A Jacobi–Davidson Method for Large Scale Canonical Correlation Analysis


Abstract
1. Introduction
2. Preliminaries
3. The Main Algorithm
3.1. Subspace Extraction
3.2. Correction Equation
- (1)
- At step 2, A- and B-orthogonality procedures are applied to make sure and .
- (2)
- At step 7, in most cases, the correct equation is not necessity to solve exactly. Some steps of iterative methods for symmetric linear systems, such as linear conjugate gradient method (CG) [34] or the minimum residual method (MINRES) [35], are sufficient. Usually, more steps in solving the correction equation lead to fewer outer iterations. This will be shown in numerical examples.
- (3)
- For the convergence test, we use the relative residual normsto determine if the approximate eigenparis has converged to a desired accuracy. In addition, in the practical implementation, once one or several of approximate eigenpairs converge to a preset accuracy, they should be deflated so that they will not be re-computed in the following iterations. Suppose for , and have been computed where . We can consider the generalized eigenvalue problemwhereBy (11), it is clear that the eigenvalues of (24) consist of two groups. Those eigenvalues associated with the eigenvectors are shifted to zero and the others remain unchanged. Furthermore, for the correction equation, we find s and t subject to additional A- and B-orthogonality constrains for s and t against and , respectively. By a similar derivation of (22), the correction equation after deflation becomeswhere . Notice that and mean and in Algorithm 1, respectively. It follows that .
- (4)
- At step 5, LAPACK’s routine xGESVD can be used to solve the singular value problem of because of its small size, where takes the following form:This form is preserved in the algorithm during refining the basis U and V at step 8. The new basis matrices and are reassigned to U and V, respectively. Although a few extra costs are incurred, this refinement is necessary in order to have faster convergence for eigenvectors as stated in [36,37]. Furthermore, the restart is easily executed by keeping the first columns of U and V when the dimension of the subspaces and exceeds . The restart technique appears at step 8 to keep the size of U, V and small. There are many ways to specify and . In our numerical examples, we just simply take and .


