
A Sequential Graph Neural Network for Short Text Classification

Abstract
:1. Introduction
- We propose an improved sequence-based feature propagation scheme. Each document in the corpus is trained as an individual graph, and the sequential features and local features of words in each document are learned, which contributes to the analysis of textual features.
- We propose new GNN-based models, SGNN and ESGNN, for short text classification, combining the Bi-LSTM network and simplified GCNs, which can better understand document semantics and generate more accurate text representation.
- We conduct extensive experiments on seven short text classification datasets with different sentence lengths, and the results show that our approach outperforms state-of-the-art text classification methods.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Sequential Information | Structural Information | Inductive Learning |
|---|---|---|---|
| Bi-LSTM | √ | √ | |
| TextGCN | √ | ||
| TensorGCN | √ | √ | |
| S-LSTM | √ | √ | |
| TextING | √ | √ | √ |
| Our Model | √ | √ | √ |
2. Methods
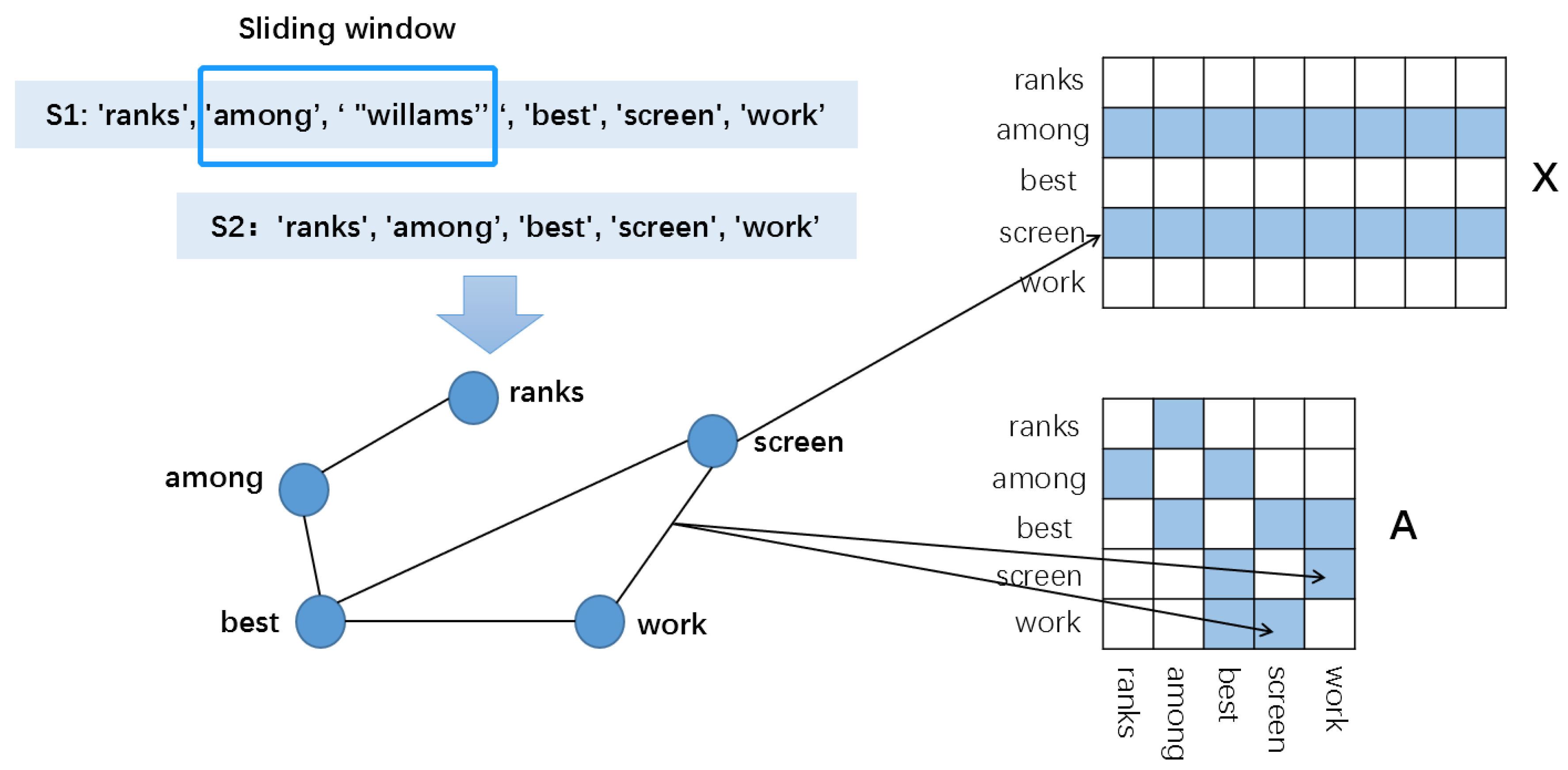
2.1. Graph Construction
2.2. SGNN Model and ESGNN Model
2.3. Document Classification
3. Materials and Experiments
3.1. Datasets
- R52 and R8 are two subsets of the Reuters 21,578 dataset (http://disi.unitn.it/moschitti/corpora.htm) (accessed on 30 November 2021). R8 has 8 categories, which were split to 5485 training and 2189 test documents. R52 has 52 categories, which were split to 6532 training and 2568 test documents.
