conventional RLS benchmark? The following three experiments are designed to address these issues.
In the first experiment, the performance of the proposed RLS-TF algorithm was analysed with respect to its main parameters, i.e., the forgetting factors , , and . In the case of an RLS-based algorithm, the value of the forgetting factor is usually related to the filter length, following a well-known rule of thumb, as shown in Table 1 (see “Initialization”). In our case, the forgetting factors of the RLS-TF algorithm were set to , , and . As we can notice, the value of each forgetting factor depended on the length of its related filter (i.e., , , or ), but also on the constant K. This tuning parameter could be used to adjust the values of the forgetting factors, as indicated in Figure 3 and Figure 4. Clearly, a higher value of K would result in a higher value of the forgetting factor (i.e., closer to one). We could expect that a higher value of the forgetting factor would reduce the misalignment, but slowing down the convergence/tracking [29]. On the other hand, reducing the forgetting factor improves the convergence/tracking, but increasing the misalignment. This behaviour was supported by the results depicted in Figure 3 and Figure 4, in terms of NPM and NM, respectively. As we can notice, the value lead to a good compromise between the performance criteria, so that it would be used in the following experiments.
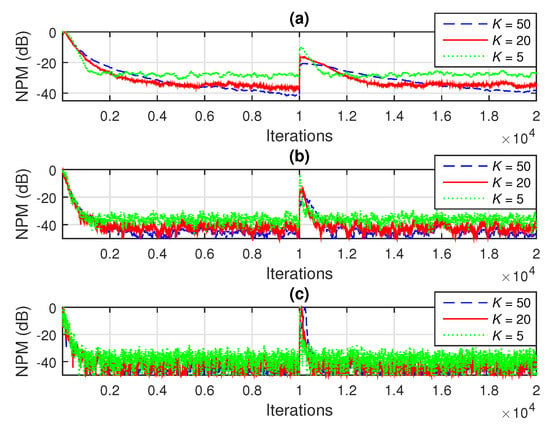
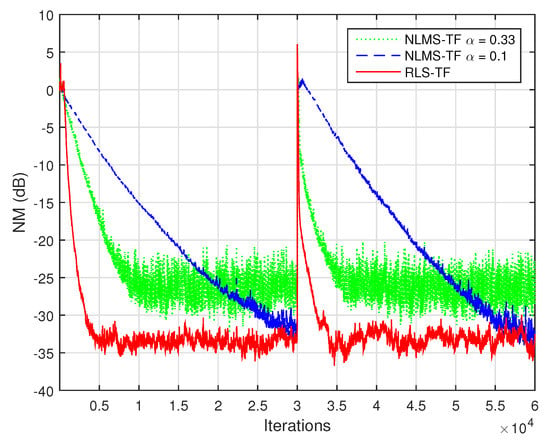
Next, we compare the performance of the proposed RLS-TF algorithm with its previously developed counterpart based on the NLMS algorithm, i.e., NLMS-TF [17]. The overall performance of this algorithm is mainly controlled by its normalized step-sizes, which are positive constants smaller than one. Using notation similar to that involved in [17], we set equal values for these parameters, i.e., . In the case of the NLMS-TF algorithm, the fastest convergence mode was obtained when , so that we could use . Smaller values of the normalized step-sizes (e.g., ) reduced the convergence/tracking, but led to a lower misalignment. As shown in Figure 5 and Figure 6 (in terms of NPM and NM, respectively), the RLS-TF algorithm clearly outperformed the NLMS-TF counterpart, achieving a faster convergence rate and tracking, together with low misalignment.
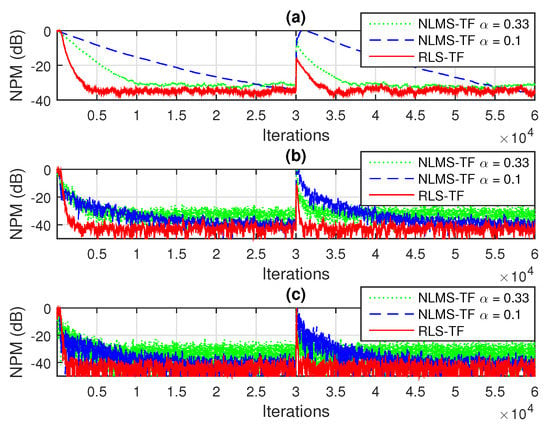
Figure 5.
Normalized projection misalignment (NPM) evaluated based on (55)–(57), in dB, for the identification of the individual impulse responses from Figure 2a–c, using the NLMS-TF algorithm [17] (with different normalized step-sizes ) and the RLS-TF algorithm (with the forgetting factors , where ): (a) , (b) , and (c) .
