
Towards Interactive Analytics over RDF Graphs



Abstract
:1. Introduction
2. Requirements and Related Work
2.1. Requirements
2.2. Related Work
3. Background
3.1. Principles of Resource Description Framework (RDF)
- ex:ID4 rdf:type ex:Invoice.ex:ID4 ex:hasDate “2019-05-09”.ex:ID4 ex:takesPlaceAt ex:branch3.ex:ID4 ex:delivers ex:product4.ex:ID4 ex:inQuantity “400”.meaning that the type of “ex:ID4” is Invoice, it took place in “2019-05-09” at “branch3”, and delivered 400 items of ex:product4. Since data is in RDF each product has a URI and in this particular example we can see that the brand of “product4” is “Hermes” and that the founder of that brand is “Manousos”, who is both Greek and French.

3.2. HIFUN– A High Level Functional Query Language for Big Data Analytics
- 1.
- one or more roots (i.e., nodes with no entering arrows representing the objects of an application) may exist
- 2.
- at least one path from a root to every other node (i.e., attributes of the objects) exists
- 3.
- all arrow labels are distinct
- 4.
- each node is associated with a non-empty set of values
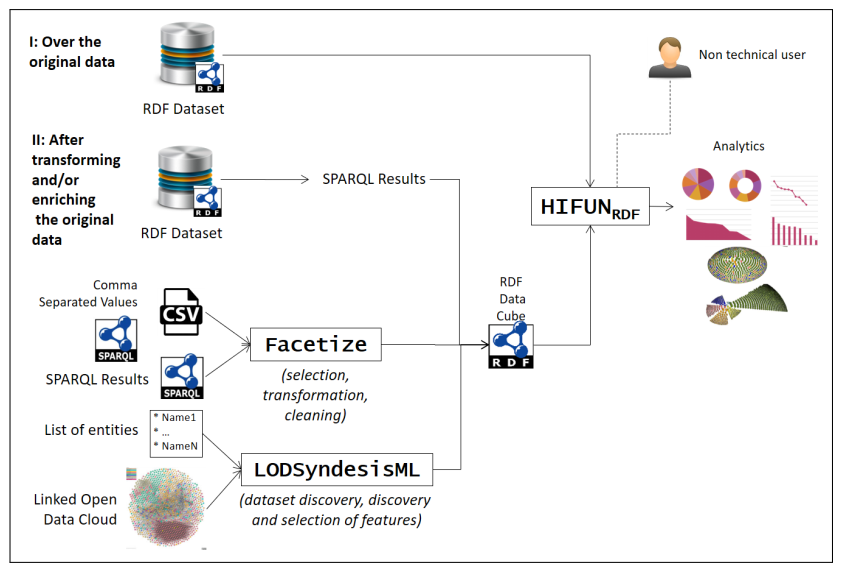
4. Using HIFUN as an Interface to RDF Dataset
5. Applicability of HIFUN over RDF
5.1. Prerequisites for Applying HIFUN over RDF Data
5.2. Methods to Apply HIFUN over RDF
- I:
- Defining an Analysis Context over the Original RDF Data. Here the user selects some properties, all satisfying the aforementioned assumptions. This is discussed in Section 5.3.
- II:
- Defining an Analysis Context after Transforming the Original RDF Data. Here the user transforms parts of the RDF graph in a way that satisfies the aforementioned assumptions. This is discussed in Section 5.4.
5.3. I: Defining an Analysis Context over the Original RDF Data
5.4. II: Defining an Analysis Context after Transforming the Original RDF Data
- suits to the normal case and it can be exploited to confirm that all the properties are functional e.g., the date that each product was delivered, the branch where each invoice took place. The value can be numerical or categorical.
- and relate to issues that concern missing and multi-valued properties and can be used for turning properties with empty values into integers.
- can be used for converting a multi-valued property to a set of single-valued features, e.g., one boolean feature for each nationality that a founder may have.
- and concern the degree of an entity and can be used to find the set of triples that contains a specific entity, defining its importance.
