Sampling Effects on Algorithm Selection for Continuous Black-Box Optimization


Abstract
:1. Introduction
2. Background and Related Work
2.1. Black-Box Optimization and Fitness Landscapes
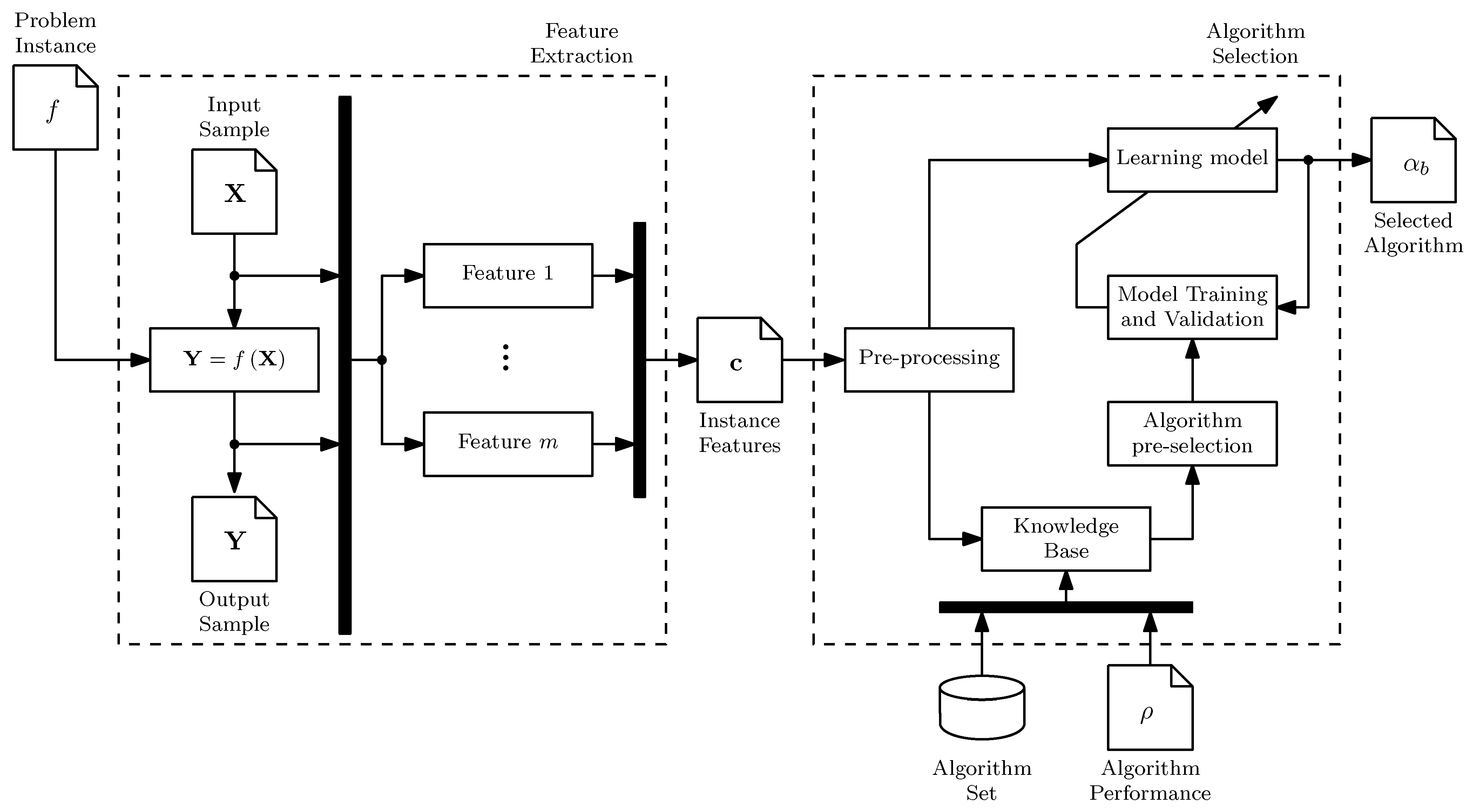
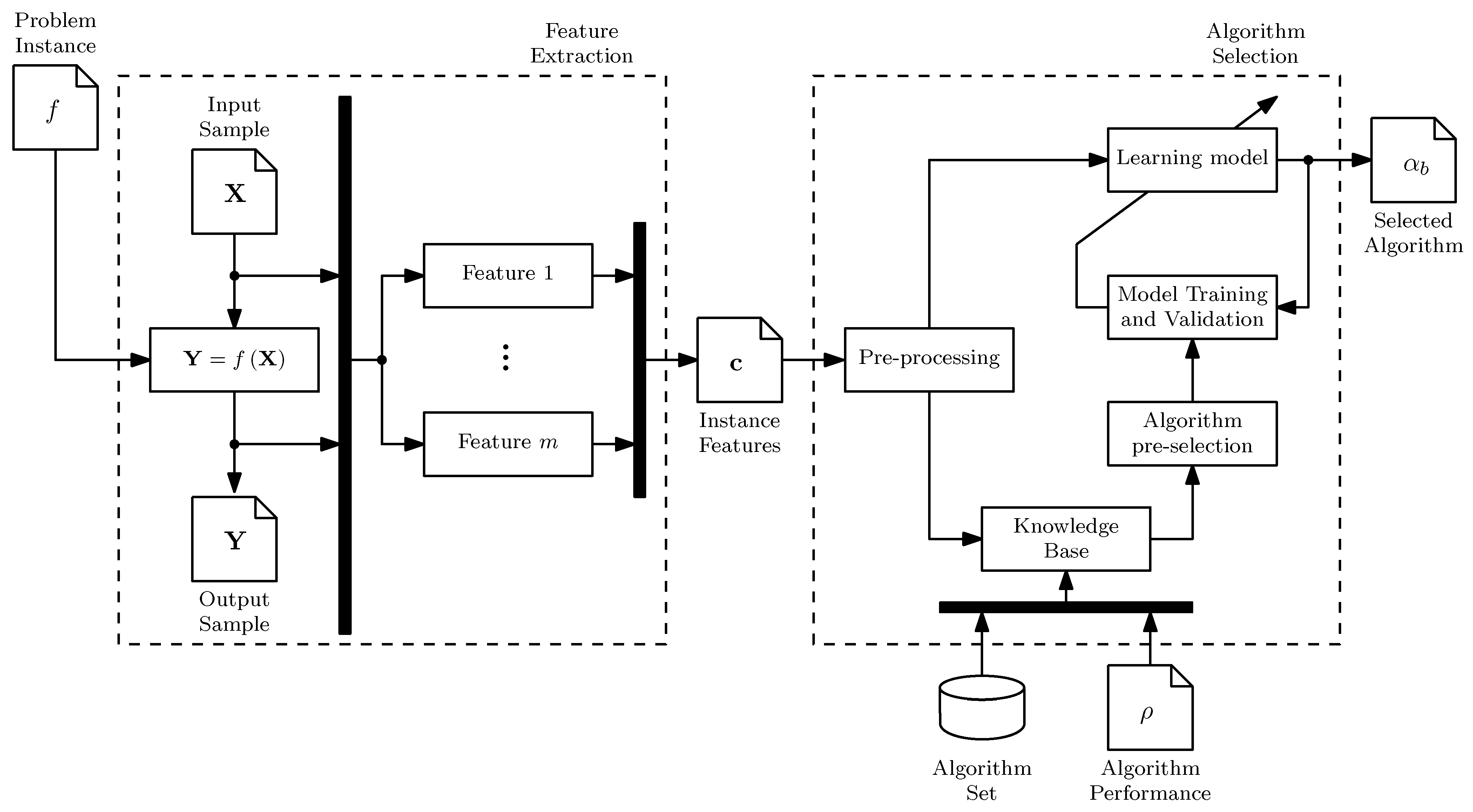
2.2. The Algorithm Selection Framework
- Problem set () contains all the relevant BBO problems. It is hard to formally define and has infinite cardinality.
