
Research on Building Target Detection Based on High-Resolution Optical Remote Sensing Imagery

Abstract
:
1. Introduction
2. Data and Methodology
2.1. Data
2.2. Methodology
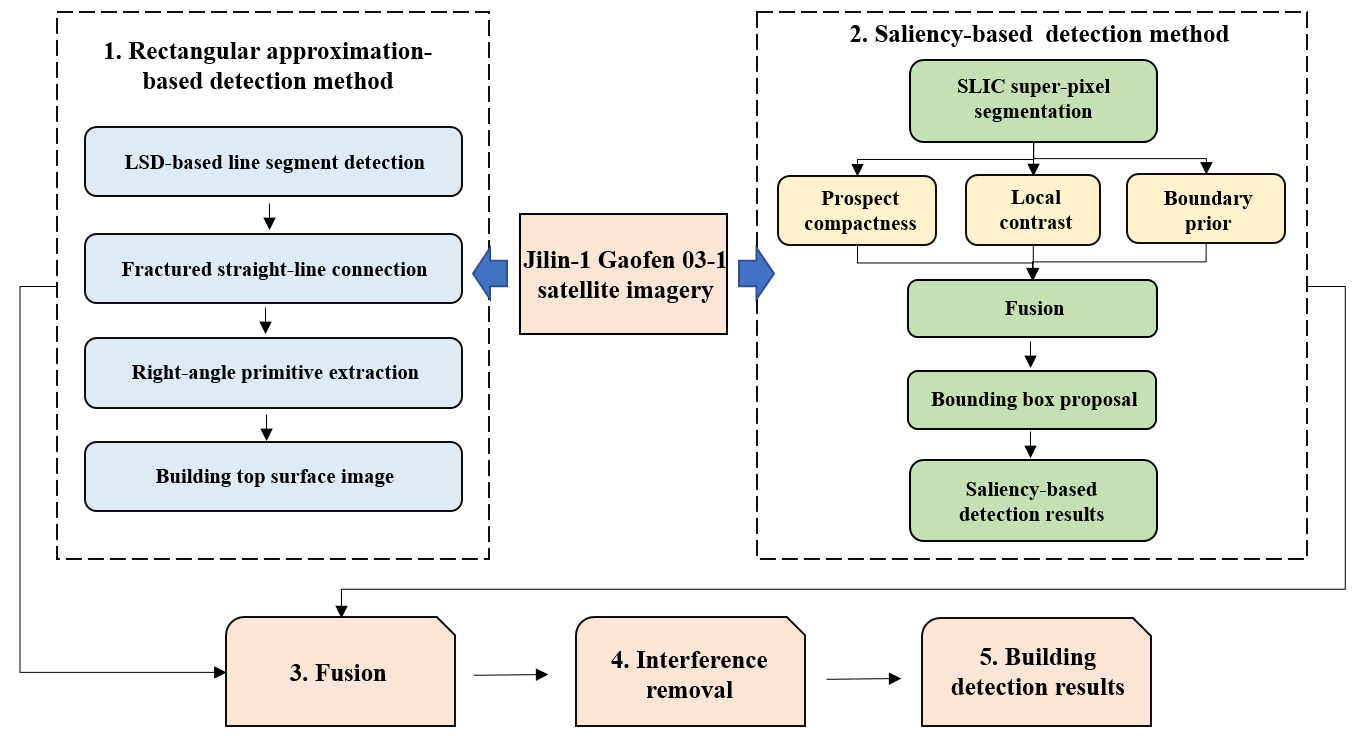
2.2.1. Building Detection Based on Rectangular Approximation and Region Growth
2.2.2. Diffusion-Based Saliency Model
2.2.3. Pixel-Level Fusion and Interference Removal
2.2.4. Evaluation
3. Result
3.1. Analysis of Building Detection Results Based on Shape Features
3.2. Results of the Diffusion-Based Saliency Model
- (1)
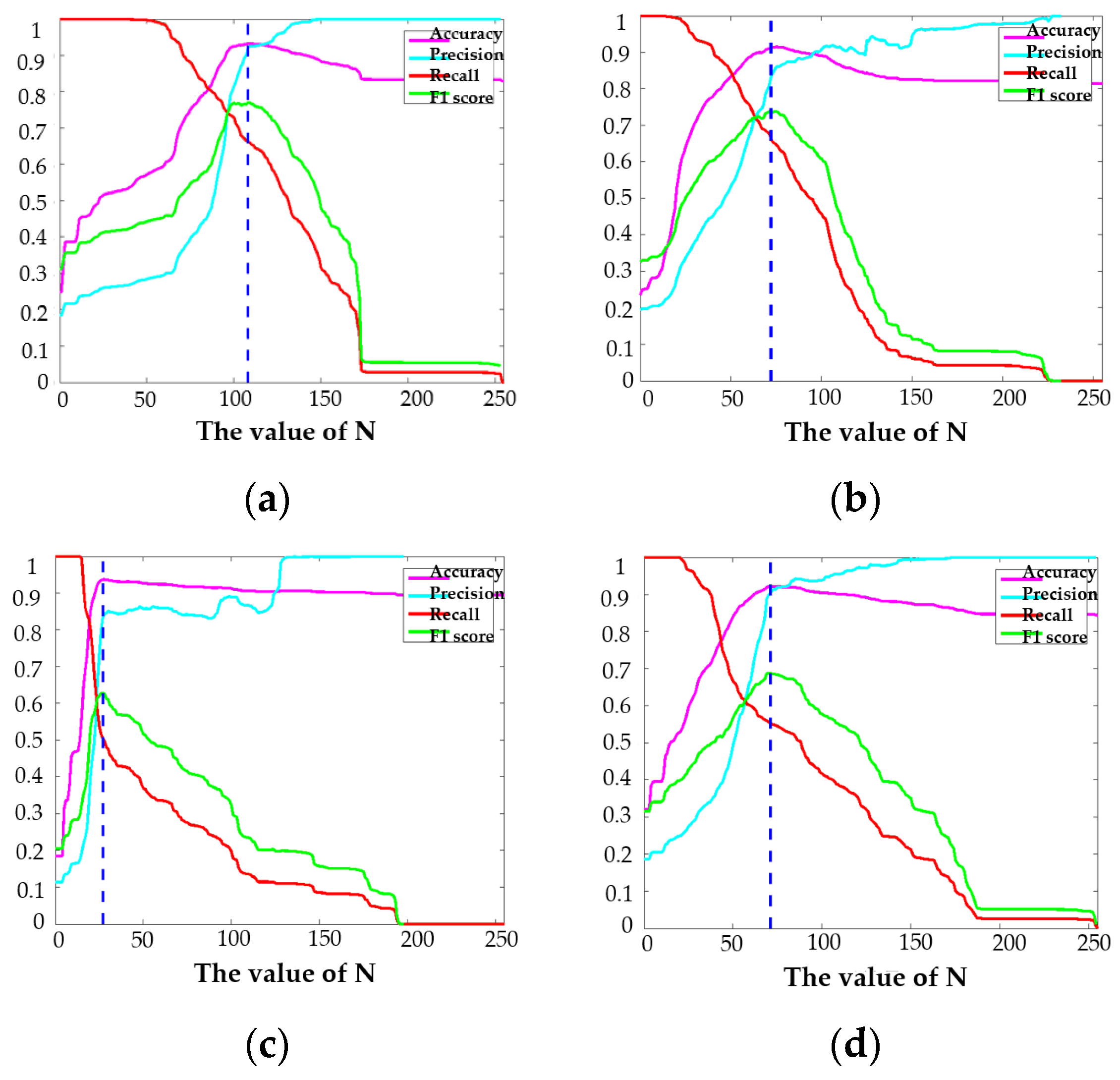
- The number of super-pixel nodes N used in the SLIC model: The SLIC model abstracts the input image into uniform and compact regions. If N is too small, different objects will be mapped to the same super-pixel, which will lead to a decrease in the accuracy of saliency object detection. If N is too large, saliency objects will be mapped to different super-pixels, which may incorrectly suppress saliency regions. The parameter N = 100 is set in the experiment based on compactness and local contrast saliency detection method. The improved saliency detection method with manifold ranking and boundary prior sets the parameter , where W and H are the width and height of the experimental image;
- (2)
- for controlling the decay rate of the exponential function: The highest accuracy was achieved when in the experiment;
- (3)
- The equilibrium parameters of the manifold ranking algorithm: The parameters of the literature “Ranking on Data Manifolds” [17] are set with and ;
- (4)
- After experimental verification, the fusion parameters are chosen as follows: , , for the best detection of the saliency map.