- to investigate paths in an RDF graph, e.g., whether at least one founder of a brand is “French”. It can be used for specifying a path (i.e., a sequence of properties etc.) and treat it as an individual property p.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| id | Operator Defining | Type | |
|---|---|---|---|
| Plain selection of one property | |||
| 1 | p.value | num/categ | |
| For missing values and multi-valued properties | |||
| 2 | p.exists | boolean | if or , otherwise |
| 3 | p.count | int | |
| For multi-valued properties | |||
| 4 | p.values.AsFeatures | boolean | for each we get the feature if or , otherwise |
| General ones | |||
| 5 | degree | double | |
| 6 | average degree | double | s.t. and |
| Indicative extensions for paths | |||
| 7 | p1.p2.exists | boolean | if s.t. |
| 8 | p1.p2.count | int | |
| 9 | p1.p2.value.maxFreq | num/categ | most frequent in |
6. Translation of HIFUN Queries to SPARQL
6.1. Simple Queries
- SELECT ?x2 SUM(?x3)WHERE {?x1 ex:takesPlaceAt ?x2 .?x1 ex:inQuantity ?x3 .}GROUP BY ?x2
6.2. Attribute-Restricted Queries
- SELECT ?x2 SUM(?x3)WHERE {?x1 ex:takesPlaceAt ?x2 .?x1 ex:inQuantity ?x3 .?x1 ex:takesPlaceAt branch1.}GROUP BY ?x2
- SELECT ?x2 SUM(?x3)WHERE {?x1 ex:takesPlaceAt ?x2 .?x1 ex:inQuantity ?x3 .FILTER(?x3 ≥ xsd:integer(“1”)).}GROUP BY ?x2
6.3. Results-Restricted Queries
- SELECT ?x2 SUM(?x3)WHERE {?x1 ex:takesPlaceAt ?x2 .?x1 ex:inQuantity ?x3 .}GROUP BY ?x2HAVING (SUM(?x3) > 1000)
6.4. Complex Grouping Queries
6.4.1. Composition
- SELECT ?x3 SUM(?x4)WHERE {?x1 ex:delivers ?x2 .?x2 ex:brand ?x3 .?x1 ex:inQuantity ?x4 .}GROUP BY ?x3
- SELECT month(?x2) SUM(?x3)WHERE {?x1 ex:hasDate ?x2 .?x1 ex:inQuantity ?x3 .}GROUP BY month(?x2)
6.4.2. Pairing
- SELECT ?x2 ?x4 SUM(?x3)WHERE {?x1 ex:takesPlaceAt ?x2 .?x1 ex:inQuantity ?x3 .?x1 ex:delivers ?x4.}GROUP BY ?x2 ?x4
6.5. The Full Algorithm for Translating a HIFUN Query to a SPARQL Query
- is the grouping expression,
- is the measuring expression,
- is the operation expression, and
- is a restriction on the grouping expression,
- is a restriction on he measuring expression, and
- is a restriction on the operation expression.
Q = “SELECT” +retVars(gE) + “ ”+opE(mE) +“\n”
+ “WHERE {” +“ \n”
+ triplePatterns(gE) +“ \n”
+ triplePatterns(mE) +“ \n”
+ “}” +“ \n”
+ “GROUP BY " +retVars(gE) +“ \n"
+“ HAVING " +restr()
- 1.
- We start the translation with the grouping expression by creating the string format of the triple patterns in which the terms of participates, triplePatterns(gE) += , as described in Section 6.1 and Section 6.4.If contains any restriction we supplementarily create the string format of the triple pattern expressing that constraint:
- 1.1.
- if refers to a URI, then triplePatterns(gE) += ,
- 1.2.
- if is represented with a LITERAL, then triplePatterns(gE) += FILTER(), as described in Section 6.2.
- 2.
- We proceed with the translation of the measuring expression by creating the string format of the triple patterns in which the terms of participates, triplePatterns(mE) += . Since this expression can also be complex, the translation is made as described in Section 6.1 and Section 6.4.If contains any restriction we supplementarily create the string format of the triple pattern expressing that constraint:
- 2.1.
- if refers to a URI, then triplePatterns(mE) += ,
- 2.2.
- if is represented with a LITERAL, then triplePatterns(mE) += FILTER(), as described in Section 6.2.
- 3.
- Following, we create the string format of the returned variables, retVars(gE) += as described in Section 6.1 and Section 6.4.
- 4.
- At last, we translate the aggregate expression by creating the string format of the operation applied over the values of , i.e., = op(), as described in Section 6.1.