- Algorithm set () contains all search algorithms. This set potentially has infinite cardinality.
- Performance evaluation is a procedure to evaluate the solution quality or speed of a search algorithm in a function f, using a performance measure, .
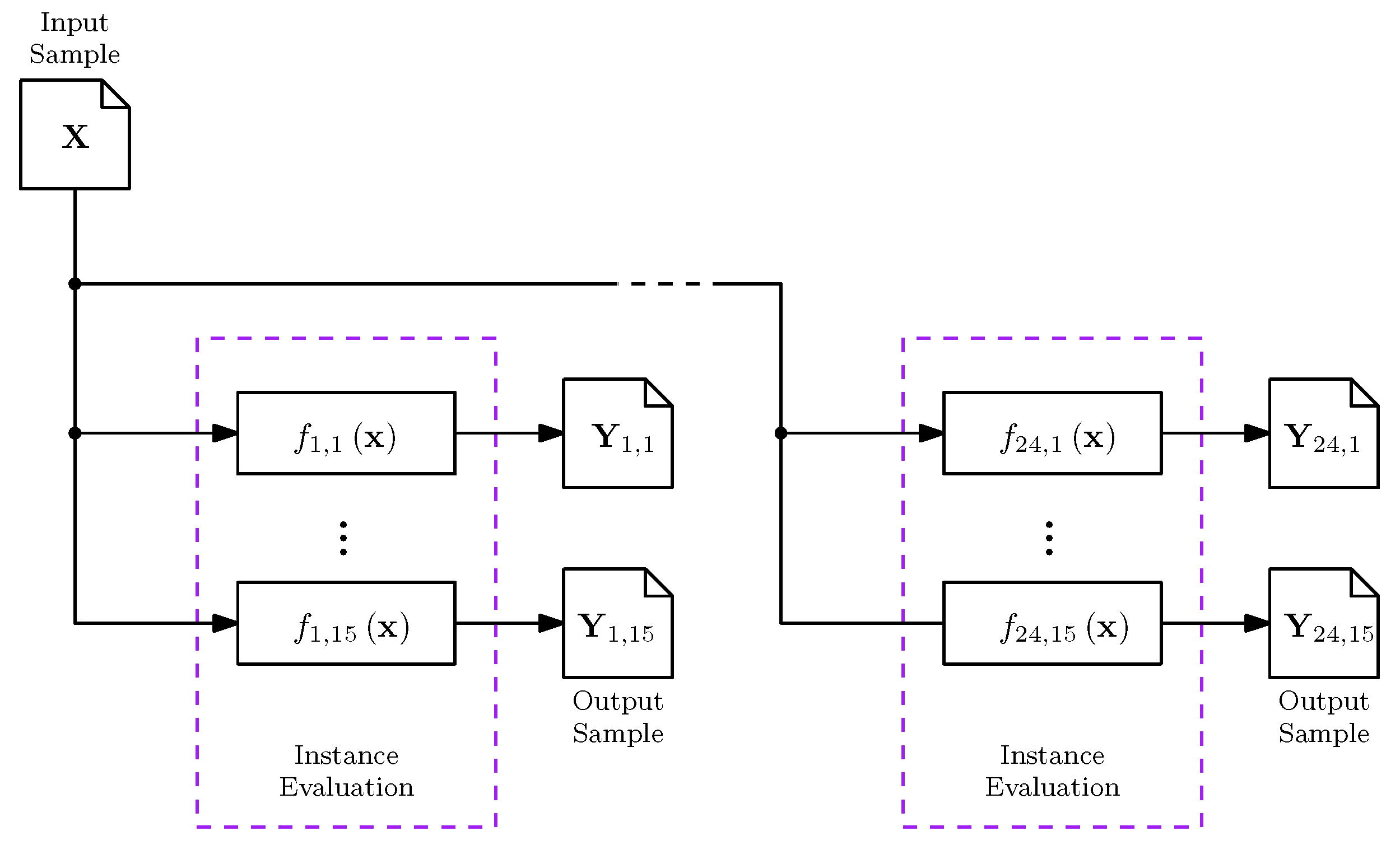
- Feature extraction is a procedure where an input sample, , is evaluated in the problem instance, resulting in an output sample, . These two samples are then used to calculate the ELA features, , as illustrated in Figure 2.