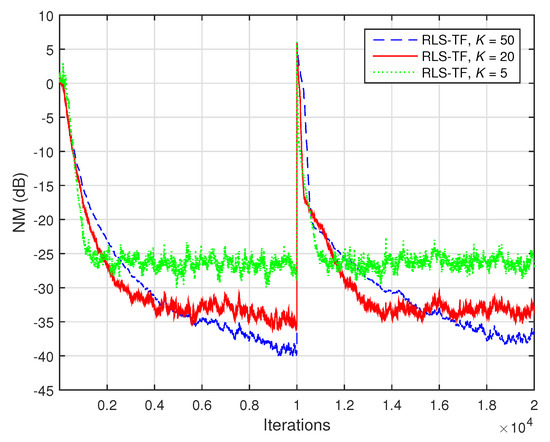
Finally, in the last experiment, we investigated the comparison between the RLS-TF solution and the conventional RLS algorithm. As explained in the last part of Section 3 (related to the computational complexity), the conventional RLS algorithm could also be used for the identification of the global impulse response of length L, based on the cost function from (36). This algorithm uses a single forgetting factor, which can also be set as , where K is the same tuning constant. The influence of the value of on the performance of the algorithm is also related to the well-known compromise between low misalignment and fast tracking. In the experiment reported in Figure 7, the conventional RLS algorithm uses two values of the forgetting factor, which were set by varying the tuning constant to and . As we can notice, even if the largest value of the forgetting factor (obtained for ) led to a lower misalignment, the tracking capability of the conventional RLS algorithm was significantly reduced. Clearly, the tracking was improved when using a smaller forgetting factor (corresponding to ), but the misalignment of the conventional RLS algorithm was much higher in this case. On the other hand, the RLS-TF algorithm outperformed by far its conventional counterpart, in terms of both performance criteria. Moreover, the complexity of the conventional RLS algorithm, i.e., , was prohibitive for practical implementations, due to the long length of the global filter (). On the other hand, the RLS-TF algorithm worked on the individual components and combined the solutions of three shorter filters, of lengths , , and (with ); thus, it was much more computationally efficient. As a trivial example related to the last experiment given in Figure 7, we could mention that the simulation time (using MATLAB) of the RLS-TF algorithm was less than one minute, while the conventional RLS algorithm took hours to reach the final result.
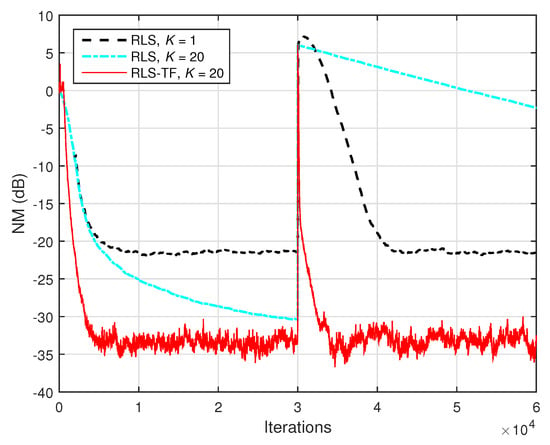
Figure 7.
Normalized misalignment (NM) evaluated based on (58), in dB, for the identification of the global impulse response (of length ) from Figure 2d, using the conventional RLS algorithm (with different values of the forgetting factor , varying the value of K) and the RLS-TF algorithm (with the forgetting factors , where ).
5. Conclusions and Future Works
In this paper, we explored the identification of trilinear forms using the RLS algorithm. The approach was developed in the framework of an MISO system identification problem, based on the decomposition and modelling of third-order tensors. The resulting RLS-TF algorithm was tailored for the identification of such trilinear forms in a more efficient way as compared to the conventional RLS algorithm. Moreover, the proposed RLS-TF algorithm outperformed its previously developed NLMS-TF counterpart in terms of the main performance criteria, providing a faster convergence rate and tracking, together with low misalignment.
The ideas presented in this paper could be further exploited in an extended framework, aiming to identify more general forms of global impulse responses, which cannot be decomposed as rank-1 tensors. Several preliminary results can be found in [30,31,32], but they are applicable only in the bilinear context (i.e., second-order tensors). The extension to the trilinear case represents a very challenging problem, since finding (and approximating) the rank of a higher order tensor is a much more sensitive task. Furthermore, it would be interesting to extend other versions of the NLMS and RLS algorithms (e.g., based on variable step-sizes [33] and variable forgetting factors [34], respectively) to the trilinear forms.