- 5.
- Optionally, if any restrictions are applied to the final answers , then we create the string format of the condition expressing these constraints, restr() = right() re as described in Section 6.3.
- SELECT ?x2 ?x5 SUM(?x3)WHERE {?x1 ex:takesPlaceAt ?x2 .?x1 ex:inQuantity ?x3 .?x1 ex:delivers ?x4 .?x4 ex:brand ?x5 .?x1 ex:hasDate ?x6 .FILTER((MONTH(?x6) = 01) && (?x3 xsd:integer("2")))}GROUP BY ?x2 ?x5HAVING (SUM(?x3) > 1000)
| Algorithm 1 Algorithm for computing the components of the translated query for the Simple Case |
 |
| Algorithm 2 Auxiliary algorithms for compositions and pairings |
 |
| Algorithm 3 Algorithm for composition if derived attributes are involved |
 |
| Algorithm 4 Algorithm for computing the components of the translated query for the General case |
 |
6.6. Cases Where the Prerequisites of HIFUN Are Not Satisfied
- =SELECT ?x2 AVG(?x5) as productFoundBirthYearAvgWHERE {?x1 ex:delivers ?x2 .?x2 ex:brand ?x3 .?x3 ex:founder ?x4 .?x4 ex:birthYear ?x5 .}GROUP BY ?x2
- SELECT AVG(?productFoundBirthYearAvg)WHERE {?x1 ex:delivers ?x2 .{SELECT ?x2 (AVG(?x5) AS ?productFoundBirthYearAvg)WHERE {?x1 ex:delivers ?x2 .?x2 ex:brand ?x3 .?x3 ex:founder ?x4 .?x4 ex:birthYear ?x5 .}GROUP BY ?x2}}
6.7. Analytics and RDF Schema Semantics
- (p1,directorOf,brand1)(p2,worksAt,brand1)(p3,worksAt,brand1)(p4,worksAt,brand1)(p1,livesAt,Athens)(p2,livesAt,Rhodes)(p3,livesAt,Corfu),(p4,livesAt,Corfu)
- Athens,1Rhodes,1Corfu,2
7. On Interactivity
- An interactive method for specifying an Analysis Context. Recall that (according to Definition 3), an analysis context C over RDF data is defined as a set of resources R to be analyzed along with a set of properties that are relevant for the analysis.
- An interactive method for formulating the desired HIFUN query , i.e., a method to select g, m, and .
- A method to translate the HIFUN query to SPARQL.
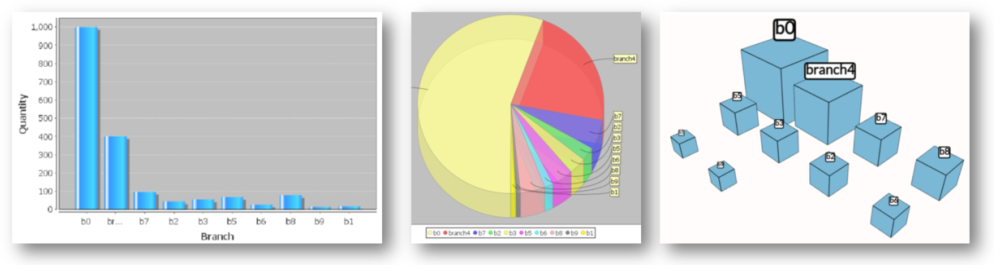
- A method for visualizing the results of the SPARQL query that is derived by translating q.