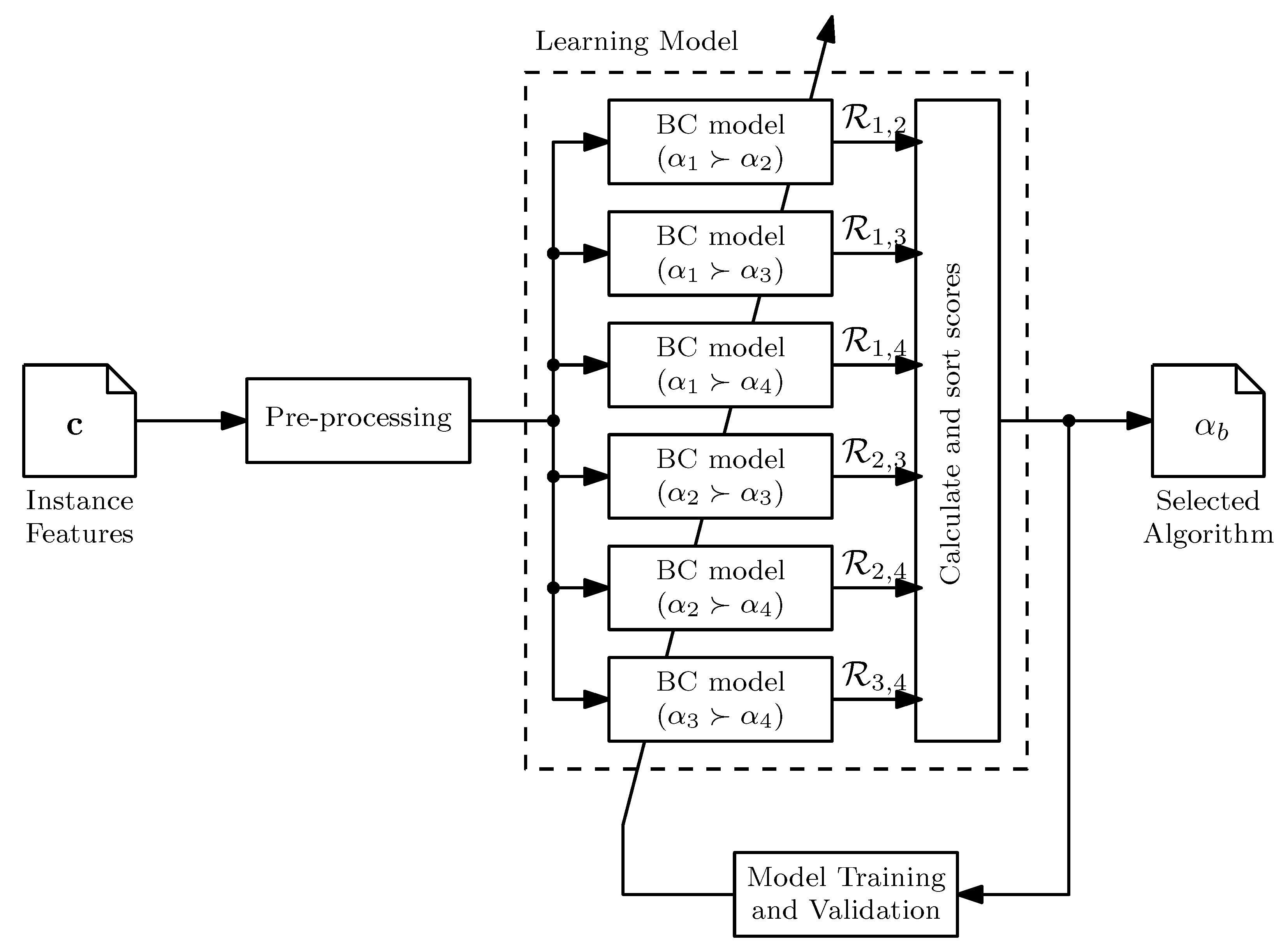
- Algorithm selection is a procedure to find the best algorithm using . Its main component is the learning model [28], as illustrated in Figure 2. The learning model maps the characteristics to the performance of a subset of complementary or well-established algorithms, , also known as algorithm portfolio. A method known as pre-selector constructs . The learning model is trained using experimental data contained in the knowledge base [32]. To predict the best performing algorithm for a new problem, it is necessary to estimate and evaluate the model.
3. Methods
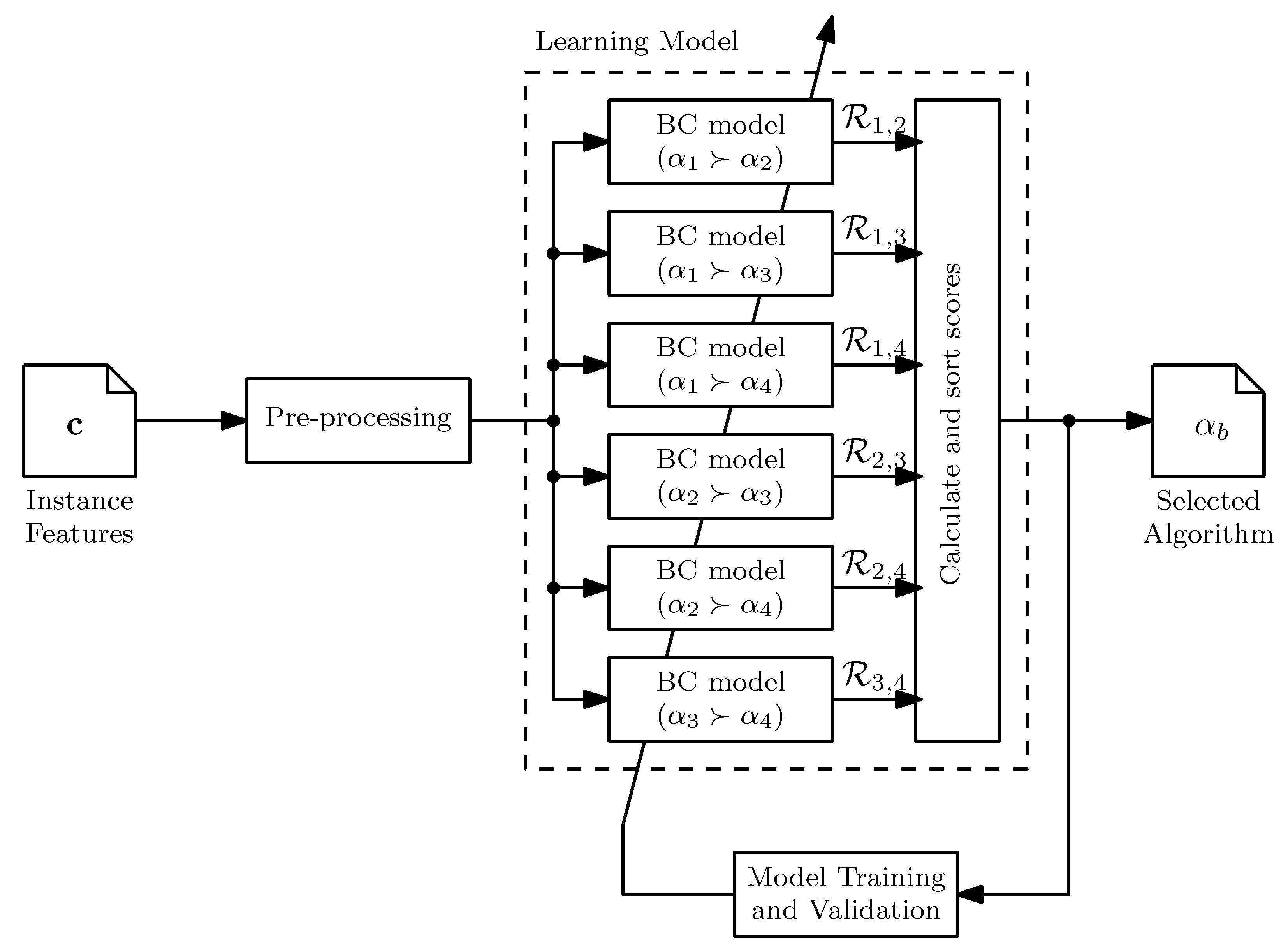
3.1. Learning Model
3.2. Exploratory Landscape Analysis Features
3.3. Algorithm Performance Measure
4. Selector Implementation
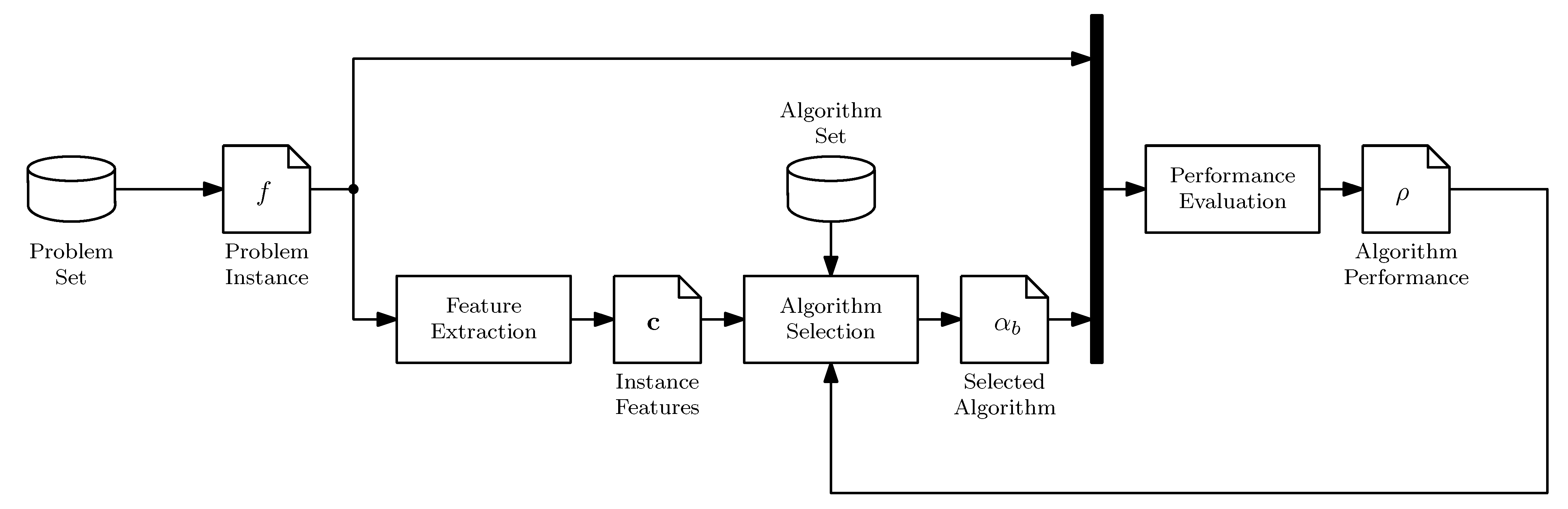
5. Selector Validation
- Q1
- Does the selector’s accuracy increases with the size of the sample used to calculate the ELA features?
- Q2
- What is the effect of the sample randomness on the selector performance?
6. Results
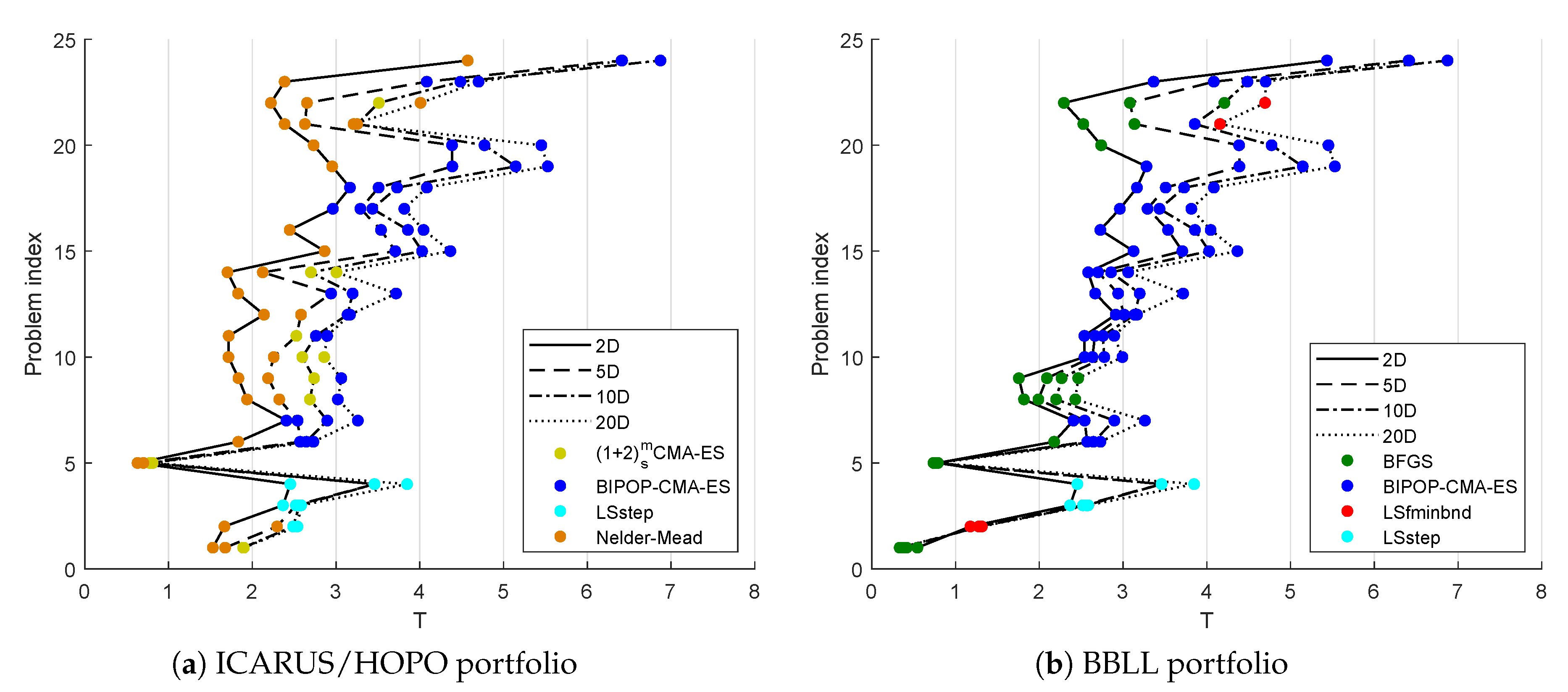
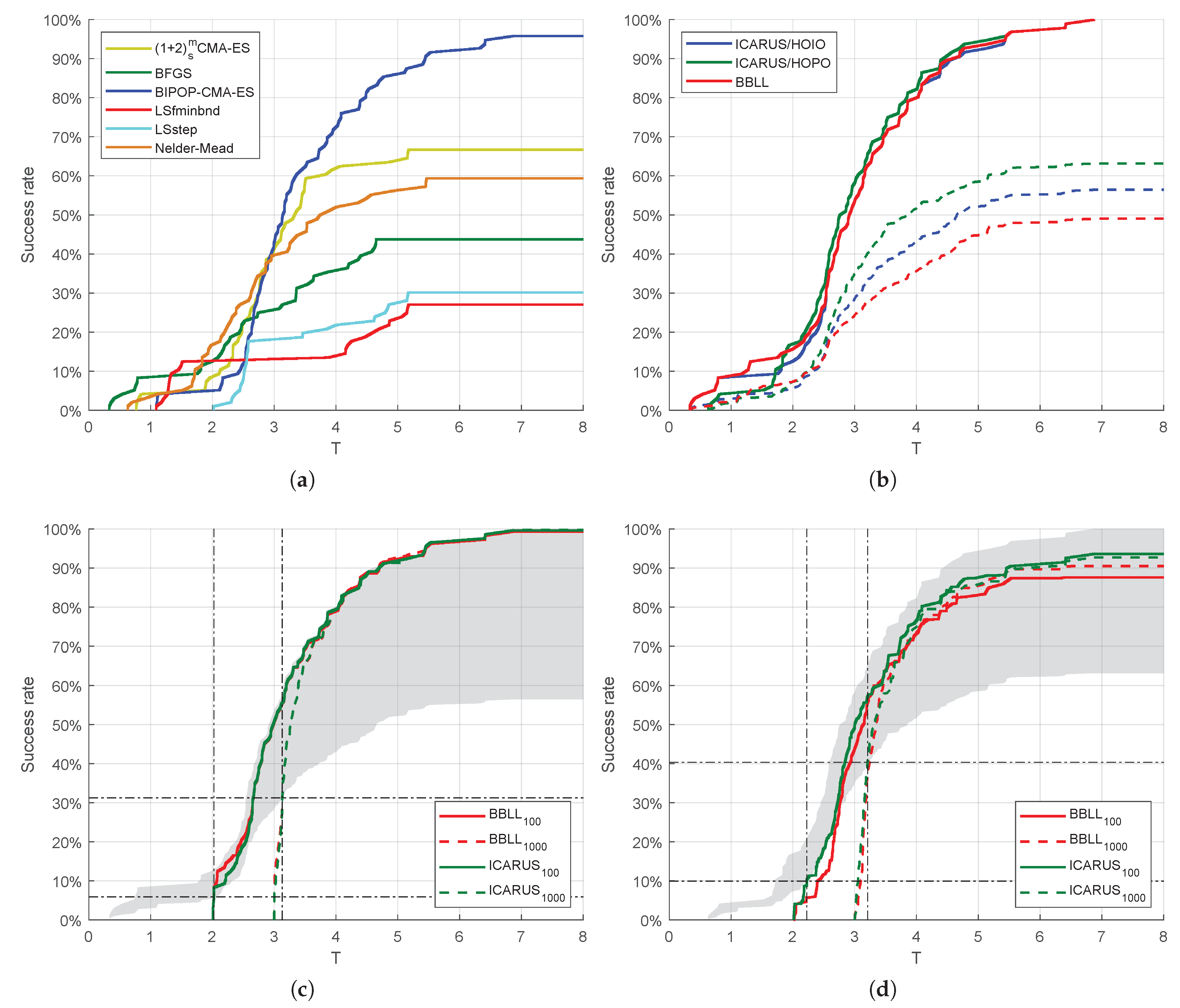
6.1. Performance of the Selector
6.2. Sampling Effects on Selection
7. Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lozano, M.; Molina, D.; Herrera, F. Editorial scalability of evolutionary algorithms and other metaheuristics for large-scale continuous optimization problems. Soft Comput. 2011, 15, 2085–2087. [Google Scholar] [CrossRef]
- Bischl, B.; Mersmann, O.; Trautmann, H.; Preuß, M. Algorithm selection based on exploratory landscape analysis and cost-sensitive learning. In Proceedings of the 14th Annual Conference on Genetic and Evolutionary Computation (GECCO’12), Philadelphia, PA, USA, 7–11 July 2012; pp. 313–320. [Google Scholar] [CrossRef]
- Muñoz, M.; Kirley, M.; Halgamuge, S. A Meta-Learning Prediction Model of Algorithm Performance for Continuous Optimization Problems. In Proceedings of the International Conference on Parallel Problem Solving from Nature, PPSN XII, Taormina, Italy, 1–5 September 2012; Volume 7941, pp. 226–235. [Google Scholar] [CrossRef]