3.3. Fusion and Analysis of Detection Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Full Name |
|---|---|
| SIFT | Scale Invariant Feature Transform |
| VHR | Very High Spatial Resolution |
| CNN | Convolutional Neural Network |
| SVM | Support Vector Machine |
| LSD | Line Segment Detector |
| SLIC | Simple Linear Iterative Clustering |
| TP | True Positive |
| FP | False Positive |
| FN | False Negative |
References
- Ghanea, M.; Moallem, P.; Momeni, M. Building extraction from high-resolution satellite images in urban areas: Recent methods and strategies against significant challenges. Int. J. Remote Sens. 2016, 37, 5234–5248. [Google Scholar] [CrossRef]
- Grinias, I.; Panagiotakis, C.; Tziritas, G. MRF-based segmentation and unsupervised classification for building and road detection in peri-urban areas of high-resolution satellite images. ISPRS J. Photogramm. Remote Sens. 2016, 122, 145–166. [Google Scholar] [CrossRef]
- Chen, R.; Li, X.; Li, J. Object-based features for house detection from RGB high-resolution images. Remote Sens. 2018, 10, 451. [Google Scholar] [CrossRef] [Green Version]
- Hui, J.; Du, M.; Ye, X.; Qin, Q.; Sui, J. Effective building extraction from high-resolution remote sensing images with multitask driven deep neural network. IEEE Geosci. Remote Sens. Lett. 2018, 16, 786–790. [Google Scholar] [CrossRef]
- Jing, W.; Xu, Z.; Ying, L. Texture-based segmentation for extracting image shape features. In Proceedings of the 2013 19th International Conference on Automation and Computing (ICAC), London, UK, 13–14 September 2013. [Google Scholar]
- Liu, Z.; Li, H.; Zhou, W.; Rui, T.; Tian, Q. Making residual vector distribution uniform for distinctive image representation. IEEE Trans. Circuits Syst. Video Technol. 2016, 26, 375–384. [Google Scholar] [CrossRef]
- Mi, W.; Yuan, S.; Pan, J. Building detection in high resolution satellite urban image using segmentation corner detection combined with adaptive windowed hough transform. In Proceedings of the 2013 IEEE International Symposium on Geoscience and Remote Sensing (IGARSS), Melbourne, Australia, 21–26 July 2013; pp. 508–511. [Google Scholar]
- Zhang, L.; Zhong, B.; Yang, A. Building change detection using object-oriented LBP feature map in very high spatial resolution imagery. In Proceedings of the 10th International Workshop on the Analysis of Multitemporal Remote Sensing Images (MultiTemp), Shanghai, China, 1 August 2019; pp. 1–4. [Google Scholar]
- Vakalopoulou, M.; Karantzalos, K.; Komodakis, N.; Paragios, N. Building detection in very high resolution multispectral data with deep learning features. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 1873–1876. [Google Scholar]
- Zhang, Q.; Wang, Y.; Liu, Q.; Liu, X.; Wang, W. CNN based suburban building detection using monocular high resolution Google Earth images. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 661–664. [Google Scholar]
- Liu, Y.; Zhang, Z.; Zhong, R.; Chen, D.; Ke, Y.; Peethambaran, J.; Chen, C.; Sun, L. Multilevel building detection framework in remote sensing images based on convolutional neural networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3688–3700. [Google Scholar] [CrossRef]
- Sidike, P.; Prince, D.; Essa, A. Automatic building change detection through adaptive local textural features and sequential background removal. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 2857–2860. [Google Scholar]
- Manandhar, P.; Aung, Z.; Marpu, P.R. Segmentation based building detection in high resolution satellite images. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 3783–3786. [Google Scholar]
- Von Gioi, R.G.; Jakubowicz, J.; Morel, J.-M.; Randall, G. LSD: A line segment detector. Image Process. Line 2012, 2, 35–55. [Google Scholar] [CrossRef] [Green Version]
- Cong, R.; Lei, J.; Zhang, C.; Huang, Q.; Cao, X.; Hou, C. Saliency detection for stereoscopic images based on depth confidence analysis and multiple cues fusion. IEEE Signal Process. Lett. 2016, 23, 819–824. [Google Scholar] [CrossRef] [Green Version]
- Jian, M.; Qi, Q.; Dong, J.; Yin, Y.; Lam, K.M. Integrating QDWD with pattern distinctness and local contrast for underwater saliency detection. J. Vis. Commun. Image Represent. 2018, 53, 31–41. [Google Scholar] [CrossRef]
- Yang, C.; Zhang, L.; Lu, H.; Ruan, X.; Yang, M.H. Saliency Detection via Graph-Based Manifold Ranking. Available online: https://openaccess.thecvf.com/content_cvpr_2013/papers/Yang_Saliency_Detection_via_2013_CVPR_paper.pdf (accessed on 14 October 2021).