Finally, it would be useful to evaluate how the proposed algorithm could benefit (in terms of implementation) from the current technology of the tensor processing unit (TPU) and the TensorFlow software [35]. This aspect could bring additional advantages, especially in the framework of specific applications related to machine learning/vision, neural networks, and artificial intelligence.
Author Contributions
Conceptualization, C.E.-I.; methodology, L.-M.D.; investigation, C.P.; validation, J.B.; software, A.-A.E.; formal analysis, S.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by UEFISCDI grant number PN-III-P1-1.1-PD-2019-0340.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Comon, P. Tensors: A brief introduction. IEEE Signal Process. Mag. 2014, 31, 44–53. [Google Scholar] [CrossRef]
- Cichocki, A.; Mandic, D.; De Lathauwer, L.; Zhou, G.; Zhao, Q.; Caiafa, C.; Phan, H.A. Tensor decompositions for signal processing applications: From two-way to multiway component analysis. IEEE Signal Process. Mag. 2015, 32, 145–163. [Google Scholar] [CrossRef]
- Vervliet, N.; Debals, O.; Sorber, L.; De Lathauwer, L. Breaking the curse of dimensionality using decompositions of incomplete tensors: Tensor-based scientific computing in big data analysis. IEEE Signal Process. Mag. 2014, 31, 71–79. [Google Scholar] [CrossRef]
- Boussé, M.; Debals, O.; De Lathauwer, L. A tensor-based method for large-scale blind source separation using segmentation. IEEE Trans. Signal Process. 2017, 65, 346–358. [Google Scholar] [CrossRef]
- Sidiropoulos, N.; De Lathauwer, L.; Fu, X.; Huang, K.; Papalexakis, E.; Faloutsos, C. Tensor decomposition for signal processing and machine learning. IEEE Trans. Signal Process. 2017, 65, 3551–3582. [Google Scholar] [CrossRef]
- Da Costa, M.N.; Favier, G.; Romano, J.M.T. Tensor modelling of MIMO communication systems with performance analysis and Kronecker receivers. Signal Process. 2018, 145, 304–316. [Google Scholar] [CrossRef]
- Ribeiro, L.N.; de Almeida, A.L.; Mota, J.C.M. Separable linearly constrained minimum variance beamformers. Signal Process. 2019, 158, 15–25. [Google Scholar] [CrossRef]
- De Lathauwer, L. Signal Processing Based on Multilinear Algebra. Ph.D. Thesis, Katholieke Universiteit Leuven, Leuven, Belgium, 1997. [Google Scholar]
- Kolda, T.G.; Bader, B.W. Tensor decompositions and applications. SIAM Rev. 2009, 51, 455–500. [Google Scholar] [CrossRef]
- Benesty, J.; Paleologu, C.; Ciochină, S. On the identification of bilinear forms with the Wiener filter. IEEE Signal Process. Lett. 2017, 24, 653–657. [Google Scholar] [CrossRef]
- Paleologu, C.; Benesty, J.; Ciochină, S. Adaptive filtering for the identification of bilinear forms. Digit. Signal Process. 2018, 75, 153–167. [Google Scholar] [CrossRef]
- Elisei-Iliescu, C.; Stanciu, C.; Paleologu, C.; Benesty, J.; Anghel, C.; Ciochină, S. Efficient recursive least-squares algorithms for the identification of bilinear forms. Digit. Signal Process. 2018, 83, 280–296. [Google Scholar] [CrossRef]
- Dogariu, L.-M.; Ciochină, S.; Paleologu, C.; Benesty, J. A connection between the Kalman filter and an optimized LMS algorithm for bilinear forms. Algorithms 2018, 11, 211. [Google Scholar] [CrossRef]
- Ribeiro, L.N.; de Almeida, A.L.F.; Mota, J.C.M. Identification of separable systems using trilinear filtering. In Proceedings of the 2015 IEEE 6th International Workshop on Computational Advances in Multi-Sensor Adaptive Processing (CAMSAP), Cancun, Mexico, 13–16 December 2015; pp. 189–192. [Google Scholar]
- Rupp, M.; Schwarz, S. A tensor LMS algorithm. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, QLD, Australia, 19–24 April 2015; pp. 3347–3351. [Google Scholar]