- Abell, T.; Malitsky, Y.; Tierney, K. Features for Exploiting Black-Box Optimization Problem Structure. In LION 2013: Learning and Intelligent Optimization; LNCS; Springer: Berlin/Heidelberg, Germany, 2013; Volume 7997, pp. 30–36. [Google Scholar]
- Belkhir, N.; Dréo, J.; Savéant, P.; Schoenauer, M. Feature Based Algorithm Configuration: A Case Study with Differential Evolution. In Parallel Problem Solving from Nature—PPSN XIV; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 156–166. [Google Scholar] [CrossRef] [Green Version]
- Belkhir, N.; Dréo, J.; Savéant, P.; Schoenauer, M. Per instance algorithm configuration of CMA-ES with limited budget. In Proceedings of the Genetic and Evolutionary Computation Conference, Berlin, Germany, 15–19 July 2017. [Google Scholar] [CrossRef] [Green Version]
- Kerschke, P.; Trautmann, H. Automated Algorithm Selection on Continuous Black-Box Problems by Combining Exploratory Landscape Analysis and Machine Learning. Evol. Comput. 2019, 27, 99–127. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mersmann, O.; Bischl, B.; Trautmann, H.; Preuß, M.; Weihs, C.; Rudolph, G. Exploratory landscape analysis. In Proceedings of the 13th Annual Conference on Genetic and Evolutionary Computation, (GECCO’11), Dublin, Ireland, 12–16 July 2011; pp. 829–836. [Google Scholar] [CrossRef]
- Jansen, T. On Classifications of Fitness Functions; Technical Report CI-76/99; University of Dortmund: Dortmund, Germany, 1999. [Google Scholar]
- Müller, C.; Sbalzarini, I. Global Characterization of the CEC 2005 Fitness Landscapes Using Fitness-Distance Analysis. In Applications of Evolutionary Computation; LNCS; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6624, pp. 294–303. [Google Scholar] [CrossRef] [Green Version]
- Tomassini, M.; Vanneschi, L.; Collard, P.; Clergue, M. A Study of Fitness Distance Correlation as a Difficulty Measure in Genetic Programming. Evol. Comput. 2005, 13, 213–239. [Google Scholar] [CrossRef]