- Ag News (http://www.di.unipi.it/~gulli/AG_corpus_of_news_articles.html) (accessed on 30 November 2021) is a news dataset from [48], which consists of the following four topics: World, Sports, Business and Sci/Tech. We randomly selected 4000 items from each category to form a dataset for the experiment. In our experiment we called it Ag News Sub.
- MR (https://github.com/mnqu/PTE/tree/master/data/mr) (accessed on 30 November 2021) is a movie review dataset for binary sentiment classification, where each review contains only one sentence [49]. The corpus has 5331 positive and 5331 negative reviews. We used the same training and test set division methods as [50].
- SearchSnippets (http://jwebpro.sourceforge.net/data-web-snippets.tar.gz) (accessed on 30 November 2021) dataset is released by [51], which contains 12,340 documents. It is composed of the search results which based on 8 different domains terms in search engines, including business, computer, health, education, etc.
- SMS (http://www.dt.fee.unicamp.br/~tiago/smsspamcollection/) (accessed on 30 November 2021) is a binary classification dataset collected for short message spam research, which contains 5574 pieces of English, real and unencrypted messages.
- Biomedical is built by [52] from an internationally renowned biomedical platform BioASQ (http://participants-area.bioasq.org/) (accessed on 30 November 2021) and contains 20,000 documents. It consists of 20 categories of titles of the papers that belong to the MeSH theme as the dataset.
3.2. Baselines
- TextCNN [28]: We implemented TextCNN, which uses pretrained word embedding and fine-tuning during the training process, and we set the kernals’ size with (3, 4, 5).
- Bi-LSTM [29]: a bidirectional LSTM that is commonly used in text classification. We input pretrained word embedding to Bi-LSTM.
- Fasttext [52]: A simple and efficient text classification method that takes the average of all word embedding as document representation and then feeds the document representation into a linear classifier. We evaluated it without bigrams.
- SWEM: A simple word embedding model proposed by [53], and in our experiment, we used SWEM-concat and obtained the final text representation through two fully connected layers.
- TextGCN: A graph-based text classification model proposed by [35], which builds a single large graph for the whole corpus and converts text classification into a node classification task based on GCN.
- TensorGCN: A graph-based text classification model in [40], which uses semantic and syntactic contextual information.
- HeteGCN [54]: A model unites the best aspects of predictive text embedding and TextGCN together.
- S-LSTM [37]: A model that treats each sentence or document as a graph and uses repeated steps to exchange local and global information between word nodes at the same time.
- TextING [41]: This model builds individual graphs for each document and uses a gated graph neural network to learn word interactions at the text level.