7.1. Future Work
8. Concluding Remarks
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mountantonakis, M.; Tzitzikas, Y. Large-scale Semantic Integration of Linked Data: A Survey. ACM Comput. Surv. (CSUR) 2019, 52, 103. [Google Scholar] [CrossRef]
- Bizer, C.; Lehmann, J.; Kobilarov, G.; Auer, S.; Becker, C.; Cyganiak, R.; Hellmann, S. DBpedia-A crystallization point for the Web of Data. J. Web Semant. 2009, 7, 154–165. [Google Scholar] [CrossRef]
- Vrandečić, D.; Krötzsch, M. Wikidata: A free collaborative knowledgebase. Commun. ACM 2014, 57, 78–85. [Google Scholar] [CrossRef]
- Wishart, D.S.; Feunang, Y.D.; Guo, A.C.; Lo, E.J.; Marcu, A.; Grant, J.R.; Sajed, T.; Johnson, D.; Li, C.; Sayeeda, Z.; et al. DrugBank 5.0: A major update to the DrugBank database for 2018. Nucleic Acids Res. 2018, 46, D1074–D1082. [Google Scholar] [CrossRef] [PubMed]
- Tzitzikas, Y.; Marketakis, Y.; Minadakis, N.; Mountantonakis, M.; Candela, L.; Mangiacrapa, F.; Pagano, P.; Perciante, C.; Castelli, D.; Taconet, M.; et al. Methods and Tools for Supporting the Integration of Stocks and Fisheries. In Chapter in Information and Communication Technologies in Modern Agricultural Development; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Jaradeh, M.Y.; Oelen, A.; Farfar, K.E.; Prinz, M.; D’Souza, J.; Kismihók, G.; Stocker, M.; Auer, S. Open Research Knowledge Graph: Next Generation Infrastructure for Semantic Scholarly Knowledge. In Proceedings of the 10th International Conference on Knowledge Capture, Marina Del Rey, CA, USA, 19–21 November 2019; pp. 243–246. [Google Scholar]
- Koho, M.; Ikkala, E.; Leskinen, P.; Tamper, M.; Tuominen, J.; Hyvönen, E. WarSampo Knowledge Graph: Finland in the Second World War as Linked Open Data. Semant. Web Interoper. Usability Appl. 2020. [Google Scholar] [CrossRef]
- Dimitrov, D.; Baran, E.; Fafalios, P.; Yu, R.; Zhu, X.; Zloch, M.; Dietze, S. TweetsCOV19—A Knowledge Base of Semantically Annotated Tweets about the COVID-19 Pandemic. In Proceedings of the 29th ACM International Conference on Information and Knowledge Management (CIKM 2020), Virtual Event, Galway, Ireland, 19–23 October 2020. [Google Scholar]
- COVID-19 Open Research Dataset (CORD-19). 2020. Available online: https://www.semanticscholar.org/cord19 (accessed on 23 January 2021).
- Raphaël, G.; Franck, M.; Fabien, G. CORD-19 Named Entities Knowledge Graph (CORD19-NEKG). 2020. Available online: https://zenodo.org/record/3827449#.YA5dhBYRXIU (accessed on 23 January 2021).
- Nikas, C.; Kadilierakis, G.; Fafalios, P.; Tzitzikas, Y. Keyword Search over RDF: Is a Single Perspective Enough? Big Data Cogn. Comput. 2020, 4, 22. [Google Scholar] [CrossRef]
- Tzitzikas, Y.; Manolis, N.; Papadakos, P. Faceted exploration of RDF/S datasets: A survey. J. Intell. Inf. Syst. 2017, 48, 329–364. [Google Scholar] [CrossRef]
- Kritsotakis, V.; Roussakis, Y.; Patkos, T.; Theodoridou, M. Assistive Query Building for Semantic Data. In Proceedings of the SEMANTICS Posters&Demos, Vienna, Austria, 10–13 September 2018. [Google Scholar]
- Spyratos, N.; Sugibuchi, T. HIFUN-a high level functional query language for big data analytics. J. Intell. Inf. Syst. 2018, 51, 529–555. [Google Scholar] [CrossRef]
- Papadaki, M.E.; Tzitzikas, Y.; Spyratos, N. Analytics over RDF Graphs. In Proceedings of the International Workshop on Information Search, Integration, and Personalization, Heraklion, Greece, 9–10 May 2019. [Google Scholar]
- Spyratos, N. A functional model for data analysis. In Proceedings of the International Conference on Flexible Query Answering Systems, Milan, Italy, 7–10 June 2006. [Google Scholar]
- Tzitzikas, Y.; Allocca, C.; Bekiari, C.; Marketakis, Y.; Fafalios, P.; Doerr, M.; Minadakis, N.; Patkos, T.; Candela, L. Integrating heterogeneous and distributed information about marine species through a top level ontology. In Proceedings of the Research Conference on Metadata and Semantic Research, Thessaloniki, Greece, 19–22 November 2013. [Google Scholar]
- Isaac, A.; Haslhofer, B. Europeana linked open data—Data. europeana. eu. Semant. Web 2013, 4, 291–297. [Google Scholar] [CrossRef]
- Mountantonakis, M.; Tzitzikas, Y. On measuring the lattice of commonalities among several linked datasets. Proc. VLDB Endow. 2016, 9, 1101–1112. [Google Scholar] [CrossRef]
- Mountantonakis, M.; Tzitzikas, Y. Scalable Methods for Measuring the Connectivity and Quality of Large Numbers of Linked Datasets. J. Data Inf. Qual. (JDIQ) 2018, 9, 1–49. [Google Scholar] [CrossRef]
- Roatis, A. Analysing RDF Data: A Realm of New Possibilities. ERCIM News. 2014. Available online: https://ercim-news.ercim.eu/en96/special/analysing-rdf-data-a-realm-of-new-possibilities (accessed on 23 January 2021).