- Zitnick, C.L.; Dollár, P. Edge boxes: Locating object proposals from edges. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 391–405. [Google Scholar]
- Huang, F.; Qi, J.; Lu, H.; Zhang, L.; Ruan, X. Salient object detection via multiple in-stance learning. IEEE Trans. Image Process. 2017, 26, 1911–1922. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Ma, X.; Zhang, J.; Wang, A.; Jin, Z. Salient object detection via deformed smoothness constraint. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 2815–2819. [Google Scholar]
- Otsu, N. A threshold selection method from gray-level histograms. Automatica 1975, 11, 23–27. [Google Scholar] [CrossRef] [Green Version]
- Yang, S.; Gu, L.; Li, X.; Jiang, T.; Ren, R. Crop classification method based on optimal feature selection and hybrid CNN-RF networks for multi-temporal remote sensing imagery. Remote Sens. 2020, 12, 3119. [Google Scholar] [CrossRef]
- Wang, Y.; Gu, L.; Li, X.; Ren, R. Building extraction in multitemporal high-resolution remote sensing imagery using a multifeature LSTM network. IEEE Geosci. Remote Sens. Lett. 2020, 18, 1645–1649. [Google Scholar] [CrossRef]
- Ghaderpour, E.; Pagiatakis, S.; Hassan, Q. A survey on change detection and time series analysis with applications. Appl. Sci. 2021, 11, 6141. [Google Scholar] [CrossRef]
- Wang, H.; Li, S.; Zhou, Y.; Chen, S. SAR automatic target recognition using a Roto-translational invariant wavelet-scattering convolution network. Remote Sens. 2018, 10, 501. [Google Scholar] [CrossRef] [Green Version]
- Aamir, M.; Pu, Y.-F.; Rahman, Z.; Tahir, M.; Naeem, H.; Dai, Q. A framework for automatic building detection from low-contrast satellite images. Symmetry 2018, 11, 3. [Google Scholar] [CrossRef] [Green Version]
















| Data/Resolution | Roll Satellite Angle | Pitch Satellite Angle | Yaw Satellite Angle |
|---|---|---|---|
| JL1GF03B01/1m | −25.60 | 1.29 | 2.98 |
| Image | Place/Time | Size | Space Occupied |
|---|---|---|---|
| Image I Image II Image III Image IV | Port/10 November 2020 | 700 × 700 (I) 700 × 700 (II) 800 × 800 (III) 700 × 700 (IV) | 407 KB (I) 483 KB (II) 509 KB (III) 422 KB (IV) |
| Accuracy | Precision | Recall | F1 | |
|---|---|---|---|---|
| Rectangular approximation-based | 0.9012 | 0.7419 | 0.6445 | 0.6898 |
| Saliency-based | 0.9328 | 0.9207 | 0.6627 | 0.7706 |
| Fusion | 0.9204 | 0.7456 | 0.8087 | 0.7759 |
| Interference removal | 0.9310 | 0.8131 | 0.7730 | 0.7925 |
| Accuracy | Precision | Recall | F1 | |
|---|---|---|---|---|
| Rectangular approximation-based | 0.8689 | 0.6429 | 0.6547 | 0.6487 |
| Saliency-based | 0.9134 | 0.8317 | 0.6663 | 0.7398 |
| Fusion | 0.8842 | 0.6445 | 0.8336 | 0.7270 |
| Interference removal | 0.8958 | 0.6807 | 0.8216 | 0.7445 |
| Accuracy | Precision | Recall | F1 | |
|---|---|---|---|---|
| Rectangular approximation-based | 0.9094 | 0.5515 | 0.7422 | 0.6329 |
| Saliency-based | 0.9373 | 0.8343 | 0.5045 | 0.6288 |
| Fusion | 0.9173 | 0.5700 | 0.8715 | 0.6892 |
| Interference removal | 0.9310 | 0.6277 | 0.8473 | 0.7212 |
| Accuracy | Precision | Recall | F1 | |
|---|---|---|---|---|
| Rectangular approximation-based | 0.9080 | 0.6970 | 0.7289 | 0.7126 |
| Saliency-based | 0.9211 | 0.9038 | 0.5550 | 0.6877 |
| Fusion | 0.9166 | 0.6965 | 0.8275 | 0.7564 |
| Interference removal | 0.9257 | 0.7430 | 0.8018 | 0.7712 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mei, Y.; Chen, H.; Yang, S. Research on Building Target Detection Based on High-Resolution Optical Remote Sensing Imagery. Algorithms 2021, 14, 300. https://doi.org/10.3390/a14100300
Mei Y, Chen H, Yang S. Research on Building Target Detection Based on High-Resolution Optical Remote Sensing Imagery. Algorithms. 2021; 14(10):300. https://doi.org/10.3390/a14100300
Chicago/Turabian StyleMei, Yong, Hao Chen, and Shuting Yang. 2021. "Research on Building Target Detection Based on High-Resolution Optical Remote Sensing Imagery" Algorithms 14, no. 10: 300. https://doi.org/10.3390/a14100300