3.3. Experiment Settings
4. Results and Discussion
4.1. Test Performance
4.2. Combine with Bert
4.3. Parameter Sensitivity Analysis
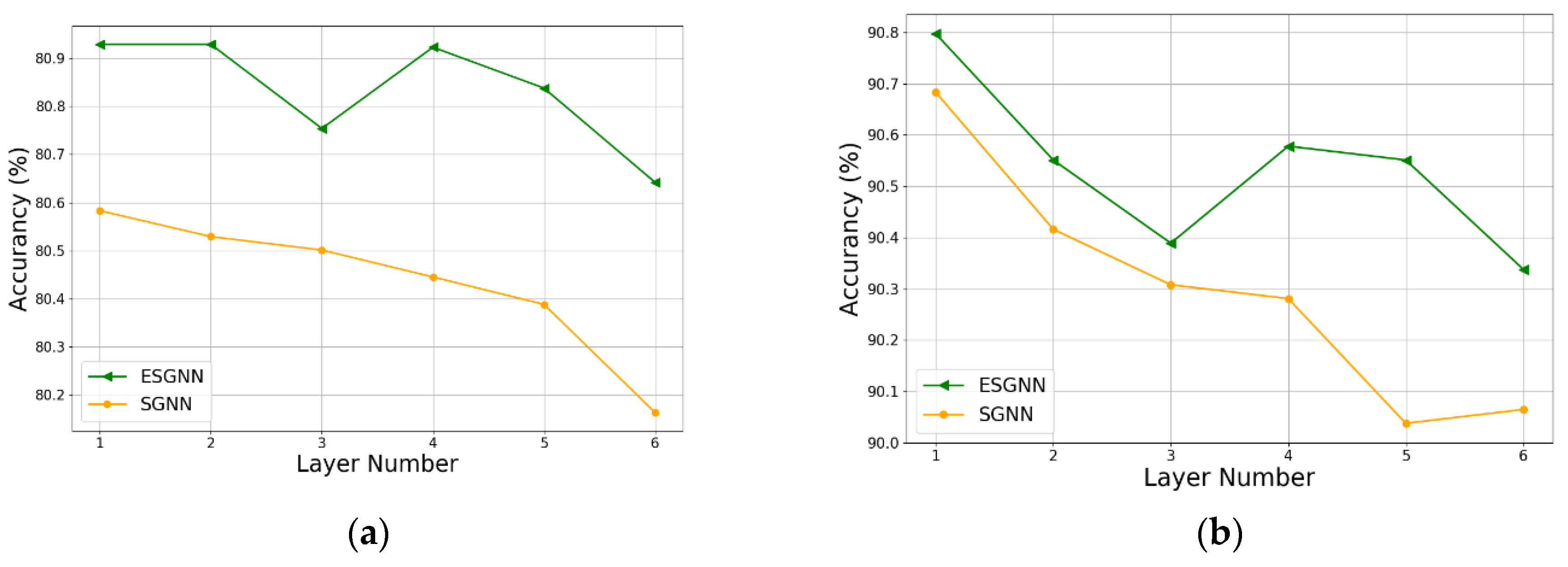
4.3.1. Graph Layers
4.3.2. Slide Window Sizes
4.3.3. Probability of
4.3.4. Proportions of Training Data
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Song, G.; Ye, Y.; Du, X.; Huang, X.; Bie, S. Short Text Classification: A Survey. J. Multimed. 2014, 9, 635–643. [Google Scholar] [CrossRef]
- Elnagar, A.; Al-Debsi, R.; Einea, O. Arabic text classification using deep learning models. Inf. Process. Manag. 2020, 57, 102121. [Google Scholar] [CrossRef]
- Tadesse, M.M.; Lin, H.; Xu, B.; Yang, L. Detection of suicide ideation in social media forums using deep learning. Algorithms 2020, 13, 7. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J.L. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Meng, Y.; Shen, J.; Zhang, C.; Han, J. Weakly-Supervised Neural Text Classification. In Proceedings of the Conference on Information and Knowledge Management, Turin, Italy, 22–26 October 2018; pp. 983–992. [Google Scholar]
- Chen, Q.; Hu, Q.; Huang, J.X.; He, L.; An, W. Enhancing Recurrent Neural Networks with Positional Attention for Question Answering. In Proceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–21 August 2017; pp. 993–996. [Google Scholar]
- Elnagar, A.; Lulu, L.; Einea, O. An Annotated Huge Dataset for Standard and Colloquial Arabic Reviews for Subjective Sentiment Analysis. Procedia Comput. Sci. 2018, 142, 182–189. [Google Scholar] [CrossRef]
- Pintelas, P.; Livieris, I.E. Special issue on ensemble learning and applications. Algorithms 2020, 13, 140. [Google Scholar] [CrossRef]
- Forman, G. BNS feature scaling: An improved representation over tf-idf for svm text classification. In Proceedings of the Conference on Information and Knowledge Management, Napa Valley, CA, USA, 26–30 October 2008; pp. 263–270. [Google Scholar]
- Zuo, Y.; Wu, J.; Zhang, H.; Lin, H.; Wang, F.; Xu, K.; Xiong, H. Topic Modeling of Short Texts: A Pseudo-Document View. In Proceedings of the Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 2105–2114. [Google Scholar]
- Wang, S.; Manning, C. Baselines and Bigrams: Simple, Good Sentiment and Topic Classification. In Proceedings of the Meeting of the Association for Computational Linguistics, Jeju, Korea, 8–14 July 2012; pp. 90–94. [Google Scholar]
- Zhang, Y.; Jin, R.; Zhou, Z.H. Understanding bag-of-words model: A statistical framework. Int. J. Mach. Learn. Cybern. 2010, 1, 43–52. [Google Scholar] [CrossRef]
- Mouratidis, D.; Kermanidis, K.L. Ensemble and deep learning for language-independent automatic selection of parallel data. Algorithms 2019, 12, 26. [Google Scholar] [CrossRef] [Green Version]
- Le, Q.; Mikolov, T. Distributed Representations of Sentences and Documents. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1188–1196. [Google Scholar]
- Cunha, W.; Mangaravite, V.; Gomes, C.; Canuto, S.; Resende, E.; Nascimento, C.; Viegas, F.; França, C.; Martins, W.S.; Almeida, J.M. On the cost-effectiveness of neural and non-neural approaches and representations for text classification: A comprehensive comparative study. Inf. Process. Manag. 2021, 58, 102481. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K.N. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the North American Chapter of the Association for Computational Linguistics, New Orleans, LA, USA, 1–8 June 2018; pp. 4171–4186. [Google Scholar]