| Algorithm 1 Jacobi–Davidson method for canonical correlation analysis (JDCCA) |
| Input: Initial vectors , , , and . Output: Converged canonical weight vectors and for .
|
3.3. Convergence
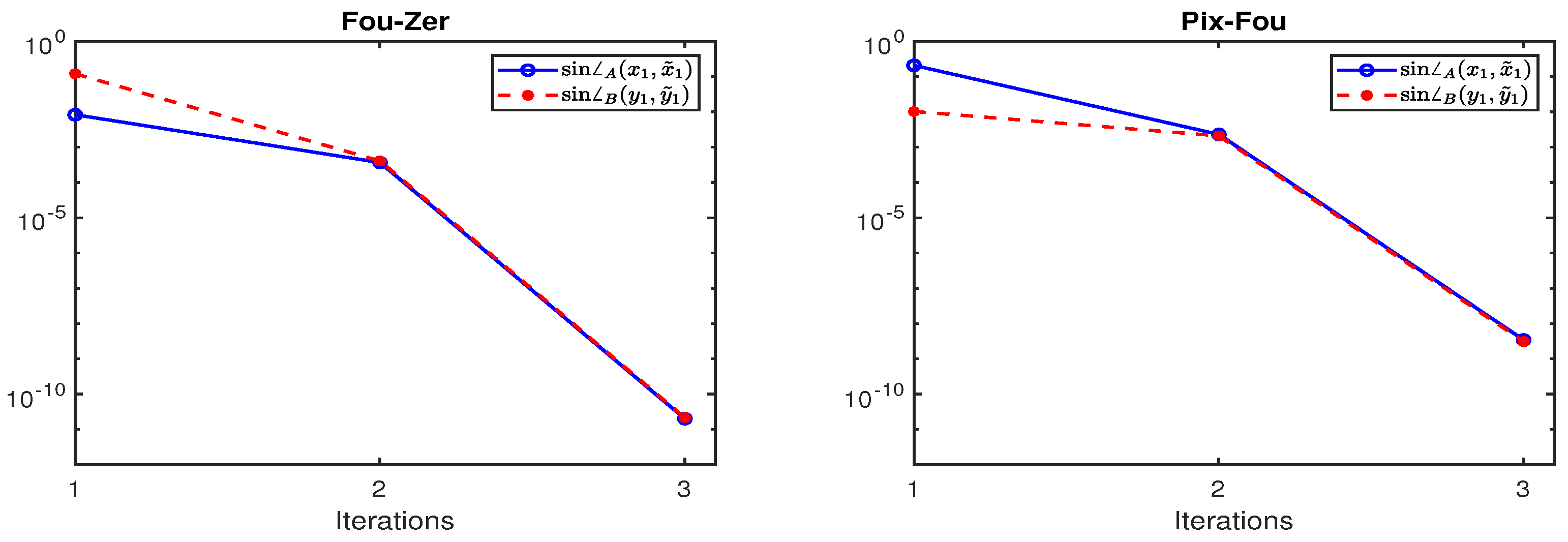
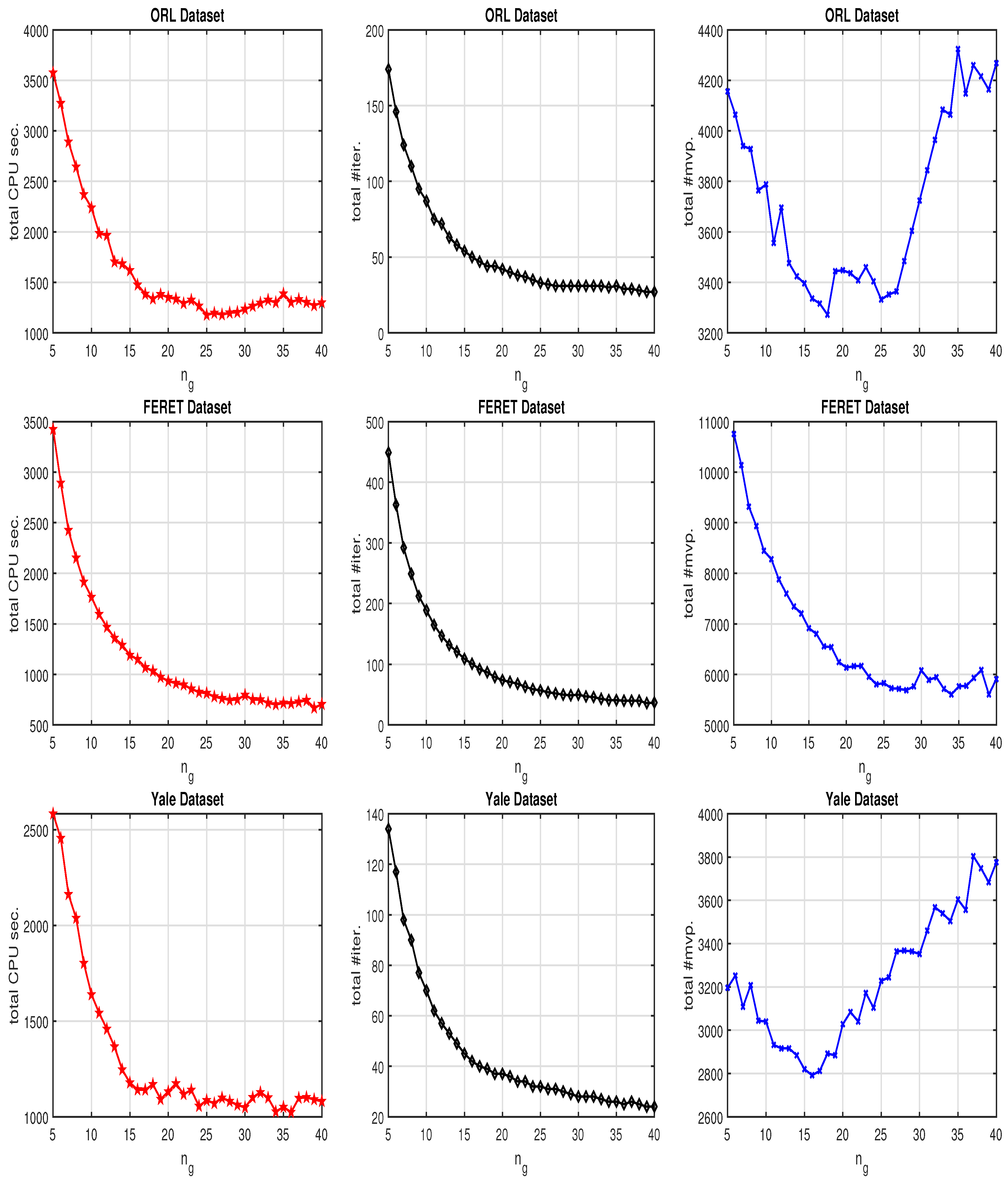
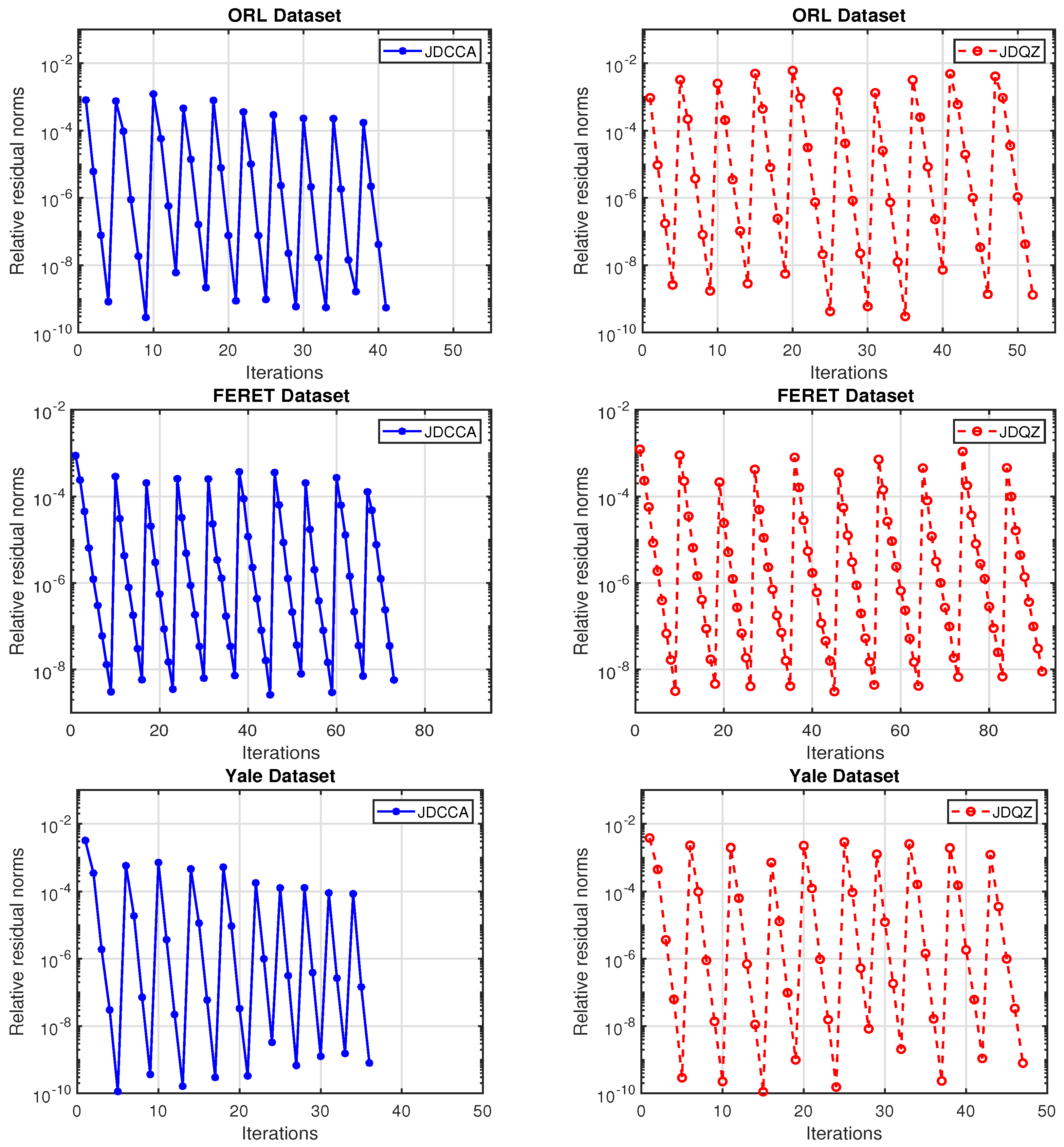
4. Numerical Examples
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A
Appendix A.1
Appendix A.2
Appendix A.3
References
- Hardoon, D.R.; Szedmak, S.; Shawe-Taylor, J. Canonical correlation analysis: An overview with application to learning methods. Neural Comput. 2004, 16, 2639–2664. [Google Scholar] [CrossRef] [PubMed]
- Harold, H. Relations between two sets of variates. Biometrika 1936, 28, 321–377. [Google Scholar]
- Wang, L.; Zhang, L.H.; Bai, Z.; Li, R.C. Orthogonal canonical correlation analysis and applications. Opt. Methods Softw. 2020, 35, 787–807. [Google Scholar] [CrossRef]
- Uurtio, V.; Monteiro, J.M.; Kandola, J.; Shawe-Taylor, J.; Fernandez-Reyes, D.; Rousu, J. A tutorial on canonical correlation methods. ACM Comput. Surv. 2017, 50, 1–33. [Google Scholar] [CrossRef]
- Zhang, L.H.; Wang, L.; Bai, Z.; Li, R.C. A self-consistent-field iteration for orthogonal CCA. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 1–15. [Google Scholar] [CrossRef]
- Fukunaga, K. Introduction to Statistical Pattern Recognition; Elsevier: Amsterdam, The Netherlands, 2013. [Google Scholar]
- González, I.; Déjean, S.; Martin, P.G.P.; Gonçalves, O.; Besse, P.; Baccini, A. Highlighting relationships between heterogeneous biological data through graphical displays based on regularized canonical correlation analysis. J. Biol. Syst. 2009, 17, 173–199. [Google Scholar] [CrossRef]
- Leurgans, S.E.; Moyeed, R.A.; Silverman, B.W. Canonical correlation analysis when the data are curves. J. R. Stat. Soc. B. Stat. Methodol. 1993, 55, 725–740. [Google Scholar] [CrossRef]
- Raul, C.C.; Lee, M.L.T. Fast regularized canonical correlation analysis. Comput. Stat. Data Anal. 2014, 70, 88–100. [Google Scholar]