- Kämpgen, B.; O’Riain, S.; Harth, A. Interacting with statistical linked data via OLAP operations. In Proceedings of the Extended Semantic Web Conference, Crete, Greece, 27–31 May 2012. [Google Scholar]
- Etcheverry, L.; Vaisman, A.A. QB4OLAP: A new vocabulary for OLAP cubes on the semantic web. In Proceedings of the Third International Conference on Consuming Linked Data, Boston, MA, USA, 12 November 2012. [Google Scholar]
- Azirani, E.A.; Goasdoué, F.; Manolescu, I.; Roatiş, A. Efficient OLAP operations for RDF analytics. In Proceedings of the 2015 31st IEEE International Conference on Data Engineering Workshops, Seoul, Korea, 13–17 April 2015; pp. 71–76. [Google Scholar]
- Ruback, L.; Pesce, M.; Manso, S.; Ortiga, S.; Salas, P.E.R.; Casanova, M.A. A mediator for statistical linked data. In Proceedings of the 28th Annual ACM Symposium on Applied Computing, Coimbra, Portugal, 18–22 March 2013. [Google Scholar]
- Etcheverry, L.; Vaisman, A.A. Enhancing OLAP analysis with web cubes. In Proceedings of the Extended Semantic Web Conference, Crete, Greece, 27–31 May 2012. [Google Scholar]
- Zhao, P.; Li, X.; Xin, D.; Han, J. Graph cube: On warehousing and OLAP multidimensional networks. In Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data, Athens, Greece, 12–16 June 2011. [Google Scholar]
- Benatallah, B.; Motahari-Nezhad, H.R. Scalable graph-based OLAP analytics over process execution data. Distrib. Parallel Databases 2016, 34, 379–423. [Google Scholar]
- Wang, K.; Xu, G.; Su, Z.; Liu, Y.D. GraphQ: Graph Query Processing with Abstraction Refinement—Scalable and Programmable Analytics over Very Large Graphs on a Single {PC}. In Proceedings of the 2015 Annual Technical Conference 15, Santa Clara, CA, USA, 8–10 July 2015. [Google Scholar]
- Zapilko, B.; Mathiak, B. Performing statistical methods on linked data. In Proceedings of the International Conference on Dublin Core and Metadata Applications, The Hague, The Netherlands, 21–23 September 2011. [Google Scholar]
- Olston, C.; Reed, B.; Srivastava, U.; Kumar, R.; Tomkins, A. Pig latin: A not-so-foreign language for data processing. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 9–12 June 2008. [Google Scholar]
- Thusoo, A.; Sarma, J.S.; Jain, N.; Shao, Z.; Chakka, P.; Zhang, N.; Antony, S.; Liu, H.; Murthy, R. Hive-a petabyte scale data warehouse using hadoop. In Proceedings of the 2010 IEEE 26th International Conference on Data Engineering (ICDE 2010), Long Beach, CA, USA, 1–6 March 2010. [Google Scholar]
- Etcheverry, L.; Vaisman, A.A. Querying Semantic Web Data Cubes. In Proceedings of the Alberto Mendelzon International Workshop on Foundations of Data Management, Panama City, Panama, 8–10 May 2016. [Google Scholar]
- Etcheverry, L.; Vaisman, A.A. Efficient Analytical Queries on Semantic Web Data Cubes. J. Data Semant. 2017, 6, 199–219. [Google Scholar] [CrossRef] [Green Version]
- Colazzo, D.; Goasdoué, F.; Manolescu, I.; Roatiş, A. RDF analytics: Lenses over semantic graphs. In Proceedings of the 23rd International Conference on World Wide Web, Seoul, Korea, 7–11 April 2014. [Google Scholar]