- Zheng, J.; Cai, F.; Chen, H.; Rijke, M.d. Pre-train, Interact, Fine-tune: A novel interaction representation for text classification. Inf. Process. Manag. 2020, 57, 102215. [Google Scholar] [CrossRef] [Green Version]
- Muaad, A.Y.; Jayappa, H.; Al-antari, M.A.; Lee, S. ArCAR: A Novel Deep Learning Computer-Aided Recognition for Character-Level Arabic Text Representation and Recognition. Algorithms 2021, 14, 216. [Google Scholar] [CrossRef]
- McCann, B.; Bradbury, J.; Xiong, C.; Socher, R. Learned in translation: Contextualized word vectors. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6297–6308. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. In Proceedings of the North American Chapter of the Association for Computational Linguistics, New Orleans, LA, USA, 1–8 June 2018; pp. 2227–2237. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.S.; Dean, J. Efficient Estimation of Word Representations in Vector Space. In Proceedings of the International Conference on Learning Representations, Scottsdale, AZ, USA, 2–4 May 2013. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of the Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global Vectors for Word Representation. In Proceedings of the Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Sanchez-Reyes, L.M.; Rodriguez-Resendiz, J.; Avecilla-Ramirez, G.N.; Garcia-Gomar, M.L.; Robles-Ocampo, J.B. Impact of EEG Parameters Detecting Dementia Diseases: A Systematic Review. IEEE Access 2021, 9, 78060–78074. [Google Scholar] [CrossRef]
- Ortiz-Echeverri, C.J.; Salazar-Colores, S.; Rodríguez-Reséndiz, J.; Gómez-Loenzo, R.A. A new approach for motor imagery classification based on sorted blind source separation, continuous wavelet transform, and convolutional neural network. Sensors 2019, 19, 4541. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Villegas-Mier, C.G.; Rodriguez-Resendiz, J.; Álvarez-Alvarado, J.M.; Rodriguez-Resendiz, H.; Herrera-Navarro, A.M.; Rodríguez-Abreo, O. Artificial Neural Networks in MPPT Algorithms for Optimization of Photovoltaic Power Systems: A Review. Micromachines 2021, 12, 1260. [Google Scholar] [CrossRef] [PubMed]
- Gutierrez-Villalobos, J.M.; Rodriguez-Resendiz, J.; Rivas-Araiza, E.A.; Mucino, V.H. A review of parameter estimators and controllers for induction motors based on artificial neural networks. Neurocomputing 2013, 118, 87–100. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Liu, P.; Qiu, X.; Huang, X. Recurrent neural network for text classification with multi-task learning. In Proceedings of the International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 2873–2879. [Google Scholar]
- Battaglia, P.W.; Hamrick, J.B.; Bapst, V.; Sanchez-Gonzalez, A.; Zambaldi, V.; Malinowski, M.; Tacchetti, A.; Raposo, D.; Santoro, A.; Faulkner, R. Relational inductive biases, deep learning, and graph networks. arXiv 2018, arXiv:1806.01261. [Google Scholar]
- Cliche, M. BB_twtr at SemEval-2017 Task 4: Twitter Sentiment Analysis with CNNs and LSTMs. In Proceedings of the Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 573–580. [Google Scholar]