- Vinod, H.D. Canonical ridge and econometrics of joint production. J. Econ. 1976, 4, 147–166. [Google Scholar] [CrossRef]
- González, I.; Déjean, S.; Martin, P.G.P.; Baccini, A. CCA: An R package to extend canonical correlation analysis. J. Stat. Softw. 2008, 23, 1–14. [Google Scholar] [CrossRef]
- Ma, Z. Canonical Correlation Analysis and Network Data Modeling: Statistical and Computational Properties. Ph.D. Thesis, University of Pennsylvania, Philadelphia, PA, USA, 2017. [Google Scholar]
- Golub, G.; Kahan, W. Calculating the singular values and pseudo-inverse of a matrix. SIAM J. Numer. Anal. 1965, 2, 205–224. [Google Scholar] [CrossRef]
- Jia, Z.; Niu, D. An implicitly restarted refined bidiagonalization Lanczos method for computing a partial singular value decomposition. SIAM J. Matrix Anal. Appl. 2003, 25, 246–265. [Google Scholar] [CrossRef]
- Hochstenbach, M.E. A Jacobi—Davidson type SVD method. SIAM J. Sci. Comput. 2001, 23, 606–628. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, Z.; Zhou, A. Accelerating large partial EVD/SVD calculations by filtered block Davidson methods. Sci. China Math. 2016, 59, 1635–1662. [Google Scholar] [CrossRef]
- Allen-Zhu, Z.; Li, Y. Doubly accelerated methods for faster CCA and generalized eigendecomposition. In Proceedings of the International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; pp. 98–106. [Google Scholar]
- Saad, Y. Numerical Methods for Large Eigenvalue Problems: Revised Edition; SIAM: Philadelphia, PA, USA, 2011. [Google Scholar]
- Stewart, G.W. Matrix Algorithms Volume II: Eigensystems; SIAM: Philadelphia, PA, USA, 2001; Volume 2. [Google Scholar]
- Sleijpen, G.L.G.; Van der Vorst, H.A. A Jacobi—Davidson iteration method for linear eigenvalue problems. SIAM Rev. 2000, 42, 267–293. [Google Scholar] [CrossRef]
- Hochstenbach, M.E. A Jacobi—Davidson type method for the generalized singular value problem. Linear Algebra Appl. 2009, 431, 471–487. [Google Scholar] [CrossRef]
- Betcke, T.; Voss, H. A Jacobi–Davidson-type projection method for nonlinear eigenvalue problems. Future Gen. Comput. Syst. 2004, 20, 363–372. [Google Scholar] [CrossRef]