- Saleem, S.; Gallagher, M.; Wood, I. Direct Feature Evaluation in Black-Box Optimization Using Problem Transformations. Evol. Comput. 2019, 27, 75–98. [Google Scholar] [CrossRef] [PubMed]
- Škvorc, U.; Eftimov, T.; Korošec, P. Understanding the problem space in single-objective numerical optimization using exploratory landscape analysis. Appl. Soft Comput. 2020, 90, 106138. [Google Scholar] [CrossRef]
- Muñoz, M.; Kirley, M.; Smith-Miles, K. Analyzing randomness effects on the reliability of Landscape Analysis. Nat. Comput. 2020. [Google Scholar] [CrossRef]
- Kerschke, P.; Preuß, M.; Wessing, S.; Trautmann, H. Low-Budget Exploratory Landscape Analysis on Multiple Peaks Models. In Proceedings of the Genetic and Evolutionary Computation Conference (GECCO ’16), Denver, CO, USA, 20–24 July 2016; ACM: New York, NY, USA, 2016; pp. 229–236. [Google Scholar] [CrossRef]
- Muñoz, M.; Smith-Miles, K. Effects of function translation and dimensionality reduction on landscape analysis. In Proceedings of the 2015 IEEE Congress on Evolutionary Computation (CEC) (IEEE CEC’15), Sendai, Japan, 25–28 May 2015; pp. 1336–1342. [Google Scholar] [CrossRef]
- Renau, Q.; Dreo, J.; Doerr, C.; Doerr, B. Expressiveness and robustness of landscape features. In Proceedings of the Genetic and Evolutionary Computation Conference Companion, GECCO’19, Prague, Czech Republic, 13–17 July 2019; ACM Press: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Renau, Q.; Doerr, C.; Dreo, J.; Doerr, B. Exploratory Landscape Analysis is Strongly Sensitive to the Sampling Strategy. In Parallel Problem Solving from Nature—PPSN XVI; Bäck, T., Preuss, M., Deutz, A., Wang, H., Doerr, C., Emmerich, M., Trautmann, H., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 139–153. [Google Scholar]
- Muñoz, M. LEOPARD: LEarning and OPtimization Archive of Research Data. Version 1.0. 2020. Available online: https://doi.org/10.6084/m9.figshare.c.5106758 (accessed on 8 November 2020).