- Diao, Y.; Guzewicz, P.; Manolescu, I.; Mazuran, M. Spade: A modular framework for analytical exploration of RDF graphs. In Proceedings of the VLDB Endowment 2019, Los Angeles, CA, USA, 26–30 August 2019. [Google Scholar]
- Antoniou, G.; Van Harmelen, F. A Semantic Web Primer; MIT Press: Cambridge, MA, USA, 2004. [Google Scholar]
- Mountantonakis, M.; Tzitzikas, Y. LODsyndesis: Global Scale Knowledge Services. Heritage 2018, 1, 335–348. [Google Scholar] [CrossRef] [Green Version]
- Spyratos, N.; Sugibuchi, T. Data Exploration in the HIFUN Language. In Proceedings of the International Conference on Flexible Query Answering Systems, Amantea, Italy, 2–5 July 2019. [Google Scholar]
- Mountantonakis, M.; Tzitzikas, Y. How linked data can aid machine learning-based tasks. In Proceedings of the International Conference on Theory and Practice of Digital Libraries, Thessaloniki, Greece, 18–21 September 2017. [Google Scholar]
- Mami, M.N.; Graux, D.; Thakkar, H.; Scerri, S.; Auer, S.; Lehmann, J. The query translation landscape: A survey. arXiv 2019, arXiv:1910.03118. [Google Scholar]
- Fafalios, P.; Petrakis, C.; Samaritakis, G.; Doerr, K.; Tzitzikas, Y.; Doerr, M. FastCat: Collaborative Data Entry and Curation for Semantic Interoperability in Digital Humanities. ACM J. Comput. Cult. Herit. 2021. accepted for publication. [Google Scholar]
- Kokolaki, A.; Tzitzikas, Y. Facetize: An Interactive Tool for Cleaning and Transforming Datasets for Facilitating Exploratory Search. arXiv 2018, arXiv:1812.10734. [Google Scholar]
- Andrienko, G.; Andrienko, N.; Drucker, S.; Fekete, J.D.; Fisher, D.; Idreos, S.; Kraska, T.; Li, G.; Ma, K.L.; Mackinlay, J.; et al. Big Data Visualization and Analytics: Future Research Challenges and Emerging Applications. In Proceedings of the BigVis 2020: Big Data Visual Exploration and Analytics, Copenhagen, Denmark, 30 March 2020. [Google Scholar]
- Papadaki, M.E.; Papadakos, P.; Mountantonakis, M.; Tzitzikas, Y. An Interactive 3D Visualization for the LOD Cloud. In Proceedings of the EDBT/ICDT Workshops, Vienna, Austria, 26 March 2018. [Google Scholar]
- Zervoudakis, P.; Kondylakis, H.; Plexousakis, D.; Spyratos, N. Incremental Evaluation of Continuous Analytic Queries in HIFUN. In Proceedings of the International Workshop on Information Search, Integration, and Personalization, Heraklion, Greece, 9–10 May 2019; pp. 53–67. [Google Scholar]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Papadaki, M.-E.; Spyratos, N.; Tzitzikas, Y. Towards Interactive Analytics over RDF Graphs. Algorithms 2021, 14, 34. https://doi.org/10.3390/a14020034
Papadaki M-E, Spyratos N, Tzitzikas Y. Towards Interactive Analytics over RDF Graphs. Algorithms. 2021; 14(2):34. https://doi.org/10.3390/a14020034
Chicago/Turabian StylePapadaki, Maria-Evangelia, Nicolas Spyratos, and Yannis Tzitzikas. 2021. "Towards Interactive Analytics over RDF Graphs" Algorithms 14, no. 2: 34. https://doi.org/10.3390/a14020034
APA StylePapadaki, M.-E., Spyratos, N., & Tzitzikas, Y. (2021). Towards Interactive Analytics over RDF Graphs. Algorithms, 14(2), 34. https://doi.org/10.3390/a14020034