- Hochstenbach, M.E.; Plestenjak, B. A Jacobi—Davidson type method for a right definite two-parameter eigenvalue problem. SIAM J. Matrix Anal. Appl. 2002, 24, 392–410. [Google Scholar] [CrossRef][Green Version]
- Arbenz, P.; Hochstenbach, M.E. A Jacobi—Davidson method for solving complex symmetric eigenvalue problems. SIAM J. Sci. Comput. 2004, 25, 1655–1673. [Google Scholar] [CrossRef][Green Version]
- Campos, C.; Roman, J.E. A polynomial Jacobi—Davidson solver with support for non-monomial bases and deflation. BIT Numer. Math. 2019, 60, 295–318. [Google Scholar] [CrossRef]
- Hochstenbach, M.E. A Jacobi—Davidson type method for the product eigenvalue problem. J. Comput. Appl. Math. 2008, 212, 46–62. [Google Scholar] [CrossRef]
- Hochstenbach, M.E.; Muhič, A.; Plestenjak, B. Jacobi—Davidson methods for polynomial two-parameter eigenvalue problems. J. Comput. Appl. Math. 2015, 288, 251–263. [Google Scholar] [CrossRef]
- Meerbergen, K.; Schröder, C.; Voss, H. A Jacobi–Davidson method for two-real-parameter nonlinear eigenvalue problems arising from delay-differential equations. Numer. Linear Algebra Appl. 2013, 20, 852–868. [Google Scholar] [CrossRef]
- Rakhuba, M.V.; Oseledets, I.V. Jacobi–Davidson method on low-rank matrix manifolds. SIAM J. Sci. Comput. 2018, 40, A1149–A1170. [Google Scholar] [CrossRef]
- Stewart, G.W.; Sun, J.G. Matrix Perturbation Theory; Academic Press: Boston, FL, USA, 1990. [Google Scholar]
- Teng, Z.; Wang, X. Majorization bounds for SVD. Jpn. J. Ind. Appl. Math. 2018, 35, 1163–1172. [Google Scholar] [CrossRef]
- Bai, Z.; Li, R.C. Minimization principles and computation for the generalized linear response eigenvalue problem. BIT Numer. Math. 2014, 54, 31–54. [Google Scholar] [CrossRef]
- Teng, Z.; Li, R.C. Convergence analysis of Lanczos-type methods for the linear response eigenvalue problem. J. Comput. Appl. Math. 2013, 247, 17–33. [Google Scholar] [CrossRef]
- Demmel, J.W. Applied Numerical Linear Algebra; SIAM: Philadelphia, PA, USA, 1997. [Google Scholar]
- Saad, Y. Iterative Methods for Sparse Linear Systems; SIAM: Philadelphia, PA, USA, 2003. [Google Scholar]