- Rice, J. The Algorithm Selection Problem. In Advances in Computers; Elsevier: Amsterdam, The Netherlands, 1976; Volume 15, pp. 65–118. [Google Scholar] [CrossRef] [Green Version]
- Reeves, C. Fitness Landscapes. In Search Methodologies; Springer: Berlin/Heidelberg, Germany, 2005; pp. 587–610. [Google Scholar] [CrossRef]
- Pitzer, E.; Affenzeller, M. A Comprehensive Survey on Fitness Landscape Analysis. In Recent Advances in Intelligent Engineering Systems; SCI; Springer: Berlin/Heidelberg, Germany, 2012; Volume 378, pp. 161–191. [Google Scholar] [CrossRef]
- Weise, T.; Zapf, M.; Chiong, R.; Nebro, A. Why Is Optimization Difficult. In Nature-Inspired Algorithms for Optimisation; SCI; Springer: Berlin/Heidelberg, Germany, 2009; Volume 193, pp. 1–50. [Google Scholar] [CrossRef]
- Mersmann, O.; Preuß, M.; Trautmann, H. Benchmarking Evolutionary Algorithms: Towards Exploratory Landscape Analysis. In PPSN XI; LNCS; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6238, pp. 73–82. [Google Scholar] [CrossRef] [Green Version]
- García-Martínez, C.; Rodriguez, F.; Lozano, M. Arbitrary function optimisation with metaheuristics. Soft Comput. 2012, 16, 2115–2133. [Google Scholar] [CrossRef]
- Hutter, F.; Hamadi, Y.; Hoos, H.; Leyton-Brown, K. Performance prediction and automated tuning of randomized and parametric algorithms. In CP ’06: Principles and Practice of Constraint Programming—CP 2006; LNCS; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4204, pp. 213–228. [Google Scholar] [CrossRef] [Green Version]
- Wolpert, D.; Macready, W. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef] [Green Version]
- Smith-Miles, K. Cross-disciplinary perspectives on meta-learning for algorithm selection. ACM Comput. Surv. 2009, 41, 6:1–6:25. [Google Scholar] [CrossRef]
- Graff, M.; Poli, R. Practical performance models of algorithms in evolutionary program induction and other domains. Artif. Intell. 2010, 174, 1254–1276. [Google Scholar] [CrossRef]
- Hutter, F.; Xu, L.; Hoos, H.; Leyton-Brown, K. Algorithm runtime prediction: Methods & evaluation. Artif. Intell. 2014, 206, 79–111. [Google Scholar] [CrossRef]
- Smith-Miles, K.; Baatar, D.; Wreford, B.; Lewis, R. Towards objective measures of algorithm performance across instance space. Comput. Oper. Res. 2014, 45, 12–24. [Google Scholar] [CrossRef]
- Hilario, M.; Kalousis, A.; Nguyen, P.; Woznica, A. A data mining ontology for algorithm selection and meta-mining. In Proceedings of the Second Workshop on Third Generation Data Mining: Towards Service-Oriented Knowledge Discovery (SoKD’09), Bled, Slovenia, 7 September 2009; pp. 76–87. [Google Scholar]
- Hansen, N.; Auger, A.; Finck, S.; Ros, R. Real-Parameter Black-Box Optimization Benchmarking BBOB-2010: Experimental Setup; Technical Report RR-7215; INRIA Saclay-Île-de-France: Paris, France, 2014. [Google Scholar]
- Hüllermeier, E.; Fürnkranz, J.; Cheng, W.; Brinker, K. Label ranking by learning pairwise differences. Artif. Intell. 2008, 172, 1897–1916. [Google Scholar] [CrossRef] [Green Version]
- Bischl, B.; Kerschke, P.; Kotthoff, L.; Lindauer, M.; Malitsky, Y.; Fréchette, A.; Hoos, H.; Hutter, F.; Leyton-Brown, K.; Tierney, K.; et al. ASlib: A benchmark library for algorithm selection. Artif. Intell. 2016, 237, 41–58. [Google Scholar] [CrossRef] [Green Version]
- Seo, D.; Moon, B. An Information-Theoretic Analysis on the Interactions of Variables in Combinatorial Optimization Problems. Evol. Comput. 2007, 15, 169–198. [Google Scholar] [CrossRef]
- Stowell, D.; Plumbley, M. Fast Multidimensional Entropy Estimation by k-d Partitioning. IEEE Signal Process. Lett. 2009, 16, 537–540. [Google Scholar] [CrossRef]
- Marin, J. How landscape ruggedness influences the performance of real-coded algorithms: A comparative study. Soft Comput. 2012, 16, 683–698. [Google Scholar] [CrossRef]
- Jones, T.; Forrest, S. Fitness Distance Correlation as a Measure of Problem Difficulty for Genetic Algorithms. In Proceedings of the Sixth International Conference on Genetic Algorithms, Pittsburgh, PA, USA, 15–19 July 1995; Morgan Kaufmann Publishers Inc.: Burlington, MA, USA, 1995; pp. 184–192. [Google Scholar]
- Morgan, R.; Gallagher, M. Length Scale for Characterising Continuous Optimization Problems. In PPSN XII; LNCS; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7941, pp. 407–416. [Google Scholar]
- Muñoz, M.; Kirley, M. ICARUS: Identification of Complementary algoRithms by Uncovered Sets. In Proceedings of the 2016 IEEE Congress on Evolutionary Computation (CEC) (IEEE CEC’16), Vancouver, BC, Canada, 24–29 July 2016; pp. 2427–2432. [Google Scholar] [CrossRef]
- Auger, A.; Brockhoff, D.; Hansen, N. Comparing the (1+1)-CMA-ES with a Mirrored (1+2)-CMA-ES with Sequential Selection on the Noiseless BBOB-2010 Testbed. In Proceedings of the 12th Annual Conference Companion on Genetic and Evolutionary Computation (GECCO’10), Portland, OR, USA, 7–11 July 2010; Association for Computing Machinery: New York, NY, USA, 2010; pp. 1543–1550. [Google Scholar] [CrossRef] [Green Version]
- Ros, R. Benchmarking the BFGS Algorithm on the BBOB-2009 Function Testbed. In GECCO’09: Proceedings of the 11th Annual Conference Companion on Genetic and Evolutionary Computation Conference: Late Breaking Papers; ACM: New York, NY, USA, 2009; pp. 2409–2414. [Google Scholar] [CrossRef] [Green Version]