- Sun, C.; Qiu, X.; Xu, Y.; Huang, X. How to Fine-Tune BERT for Text Classification? In Proceedings of the China National Conference on Chinese Computational Linguistics, Kunming, China, 18–20 October 2019. [Google Scholar]
- Garg, S.; Ramakrishnan, G. BAE: BERT-based Adversarial Examples for Text Classification. In Proceedings of the The 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020. [Google Scholar]
- Zhou, J.; Cui, G.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. arXiv 2018, arXiv:1812.08434. [Google Scholar] [CrossRef]
- Yao, L.; Mao, C.; Luo, Y. Graph Convolutional Networks for Text Classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 July–1 February 2019; pp. 7370–7377. [Google Scholar]
- Huang, L.; Ma, D.; Li, S.; Zhang, X.; Wang, H. Text Level Graph Neural Network for Text Classification. In Proceedings of the Empirical Methods in Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 3442–3448. [Google Scholar]
- Zhang, Y.; Liu, Q.; Song, L. Sentence-State LSTM for Text Representation. In Proceedings of the Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 317–327. [Google Scholar]
- Mihalcea, R.; Tarau, P. TextRank: Bringing Order into Text. In Proceedings of the Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–26 July 2004; pp. 404–411. [Google Scholar]
- Ding, K.; Wang, J.; Li, J.; Li, D.; Liu, H. Be More with Less: Hypergraph Attention Networks for Inductive Text Classification. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020. [Google Scholar] [CrossRef]
- Liu, X.; You, X.; Zhang, X.; Wu, J.; Lv, P. Tensor Graph Convolutional Networks for Text Classification. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 1–12 February 2020; pp. 8409–8416. [Google Scholar]
- Zhang, Y.; Yu, X.; Cui, Z.; Wu, S.; Wen, Z.; Wang, L. Every Document Owns Its Structure: Inductive Text Classification via Graph Neural Networks. In Proceedings of the Meeting of the Association for Computational Linguistics, Online, 6–8 July 2020; pp. 334–339. [Google Scholar]
- Peng, H.; Li, J.; He, Y.; Liu, Y.; Bao, M.; Wang, L.; Song, Y.; Yang, Q. Large-Scale Hierarchical Text Classification with Recursively Regularized Deep Graph-CNN. In Proceedings of the The Web Conference, Lyon, France, 23–27 April 2018; pp. 1063–1072. [Google Scholar]
- Abdi, A.; Shamsuddin, S.M.; Hasan, S.; Piran, J. Deep learning-based sentiment classification of evaluative text based on Multi-feature fusion. Inf. Process. Manag. 2019, 56, 1245–1259. [Google Scholar] [CrossRef]
- Liu, Y.; Meng, F.; Chen, Y.; Xu, J.; Zhou, J. Depth-Adaptive Graph Recurrent Network for Text Classification. arXiv 2020, arXiv:2003.00166. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Wu, F.; Souza, A.H.; Zhang, T.; Fifty, C.; Yu, T.; Weinberger, K.Q. Simplifying Graph Convolutional Networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6861–6871. [Google Scholar]
- Chen, M.; Wei, Z.; Huang, Z.; Ding, B.; Li, Y. Simple and Deep Graph Convolutional Networks. In Proceedings of the International Conference on Machine Learning, Online, 13–18 July 2020; pp. 1725–1735. [Google Scholar]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level convolutional networks for text classification. In Proceedings of the Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 649–657. [Google Scholar]