- Teng, Z.; Zhou, Y.; Li, R.C. A block Chebyshev-Davidson method for linear response eigenvalue problems. Adv. Comput. Math. 2016, 42, 1103–1128. [Google Scholar] [CrossRef]
- Zhou, Y.; Saad, Y. A Chebyshev–Davidson algorithm for large symmetric eigenproblems. SIAM J. Matrix Anal. Appl. 2007, 29, 954–971. [Google Scholar] [CrossRef]
- Sleijpen, G.L.G.; Van der Vorst, H.A. The Jacobi–Davidson method for eigenvalue problems as an accelerated inexact Newton scheme. In Proceedings of the IMACS Conference, Blagoevgrad, Bulgaria, 17–20 June 1995. [Google Scholar]
- Saad, Y.; Schultz, M.H. GMRES: A generalized minimal residual algorithm for solving nonsymmetric linear systems. SIAM J. Sci. Statist. Comput. 1986, 7, 856–869. [Google Scholar] [CrossRef]
- Lee, S.H.; Choi, S. Two-dimensional canonical correlation analysis. IEEE Signal Process. Lett. 2007, 14, 735–738. [Google Scholar] [CrossRef]
- Fokkema, D.R.; Sleijpen, G.L.G.; Van der Vorst, H.A. Jacobi–Davidson style QR and QZ algorithms for the reduction of matrix pencils. SIAM J. Sci. Comput. 1998, 20, 94–125. [Google Scholar] [CrossRef]
- Desai, N.; Seghouane, A.K.; Palaniswami, M. Algorithms for two dimensional multi set canonical correlation analysis. Pattern Recognit. Lett. 2018, 111, 101–108. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Problems | ORL | FERET | Yale |
|---|---|---|---|
| m | 10,304 | 6400 | 10,000 |
| n | 10,304 | 6400 | 10,000 |
| d | 200 | 600 | 75 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Teng, Z.; Zhang, X. A Jacobi–Davidson Method for Large Scale Canonical Correlation Analysis. Algorithms 2020, 13, 229. https://doi.org/10.3390/a13090229
Teng Z, Zhang X. A Jacobi–Davidson Method for Large Scale Canonical Correlation Analysis. Algorithms. 2020; 13(9):229. https://doi.org/10.3390/a13090229
Chicago/Turabian StyleTeng, Zhongming, and Xiaowei Zhang. 2020. "A Jacobi–Davidson Method for Large Scale Canonical Correlation Analysis" Algorithms 13, no. 9: 229. https://doi.org/10.3390/a13090229
APA StyleTeng, Z., & Zhang, X. (2020). A Jacobi–Davidson Method for Large Scale Canonical Correlation Analysis. Algorithms, 13(9), 229. https://doi.org/10.3390/a13090229