- Dogariu, L.-M.; Ciochină, S.; Benesty, J.; Paleologu, C. An iterative Wiener filter for the identification of trilinear forms. In Proceedings of the 2019 42nd International Conference on Telecommunications and Signal Processing (TSP), Budapest, Hungary, 1–3 July 2019; pp. 88–93. [Google Scholar]
- Dogariu, L.-M.; Ciochină, S.; Benesty, J.; Paleologu, C. System identification based on tensor decompositions: A trilinear approach. Symmetry 2019, 11, 556. [Google Scholar] [CrossRef]
- Haykin, S. Adaptive Filter Theory, 4th ed.; Prentice-Hall: Upper Saddle River, NJ, USA, 2002. [Google Scholar]
- Parathai, P.; Tengtrairat, N.; Woo, W.L.; Gao, B. Single-channel signal separation using spectral basis correlation with sparse nonnegative tensor factorization. Circuits Syst. Signal Process. 2019, 38, 5786–5816. [Google Scholar] [CrossRef]
- Woo, W.L.; Dlay, S.S.; Al-Tmeme, A.; Gao, B. Reverberant signal separation using optimized complex sparse nonnegative tensor deconvolution on spectral covariance matrix. Digit. Signal Process. 2018, 83, 9–23. [Google Scholar] [CrossRef]
- Gao, B.; Lu, P.; Woo, W.L.; Tian, G.Y.; Zhu, Y.; Johnston, M. Variational Bayes sub-group adaptive sparse component extraction for diagnostic imaging system. IEEE Trans. Ind. Electron. 2018, 65, 8142–8152. [Google Scholar] [CrossRef]
- Kiers, H.A.L. Towards a standardized notation and terminology in multiway analysis. J. Chemom. 2000, 14, 105–122. [Google Scholar] [CrossRef]
- Kroonenberg, P. Applied Multiway Data Analysis; Wiley: Hoboken, NJ, USA, 2008. [Google Scholar]
- Van Loan, C.F. The ubiquitous Kronecker product. J. Comput. Appl. Math. 2000, 123, 85–100. [Google Scholar] [CrossRef]
- Bertsekas, D.P. Nonlinear Programming, 2nd ed.; Athena Scientific: Belmont, MA, USA, 1999. [Google Scholar]
- Digital Network Echo Cancellers; ITU-T Recommendations G.168; ITU: Geneva, Switzerland, 2002.
- Gay, S.L.; Benesty, J. (Eds.) Acoustic Signal Processing for Telecommunication; Kluwer Academic Publisher: Boston, MA, USA, 2000. [Google Scholar]
- Morgan, D.R.; Benesty, J.; Sondhi, M.M. On the evaluation of estimated impulse responses. IEEE Signal Process. Lett. 1998, 5, 174–176. [Google Scholar] [CrossRef]
- Ciochină, S.; Paleologu, C.; Benesty, J.; Enescu, A.A. On the influence of the forgetting factor of the RLS adaptive filter in system identification. In Proceedings of the 2009 International Symposium on Signals, Circuits and Systems, Iasi, Romania, 9–10 July 2009; pp. 205–208. [Google Scholar]
- Paleologu, C.; Benesty, J.; Ciochină, S. Linear system identification based on a Kronecker product decomposition. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 1793–1808. [Google Scholar] [CrossRef]
- Elisei-Iliescu, C.; Paleologu, C.; Benesty, J.; Ciochină, S. A recursive least-squares algorithm based on the nearest Kronecker product decomposition. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 4843–4847. [Google Scholar]
- Elisei-Iliescu, C.; Paleologu, C.; Benesty, J.; Stanciu, C.; Anghel, C.; Ciochină, S. Recursive least-squares algorithms for the identification of low-rank systems. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 903–918. [Google Scholar] [CrossRef]
- Benesty, J.; Rey, H.; Rey Vega, L.; Tressens, S. A non-parametric VSS NLMS algorithm. IEEE Signal Process. Lett. 2006, 13, 581–584. [Google Scholar] [CrossRef]
- Paleologu, C.; Benesty, J.; Ciochină, S. A robust variable forgetting factor recursive least-squares algorithm for system identification. IEEE Signal Process. Lett. 2008, 15, 597–600. [Google Scholar] [CrossRef]
- Jouppi, N.P.; Young, C.; Patil, N.; Patterson, D.; Agrawal, G.; Bajwa, R.; Bates, S.; Bhatia, S.; Boden, N.; Borchers, A.; et al. In-datacenter performance analysis of a tensor processing unit. In Proceedings of the 44th Annual International Symposium on Computer Architecture, Toronto, ON, Canada, 24–28 June 2017; pp. 1–12. [Google Scholar]







© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).