- Pang, B.; Lee, L. Seeing Stars: Exploiting Class Relationships for Sentiment Categorization with Respect to Rating Scales. In Proceedings of the Meeting of the Association for Computational Linguistics, Ann Arbor, MI, USA, 25–30 June 2005; pp. 115–124. [Google Scholar]
- Tang, J.; Qu, M.; Mei, Q. PTE: Predictive Text Embedding through Large-scale Heterogeneous Text Networks. In Proceedings of the Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 1165–1174. [Google Scholar]
- Xu, J.; Xu, B.; Wang, P.; Zheng, S.; Tian, G.; Zhao, J. Self-Taught convolutional neural networks for short text clustering. Neural Netw. 2017, 88, 22–31. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of Tricks for Efficient Text Classification. In Proceedings of the Conference of the European Chapter of the Association for Computational Linguistics, Valencia, Spain, 3–7 April 2017; pp. 427–431. [Google Scholar]
- Shen, D.; Wang, G.; Wang, W.; Min, M.R.; Su, Q.; Zhang, Y.; Li, C.; Henao, R.; Carin, L. Baseline Needs More Love: On Simple Word-Embedding-Based Models and Associated Pooling Mechanisms. In Proceedings of the Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 440–450. [Google Scholar]
- Ragesh, R.; Sellamanickam, S.; Iyer, A.; Bairi, R.; Lingam, V. Hetegcn: Heterogeneous graph convolutional networks for text classification. In Proceedings of the Proceedings of the 14th ACM International Conference on Web Search and Data Mining, Jerusalem, Israel, 8–12 March 2021; pp. 860–868. [Google Scholar]
- Gao, H.; Chen, Y.; Ji, S. Learning Graph Pooling and Hybrid Convolutional Operations for Text Representations. In Proceedings of the The Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 2743–2749. [Google Scholar]
- Landro, N.; Gallo, I.; La Grassa, R. Combining Optimization Methods Using an Adaptive Meta Optimizer. Algorithms 2021, 14, 186. [Google Scholar] [CrossRef]
- Grover, A.; Leskovec, J. node2vec: Scalable Feature Learning for Networks. In Proceedings of the Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Abu-El-Haija, S.; Perozzi, B.; Al-Rfou, R.; Alemi, A.A. Watch Your Step: Learning Node Embeddings via Graph Attention. In Proceedings of the Neural Information Processing Systems, Montreal, QC, Canada, 2–8 December 2018; pp. 9180–9190. [Google Scholar]
- Linmei, H.; Yang, T.; Shi, C.; Ji, H.; Li, X. Heterogeneous Graph Attention Networks for Semi-supervised Short Text Classification. In Proceedings of the Empirical Methods in Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 4820–4829. [Google Scholar]





| Datasets | Doc | Train | Test | Classes | Avg Length | Max Length |
|---|---|---|---|---|---|---|
| R52 | 9100 | 6532 | 2568 | 52 | 69.82 | 612 |
| R8 | 7674 | 5485 | 2189 | 8 | 65.72 | 520 |
| Ag News Sub | 16,000 | 11,200 | 4800 | 4 | 28.11 | 146 |
| MR | 10,662 | 7108 | 3554 | 2 | 20.39 | 56 |
| SearchSnippets | 12,340 | 8636 | 3704 | 8 | 18.10 | 50 |
| SMS | 5574 | 3900 | 1674 | 2 | 17.11 | 190 |
| Biomedical | 20,000 | 14,000 | 6000 | 20 | 12.88 | 53 |
| Models | R8 | R52 | Agnewssub | MR | Searchsnippets | SMS | Biomedical |
|---|---|---|---|---|---|---|---|