- Hansen, N. Benchmarking a bi-population CMA-ES on the BBOB-2009 Function Testbed. In GECCO’09: Proceedings of the 11th Annual Conference Companion on Genetic and Evolutionary Computation Conference: Late Breaking Papers; ACM: New York, NY, USA, 2009; pp. 2389–2396. [Google Scholar] [CrossRef] [Green Version]
- Pošík, P.; Huyer, W. Restarted Local Search Algorithms for Continuous Black Box Optimization. Evol. Comput. 2012, 20, 575–607. [Google Scholar] [CrossRef] [Green Version]
- Doerr, B.; Fouz, M.; Schmidt, M.; Wahlstrom, M. BBOB: Nelder-Mead with Resize and Halfruns. In GECCO’09: Proceedings of the 11th Annual Conference Companion on Genetic and Evolutionary Computation Conference: Late Breaking Papers; ACM: New York, NY, USA, 2009; pp. 2239–2246. [Google Scholar] [CrossRef]
- Belkhir, N.; Dréo, J.; Savéant, P.; Schoenauer, M. Surrogate Assisted Feature Computation for Continuous Problems. In LION 2016: Learning and Intelligent Optimization; Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 17–31. [Google Scholar] [CrossRef] [Green Version]
- Xu, L.; Hutter, F.; Hoos, H.; Leyton-Brown, K. SATzilla: Portfolio-based algorithm selection for SAT. J. Artif. Intell. Res. 2008, 32, 565–606. [Google Scholar] [CrossRef] [Green Version]
- Efron, B.; Tibshirani, R. An Introduction to the Bootstrap; Chapman & Hall: London, UK, 1993. [Google Scholar]
- Efron, B. Nonparametric Standard Errors and Confidence Intervals. Can. J. Stat./ Rev. Can. Stat. 1981, 9, 139–158. [Google Scholar] [CrossRef]
- Gomes, C.; Selman, B.; Crato, N.; Kautz, H. Heavy-Tailed Phenomena in Satisfiability and Constraint Satisfaction Problems. J. Autom. Reason. 2000, 24, 67–100. [Google Scholar] [CrossRef]
- Smith-Miles, K.; van Hemert, J. Discovering the suitability of optimisation algorithms by learning from evolved instances. Ann. Math. Artif. Intel. 2011, 61, 87–104. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Feature | Description | Scaling |
|---|---|---|---|
| D | Dimensionality of the problem | ||
| Surrogate models | Adjusted coefficient of determination of a linear regression model including variable interactions | Unit scaling | |
| Adjusted coefficient of determination of a purely quadratic regression model | Unit scaling | ||
| Ratio between the minimum and the maximum absolute values of the quadratic term coefficients in the purely quadratic model | Unit scaling | ||
| Significance | Significance of D-th order | z-score, tanh | |
| Significance of first order | z-score, tanh | ||
| Cost distribution | Skewness of the cost distribution | z-score, tanh | |
| Kurtosis of the cost distribution | , z-score | ||
| Entropy of the cost distribution | , z-score |
| Algorithm | Description | Reference |
|---|---|---|
| CMA-ES | A simple CMA-ES variant, with one parent and two offspring, sequential selection, mirroring and random restarts. All other parameters are set to the defaults. | [42] |
| BFGS | The MATLAB implementation (fminunc) of this quasi-Newton method, which is randomly restarted whenever a numerical error occurs. The Hessian matrix is iteratively approximated using forward finite differences, with a step size equal to the square root of the machine precision. Other than the default parameters, the function and step tolerances were set to and 0, respectively. | [43] |
| BIPOP-CMA-ES | A multistart CMA-ES variant with equal budgets for two interlaced restart strategies. After completing a first run with a population of size , the first strategy doubles the population size; while the second one keeps a small population given by , where is the latest population size from the first strategy, , and is an independent uniformly distributed random number. Therefore, . All other parameters are at default values. | [44] |
| LSfminbnd | The MATLAB implementation (fminbnd) of this axis parallel line search method, which is based on the golden section search and parabolic interpolation. It can identify the optimum of quadratic functions in a few steps. On the other hand, it is a local search technique; it can miss the global optimum (of the 1D function). | [45] |
| LSstep | An axis parallel line search method effective only on separable functions. To find a new solution, it optimizes over each variable independently, keeping every other variable fixed. The STEP version of this method uses interval division, i.e., it starts from an interval corresponding to the upper and lower bounds of a variable, which is divided by half at each iteration. The next sampled interval is based on its “difficulty,” i.e., by its belief of how hard it would be to improve the best-so-far solution by sampling from the respective interval. The measure of difficulty is the coefficient a from a quadratic function , which must go through the both interval boundary points. | [45] |