| TextCNN | 95.71 ± 0.52 | 87.59 ± 0.48 | 88.74 ± 0.16 | 77.75 ± 0.72 | 89.52 ± 0.35 | 99.03 ± 0.05 | 73.08 ± 0.33 |
| Bi-LSTM | 96.31 ± 0.33 | 90.54 ± 0.91 | 87.68 ± 0.35 | 77.68 ± 0.86 | 84.81 ± 1.40 | 98.77 ± 0.10 | 63.42 ± 0.97 |
| fastText | 96.13 ± 0.21 | 92.81 ± 0.09 | 88.22 ± 0.04 | 75.14 ± 0.20 | 88.56 ± 0.12 | 98.84 ± 0.06 | 65.17 ± 0.22 |
| SWEM | 95.32 ± 0.26 | 92.94 ± 0.24 | 87.77 ± 0.05 | 76.65 ± 0.63 | 87.36 ± 0.32 | 98.33 ± 0.11 | 68.97 ± 0.20 |
| TextGCN | 97.07 ± 0.10 | 93.56 ± 0.18 | 87.55 ± 0.10 | 76.74 ± 0.20 | 83.49 ± 0.20 | 98.30 ± 0.05 | 69.67 ± 0.20 |
| TensorGCN | 98.04 ± 0.08 | 95.05 ± 0.11 | - | 77.91 ± 0.07 | - | - | - |
| S-LSTM | 97.67 ± 0.14 | 94.92 ± 0.19 | 88.21 ± 0.38 | 77.75 ± 0.31 | 87.54 ± 0.33 | 98.60 ± 0.08 | 73.77 ± 0.20 |
| TextING | 98.04 ± 0.25 | 95.48 ± 0.19 | 89.24 ± 0.20 | 79.82 ± 0.20 | 87.03 ± 0.43 | 98.89 ± 0.19 | 73.88 ± 0.50 |
| SGNN | 98.09 ± 0.08 | 95.46 ± 0.15 | 89.57 ± 0.25 | 80.58 ± 0.18 | 90.68 ± 0.32 | 99.22 ± 0.11 | 74.92 ± 0.34 |
| ESGNN | 98.23 ± 0.09 | 95.72 ± 0.16 | 89.66 ± 0.18 | 80.93 ± 0.14 | 90.80 ± 0.21 | 99.31 ± 0.06 | 75.34 ± 0.36 |
| Models | R8 | R52 | Agnewssub | MR | Searchsnippets | SMS | Biomedical |
|---|---|---|---|---|---|---|---|
| TextCNN | 93.24 | 60.93 | 88.14 | 77.25 | 88.12 | 97.21 | 71.95 |
| Bi-LSTM | 93.68 | 63.10 | 87.06 | 77.13 | 83.62 | 96.91 | 60.08 |
| fastText | 90.76 | 57.98 | 88.10 | 74.45 | 87.33 | 95.67 | 60.55 |
| SWEM | 89.29 | 48.27 | 86.98 | 75.67 | 87.06 | 95.42 | 68.19 |
| TextGCN | 93.38 | 67.79 | 86.88 | 76.24 | 82.74 | 95.62 | 69.76 |
| HeteGCN | 92.33 | 66.53 | - | 75.62 | - | - | - |
| S-LSTM | 93.80 | 73.33 | 87.44 | 76.96 | 86.63 | 96.03 | 71.53 |
| TextING | 93.62 | 73.38 | 88.89 | 79.02 | 86.26 | 97.19 | 72.14 |
| ESGNN | 94.31 | 74.54 | 88.95 | 79.83 | 89.10 | 97.87 | 73.02 |
| Dataset | TextGCN | TensorGCN | S-LSTM | TextING | SGNN | ESGNN |
|---|---|---|---|---|---|---|
| MR | 1.72 | 3.34 | 8.09 | 2.58 | 2.42 | 2.50 |
| R52 | 2.64 | 4.32 | 10.65 | 4.98 | 3.19 | 3.24 |
| Models | R8 | R52 | Agnewssub | MR | Searchsnippets | SMS | Biomedical |
|---|---|---|---|---|---|---|---|
| ESGNN | 98.23 ± 0.09 | 95.72 ± 0.16 | 89.66 ± 0.18 | 80.93 ± 0.14 | 90.80 ± 0.21 | 99.31 ± 0.06 | 75.34 ± 0.36 |
| BERT | 98.07 ± 0.13 | 95.79 ± 0.07 | 90.02 ± 0.23 | 85.86 ± 0.16 | 90.15 ± 0.11 | 99.40 ± 0.05 | 72.60 ± 0.33 |
| C-BERT | 98.28 ± 0.39 | 96.52 ± 0.85 | 90.36 ± 0.40 | 86.06 ± 0.73 | 90.43 ± 0.60 | 99.36 ± 0.08 | 74.15 ± 0.66 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, K.; Huang, L.; Song, R.; Shen, Q.; Xu, H. A Sequential Graph Neural Network for Short Text Classification. Algorithms 2021, 14, 352. https://doi.org/10.3390/a14120352
Zhao K, Huang L, Song R, Shen Q, Xu H. A Sequential Graph Neural Network for Short Text Classification. Algorithms. 2021; 14(12):352. https://doi.org/10.3390/a14120352
Chicago/Turabian StyleZhao, Ke, Lan Huang, Rui Song, Qiang Shen, and Hao Xu. 2021. "A Sequential Graph Neural Network for Short Text Classification" Algorithms 14, no. 12: 352. https://doi.org/10.3390/a14120352
APA StyleZhao, K., Huang, L., Song, R., Shen, Q., & Xu, H. (2021). A Sequential Graph Neural Network for Short Text Classification. Algorithms, 14(12), 352. https://doi.org/10.3390/a14120352