| Nelder–Mead | A version of the Nelder–Mead algorithm that uses random restarts, resizing and half-runs. In a resizing step, the current simplex is replaced by a “fat” simplex, which maintains the best vertex, but relocates the remaining ones such that they have the same average distance to the center of the simplex. Such steps are performed every 1000 algorithm iterations. In a half-run, the algorithm is stopped after interations, with only the most promising half-runs being allowed to continue. | [46] |
| CI | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| CMA-ES | 2.852 | 66.7% | 1.511 | ||||||
| BFGS | 2.633 | 43.8% | 1.074 | ||||||
| BIPOP-CMA-ES | 3.397 | 95.8% | 1.823 | ||||||
| LSfminbnd | 3.092 | 27.1% | 0.566 | ||||||
| LSstep | 3.306 | 30.2% | 0.591 | ||||||
| Nelder–Mead | 2.765 | 59.4% | 1.388 | ||||||
| ICARUS | HOIO | 100 | 3.287 | 99.7% | 98.6% | 0.5% | 0.3% | 1.960 | |
| 178 | 3.341 | 99.6% | 98.9% | 0.3% | 0.3% | 1.926 | |||
| 316 | 3.417 | 99.7% | 98.9% | 0.4% | 0.2% | 1.885 | |||
| 562 | 3.509 | 99.8% | 99.1% | 0.3% | 0.2% | 1.837 | |||
| 1000 | 3.622 | 99.7% | 99.1% | 0.4% | 0.3% | 1.779 | |||
| ORACLE | 3.092 | 100.0% | 100.0% | 0.0% | 0.0% | 2.090 | |||
| RAND | 3.178 | 56.5% | 33.3% | 33.3% | 18.5% | 1.148 | |||
| HOPO | 100 | 3.269 | 93.6% | 60.6% | 4.2% | 2.0% | 1.851 | ||
| 178 | 3.293 | 92.5% | 55.9% | 4.3% | 0.7% | 1.814 | |||
| 316 | 3.371 | 93.8% | 61.1% | 4.7% | 1.9% | 1.798 | |||
| 562 | 3.510 | 95.4% | 60.9% | 5.9% | 1.3% | 1.756 | |||
| 1000 | 3.618 | 92.7% | 57.4% | 8.1% | 2.3% | 1.656 | |||
| ORACLE | 3.025 | 100.0% | 100.0% | 0.0% | 0.0% | 2.136 | |||
| RAND | 3.093 | 63.2% | 25.9% | 26.2% | 15.6% | 1.320 | |||
| BBLL | HOIO | 100 | 3.264 | 99.4% | 98.3% | 0.7% | 0.5% | 1.968 | |
| 178 | 3.321 | 99.5% | 98.8% | 0.6% | 0.4% | 1.936 | |||
| 316 | 3.401 | 99.5% | 98.8% | 0.5% | 0.4% | 1.891 | |||
| 562 | 3.495 | 99.7% | 99.1% | 0.5% | 0.3% | 1.843 | |||
| 1000 | 3.611 | 99.7% | 99.0% | 0.5% | 0.3% | 1.784 | |||
| HOPO | 100 | 3.228 | 87.7% | 59.7% | 10.2% | 6.7% | 1.755 | ||
| 178 | 3.310 | 90.0% | 60.2% | 9.6% | 4.7% | 1.757 | |||
| 316 | 3.353 | 88.5% | 59.8% | 9.6% | 5.7% | 1.707 | |||
| 562 | 3.435 | 88.5% | 58.6% | 8.2% | 5.4% | 1.665 | |||
| 1000 | 3.571 | 90.5% | 61.2% | 10.5% | 4.6% | 1.638 | |||
| ORACLE | 3.040 | 100.0% | 100.0% | 0.0% | 0.0% | 2.126 | |||
| RAND | 3.170 | 49.1% | 25.0% | 25.0% | 14.3% | 1.000 | |||
| HOIO | HOPO | |||||||
|---|---|---|---|---|---|---|---|---|
| 100.0% | 63.0% | 9.2% | 0.0% | 100.0% | 45.5% | 15.0% | 0.0% | |
| 100.0% | 69.8% | 13.7% | 0.0% | 100.0% | 55.0% | 19.5% | 0.0% | |
| 99.8% | 91.0% | 0.2% | 0.2% | 100.0% | 86.6% | 0.1% | 0.1% | |
| 98.0% | 89.1% | 1.3% | 1.0% | 95.2% | 82.2% | 2.4% | 2.2% | |
| 100.0% | 75.5% | 11.1% | 0.0% | 100.0% | 67.1% | 18.4% | 0.0% | |
| 98.7% | 88.8% | 0.1% | 0.1% | 98.4% | 86.9% | 0.2% | 0.2% | |
| 98.7% | 95.2% | 0.4% | 0.4% | 98.3% | 92.8% | 0.9% | 0.9% | |
| 98.6% | 74.1% | 1.4% | 1.4% | 93.0% | 59.6% | 7.0% | 7.0% | |
| 100.0% | 74.9% | 0.0% | 0.0% | 100.0% | 66.2% | 0.0% | 0.0% | |
| 99.5% | 83.6% | 0.4% | 0.4% | 99.5% | 76.2% | 0.4% | 0.4% | |
| 99.0% | 83.8% | 0.8% | 0.8% | 99.2% | 76.8% | 0.8% | 0.8% | |
| 94.0% | 81.7% | 2.2% | 0.0% | 91.6% | 76.4% | 1.8% | 0.0% | |
| 97.1% | 93.9% | 1.7% | 1.7% | 95.3% | 90.5% | 2.8% | 2.8% | |
| 95.7% | 79.9% | 4.3% | 4.3% | 93.5% | 70.7% | 6.5% | 6.5% | |
| 99.7% | 94.3% | 1.0% | 0.0% | 99.0% | 92.8% | 1.2% | 0.2% | |
| 99.1% | 94.9% | 0.6% | 0.6% | 99.2% | 95.4% | 0.5% | 0.5% | |
| 91.8% | 86.9% | 1.9% | 1.9% | 90.2% | 83.1% | 1.5% | 1.5% | |
| 97.3% | 92.7% | 2.5% | 2.5% | 97.0% | 91.1% | 2.8% | 2.8% | |
| 99.7% | 96.5% | 0.3% | 0.3% | 95.6% | 91.3% | 2.5% | 2.5% | |
| 90.0% | 81.9% | 3.2% | 0.0% | 85.5% | 74.5% | 3.2% | 0.0% | |
| 100.0% | 67.9% | 0.0% | 0.0% | 100.0% | 50.3% | 0.0% | 0.0% | |
| 100.0% | 75.7% | 0.0% | 0.0% | 100.0% | 67.8% | 0.0% | 0.0% | |
| 80.8% | 80.7% | 9.0% | 9.0% | 66.9% | 66.9% | 16.4% | 16.4% | |
| 76.2% | 71.8% | 9.1% | 9.1% | 71.5% | 68.0% | 13.9% | 13.9% | |
| 2 | 96.2% | 79.6% | 5.0% | 2.0% | 95.1% | 73.2% | 7.0% | 2.6% |
| 5 | 96.0% | 83.7% | 2.8% | 1.2% | 94.2% | 77.2% | 4.2% | 2.0% |
| 10 | 96.6% | 82.0% | 3.3% | 1.4% | 95.1% | 74.4% | 4.6% | 2.5% |
| 20 | 96.8% | 86.0% | 1.3% | 1.0% | 93.8% | 77.4% | 3.8% | 2.7% |
| ICARUS | HOIO | 100 | |||||
| 178 | |||||||
| 316 | |||||||
| 562 | |||||||
| 1000 | |||||||
| HOPO | 100 | ||||||
| 178 | |||||||
| 316 | |||||||
| 562 | |||||||
| 1000 | |||||||
| BBLL | HOIO | 100 | |||||
| 178 | |||||||
| 316 | |||||||
| 562 | |||||||
| 1000 | |||||||
| HOPO | 100 | ||||||
| 178 | |||||||
| 316 | |||||||
| 562 | |||||||
| 1000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Muñoz, M.A.; Kirley, M. Sampling Effects on Algorithm Selection for Continuous Black-Box Optimization. Algorithms 2021, 14, 19. https://doi.org/10.3390/a14010019
Muñoz MA, Kirley M. Sampling Effects on Algorithm Selection for Continuous Black-Box Optimization. Algorithms. 2021; 14(1):19. https://doi.org/10.3390/a14010019
Chicago/Turabian StyleMuñoz, Mario Andrés, and Michael Kirley. 2021. "Sampling Effects on Algorithm Selection for Continuous Black-Box Optimization" Algorithms 14, no. 1: 19. https://doi.org/10.3390/a14010019
APA StyleMuñoz, M. A., & Kirley, M. (2021). Sampling Effects on Algorithm Selection for Continuous Black-Box Optimization. Algorithms, 14(1), 19. https://doi.org/10.3390/a14010019